
Metamodelle für maschinelles Lernen und Handel: Ursprünglicher Zeitpunkt der Handelsaufträge
Einführung
Eine Besonderheit einiger Handelssysteme ist der selektive Handel, d. h. sie sind nicht ständig auf dem Markt. In den meisten Fällen ist dies auf das Vorhandensein von Mustern zu bestimmten Zeitpunkten zurückzuführen, während die Muster zu anderen Zeiten nicht vorhanden oder nicht definiert sind.
In den vorangegangenen Artikeln habe ich ausführlich die verschiedenen Möglichkeiten beschrieben, mit denen Modelle des maschinellen Lernens auf Klassifizierungsaufgaben für Zeitreihen angewendet werden können. Alle diese Modelle wurden auf der Trainingsmenge trainiert und nach dem Training zu Bots zusammengestellt. Der Prozess der Kennzeichnung des Trainingsdatensatzes und der Auswahl des besten Modells wurde so weit wie möglich automatisiert, wodurch der menschliche Faktor fast vollständig ausgeschaltet wurde. Bei aller Eleganz der vorgeschlagenen Ansätze weisen diese Modelle zwei Nachteile auf, die nur schwer zu beheben sind, ohne zusätzliche Funktionen einzuführen.
Ich habe mir vorgenommen, den Ansatz auf die Fälle auszudehnen, in denen das Modell funktioniert:
- Anpassung an den Trainingsdatensatz durch Auswahl der besten Beispiele für das Training
- Aussortieren der schwer zu klassifizierenden Teile der Zeitreihen, um sie beim Training und beim Handel auszulassen
Diese Verallgemeinerung hat mich dazu veranlasst, den Ansatz der Ausbildung teilweise zu überdenken. Es stellte sich heraus, dass die Verwendung von nur einem Klassifikator den neuen Anforderungen nicht genügt. Sie kann sich während des Trainings nicht selbst korrigieren. Daher habe ich beschlossen, die Funktionalität für die genannten Fälle zu ändern.
Theoretische Aspekte des neuen Ansatzes
Zunächst muss ich eine kleine Bemerkung machen. Da ein Forscher bei der Entwicklung von Handelssystemen (einschließlich derjenigen, die maschinelles Lernen anwenden) mit Ungewissheit zu tun hat, ist es unmöglich, den Gegenstand der Suche streng zu formalisieren. Sie können als mehr oder weniger stabile Abhängigkeiten in einem mehrdimensionalen Raum definiert werden, die in menschlichen und sogar mathematischen Sprachen schwer zu interpretieren sind. Es ist schwierig, eine detaillierte Analyse dessen durchzuführen, was wir von hoch parametrisierten Selbstlernsystemen erhalten. Solche Algorithmen setzen ein gewisses Vertrauen des Händlers in die Ergebnisse von Backtests voraus, klären aber nicht das eigentliche Wesen und sogar die Art des gefundenen Musters.
Ich möchte einen Algorithmus schreiben, der in der Lage ist, seine eigenen Fehler zu analysieren und zu korrigieren und so seine Ergebnisse iterativ zu verbessern. Dazu schlage ich vor, eine Gruppe von zwei Klassifikatoren zu nehmen und sie nacheinander zu trainieren, wie im folgenden Diagramm vorgeschlagen. Eine ausführliche Beschreibung der Idee finden Sie weiter unten.
