
外国為替データ分析における連関規則の使用

連関規則の概念について
現代のアルゴリズム取引では、新しい分析アプローチが求められています。市場は常に変化し、従来のテクニカル分析だけでは複雑な市場関係の把握が難しくなっています。
私自身、長年データ分析に携わる中で、多くの優れたアイデアは異分野からの応用によって生まれることを実感してきました。今回は、小売分析で実績のある連関規則をFX取引に応用する経験を共有します。この手法は、小売の分野で購買履歴や取引、価格変動と将来の需要・供給との関係を見つけるために広く使われています。では、これを外国為替市場に応用したらどうなるでしょうか。
基本的な考え方はシンプルで、価格の動きやインジケーター、そしてそれらの組み合わせにおける安定したパターンを探すというものです。たとえば、USDJPYの下落の後にどれくらいの頻度でEURUSDの上昇が続くのか、あるいはどのような条件が強い値動きの前に最も頻繁に現れるのか、といったことです。
この記事では、このアイデアに基づいて取引システムを作成するプロセス全体を紹介します。具体的には、以下をおこないます。
- MQL5で履歴データを収集する
- Pythonで分析する
- 有意なパターンを抽出する
- 売買シグナルに変換する
なぜこの組み合わせなのかというと、MQL5は取引所データの処理や取引自動化に非常に適しており、一方でPythonは分析に強力なツールを備えているからです。私の経験から言っても、この組み合わせは取引システムの開発に非常に効果的です。
この記事のコード部分では、特に連関規則をFXに適用する部分に多くの興味深い内容が含まれています。
過去の外国為替データの収集と準備
必要なデータをすべて収集・準備することは非常に重要です。ここでは、主要通貨ペアの過去2年間(2022年以降)のH1データを基礎として使用します。
次に、必要なデータを収集し、CSV形式でエクスポートするMQL5スクリプトを作成します。
//+------------------------------------------------------------------+ //| Dataset.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { string pairs[] = {"EURUSD", "GBPUSD", "USDJPY", "USDCHF"}; datetime startTime = D'2022.01.01 00:00'; datetime endTime = D'2024.01.01 00:00'; for(int i=0; i<ArraySize(pairs); i++) { string filename = pairs[i] + "_H1.csv"; int fileHandle = FileOpen(filename, FILE_WRITE|FILE_CSV); if(fileHandle != INVALID_HANDLE) { // Set headers FileWrite(fileHandle, "DateTime", "Open", "High", "Low", "Close", "Volume"); MqlRates rates[]; ArraySetAsSeries(rates, true); int copied = CopyRates(pairs[i], PERIOD_H1, startTime, endTime, rates); for(int j=copied-1; j>=0; j--) { FileWrite(fileHandle, TimeToString(rates[j].time), DoubleToString(rates[j].open, 5), DoubleToString(rates[j].high, 5), DoubleToString(rates[j].low, 5), DoubleToString(rates[j].close, 5), IntegerToString(rates[j].tick_volume) ); } FileClose(fileHandle); } } } //+------------------------------------------------------------------+
Pythonでのデータ処理
データセットを作成した後は、データを正しく扱うことが重要です。
この目的のために、特別なForexDataProcessorクラスを作成しました。このクラスは、すべての面倒な作業を処理してくれます。その主なコンポーネントを見ていきましょう。
まずはデータの読み込みから始めます。私たちの関数は、主要通貨ペア(EURUSD、GBPUSD、USDJPY、USDCHF)の時間ごとのデータで動作します。データは、主要な価格の特徴を含むCSV形式である必要があります。
import pandas as pd
import numpy as np
from datetime import datetime
import os
import warnings
warnings.filterwarnings('ignore')
class ForexDataProcessor:
def __init__(self):
self.pairs = ["EURUSD", "GBPUSD", "USDJPY", "USDCHF"]
self.data = {}
self.processed_data = {}
def load_data(self):
"""Load data for all currency pairs"""
success = True
for pair in self.pairs:
filename = f"{pair}_H1.csv"
try:
df = pd.read_csv(filename,
encoding='utf-16',
sep='\t',
names=['DateTime', 'Open', 'High', 'Low', 'Close', 'Volume'])
# Remove lines with duplicate headers
df = df[df['DateTime'] != 'DateTime']
# Convert data types
df['DateTime'] = pd.to_datetime(df['DateTime'], format='%Y.%m.%d %H:%M')
for col in ['Open', 'High', 'Low', 'Close']:
df[col] = pd.to_numeric(df[col], errors='coerce')
df['Volume'] = pd.to_numeric(df['Volume'], errors='coerce')
# Remove NaN strings
df = df.dropna()
df.set_index('DateTime', inplace=True)
self.data[pair] = df
print(f"Loaded {pair} data successfully. Shape: {df.shape}")
except Exception as e:
print(f"Error loading {pair} data: {str(e)}")
success = False
return success
def safe_qcut(self, series, q, labels):
"""Safe quantization with error handling"""
try:
if series.nunique() <= q:
# If there are fewer unique values than quantiles, use regular categorization
return pd.qcut(series, q=q, labels=labels, duplicates='drop')
return pd.qcut(series, q=q, labels=labels)
except Exception as e:
print(f"Warning: Error in qcut - {str(e)}. Using manual categorization.")
