
ニューラルネットワークが簡単に(第96回):マルチスケール特徴量抽出(MSFformer)

はじめに
時系列データは実世界で広く利用されており、金融をはじめとするさまざまな分野で重要な役割を果たしています。このデータは、異なる時点で収集された観測値のシーケンスを表します。深い時系列分析とモデリングを通じて、研究者は将来のトレンドやパターンを予測することが可能になり、それが意思決定プロセスに活用されています。
近年、ディープラーニングモデルを用いた時系列データの研究に多くの研究者が注力しています。これらの手法は、非線形な関係を捉え、長期的な依存関係を処理するのに優れており、特に複雑なシステムのモデリングに効果的であることが実証されています。しかし、これまでの研究成果がある一方で、長期的な依存関係と短期的な特徴量をいかに効率的に抽出・統合するかという課題が依然として残されています。正確で信頼性の高い予測モデルを構築するためには、これら2種類の依存関係を適切に理解し、統合することが極めて重要です。
この問題を解決するための選択肢の1つとして、論文「Time Series Prediction Based on Multi-Scale Feature Extraction」が発表されました。本論文では、時系列予測モデルであるMSFformer (Multi-Scale Feature Transformer)が紹介されています。このモデルは、改良されたピラミッド型アテンションアーキテクチャを基盤としており、マルチスケールの特徴量を効率的に抽出・統合するために設計されています。
本モデルの著者は、MSFformerの革新性として以下の点を強調しています。
- Skip-PAMメカニズムの導入により、長期および短期の特徴量を効果的に捉えることが可能
- ピラミッドデータ構造を作成するCSCMモジュールの改良
さらに、MSFformerの著者は3つの時系列データセットを用いて実験をおこない、提案モデルの卓越した性能を実証しました。提案されたメカニズムにより、MSFformerモデルは複雑な時系列データを従来よりも正確かつ効率的に処理し、高い予測精度と信頼性を実現しています。
1. MSFformerアルゴリズム
MSFformerモデルの著者は、異なる時間間隔におけるピラミッド型アテンションメカニズムの革新的なアーキテクチャを提案しています。さらに、入力データ内の多階層の時間情報を構築するため、大規模構築モジュールであるCSCM (Coarser-Scale Construction Module)において特徴量の畳み込みを用いています。これにより、粗いスケールでの時間的情報を効率的に抽出することが可能になります。
CSCMモジュールは、分析対象となる時系列データの特徴量ツリーを構築します。このプロセスでは、入力データがまず全結合層を通過し、特徴量の次元が固定サイズに変換されます。その後、特別に設計された複数のFCNN特徴量畳み込みブロックが順次適用されます。
FCNNブロックでは、まず所定のクロスステップ(間隔)を用いて入力シーケンスからデータを抽出し、特徴量ベクトルを形成します。その後、これらの特徴量ベクトルが結合され、結合されたベクトルに対して畳み込み演算が実行されます。以下に、著者によるFCNNブロックの可視化図を示します。
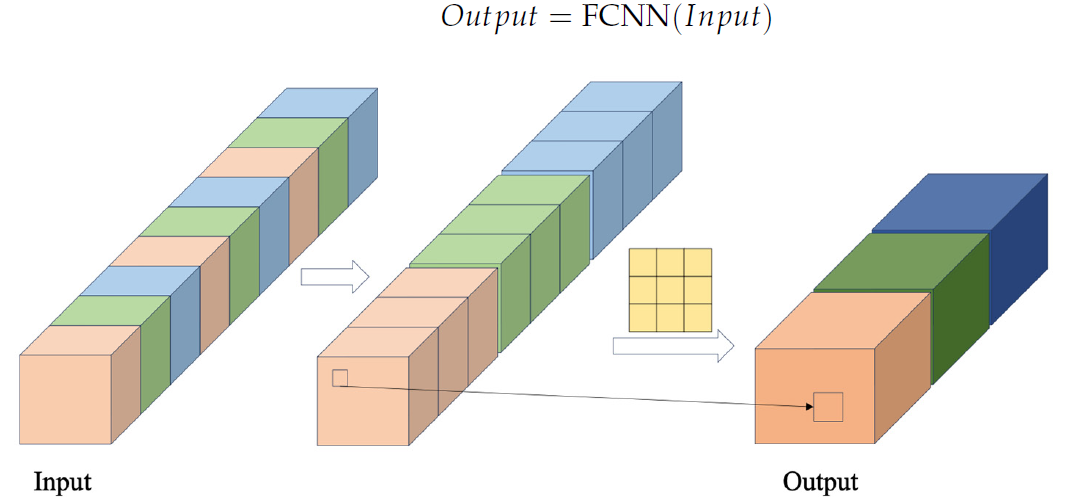
著者が提案したCSCMモジュールは、複数の連続したFCNNブロックを使用します。それぞれのブロックは、前のブロックの出力を入力として利用し、より大きなスケールの特徴量を抽出します。
このプロセスによって得られた異なるスケールの特徴量は1つのベクトルに統合されます。その後、この統合されたベクトルは、線形層によって入力データのスケールに縮小されます。
以下に、筆者によるCSCMモジュールの視覚化を示します。
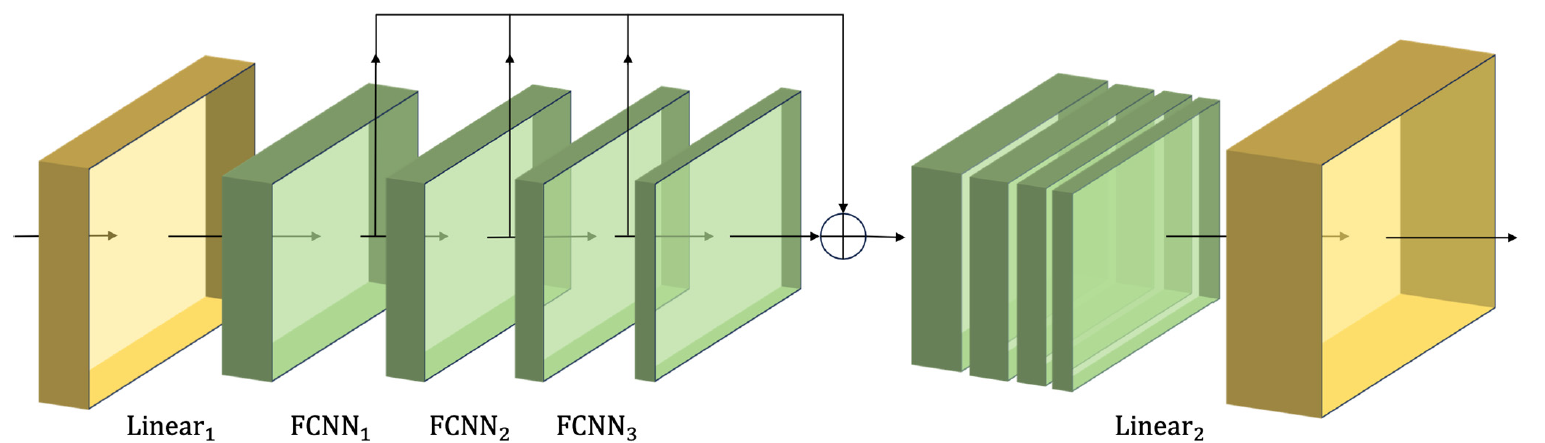
分析対象の時系列データをこのようなCSCMに通すことで、異なる粒度レベルの特徴量に関する時間的情報を取得することが可能になります。FCNN層を積み重ねることで特徴量のピラミッドツリーを構築します。これにより、データを複数のレベルで理解することができ、革新的なピラミッド型アテンション構造Skip-PAM (Skip-Pyramidal Attention Module)を実装するための強固な基盤となります。
Skip-PAMの主なアイデアは、異なる時間間隔で入力データを処理することで、モデルが異なる粒度レベルの時間依存性を捉えられるようにすることです。低いレベルでは、短期的で詳細なパターンに焦点を当てることが可能です。一方、上位レベルでは、より巨視的な傾向や周期性を捉えることができます。提案されたSkip-PAMは、たとえば「毎週月曜日」や「毎月の初め」といった定期的な依存関係に特に注目します。このマルチスケールアプローチにより、モデルはさまざまなレベルの時間的関係を幅広く捉えることができます。
Skip-PAMは、時間特徴量ツリーに基づくアテンションメカニズムを活用して、複数のスケールにわたる時系列データから情報を抽出します。このプロセスには、スケール内接続とスケール間接続が含まれます。スケール内接続では、同じ層にあるノードとその隣接ノードとの間でアテンション計算をおこないます。一方、スケール間接続では、ノードとその親ノードとの間でアテンション計算を実行します。
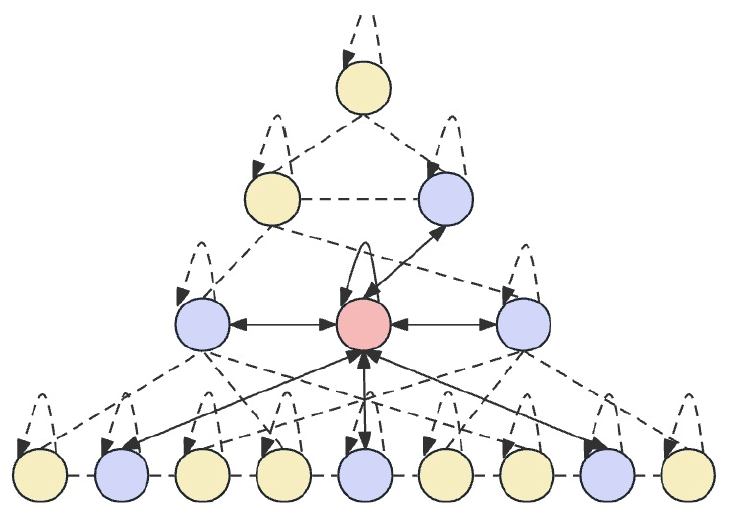
このピラミッド型アテンションメカニズムSkip-PAMとCSCMのマルチスケール特徴量畳み込みを組み合わせることで、短期的な変動であれ長期的な進化であれ、異なる時間スケールにおけるダイナミックな変化に適応可能な強力な特徴量抽出ネットワークが形成されます。
この手法の著者は、上記の2つのモジュールを統合し、1つの強力なMSFformerモデルを構築しました。そのオリジナルのビジュアルを以下に示します。
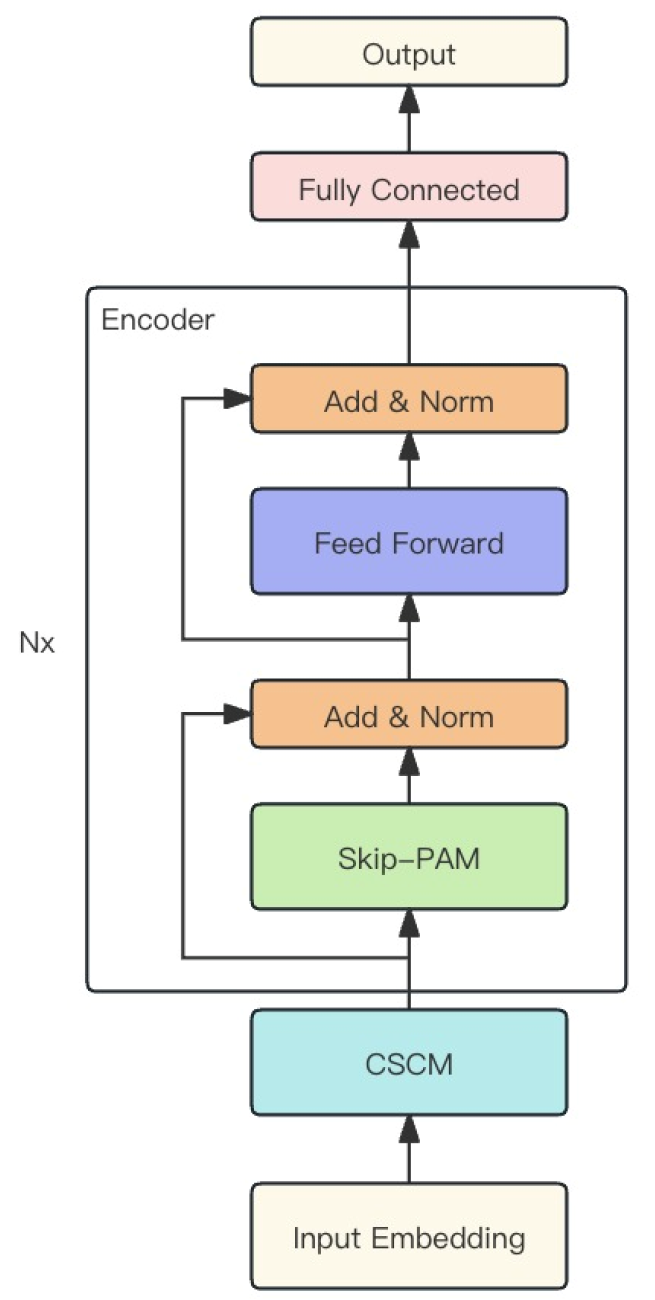
2. MQL5での実装
MSFformer手法の理論的な側面を考察した後、記事の実践的な部分に進みます。このセクションでは、提案されたアプローチをMQL5を使用して実装する方法を説明します。
前述のとおり、提案されたMSFformer手法はCSCMとSkip-PAMの2つのモジュールに基づいています。本記事の範囲内でこれらを実装します。作業量が多いため、各モジュールの実装に基づき、2つの部分に分割して説明します。
2.1.CSCMモジュールの構築
最初に、CSCMモジュールの構築をおこないます。このモジュールのアーキテクチャを実装するために、CNeuronCSCMOCLクラスを作成します。このクラスはニューラル層の基盤クラスCNeuronBaseOCLから主な機能を継承します。以下に新しいクラスの構造を示します。
class CNeuronCSCMOCL : public CNeuronBaseOCL { protected: uint i_Count; uint i_Variables; bool b_NeedTranspose; //--- CArrayInt ia_Windows; CArrayObj caTranspose; CArrayObj caConvolutions; CArrayObj caMLP; CArrayObj caTemp; CArrayObj caConvOutputs; CArrayObj caConvGradients; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronCSCMOCL(void) {}; ~CNeuronCSCMOCL(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint &windows[], uint variables, uint inputs_count, bool need_transpose, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronCSCMOCL; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
提示されたCNeuronCSCMOCLクラスの構造には、標準的なオーバーライド可能なメソッドセットと、多数の動的配列があります。これらの配列は、マルチスケール特徴量抽出構造を整理する際に役立ちます。動的配列と宣言された変数の目的については、メソッドの実装過程で説明します。
このクラスのすべてのオブジェクトは静的に宣言されています。これにより、クラスのコンストラクタとデストラクタを空の状態にすることができます。ネストされたすべてのオブジェクトや変数は、Initメソッド内で初期化されます。
Initメソッドでは、生成されるオブジェクトのアーキテクチャを一意に決定するための基本定数を取得します。
また、ユーザーが特徴量抽出層の数や畳み込みウィンドウのサイズを柔軟に決定できるように、動的配列windowsを使用します。この配列の要素数は、作成するFCNN特徴量抽出ブロックの数を示します。それぞれの要素の値は、対応するブロックの畳み込みウィンドウのサイズを示します。
