
取引におけるニューラルネットワーク:制御されたセグメンテーション

はじめに
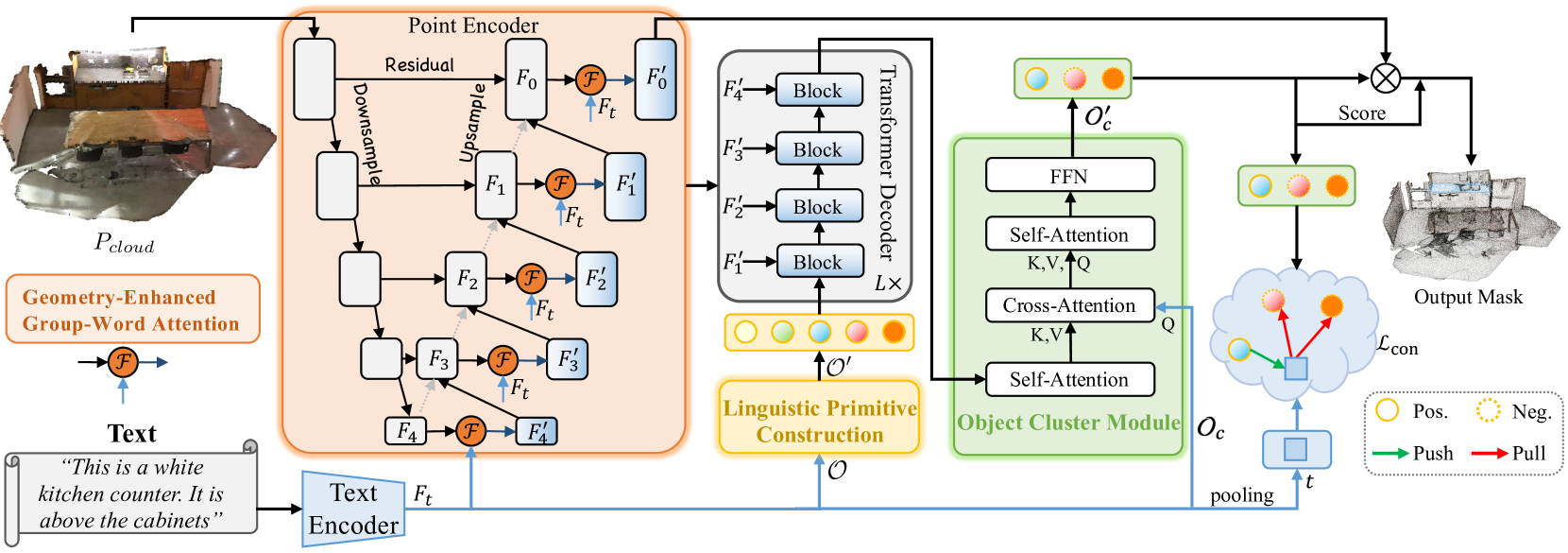
ガイド付きセグメンテーションのタスクでは、点群内の特定領域を、ターゲットオブジェクトの自然言語による説明に基づいて抽出する必要があります。このタスクを解決するために、モデルは複雑で細かい意味的依存関係を詳細に分析し、ターゲットオブジェクトに対する点単位のマスクを生成します。論文「RefMask3D:Language-Guided Transformer for 3D Referring Segmentation」では、言語情報を広範に活用する効率的かつ包括的なフレームワークを提案しています。提案されたRefMask3D手法は、マルチモーダルな相互作用と理解能力を強化するものです。
著者らは、豊富なマルチモーダル文脈を抽出するために、早期段階での特徴量エンコーディングを採用しています。これを実現するために、Geometry-Enhanced Group-Word Attention(幾何拡張グループワードアテンション)モジュールを導入し、自然言語によるターゲットオブジェクトの説明と、局所的な点群グループ(サブクラウド)との間でクロスモーダルアテンションをおこないます。この統合により、点群特有の疎で不規則な性質に起因する、直接的な点と言葉の相関によるノイズが軽減されるだけでなく、点群内の本質的な幾何学的関係や細かい構造的特徴量を活用することができます。これにより、言語情報と幾何情報の両方に対するモデルの対応力が大きく向上します。
さらに、著者らは学習可能な「背景」トークンを導入し、無関係な言語特徴量が局所グループの特徴量と混在しないようにしています。この仕組みによって、点レベルの表現は、関連する意味的言語情報によって強化され、点群内の各グループやオブジェクトに対して、適切な言語コンテキストに基づいた連続的かつ文脈を認識した整合性を維持します。
コンピュータビジョンと自然言語処理の特徴を統合することで、著者らはLinguistic Primitives Construction(LPC、言語プリミティブ構築)と呼ばれる効果的なターゲットオブジェクト識別戦略をデコーダに導入しました。この戦略では、形状、色、サイズ、関係、位置などの特定の意味属性を表すために、多様なプリミティブを初期化します。これらのプリミティブは関連する言語情報と相互作用することで、対応する属性を獲得します。
この意味的に強化されたプリミティブをデコーダ内で活用することにより、モデルは点群の多様な意味をより正確に把握できるようになり、ターゲットオブジェクトの局在化および識別性能が大幅に向上します。
さらに、全体的な情報を収集し、ターゲットオブジェクトの埋め込み表現を生成するために、RefMask3DフレームワークはObject Cluster Module (OCM)を導入しています。言語プリミティブは、それぞれの意味属性と相関する点群の特定部分を強調するために使用されます。しかし、最終的な目的は、与えられた記述に基づいてターゲットオブジェクトを正確に識別することです。この目的を達成するためには、言語の意味内容を包括的に理解する必要があります。これを実現するのがObject Cluster Module (OCM)です。このモジュールでは、まず言語プリミティブ間の関係を分析し、共通する特徴や中核領域における違いを特定します。この情報をもとに、自然言語に基づくクエリを生成し、これらの共通特徴を捉え、最終的なターゲットオブジェクト識別に不可欠な埋め込み表現を形成します。
このObject Cluster Moduleは、モデルが言語情報と視覚情報の両方をより深く、より包括的に理解するための重要な役割を果たしています。
1. RefMask3Dアルゴリズム
RefMask3Dは、初期の点群シーンと対象の属性に関するテキスト記述を解析することで、ターゲットオブジェクトの点単位のマスクを生成します。解析対象のシーンはN個の点から構成され、それぞれの点には3次元座標データPと、色や形状、その他の属性を記述する補助的な特徴ベクトルFが含まれています。
まず、テキストエンコーダがテキスト記述から埋め込み表現Ftを生成します。次に、ポイントエンコーダによって点単位の特徴量が抽出され、Geometry-Enhanced Group-Word Attention(幾何拡張グループワードアテンション)モジュールを通じて、観測された幾何形状とテキスト入力の間に深い相互作用が構築されます。ポイントエンコーダは、3D U-Netに類似したバックボーン構造として機能します。
Linguistic Primitives Constructor(言語プリミティブ構築モジュール)は、情報豊かな言語的手がかりを利用して、さまざまな意味属性を表現するためのプリミティブ集合𝒪′を生成します。これにより、モデルは特定の意味的信号に注目することで、ターゲットオブジェクトの局在化と識別精度を高めることができます。
言語プリミティブ𝒪′、マルチスケールポイント特徴量{𝑭1′、𝑭2′、𝑭3′、𝑭4′}、および言語特徴量𝑭tは、Transformerアーキテクチャ上に構築された4層クロスモーダルデコーダへの入力として機能します。
意味的に強化された言語プリミティブとオブジェクトクエリ𝒪cはObject Cluster Module (OCM)に渡され、プリミティブ間の関係性を解析し、それらの意味理解を統合し、共通する特徴量を抽出します。
