
神经网络变得简单(第 96 部分):多尺度特征提取(MSFformer)

概述
时间序列数据在现实世界中广泛存在,于包括金融在内的各个领域扮演着重要角色。该数据代表在不同时间点收集到的观测值序列。深度时间序列分析和建模,令研究人员能够预测未来的趋势和形态,并将其用于决策制定过程。
近年来,许多研究人员将精力集中在运用深度学习模型来研究时间序列。这些方法已被证明,在捕获非线性关系、及处理长期依赖关系方面很有效,这对于复杂系统建模尤其实用。然而,尽管成就斐然,但如何有效地提取和集成长期依赖关系和短期特征仍有问题。明白并正确组合这两种类型的依赖关系,对于构建准确可靠的预测模型至关重要。
解决该问题的选项之一在论文《基于多尺度特征提取进行时间序列预测》 中提出。该论文提出了一种时间序列预测模型 MSFformer(多尺度特征变换器),其基于改进的金字塔关注度架构。该模型设计用于多尺度特征的高效提取和集成。
该方法作者强调了以下 MSFformer 创新:
- 引入 Skip-PAM 机制,令模型能够有效地捕获较长时间序列中的长期和短期特征。
- 改进了创建金字塔数据结构的 CSCM 模块。
MSFformer 的作者展示了依据三个时间序列数据集的实验结果,其验证了所提议模型的卓越性能。所提议机制令 MSFformer 模型能够更准确、更高效地处理复杂的时间序列数据,从而确保较高的预测准确性、及可靠性。
1. MSFformer 算法
MSFformer 模型作者提出了一种创新的不同时间间隔的金字塔关注度机制架构,其为他们方法的底线。此外,为了在输入数据中构造多级时态信息,他们在大尺度构造模块 CSCM(粗尺度构造模块)中采用了特征卷积。这允许他们在更粗略的级别上提取时态信息。
CSCM 模块构造了所分析时间序列的特征树。于此,输入首先通过一个全连接层,以便将特征维度转换为固定大小。然后实用若干顺序的、专门设计的 FCNN 特征卷积模块。
在 FCNN 模块中,首先使用给定的交叉步长从输入序列中提取数据来形成特征向量。然后,这些向量被组合起来。组合后的向量随即交予卷积运算。作者对 FCNN 模块的可视化如下所示。
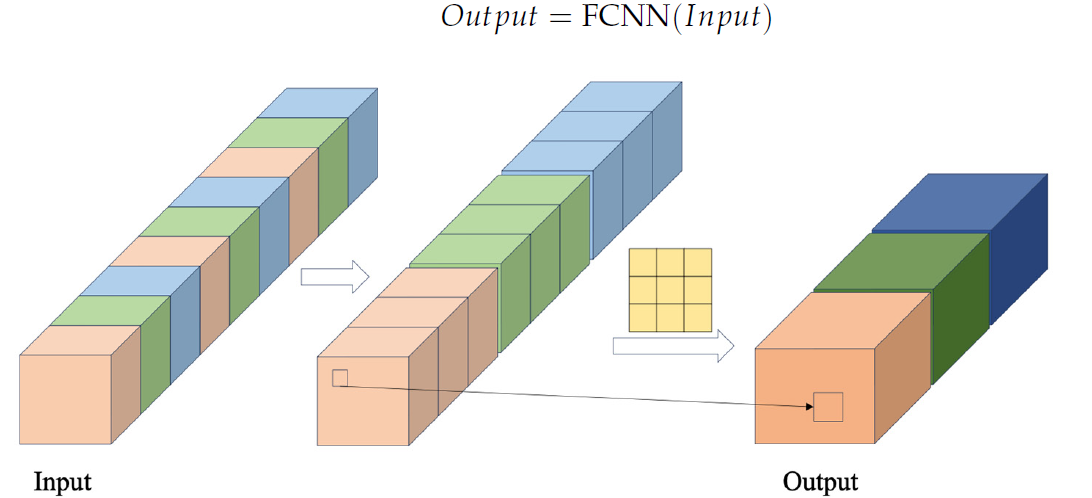
作者提出的 CSCM 模块用到了若干个连续的 FCNN 模块。它们中的每一个都使用前一个模块的结果作为输入,提取更大尺度的特征。
以这种方式获得的不同尺度的特征,被组合到一个向量里,其大小通过线性层降低到输入数据的尺度。
作者对 CSCM 模块的可视化如下所示。
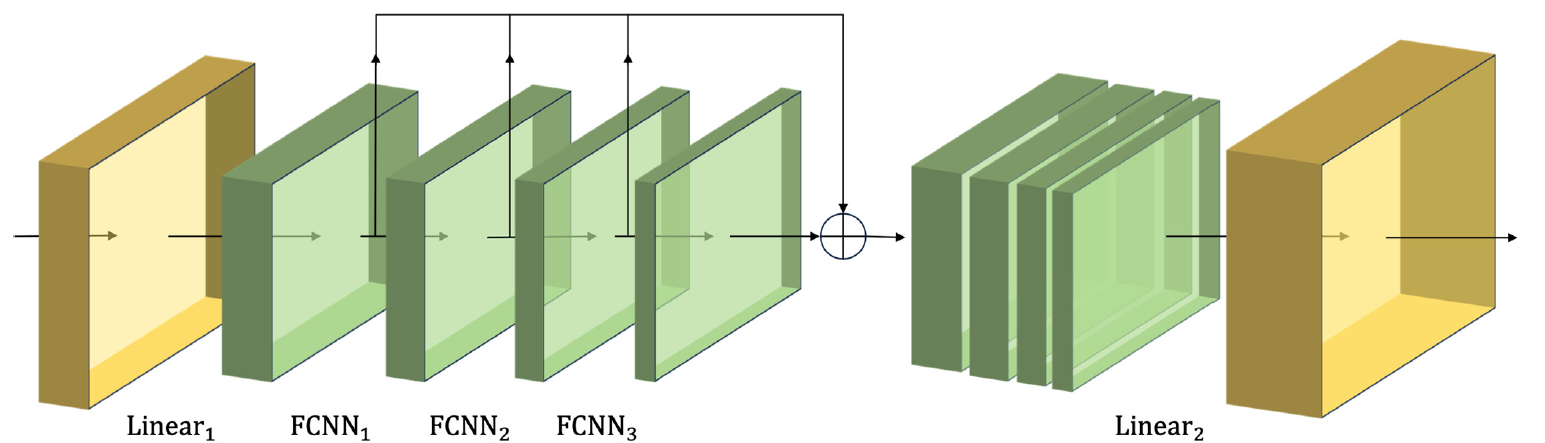
经由此类 CSCM 传递所分析时间序列数据,我们可以获得有关在不同粒度级别特征的时态信息。我们通过堆叠 FCNN 层来构建一个特征金字塔树。这允许我们在多个层面上理解数据,并为实现创新的金字塔关注度结构 Skip-PAM(跳跃金字塔关注度模块)提供坚实的基础。
Skip-PAM 的主要思路是按不同的时间间隔处理输入数据,这允许模型捕获不同粒度级的时间依赖关系。在较低级别,该模型也许侧重于短期、详细的形态。更高级别则能够捕捉到更多的宏观趋势、和周期性。所提议 Skip-PAM 更多关注周期性的依赖关系,譬如每周一、或每月初。这种多尺度方式令模型能够捕获不同级别的各种时态关系。
Skip-PAM 通过据时间特征树上构建的关注度机制,在多个尺度的时间序列中提取信息。该过程涉及尺度内和尺度间连接。尺度内连接涉及在同一层中的节点与其相邻节点之间执行关注度计算。尺度间连接涉及节点与其父节点之间的关注度计算。
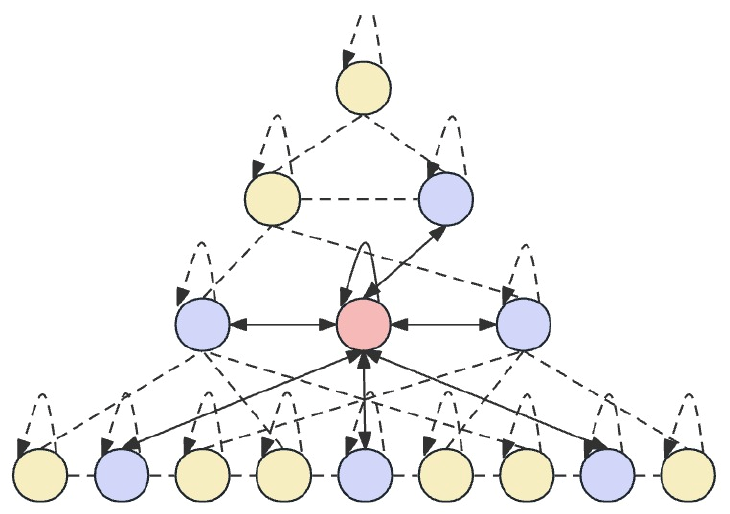
通过这种金字塔式关注度机制 Skip-PAM,结合 CSCM 中的多尺度特征卷积,形成了一个强大的特征提取网络,可以适应不同时间尺度的动态变化,无论是短期波动、还是长期演变。
该方法作者将上述两个模块组合成一个强大的 MSFformer 模型。其原始可视化如下所示。
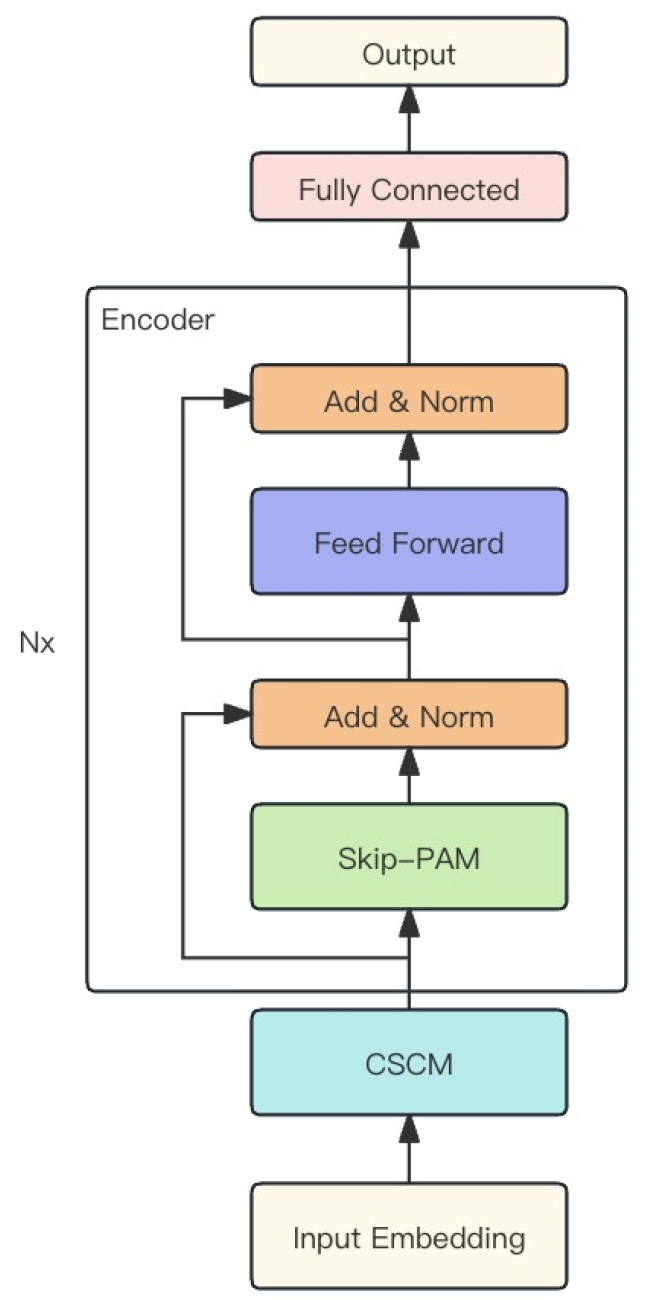
2. 利用 MQL5 实现
在研究了 MSFformer 方法的理论层面之后,我们转到本文的实践部分,其中我们利用 MQL5 实现我们对所提议方式的愿景。
如上所述,提议的 MSFformer 方法基于 2 个模块:CSCM 和 Skip-PAM。我们将在本文的框架内实现它们。还有很多工作要做。我们依照正在实现的模块将其分为 2 个部分。
2.1. 构建 CSCM 模块
我们从构建 CSCM 模块开始。为了实现该模块架构,我们将创建 CNeuronCSCMOCL 类,其会继承神经层基类 CNeuronBaseOCL 的主要功能。新类的结构如下所示。
class CNeuronCSCMOCL : public CNeuronBaseOCL { protected: uint i_Count; uint i_Variables; bool b_NeedTranspose; //--- CArrayInt ia_Windows; CArrayObj caTranspose; CArrayObj caConvolutions; CArrayObj caMLP; CArrayObj caTemp; CArrayObj caConvOutputs; CArrayObj caConvGradients; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronCSCMOCL(void) {}; ~CNeuronCSCMOCL(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint &windows[], uint variables, uint inputs_count, bool need_transpose, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronCSCMOCL; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
所呈现的 CNeuronCSCMOCL 类结构具有一组相当标准的可重写方法、及大量动态数组,这将有助于我们组织多尺度特征提取结构。动态数组及所声明变量的用途,将在方法实现过程中加以解释。
该类的所有对象都声明为静态。这就允许我们将类的构造函数和析构函数“留空”。所有嵌套对象和变量都在 Init 方法中初始化。
如常,在 Init 方法参数中,我们获得基本常量,这些常量令我们唯一地确定正在创建的对象架构。
为了给用户提供灵活判定特征提取层的数量、及卷积窗口的大小,我们使用了动态数组 windows。数组中的元素数量表示要创建的 FCNN 特征提取模块的数量。每个元素值表示相应模块的卷积窗口的大小。
多维输入时间序列中的幺正时间序列的数量、及原始序列的大小分别在 variables 和 inputs_count 参数中指定。
此外,我们将添加一个逻辑变量 need_transpose,其指示在特征提取之前需要转置输入。
bool CNeuronCSCMOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint &windows[], uint variables, uint inputs_count, bool need_transpose, ENUM_OPTIMIZATION optimization_type, uint batch) { const uint layers = windows.Size(); if(layers <= 0) return false; if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, inputs_count * variables, optimization_type, batch)) return false;
在方法主体中,我们实现了一个小型控制模块。此处我们首先检查是否有必要创建至少一个特征提取模块。之后,我们调用父类的同名方法,于其中实现了函数控制、和继承对象初始化的部分。我们按照返回的逻辑值,来控制父类方法的执行操作结果。