多次元入力時系列中の単位時系列の数と元の時系列のサイズは、それぞれvariablesとinputs_countパラメータで指定します。
さらに、特徴量抽出の前に入力を転置する必要性を示す論理変数need_transposeを追加します。
bool CNeuronCSCMOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint &windows[], uint variables, uint inputs_count, bool need_transpose, ENUM_OPTIMIZATION optimization_type, uint batch) { const uint layers = windows.Size(); if(layers <= 0) return false; if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, inputs_count * variables, optimization_type, batch)) return false;
メソッド本体では、小さな制御ブロックを実装します。ここではまず、少なくとも1つの特徴量抽出ブロックを作る必要があるかどうかを確認します。その後、同じ名前の親クラスのメソッドを呼び出します。このメソッドでは、制御関数の一部と継承オブジェクトの初期化がすでに実装されています。親クラスのメソッドの実行結果を、返される論理値でコントロールします。
次のステップでは、受け取ったパラメータを対応する内部変数と配列に保存します。
if(!ia_Windows.AssignArray(windows)) return false; i_Variables = variables; i_Count = inputs_count / ia_Windows[0]; b_NeedTranspose = need_transpose;
その後、ネストしたオブジェクトを初期化するプロセスに入ります。入力データを転置する必要がある場合は、ここで2つのネスト化されたデータ転置層を作成します。最初の層は、入力データを移調するためのものです。
if(b_NeedTranspose) { CNeuronTransposeOCL *transp = new CNeuronTransposeOCL(); if(!transp) return false; if(!transp.Init(0, 0, OpenCL, inputs_count, i_Variables, optimization, iBatch)) { delete transp; return false; } if(!caTranspose.Add(transp)) { delete transp; return false; }
もう1つは、出力を転置して入力の次元に戻すものです。
transp = new CNeuronTransposeOCL(); if(!transp) return false; if(!transp.Init(0, 1, OpenCL, i_Variables, inputs_count, optimization, iBatch)) { delete transp; return false; } if(!caTranspose.Add(transp)) { delete transp; return false; } if(!SetOutput(transp.getOutput()) || !SetGradient(transp.getGradient()) ) return false; }
なお、データを転置する必要があるときは、このクラスの結果とグラデーションバッファを、転置結果の層の対応するバッファにオーバーライドします。このステップによって、不必要なデータコピー作業を省くことができます。
次に、個々の単位配列内で入力データのサイズを揃える層を作成します。
uint total = ia_Windows[0] * i_Count; CNeuronConvOCL *conv = new CNeuronConvOCL(); if(!conv.Init(0, 0, OpenCL, inputs_count, inputs_count, total, 1, i_Variables, optimization, iBatch)) { delete conv; return false; } if(!caConvolutions.Add(conv)) { delete conv; return false; }
ループの中で、必要な数の畳み込み特徴量抽出層を作成します。
total = 0; for(uint i = 0; i < layers; i++) { conv = new CNeuronConvOCL(); if(!conv.Init(0, i + 1, OpenCL, ia_Windows[i], ia_Windows[i], (i < (layers - 1) ? ia_Windows[i + 1] : 1), i_Count, i_Variables, optimization, iBatch)) { delete conv; return false; } if(!caConvolutions.Add(conv)) { delete conv; return false; } if(!caConvOutputs.Add(conv.getOutput()) || !caConvGradients.Add(conv.getGradient()) ) return false; total += conv.Neurons(); }
caConvolutions配列では、入力データサイズのアライメント層と特徴量抽出畳み込み層を組み合わせます。したがって、FCNNブロックの指定数より1つ多いオブジェクトが含まれています。
CSCMモジュールのアルゴリズムに従い、分析したすべてのスケールの特徴量を1つのテンソルに連結する必要があります。したがって、畳み込み層の作成とともに、関連する出力テンソルの合計サイズを計算します。さらに、作成された特徴量抽出層の出力データバッファと誤差勾配へのポインタを別々の動的配列に保存しました。これにより、モデルの訓練や運用プロセスにおいて、その内容に素早くアクセスできるようになります。
さて、必要な値を得たので、連結したテンソルを書くための層を作ることができます。
CNeuronBaseOCL *comul = new CNeuronBaseOCL(); if(!comul.Init(0, 0, OpenCL, total, optimization, iBatch)) { delete comul; return false; } if(!caMLP.Add(comul)) { delete comul; return false; }
ここでは、1つの特徴量抽出層を作成するための特別なケースも提供します。この場合、結合するものは何もなく、結合されたテンソルは単一の特徴量抽出テンソルの完全なコピーとなります。そこで、不要なコピー操作を避けるために、結果バッファと誤差勾配バッファを再定義します。
if(layers == 1) { comul.SetOutput(conv.getOutput()); comul.SetGradient(conv.getGradient()); }
その後、連結した特徴量テンソルの次元を入力シーケンスのサイズに線形調整する層を作成します。
conv = new CNeuronConvOCL(); if(!conv.Init(0, 0, OpenCL, total / i_Variables, total / i_Variables, inputs_count, 1, i_Variables, optimization, iBatch)) { delete conv; return false; } if(!caMLP.Add(conv)) { delete conv; return false; }
入力データを転置する必要がある場合のために、クラスの入力バッファと結果バッファをオーバーライドしました。別のケースを想定して、今はそれをオーバーライドします。
if(!b_NeedTranspose) { if(!SetOutput(conv.getOutput()) || !SetGradient(conv.getGradient()) ) return false; }
こうすることで、入力データの転置が必要であろうとなかろうと、どちらの場合でも不必要なデータコピー操作を排除しました。
メソッドの最後に、中間データを格納するための3つの補助バッファを作成します。これは、特徴量を連結し、対応する誤差勾配をデコンカテナ化する際に使用します。