# Manual categorization as a backup option
percentiles = np.percentile(series, [20, 40, 60, 80])
return pd.cut(series,
bins=[-np.inf] + list(percentiles) + [np.inf],
labels=labels)
def calculate_indicators(self, df):
"""Calculate technical indicators for a single dataframe"""
result = df.copy()
# Basic calculations
result['Returns'] = result['Close'].pct_change()
result['Log_Returns'] = np.log(result['Close']/result['Close'].shift(1))
result['Range'] = result['High'] - result['Low']
result['Range_Pct'] = result['Range'] / result['Open'] * 100
# SMA calculations
for period in [5, 10, 20, 50, 200]:
result[f'SMA_{period}'] = result['Close'].rolling(window=period).mean()
# EMA calculations
for period in [5, 10, 20, 50]:
result[f'EMA_{period}'] = result['Close'].ewm(span=period, adjust=False).mean()
# Volatility
result['Volatility'] = result['Returns'].rolling(window=20).std() * np.sqrt(20)
# RSI
delta = result['Close'].diff()
gain = (delta.where(delta > 0, 0)).rolling(window=14).mean()
loss = (-delta.where(delta < 0, 0)).rolling(window=14).mean()
rs = gain / loss
result['RSI'] = 100 - (100 / (1 + rs))
# MACD
exp1 = result['Close'].ewm(span=12, adjust=False).mean()
exp2 = result['Close'].ewm(span=26, adjust=False).mean()
result['MACD'] = exp1 - exp2
result['MACD_Signal'] = result['MACD'].ewm(span=9, adjust=False).mean()
result['MACD_Hist'] = result['MACD'] - result['MACD_Signal']
# Bollinger Bands
result['BB_Middle'] = result['Close'].rolling(window=20).mean()
result['BB_Upper'] = result['BB_Middle'] + (result['Close'].rolling(window=20).std() * 2)
result['BB_Lower'] = result['BB_Middle'] - (result['Close'].rolling(window=20).std() * 2)
result['BB_Width'] = (result['BB_Upper'] - result['BB_Lower']) / result['BB_Middle']
# Discretization for association rules
# SMA-based trend
result['Trend'] = 'Sideways'
result.loc[result['Close'] > result['SMA_50'], 'Trend'] = 'Uptrend'
result.loc[result['Close'] < result['SMA_50'], 'Trend'] = 'Downtrend'
# RSI zones
result['RSI_Zone'] = pd.cut(result['RSI'].fillna(50),
bins=[-np.inf, 30, 45, 55, 70, np.inf],
labels=['Oversold', 'Weak', 'Neutral', 'Strong', 'Overbought'])
# Secure quantization for other parameters
labels = ['Very_Low', 'Low', 'Medium', 'High', 'Very_High']
result['Volatility_Zone'] = self.safe_qcut(
result['Volatility'].fillna(result['Volatility'].mean()),
5, labels)
result['Price_Zone'] = self.safe_qcut(
result['Close'],
5, labels)
result['Volume_Zone'] = self.safe_qcut(
result['Volume'],
5, labels)
# Candle patterns
result['Body'] = result['Close'] - result['Open']
result['Upper_Shadow'] = result['High'] - result[['Open', 'Close']].max(axis=1)
result['Lower_Shadow'] = result[['Open', 'Close']].min(axis=1) - result['Low']
result['Body_Pct'] = result['Body'] / result['Open'] * 100
body_mean = abs(result['Body_Pct']).mean()
result['Candle_Pattern'] = 'Normal'
result.loc[abs(result['Body_Pct']) < body_mean * 0.1, 'Candle_Pattern'] = 'Doji'
result.loc[result['Body_Pct'] > body_mean * 2, 'Candle_Pattern'] = 'Long_Bullish'
result.loc[result['Body_Pct'] < -body_mean * 2, 'Candle_Pattern'] = 'Long_Bearish'
return result
def process_all_pairs(self):
"""Process all currency pairs and create combined dataset"""
if not self.load_data():
return None
# Handling each pair
for pair in self.pairs:
if not self.data[pair].empty:
print(f"Processing {pair}...")