在下一步中,我们将接收到的参数保存到相应的内部变量和数组之中。
if(!ia_Windows.AssignArray(windows)) return false; i_Variables = variables; i_Count = inputs_count / ia_Windows[0]; b_NeedTranspose = need_transpose;
之后,我们开始初始化嵌套对象的过程。如果需要转置输入数据,我们在此创建 2 个嵌套数据转置层。第一个是为了转置输入数据。
if(b_NeedTranspose) { CNeuronTransposeOCL *transp = new CNeuronTransposeOCL(); if(!transp) return false; if(!transp.Init(0, 0, OpenCL, inputs_count, i_Variables, optimization, iBatch)) { delete transp; return false; } if(!caTranspose.Add(transp)) { delete transp; return false; }
第二个是为了转置输出,将它们返回到输入的维度。
transp = new CNeuronTransposeOCL(); if(!transp) return false; if(!transp.Init(0, 1, OpenCL, i_Variables, inputs_count, optimization, iBatch)) { delete transp; return false; } if(!caTranspose.Add(transp)) { delete transp; return false; } if(!SetOutput(transp.getOutput()) || !SetGradient(transp.getGradient()) ) return false; }
注意,当我们需要转置数据时,我们在结果转置层的相应缓冲区里以类的结果、和梯度缓冲区覆盖。该步骤允许我们剔除不必要的数据复制操作。
然后我们创建一个层,把独立的幺正序列中输入数据的大小对齐。
uint total = ia_Windows[0] * i_Count; CNeuronConvOCL *conv = new CNeuronConvOCL(); if(!conv.Init(0, 0, OpenCL, inputs_count, inputs_count, total, 1, i_Variables, optimization, iBatch)) { delete conv; return false; } if(!caConvolutions.Add(conv)) { delete conv; return false; }
在一个循环中,我们创建所需数量的卷积特征提取层。
total = 0; for(uint i = 0; i < layers; i++) { conv = new CNeuronConvOCL(); if(!conv.Init(0, i + 1, OpenCL, ia_Windows[i], ia_Windows[i], (i < (layers - 1) ? ia_Windows[i + 1] : 1), i_Count, i_Variables, optimization, iBatch)) { delete conv; return false; } if(!caConvolutions.Add(conv)) { delete conv; return false; } if(!caConvOutputs.Add(conv.getOutput()) || !caConvGradients.Add(conv.getGradient()) ) return false; total += conv.Neurons(); }
注意,在 caConvolutions 数组中,我们将输入数据大小对齐层,和特征提取卷积层组合在一起。因此,它包含的对象比指定的 FCNN 模块数量多一个。
根据 CSCM 模块算法,我们需要将全部所分析尺度的特征级联到一个张量之中。因此,在创建卷积层的同时,我们计算相关输出张量的总体大小。此外,我们将指向所创建特征提取层的输出数据缓冲区、和误差梯度的指针保存在单独的动态数组之中。在模型训练和操作过程中,这将提供对其内容的快捷访问。
现在,有了我们需要的数值,我们能够创建一个层来写入级联的张量。
CNeuronBaseOCL *comul = new CNeuronBaseOCL(); if(!comul.Init(0, 0, OpenCL, total, optimization, iBatch)) { delete comul; return false; } if(!caMLP.Add(comul)) { delete comul; return false; }
此处我们还提供了一个特殊情况,可创建 1 个特征提取层。在该情况下,我们没有什么可组合,级联的张量将是单一特征提取张量的完整副本。因此,为了避免不必要的复制操作,我们重新定义了结果和误差梯度缓冲区。
if(layers == 1) { comul.SetOutput(conv.getOutput()); comul.SetGradient(conv.getGradient()); }
之后,我们创建一个层,用来把级联特征张量的维度线性调整至输入序列的大小。
conv = new CNeuronConvOCL(); if(!conv.Init(0, 0, OpenCL, total / i_Variables, total / i_Variables, inputs_count, 1, i_Variables, optimization, iBatch)) { delete conv; return false; } if(!caMLP.Add(conv)) { delete conv; return false; }
我们已经覆盖了类的输入和结果缓冲区,以备我们转置输入数据之需。对于不同的情况,我们现在就来覆盖它们。
if(!b_NeedTranspose) { if(!SetOutput(conv.getOutput()) || !SetGradient(conv.getGradient()) ) return false; }
以这种方式,我们在这两种情况下都剔除了不必要的数据复制操作,无论输入数据是否需要转置。
在该方法的末尾,我们创建了 3 个辅助缓冲区来存储中间数据,当级联特征、和析联相应的误差梯度时,我们将用到它们。
CBufferFloat *buf = new CBufferFloat(); if(!buf) return false; if(!buf.BufferInit(total, 0) || !buf.BufferCreate(OpenCL) || !caTemp.Add(buf)) { delete buf; return false; } buf = new CBufferFloat(); if(!buf) return false; if(!buf.BufferInit(total, 0) || !buf.BufferCreate(OpenCL) || !caTemp.Add(buf)) { delete buf; return false; } buf = new CBufferFloat(); if(!buf) return false; if(!buf.BufferInit(total, 0) || !buf.BufferCreate(OpenCL) || !caTemp.Add(buf)) { delete buf; return false; } //--- caConvOutputs.FreeMode(false); caConvGradients.FreeMode(false); //--- return true; }
不要忘记控制所有嵌套对象的创建过程。所有嵌套对象初始化成功之后,我们将操作的逻辑结果返回给调用方。