CBufferFloat *buf = new CBufferFloat(); if(!buf) return false; if(!buf.BufferInit(total, 0) || !buf.BufferCreate(OpenCL) || !caTemp.Add(buf)) { delete buf; return false; } buf = new CBufferFloat(); if(!buf) return false; if(!buf.BufferInit(total, 0) || !buf.BufferCreate(OpenCL) || !caTemp.Add(buf)) { delete buf; return false; } buf = new CBufferFloat(); if(!buf) return false; if(!buf.BufferInit(total, 0) || !buf.BufferCreate(OpenCL) || !caTemp.Add(buf)) { delete buf; return false; } //--- caConvOutputs.FreeMode(false); caConvGradients.FreeMode(false); //--- return true; }
すべてのネストされたオブジェクトの作成プロセスを制御することを忘れないでください。すべてのネストしたオブジェクトの初期化に成功したら、操作の論理結果を呼び出し元に返します。
CNeuronCSCMOCLクラスのオブジェクトを初期化した後、フィードフォワードアルゴリズムの作成に移ります。このクラスの枠組みでは、OpenCLプログラム側の操作は実装しないことに注意してください。実装全体は、ネストされたオブジェクトメソッドの使用に基づいています。そのアルゴリズムはすでにOpenCL側に実装されています。このような状況では、ネストしたオブジェクトのメソッドと親クラスから継承したメソッドから、高レベルのアルゴリズムを構築すれば済みます。
feedForwardメソッドのパラメータには、呼び出し元のプログラムが前の層のオブジェクトへのポインタを提供します。
bool CNeuronCSCMOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL *inp = NeuronOCL; CNeuronBaseOCL *current = NULL;
メソッド本体では、ニューラル層オブジェクトへのポインタを格納するために2つの変数を宣言します。この段階で、呼び出し元のプログラムから受け取ったポインタをソースデータ変数に渡します。そして2番目の変数は空にしておきます。
次に、入力データの転置の必要性を確認します。必要であれば、この作業をおこないます。
if(b_NeedTranspose) { current = caTranspose.At(0); if(!current || !current.FeedForward(inp)) return false; inp = current; }
その後、入力時系列を、caConvolutions配列に保存されたポインタを持つ、異なるスケールの連続した畳み込み特徴量抽出層に通します。
int layers = caConvolutions.Total() - 1; for(int l = 0; l <= layers; l++) { current = caConvolutions.At(l); if(!current || !current.FeedForward(inp)) return false; inp = current; }
この配列の最初の層は、入力データ列のサイズを揃えるためのものです。抽出された特徴量を連結する際には、この結果は使用しません。
ここでは、畳み込み特徴量抽出層の上限を制限せずにアルゴリズムを構築しています。この場合、特徴量抽出層は最低の1層でも構まいません。そして、この場合に使える最も単純なアルゴリズムは、1つの特徴量配列をテンソルに逐次追加するループを作ることでしょう。しかし、この方法では同じデータを何度もコピーする可能性があります。これは、フィードフォワードパスの計算コストを大幅に増加させます。このような操作を最小化するために、特徴量抽出ブロック数に基づく分岐アルゴリズムを作成しました。
前述したように、少なくとも1つの特徴量抽出層がなければなりません。もしそれがなければ、呼び出し元のプログラムに誤差信号を負の結果という形で返します。
current = caMLP.At(0); if(!current) return false; switch(layers) { case 0: return false;
単一の特徴量抽出層を使用する場合、連結するものは何もありません。ご記憶の通り、今回のケースでは、クラスの初期化メソッドで、特徴量抽出層と連結層のデータバッファを再定義し、不要なコピー操作を減らすことができました。次の作戦に移るだけです。
case 1: break;
2層から4層の特徴量抽出層が存在するため、適切なデータ連結方法が選択されます。
case 2: if(!Concat(caConvOutputs.At(0), caConvOutputs.At(1), current.getOutput(), ia_Windows[1], 1, i_Variables * i_Count)) return false; break; case 3: if(!Concat(caConvOutputs.At(0), caConvOutputs.At(1), caConvOutputs.At(2), current.getOutput(), ia_Windows[1], ia_Windows[2], 1, i_Variables * i_Count)) return false; break; case 4: if(!Concat(caConvOutputs.At(0), caConvOutputs.At(1), caConvOutputs.At(2), caConvOutputs.At(3), current.getOutput(), ia_Windows[1], ia_Windows[2], ia_Windows[3], 1, i_Variables * i_Count)) return false;
このような層がさらにある場合は、最初の4つの特徴量抽出層を連結するが、その結果は一時的なデータ記憶バッファに書き込まれます。
default: if(!Concat(caConvOutputs.At(0), caConvOutputs.At(1), caConvOutputs.At(2), caConvOutputs.At(3), caTemp.At(0), ia_Windows[1], ia_Windows[2], ia_Windows[3], ia_Windows[4], i_Variables * i_Count)) return false; break; }
連結操作を実行するときは、caConvolutions配列から畳み込み層オブジェクトにアクセスするのではなく、その結果のバッファー、つまり動的配列caConvOutputsに慎重に保存したポインタに直接アクセスすることに注意してください。
次に、4層目の特徴量抽出から始めて3層ずつステップを踏むループを作ります。このループの本体では、まず一時バッファに格納されているデータウィンドウのサイズを計算します。
uint last_buf = 0; for(int i = 4; i < layers; i += 3) { uint buf_size = 0; for(int j = 1; j <= i; j++) buf_size += ia_Windows[j];
次に、上で与えられたものと同様の連結関数を選択するアルゴリズムを整理します。しかし、この場合、以前に収集されたデータを含む一時的なバッファは常に最初の位置にあり、抽出された特徴の次のバッチはそこに追加されます。
switch(layers - i) { case 1: if(!Concat(caTemp.At(last_buf), caConvOutputs.At(i), current.getOutput(), buf_size, 1, i_Variables * i_Count)) return false; break; case 2: if(!Concat(caTemp.At(last_buf), caConvOutputs.At(i), caConvOutputs.At(i + 1), current.getOutput(), buf_size, ia_Windows[i + 1], 1, i_Variables * i_Count)) return false; break; case 3: if(!Concat(caTemp.At(last_buf), caConvOutputs.At(i), caConvOutputs.At(i + 1), caConvOutputs.At(i + 2), current.getOutput(), buf_size, ia_Windows[i + 1], ia_Windows[i + 2], 1, i_Variables * i_Count)) return false; break; default: if(!Concat(caTemp.At(last_buf), caConvOutputs.At(i), caConvOutputs.At(i + 1), caConvOutputs.At(i + 2), caTemp.At((last_buf + 1) % 2), buf_size, ia_Windows[i + 1], ia_Windows[i + 2], ia_Windows[i + 3], i_Variables * i_Count)) return false; break; } last_buf = (last_buf + 1) % 2; }
