
ゴールドを例にした一方向トレンド取引における機械学習の考察
はじめに
最近、私たちは二値分類の観点から対称的な取引システムの実装を研究してきました。買いと売りの取引は特徴空間上でうまく分離できると仮定し、機械学習アルゴリズムが買いと売りポジションの両方を同等に予測できるような分離境界(超平面)が存在すると考えました。
しかし実際には、これは常に当てはまるわけではありません。特に一部の金属や指数、暗号資産のように明確なトレンドを持つ取引対象ではそうです。そのような資産では、双方向の取引システムはリスクが高くなる可能性があります。また、取引結果の分布は大きく非対称になることがあり、多くの誤分類が発生する原因となります。
この場合、双方向の取引システムは効果的でないことがあり、一方向の取引に集中する方が適しています。本記事では、そのような一方向の戦略を構築するための機械学習の特徴について解説します。
私は、因果推論のアプローチを一方向取引の課題に合わせて再考し、適応させる必要があると考えています。
前回の記事の内容を前提として参照します。
因果推論とテストの考え方をより深く理解するために、これらの記事を読むことを強くお勧めします。
指定方向の取引サンプラーの作成
これまでは買いと売りの取引を同時にラベル付けしていたため、ラベル付けロジックを修正し、選択した方向の取引のみをラベル付けする必要があります。以下は、本記事で使用するそのようなサンプラーの例です。
@njit def calculate_labels_one_direction(close_data, markup, min, max, direction): labels = [] for i in range(len(close_data) - max): rand = random.randint(min, max) curr_pr = close_data[i] future_pr = close_data[i + rand] if direction == "sell": if (future_pr + markup) < curr_pr: labels.append(1.0) else: labels.append(0.0) if direction == "buy": if (future_pr - markup) > curr_pr: labels.append(1.0) else: labels.append(0.0) return labels def get_labels_one_direction(dataset, markup, min = 1, max = 15, direction = 'buy') -> pd.DataFrame: close_data = dataset['close'].values labels = calculate_labels_one_direction(close_data, markup, min, max, direction) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() return dataset
新しいdirectionパラメータにより、買い取引または売り取引のラベル付け対象の方向を指定できます。これにより、クラス1は選択した方向で取引をおこなうべきであることを示し、クラス0はこの時点で取引をおこなわない方がよいことを示します。また、パラメータによって{min, max}の範囲でランダムに取引期間を設定できます。取引期間は、エントリーからの経過バー数で定義されます。このサンプラーは非常にシンプルですが、この種の戦略においては実績ある方法です。
カスタムストラテジーテスターの修正
一方向取引戦略では、これまでとは異なるテストロジックが必要になります。そのため、ストラテジーテスター自体をロジックに合わせて変更する必要があります。tester_lib.pyモジュールには、一方向取引用の関数が追加されました。詳しく見てみましょう。
関数process_data_one_direction()は、一方向取引のデータを処理します。
@jit(nopython=True) def process_data_one_direction(close, labels, metalabels, stop, take, markup, forward, backward, direction): last_deal = 2 last_price = 0.0 report = [0.0] chart = [0.0] line_f = 0 line_b = 0 for i in range(len(close)): line_f = len(report) if i <= forward else line_f line_b = len(report) if i <= backward else line_b pred = labels[i] pr = close[i] pred_meta = metalabels[i] # 1 = allow trades if last_deal == 2 and pred_meta == 1: last_price = pr last_deal = 2 if pred < 0.5 else 1 continue if last_deal == 1 and direction == 'buy': if (-markup + (pr - last_price) >= take) or (-markup + (last_price - pr) >= stop): last_deal = 2 profit = -markup + (pr - last_price) report.append(report[-1] + profit) chart.append(chart[-1] + profit) continue if last_deal == 1 and direction == 'sell': if (-markup + (pr - last_price) >= stop) or (-markup + (last_price - pr) >= take): last_deal = 2 profit = -markup + (last_price - pr) report.append(report[-1] + profit) chart.append(chart[-1] + (pr - last_price)) continue # close deals by signals if last_deal == 1 and pred < 0.5 and direction == 'buy': last_deal = 2 profit = -markup + (pr - last_price) report.append(report[-1] + profit) chart.append(chart[-1] + profit) continue if last_deal == 1 and pred < 0.5 and direction == 'sell': last_deal = 2 profit = -markup + (last_price - pr) report.append(report[-1] + profit) chart.append(chart[-1] + (pr - last_price)) continue return np.array(report), np.array(chart), line_f, line_b
基本関数との主な違いは、テスターで使用する取引の種類(買いまたは売り)を明示的に示すフラグが追加されたことです。Numbaによる高速化により非常に速く動作し、各取引からの利益を計算しながら価格履歴を順に処理します。このテスターは、モデルのシグナルだけでなく、ストップロスやテイクプロフィットによっても取引を決済できる点に注意してください。どの条件が先に満たされるかによって決まるため、学習段階でリスクに応じたモデル選択が可能になります。
tester_one_direction()関数は、価格とラベルを含むラベル付け済みデータセットを受け取り、process_data_one_direction()関数に渡します。その後、チャート描画のために結果を取得します。
def tester_one_direction(*args): ''' This is a fast strategy tester based on numba List of parameters: dataset: must contain first column as 'close' and last columns with "labels" and "meta_labels" stop: stop loss value take: take profit value forward: forward time interval backward: backward time interval markup: markup value direction: buy/sell plot: false/true ''' dataset, stop, take, forward, backward, markup, direction, plot = args forw = dataset.index.get_indexer([forward], method='nearest')[0] backw = dataset.index.get_indexer([backward], method='nearest')[0] close = dataset['close'].to_numpy() labels = dataset['labels'].to_numpy() metalabels = dataset['meta_labels'].to_numpy() report, chart, line_f, line_b = process_data_one_direction(close, labels, metalabels, stop, take, markup, forw, backw, direction) y = report.reshape(-1, 1) X = np.arange(len(report)).reshape(-1, 1) lr = LinearRegression() lr.fit(X, y) l = 1 if lr.coef_[0][0] >= 0 else -1 if plot: plt.plot(report) plt.axvline(x=line_f, color='purple', ls=':', lw=1, label='OOS') plt.axvline(x=line_b, color='red', ls=':', lw=1, label='OOS2') plt.plot(lr.predict(X)) plt.title("Strategy performance R^2 " + str(format(lr.score(X, y) * l, ".2f"))) plt.xlabel("the number of trades") plt.ylabel("cumulative profit in pips") plt.show() return lr.score(X, y) * l
test_model_one_direction()関数は、選択したデータに基づいてモデルの予測を取得します。取得した予測はtester_one_direction()関数に渡され、モデルのテスト結果を算出します。
def test_model_one_direction(dataset: pd.DataFrame, result: list, stop: float, take: float, forward: float, backward: float, markup: float, direction: str, plt = False): ext_dataset = dataset.copy() X = ext_dataset[ext_dataset.columns[1:]] ext_dataset['labels'] = result[0].predict_proba(X)[:,1] ext_dataset['meta_labels'] = result[1].predict_proba(X)[:,1] ext_dataset['labels'] = ext_dataset['labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) ext_dataset['meta_labels'] = ext_dataset['meta_labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) return tester_one_direction(ext_dataset, stop, take, forward, backward, markup, direction, plt)
メタラーナー:取引システムの心臓部
まず、クロスバリデーションに関する記事で紹介した最初のメタラーナーを考えてみましょう。そして、なぜ一方向戦略の場合に双方向戦略よりも効果が高くなるのか、論理的に説明します。
def meta_learner(folds_number: int, iter: int, depth: int, l_rate: float) -> pd.DataFrame: dataset = get_labels_one_direction(get_features(get_prices()), markup=hyper_params['markup'], min=1, max=15, direction=hyper_params['direction']) data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() X = data[data.columns[1:-2]] y = data['labels'] B_S_B = pd.DatetimeIndex([]) # learn meta model with CV method meta_model = CatBoostClassifier(iterations = iter, max_depth = depth, learning_rate=l_rate, verbose = False) cv = StratifiedKFold(n_splits=folds_number, shuffle=False) predicted = cross_val_predict(meta_model, X, y, method='predict_proba', cv=cv) coreset = X.copy() coreset['labels'] = y coreset['labels_pred'] = [x[0] < 0.5 for x in predicted] coreset['labels_pred'] = coreset['labels_pred'].apply(lambda x: 