Artikel über maschinelles Lernen im Handel.
Erstellen von KI-basierten Handelsrobotern: native Integration der Bibliotheken für Python, Matrizen und Vektoren, Mathematik und Statistik und vieles mehr.
Finden Sie heraus, wie Sie maschinelles Lernen im Handel einsetzen können. Neuronen, Perzeptronen, Faltungs- und rekurrente Netze, Vorhersagemodelle – beginnen Sie mit den Grundlagen und arbeiten Sie sich bis zur Entwicklung Ihrer eigenen KI vor. Sie lernen, wie man neuronale Netze für den algorithmischen Handel auf Finanzmärkten trainiert und anwendet.
Neuer Artikel

Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich

Entwicklung eines Handelsroboters in Python (Teil 3): Implementierung eines modellbasierten Handelsalgorithmus
Wir setzen die Serie von Artikeln über die Entwicklung eines Handelsroboters in Python und MQL5 fort. In diesem Artikel werden wir einen Handelsalgorithmus in Python erstellen.

Neuronale Netze leicht gemacht (Teil 16): Praktische Anwendung des Clustering
Im vorigen Artikel haben wir eine Klasse für das Clustering von Daten erstellt. In diesem Artikel möchte ich Varianten für die mögliche Anwendung der gewonnenen Ergebnisse bei der Lösung praktischer Handelsaufgaben vorstellen.

Entwicklung eines Roboters in Python und MQL5 (Teil 1): Vorverarbeitung der Daten
Entwicklung eines auf maschinellem Lernen basierenden Handelsroboters: Ein detaillierter Leitfaden. Der erste Artikel in dieser Reihe befasst sich mit der Erfassung und Aufbereitung von Daten und Merkmalen. Das Projekt wird unter Verwendung der Programmiersprache Python und der Bibliotheken sowie der Plattform MetaTrader 5 umgesetzt.

Neuronale Netze leicht gemacht (Teil 14): Datenclustering
Es ist mehr als ein Jahr her, dass ich meinen letzten Artikel veröffentlicht habe. Das ist eine ganze Menge Zeit, um Ideen zu überarbeiten und neue Ansätze zu entwickeln. In dem neuen Artikel möchte ich von der bisher verwendeten Methode des überwachten Lernens abweichen. Diesmal werden wir uns mit Algorithmen des unüberwachten Lernens beschäftigen. Wir werden insbesondere einen der Clustering-Algorithmen - K-Means - betrachten.

Datenkennzeichnung für Zeitreihenanalyse (Teil 2): Datensätze mit Trendmarkern mit Python erstellen
In dieser Artikelserie werden verschiedene Methoden zur Kennzeichnung von Zeitreihen vorgestellt, mit denen Daten erstellt werden können, die den meisten Modellen der künstlichen Intelligenz entsprechen. Eine gezielte und bedarfsgerechte Kennzeichnung von Daten kann dazu führen, dass das trainierte Modell der künstlichen Intelligenz besser mit dem erwarteten Design übereinstimmt, die Genauigkeit unseres Modells verbessert wird und das Modell sogar einen qualitativen Sprung machen kann!