最後の特徴層(1~3)を追加する場合、操作の結果はデータ連結層バッファに保存されることに注意してください。それ以外の場合は、一時的なデータ保存に別のバッファを使用します。ループの各反復では、データの破損や損失を防ぐために、バッファが交互に入れ替わります。
すべての特徴を1つのテンソルに連結した後は、結果のテンソルのサイズを調整するだけですみます。
inp = current; current = caMLP.At(1); if(!current || !current.FeedForward(inp)) return false;
必要であれば、入力データの次元に転置します。
if(b_NeedTranspose) { inp = current; current = caTranspose.At(1); if(!current || !current.FeedForward(inp)) return false; } //--- return true; }
初期化メソッドの中で、データバッファの置換を整理したことを思い出してください。したがって、操作の結果は「自動的に」クラスの対応する継承されたバッファにコピーされます。
フィードフォワードパスメソッドを構築した後、バックプロパゲーションアルゴリズムの実装に移ります。まず、全体の結果に対する影響力に応じて、誤差勾配をすべてのオブジェクトに伝播するメソッドを作成します(calcInputGradients)。いつものように、このメソッドのパラメータには、前のニューラル層のオブジェクトへのポインタを受け取ります。この場合、誤差勾配に対応する分け前を渡す必要があります。
bool CNeuronCSCMOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!prevLayer) return false;
メソッド本体では、受け取ったポインタの妥当性を即座に確認します。その後、2つのニューラル層のローカルポインタを作成します。
CNeuronBaseOCL *current = caMLP.At(0); CNeuronBaseOCL *next = caMLP.At(1);
誤差勾配を分配する過程では、フィードフォワードパスアルゴリズムに従って動くが、その方向は逆であることを思い出してください。したがって、もちろんそのような操作が必要であれば、まずデータ移調層を通して勾配を伝播させます。
if(b_NeedTranspose) { if(!next.calcHiddenGradients(caTranspose.At(1))) return false; }
そして、その誤差勾配を、抽出された異なるスケールの特徴の連結層に与えます。
if(!current.calcHiddenGradients(next.AsObject())) return false; next = current;
その後、誤差勾配を対応する特徴量抽出層に分配する必要があります。
特徴量抽出層が1つという特殊なケースを忘れてはなりません。ここでは、活性化関数の微分によって誤差勾配を調整するだけですみます。
int layers = caConvGradients.Total(); if(layers == 1) { next = caConvolutions.At(1); if(next.Activation() != None) { if(!DeActivation(next.getOutput(), next.getGradient(), next.getGradient(), next.Activation())) return false; } }
一般的には、まず最後の特徴量抽出層の誤差勾配を分離し、活性化関数の微分で補正します。
else { int prev_window = 0; for(int i = 1; i < layers; i++) prev_window += int(ia_Windows[i]); if(!DeConcat(caTemp.At(0), caConvGradients.At(layers - 1), next.getGradient(), prev_window, 1, i_Variables * i_Count)) return false; next = caConvolutions.At(layers); int current_buf = 0;
その後、特徴量抽出層の逆ループを作成します。このループの本体では、まず後続の特徴量抽出層から誤差勾配を求めます。
for(int l = layers; l > 1; l--) { current = caConvolutions.At(l - 1); if(!current.calcHiddenGradients(next.AsObject())) return false;
次に、連結された特徴テンソルの誤差勾配のバッファから、分析された層の割合を抽出します。
int window = int(ia_Windows[l - 1]); prev_window -= window; if(!DeConcat(caTemp.At((current_buf + 1) % 2), caTemp.At(2), caTemp.At(current_buf), prev_window, window, i_Variables * i_Count)) return false;
活性化関数の微分を調整します。
if(current.Activation() != None) { if(!DeActivation(current.getOutput(), caTemp.At(2), caTemp.At(2), current.Activation())) return false; }
そして、2つのデータストリームからの誤差勾配を合計します。
if(!SumAndNormilize(current.getGradient(), caTemp.At(2), current.getGradient(), 1, false, 0, 0, 0, 1)) return false; next = current; current_buf = (current_buf + 1) % 2; } }
その後、ループの次の反復に移ります。
こうすることで、誤差勾配をすべての特徴量抽出層に分散させることができます。そして、その誤差勾配を入力データサイズ整列層に渡します。
current = caConvolutions.At(0); if(!current.calcHiddenGradients(next.AsObject())) return false; next = current;
必要であれば、誤差勾配をデータ転置層を通して伝搬させます。
if(b_NeedTranspose) { current = caTranspose.At(0); if(!current.calcHiddenGradients(next.AsObject())) return false; next = current; }
メソッド操作の最後に、誤差勾配を、このメソッドのパラメータで受け取ったポインタの前のニューラル層に渡します。
if(!prevLayer.calcHiddenGradients(next.AsObject())) return false; //--- return true; }
ご存知のように、誤差の勾配伝搬はモデル訓練の目的ではありません。あくまでも、モデルパラメータの調整の方向性と範囲を決定するための手段です。したがって、誤差勾配をうまく伝搬させた後は、その動作の全体的な誤差を最小化するように、モデルのパラメータを調整しなければなりません。この機能はupdateInputWeightsメソッドに実装されています。
bool CNeuronCSCMOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { CObject *prev = (b_NeedTranspose ? caTranspose.At(0) : NeuronOCL); CNeuronBaseOCL *current = NULL;
メソッドのパラメータには、前回と同様に、前のニューラル層のオブジェクトへのポインタを受け取ります。しかしこの場合、受信したインデックスの関連性は確認しません。ローカル変数に保存するだけです。しかし、ここにはニュアンスがあります。データ移調層にはパラメータは含まれていません。そのため、モデルパラメータ調整メソッドは呼び出しません。しかし、入力サイズの整列層については、入力データの転置が必要かどうかを示すb_NeedTransposeパラメータに応じて、前の層を選択します。
次に、元のシーケンスと特徴量抽出ブロックのサイズを調整する層を含む、畳み込み層のパラメータを逐次調整するループを構成します。
for(int i = 0; i < caConvolutions.Total(); i++) { current = caConvolutions.At(1); if(!current || !current.UpdateInputWeights(prev) ) return false; prev = current; }