0 if x < 0.5 else 1) # select bad samples (bad labels indices) diff_negatives = coreset['labels'] != coreset['labels_pred'] B_S_B = B_S_B.append(diff_negatives[diff_negatives == True].index) to_mark = B_S_B.value_counts() marked_idx = to_mark.index data['meta_labels'] = 1.0 data.loc[data.index.isin(marked_idx), 'meta_labels'] = 0.0 data.loc[data.index.isin(marked_idx), 'labels'] = 0.0 return data[data.columns[:]]
分かりやすくするために、以下にmeta_learner()関数の主要なブロックを示した模式図を提示します。各ブロックは異なる機能を担当しています。
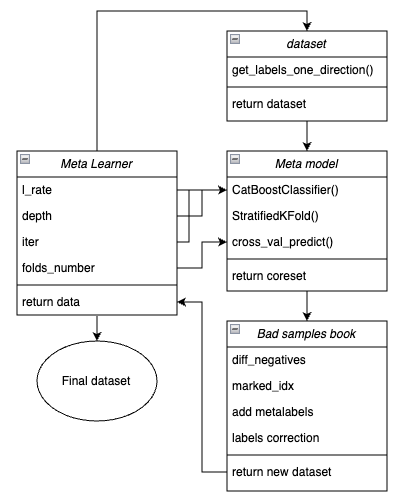
図1:meta_learner()関数の概略図
メタラーナーは、初期データと最終モデルの間の伝達ギアの役割を持つことを思い出してください。メタモデルを用いてメタラベルを作成することで、効果的な前処理の主要な負荷を引き受けます。私が開発したこの関数の独自性は、データセットを精査・整備して構築する点にあります。このため、堅牢なモデルと取引システムの構築が可能になります。
関数の入力パラメータ
- l_rate(学習率)は、メタモデル、またはCatBoost分類器の勾配更新幅です。通常{0.01, 0.5}の範囲で設定します。このパラメータに対してアルゴリズムは敏感です。
- depth(深さ)は、CatBoost分類器の各イテレーションで構築される決定木の深さを指定します。推奨範囲は{1, 6}です。
- iter(反復数)はモデルの学習回数です。通常{5, 25}の範囲で設定します。
- folds_number(フォールド数)は、クロスバリデーションに使用する分割数です。通常は、{5、15}フォールドで十分です。
関数の動作メカニズム
- 特徴量とラベルを含むデータセットを作成します。先に説明したget_labels_one_direction()関数がサンプラーとして使用されます。
- 指定されたパラメータでメタラーナーを学習させます。StratifiedKFold()関数を用いたクロスバリデーションモードで学習します。この関数は、クラスのバランスを考慮しながら学習データを複数のフォールドに分割します。各フォールドごとにメタモデルが学習され、すべての予測が保存されます。これは、学習データに対するモデル誤差を偏りなく評価するために必要です。保存された予測値は、元のラベルとの比較に使用されます。
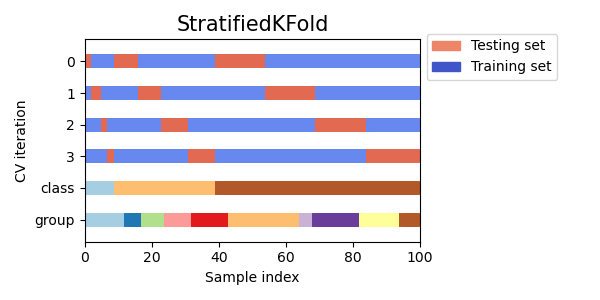
図2:StratifiedKFold()関数によるデータのフォールド分割の模式図
- クロスバリデーションで得られた予測ラベルと元のラベルの両方を記録するコアセットデータセットを作成します。
- diff_negativesという変数を作成し、元のラベルと予測ラベルの一致と不一致をバイナリフラグで保存します。
- 不正確なサンプルのインデックスを記録するB_S_B (Bad Samples Book)を作成します。この中には、予測が元のラベルと一致しなかったデータセット行の時刻インデックスが記録されます。
- すべてのフォールドに対して誤って予測された例の一意のインデックスを抽出します。
- 元のデータセットに「meta_labels」という追加列を作成し、すべての観測値に1(取引可能)を割り当てます。
- クロスバリデーション中に予測が不正確だったすべての例に対して、meta_labels列に0(取引不可)を割り当てます。
- また、不正確に予測されたサンプルについては、メインモデル用のlabels列にも0(取引不可)を割り当てます。
- 関数は、修正されたデータセットを返します。
より信頼性の高い因果推論
前のセクションでは、基本的なメタラーナーについて説明しました。この例は、基本概念を理解しやすくするためのものです。このセクションでは、アプローチをやや高度化し、因果推論そのもののプロセスを直接検討します。リンク先の記事で紹介した因果推論関数を、一方向取引に適用できるように改良しました。この手法はより高度で、柔軟な機能を備えています。