視覚および言語モデルのバックボーンの上には、モダリティ融合モジュールが配置されており、著者らはマルチモーダル特徴量の融合をポイントエンコーダ内に統合しています。クロスモーダル特徴量の早期統合によって、融合プロセスの効率が向上します。Geometry-Enhanced Group-Word Attentionメカニズムは、幾何的に近接した局地的な点群(サブクラウド)を処理する革新的なアプローチを採用しており、直接的な点と言葉の相関によるノイズを軽減し、点群内に存在する本質的な幾何関係を活用することで、3D構造とテキスト情報の正確な統合を可能にしています。
従来の単純なクロスモーダルアテンション機構では、記述に対応する言葉を持たない点の処理が難しいという課題がありました。これに対処するために、著者らは学習可能な背景トークンを導入しています。この戦略により、対応するテキストが存在しない点は、共有の背景トークン埋め込みに注目するようになり、無関係なテキスト情報による歪みを最小限に抑えられます。
さらに、言語的対応が存在しない点を背景オブジェクトクラスタに組み込むことで、無関係な要素の影響をさらに減少させることができます。これにより、点の特徴量は、局所中心に基づいた意味情報で洗練され、無関係な語からの影響を受けにくくなります。この背景埋め込みは学習可能なパラメータであり、データセット全体の分布を捉え、元の入力情報を効果的に表現します。これはアテンション計算時のみ使用され、無関係な言語手がかりの影響を排除しながら、より精密なクロスモーダル相互作用を可能にします。
従来の多くの手法では、点群から直接サンプリングされた中心点に依存していましたが、この方法では、正確なセグメンテーションに不可欠な、言語学的文脈が無視されるという致命的な欠点があります。特に疎なシーンでは、遠く離れた点のみをサンプリングすることで予測が対象からずれ、収束を妨げ、検出漏れの原因になります。この問題は、選択された点がターゲットオブジェクトを正確に表現していなかったり、特定の単語にしか関連していなかったりする場合に顕著です。この課題に対処するために、著者らは意味的内容を含んだ言語プリミティブの構築を提案しています。これにより、モデルはターゲットオブジェクトに関連する様々な意味属性を学習できるようになります。
これらのプリミティブは、それぞれ異なるガウス分布からのサンプリングによって初期化され、各分布は特定の意味属性を表します。プリミティブは、形状、色、サイズ、材質、関係性、位置などの属性を符号化するように設計されています。各プリミティブは、対応する言語的特徴を集約し、関連する情報を抽出します。これらは、意味的パターンを表現することを目的としており、Transformerデコーダに通すことで多様な言語的手がかりを抽出できるようになります。これにより、後続のオブジェクト識別性能が向上します。
各言語プリミティブは、それぞれの意味属性と相関する点群内の異なる意味パターンに注目します。ただし、最終的な目標は、与えられたテキスト記述に基づいて唯一のターゲットオブジェクトを正確に識別することです。これには、オブジェクトの説明の包括的な理解と意味的解釈が必要です。この目的を達成するために、著者らはObject Cluster Moduleを用いて、言語プリミティブ間の関係を分析し、それらの主要領域における共通点と相違点を明らかにします。これにより、記述された対象物の意味理解が深化します。また、自己注意(Self-Attention)機構を用いて、言語的プリミティブ間に共通する特徴を抽出します。デコーディングの段階では、オブジェクトクエリがQueryとして導入され、言語的プリミティブによって強化された共有特徴量がKey-Valueとして機能します。この構成により、デコーダはプリミティブからの言語的知識をオブジェクトクエリに統合できるようになり、ターゲットオブジェクトに関連するクエリを効果的に識別・グループ化して𝒪c′を生成し、高精度なオブジェクト同定を実現します。
提案されたObject Cluster Moduleは、ターゲットオブジェクトの識別に大きく貢献する一方で、他の展開環境における推論時に生じうる曖昧性を完全に排除するものではありません。こうした曖昧性は、誤検出を引き起こす可能性があります。この問題を軽減するために、RefMask3Dの著者らは対照学習(contrastive learning)を導入し、ターゲットトークンとその他のトークンとを明確に区別できるようにしています。具体的には、正しいテキスト参照との類似度を最大化し、誤った(非ターゲット)ペアとの類似度を最小化することによって、学習をおこないます。
以下にRefMask3D手法の視覚化を示します。
2.MQL5での実装
RefMask3D手法の理論的な側面を検討したので、この記事の実践的な部分に移りましょう。この部分では、MQL5を使用して提案されたアプローチのビジョンを実装します。
上記の説明にあるように、RefMask3D手法の著者らは、複雑なアルゴリズムをいくつかの機能ブロックに分割しています。したがって、ここでの実装も、それに対応するモジュール形式で構築するのが理にかなっていると考えられます。
2.1幾何拡張グループワードアテンション
まず、ポイントエンコーダの構築から始めます。元の手法では、このエンコーダにGeometry-Enhanced Group-Word Attention(幾何拡張グループワードアテンション)モジュールが組み込まれています。このモジュールを、新たに作成するクラスCNeuronGEGWAに実装していきます。RefMask3Dの理論的概要でも述べられているように、ポイントエンコーダはU-Net形式のバックボーンとして設計されています。これに従い、この記事ではCNeuronGEGWAの親クラスとしてCNeuronUShapeAttentionを選択しました。この親クラスが、目的のオブジェクトに必要な基本機能を提供します。新クラスの構造は以下のとおりです。