次に、結果のサイズを揃える層のパラメータを調整する必要があります。
current = caMLP.At(1); if(!current || !current.UpdateInputWeights(caMLP.At(0)) ) return false; //--- return true; }
CNeuronCSCMOCLクラスの他のネストされたオブジェクトには、学習可能なパラメータは含まれていません。
この時点で、CSCMモジュールの主要アルゴリズムの実装は完了したとみなすことができます。もちろん、補助メソッドアルゴリズムを追加実装しなければ、このクラスの機能は完全ではありません。しかし、記事の分量を減らすため、ここではそれらの説明は割愛します。このクラスのすべてのメソッドの完全なコードは添付ファイルにあります。添付ファイルには、記事で使用されているすべてのプログラムの完全なコードも含まれています。次のモジュールであるSkip-PAMのアルゴリズムの構築に移ります。
2.2Skip-PAMモジュールアルゴリズムの実装
私たちがやらなければならない仕事の2番目の部分は、ピラミッド型アテンションアルゴリズムを実装することです。MSFformer法の著者の革新的な点は、異なる区間を持つ特徴木にアテンションアルゴリズムを適用したことです。この手法の著者は、1つのアテンションレベル内で特徴間の固定ステップを使用しています。私たちの実装では、少し違った進め方をします。それぞれのアテンションピラミッドが、それぞれのアテンションレベルでどの特徴を分析するか、モデルに自分で学習させたらどうでしょうか。期待できそうです。また、私見ではありますが、実装は明白でシンプルです。それぞれのアテンションレベルの前にS3層を追加するだけです。
CNeuronSPyrAttentionOCLクラス内にSkip-PAMモジュール実装のアルゴリズムを構築します。その構造を以下に示します。
class CNeuronSPyrAttentionOCL : public CNeuronBaseOCL { protected: uint iWindowIn; uint iWindowKey; uint iHeads; uint iHeadsKV; uint iCount; uint iPAMLayers; //--- CArrayObj caS3; CArrayObj caQuery; CArrayObj caKV; CArrayInt caScore; CArrayObj caAttentionOut; CArrayObj caW0; CNeuronConvOCL cFF1; CNeuronConvOCL cFF2; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool AttentionOut(CBufferFloat *q, CBufferFloat *kv, int scores, CBufferFloat *out, int window); virtual bool AttentionInsideGradients(CBufferFloat *q, CBufferFloat *q_g, CBufferFloat *kv, CBufferFloat *kv_g, int scores, CBufferFloat *gradient); //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual void ArraySetOpenCL(CArrayObj *array, COpenCLMy *obj); public: CNeuronSPyrAttentionOCL(void) {}; ~CNeuronSPyrAttentionOCL(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint window_key, uint heads, uint heads_kv, uint units_count, uint pam_layers, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronSPyrAttentionMLKV; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
提示された構造からわかるように、新しいクラスはさらにダイナミックな配列とパラメータを含んでいます。その名前は、他のアテンションクラスのオブジェクトと同じです。お分かりのように、これは故意にやっています。実装の過程で、作成したオブジェクトや変数の使い方に慣れていきます。
前回と同様に、オブジェクトのInit初期化メソッドから新しいクラスのアルゴリズムの考察を始めます。
bool CNeuronSPyrAttentionOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint window_key, uint heads, uint heads_kv, uint units_count, uint pam_layers, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_in * units_count, optimization_type, batch)) return false;
メソッドのパラメータには、作成されるオブジェクトのアーキテクチャを決定する主な定数を受け取ります。メソッド本体では、親クラスの関連するメソッドを呼び出す。このメソッドでは、最低限必要な制御と継承オブジェクトの初期化が実装されています。
また、この手法の枠組みでは、全体的なマルチモーダルなタイムシーケンスの中で、個々のタイムステップを分析することに留意すべきです。しかし、この場合、Skip-PAMモジュールに入力される元のデータをマルチモーダル時系列と呼ぶことは難しいでしょう。なぜなら、前のCSCMモジュールの結果は、時系列ではなく、異なるデータスケールの抽出された特徴の集合を表しているからです。
親クラスオブジェクトの初期化メソッドの実行に成功したら、得られた定数をローカル変数に保存します。
iWindowIn = window_in; iWindowKey = MathMax(window_key, 1); iHeads = MathMax(heads, 1); iHeadsKV = MathMax(heads_kv, 1); iCount = units_count; iPAMLayers = MathMax(pam_layers, 2);
新しいパラメータiPAMLayersの出現に注目してください。これはピラミッド型アテンションのレベル数を決定します。残りのパラメータは、先に説明したアテンションメソッドと同じ機能を意味します。また、MLKVメソッドで考慮されたように、iHeadsKVパラメータは、Queryアテンションヘッドの次元とは異なるKey-Valueヘッドの数を使用する可能性のために保持しました。
そして、動的配列をクリアします。
caS3.Clear(); caQuery.Clear(); caKV.Clear(); caScore.Clear(); caAttentionOut.Clear(); caW0.Clear();
必要なローカル変数を作成しましょう。
CNeuronBaseOCL *base = NULL; CNeuronConvOCL *conv = NULL; CNeuronS3 *s3 = NULL;
ピラミッド型アテンションブロックオブジェクトの初期化ループを作成します。ご想像の通り、ループの反復回数は、作成されたアテンションレベルの数に等しくなります。
for(uint l = 0; l < iPAMLayers; l++) { //--- S3 s3 = new CNeuronS3(); if(!s3) return false; if(!s3.Init(0, l, OpenCL, iWindowIn, iCount, optimization, iBatch) || !caS3.Add(s3)) return false; s3.SetActivationFunction(None);
ループの本体では、まずS3層を作成し、その中で解析された配列の順列を整理します。この場合、元のマルチモーダルシーケンスの分析パラメータ数に等しいウィンドウを持つ1つのデータ混合層のみを使用します。
次に、Query、Key、Valueのエンティティ生成オブジェクトを作成します。エンティティを形成する場合、1つのINPUTデータオブジェクトを使用しますが、異なるアテンションヘッドパラメータを使用することに注意してください。