def meta_learners(models_number: int, iterations: int, depth: int, bad_samples_fraction: float): dataset = get_labels_one_direction(get_features(get_prices()), markup=hyper_params['markup'], min=1, max=15, direction=hyper_params['direction']) data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() X = data[data.columns[1:-2]] y = data['labels'] BAD_WAIT = pd.DatetimeIndex([]) BAD_TRADE = pd.DatetimeIndex([]) for i in range(models_number): X_train, X_val, y_train, y_val = train_test_split( X, y, train_size = 0.5, test_size = 0.5, shuffle = True) # learn debias model with train and validation subsets meta_m = CatBoostClassifier(iterations = iterations, depth = depth, custom_loss = ['Accuracy'], eval_metric = 'Accuracy', verbose = False, use_best_model = True) meta_m.fit(X_train, y_train, eval_set = (X_val, y_val), plot = False) coreset = X.copy() coreset['labels'] = y coreset['labels_pred'] = meta_m.predict_proba(X)[:, 1] coreset['labels_pred'] = coreset['labels_pred'].apply(lambda x: 0 if x < 0.5 else 1) # add bad samples of this iteration (bad labels indices) coreset_w = coreset[coreset['labels']==0] coreset_t = coreset[coreset['labels']==1] diff_negatives_w = coreset_w['labels'] != coreset_w['labels_pred'] diff_negatives_t = coreset_t['labels'] != coreset_t['labels_pred'] BAD_WAIT = BAD_WAIT.append(diff_negatives_w[diff_negatives_w == True].index) BAD_TRADE = BAD_TRADE.append(diff_negatives_t[diff_negatives_t == True].index) to_mark_w = BAD_WAIT.value_counts() to_mark_t = BAD_TRADE.value_counts() marked_idx_w = to_mark_w[to_mark_w > to_mark_w.mean() * bad_samples_fraction].index marked_idx_t = to_mark_t[to_mark_t > to_mark_t.mean() * bad_samples_fraction].index data['meta_labels'] = 1.0 data.loc[data.index.isin(marked_idx_w), 'meta_labels'] = 0.0 data.loc[data.index.isin(marked_idx_t), 'meta_labels'] = 0.0 data.loc[data.index.isin(marked_idx_t), 'labels'] = 0.0 return data[data.columns[:]]
以下は、meta_learners()関数の主要ブロックを示した模式図です。各ブロックは異なる機能を担っています。
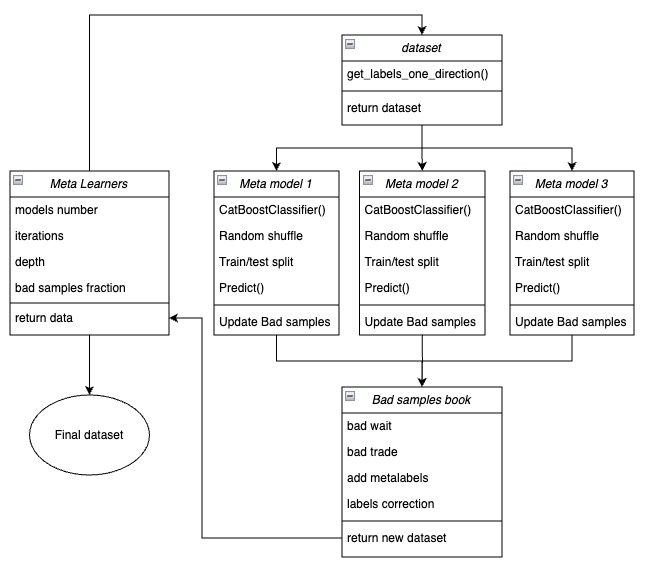
図3:meta_learners()関数の概略図
この関数の特徴は、複数のメタモデル(いわば複数の「ヘッド」)を持つ点にあります。これらは、ブートストラップ法(復元抽出)によって生成された元データのランダムなサブサンプル上で学習されます。この手法により、元のデータセットから複数のサブサンプルを生成できます。そして、このサブサンプル集合に基づいて統計的および確率的特性を評価できます。
たとえば、集団から抽出された特定のサンプルが、異なるサブサンプルで学習した複数のモデルにおいてどの程度正確に予測されるか、その平均値を評価できます。これにより、各サンプルに対してよりバイアスの少ない評価が可能となり、信頼度の高い「良いサンプル」「悪いサンプル」の判定が可能になります。
関数の入力パラメータ
- models_numberは、アルゴリズムで使用されるメタモデルの数です。推奨範囲は{5, 100}です。