CNeuronCSCMOCL 类的对象初始化之后,我们转至创建前馈算法。请注意,在该类框架内,我们不会在 OpenCL 程序端实现操作。整个实现基于嵌套对象方法的使用。它们的算法已在 OpenCL 端实现。按这样条件,我们只需要自嵌套对象的方法构建一个高级算法,并从父类继承。
我们在 feedForward 方法中规划前馈通验,在其参数中,调用程序提供一个指向前一层对象的指针。
bool CNeuronCSCMOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL *inp = NeuronOCL; CNeuronBaseOCL *current = NULL;
在方法主体中,我们将声明 2 个变量来存储指向神经层对象的指针。在该阶段,我们把接收自调用程序的指针传递给源数据变量。我们将第二个变量留空。
接下来,我们检查是否需要转置输入数据。如有必要,我们执行该操作。
if(b_NeedTranspose) { current = caTranspose.At(0); if(!current || !current.FeedForward(inp)) return false; inp = current; }
之后,我们经由不同尺度的连续卷积特征提取层通验输入时间序列,其指针我们已保存在 caConvolutions 数组之中。
int layers = caConvolutions.Total() - 1; for(int l = 0; l <= layers; l++) { current = caConvolutions.At(l); if(!current || !current.FeedForward(inp)) return false; inp = current; }
该数组中的第一层用于对齐输入数据序列的大小。我们未用到级联提取特征的结果,我们将在下一阶段执行。
请注意,我们正在构建一种算法,未限制卷积特征提取层的上限。在这种情况下,甚至最少允许 1 层特征提取。在这种情况下,我们能用的最简单算法大概是创建一个循环,顺序往张量添加 1 个特征数组。但这种方式会导致同一数据进行多次复制的潜在可能。这显见增加了我们在前馈通验期间的计算成本。为了将这样的操作降至最低,我们基于特征提取模块数量创建了一条分支算法。
如上所述,必须至少有一个特征提取层。如果不存在,则我们以负结果的形式向调用程序返回错误信号。
current = caMLP.At(0); if(!current) return false; switch(layers) { case 0: return false;
当使用单一特征提取层时,我们没有什么可级联的。如您所知,对于这种情况,在类初始化方法中,我们重新定义了特征提取层、和级联层的数据缓冲区,这令我们能够减少不必要的复制操作。如此,我们只要转到下一个操作。
case 1: break;
若存在 2 到 4 个特征提取层,则导致选择相应的数据级联方法。
case 2: if(!Concat(caConvOutputs.At(0), caConvOutputs.At(1), current.getOutput(), ia_Windows[1], 1, i_Variables * i_Count)) return false; break; case 3: if(!Concat(caConvOutputs.At(0), caConvOutputs.At(1), caConvOutputs.At(2), current.getOutput(), ia_Windows[1], ia_Windows[2], 1, i_Variables * i_Count)) return false; break; case 4: if(!Concat(caConvOutputs.At(0), caConvOutputs.At(1), caConvOutputs.At(2), caConvOutputs.At(3), current.getOutput(), ia_Windows[1], ia_Windows[2], ia_Windows[3], 1, i_Variables * i_Count)) return false;
如果有更多这样的层,那么我们将前 4 个特征提取层级联,但将结果写入临时数据存储缓冲区。
default: if(!Concat(caConvOutputs.At(0), caConvOutputs.At(1), caConvOutputs.At(2), caConvOutputs.At(3), caTemp.At(0), ia_Windows[1], ia_Windows[2], ia_Windows[3], ia_Windows[4], i_Variables * i_Count)) return false; break; }
注意,在执行级联操作时,我们不会从 caConvolutions 数组访问卷积层对象,而是直接访问其结果缓冲区,指向缓冲区的指针,我们已谨慎保存在动态数组 caConvOutputs 当中。
接下来,我们创建一个循环,从第 4 特征提取层开始,步长为 3 层。在该循环主体中,我们首先计算存储在临时缓冲区中的数据窗口大小。
uint last_buf = 0; for(int i = 4; i < layers; i += 3) { uint buf_size = 0; for(int j = 1; j <= i; j++) buf_size += ia_Windows[j];
然后我们组织一个算法,选择类似于上面给出的级联函数。但在这种情况下,含有先前已收集数据的临时缓冲区将始终位于第一位,并且下一批所提取特征会被加入其中。
switch(layers - i) { case 1: if(!Concat(caTemp.At(last_buf), caConvOutputs.At(i), current.getOutput(), buf_size, 1, i_Variables * i_Count)) return false; break; case 2: if(!Concat(caTemp.At(last_buf), caConvOutputs.At(i), caConvOutputs.At(i + 1), current.getOutput(), buf_size, ia_Windows[i + 1], 1, i_Variables * i_Count)) return false; break; case 3: if(!Concat(caTemp.At(last_buf), caConvOutputs.At(i), caConvOutputs.At(i + 1), caConvOutputs.At(i + 2), current.getOutput(), buf_size, ia_Windows[i + 1], ia_Windows[i + 2], 1, i_Variables * i_Count)) return false; break; default: if(!Concat(caTemp.At(last_buf), caConvOutputs.At(i), caConvOutputs.At(i + 1), caConvOutputs.At(i + 2), caTemp.At((last_buf + 1) % 2), buf_size, ia_Windows[i + 1], ia_Windows[i + 2], ia_Windows[i + 3], i_Variables * i_Count)) return false; break; } last_buf = (last_buf + 1) % 2; }
注意,当添加最后一个特征层(1 到 3)时,操作结果将保存在数据级联层缓冲区之中。在其它情况下,我们用另一个缓冲区作为临时数据存储。在循环的每次迭代中,缓冲区都会交替出现,以防止数据损坏和丢失。
将所有特征级联成至单一张量之后,我们只需要调整结果张量的大小。
inp = current; current = caMLP.At(1); if(!current || !current.FeedForward(inp)) return false;
如有必要,我们将它们转置到输入数据的维度。
