Обсуждение статьи "Торговля по алгоритму: ИИ и его путь к золотым вершинам"
После того, как прочел статью, появилась мысль поиграть с самим процессом кластеризации.
Написал такой вариант, который производит кластеризацию в скользящем окне, а не на всем датасете. Это может улучшить разметку кластеров, с учетом временной структуры ВР.
def sliding_window_clustering(dataset, n_clusters: int, window_size=200) -> pd.DataFrame: import numpy as np data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() meta_X = data.loc[:, data.columns.str.contains('meta_feature')] # Сначала создаем глобальные эталонные центроиды global_kmeans = KMeans(n_clusters=n_clusters).fit(meta_X) global_centroids = global_kmeans.cluster_centers_ clusters = np.zeros(len(data)) # Применяем кластеризацию в скользящем окне for i in range(0, len(data) - window_size + 1, window_size): window_data = meta_X.iloc[i:i+window_size] # Обучаем KMeans на текущем окне local_kmeans = KMeans(n_clusters=n_clusters).fit(window_data) local_centroids = local_kmeans.cluster_centers_ # Сопоставляем локальные центроиды с глобальными # для обеспечения согласованности меток кластеров centroid_mapping = {} for local_idx in range(n_clusters): # Находим ближайший глобальный центроид к данному локальному distances = np.linalg.norm(local_centroids[local_idx] - global_centroids, axis=1) global_idx = np.argmin(distances) centroid_mapping[local_idx] = global_idx + 1 # +1 для начала нумерации с 1 # Получаем метки для текущего окна local_labels = local_kmeans.predict(window_data) # Преобразуем локальные метки в согласованные глобальные метки for j in range(window_size): if i+j < len(clusters): # Проверка на выход за границы clusters[i+j] = centroid_mapping[local_labels[j]] data['clusters'] = clusters return data
Эту функцию вставить в код и заменить clustering на sliding_window_clustering.
По ощущениям, улучшает результаты.
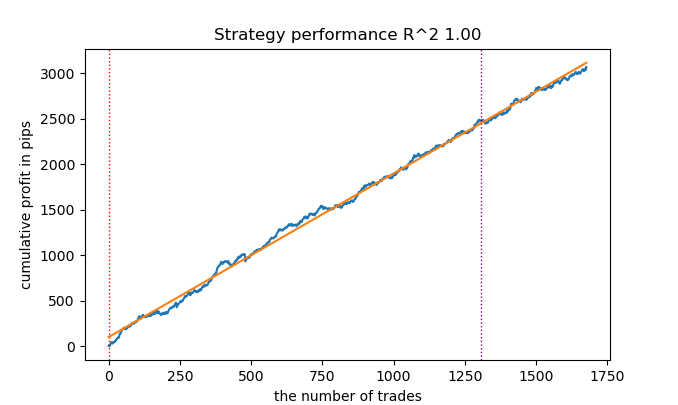
Все-таки иногда полезно писать статьи.
Thanks for the article Dmitrievsky. It looks the uploaded EA and its include file are mismatch with each other. It refer the mpq file in the folder "Trend following", but the sample files were in "Mean reversion".
And the function get_features in the "causal one direction.py" are not same as what appears in the article. Besides that, the mqh file generated by "causal one direction.py" when exporting .onnx is not same as what offered in MQL5_files.zip.
Very appriciate if you can make necessary clarification.
Paul

Thanks for the article Dmitrievsky. It looks the uploaded EA and its include file are mismatch with each other. It refer the mpq file in the folder "Trend following", but the sample files were in "Mean reversion".
And the function get_features in the "causal one direction.py" are not same as what appears in the article. Besides that, the mqh file generated by "causal one direction.py" when exporting .onnx is not same as what offered in MQL5_files.zip.
Very appriciate if you can make necessary clarification.
Paul
Обновил архивы + добавил новый метод кластеризации.
Теперь все пути и функции соответствуют.
Думаю стоит добавить перебор параметров RandomizedSearchCV для модели CatBoost для подбора лучших параметров. Да и кросс-валидация не помешает. Все это улучшает точность модели.
Так у вас же R2 это модифицированный показатель, эффективность которого основывается на профите в пипсах. А как же просадка и другие показатели эффективности? Если мы получим модель которая на обучении выдает более 90% и на тесте не менее 85%, то и ваш показатель выдаст внушительные цифры. Я вот сколько ни гонял тестер на MT5 ни разу не получил профита на истории. Депозит сливается. Это при том, что ваш тестер на питоне выдает 0.97-0.98
Не понял какое отношение это имеет к CV.
Все эти стратегии имеют низкую доказательную способность, потому что основаны только на истории нестационарных котировок. Но можно ловить тренды.- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Опубликована статья Торговля по алгоритму: ИИ и его путь к золотым вершинам:
В данной статье продемонстрирован подход к созданию торговых стратегий для золота с помощью машинного обучения. Рассматривая предложенный подход к анализу и прогнозированию временных рядов с разных ракурсов, можно определить его преимущества и недостатки по сравнению с другими способами создания торговых систем, основанных исключительно на анализе и прогнозировании финансовых временных рядов.
Эволюция понимания возможностей методов машинного обучения в торговле привела к созданию разных алгоритмов, которые одинаково хорошо справляются с одной и той же задачей, но принципиально отличаются. В этой статье снова будет рассмотрена однонаправленная трендовая торговая система на примере золота, но с использованием алгоритма кластеризации.
Рассматривая этот важный подход к анализу и прогнозированию временных рядов с разных ракурсов, можно определить его преимущества и недостатки по сравнению с другими способами создания торговых систем, основанных исключительно на анализе и прогнозировании финансовых временных рядов. В некоторых случаях данные алгоритмы становятся достаточно эффективными и превосходят классические подходы как по скорости создания, так и и по качеству торговых систем на выходе.
В этой статье мы сконцентрируем свое внимание на однонаправленной торговле, когда алгоритм будет открывать сделки только на покупку или продажу. В качестве базовых алгоритмов будут использованы алгоритмы CatBoost и K-Means. CatBoost является базовой моделью, которая выполняет функции бинарного классификатора для классификации сделок. K-Means же используется для определения режимов рынка на этапе препроцессинга.
Автор: Maxim Dmitrievsky