Datenwissenschaft und maschinelles Lernen (Teil 06): Gradientenverfahren
Der Gradientenverfahren spielt eine wichtige Rolle beim Training neuronaler Netze und vieler Algorithmen des maschinellen Lernens. Es handelt sich um einen schnellen und intelligenten Algorithmus, der trotz seiner beeindruckenden Arbeit von vielen Datenwissenschaftlern immer noch missverstanden wird - sehen wir uns an, worum es geht.
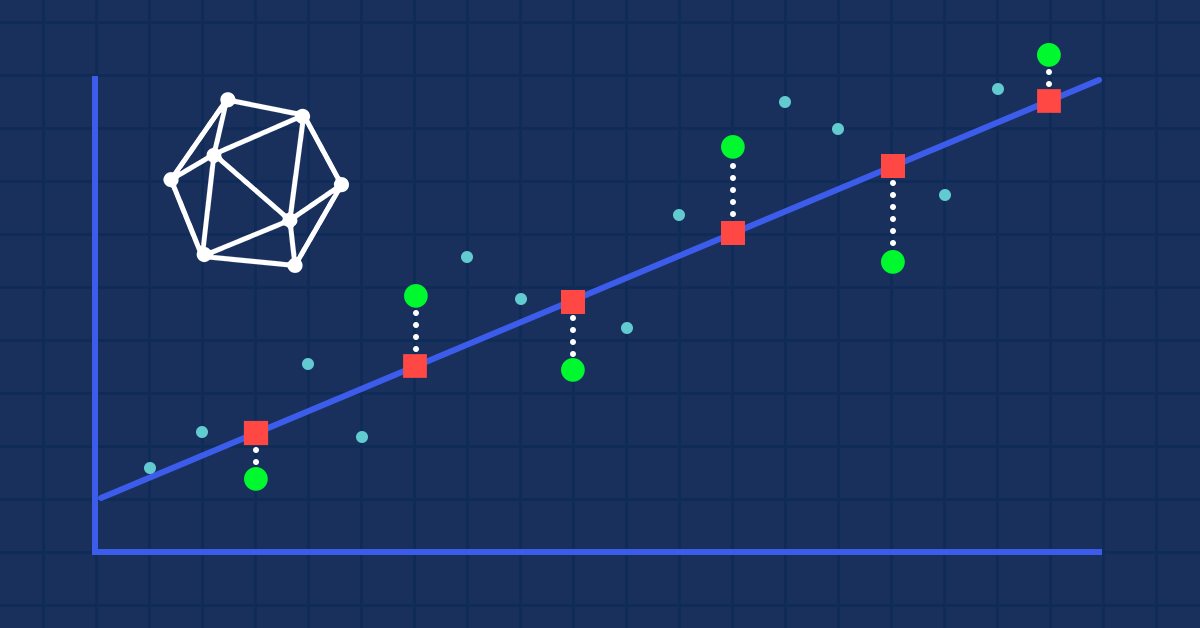
Bewertung von ONNX-Modellen anhand von Regressionsmetriken
Bei der Regression geht es um die Prognose eines realen Wertes anhand eines unbekannten Beispiels. Die so genannten Regressionsmetriken werden verwendet, um die Genauigkeit der Vorhersagen des Regressionsmodells zu bewerten.

Neuronale Netze leicht gemacht (Teil 21): Variierter Autoencoder (VAE)
Im letzten Artikel haben wir uns mit dem Algorithmus des Autoencoders vertraut gemacht. Wie jeder andere Algorithmus hat auch dieser seine Vor- und Nachteile. In seiner ursprünglichen Implementierung wird der Autoencoder verwendet, um die Objekte so weit wie möglich von der Trainingsstichprobe zu trennen. Dieses Mal werden wir darüber sprechen, wie man mit einigen ihrer Nachteile umgehen kann.
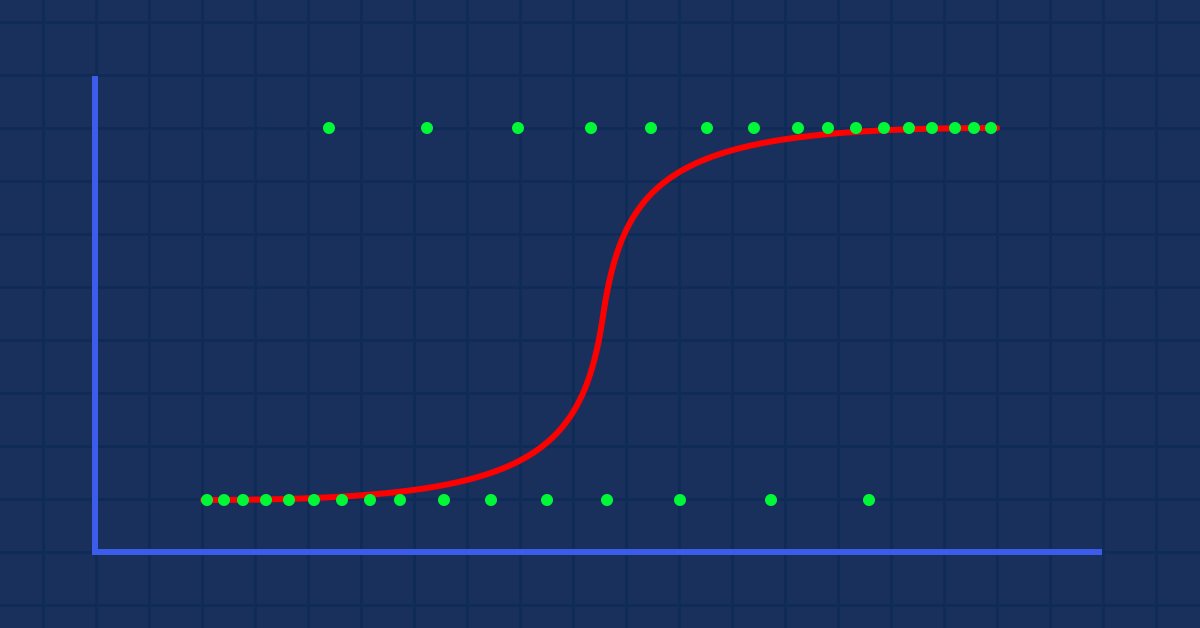
Datenwissenschaft und maschinelles Lernen (Teil 02): Logistische Regression
Die Klassifizierung von Daten ist für einen Algo-Händler und einen Programmierer von entscheidender Bedeutung. In diesem Artikel werden wir uns auf einen logistischen Klassifizierungsalgorithmus konzentrieren, der uns wahrscheinlich helfen kann, die Ja- oder Nein-Stimmen, die Höhen und Tiefen, Käufe und Verkäufe zu identifizieren.