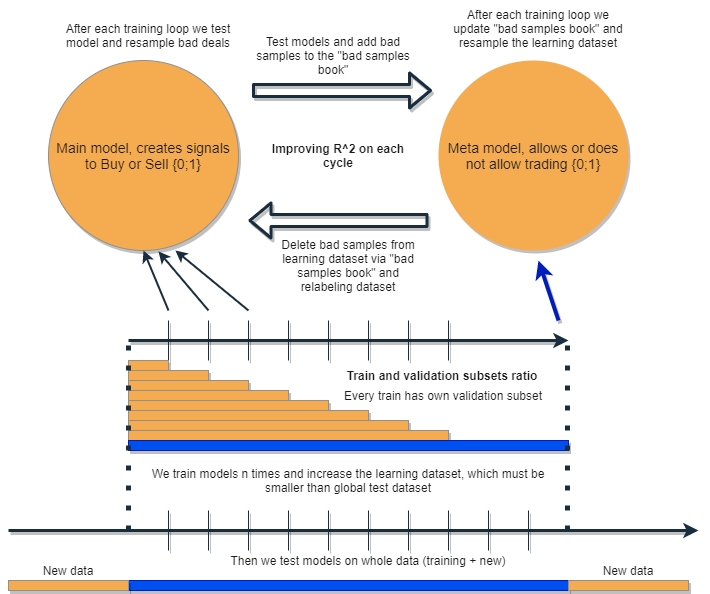
Jeder der Klassifikatoren wird auf einem eigenen Datensatz trainiert, der eine eigene Größe hat. Die blaue horizontale Linie stellt die bedingte historische Tiefe für das Metamodell dar, und die orangefarbenen Linien stehen für das Basismodell. Mit anderen Worten: Die Tiefe der Geschichte für ein Metamodell ist immer größer als für das Basismodell und entspricht dem geschätzten (Test-)Zeitintervall, in dem die Kombination dieser Modelle getestet wird.
Das Bündel von Modellen wird mehrmals neu trainiert, wobei der Trainingsdatensatz für das Basismodell schrittweise vergrößert werden kann (die Länge der orangefarbenen Spalten wird bei jeder neuen Iteration vergrößert), aber seine Länge sollte die Länge der blauen Spalte nicht überschreiten. Nach jeder Iteration werden alle Beispiele, die vom Metamodell als falsch (oder Null) eingestuft wurden, aus der Trainingsstichprobe des Basismodells entfernt. Das Metamodell wiederum wird auf allen Beispielen weiter trainiert.
Die Intuition, die hinter diesem Ansatz steht, ist, dass Verlustgeschäfte Klassifizierungsfehler der Klasse I für das zugrunde liegende Modell gemäß der Terminologie der Konfusionsmatrix sind. Mit anderen Worten: Diese Fälle werden als falsch positiv eingestuft. Das Metamodell filtert solche Fälle heraus und vergibt eine Punktzahl von 1 für echte positive Ergebnisse und 0 für alle anderen. Indem wir den Datensatz für das Training des Basismodells über das Metamodell sortieren, erhöhen wir dessen Präzision, d. h. die Anzahl der korrekten Kauf- und Verkaufsauslöser. Gleichzeitig erhöht das Metamodell seinen Recall (Vollständigkeit), indem es so viele verschiedene Ergebnisse wie möglich klassifiziert.
Je höher die Genauigkeit ist, desto genauer ist das Modell. In realen Situationen führt jedoch die Verbesserung eines Indikators zu einer Verschlechterung eines anderen Indikators innerhalb desselben Klassifizierers, sodass die Verwendung eines Bündels von zwei Klassifizierern eine interessante Idee darstellt, die zu einer Verbesserung beider Indikatoren führt.
Die Idee ist, dass die beiden Modelle auf denselben Attributen trainiert werden und daher eine zusätzliche Interaktion stattfindet. Aufgrund der erhöhten Auswahl für das Metamodell (blaue horizontale Säule im Vergleich zu den orangenen), lässt es gute Handelssituationen, als ob es die Fehler des Basismodells auf neuen Daten aussortiert. Indem sie miteinander interagieren, verbessern sich die Modelle iterativ durch erneute Kennzeichnung (relabeling), und der R^2-Wert auf der Validierungsmenge nimmt ständig zu. Das Metamodell kann jedoch auf seine eigenen Attribute als Filter für das Basismodell trainiert werden. Eine solche Verbindung passt nicht ganz in den Rahmen des vorgeschlagenen Ansatzes und wird daher hier nicht berücksichtigt.