class CNeuronGEGWA : public CNeuronUShapeAttention { protected: CNeuronBaseOCL cResidual; CNeuronMLCrossAttentionMLKV cCrossAttention; CBufferFloat cTemp; bool bAddNeckGradient; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronGEGWA(void) : bAddNeckGradient(false) {}; ~CNeuronGEGWA(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint window_kv, uint heads_kv, uint units_count_kv, uint layers, uint inside_bloks, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronGEGWA; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); //--- virtual CNeuronBaseOCL* GetInsideLayer(const int layer) const; virtual void AddNeckGradient(const bool flag) { bAddNeckGradient = flag; } };
ほとんどの変数やオブジェクトは、U-Netバックボーンを構成するために必要なものであり、親クラスから継承されます。ただし、クロスモーダルアテンション機構を構築するために、追加のコンポーネントも導入しています。
これらのオブジェクトはすべてstaticとして宣言されており、それによってクラスのコンストラクタおよびデストラクタを空のままにしておくことが可能になります。継承されたオブジェクトと新たに追加したオブジェクトの初期化処理は、Initメソッド内でおこなわれます。ご存知のとおり、このInitメソッドは、生成されるオブジェクトの必要なアーキテクチャに関する情報を明示的に指定するためのパラメータを受け取ります。
bool CNeuronGEGWA::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint window_kv, uint heads_kv, uint units_count_kv, uint layers, uint inside_bloks, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
メソッド本体では、まず最初に、全てのニューラルレイヤーオブジェクトの最上位クラスであるCNeuronBaseOCLの同名メソッドを呼び出します。このクラスは、ベースとなる全結合層クラスとして機能しています。
ここで注意すべき点は、呼び出しているのが直近の親クラスではなく、さらに上位の基底クラスであるということです。これは、U-Netバックボーンの構築において用いている、特定のアーキテクチャ上の設計によるものです。具体的には、「ネック」部分の構築時に、オブジェクトの再帰的生成をおこなうため、この段階では異なるクラスのコンポーネントを利用する必要があります。
その後、主となるアテンションおよびスケーリング用のオブジェクトの初期化処理に進みます。
if(!cAttention[0].Init(0, 0, OpenCL, window, window_key, heads, units_count, layers, optimization, iBatch)) return false; if(!cMergeSplit[0].Init(0, 1, OpenCL, 2 * window, 2*window, window, (units_count + 1) / 2, optimization, iBatch)) return false;
続いて、「ネック」部分の生成アルゴリズムが実行されます。作成される「ネック」オブジェクトの種類は、そのサイズに依存します。基本的には、現在のオブジェクトと同様の構造を持つオブジェクトを生成しますが、内部の「ネック」のサイズを「1」だけ減らすという点が異なります。
if(inside_bloks > 0) { CNeuronGEGWA *temp = new CNeuronGEGWA(); if(!temp) return false; if(!temp.Init(0, 2, OpenCL, window, window_key, heads, (units_count + 1) / 2, window_kv, heads_kv, units_count_kv, layers, inside_bloks - 1, optimization, iBatch)) { delete temp; return false; } cNeck = temp; }
最終層では、クロスアテンションブロックを使用します。
else { CNeuronMLCrossAttentionMLKV *temp = new CNeuronMLCrossAttentionMLKV(); if(!temp) return false; if(!temp.Init(0, 2, OpenCL, window, window_key, heads, window_kv, heads_kv, (units_count + 1) / 2, units_count_kv, layers, 1, optimization, iBatch)) { delete temp; return false; } cNeck = temp; }