self.processed_data[pair] = self.calculate_indicators(self.data[pair])
# Add a pair prefix to the column names
self.processed_data[pair].columns = [f"{pair}_{col}" for col in self.processed_data[pair].columns]
else:
print(f"Skipping {pair} - no data")
# Find the common time range for non-empty data
common_dates = None
for pair in self.pairs:
if pair in self.processed_data and not self.processed_data[pair].empty:
if common_dates is None:
common_dates = set(self.processed_data[pair].index)
else:
common_dates &= set(self.processed_data[pair].index)
if not common_dates:
print("No common dates found")
return None
# Align all pairs by common dates
aligned_data = {}
for pair in self.pairs:
if pair in self.processed_data and not self.processed_data[pair].empty:
aligned_data[pair] = self.processed_data[pair].loc[sorted(common_dates)]
# Combine all pairs
combined_df = pd.concat([aligned_data[pair] for pair in aligned_data], axis=1)
return combined_df
def save_data(self, data, suffix='combined'):
"""Save processed data to CSV"""
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
filename = f"forex_data_{suffix}_{timestamp}.csv"
try:
data.to_csv(filename, sep='\t', encoding='utf-16')
print(f"Saved processed data to: {filename}")
return True
except Exception as e:
print(f"Error saving data: {str(e)}")
return False
if __name__ == "__main__":
processor = ForexDataProcessor()
# Handling all pairs
combined_data = processor.process_all_pairs()
if combined_data is not None:
# Save the combined dataset
processor.save_data(combined_data)
# Display dataset info
print("\nCombined dataset shape:", combined_data.shape)
print("\nFeatures for association rules analysis:")
for col in combined_data.columns:
if any(x in col for x in ['_Zone', '_Pattern', 'Trend']):
print(f"- {col}")
# Save individual pairs
for pair in processor.pairs:
if pair in processor.processed_data and not processor.processed_data[pair].empty:
processor.save_data(processor.processed_data[pair], pair)
データの読み込みが成功した後、最も興味深い部分が始まります。テクニカル指標の計算です。ここでは、長年の実績あるさまざまなツールに頼ります。移動平均線は、異なる期間のトレンドを把握するのに役立ちます。SMA(50)はしばしば動的なサポートやレジスタンスとして機能します。一般的な期間14のRSIオシレーターは、買われすぎ・売られすぎの相場ゾーンを判定するのに適しています。MACDはモメンタムや反転ポイントの特定に欠かせません。ボリンジャーバンドは、現在の市場のボラティリティを明確に示してくれます。
# Volatility and RSI calculation example result['Volatility'] = result['Returns'].rolling(window=20).std() * np.sqrt(20) delta = result['Close'].diff() gain = (delta.where(delta > 0, 0)).rolling(window=14).mean() loss = (-delta.where(delta < 0, 0)).rolling(window=14).mean() rs = gain / loss result['RSI'] = 100 - (100 / (1 + rs))
データの離散化には特別な注意が必要です。すべての連続値は、明確なカテゴリに分ける必要があります。この際、黄金の中庸を見つけることが重要です。分割が急すぎるとパターンの探索が複雑になり、逆に細かすぎると重要な市場のニュアンスが失われてしまいます。たとえば、トレンドを判定する場合は、より単純な分割のほうが適しています。つまり、価格の平均値に対する位置で分ける方法です。
# Defining a trend result['Trend'] = 'Sideways' result.loc[result['Close'] > result['SMA_50'], 'Trend'] = 'Uptrend' result.loc[result['Close'] < result['SMA_50'], 'Trend'] = 'Downtrend'
ローソク足パターンも特別なアプローチが必要です。統計分析に基づき、ローソク足の実体が非常に小さい場合はDojiを、極端な値動きの場合はLong_BullishやLong_Bearishを識別します。この分類により、市場の迷いの局面や強い衝撃的な値動きを明確に捉えることができます。
処理の最後に、すべての通貨ペアを共通の時間軸で単一のデータ配列に統合します。このステップは非常に重要で、異なる金融商品間の複雑な関係を探索する可能性が開かれます。これにより、ある通貨ペアのトレンドが他の通貨ペアのボラティリティにどのような影響を与えるか、あるいはローソク足パターンが市場全体の取引量とどのように関連しているかを確認できるようになります。
PythonによるAprioriアルゴリズムの実装