- iterationsは、各モデルの学習反復数です。推奨範囲は{15, 35}です。
- depthは、CatBoost分類器の各イテレーションで構築される決定木の深さです。推奨範囲は{1, 6}です。
- bad_samples_fractionは、「悪いサンプル」としてマークする割合を制御するパラメータです。推奨範囲は{0.4, 0.9}です。
関数の動作メカニズム
- 指定した取引方向に対する特徴量とラベルを含むデータセットを作成します。
- ループ内で、各メタモデルがブートストラップ法を用いてランダムに選択された学習データおよび検証データで学習されます。
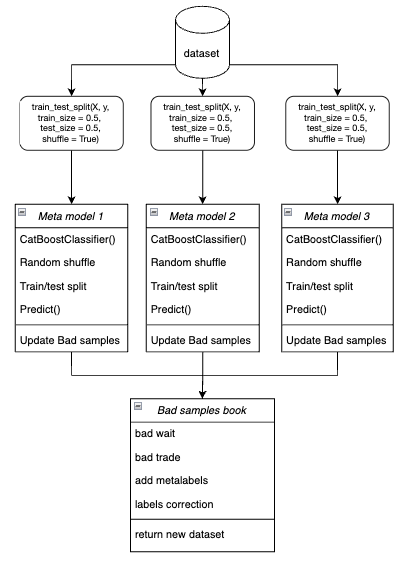
図4:ブートストラップサンプリングの模式図
- 各モデルについて、その予測結果を真のラベルと比較します。誤分類されたインデックスは「Bad Samples Book」に保存されます。
- すべての反復における誤分類インデックスの平均出現回数を算出します。
- 誤分類回数が最も多く、かつ「平均値×閾値」を超えるインデックスを抽出し、meta_labels列に0(取引禁止)として設定します。
- 同じ原則に基づき、labels列も0に設定します。
一方向取引におけるメタラーナー活用の哲学
- メタラーナーのコードは、ラベル付け済みデータセットに含まれる「悪い」シグナルをフィルタリングする問題を解決します。
- 分類タスクを単純化します。特徴量は一種類のパターン(例えばトレンド継続)にのみ最適化されます。
- クラスバランスが取れている場合(買い50%/売り50%)でも、トレンドには非対称性が残ります。トレンド方向の買いはより安定したパターンを持つ一方で、逆張りの売りはノイズ的な事象(調整局面やダマシ反転)に関連することが多く、予測が困難です。
- 上昇トレンド中の売りシグナルの多くは、初期段階では偽陽性になります。これは分類エラーの増加につながります。そのため、双方向取引では買いと売りは本質的に性質が異なり、単純に比較することはできません。
- 一方向システムでは、エラーはトレンド方向への誤ったエントリー(たとえば調整前の早すぎるエントリー)に限定されます。メタラーナーは、そのようなケースを効果的に検出できます。なぜなら、これらは明確な兆候(例:買われ過ぎ)を伴うからです。一方、双方向システムでは、偽の買いと偽の売りの両方がエラーに含まれ、それらは類似したパターンを持つことがあります。その結果、特徴量が混在し、「ノイズ」と真のシグナルを高い信頼性で分離することが難しくなります。
- 一方向システムでは、モデルは単一の非定常性(たとえばトレンド強化)に集中できます。これにより、特徴量は現在の市場局面に適応しやすくなります。
- 双方向システムでは、トレンドと調整という2種類の非定常性が存在します。そのため、より多くのデータが必要となり、汎化も困難になります。
結果
- 分類タスクが単純化されます。2つのクラスを同時に正しく予測する必要はなく、1つのクラスに集中すれば十分です。
- ノイズが低減されます。最終的なメタモデルは一種類のエラーのみをフィルタリングします。
- クロスバリデーションの効果が向上します。層化がより適切に機能します。
- トレンドの非定常性が考慮されます。モデルは単一の市場局面に適応します。
メタラーナーの重要な特徴
メタラーナーは、メタラーナーによって準備されたラベルで学習される最終メタモデルと混同してはなりません。メタラーナーは最終モデルではなく、前処理段階でのみ使用されます。基本学習器としては、ロジスティック回帰、ニューラルネットワーク、ツリーベースモデルなど、あらゆる二値分類アルゴリズムを使用できます。また、若干のコード修正により回帰モデルを使用することも可能ですが、それは本記事の範囲を超えるため、今後の記事で扱うこととします。本記事では利便性のため、私が使い慣れているCatBoostの二値分類器を使用しています。
学習に関連する特徴量
前述のとおり、一方向取引は分類タスクを単純化します。特徴量は一種類のパターン(たとえば買い)にのみ最適化されるため、対称的な特徴量は不要になります。対称的な特徴量とは、異なる時間ラグを持つ元の時系列データであり、その値が買いと売りの両方に対応するものや、価格変化量(増分)や各種オシレーターなどの派生指標を指します。一方、非対称的な特徴量には、異なる時間ウィンドウで計算されるボラティリティが含まれます。ボラティリティは価格変動の大きさを反映しますが、方向性は含みません。このプロジェクトでは、periods変数で指定された複数のウィンドウを用いたボラティリティを使用します。
以下は、特徴量生成を実装する完全なコードです。
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC.rolling(i).std() count += 1 return pFixed.dropna()
スライディングウィンドウの期間は辞書内で指定されます。これらの値は任意に変更でき、モデル性能への影響を確認できます。