if(b_NeedTranspose) { inp = current; current = caTranspose.At(1); if(!current || !current.FeedForward(inp)) return false; } //--- return true; }
我要提醒您,在初始化方法中,我们组织了数据缓冲区的代入。因此,操作结果被“自动”复制到我们类的相应继承缓冲区之中。
在构造了前馈通验方法之后,我们转到实现反向传播算法。首先,我们创建一个方法,根据误差梯度对整体结果的影响,把它们传播到所有对象的方法(calcInputGradients)。如常,在该方法的参数中,我们收到一个指向前一个神经层对象的指针。在这种情况下,我们需要将误差梯度的相应份额传递给它。
bool CNeuronCSCMOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!prevLayer) return false;
在方法主体中,我们立即检查所接收指针的相关性。之后,我们创建 2 个神经层的局部指针,我们将依序操作。
CNeuronBaseOCL *current = caMLP.At(0); CNeuronBaseOCL *next = caMLP.At(1);
我要提醒你,在分配误差梯度的过程中,我们根据前馈通验算法移动,但朝相对方向。因此,我们首先经由数据转置层传播梯度,当然,如果需要这样的操作。
if(b_NeedTranspose) { if(!next.calcHiddenGradients(caTranspose.At(1))) return false; }
然后,我们将误差梯度投喂到不同尺度的提取特征的级联层之中。
if(!current.calcHiddenGradients(next.AsObject())) return false; next = current;
之后,我们需要将误差梯度分派到相应的特征提取层。
我们不要忘记拥有 1 个特征提取层的特殊情况。此处我们仅需通过激活函数的导数来调整误差梯度。
int layers = caConvGradients.Total(); if(layers == 1) { next = caConvolutions.At(1); if(next.Activation() != None) { if(!DeActivation(next.getOutput(), next.getGradient(), next.getGradient(), next.Activation())) return false; } }
一般来说,我们首先分离最后一个特征提取层的误差梯度,并通过激活函数的导数进行校正。
else { int prev_window = 0; for(int i = 1; i < layers; i++) prev_window += int(ia_Windows[i]); if(!DeConcat(caTemp.At(0), caConvGradients.At(layers - 1), next.getGradient(), prev_window, 1, i_Variables * i_Count)) return false; next = caConvolutions.At(layers); int current_buf = 0;
之后,我们创建一个逆循环遍历特征提取层。在该循环主体中,我们首先从后续的特征提取层获得误差梯度。
for(int l = layers; l > 1; l--) { current = caConvolutions.At(l - 1); if(!current.calcHiddenGradients(next.AsObject())) return false;
然后,我们从级联特征张量的误差梯度缓冲区中提取所分析层的分数。
int window = int(ia_Windows[l - 1]); prev_window -= window; if(!DeConcat(caTemp.At((current_buf + 1) % 2), caTemp.At(2), caTemp.At(current_buf), prev_window, window, i_Variables * i_Count)) return false;
我们根据激活函数的导数调整它。
if(current.Activation() != None) { if(!DeActivation(current.getOutput(), caTemp.At(2), caTemp.At(2), current.Activation())) return false; }
我们汇总来自 2 个数据流的误差梯度。
if(!SumAndNormilize(current.getGradient(), caTemp.At(2), current.getGradient(), 1, false, 0, 0, 0, 1)) return false; next = current; current_buf = (current_buf + 1) % 2; } }
之后,我们转到循环的下一次迭代。
以这种方式,我们可在所有特征提取层之间分派误差梯度。然后,我们将误差梯度传递给输入数据大小对齐层。
current = caConvolutions.At(0); if(!current.calcHiddenGradients(next.AsObject())) return false; next = current;
如有必要,我们将误差梯度传播到数据转置层。
if(b_NeedTranspose) { current = caTranspose.At(0); if(!current.calcHiddenGradients(next.AsObject())) return false; next = current; }
在方法操作末尾,我们将误差梯度传递给前一个神经层,即我们在该方法参数中收到的指针所指层。
if(!prevLayer.calcHiddenGradients(next.AsObject())) return false; //--- return true; }
如您所知,误差梯度传播不是模型训练的目标。它仅意指判定模型参数调整方向、及程度。因此,在误差梯度成功传播之后,我们必须调整模型参数,从而令其操作的整体误差最小。该功能在 updateInputWeights 方法中实现。
bool CNeuronCSCMOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { CObject *prev = (b_NeedTranspose ? caTranspose.At(0) : NeuronOCL); CNeuronBaseOCL *current = NULL;
在方法参数中,如前,我们收到一个指向前一个神经层对象的指针。不过,在这种情况下,我们不会检查接收索引的相关性。我们只需将其保存到局部变量之中。不过,此处有一个细微差别。数据转置层不包含任何参数。因此,我们务须为其调用模型参数调整方法。但是对于输入大小对齐层,我们将根据 b_NeedTranspose 参数选择之前的层,该参数指示是否需要转置输入数据。
接下来,我们组织一个卷积层参数的顺序调整循环,包括一个调整原始序列和特征提取模块大小的层。
for(int i = 0; i < caConvolutions.Total(); i++) { current = caConvolutions.At(1); if(!current || !current.UpdateInputWeights(prev) ) return false; prev = current; }
接下来我们需要调整结果大小对齐层的参数。
current = caMLP.At(1); if(!current || !current.UpdateInputWeights(caMLP.At(0)) ) return false; //--- return true; }
我们的 CNeuronCSCMOCL 类的其它嵌套对象不包含可训练参数。