データの準備が整ったら、次の重要なステージ、つまり、Aprioriアルゴリズムの実装に進みます。このアルゴリズムを用いて、金融データにおける連関規則を発見します。もともとはマーケットバスケット分析のために開発されたAprioriアルゴリズムを、通貨ペアの時系列データに対応させて適用します。
外国為替市場の文脈では、「トランザクション」とは、ある時点における様々な指標や通貨ペアの状態の集合を意味します。以下はその例です。- EURUSD_Trend = Uptrend
- GBPUSD_RSI_Zone = Overbought
- USDJPY_Volatility_Zone = High
アルゴリズムは、このような状態の頻出組み合わせを検索し、そこから取引ルールを形成します。
import pandas as pd import numpy as np from collections import defaultdict from itertools import combinations import time import logging # Setting up logging logging.basicConfig( level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s', handlers=[ logging.FileHandler('apriori_forex_advanced.log'), logging.StreamHandler() ] ) class AdvancedForexApriori: def __init__(self, min_support=0.01, min_confidence=0.7, max_length=3): self.min_support = min_support self.min_confidence = min_confidence self.max_length = max_length def find_patterns(self, df): start_time = time.time() logging.info("Starting advanced pattern search...") # Group columns by type for more meaningful analysis column_groups = { 'trend': [col for col in df.columns if 'Trend' in col], 'rsi': [col for col in df.columns if 'RSI_Zone' in col], 'volume': [col for col in df.columns if 'Volume_Zone' in col], 'price': [col for col in df.columns if 'Price_Zone' in col], 'pattern': [col for col in df.columns if 'Pattern' in col] } # Create a list of all columns for analysis pattern_cols = [] for cols in column_groups.values(): pattern_cols.extend(cols) logging.info(f"Found {len(pattern_cols)} pattern columns in {len(column_groups)} groups") # Prepare data pattern_df = df[pattern_cols] n_rows = len(pattern_df) # Find single patterns logging.info("Finding single patterns...") single_patterns = {} for col in pattern_cols: value_counts = pattern_df[col].value_counts() value_counts = value_counts[value_counts/n_rows >= self.min_support] for value, count in value_counts.items(): pattern = f"{col}={value}" single_patterns[pattern] = count/n_rows # Find pair and triple patterns logging.info("Finding complex patterns...") complex_rules = [] # Generate column combinations for analysis column_combinations = [] for i in range(2, self.max_length + 1): column_combinations.extend(combinations(pattern_cols, i)) total_combinations = len(column_combinations) for idx, cols in enumerate(column_combinations, 1): if idx % 10 == 0: logging.info(f"Processing combination {idx}/{total_combinations}") # Create a cross-table for the selected columns grouped = pattern_df.groupby([*cols]).size().reset_index(name='count') grouped['support'] = grouped['count'] / n_rows # Sort by minimum support grouped = grouped[grouped['support'] >= self.min_support] for _, row in grouped.iterrows(): # Form all possible combinations of antecedents and consequents items = [f"{col}={row[col]}" for col in cols] for i in range(1, len(items)): for antecedent in combinations(items, i): consequent = tuple(set(items) - set(antecedent)) # Calculate the support of the antecedent ant_support = self._calculate_support(pattern_df, antecedent) if ant_support > 0: # Avoid division by zero confidence = row['support'] / ant_support if confidence >= self.min_confidence: # Count the lift cons_support = self._calculate_support(pattern_df, consequent) lift = confidence / cons_support if cons_support > 0 else 0 # Adding additional metrics to evaluate rules leverage = row['support'] - (ant_support * cons_support) conviction = (1 - cons_support) / (1 - confidence) if confidence < 1 else float('inf') rule = { 'antecedent': antecedent, 'consequent': consequent, 'support': row['support'], 'confidence': confidence, 'lift': lift, 'leverage': leverage, 'conviction': conviction } # Sort the rules by additional criteria if self._is_meaningful_rule(rule): complex_rules.append(rule) # Sort the rules by complex metric complex_rules.sort(key=self._rule_score, reverse=True) end_time = time.time() logging.info(f"Pattern search completed in {end_time - start_time:.2f} seconds") logging.info(f"Found {len(complex_rules)} meaningful rules") return complex_rules def _calculate_support(self, df, items): """Calculate support for a set of elements""" mask = pd.Series(True, index=df.index) for item in items: col, val = item.split('=') mask &= (df[col] == val) return mask.mean() def _is_meaningful_rule(self, rule): """Check the rule for its relevance to trading""" # The rule should have the high lift and 'leverage' if rule['lift'] < 1.5 or rule['leverage'] < 0.01: return False # At least one element should be related to a trend or RSI has_trend_or_rsi = any('Trend' in item or 'RSI' in item for item in rule['antecedent'] + rule['consequent']) if not has_trend_or_rsi: return False return True def _rule_score(self, rule): """Calculate the rule complex evaluation""" return (rule['lift'] * 0.4 + rule['confidence'] * 0.3 + rule['support'] * 0.2 + rule['leverage'] * 0.1) # Load data logging.info("Loading data...") data = pd.read_csv('forex_data_combined_20241116_074242.csv', sep='\t', encoding='utf-16', index_col='DateTime') logging.info(f"Data loaded, shape: {data.shape}") # Apply the algorithm apriori = AdvancedForexApriori(min_support=0.01, min_confidence=0.7, max_length=3) rules = apriori.find_patterns(data) # Display results logging.info("\nTop 10 trading rules:") for i, rule in enumerate(rules[:10], 1): logging.info(f"\nRule {i}:") logging.info(f"IF {' AND '.join(rule['antecedent'])}") logging.info(f"THEN {' AND '.join(rule['consequent'])}") logging.info(f"Support: {rule['support']:.3f}") logging.info(f"Confidence: {rule['confidence']:.3f}") logging.info(f"Lift: {rule['lift']:.3f}") logging.info(f"Leverage: {rule['leverage']:.3f}") logging.info(f"Conviction: {rule['conviction']:.3f}") # Save results results_df = pd.DataFrame(rules) results_df.to_csv('forex_rules_advanced.csv', index=False, sep='\t', encoding='utf-16') logging.info("Results saved to forex_rules_advanced.csv")
通貨ペア分析のための連関規則の適応
外国為替市場向けにAprioriアルゴリズムを適応させる過程で、私は興味深い課題に直面しました。この手法はもともと店内での購買分析のために作られたものですが、Forexに応用する可能性は非常に高いと感じました。
最大の難点は、FX市場が一般的な店舗での買い物とは根本的に異なることです。金融市場で長年働く中で、絶えず変化する価格や指標に対応することには慣れています。しかし、普段はスーパーのレシート上で「バナナと牛乳の関連」を探すアルゴリズムを、どうやって為替市場に応用するのでしょうか。
私の試行の結果、5つの指標からなるシステムが誕生しました。それぞれを徹底的にテストしました。
「Support」は非常に扱いが難しい指標でした。一度、パフォーマンスは抜群なのにサポートが0.02のルールを取引システムに組み込みそうになったことがあります。幸い気づいたおかげで助かりました。実際には、このルールは百年に一度しか発動しないようなものでした。
「Confidence」は比較的シンプルでした。市場で取引していると、70%の確率でも優れた指標であることがすぐにわかります。重要なのは、残りの30%のリスクを賢く管理することです。リスク管理を無視すると、いくら聖杯を手にしていてもドローダウンや資金の枯渇に直面します。
「Lift」は私のお気に入りの指標になりました。数百時間のテストを経て、Liftが1.5以上のルールは実際の市場でも機能するというパターンに気づきました。この発見は、シグナルの選別方法に大きな影響を与えました。
「Leverage」は最初は面白い扱いでした。最初は役に立たないと考え、システムから完全に除外しようとしました。しかし、市場が特にボラタイルな期間には、ほとんどの誤シグナルをふるい落とすのに役立ちました。
「Conviction」は最後にフォーラム調査を経て追加しました。発見されたパターンの実際の重要性を評価する上で、この指標の重要性が理解できました。