次に、再アテンションモジュールと逆スケーリングモジュールを初期化します。
if(!cAttention[1].Init(0, 3, OpenCL, window, window_key, heads, (units_count + 1) / 2, layers, optimization, iBatch)) return false; if(!cMergeSplit[1].Init(0, 4, OpenCL, window, window, 2*window, (units_count + 1) / 2, optimization, iBatch)) return false;
その後、残差接続層とマルチモーダルクロスアテンションモジュールを追加します。
if(!cResidual.Init(0, 5, OpenCL, Neurons(), optimization, iBatch)) return false; if(!cCrossAttention.Init(0, 6, OpenCL, window, window_key, heads, window_kv, heads_kv, units_count, units_count_kv, layers, 1, optimization, iBatch)) return false;
また、一時的なデータ保存用の補助バッファも初期化します。
if(!cTemp.BufferInit(MathMax(cCrossAttention.GetSecondBufferSize(), cAttention[0].Neurons()), 0) || !cTemp.BufferCreate(OpenCL)) return false;
初期化メソッドの最後に、データのコピー回数を最小限に抑えるために、データバッファへのポインタを差し替えます。
if(Gradient != cCrossAttention.getGradient()) { if(!SetGradient(cCrossAttention.getGradient(), true)) return false; } if(cResidual.getGradient() != cMergeSplit[1].getGradient()) { if(!cResidual.SetGradient(cMergeSplit[1].getGradient(), true)) return false; } if(Output != cCrossAttention.getOutput()) { if(!SetOutput(cCrossAttention.getOutput(), true)) return false; } //--- return true; }
次に、メソッドの処理結果を示す真偽値を呼び出し元プログラムに返します。
新しいオブジェクトの初期化処理が完了した後、feedForwardメソッドにてフィードフォワードアルゴリズムの構築に移ります。親クラスとは異なり、本オブジェクトは2つのデータソースを必要とするため、単一データソース用に設計された親クラスのメソッドは、ネガティブスタブ(機能停止)としてオーバーライドされています。一方で、新たに実装されたメソッドは一から書き直されたものです。
メソッドのパラメータとして、2つの入力データオブジェクトへのポインタを受け取りますが、現時点では両者に対する検証はおこなわれていません。
bool CNeuronGEGWA::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!cAttention[0].FeedForward(NeuronOCL)) return false;
まず、2つのデータソースのうちの一方へのポインタを、プライマリアテンションサブレイヤーの同名メソッドに渡します。ポインタの検証は既に当該メソッド内でおこなわれているため、こちらではメソッドの論理的な実行結果のみを確認すれば十分です。その後、アテンションブロックの出力をスケーリングします。
if(!cMergeSplit[0].FeedForward(cAttention[0].AsObject())) return false;
スケーリングしたデータと、2つ目のデータソースオブジェクトへのポインタを「ネック」に渡します。
if(!cNeck.FeedForward(cMergeSplit[0].AsObject(), SecondInput)) return false;
得られた結果を2番目のアテンションブロックに渡し、逆データスケーリングを実行します。
if(!cAttention[1].FeedForward(cNeck)) return false; if(!cMergeSplit[1].FeedForward(cAttention[1].AsObject())) return false;
その後、残差接続を追加し、クロスモーダルな依存関係を解析します。
if(!SumAndNormilize(NeuronOCL.getOutput(), cMergeSplit[1].getOutput(), cResidual.getOutput(), 1, false)) return false; if(!cCrossAttention.FeedForward(cResidual.AsObject(), SecondInput)) return false; //--- return true; }
逆伝播メソッドの作業に入る前に、ひとつ確認しておくべきポイントがあります。以下に、RefMask3D手法の可視化からの抜粋をご覧ください。
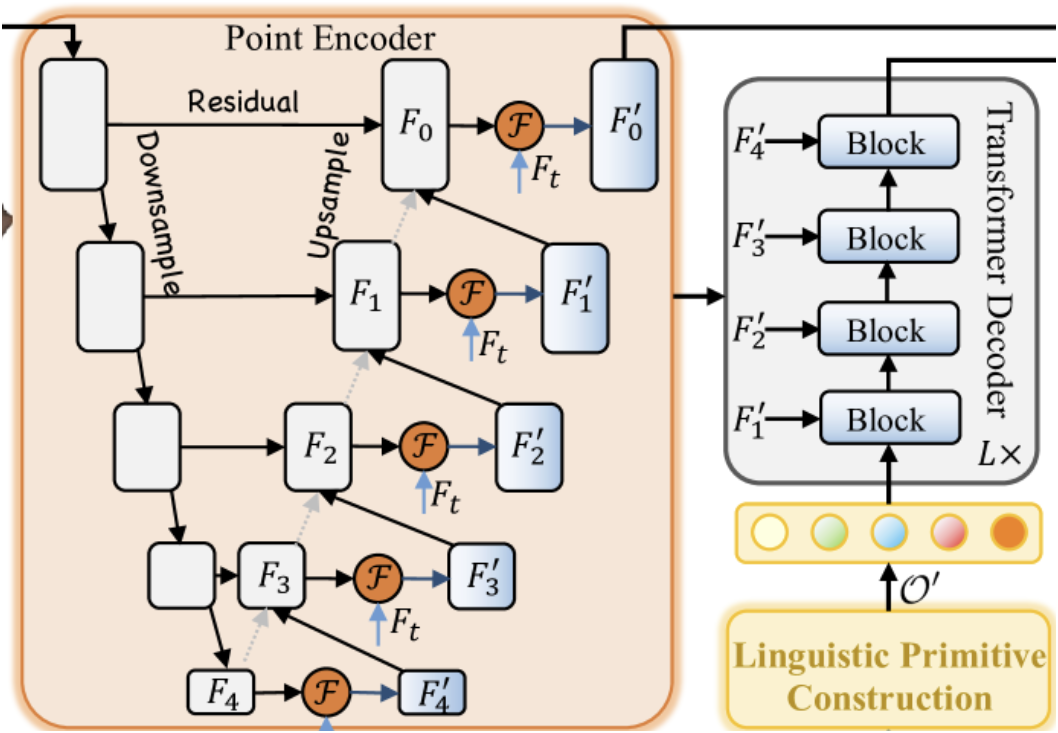