Integrieren Sie Ihr eigenes LLM in Ihren EA (Teil 1): Die bereitgestellte Hardware und Umgebung
Angesichts der rasanten Entwicklung der künstlichen Intelligenz sind Sprachmodelle (language models, LLMs) heute ein wichtiger Bestandteil der künstlichen Intelligenz, sodass wir darüber nachdenken sollten, wie wir leistungsstarke LLMs in unseren algorithmischen Handel integrieren können. Für die meisten Menschen ist es schwierig, diese leistungsstarken Modelle auf ihre Bedürfnisse abzustimmen, sie lokal einzusetzen und sie dann auf den algorithmischen Handel anzuwenden. In dieser Artikelserie werden wir Schritt für Schritt vorgehen, um dieses Ziel zu erreichen.

Kometenschweif-Algorithmus (CTA)
In diesem Artikel befassen wir uns mit der Optimierungsalgorithmus nach dem Kometenschweif (Comet Tail Optimization Algorithm, CTA), der sich von einzigartigen Weltraumobjekten inspirieren lässt - von Kometen und ihren beeindruckenden Schweifen, die sich bei der Annäherung an die Sonne bilden. Der Algorithmus basiert auf dem Konzept der Bewegung von Kometen und ihren Schweifen und ist darauf ausgelegt, optimale Lösungen für Optimierungsprobleme zu finden.

ONNX-Modelle in Klassen packen
Die objektorientierte Programmierung ermöglicht die Erstellung eines kompakteren Codes, der leicht zu lesen und zu ändern ist. Hier sehen wir uns das Beispiel für drei ONNX-Modelle an.

Ein Beispiel für die Zusammenstellung von ONNX-Modellen in MQL5
ONNX (Open Neural Network eXchange) ist ein offenes Format zur Darstellung neuronaler Netze. In diesem Artikel zeigen wir Ihnen, wie Sie zwei ONNX-Modelle gleichzeitig in einem Expert Advisor verwenden können.

Neuronale Netze leicht gemacht (Teil 30): Genetische Algorithmen
Heute möchte ich Ihnen eine etwas andere Lernmethode vorstellen. Wir können sagen, dass sie von Darwins Evolutionstheorie entlehnt ist. Sie ist wahrscheinlich weniger kontrollierbar als die zuvor besprochenen Methoden, aber sie ermöglicht die Ausbildung nicht-differenzierbarer Modelle.

Datenkennzeichnung für Zeitreihenanalyse (Teil 1):Erstellen eines Datensatzes mit Trendmarkierungen durch den EA auf einem Chart
In dieser Artikelserie werden verschiedene Methoden zur Kennzeichnung von Zeitreihen vorgestellt, mit denen Daten erstellt werden können, die den meisten Modellen der künstlichen Intelligenz entsprechen. Eine gezielte und bedarfsgerechte Kennzeichnung von Daten kann dazu führen, dass das trainierte Modell der künstlichen Intelligenz besser mit dem erwarteten Design übereinstimmt, die Genauigkeit unseres Modells verbessert wird und das Modell sogar einen qualitativen Sprung machen kann!