最も驚いたのは、アルゴリズムが異なる通貨ペア間で予想外の関連性を見つけることです。たとえば、EURUSDの特定のパターンがUSDJPYの動きを非常に正確に予測することがあるとは誰が想像したでしょうか。市場での9年間の経験でも、アルゴリズムが発見した多くの関係性には気づきませんでした。かつてペアトレード、バスケットトレード、アービトラージは私の得意分野でしたが、cmillionがペアの相互の動きに基づくロボットを開発し始めた頃のことを今でも覚えています。
現在も研究を続けており、新しい指標や時間枠の組み合わせをテストしています。市場は常に変化しており、毎日新たな発見があります。来週は、年間データでのシステムテストの結果と、アルゴリズムを用いたライブデモ取引の最初の結果を公開する予定です。非常に興味深い発見がいくつもあります。
正直に言うと、このプロジェクトがここまで進むとは思っていませんでした。すべてはデータマイニングの簡単な実験と、市場の動きを分類アルゴリズム向けに厳密に分類しようとする試みとして始まり、最終的には本格的な取引システムへと発展しました。このアプローチの真の可能性を、ようやく理解し始めたところです。
外国為替における実装の特徴
少しコード自体に戻りましょう。私たちのコードには、金融データを扱うためのアルゴリズムのいくつかの重要な適応があります。
column_groups = {
'trend': [col for col in df.columns if 'Trend' in col],
'rsi': [col for col in df.columns if 'RSI_Zone' in col],
'volume': [col for col in df.columns if 'Volume_Zone' in col],
'price': [col for col in df.columns if 'Price_Zone' in col],
'pattern': [col for col in df.columns if 'Pattern' in col]
}
このグループ化により、より意味のある指標の組み合わせを見つけることができ、計算の複雑さが軽減されます。
def _is_meaningful_rule(self, rule): if rule['lift'] < 1.5 or rule['leverage'] < 0.01: return False has_trend_or_rsi = any('Trend' in item or 'RSI' in item for item in rule['antecedent'] + rule['consequent']) if not has_trend_or_rsi: return False return True
統計的有意性が高く(Lift > 1.5)、かつ、トレンド指標またはRSIのいずれかが必ず含まれるルールのみを選択します。
def _rule_score(self, rule): return (rule['lift'] * 0.4 + rule['confidence'] * 0.3 + rule['support'] * 0.2 + rule['leverage'] * 0.1)
加重スコアは、ルールの取引における潜在的有用性に基づいてランク付けするのに役立ちます。
発見された連関の可視化
連関規則を見つけた後は、正しく可視化・分析する必要があります。この目的のために、特別なForexRulesVisualizerクラスを開発しました。このクラスは、発見されたパターンを視覚的に分析するためのいくつかの方法を提供します。
ルール指標の分布
分析の最初のステップは、発見されたルールの主要指標の分布を理解することです。Support、Confidence、Lift、Leverageの分布グラフは、発見されたルールの品質を評価し、必要に応じてアルゴリズムのパラメータを調整するのに役立ちます。
特に有用だったのは、インタラクティブなネットワークグラフです。これにより、異なる市場状況間のつながりを明確に確認できます。このグラフでは、ノードが指標の状態(例:「EURUSD_Trend=Uptrend」や「USDJPY_RSI_Zone=Overbought」)を表し、エッジが発見されたルールを示します。エッジの太さはLift値に比例しています。
通貨ペアの相互作用のヒートマップ 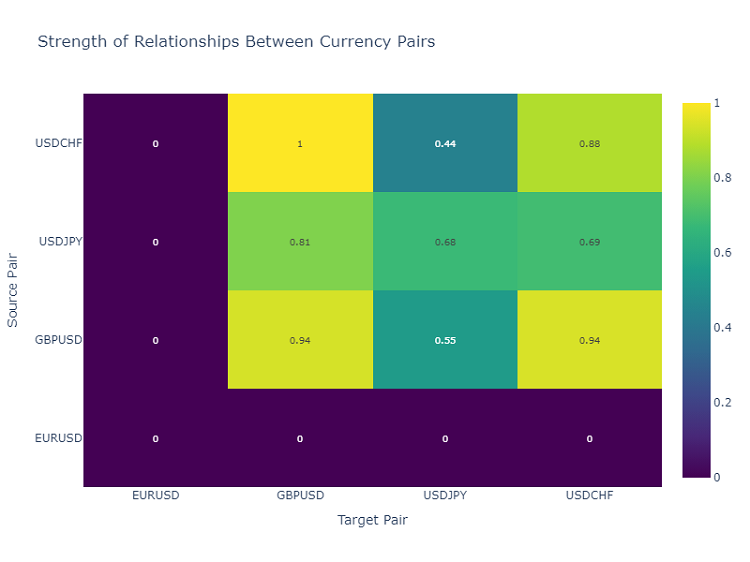
通貨ペア間の関係を分析するために、ヒートマップを使用します。ヒートマップは、異なる金融商品の関係の強さを示し、どのペアが互いに最も影響を与えやすいかを特定するのに役立ちます。これは、多様な取引ポートフォリオを構築する上で非常に重要です。
取引シグナルの作成
連関規則を発見し可視化した後の次の重要なステップは、それらを取引シグナルに変換することです。この目的のために、ForexSignalGeneratorクラスを開発しました。このクラスは市場の現在の状態を分析し、発見されたルールに基づいて取引シグナルを生成します。
import pandas as pd import numpy as np from datetime import datetime import logging class ForexSignalGenerator: def __init__(self, rules_df, min_rule_strength=0.5): """ Signal generator initialization Parameters: rules_df: DataFrame with association rules min_rule_strength: minimum rule strength to generate a signal """ self.rules_df = rules_df self.min_rule_strength = min_rule_strength self.active_signals = {} def calculate_rule_strength(self, rule): """ Comprehensive assessment of the rule strength Takes into account all metrics with different weights """ strength = ( rule['lift'] * 0.4 + # Main weight on 'lift' rule['confidence'] * 0.3 + # Rule confidence rule['support'] * 0.2 + # Occurrence frequency rule['leverage'] * 0.1 # Improvement over randomness ) # Additional bonus for having trend indicators if any('Trend' in item for item in rule['antecedent']): strength *= 1.2 return strength def analyze_market_state(self, current_data): """ Current market state analysis Parameters: current_data: DataFrame with current indicator values """ signals = [] state = self._create_market_state(current_data) # Find all the matching rules matching_rules = self._find_matching_rules(state) # Grouping rules by currency pairs for pair in ['EURUSD', 'GBPUSD', 'USDJPY', 'USDCHF']: pair_rules = [r for r in matching_rules if any(pair in c for c in r['consequent'])] if pair_rules: signal = self._generate_pair_signal(pair, pair_rules) signals.append(signal) return signals def _create_market_state(self, data): """Forming the current market state""" state = [] for col in data.columns: if any(x in col for x in ['_Zone', '_Pattern', 'Trend']): state.append(f"{col}={data[col].iloc[-1]}") return set(state) def _find_matching_rules(self, state): """Searching for rules that match the current state""" matching_rules = [] for _, rule in self.rules_df.iterrows(): # Check if all the rule conditions are met if all(cond in state for cond in rule['antecedent']): strength = self.calculate_rule_strength(rule) if strength >= self.min_rule_strength: rule['calculated_strength'] = strength matching_rules.append(rule) return matching_rules def _generate_pair_signal(self, pair, rules): """Generating a signal for a specific currency pair""" # Divide the rules by signal type trend_signals = defaultdict(float) for rule in rules: # Looking for trend-related consequents trend_cons = [c for c in rule['consequent'] if pair in c and 'Trend' in c] if trend_cons: for cons in trend_cons: trend = cons.split('=')[1] trend_signals[trend] += rule['calculated_strength'] # Determine the final signal if trend_signals: strongest_trend = max(trend_signals.items(), key=lambda x: x[1]) return { 'pair': pair, 'signal': strongest_trend[0], 'strength': strongest_trend[1], 'timestamp': datetime.now() } return None # Usage example def run_trading_system(data, rules_df): """ Trading system launch Parameters: data: DataFrame with historical data rules_df: DataFrame with association rules """ signal_generator = ForexSignalGenerator(rules_df) # Simulate a pass along historical data signals_history = [] for i in range(len(data) - 1): current_slice = data.iloc[i:i+1] signals = signal_generator.analyze_market_state(current_slice) for signal in signals: if signal: signals_history.append({ 'datetime': current_slice.index[0], 'pair': signal['pair'], 'signal': signal['signal'], 'strength': signal['strength'] }) return pd.DataFrame(signals_history) # Loading historical data and rules data = pd.read_csv('forex_data_combined_20241116_090857.csv', sep='\t', encoding='utf-16', index_col='DateTime', parse_dates=True) rules_df = pd.read_csv('forex_rules_advanced.csv', sep='\t', encoding='utf-16') rules_df['antecedent'] = rules_df['antecedent'].apply(eval) rules_df['consequent'] = rules_df['consequent'].apply(eval) # Launch the test signals_df = run_trading_system(data, rules_df) # Analyze the results print("Generated signals statistics:") print(signals_df.groupby('pair')['signal'].value_counts())
ルールの強さの評価
ルールの可視化に長い時間を費やした後、次はいよいよ最も難しい部分、つまり実際の取引シグナルの作成です。正直に言うと、この作業にはかなり汗をかきました。チャート上で美しいパターンを見つけるのと、それを実際に機能するトレーディングシステムに変えるのとでは、全く別物です。
別モジュールとしてForexSignalGeneratorを作ることにしました。当初は、最も強いルールに従ってシグナルを生成するだけで十分だと思っていましたが、すぐにそれでは不十分だと気づきました。市場は常に変化しており、昨日うまく機能したルールが今日も通用するとは限りません。
そこで、ルールの強さを評価するために真剣なアプローチを取る必要がありました。いくつかの失敗実験の後、評価のためのスケールシステムを開発しました。比率の設定には最も苦労し、おそらく数十通りの組み合わせを試しました。最終的に、最終評価の40%をLiftに割り当て(これは非常に重要な指標です)、Confidenceを30%、sapportを20%、Leverageを10%にすることにしました。