ここでの重要なポイントは、デコーダーにおいて、学習可能なプリミティブと私たちのポイントエンコーダの中間出力との間でクロスモーダルアテンションがおこなわれていることです。一見単純なこの操作は、対応する誤差勾配の伝搬を必要とすることを意味しています。当然ながら、このために適切なインターフェイスの実装が求められます。統合されたRefMask3Dブロックにおける勾配分配の実装では、まずデコーダーの勾配を計算し、その後にポイントエンコーダの勾配を計算します。しかし、古典的な勾配の逆伝播モデルにおいては、この順序で処理をおこなうと、デコーダから渡された勾配データが失われてしまいます。このブロックの特定の利用方法は特例に該当すると認識しているため、calcInputGradientsメソッドでは2つの動作モードを用意しています。ひとつは従来どおり、既に保持されている勾配をクリアする標準動作、もうひとつは今回のような特殊ケースに対応するため、勾配を保持し続けるモードです。この機能を有効にするために、内部フラグ変数bAddNeckGradientと、それを操作するセッターメソッドAddNeckGradientを導入しました。
virtual void AddNeckGradient(const bool flag) { bAddNeckGradient = flag; }
では、逆伝播アルゴリズムに戻りましょう。calcInputGradientsメソッドのパラメータには、3つのオブジェクトへのポインタと、2つ目のデータソースの活性化関数の定数が渡されます。
bool CNeuronGEGWA::calcInputGradients(CNeuronBaseOCL *prevLayer, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = -1) { if(!prevLayer) return false;
メソッド本体では、最初のデータソースへのポインタの有効性のみをチェックします。その他のポインタについては、内部層の誤差勾配分配メソッド内で検証がおこなわれます。
また、データバッファへのポインタ差し替えを実装しているため、誤差勾配分配アルゴリズムはクロスモーダルアテンションの内部層から開始されます。
if(!cResidual.calcHiddenGradients(cCrossAttention.AsObject(), SecondInput, SecondGradient, SecondActivation)) return false;
その後、誤差勾配のスケーリングを実行します。
if(!cAttention[1].calcHiddenGradients(cMergeSplit[1].AsObject())) return false;
次に、これまでに蓄積された誤差勾配を保持する必要があるかどうかで、アルゴリズムの分岐を整理します。誤差勾配を保持する必要がある場合は、「ネック」にある誤差勾配バッファを、第一のデータスケーリング層にある同様の勾配バッファに差し替えます。ここで利用する性質は、指定されたスケーリング層の出力テンソルのサイズが「ネック」のサイズと等しいという点です。誤差勾配は後ほどこの層へ転送されるため、この場合は安全に操作をおこなうことができます。
if(bAddNeckGradient) { CBufferFloat *temp = cNeck.getGradient(); if(!cNeck.SetGradient(cMergeSplit[0].getGradient(), false)) return false;
次に、古典的な手法を用いて「ネック」レベルでの誤差勾配を取得します。2つの情報経路から得られた結果を合算し、オブジェクトへのポインタを返します。
if(!cNeck.calcHiddenGradients(cAttention[1].AsObject())) return false; if(!SumAndNormilize(cNeck.getGradient(), temp, temp, 1, false, 0, 0, 0, 1)) return false; if(!cNeck.SetGradient(temp, false)) return false; }
これまでに蓄積された誤差勾配を保持する必要がない場合は、通常の手法で誤差勾配を取得します。
else if(!cNeck.calcHiddenGradients(cAttention[1].AsObject())) return false;
次に、「ネック」オブジェクトを通じて誤差勾配を伝播させる必要があります。今回は古典的な方法を使います。ここでは、第二のデータソースの誤差勾配を一時的なデータ格納バッファに受け取ります。後ほど、現在のオブジェクトのクロスモーダルアテンションモジュールから得られた値と「ネック」からの値を合算する必要があります。
if(!cMergeSplit[0].calcHiddenGradients(cNeck.AsObject(), SecondInput, GetPointer(cTemp), SecondActivation)) return false; if(!SumAndNormilize(SecondGradient, GetPointer(cTemp), SecondGradient, 1, false, 0, 0, 0, 1)) return false;
次に、誤差勾配を最初の入力データソースのレベルに伝播します。
if(!cAttention[0].calcHiddenGradients(cMergeSplit[0].AsObject())) return false; if(!prevLayer.calcHiddenGradients(cAttention[0].AsObject())) return false;