Das Basismodell sollte aufgrund der ständigen „Wartung“ des Metamodells gut funktionieren, aber das Metamodell selbst kann auch falsch sein. Bei der ersten Iteration wurden zum Beispiel Fälle aufgedeckt, die sich nicht für den Handel eignen. In der zweiten Iteration, nachdem das Basismodell neu trainiert und die Beispiele für das Metamodell angepasst wurden, können sich schlechte Beispiele von denen der vorherigen Iteration unterscheiden. Aus diesem Grund kann das Metamodell dazu neigen, Beispiele, die sich von Iteration zu Iteration unterscheiden, ständig neu zu benennen. Dieses Verhalten darf niemals das Gleichgewicht erreichen. Um dieses Manko zu beheben, erstellen wir die Tabelle „Bad Samples Book“ (Buch mit schlechten Beispielen), die mit Beispielen aus allen früheren Iterationen aktualisiert wird. Genauer gesagt, speichert es die Merkmalswerte zu Zeiten, die in allen vorherigen Trainingsiterationen als schlecht für den Handel markiert wurden. Auf diese Weise kann der Datensatz des Metamodells vor jeder Umschulung so aktualisiert werden, dass alle erfolglosen Momente aus früheren Iterationen ebenfalls als schlecht (Nullen) markiert werden.
Das „Bad Samples Book“ hat auch seinen Nachteil, da bei zu vielen Iterationen zu viele Nullen (Bad Trades) hinzugefügt werden. Die Anzahl der Beispiele wird bei jeder neuen Trainingsiteration deutlich abnehmen. Daher ist es notwendig, ein Gleichgewicht zwischen der Anzahl der Iterationen und der Anzahl der Beispiele zu finden, die dem Buch der schlechten Beispiele hinzugefügt werden. Die Situation kann teilweise gelöst werden, indem die Anzahl der schlechten Beispiele in Abhängigkeit vom Zeitpunkt ihres Auftretens gemittelt und nur die häufigsten sortiert werden. Der Metamodell-Datensatz wird in diesem Fall nicht degenerieren (das Gleichgewicht zwischen Nullen und Einsen bleibt erhalten). Ein Oversampling wäre sinnvoll, wenn sich die Klassen als sehr unausgewogen erweisen.
Nach mehreren Iterationen wird diese Gruppe von Modellen hervorragende Ergebnisse bei Trainings- und Validierungsdaten zeigen. Außerdem wird das Ergebnis von Iteration zu Iteration besser. Nach dem Training sollten die Modelle an völlig neuen Daten getestet werden, die sowohl zu einem früheren als auch zu einem späteren Zeitpunkt als die Trainingsstichprobe liegen können. Es gibt keine Theorie, die eine eindeutige Aussage darüber zulässt, welcher Teil der Geschichte für Tests an nicht-stationären Finanzzeitreihen gewählt werden sollte. Dennoch erwarte ich eine Verbesserung der Leistung des vorgeschlagenen Ansatzes bei neuen Daten, während die Praxis den Rest zeigen wird.
Wir trainieren also ein einzelnes Modell, korrigieren seine Fehler auf neuen Daten mit einem anderen Modell und wiederholen diesen Vorgang mehrere Male. Warum sollte dies die Robustheit der Klassifikatoren bei neuen Daten erhöhen? Auf diese Frage gibt es keine einheitliche Antwort. Es wird davon ausgegangen, dass wir es mit einer Art Muster zu tun haben. Wenn es ein solches Muster gibt, wird es gefunden, und Situationen ohne Muster werden aussortiert. Wenn das Muster stabil ist, funktioniert das Modell auch bei neuen Daten.