興味深いことに、最も強いシグナルは、ルールにトレンド成分が含まれている場合に多く見られました。そのため、そうしたルールには特別に強さ評価に20%のボーナスを加えました。実践でもこれが正当であることが示されています。
また、現在の市場状態の分析にも工夫が必要でした。当初は単純に指標の現在値とルール条件を比較していましたが、より広い文脈を考慮する必要があることに気づきました。たとえば、過去数期間の全体トレンド、ボラティリティの状況、さらには時間帯までも検証に加えました。
現在のシステムでは、各通貨ペアに対して約20種類のパラメータを分析しています。見つけたパターンの中には、本当に驚かされるものもありました。
もちろん、システムはまだ完璧ではありません。時々、ファンダメンタル要因も加えるべきだと考えることもあります。しかし、それは後回しにしています。まずは現在のバージョンを完成させることが優先です。
シグナルの分類と集約
システム開発の過程で、単にルールを見つけるだけでは不十分であり、シグナルの品質を厳密に管理する必要があることにすぐ気付きました。いくつかの不成功な取引を経験した後、パターンを見つけることそのものよりも、取捨選択の方が重要かもしれないと実感しました。
最初は、ルール強度の最小閾値を設けるという単純な方法から始めました。当初は0.5に設定しましたが、依然として誤ったシグナルが多発しました。2週間のテスト後、これを0.7に引き上げたところ、状況は明らかに改善しました。シグナル数は約3分の1減少しましたが、その質は大幅に向上しました。
2段階目の取捨選択は、特に悔しい出来事をきっかけに導入しました。あるルールは非常に優れた成績を示していたので、それに従ってポジションを取ったのですが、市場は真逆に動きました。調べてみると、その時点で他のルールは反対方向のシグナルを出していたことが判明しました。それ以来、複数のルールが同じ方向を示している場合にのみポジションを取るよう、一貫性のチェックをおこなうようにしました。
ボラティリティへの対処も興味深い課題でした。落ち着いた相場ではシステムは非常に安定して機能しますが、市場が活発になると問題が発生しやすくなります。そこで、ATRによる動的フィルターを追加しました。直近20日間のボラティリティが75パーセンタイルを超える場合、ルール強度の基準値を20%引き上げるようにしました。
最も難しかったのは、相反するシグナルの確認です。買いシグナルを出すルールもあれば、売りシグナルを出すルールもあり、どちらも優れたパラメータを持つ場合があります。さまざまな方法を試した結果、最終的には単純な解決策に落ち着きました。つまり、重大な矛盾がある場合は、その場面はスキップするという方法です。これにより一部のチャンスは逃しますが、リスクを大幅に減らすことができます。
来月は、時間帯による取捨選択を追加する予定です。特定の時間帯ではルールの成績が明らかに悪化することに気付きました。特に流動性が低い時間帯や重要なニュースが発表される時間帯です。これを導入すれば、成功トレードの割合がさらに向上すると考えています。
テスト結果
数か月にわたってシステムを開発した後、私はある重要な疑問に直面しました──発見された各ルールの強さを正しく評価するにはどうすればよいのか。理論上は簡単に見えましたが、実際の市場は初期アプローチの弱点をすぐに露呈させました。
長期間の実験の結果、私は複数の要因に重み付けをおこなう方式にたどり着きました。メインの構成要素にはLiftを採用し、その影響度は40%としました。実際の運用から、これが極めて重要な指標であることが分かったからです。Confidenceは30%──やはりルールの信頼度は大きな意味を持ちます。SupportとLeverageには小さめの重みを割り当て、フィルター的な役割を担わせました。
シグナルの取捨選択は、また別の課題でした。最初はすべてのルールに従って順番に取引してみましたが、それが誤りであることにすぐ気付きました。そこで、複数段階の取捨選択システムを導入することになりました。まず、最低強度の閾値で弱いルールをふるい落とします。次に、複数のルールによって確認されたシグナルかをチェックします。単独のシグナルは信頼性が低い傾向があります。
ボラティリティの考慮は特に重要であることがわかりました。落ち着いた相場ではシステムは完璧に機能しましたが、ボラティリティが急上昇すると、誤シグナルの数が急増しました。そのため、ボラティリティが高くなるほど基準が厳しくなる動的フィルターを追加しました。
システムのテストにはほぼ3か月を要しました。4つの主要通貨ペアについて2年間の履歴データで運用を試みました。結果はかなり意外なものでした。たとえば、USDJPYは最も良好な成績を示し、勝率65%でRR(リスクリワード比)は1.6。しかし、GBPUSDは期待外れで、勝率は58%、RRは1.4にとどまりました。
興味深いことに、Liftが2.0以上かつConfidenceが0.8以上のルールは、すべてのペアで一貫して最良の結果を示しました。どうやら、これらの水準はFX市場における一種の自然な有意性の閾値のようです。
さらなる改善
現在、システム改善の方向性としていくつかの点が見えています。第一に、ルールのパラメータをより動的にする必要があります──市場は変化し続けており、システムもそれに適応しなければなりません。第二に、マクロ経済やニュース背景の考慮が明らかに不足しています。確かにシステムは複雑になりますが、その潜在的な利益は十分に価値があります。
特に興味深いのは、適応型フィルターの適用です。市場のフェーズが異なれば、明らかに必要とされるシステム設定も異なります。現状ではまだ粗削りな実装ですが、すでにいくつかの改善案が見えています。
来週からは、ポジションサイズの動的最適化を組み込んだ新バージョンのテストを開始する予定です。過去データでの事前結果は有望ですが、実際の市場はいつものように独自の修正を加えてくることでしょう。
結論
アルゴリズム取引におけるアソシエーションルールの活用は、目に見えにくい市場パターンを発見する上で興味深い可能性を開きます。ここでの成功の鍵は、適切なデータ準備、慎重なルール選定、そして十分に考え抜かれたシグナル生成システムにあります。
また、どのような取引システムであっても、市場環境の変化に応じた継続的な監視と適応が必要であることを忘れてはなりません。アソシエーションルールは強力な分析ツールですが、他のテクニカル分析やファンダメンタル分析と組み合わせて活用することが重要です。
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/16061
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
どうやら、読者はすでにそのような方法についてある程度の知識を持っていることが前提となっているようだ。
特に言及されている指標については理解できない:
リフトは私のお気に入りの指標となった。何百時間もテストした後、私はあるパターンに気づきました - 1.5以上のリフトを持つルールは、実際の市場で本当に機能します。この発見は、私のシグナルフィルタリングへの アプローチに大きな影響を与えました。
私がこの方法を正しく理解していれば、相関するシグナルは量子セグメントで検索されます。しかし、私は次のステップを理解していなかった。ターゲットとなるものは何か?私は、得られたルールがターゲットと照合され、メトリクスと照合されて評価されると考えている。
もしそうなら、私の方法と同じで、パフォーマンスと効率を評価するのは興味深い。