Algorithmen zur Optimierung mit Populationen: Der Algorithmus intelligenter Wassertropfen (IWD)
Der Artikel befasst sich mit einem interessanten, von der unbelebten Natur abgeleiteten Algorithmus - intelligente Wassertropfen (IWD), die den Prozess der Flussbettbildung simulieren. Die Ideen dieses Algorithmus ermöglichten es, den bisherigen Spitzenreiter der Bewertung - SDS - deutlich zu verbessern. Der neue Führende (modifizierter SDSm) befindet sich wie üblich im Anhang.

Arbeiten mit ONNX-Modellen in den Datenformaten float16 und float8
Die Datenformate, die zur Darstellung von Modellen des maschinellen Lernens verwendet werden, spielen eine entscheidende Rolle für deren Effektivität. In den letzten Jahren sind mehrere neue Datentypen aufgetaucht, die speziell für die Arbeit mit Deep-Learning-Modellen entwickelt wurden. In diesem Artikel werden wir uns auf zwei neue Datenformate konzentrieren, die sich in modernen Modellen durchgesetzt haben.

Neuronale Netze leicht gemacht (Teil 26): Reinforcement-Learning
Wir untersuchen weiterhin Methoden des Reinforcement-Learnings. Mit diesem Artikel beginnen wir ein weiteres großes Thema, das Reinforcement-Learning. Dieser Ansatz ermöglicht es den Modellen, bestimmte Strategien zur Lösung der Probleme zu entwickeln. Es ist zu erwarten, dass diese Eigenschaft des Reinforcement-Learnings (Lernen durch Verstärkung) neue Horizonte für die Entwicklung von Handelsstrategien eröffnen wird.

Integrieren Sie Ihr eigenes LLM in EA (Teil 2): Beispiel für den Einsatz in einer Umgebung
Angesichts der rasanten Entwicklung der künstlichen Intelligenz sind Sprachmodelle (language models, LLMs) heute ein wichtiger Bestandteil der künstlichen Intelligenz, sodass wir darüber nachdenken sollten, wie wir leistungsstarke LLMs in unseren algorithmischen Handel integrieren können. Für die meisten Menschen ist es schwierig, diese leistungsstarken Modelle auf ihre Bedürfnisse abzustimmen, sie lokal einzusetzen und sie dann auf den algorithmischen Handel anzuwenden. In dieser Artikelserie werden wir Schritt für Schritt vorgehen, um dieses Ziel zu erreichen.
Entwicklung des Price Action Analysis Toolkit (Teil 36): Direkter Python-Zugang zu MetaTrader 5 Market Streams freischalten
Schöpfen Sie das volle Potenzial Ihres MetaTrader 5 Terminals aus, indem Sie das datenwissenschaftliche Ökosystem von Python und die offizielle MetaTrader 5 Client-Bibliothek nutzen. Dieser Artikel zeigt, wie man Live-Tick- und Minutenbalken-Daten direkt in den Parquet-Speicher authentifiziert und streamt, mit Ta und Prophet ein ausgefeiltes Feature-Engineering durchführt und ein zeitabhängiges Gradient-Boosting-Modell trainiert. Anschließend setzen wir einen leichtgewichtigen Flask-Dienst ein, um Handelssignale in Echtzeit zu liefern. Egal, ob Sie ein hybrides Quant-Framework aufbauen oder Ihren EA mit maschinellem Lernen erweitern, Sie erhalten eine robuste Ende-zu-Ende-Pipeline für den datengesteuerten algorithmischen Handel an die Hand.

Einführung in MQL5 (Teil 3): Beherrschung der Kernelemente von MQL5
Entdecken Sie die Grundlagen der MQL5-Programmierung in diesem einsteigerfreundlichen Artikel, in dem wir Arrays, nutzerdefinierte Funktionen, Präprozessoren und die Ereignisbehandlung entmystifizieren, wobei jede Codezeile verständlich erklärt wird. Erschließen wir die Leistungsfähigkeit von MQL5 mit einem einzigartigen Ansatz, der das Verständnis bei jedem Schritt sicherstellt. Dieser Artikel legt den Grundstein für die Beherrschung von MQL5, indem er die Erklärung jeder Codezeile hervorhebt und eine eindeutige und bereichernde Lernerfahrung bietet.