//--- Query conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, 0, OpenCL, iWindowIn, iWindowIn, iWindowKey*iHeads, iCount, optimization, iBatch) || !caQuery.Add(conv)) { delete conv; return false; } conv.SetActivationFunction(None); //--- KV conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, 0, OpenCL, iWindowIn, iWindowIn, 2*iWindowKey*iHeadsKV, iCount, optimization, iBatch) || !caKV.Add(conv)) { delete conv; return false; } conv.SetActivationFunction(None);
OpenCLのコンテキスト側だけで依存係数の行列を作成します。ここでは、バッファへのポインタを保存するだけです。
//--- Score int temp = OpenCL.AddBuffer(sizeof(float) * iCount * iCount * iHeads, CL_MEM_READ_WRITE); if(temp < 0) return false; if(!caScore.Add(temp)) return false;
次のステップでは、多頭アテンションの結果を記録する層を作成します。
//--- MH Attention Out base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, 0, OpenCL, iWindowKey * iHeadsKV * iCount, optimization, iBatch) || !caAttentionOut.Add(conv)) { delete base; return false; } base.SetActivationFunction(None);
ループの反復は、入力データレベルまで次元を下げる層によって完了します。
//--- W0 conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, 0, OpenCL, iWindowKey * iHeadsKV, iWindowKey * iHeadsKV, iWindowIn, iCount, optimization, iBatch) || !caW0.Add(conv)) { delete conv; return false; } conv.SetActivationFunction(None); }
ピラミッド型のアテンションレベルを作る反復がすべて成功したら、層を追加します。この層のバッファには、ピラミッド型アテンションブロックの結果と入力データの和を記録します。
//--- Residual base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, 0, OpenCL, iWindowIn * iCount, optimization, iBatch) || !caW0.Add(conv)) { delete base; return false; } base.SetActivationFunction(None);
あとはFeedForwardブロックの層を初期化するだけです。
//--- FeedForward if(!cFF1.Init(0, 0, OpenCL, iWindowIn, iWindowIn, 4 * iWindowIn, iCount, optimization, iBatch)) return false; cFF1.SetActivationFunction(LReLU); if(!cFF2.Init(0, 0, OpenCL, 4 * iWindowIn, 4 * iWindowIn, iWindowIn, iCount, optimization, iBatch)) return false; cFF2.SetActivationFunction(None); if(!SetGradient(cFF2.getGradient())) return false;
メソッドの最後に、層の活性化関数を強制的に削除します。
SetActivationFunction(None); //--- return true; }
クラスのオブジェクトを初期化した後、フィードフォワードパスのアルゴリズムの実装に移ります。ここで、OpenCLプログラム側で少し準備作業をする必要があります。MH2PyrAttentionOutカーネルは、基本的にMH2AttentionOutカーネルを修正したものです。
__kernel void MH2PyrAttentionOut(__global float *q, __global float *kv, __global float *score, __global float *out, const int dimension, const int heads_kv, const int window ) { //--- init const int q_id = get_global_id(0); const int k = get_global_id(1); const int h = get_global_id(2); const int qunits = get_global_size(0); const int kunits = get_global_size(1); const int heads = get_global_size(2);
カーネル名に加えて、アテンションウィンドウのための追加windowパラメータが存在することで、以前のものと異なっています。ここでは、3次元のタスク空間でカーネルを呼び出すことを計画しています。いつものように、カーネルの最初に、タスク空間のすべての次元でスレッドを特定します。
次に、必要な定数を計算します。
const int h_kv = h % heads_kv; const int shift_q = dimension * (q_id * heads + h); const int shift_k = dimension * (2 * heads_kv * k + h_kv); const int shift_v = dimension * (2 * heads_kv * k + heads_kv + h_kv); const int shift_s = kunits * (q_id * heads + h) + k; const uint ls = min((uint)get_local_size(1), (uint)LOCAL_ARRAY_SIZE); const int delta_win = (window + 1) / 2; float koef = sqrt((float)dimension); if(koef < 1) koef = 1;
また、中間値を記録するためのローカル配列も初期化します。
__local float temp[LOCAL_ARRAY_SIZE];
まず、シーケンスの各要素の依存係数を決定する必要があります。ご存知のように、アテンションブロックでは、依存係数はSoftMax関数によって正規化されます。そのために、まず依存係数の指数の和を計算します。
最初の段階では、各スレッドは指数値の和の一部をローカルデータ配列の対応する要素に集めます。依存係数は、現在の要素のアテンションウィンドウ内でのみ計算します。その他の要素については、依存係数は「0」です。
//--- sum of exp uint count = 0; if(k < ls) do { if((count * ls) < (kunits - k)) { float sum = 0; if(abs(count * ls + k - q_id) <= delta_win) { for(int d = 0; d < dimension; d++) sum = q[shift_q + d] * kv[shift_k + d]; sum = exp(sum / koef); if(isnan(sum)) sum = 0; } temp[k] = (count > 0 ? temp[k] : 0) + sum; } count++; } while((count * ls + k) < kunits); barrier(CLK_LOCAL_MEM_FENCE);
ローカルグループのスレッドを同期させるために、バリアを使用します。
次のステップでは、ローカル配列の全要素の値の合計を収集する必要があります。そのためにもう1つループを作り、反復ごとにローカルスレッドを同期させます。ここでは、各スレッドが同じ数のバリアにアクセスするように注意する必要があります。そうしないと、個々のスレッドが「フリーズ」してしまうかもしれません。
count = min(ls, (uint)kunits); //--- do { count = (count + 1) / 2; if(k < ls) temp[k] += (k < count && (k + count) < kunits ? temp[k + count] : 0); if(k + count < ls) temp[k + count] = 0; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