Theoretisch sollte dieser Ansatz zwei Fliegen mit einer Klappe schlagen:
- eine hohe Erwartung an gewinnbringende Positionen bieten
- automatisches „Timing“ des Handelssystems, wobei nur zu bestimmten, besonders effektiven Zeitpunkten gehandelt wird
Da wir gerade über das Timing des Handelssystems sprechen, sollten wir einen weiteren interessanten Punkt ansprechen. Jetzt ist die Abhängigkeit von der Wahl der Attribute (Merkmale) für das Modell geringer.
Der grundlegende Ansatz und die überwachte Aufbereitung erfordern eine sorgfältige Auswahl der Prädiktoren und Ziele. Dies ist in der Tat das Hauptproblem dieses Ansatzes. Datenaufbereitung und -analyse haben immer oberste Priorität, während die Qualität der Modelle direkt von der Professionalität des Analysten in einem bestimmten Bereich (in unserem Fall FOREX) abhängt.
Der vorgeschlagene Ansatz sollte automatisch zusammenhängende Timing-, Prädiktor- und Label-Ereignisse finden und die automatisch gefundenen Muster ausnutzen. Die Auswahl der Prädiktoren und die Kennzeichnung der Geschäfte erfolgen automatisch. Es müssen noch eine Reihe von Bedingungen erfüllt werden: So sollten die Attribute stationär sein und zumindest einen indirekten Bezug zu dem Finanzinstrument haben. Aber in einer Situation, in der uns die wahren Muster nicht bekannt sind und es keine Möglichkeit gibt, Informationen zu erhalten, scheint dieser Ansatz gerechtfertigt.
Wenn wir mit „garbage“-Attributen arbeiten, die in keinem kausalen Zusammenhang mit Geschäften stehen, funktioniert der Algorithmus natürlich nach dem Zufallsprinzip. Dies ist jedoch bereits eine Frage des Vorhandenseins bzw. Nichtvorhandenseins von Ursache-Wirkungs-Beziehungen als solche. Dieser Artikel befasst sich bewusst nicht mit der Konstruktion von anderen Merkmalen als Inkrementen (der Differenz zwischen einem gleitenden Durchschnitt und einem Preis), da dies ein separates großes Thema ist, das in anderen Artikeln behandelt werden kann. Es wird davon ausgegangen, dass der analytische Ansatz bei der Auswahl informativer Merkmale die Stabilität des Algorithmus bei neuen Daten deutlich erhöhen sollte.
Praktische Umsetzung des vorgeschlagenen Ansatzes
Wie immer sieht in der Theorie alles wunderbar aus. Prüfen wir nun, welche Wirkung ein Bündel von zwei Klassifikatoren tatsächlich erzielen kann. Dazu müssen wir den Code noch einmal neu schreiben.
Die Funktion der automatischen Markierung von Geschäften
Ich habe einige Änderungen vorgenommen. Nun ist es möglich, die Kennzeichnungen für die Basismodelle auf der Grundlage der Metamodell-Labels erneut vorzunehmen:
def labelling_relabeling(dataset, min=15, max=15, relabeling=False) -> pd.DataFrame: labels = [] for i in range(dataset.shape[0]-max): rand = random.randint(min, max) curr_pr = dataset['close'][i] future_pr = dataset['close'][i + rand] if relabeling: m_labels = dataset['meta_labels'][i:rand+1].values if relabeling and 0.0 in m_labels: labels.append(2.0) else: if future_pr + MARKUP < curr_pr: labels.append(1.0) elif future_pr - MARKUP > curr_pr: labels.append(0.0) else: labels.append(2.0) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() dataset = dataset.drop( dataset[dataset.labels == 2].index) return dataset
Der hervorgehobene Code prüft, ob das Flag der erneuten Kennzeichnung vorhanden ist. Wenn es True ist und die Metatags des aktuellen Handelshorizonts Nullen enthalten, dann lehnt das Metamodell den Handel in diesem Abschnitt ab. Dementsprechend werden solche Geschäfte als 2.0 markiert und aus dem Datensatz entfernt. Auf diese Weise können wir iterativ unnötige Stichproben aus der Trainingsstichprobe für das Basismodell entfernen und so den Fehler beim Training reduzieren.