hyper_params = {
'periods': [i for i in range(5, 300, 30)],
}
この例では、10個の特徴量を作成します。最初の期間は5であり、その後は30ずつ増加し、300未満まで続きます。
>>> [i for i in range(5, 300, 30)] [5, 35, 65, 95, 125, 155, 185, 215, 245, 275]
一方向モデルの学習とテスト
hyper_params = {
'symbol': 'XAUUSD_H1',
'export_path': '/drive_c/Program Files/MetaTrader 5/MQL5/Include/Mean reversion/',
'model_number': 0,
'markup': 0.25,
'stop_loss': 10.0000,
'take_profit': 5.0000,
'direction': 'buy',
'periods': [i for i in range(5, 300, 30)],
'backward': datetime(2020, 1, 1),
'forward': datetime(2024, 1, 1),
'full forward': datetime(2026, 1, 1),
}
models = []
for i in range(10):
print('Learn ' + str(i) + ' model')
models.append(fit_final_models(meta_learner(5, 15, 3, 0.1)))
# models.append(fit_final_models(meta_learners(25, 15, 3, 0.8)))まず、最初のメタラーナーをテストし、2つ目のメタラーナーはコメントアウトします。現在、金価格は上昇トレンドにあるため、取引方向は「買い」を優先的に選択します。学習期間は2020年初頭から2024年までとします。テスト期間は2024年初頭から2025年4月1日までとします。
メタラーナーの設定は以下のとおりです。
- クロスバリデーションは5フォールド
- CatBoostアルゴリズムの学習反復数は15
- 各反復における決定木の深さは3
- 学習率は0.1
以下は、「買い」方向における最良モデルのストラテジーテスター上の結果です。
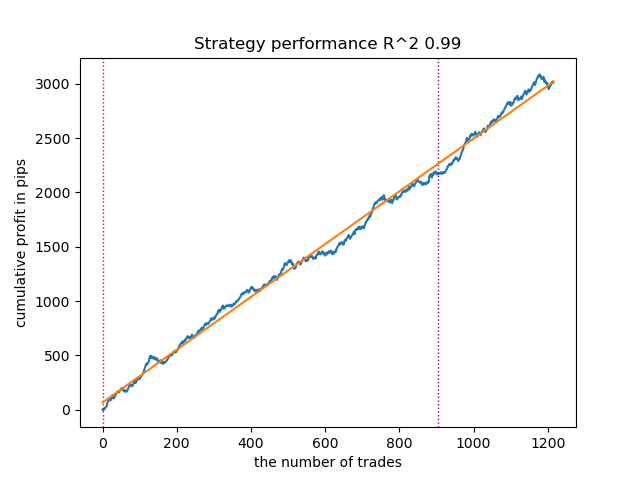
図5:meta_learner()関数の買い方向における特徴量テスト結果
比較のために、「売り」方向における最良モデルの結果を以下に示します。
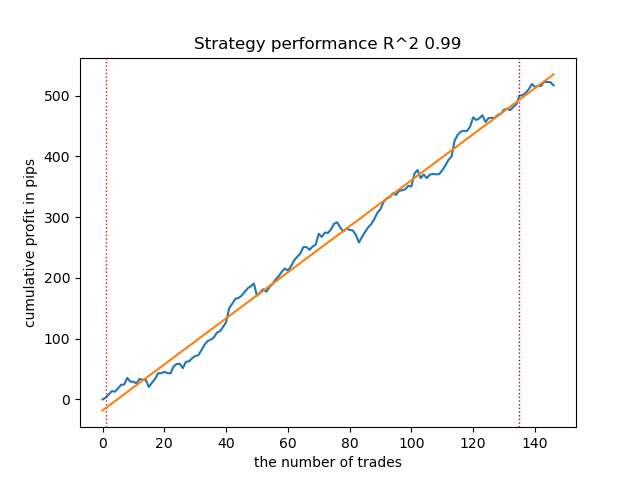
図6:meta_learner()関数の売り方向における特徴量テスト結果
アルゴリズムは、買い方向と売り方向の両方において取引を予測できるようになっています。しかし、売り取引の回数は明らかに少なく、これは上昇トレンド市場では自然な結果です。メタモデルは、ハイパーパラメータの最適化をおこなわなくても十分に効果的に機能しました。このことは、学習期間およびフォワードテスト期間の両方における結果に反映されています。
次に、より高度なメタラーナーについて検討します。meta_learners()関数に対して同様の手順を実行します。これまで使用していた関数をコメントアウトし、こちらを有効化します。
models = [] for i in range(10): print('Learn ' + str(i) + ' model') # models.append(fit_final_models(meta_learner(5, 15, 3, 0.1))) models.append(fit_final_models(meta_learners(25, 15, 3, 0.8)))
メタラーナーの設定は以下のとおりです。
- 25個の「ヘッド」(メタモデル)
- 各モデルに対してCatBoostアルゴリズムの学習反復数は15
- 各反復における決定木の深さは3
- bad_samples_fractionパラメータは0.8で、学習データセットに残される悪いサンプルの割合を決定します。0.1の場合は非常に強いフィルタリングを意味し、0.9の場合は除外される悪いサンプルが少なくなります。
以下は、「買い」方向における最良モデルのストラテジーテスター上の結果です。
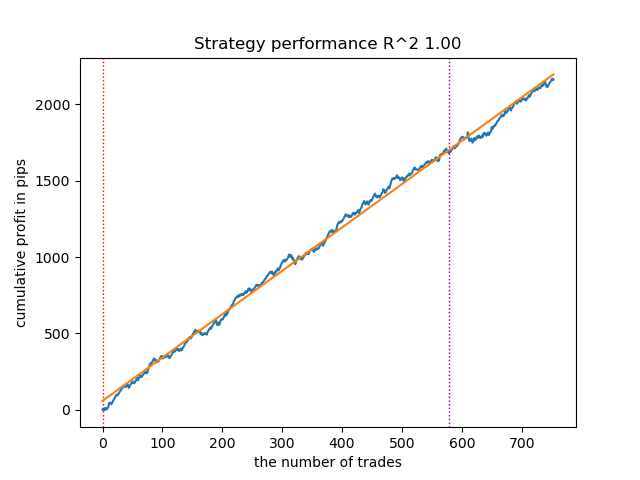
図7:meta_learners()関数の買い方向における特徴量テスト結果
比較のために、「売り」方向における最良モデルの結果を以下に示します。
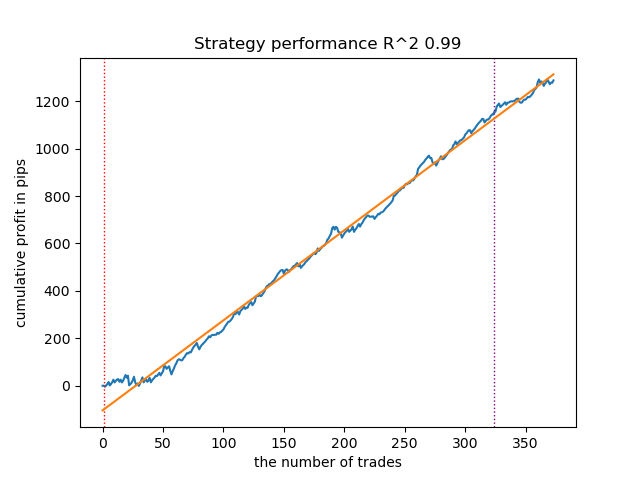
図8:meta_learners()関数の売り方向における特徴量テスト結果