Datenwissenschaft und maschinelles Lernen (Teil 04): Vorhersage des aktuellen Börsenkrachs
In diesem Artikel werde ich versuchen, unser logistisches Modell zu verwenden, um den Börsencrash auf der Grundlage der Fundamentaldaten der US-Wirtschaft vorherzusagen. NETFLIX und APPLE sind die Aktien, auf die wir uns konzentrieren werden, wobei wir die früheren Börsencrashs von 2019 und 2020 nutzen werden, um zu sehen, wie unser Modell in der aktuellen Krise abschneiden wird.

Neuronale Netze leicht gemacht (Teil 43): Beherrschen von Fähigkeiten ohne Belohnungsfunktion
Das Problem des Verstärkungslernens liegt in der Notwendigkeit, eine Belohnungsfunktion zu definieren. Sie kann komplex oder schwer zu formalisieren sein. Um dieses Problem zu lösen, werden aktivitäts- und umweltbasierte Ansätze zum Erlernen von Fähigkeiten ohne explizite Belohnungsfunktion erforscht.

Neuronale Netze leicht gemacht (Teil 50): Soft Actor-Critic (Modelloptimierung)
Im vorigen Artikel haben wir den Algorithmus Soft Actor-Critic (Akteur-Kritiker) implementiert, konnten aber kein profitables Modell trainieren. Hier werden wir das zuvor erstellte Modell optimieren, um die gewünschten Ergebnisse zu erzielen.

Neuronale Netze leicht gemacht (Teil 17): Reduzierung der Dimensionalität
In diesem Teil setzen wir die Diskussion über die Modelle der Künstlichen Intelligenz fort. Wir untersuchen vor allem Algorithmen für unüberwachtes Lernen. Wir haben bereits einen der Clustering-Algorithmen besprochen. In diesem Artikel stelle ich eine Variante zur Lösung von Problemen im Zusammenhang mit der Dimensionsreduktion vor.

Algorithmen zur Optimierung mit Populationen Künstliches Bienenvolk (Artificial Bee Colony, ABC)
In diesem Artikel werden wir den Algorithmus eines künstlichen Bienenvolkes untersuchen und unser Wissen durch neue Prinzipien zur Untersuchung funktionaler Räume ergänzen. In diesem Artikel werde ich meine Interpretation der klassischen Version des Algorithmus vorstellen.

Python, ONNX und MetaTrader 5: Erstellen eines RandomForest-Modells mit RobustScaler und PolynomialFeatures zur Datenvorverarbeitung
In diesem Artikel werden wir ein Random-Forest-Modell in Python erstellen, das Modell trainieren und es als ONNX-Pipeline mit Datenvorverarbeitung speichern. Danach werden wir das Modell im MetaTrader 5 Terminal verwenden.

Datenwissenschaft und maschinelles Lernen (Teil 25): Forex-Zeitreihenvorhersage mit einem rekurrenten neuronalen Netzwerk (RNN)
Rekurrente neuronale Netze (RNNs) zeichnen sich dadurch aus, dass sie Informationen aus der Vergangenheit nutzen, um zukünftige Ereignisse vorherzusagen. Ihre bemerkenswerten Vorhersagefähigkeiten wurden in verschiedenen Bereichen mit großem Erfolg eingesetzt. In diesem Artikel werden wir RNN-Modelle zur Vorhersage von Trends auf dem Devisenmarkt einsetzen und ihr Potenzial zur Verbesserung der Vorhersagegenauigkeit beim Devisenhandel aufzeigen.

Neuronale Netze leicht gemacht (Teil 19): Assoziationsregeln mit MQL5
Wir fahren mit der Besprechung von Assoziationsregeln fort. Im vorigen Artikel haben wir den theoretischen Aspekt dieser Art von Problemen erörtert. In diesem Artikel werde ich die Implementierung der FP Growth-Methode mit MQL5 zeigen. Außerdem werden wir die implementierte Lösung anhand realer Daten testen.

Experimente mit neuronalen Netzen (Teil 6): Das Perzeptron als autarkes Instrument zur Preisprognose
Der Artikel liefert ein Beispiel für die Verwendung eines Perzeptrons als autarkes Preisprognoseinstrument, indem er allgemeine Konzepte und den einfachsten vorgefertigten Expert Advisor vorstellt und anschließend die Ergebnisse seiner Optimierung zeigt.