Nutzerdefinierte Prüffunktion
Jetzt gibt es eine erweiterte Funktionalität, die es uns ermöglicht, zwei Modelle gleichzeitig zu testen (Basis- und Metamodell). Außerdem kann der nutzerdefinierte Tester nun die Labels für das Metamodell neu beschriften, um es bei der nächsten Iteration zu verbessern.
def tester(dataset: pd.DataFrame, markup=0.0, use_meta=False, plot=False): last_deal = int(2) last_price = 0.0 report = [0.0] meta_labels = dataset['labels'].copy() for i in range(dataset.shape[0]): pred = dataset['labels'][i] meta_labels[i] = np.nan if use_meta: pred_meta = dataset['meta_labels'][i] # 1 = allow trades if last_deal == 2 and ((use_meta and pred_meta==1) or not use_meta): last_price = dataset['close'][i] last_deal = 0 if pred <= 0.5 else 1 continue if last_deal == 0 and pred > 0.5 and ((use_meta and pred_meta==1) or not use_meta): last_deal = 2 report.append(report[-1] - markup + (dataset['close'][i] - last_price)) if report[-1] > report[-2]: meta_labels[i] = 1 else: meta_labels[i] = 0 continue if last_deal == 1 and pred < 0.5 and ((use_meta and pred_meta==1) or not use_meta): last_deal = 2 report.append(report[-1] - markup + (last_price - dataset['close'][i])) if report[-1] > report[-2]: meta_labels[i] = 1 else: meta_labels[i] = 0 y = np.array(report).reshape(-1, 1) X = np.arange(len(report)).reshape(-1, 1) lr = LinearRegression() lr.fit(X, y) l = lr.coef_ if l >= 0: l = 1 else: l = -1 if(plot): plt.plot(report) plt.plot(lr.predict(X)) plt.title("Strategy performance R^2 " + str(format(lr.score(X, y) * l,".2f"))) plt.xlabel("the number of trades") plt.ylabel("cumulative profit in pips") plt.show() return lr.score(X, y) * l, meta_labels.fillna(method='backfill')
Die Prüfung funktioniert wie folgt.
Wenn das Flag für die Berücksichtigung des Metamodells bei der Prüfung gesetzt ist, wird die Bedingung für das Vorhandensein seines Signals (Eins) geprüft. Liegt das Signal vor, darf das Basismodell Geschäfte eröffnen und schließen, andernfalls wird nicht gehandelt. Die hellgrüne Markierung hebt das Hinzufügen neuer Bezeichnungen für das Metamodell in Abhängigkeit vom Ergebnis eines abgeschlossenen Geschäfts hervor. Wenn das Ergebnis positiv ist, wird eine Eins hinzugefügt. Andernfalls wird das Geschäft als 0 (erfolglos) markiert.
Brute-Force-Funktion
Hier wurden die größten Änderungen vorgenommen. Ich werde sie in der Darstellung mit verschiedenen Farben markieren und zum besseren Verständnis beschreiben.