指数の和を求めた後、正規化された依存係数を計算することができます。依存関係はアテンションウィンドウ内にしか存在しないことを忘れないでください。
//--- score float sum = temp[0]; float sc = 0; if(sum != 0 && abs(k - q_id) <= delta_win) { for(int d = 0; d < dimension; d++) sc = q[shift_q + d] * kv[shift_k + d]; sc = exp(sc / koef) / sum; if(isnan(sc)) sc = 0; } score[shift_s] = sc; barrier(CLK_LOCAL_MEM_FENCE);
もちろん、依存係数を計算した後はローカルスレッドを同期させます。
次に、依存関係を考慮して要素の値を決定する必要があります。ここでは、依存関係の指数値の合計を求めたときと同じアルゴリズムを、並列スレッドでの値の合計に使用します。まず、ローカル配列の要素にある個々の値の合計を集めます。
//--- out for(int d = 0; d < dimension; d++) { uint count = 0; if(k < ls) do { if((count * ls) < (kunits - k)) { float sum = 0; if(abs(count * ls + k - q_id) <= delta_win) { sum = kv[shift_v + d] * (count == 0 ? sc : score[shift_s + count * ls]); if(isnan(sum)) sum = 0; } temp[k] = (count > 0 ? temp[k] : 0) + sum; } count++; } while((count * ls + k) < kunits); barrier(CLK_LOCAL_MEM_FENCE);
そして、配列要素の値の合計を収集します。
//--- count = min(ls, (uint)kunits); do { count = (count + 1) / 2; if(k < ls) temp[k] += (k < count && (k + count) < kunits ? temp[k + count] : 0); if(k + count < ls) temp[k + count] = 0; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1); //--- out[shift_q + d] = temp[0]; } }
結果の合計を結果バッファの対応する要素に保存します。
こうして、与えられたウィンドウの中に新しいアテンションカーネルを作り出しました。アテンションウィンドウの外にある要素については、依存係数を「0」に設定していることに注意してください。この単純な動きによって、先に作成したMH2AttentionInsideGradientsカーネルを使って、バックプロパゲーションパスの中で誤差勾配を分散させることができます。
指定したカーネルをメインプログラム側の実行キューに入れるために、それぞれAttentionOutメソッドとAttentionInsideGradientsメソッドを作りました。そのアルゴリズムは、この連載の以前の記事で取り上げた同様の方法と大差はないので、今は詳しく触れないことにします。コードは添付ファイルにあります。次に、フィードフォワードメソッドのアルゴリズムの実装に移ります。
パラメータにおいて、フォワードパスメソッドは、入力データを含む前のニューラル層のオブジェクトへのポインタを受け取ります。
bool CNeuronSPyrAttentionOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL *prev = NeuronOCL; CNeuronBaseOCL *current = NULL; CBufferFloat *q = NULL; CBufferFloat *kv = NULL;
メソッド本体では、ネストされたニューラル層の処理オブジェクトへのポインタを格納するために、いくつかのローカル変数を作成します。
次に、アテンションレベルのループを作ります。ループの本体では、まずソースデータをシャッフルします。
for(uint l = 0; l < iPAMLayers; l++) { //--- Mix current = caS3.At(l); if(!current || !current.FeedForward(prev.AsObject()) ) return false; prev = current;
その後、マルチヘッドアテンションアルゴリズムを実装するために、Query、Key、Valueの各エンティティのテンソルを生成します。
//--- Query current = caQuery.At(l); if(!current || !current.FeedForward(prev.AsObject()) ) return false; q = current.getOutput(); //--- Key and Value current = caKV.At(l); if(!current || !current.FeedForward(prev.AsObject()) ) return false; kv = current.getOutput();
このレベルのアテンションカーネルアルゴリズムを実行します。
//--- PAM current = caAttentionOut.At(l); if(!current || !AttentionOut(q, kv, caScore.At(l), current.getOutput(), iPAMLayers - l)) return false; prev = current;
各レベルで、アテンションウィンドウを小さくすることで、ピラミッド効果を生み出しています。これにはiPAMLayers - lという差分を使います。
ループの繰り返し終了時に、マルチヘッドアテンション結果テンソルのサイズを入力データサイズまで縮小します。
//--- W0 current = caW0.At(l); if(!current || !current.FeedForward(prev.AsObject()) ) return false; prev = current; }
全レベルのピラミッド型アテンションの完了後、アテンションの結果を入力データと合計し、正規化します。
//--- Residual current = caW0.At(iPAMLayers); if(!SumAndNormilize(NeuronOCL.getOutput(), prev.getOutput(), current.getOutput(), iWindowIn, true)) return false;
そして、ピラミッド型のアテンション層の最後のものは、バニラTransformerと同様のフィードフォワードブロックです。
//---FeedForward if(!cFF1.FeedForward(current.AsObject()) || !cFF2.FeedForward(cFF1.AsObject()) ) return false;
次に、2つのスレッドのデータを合計し、正規化します。
//--- Residual if(!SumAndNormilize(current.getOutput(), cFF2.getOutput(), getOutput(), iWindowIn, true)) return false; //--- return true; }
操作の実行を制御することを忘れないでください。メソッドの最後に、操作の論理結果を呼び出し元に返します。
いつものように、フィードフォワードパスを実装した後、バックプロパゲーションパスアルゴリズムの構築に移ります。このアルゴリズムは、誤差勾配の伝播とモデルパラメータの最適化の2段階からなります。
誤差勾配の伝搬はcalcInputGradientsメソッドで実装されています。
bool CNeuronSPyrAttentionOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!prevLayer) return false;
このメソッドのパラメータには、前のニューラル層のオブジェクトへのポインタを受け取ります。この層のバッファには、入力データが全体の結果に与える影響に応じた誤差勾配を転送しなければなりません。
次に、内部オブジェクトへのポインタを一時的に格納するローカル変数をいくつか作ります。
CNeuronBaseOCL *next = NULL; CNeuronBaseOCL *current = NULL; CNeuronBaseOCL *q = NULL; CNeuronBaseOCL *kv = NULL;
誤差勾配の分配は、フィードフォワードパスの操作に従っておこなわれるが、順序は逆です。まず、FeedForwardブロックを通して誤差勾配を伝播させます。