残差接続の誤差勾配を活性化関数の微分を通じて伝播させ、2つの情報経路からの情報を合算します。
if(!DeActivation(prevLayer.getOutput(), GetPointer(cTemp), cMergeSplit[1].getGradient(), prevLayer.Activation())) return false; if(!SumAndNormilize(prevLayer.getGradient(), GetPointer(cTemp), prevLayer.getGradient(), 1, false)) return false; //--- return true; }
モデルパラメータを更新するためのupdateInputWeightsメソッドは非常にシンプルです。学習可能なパラメータを持つ内部層の対応する更新メソッドを呼び出すだけなので、それらの実装についてはぜひご自身で確認してみてください。このクラスおよび全メソッドの完全な実装は添付ファイルにあります。
次に、「ネック」オブジェクトへアクセスするためのインターフェイス作成について少し補足します。この機能を実装するために、GetInsideLayerメソッドを作成しました。このメソッドのパラメータには、必要な層のインデックスを渡します。
CNeuronBaseOCL* CNeuronGEGWA::GetInsideLayer(const int layer) const { if(layer < 0) return NULL;
負のインデックスが取得された場合は、エラーが発生したことを意味します。この場合、メソッドはNULLポインタを返します。一方、ゼロが渡された場合は現在の層にアクセスしていることを示します。したがって、メソッドは「ネック」オブジェクトへのポインタを返します。
if(layer == 0) return cNeck;
それ以外の場合、「ネック」は対応するクラスのオブジェクトである必要があり、必要な層のインデックスを1減らして、このメソッドを再帰的に呼び出します。
if(!cNeck || cNeck.Type() != Type()) return NULL; //--- CNeuronGEGWA* temp = cNeck; return temp.GetInsideLayer(layer - 1); }
2.2 言語プリミティブの構築
次のステップでは、CNeuronLPCクラスで言語プリミティブ構築モジュールのオブジェクトを作成します。このメソッドの元の図を以下に示します。
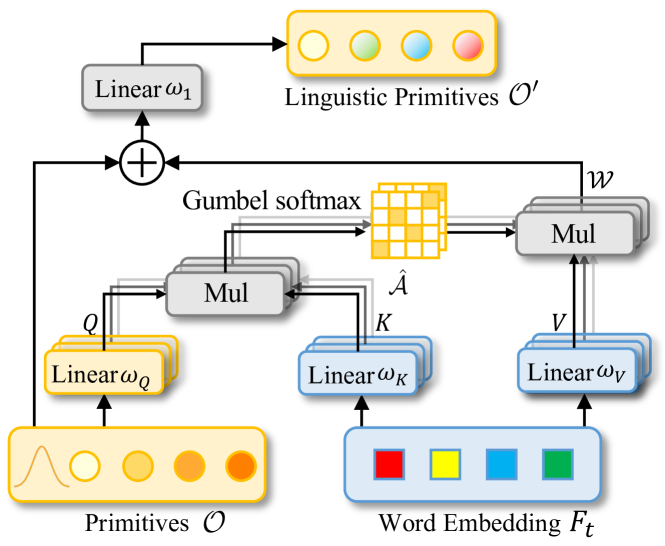
ここで、古典的なクロスアテンションブロックとの類似点が見受けられます。これは適切な親クラスを選定する指針となります。この場合、CNeuronMLCrossAttentionMLKVというクロスアテンションオブジェクトクラスを使用します。新クラスの構造は以下のとおりです。
class CNeuronLPC : public CNeuronMLCrossAttentionMLKV { protected: CNeuronBaseOCL cOne; CNeuronBaseOCL cPrimitives; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) override { return feedForward(NeuronOCL); } //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override { return calcInputGradients(NeuronOCL); } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) override { return updateInputWeights(NeuronOCL); } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronLPC(void) {}; ~CNeuronLPC(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint units_count_kv, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronLPC; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
前回のケースでは、フィードフォワードおよび逆伝播処理のために入力データのソースを追加しました。しかし今回はその逆で、クロスアテンションモジュールは2つのデータソースを必要としますが、本実装では1つだけを使用します。これは、2つ目のデータソース(学習可能なプリミティブ)がこのオブジェクト内部で生成されるためです。
この学習可能なプリミティブを生成するために、2つの内部全結合層オブジェクトを定義します。これらのオブジェクトはいずれもstaticとして宣言されているため、クラスのコンストラクタおよびデストラクタは空のままにできます。これらの宣言済みおよび継承されたオブジェクトの初期化は、Initメソッド内でおこなわれます。
bool CNeuronLPC::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint units_count_kv, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronMLCrossAttentionMLKV::Init(numOutputs, myIndex, open_cl, window, window_key, heads, window, heads_kv, units_count, units_count_kv, layers, layers_to_one_kv, optimization_type, batch)) return false;