Neuronale Netze leicht gemacht (Teil 51): Behavior-Guided Actor-Critic (BAC)
Die letzten beiden Artikel befassten sich mit dem Soft Actor-Critic-Algorithmus, der eine Entropie-Regularisierung in die Belohnungsfunktion integriert. Dieser Ansatz schafft ein Gleichgewicht zwischen Umwelterkundung und Modellnutzung, ist aber nur auf stochastische Modelle anwendbar. In diesem Artikel wird ein alternativer Ansatz vorgeschlagen, der sowohl auf stochastische als auch auf deterministische Modelle anwendbar ist.

Verwendung des Algorithmus PatchTST für maschinelles Lernen zur Vorhersage der Kursentwicklung in den nächsten 24 Stunden
In diesem Artikel wenden wir einen relativ komplexen Algorithmus eines neuronalen Netzes aus dem Jahr 2023 namens PatchTST zur Vorhersage der Kursentwicklung der nächsten 24 Stunden an. Wir werden das offizielle Repository verwenden, geringfügige Änderungen vornehmen, ein Modell für EURUSD trainieren und es zur Erstellung von Zukunftsprognosen sowohl in Python als auch in MQL5 anwenden.
Datenwissenschaft und maschinelles Lernen (Teil 07): Polynome Regression
Im Gegensatz zur linearen Regression ist die polynome Regression ein flexibles Modell, das darauf abzielt, Aufgaben besser zu erfüllen, die das lineare Regressionsmodell nicht bewältigen kann. Lassen Sie uns herausfinden, wie man polynome Modelle in MQL5 erstellt und etwas Positives daraus macht.

Neuronale Netze leicht gemacht (Teil 38): Selbstüberwachte Erkundung bei Unstimmigkeit (Self-Supervised Exploration via Disagreement)
Eines der Hauptprobleme beim Verstärkungslernen ist die Erkundung der Umgebung. Zuvor haben wir bereits die Forschungsmethode auf der Grundlage der intrinsischen Neugier kennengelernt. Heute schlage ich vor, einen anderen Algorithmus zu betrachten: Erkundung bei Unstimmigkeit.

Neuronale Netze leicht gemacht (Teil 15): Datenclustering mit MQL5
Wir fahren fort mit der Betrachtung der Clustermethode. In diesem Artikel werden wir eine neue CKmeans-Klasse erstellen, um eine der gängigsten k-means-Clustermethoden zu implementieren. Während der Tests gelang es dem Modell, etwa 500 Muster zu erkennen.
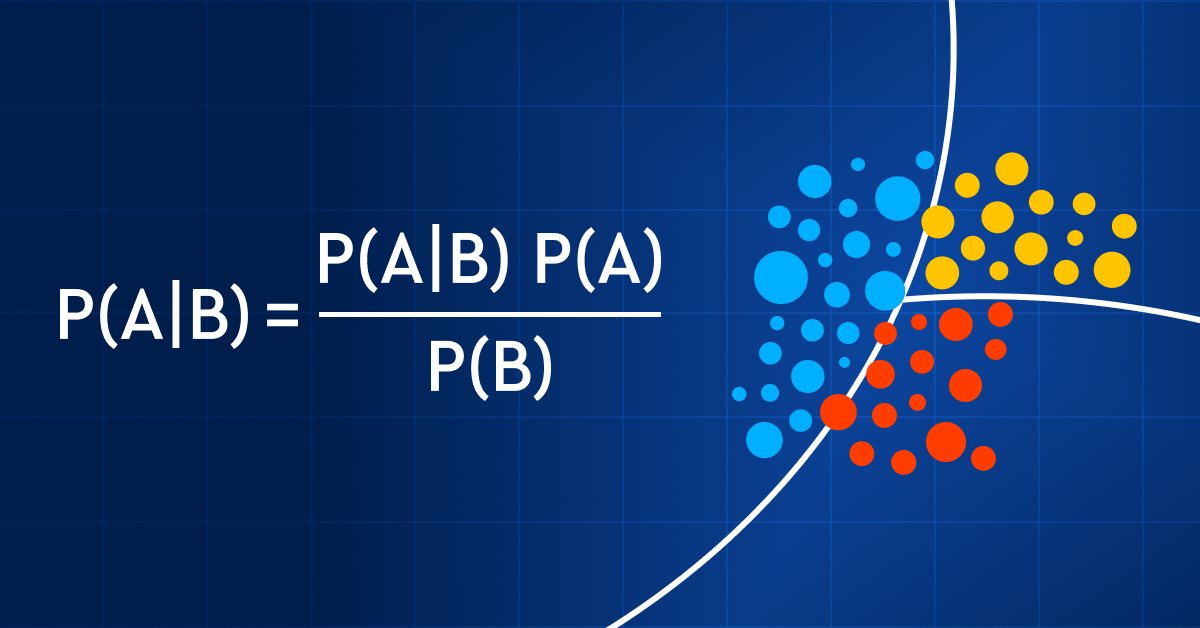
Datenwissenschaft und maschinelles Lernen (Teil 11): Naïve Bayes, Wahrscheinlichkeitsrechnung im Handel
Der Handel mit Wahrscheinlichkeiten ist wie ein Drahtseilakt - er erfordert Präzision, Ausgewogenheit und ein ausgeprägtes Risikobewusstsein. In der Welt des Handels ist die Wahrscheinlichkeit alles. Das ist der Unterschied zwischen Erfolg und Misserfolg, Gewinn und Verlust. Indem sie sich die Macht der Wahrscheinlichkeit zunutze machen, können Händler fundierte Entscheidungen treffen, Risiken effektiv verwalten und ihre finanziellen Ziele erreichen. Ob Sie nun ein erfahrener Anleger oder ein Anfänger sind, das Verständnis der Wahrscheinlichkeit ist der Schlüssel zur Entfaltung Ihres Handelspotenzials. In diesem Artikel werden wir die aufregende Welt des Handels mit Wahrscheinlichkeiten erkunden und Ihnen zeigen, wie Sie Ihr Handelsspiel auf die nächste Stufe heben können.