此刻,可认为 CSCM 模块主要算法的实现已完成。当然,如果没有额外辅助方法算法的实现,我们的类功能将是不完整的。但为了减少文章的篇幅,我不会在此提供它们的讲述。您将在附件中找到该类所有方法的完整代码。附件还包含本文中用到的所有程序的完整代码。我们转到构建下一个模块的算法 — Skip-PAM。
2.2实现 Skip-PAM 模块算法
我们要做的工作的第二部分是实现金字塔关注度算法。MSFformer 方法作者的创新之处在于将关注度算法应用到具有不同间隔的特征树。该方法作者在一个关注级别内的特征之间使用固定步骤。在我们的实现中,我们的处理略有不同 。如果我们让模型自行学习,每个单独的关注度金字塔的特征都在每个单独的关注度级别上进行分析,那样会如何?听起来很有希望。此外,在我看来,实现是显而易见和简单的。我们只在每个关注度级别之前添加一个 S3 层。
我们将在 CNeuronSPyrAttentionOCL 类中为 Skip-PAM 模块实现构建算法。其结构如下所示。
class CNeuronSPyrAttentionOCL : public CNeuronBaseOCL { protected: uint iWindowIn; uint iWindowKey; uint iHeads; uint iHeadsKV; uint iCount; uint iPAMLayers; //--- CArrayObj caS3; CArrayObj caQuery; CArrayObj caKV; CArrayInt caScore; CArrayObj caAttentionOut; CArrayObj caW0; CNeuronConvOCL cFF1; CNeuronConvOCL cFF2; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool AttentionOut(CBufferFloat *q, CBufferFloat *kv, int scores, CBufferFloat *out, int window); virtual bool AttentionInsideGradients(CBufferFloat *q, CBufferFloat *q_g, CBufferFloat *kv, CBufferFloat *kv_g, int scores, CBufferFloat *gradient); //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual void ArraySetOpenCL(CArrayObj *array, COpenCLMy *obj); public: CNeuronSPyrAttentionOCL(void) {}; ~CNeuronSPyrAttentionOCL(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint window_key, uint heads, uint heads_kv, uint units_count, uint pam_layers, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronSPyrAttentionMLKV; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
从所呈现结构中可见,新类包含更多的动态数组和参数。它们的名称与其它关注度类的对象一致。如您所知,这是有意为之的。在实现过程中,我们将领略所创建对象和变量的用法。
如前,我们从对象的 Init 初始化方法开始研究新类的算法。
bool CNeuronSPyrAttentionOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint window_key, uint heads, uint heads_kv, uint units_count, uint pam_layers, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_in * units_count, optimization_type, batch)) return false;
在方法参数中,我们接收主要常量,判定所创建对象的架构。在方法主体中,我们调用父类的相关方法,其中实现了继承对象的最少必要控制和初始化。
还应当注意的是,在该方法框架内,我们将分析整个多模态时间序列内的各个时间步骤。不过,在这种情况下,大概很难将 Skip-PAM 模块的原始数据输入称为多模时间序列。因为前面的 CSCM 模块的结果表示一组不同数据尺度的提取特征,而非一个时间序列。
父类对象的初始化方法成功执行之后,我们将获得的常量保存在局部变量之中。
iWindowIn = window_in; iWindowKey = MathMax(window_key, 1); iHeads = MathMax(heads, 1); iHeadsKV = MathMax(heads_kv, 1); iCount = units_count; iPAMLayers = MathMax(pam_layers, 2);
注意出现的新参数 iPAMLayers,其判定金字塔式关注度的级别数量。其余参数含义与前面讨论过的关注度方法功能相同。我们还保留了 iHeadsKV 参数,以便能使用与 Query 关注度头的维度不同的 键-值 头的数量,就像在 MLKV 方法中所研究的那样。
然后我们清除动态数组。
caS3.Clear(); caQuery.Clear(); caKV.Clear(); caScore.Clear(); caAttentionOut.Clear(); caW0.Clear();
我们创建必要的局部变量。
CNeuronBaseOCL *base = NULL; CNeuronConvOCL *conv = NULL; CNeuronS3 *s3 = NULL;
我们为金字塔式关注度模块对象创建初始化循环。正如您可能猜到的那样,循环的迭代次数等于所创建关注度级别的数量。
for(uint l = 0; l < iPAMLayers; l++) { //--- S3 s3 = new CNeuronS3(); if(!s3) return false; if(!s3.Init(0, l, OpenCL, iWindowIn, iCount, optimization, iBatch) || !caS3.Add(s3)) return false; s3.SetActivationFunction(None);
在循环主体中,我们首先创建 S3 层,于其中组织了所分析序列的排列。在这种情况下,我们仅用到一个数据混合层,其窗口等于原始多模序列中所分析参数的数量。
然后我们创建 Query、Key 和 Value 实体生成对象。请注意,在形成实体时,我们用到一个 INPUT 数据对象,但所用的关注度头参数不同。
//--- Query conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, 0, OpenCL, iWindowIn, iWindowIn, iWindowKey*iHeads, iCount, optimization, iBatch) || !caQuery.Add(conv)) { delete conv; return false; } conv.SetActivationFunction(None); //--- KV conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, 0, OpenCL, iWindowIn, iWindowIn, 2*iWindowKey*iHeadsKV, iCount, optimization, iBatch) || !caKV.Add(conv)) { delete conv; return false; } conv.SetActivationFunction(None);
我们将仅在 OpenCL 关联环境端创建依赖系数矩阵。于此,我们仅保存一个指向缓冲区的指针。
