記事「アルゴリズム取引戦略:AIで金市場の頂点を目指す」についてのディスカッション
この記事を読んだ後、クラスタリング処理そのものを弄ることを思いついた。
データセット全体ではなく、スライディングウィンドウでクラスタリングを実行する変種を書いた。これにより、BPの時間的構造を考慮したクラスタの分割が改善されるかもしれない。
def sliding_window_clustering(dataset, n_clusters: int, window_size=200) -> pd.DataFrame: import numpy as np data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() meta_X = data.loc[:, data.columns.str.contains('meta_feature')] # 最初にグローバルな参照用セントロイドを作成する global_kmeans = KMeans(n_clusters=n_clusters).fit(meta_X) global_centroids = global_kmeans.cluster_centers_ clusters = np.zeros(len(data)) # スライディングウィンドウでクラスタリングを適用する for i in range(0, len(data) - window_size + 1, window_size): window_data = meta_X.iloc[i:i+window_size] # 現在のウィンドウでKMeansを教える local_kmeans = KMeans(n_clusters=n_clusters).fit(window_data) local_centroids = local_kmeans.cluster_centers_ # ローカルなセントロイドをグローバルなセントロイドに合わせる # クラスタラベルの一貫性を確保する centroid_mapping = {} for local_idx in range(n_clusters): # このローカルセントロイドに最も近いグローバルセントロイドを見つける distances = np.linalg.norm(local_centroids[local_idx] - global_centroids, axis=1) global_idx = np.argmin(distances) centroid_mapping[local_idx] = global_idx + 1 1 からナンバリングを開始するには # +1 # 現在のウィンドウのラベルを取得する local_labels = local_kmeans.predict(window_data) # ローカルラベルを一貫性のあるグローバルラベルに変換する for j in range(window_size): if i+j < len(clusters): # アウトオブバウンズのチェック clusters[i+j] = centroid_mapping[local_labels[j]] data['clusters'] = clusters return data
この関数をコードに挿入し、クラスタリングをsliding_window_clusteringに置き換えてください。
結果は改善されるようだ。
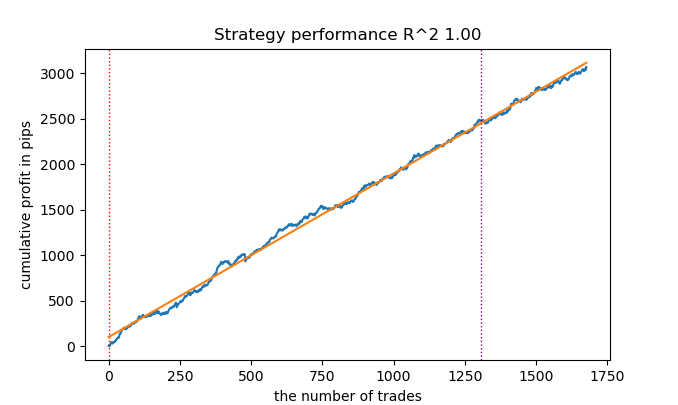
それでも、記事を書くことが役に立つこともある。
ドミトリエフスキーさん、記事ありがとうございます。アップロードしたEAとインクルードファイルが不一致のようです。mpqファイルは "Trend following "フォルダにありますが、サンプルファイルは "Mean reversion "フォルダにあります。
また、"causal one direction.py "のget_features関数は記事にあるものとは異なります。さらに、.onnxをエクスポートする際に "causal one direction.py " が生成するmqhファイルは、MQL5_files.zipで提供されているものと同じではありません。
必要な説明をしていただければ幸いです。
ポール

ドミトリエフスキーさん、記事ありがとうございます。アップロードしたEAとインクルードファイルが不一致のようです。mpqファイルは "Trend following "フォルダにありますが、サンプルファイルは "Mean reversion "フォルダにあります。
また、"causal one direction.py "のget_features関数は記事にあるものとは異なります。また、"causal one direction.py "が.onnxをエクスポートする際に 生成するmqhファイルは、MQL5_files.zipで提供されているものとは異なります。
必要な説明をしていただければ幸いです。
ポール
アーカイブを更新し、新しいクラスタリング手法を追加した。
これですべてのパスと関数が一致するようになった。
つまり、R2は修正指数であり、その効率はpipsの利益に基づいています。ドローダウンやその他のパフォーマンス指標はどうでしょうか?トレーニングで90%以上、テストで85%以上の結果を出すモデルがあれば、その指標は印象的な数字になるでしょう。MT5で何度テスターを実行しても、履歴で利益を得たことがありません。入金は途絶えています。Pythonのテスターでは0.97-0.98の利益を出しているにもかかわらずです。
これがCVと何の関係があるのか理解できません。
これらの戦略はすべて、非定常相場の履歴のみに基づいているため、証明力が低い。しかし、トレンドを捉えることはできる。- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
新しい記事「アルゴリズム取引戦略:AIで金市場の頂点を目指す」はパブリッシュされました:
機械学習手法が取引分野で有効であることが広く認識されるようになり、さまざまなアルゴリズムが生まれました。これらのアルゴリズムは、同じタスクに対して同様の性能を発揮しますが、基本的な仕組みは異なります。本記事でも金市場における一方向型のトレンドフォロー戦略を構築しますが、今回はクラスタリングアルゴリズムを使用します。
このように、時系列データを多角的に分析・予測する重要なアプローチを考慮することで、従来の金融時系列の分析と予測のみを基にした取引システム作成法と比較し、利点や欠点を評価することが可能です。場合によっては、これらのアルゴリズムは非常に高い効果を発揮し、作成速度や生成される取引システムの品質の両面で、従来手法を上回ることもあります。
本記事では、一方向性取引戦略に焦点を当てます。この場合、アルゴリズムは買いまたは売りのいずれか一方向のポジションのみを保有します。基本アルゴリズムとしてCatBoostとK-Meansを使用します。CatBoostは、取引方向を判定する二値分類モデルとして機能します。一方、K-Meansは、前処理フェーズで市場のモードを判定するために使用されます。
作者: dmitrievsky