このメソッドのパラメータには、作成されるオブジェクトのアーキテクチャを一意に決定するための定数が渡されます。メソッド本体では、まず親クラスの該当メソッドを呼び出し、受け取ったパラメータの検証および継承オブジェクトの初期化をおこないます。
なお、生成されるプリミティブのパラメータを、プライマリデータソースに関する情報として使用している点にご注意ください。
次に、要素数が1の単一全結合層を生成します。
if(!cOne.Init(window * units_count, 0, OpenCL, 1, optimization, iBatch)) return false; CBufferFloat *out = cOne.getOutput(); if(!out.BufferInit(1, 1) || !out.BufferWrite()) return false;
次に、プリミティブを使用して生成層を初期化します。
if(!cPrimitives.Init(0, 1, OpenCL, window * units_count, optimization, iBatch)) return false; //--- return true; }
なお、本ケースでは位置エンコーディング層は使用していません。元のロジックによれば、プリミティブの一部は対象物の位置を捉え、他のプリミティブはその意味的属性を蓄積する役割を担っています。
本実装のfeedForwardメソッドも非常にシンプルです。パラメータとして入力データオブジェクトへのポインタを受け取り、最初のステップでこのポインタの有効性を検証します。ただし、このポインタ検証は最近の多くのフィードフォワードメソッドでは一般的におこなわれていない点を付け加えておきます。
bool CNeuronLPC::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
このようなチェックは通常、ネストされたコンポーネント内部で処理されます。しかし今回の場合、外部プログラムから受け取ったデータをコンテキストとして使用するため、内部オブジェクトのメソッドを呼び出す際に、渡された入力オブジェクトのネストされたメンバーにアクセスする必要があります。このため、受け取ったポインタの有効性を明示的に確認する義務があります。
次に、特徴量テンソルを生成します。
if(bTrain && !cPrimitives.FeedForward(cOne.AsObject())) return false;
ここで注意すべき点は、意思決定プロセスの時間を短縮するため、この処理は訓練時のみ実行されるということです。展開フェーズ(推論時)では、プリミティブテンソルは静的なままであり、毎回のイテレーションで再生成する必要はありません。
フォワードパスは、親クラスのfeedForwardメソッドを呼び出すことで終了します。このメソッドには、生成したプリミティブテンソルをプライマリデータソースとして渡し、外部プログラムからのコンテキスト情報をセカンダリ入力として渡します。
if(!CNeuronMLCrossAttentionMLKV::feedForward(cPrimitives.AsObject(), NeuronOCL.getOutput())) return false; //--- return true; }
calcInputGradients勾配伝播メソッドでは、フィードフォワードパスアルゴリズムの操作を逆の順序で実行します。
bool CNeuronLPC::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
ここでも、まずソースデータオブジェクトへの受信したポインタを確認します。そして、同じ名前の親クラスのメソッドを呼び出して、プリミティブと元のコンテキストの間で誤差勾配を分散します。
if(!CNeuronMLCrossAttentionMLKV::calcInputGradients(cPrimitives.AsObject(), NeuronOCL.getOutput(), NeuronOCL.getGradient(), (ENUM_ACTIVATION)NeuronOCL.Activation())) return false;
その後、プリミティブ多様化誤差の勾配を加算します。
if(!DiversityLoss(cPrimitives.AsObject(), iUnits, iWindow, true)) return false; //--- return true; }
誤差勾配を個々の層のレベルまで伝播させることは実務上あまり意味がないため、この処理は省略します。パラメータ更新アルゴリズムについても独自に検討していただく形とします。このクラスとそのすべてのメソッドの完全なコードは、添付ファイルで確認できます。
RefMask3Dパイプラインの次のコンポーネントは、点群と学習可能なプリミティブ間のマルチモーダルクロスアテンション機構を実装する、バニラTransformerデコーダブロックです。この機能は既に開発済みのツール群でカバーできるため、専用の新規ブロックは作成しません。