Neuronale Netze leicht gemacht (Teil 32): Verteiltes Q-Learning
Wir haben die Q-Learning-Methode in einem der früheren Artikel dieser Serie kennengelernt. Bei dieser Methode werden die Belohnungen für jede Aktion gemittelt. Im Jahr 2017 wurden zwei Arbeiten vorgestellt, die einen größeren Erfolg bei der Untersuchung der Belohnungsverteilungsfunktion zeigen. Wir sollten die Möglichkeit in Betracht ziehen, diese Technologie zur Lösung unserer Probleme einzusetzen.

Datenwissenschaft und maschinelles Lernen (Teil 12): Können selbstlernende neuronale Netze Ihnen helfen, den Aktienmarkt zu überlisten?
Sind Sie es leid, ständig zu versuchen, den Aktienmarkt vorherzusagen? Hätten Sie gerne eine Kristallkugel, die Ihnen hilft, fundiertere Investitionsentscheidungen zu treffen? Selbst trainierte neuronale Netze könnten die Lösung sein, nach der Sie schon lange gesucht haben. In diesem Artikel gehen wir der Frage nach, ob diese leistungsstarken Algorithmen Ihnen helfen können, „die Welle zu reiten“ und den Aktienmarkt zu überlisten. Durch die Analyse großer Datenmengen und die Erkennung von Mustern können selbst trainierte neuronale Netze Vorhersagen treffen, die oft genauer sind als die von menschlichen Händlern. Entdecken Sie, wie Sie diese Spitzentechnologie nutzen können, um Ihre Gewinne zu maximieren und intelligentere Investitionsentscheidungen zu treffen.

Algorithmen zur Optimierung mit Populationen: Differenzielle Evolution (DE)
In diesem Artikel werden wir uns mit dem Algorithmus befassen, der von allen bisher diskutierten Algorithmen die umstrittensten Ergebnisse zeigt - der Algorithmus der differentiellen Evolution (DE).

Datenwissenschaft und maschinelles Lernen (Teil 18): Der Kampf um die Beherrschung der Marktkomplexität, verkürzte SVD versus NMF
Die verkürzte Singulärwertzerlegung (Truncated Singular Value Decomposition, SVD) und die nicht-negative Matrixzerlegung (Non-Negative Matrix Factorization, NMF) sind Verfahren zur Dimensionsreduktion. Beide spielen eine wichtige Rolle bei der Entwicklung von datengesteuerten Handelsstrategien. Entdecken Sie die Kunst der Dimensionalitätsreduzierung, der Entschlüsselung von Erkenntnissen und der Optimierung quantitativer Analysen für einen fundierten Ansatz zur Navigation durch die Feinheiten der Finanzmärkte.