//--- Score int temp = OpenCL.AddBuffer(sizeof(float) * iCount * iCount * iHeads, CL_MEM_READ_WRITE); if(temp < 0) return false; if(!caScore.Add(temp)) return false;
在下一步中,我们创建一个层来记录多头关注度的结果。
//--- MH Attention Out base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, 0, OpenCL, iWindowKey * iHeadsKV * iCount, optimization, iBatch) || !caAttentionOut.Add(conv)) { delete base; return false; } base.SetActivationFunction(None);
循环的迭代是通过一层降维到输入数据级别的来完成的。
//--- W0 conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, 0, OpenCL, iWindowKey * iHeadsKV, iWindowKey * iHeadsKV, iWindowIn, iCount, optimization, iBatch) || !caW0.Add(conv)) { delete conv; return false; } conv.SetActivationFunction(None); }
创建金字塔关注度级别的所有迭代成功完成之后,我们添加一个层。在该层的缓冲区中,我们将记录金字塔关注度模块的结果,及输入数据的总和。
//--- Residual base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, 0, OpenCL, iWindowIn * iCount, optimization, iBatch) || !caW0.Add(conv)) { delete base; return false; } base.SetActivationFunction(None);
现在我们只需初始化 FeedForward 模块层。
//--- FeedForward if(!cFF1.Init(0, 0, OpenCL, iWindowIn, iWindowIn, 4 * iWindowIn, iCount, optimization, iBatch)) return false; cFF1.SetActivationFunction(LReLU); if(!cFF2.Init(0, 0, OpenCL, 4 * iWindowIn, 4 * iWindowIn, iWindowIn, iCount, optimization, iBatch)) return false; cFF2.SetActivationFunction(None); if(!SetGradient(cFF2.getGradient())) return false;
方法的结尾,我们强行删除我们层里的激活函数。
SetActivationFunction(None); //--- return true; }
类的对象初始化之后,我们转到实现前馈通验算法。此处,我们需要在 OpenCL 程序端做一些准备工作。我们将创建一个新的 MH2PyrAttentionOut 内核,它本质上是 MH2AttentionOut 内核的修改版本。
__kernel void MH2PyrAttentionOut(__global float *q, __global float *kv, __global float *score, __global float *out, const int dimension, const int heads_kv, const int window ) { //--- init const int q_id = get_global_id(0); const int k = get_global_id(1); const int h = get_global_id(2); const int qunits = get_global_size(0); const int kunits = get_global_size(1); const int heads = get_global_size(2);
除了内核名称之外,它与前一个内核的不同之处在于多了关注度窗口的 window 参数。我们计划在 3-维任务空间中调用内核。如常,在内核的开头,我们在任务空间的所有维度中识别线程。
接下来,我们计算必要的常数。
const int h_kv = h % heads_kv; const int shift_q = dimension * (q_id * heads + h); const int shift_k = dimension * (2 * heads_kv * k + h_kv); const int shift_v = dimension * (2 * heads_kv * k + heads_kv + h_kv); const int shift_s = kunits * (q_id * heads + h) + k; const uint ls = min((uint)get_local_size(1), (uint)LOCAL_ARRAY_SIZE); const int delta_win = (window + 1) / 2; float koef = sqrt((float)dimension); if(koef < 1) koef = 1;
我们还初始化一个本地数组来记录中间值。
__local float temp[LOCAL_ARRAY_SIZE];
首先,我们需要判定序列中每个元素的依赖系数。如您所知,在关注度模块中,依赖系数由 SoftMax 函数归一化。为此,我们首先计算依赖系数指数之和。
在第一阶段,每个线程都会将其指数值之和的一部分收集到本地数据数组的相应元素之中。请注意以下添加:我们只在当前元素的关注度窗口内计算依赖系数。对于所有其它元素,依赖系数为 “0”。
//--- sum of exp uint count = 0; if(k < ls) do { if((count * ls) < (kunits - k)) { float sum = 0; if(abs(count * ls + k - q_id) <= delta_win) { for(int d = 0; d < dimension; d++) sum = q[shift_q + d] * kv[shift_k + d]; sum = exp(sum / koef); if(isnan(sum)) sum = 0; } temp[k] = (count > 0 ? temp[k] : 0) + sum; } count++; } while((count * ls + k) < kunits); barrier(CLK_LOCAL_MEM_FENCE);
为了同步局部组线程,我们使用一个屏障。
在下一步中,我们需要收集局部数组的所有元素的数值之和。为此,我们创建另一个循环,在每次迭代时同步局部线程。此处,您需要注意每个线程访问相同数量的屏障。否则,我们也许会遇到 “冻结” 单个线程。
count = min(ls, (uint)kunits); //--- do { count = (count + 1) / 2; if(k < ls) temp[k] += (k < count && (k + count) < kunits ? temp[k + count] : 0); if(k + count < ls) temp[k + count] = 0; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
判定指数之和后,我们可以计算归一化依赖系数。不要忘记,依赖项仅存在于关注度窗口中。