//--- FeedForward current = caW0.At(iPAMLayers); if(!current || !cFF1.calcHiddenGradients(cFF2.AsObject()) || !current.calcHiddenGradients(cFF1.AsObject()) ) return false; next = current;
次に、2つの操作スレッドからの誤差勾配を加える必要があります。
//--- Residual current = caW0.At(iPAMLayers - 1); if(!SumAndNormilize(getGradient(), next.getGradient(), current.getGradient(), iWindowIn, false)) return false; CBufferFloat *residual = next.getGradient(); next = current;
その後、逐次誤差勾配降下法でアテンションレベルを逆ループさせます。
for(int l = int(iPAMLayers - 1); l >= 0; l--) { //--- W0 current = caAttentionOut.At(l); if(!current || !current.calcHiddenGradients(next.AsObject()) ) return false;
ループの本体では、まずアテンションヘッド全体に誤差勾配を伝播させます。そして、それをQuery、Key、Valueの各エンティティのレベルまで伝搬させます。
//--- MH Attention q = caQuery.At(l); kv = caKV.At(l); if(!q || !kv || !AttentionInsideGradients(q.getOutput(), q.getGradient(), kv.getOutput(), kv.getGradient(), caScore.At(l), current.getGradient()) ) return false;
次のステップは、誤差勾配をデータシャッフリング層に伝搬させることです。ここでは、QueryとKey-Valueの2つのスレッドからデータを結合する必要があります。そのために、まずQueryから誤差勾配を取得し、それを一時的なバッファに転送します。
//--- Query current = caS3.At(l); if(!current || !current.calcHiddenGradients(q.AsObject()) || !Concat(current.getGradient(), current.getGradient(), residual, iWindowIn,0, iCount) ) return false;
次に、Key-Valueから勾配をとり、2つのデータスレッドの結果を合計します。
//--- Key and Value if(!current || !current.calcHiddenGradients(kv.AsObject()) || !SumAndNormilize(current.getGradient(), residual, current.getGradient(), iWindowIn, false) ) return false; next = current;
誤差の勾配をデータシャフリング層に伝搬させ、ループの次の反復に移ります。
//--- S3 current = (l == 0 ? prevLayer : caW0.At(l - 1)); if(!current || !current.calcHiddenGradients(next.AsObject()) ) return false; next = current; }
メソッド操作の最後には、2つのスレッドからの誤差勾配を組み合わせれば済みます。ここではまず、残差接続の誤差勾配を前の層の活性化関数の導関数で調整します。誤差勾配が直接層レベルまで下降すると、活性化関数に対する誤差勾配の調整が自動的におこなわれます。
current = caW0.At(iPAMLayers - 1); if(!DeActivation(prevLayer.getOutput(), current.getGradient(), residual, prevLayer.Activation()) || !SumAndNormilize(prevLayer.getGradient(), residual, prevLayer.getGradient(), iWindowIn, false) ) return false; //--- return true; }
そして、両スレッドからの誤差勾配を合計します。
誤差勾配を分布させた後、モデルパラメータの調整に移ります。この機能をupdateInputWeightsメソッドに実装します。このメソッドのアルゴリズムは非常に簡単で、学習可能なパラメータを含むネストしたオブジェクトの同名メソッドを順次呼び出します。
bool CNeuronSPyrAttentionOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL *prev = NeuronOCL; CNeuronBaseOCL *current = NULL; for(uint l = 0; l < iPAMLayers; l++) { //--- S3 current = caS3.At(l); if(!current || !current.UpdateInputWeights(prev) ) return false; //--- Query prev = current; current = caQuery.At(l); if(!current || !current.UpdateInputWeights(prev) ) return false; //--- Key and Value current = caKV.At(l); if(!current || !current.UpdateInputWeights(prev) ) return false; //--- W0 prev = caAttentionOut.At(l); current = caW0.At(l); if(!current || !current.UpdateInputWeights(prev) ) return false; prev = current; } //--- FeedForward prev = caW0.At(iPAMLayers); if(!cFF1.UpdateInputWeights(prev) || !cFF2.UpdateInputWeights(cFF1.AsObject()) ) return false; //--- return true; }
メソッドのすべての操作の実行プロセスを制御し、実行された操作の論理結果を呼び出し元に返すようにします。
これで、MSFformer手法の提案されたアプローチの実装に関する研究は終わりです。作成したクラスとそのメソッドの完全なコードは添付ファイルでご覧いただけます。
結論
この記事では、時系列予測のための、もう1つの興味深く有望な手法を検討しました。MSFformer (Multi-Scale Feature Transformer)です。この手法は、論文「Time Series Prediction Based on Multi-Scale Feature Extraction」で初めて発表されました。提案アルゴリズムは、改良されたピラミッド型アテンションアーキテクチャと、入力データからの異なるスケールのマルチスケール特徴量抽出への新しいアプローチに基づいています。
実用的な部分では、提案アルゴリズムの2つの主要モジュールを実装しました。次回はその結果について見ていきたいと思います。
参照文献
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | コレクションEAの例 |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法による事例収集のためのEA |
| 3 | Study.mq5 | EA | モデル訓練EA |
| 4 | StudyEncoder.mq5 | EA | エンコーダー訓練EA |
| 5 | Test.mq5 | EA | モデルをテストするEA |
| 6 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 7 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 8 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/15156
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

 スマートマネーコンセプト(オーダーブロック)とフィボナッチ指標を組み合わせた最適な取引エントリー方法
スマートマネーコンセプト(オーダーブロック)とフィボナッチ指標を組み合わせた最適な取引エントリー方法
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索