より高度なメタラーナー関数は、より滑らかで安定した収益曲線を示しました。買いと売りの取引バランスは維持されていますが、最も優れた戦略は明らかに買い戦略です。モデルの学習と最良モデルの選択が完了した後、それらをMetaTrader 5ターミナルへエクスポートできます。両方の戦略を使用することも可能ですが、売りポジション戦略は効率が劣るため、買いポジション戦略のみを採用します。
以下に、高度なメタラーナーのパラメータと学習成果の依存関係を示した表を掲載します。
| パラメータ名 | フィルタリング品質への影響 |
|---|---|
| models_number (int) | 「ヘッド」すなわちメタモデルの数が多いほど、悪いサンプルの評価におけるバイアスは小さくなります。 学習データセットの規模は、モデル数の選択に影響します。履歴データが長いほど、より多くのモデルが必要になる場合があります。 このパラメータは5〜100の範囲で変化させながら実験することが推奨されます。 |
| iterations (int) | フィルタリングの度合いに大きく影響します。各メタラーナーの学習反復数が多いほど、フィルタリングは緩やかになります。 値が小さすぎると未学習が発生し、結果としてフィルタリングが強まり、最終的な取引回数が少なくなる可能性があります。 推奨範囲は5〜50です。 |
| depth (int) | 決定木の深さは1〜6の範囲で設定します。各反復において、アルゴリズムは指定された深さの木を構築します。筆者は深さ3を使用していますが、本パラメータについても実験が可能です。 |
| bad_samples_fraction (float) | 悪いサンプルの最終的な選択および取引回数に影響します。0.9は「緩やかな」フィルタリングを意味し、最終的な取引回数は多くなります。0.5は「強い」フィルタリングを意味し、その結果、最終的な取引回数は少なくなります。 |
仕上げ:モデルのエクスポートと取引アドバイザーの作成
モデルのエクスポートは、他の記事で使用している方法とまったく同様におこないます。まず、ソート済みモデル一覧の中から任意のモデルを選択し、エクスポート関数を呼び出します。
models.sort(key=lambda x: x[0]) data = get_features(get_prices()) test_model_one_direction(data, models[-1][1:], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], hyper_params['direction'], plt=True) export_model_to_ONNX(models[-1], 0)
自動売買ボットのロジックも変更されており、エクスポートしたモデルに応じて一方向のみで取引をおこなうようになっています。
input bool direction = true; //True = Buy, False = Sell
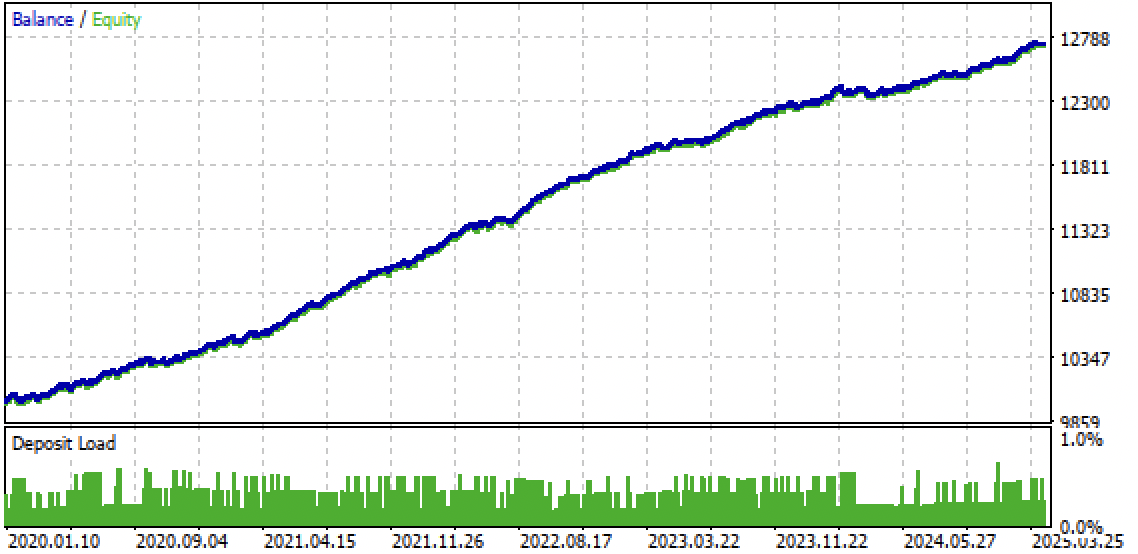
図9:MetaTrader 5ターミナルにおけるボットのテスト結果
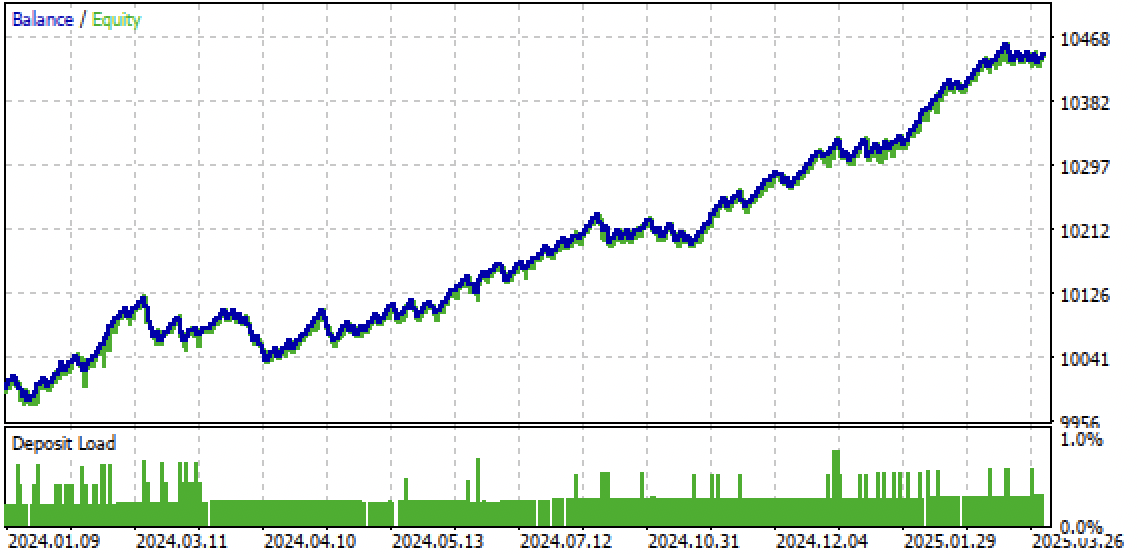
図10:2024年初頭からのフォワード期間のみによるテスト結果
結論
機械学習を用いた一方向戦略のアイデアは非常に興味深いと感じたため、本記事で提案した手法を含め、いくつかの実験を実施しました。この手法は唯一の解決策ではありませんが、課題に対して十分に有効に機能します。このようなトレンド依存型戦略は、トレンドが継続する限り良好なパフォーマンスを示す可能性があります。そのため、グローバルトレンドの変化を継続的に監視し、市場状況に応じてシステムを調整することが重要です。
Python files.zipアーカイブには、以下のPythonでの開発用のファイルが含まれています。
| ファイル名 | 説明 |
|---|---|
| causal one direction.py | 学習モデルのメインスクリプト |
| labeling_lib.py | ラベル付けロジックを更新したモジュール |
| tester_lib.py | 機械学習ベース戦略用に更新されたカスタムテスター |
| XAUUSD_H1.csv | MetaTrader 5ターミナルからエクスポートした価格データファイル |
MQL5 files.zipアーカイブには、MetaTrader 5用のファイルが含まれています。
| ファイル名 | 説明 |
|---|---|
| one direction.ex5 | 記事で作成したボットのコンパイル済みファイル |
| one direction.mq5 | 記事のボットのソースコード |
| Include//Trend following(フォルダ) | ONNXモデルおよびボット接続用ヘッダファイルの配置フォルダ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/17654
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索