もう一つ実装が必要なモジュールは、オブジェクトクラスタリングモジュールです。このモジュールのアルゴリズムは、CNeuronOCMクラスに実装されます。かなり複雑なモジュールで、プリミティブ用とセマンティック特徴用の2つの自己アテンションブロックを組み合わせ、さらにクロスアテンションブロックで拡張しています。新クラスの構造は以下のとおりです。
class CNeuronOCM : public CNeuronBaseOCL { protected: uint iPrimWindow; uint iPrimUnits; uint iPrimHeads; uint iContWindow; uint iContUnits; uint iContHeads; uint iWindowKey; //--- CLayer cQuery; CLayer cKey; CLayer cValue; CLayer cMHAttentionOut; CLayer cAttentionOut; CArrayInt cScores; CLayer cResidual; CLayer cFeedForward; //--- virtual bool CreateBuffers(void); virtual bool AttentionOut(CNeuronBaseOCL *q, CNeuronBaseOCL *k, CNeuronBaseOCL *v, const int scores, CNeuronBaseOCL *out, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension); virtual bool AttentionInsideGradients(CNeuronBaseOCL *q, CNeuronBaseOCL *k, CNeuronBaseOCL *v, const int scores, CNeuronBaseOCL *out, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } public: CNeuronOCM(void) {}; ~CNeuronOCM(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint prim_window, uint window_key, uint prim_units, uint prim_heads, uint cont_window, uint cont_units, uint cont_heads, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronOCM; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool feedForward(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); virtual bool calcInputGradients(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); virtual bool updateInputWeights(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); };
ご理解いただけると思いますが、このクラスに含まれる各メソッドは、かなり複雑なアルゴリズムを伴います。それぞれに詳細な説明が必要となりますが、本記事の形式ではそれを十分に扱うには制約があります。そのため、実装済みアルゴリズムの詳細な解説と品質の高い概要を提供するために、続編記事にて議論を続けることを提案いたします。次回の記事では、実際の市場データを用いたモデルのテスト結果についても取り上げる予定です。
結論
本記事では、複雑なマルチモーダル相互作用と特徴量理解のために設計されたRefMask3D手法について考察しました。この手法は、取引分野における革新的アプローチとして、大きな可能性を秘めています。多次元データを活用することで、市場行動の現在および過去のパターンの両方を考慮することが可能です。RefMask3Dでは、重要な特徴に注目しつつ、ノイズや無関係な入力の影響を最小限に抑えるためのさまざまなメカニズムが導入されています。
実装セクションでは、MQL5を用いて提案手法の実装を開始し、提案されたモジュールのうち2つのオブジェクトを開発しました。しかしながら、完了した作業の範囲は一つの記事で十分に扱える量を超えています。したがって、本記事で開始した実装と考察は、今後の続編記事でさらに展開していきます。
参照文献
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | 事例収集のためのEA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法による事例収集のためのEA |
| 3 | Study.mq5 | EA | モデル訓練EA |
| 4 | Test.mq5 | EA | モデルテストEA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | ライブラリ | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/16038
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

 Metatrader 5のWebsockets — Windows APIを使用した非同期クライアント接続
Metatrader 5のWebsockets — Windows APIを使用した非同期クライアント接続
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索