//--- score float sum = temp[0]; float sc = 0; if(sum != 0 && abs(k - q_id) <= delta_win) { for(int d = 0; d < dimension; d++) sc = q[shift_q + d] * kv[shift_k + d]; sc = exp(sc / koef) / sum; if(isnan(sc)) sc = 0; } score[shift_s] = sc; barrier(CLK_LOCAL_MEM_FENCE);
当然,我们在计算依赖系数后同步局部线程。
接下来,我们需要在参考依赖关系的情况下判定元素值。此处,我们将汇总并行线程中的数值,其算法与我们在判定依赖项的指数值之和的所做相同。我们首先收集局部数组元素中各个数值的总和。
//--- out for(int d = 0; d < dimension; d++) { uint count = 0; if(k < ls) do { if((count * ls) < (kunits - k)) { float sum = 0; if(abs(count * ls + k - q_id) <= delta_win) { sum = kv[shift_v + d] * (count == 0 ? sc : score[shift_s + count * ls]); if(isnan(sum)) sum = 0; } temp[k] = (count > 0 ? temp[k] : 0) + sum; } count++; } while((count * ls + k) < kunits); barrier(CLK_LOCAL_MEM_FENCE);
然后我们收集数组元素值之和。
//--- count = min(ls, (uint)kunits); do { count = (count + 1) / 2; if(k < ls) temp[k] += (k < count && (k + count) < kunits ? temp[k + count] : 0); if(k + count < ls) temp[k + count] = 0; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1); //--- out[shift_q + d] = temp[0]; } }
我们将结果总和保存在结果缓冲区的相应元素之中。
因此,我们在给定的窗口中创建了一个新的关注度内核。请注意,对于关注度窗口之外的元素,我们已将依赖系数设置为 “0”。这个简单的移动允许我们使用之前创建的 MH2AttentionInsideGradients 内核,在反向传播通验中分派误差梯度。
为了将指定的内核放在主程序端的执行队列当中,我分别创建了 AttentionOut 和 AttentionInsideGradients 方法。它们的算法与本系列之前文章中讨论过的类似方法并无太大区别,因此我们现在不再赘述它们。您可在附件中自行找到代码。我们转到实现 feedForward 方法算法。
在参数中,前馈通验方法接收指向前一个神经层对象的指针,其中包含输入数据。
bool CNeuronSPyrAttentionOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL *prev = NeuronOCL; CNeuronBaseOCL *current = NULL; CBufferFloat *q = NULL; CBufferFloat *kv = NULL;
在方法主体中,我们创建了许多局部变量来存储指向嵌套神经层的已处理对象的指针。
接下来,我们创建一个循环,遍历关注度级别。在循环主体中,我们首先对源数据进行随机排序。
for(uint l = 0; l < iPAMLayers; l++) { //--- Mix current = caS3.At(l); if(!current || !current.FeedForward(prev.AsObject()) ) return false; prev = current;
之后,我们生成 Query、Key 和 Value 实体的张量,实现多头关注度算法。
//--- Query current = caQuery.At(l); if(!current || !current.FeedForward(prev.AsObject()) ) return false; q = current.getOutput(); //--- Key and Value current = caKV.At(l); if(!current || !current.FeedForward(prev.AsObject()) ) return false; kv = current.getOutput();
执行该级别的关注度内核算法。
//--- PAM current = caAttentionOut.At(l); if(!current || !AttentionOut(q, kv, caScore.At(l), current.getOutput(), iPAMLayers - l)) return false; prev = current;
注意,在每个后续级别,我们都会降低关注度窗口,从而产生金字塔效应。为此,我们使用差值 “iPAMLayers - l”。
在循环迭代结束时,我们将多头关注度结果张量的大小降低至输入数据大小。
//--- W0 current = caW0.At(l); if(!current || !current.FeedForward(prev.AsObject()) ) return false; prev = current; }
所有级别的金字塔关注度成功完成之后,我们用输入数据对关注度的结果进行求和,并归一化。
//--- Residual current = caW0.At(iPAMLayers); if(!SumAndNormilize(NeuronOCL.getOutput(), prev.getOutput(), current.getOutput(), iWindowIn, true)) return false;
而金字塔关注度层的最后一个是前馈模块,类似于 vanilla 变换器。
//---FeedForward if(!cFF1.FeedForward(current.AsObject()) || !cFF2.FeedForward(cFF1.AsObject()) ) return false;
然后,我们再次针对来自 2 个线程的数据求和,并归一化。
//--- Residual if(!SumAndNormilize(current.getOutput(), cFF2.getOutput(), getOutput(), iWindowIn, true)) return false; //--- return true; }
切记要控制操作的执行。在方法末尾,我们将操作的逻辑结果返回至调用者。
如常,在实现前馈通验之后,我们转到构建反向传播通验算法,其包括 2 个阶段:误差梯度的传播,和模型参数的优化。
误差梯度的传播是在 calcInputGradients 方法中实现的。
bool CNeuronSPyrAttentionOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!prevLayer) return false;
在该方法参数中,我们接收到指向前一个神经层对象的指针。在该层的缓冲区中,我们必须根据输入数据对整体结果的影响来传递误差梯度。
接下来,我们创建一些局部变量来临时存储指向内部对象的指针。
CNeuronBaseOCL *next = NULL; CNeuronBaseOCL *current = NULL; CNeuronBaseOCL *q = NULL; CNeuronBaseOCL *kv = NULL;
误差梯度的分派是根据前馈通验操作执行的,但顺序相反。首先,我们经由 FeedForward 模块传播误差梯度。
//--- FeedForward current = caW0.At(iPAMLayers); if(!current || !cFF1.calcHiddenGradients(cFF2.AsObject()) || !current.calcHiddenGradients(cFF1.AsObject()) ) return false; next = current;
然后我们需要加上来自 2 个操作线程的误差梯度。
//--- Residual current = caW0.At(iPAMLayers - 1); if(!SumAndNormilize(getGradient(), next.getGradient(), current.getGradient(), iWindowIn, false)) return false; CBufferFloat *residual = next.getGradient(); next = current;
之后,我们创建一个逆循环,按误差梯度降序遍历关注度级别。
for(int l = int(iPAMLayers - 1); l >= 0; l--) { //--- W0 current = caAttentionOut.At(l); if(!current || !current.calcHiddenGradients(next.AsObject()) ) return false;
在循环主体中,我们首先跨关注度头传播误差梯度。然后,我们将其传播到 Query、Key 和 Value 实体级别。
//--- MH Attention q = caQuery.At(l); kv = caKV.At(l); if(!q || !kv || !AttentionInsideGradients(q.getOutput(), q.getGradient(), kv.getOutput(), kv.getGradient(), caScore.At(l), current.getGradient()) ) return false;
下一步是将误差梯度向下传播到数据乱序层。此处,我们需要合并来自 2 个线程的数据 — Query 和 Key-Value。为此,我们首先从 Query 获取误差梯度,并将其传送到临时缓冲区。
//--- Query current = caS3.At(l); if(!current || !current.calcHiddenGradients(q.AsObject()) || !Concat(current.getGradient(), current.getGradient(), residual, iWindowIn,0, iCount) ) return false;
然后我们从 Key-Value 中获取梯度,并将 2 个数据线程的结果相加。
//--- Key and Value if(!current || !current.calcHiddenGradients(kv.AsObject()) || !SumAndNormilize(current.getGradient(), residual, current.getGradient(), iWindowIn, false) ) return false; next = current;
我们将误差梯度传播到数据乱序层,并转到循环的下一次迭代。
//--- S3 current = (l == 0 ? prevLayer : caW0.At(l - 1)); if(!current || !current.calcHiddenGradients(next.AsObject()) ) return false; next = current; }
在方法操作的末尾,我们只需将来自两个线程的误差梯度组合在一起。此处我们首先依据前一层的激活函数的导数来调整残差连接的误差梯度。当误差梯度下降直达层级时,误差梯度调整会自动变更为激活函数。
current = caW0.At(iPAMLayers - 1); if(!DeActivation(prevLayer.getOutput(), current.getGradient(), residual, prevLayer.Activation()) || !SumAndNormilize(prevLayer.getGradient(), residual, prevLayer.getGradient(), iWindowIn, false) ) return false; //--- return true; }
然后我们对两个线程的误差梯度求和。
分派误差梯度之后,我们转到调整模型参数。我们在 updateInputWeights 方法中实现该功能。该方法的算法十分简单 — 我们按顺序调用包含可学习参数的嵌套对象同名方法。
bool CNeuronSPyrAttentionOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL *prev = NeuronOCL; CNeuronBaseOCL *current = NULL; for(uint l = 0; l < iPAMLayers; l++) { //--- S3 current = caS3.At(l); if(!current || !current.UpdateInputWeights(prev) ) return false; //--- Query prev = current; current = caQuery.At(l); if(!current || !current.UpdateInputWeights(prev) ) return false; //--- Key and Value current = caKV.At(l); if(!current || !current.UpdateInputWeights(prev) ) return false; //--- W0 prev = caAttentionOut.At(l); current = caW0.At(l); if(!current || !current.UpdateInputWeights(prev) ) return false; prev = current; } //--- FeedForward prev = caW0.At(iPAMLayers); if(!cFF1.UpdateInputWeights(prev) || !cFF2.UpdateInputWeights(cFF1.AsObject()) ) return false; //--- return true; }
确保控制该方法所有操作的执行过程,并将操作执行的逻辑结果返回给调用方。
我们实现所提议 MSFformer 方法的工作到此结束。您可在附件中查看创建的类、及其方法的完整代码。
结束语
在本文中,我们研究了另一种有趣、且有前途的时间序列预测方法:MSFformer(多尺度特征变换器)。该方法首次在论文《基于多尺度特征提取进行时间序列预测》中提出。所提议算法基于一种改进的金字塔关注度架构,和一种从输入数据中提取不同尺度特征的新方法。
在本文的实践部分,我们实现了所提议算法的 2 个主要模块。我们将在下一篇文章中讲述这项工作的结果。
参考
文中所用程序
| # | 名称 | 类型 | 说明 |
|---|---|---|---|
| 1 | Research.mq5 | EA | 样本收集 EA |
| 2 | ResearchRealORL.mq5 | EA | 运用 Real-ORL 方法收集示例的 EA |
| 3 | Study.mq5 | EA | 模型训练 EA |
| 4 | StudyEncoder.mq5 | EA | 编码器训练 EA |
| 5 | Test.mq5 | EA | 模型测试 EA |
| 6 | Trajectory.mqh | 类库 | 系统状态定义结构 |
| 7 | NeuroNet.mqh | 类库 | 创建神经网络的类库 |
| 8 | NeuroNet.cl | 代码库 | OpenCL 程序代码库 |
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/15156
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。