def brute_force(dataset, bad_samples_fraction=0.5): # features for model\meta models. We learn main model only on filtered labels X = dataset[dataset['meta_labels']==1] X = dataset[dataset.columns[:-2]] X = X[X.index >= START_DATE] X = X[X.index <= STOP_DATE] X_meta = dataset[dataset.columns[:-2]] X_meta = X_meta[X_meta.index >= TSTART_DATE] X_meta = X_meta[X_meta.index <= STOP_DATE] # labels for model\meta models y = dataset[dataset['meta_labels']==1] y = dataset[dataset.columns[-2]] y = y[y.index >= START_DATE] y = y[y.index <= STOP_DATE] y_meta = dataset[dataset.columns[-1]] y_meta = y_meta[y_meta.index >= TSTART_DATE] y_meta = y_meta[y_meta.index <= STOP_DATE] # train\test split train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.5, test_size=0.5, shuffle=True,) # learn main model with train and validation subsets model = CatBoostClassifier(iterations=1000, depth=6, learning_rate=0.1, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU', random_seed=13) model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=50, plot=False) # train\test split train_X, test_X, train_y, test_y = train_test_split( X_meta, y_meta, train_size=0.5, test_size=0.5, shuffle=True) # learn meta model with train and validation subsets meta_model = CatBoostClassifier(iterations=1000, depth=6, learning_rate=0.1, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU', random_seed=13) meta_model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=50, plot=False) # predict on new data (validation plus learning) pr_tst = get_prices() X = pr_tst[pr_tst.columns[1:]] X.columns = [''] * len(X.columns) X_meta = X.copy() # predict the learned models (base and meta) p = model.predict_proba(X) p_meta = meta_model.predict_proba(X_meta) p2 = [x[0] < 0.5 for x in p] p2_meta = [x[0] < 0.5 for x in p_meta] pr2 = pr_tst.iloc[:len(p2)].copy() pr2['labels'] = p2 pr2['meta_labels'] = p2_meta pr2['labels'] = pr2['labels'].astype(float) pr2['meta_labels'] = pr2['meta_labels'].astype(float) full_pr = pr2.copy() pr2 = pr2[pr2.index >= TSTART_DATE] pr2 = pr2[pr2.index <= STOP_DATE] # add bad samples of this iteratin (bad meta labels) global BAD_SAMPLES_BOOK BAD_SAMPLES_BOOK = BAD_SAMPLES_BOOK.append(pr2[pr2['meta_labels']==0.0].index) # test mdels and resample meta labels R2, meta_labels = tester(pr2, MARKUP, use_meta=True, plot=False) pr2['meta_labels'] = meta_labels # resample labels based on meta labels pr2 = labelling_relabeling(pr2, relabeling=True) pr2['labels'] = pr2['labels'].astype(float) pr2['meta_labels'] = pr2['meta_labels'].astype(float) # mark bad labels from bad_samples_book if BAD_SAMPLES_BOOK.value_counts().max() > 1: to_mark = BAD_SAMPLES_BOOK.value_counts() mean = to_mark.mean() marked_idx = to_mark[to_mark > mean*bad_samples_fraction].index pr2.loc[pr2.index.isin(marked_idx), 'meta_labels'] = 0.0 else: pr2.loc[pr2.index.isin(BAD_SAMPLES_BOOK), 'meta_labels'] = 0.0 R2, _ = tester(full_pr, MARKUP, use_meta=True, plot=False) return [R2, model, meta_model, pr2]
BAD_SAMPLES_BOOK und der Rest des mit der entsprechenden Markierung hervorgehobenen Codes ist für die Implementierung des schlechten Musterbuchs verantwortlich. Bei jeder neuen Iteration der Umschulung der beiden Modelle wird es mit neuen Beispielen von erfolglosen Geschäften aufgefüllt, die von den vorherigen Modellen eröffnet wurden, nachdem sie trainiert wurden. Die Überprüfung erfolgt mit dem Tester.
Der letzte hervorgehobene Block kann flexibel konfiguriert werden, je nachdem, welcher Teil der fehlgeschlagenen Beispiele bei der nächsten Umschulung als 0 markiert werden soll. Standardmäßig wird der Durchschnitt aller Duplikate für jedes in der Arbeitsmappe enthaltene Datum berechnet.
marked_idx = to_mark[to_mark > mean*bad_samples_fraction].index Dies geschieht, damit nicht alle schlechten Daten entfernt werden können, sondern nur die, bei denen das Modell die meisten Fehler gemacht hat, während es alle Trainingsiterationen durchlief. Je größer der Wert des Parameters bad_samples_fraction ist, desto weniger schlechte Daten werden entfernt und umgekehrt.
Die blaue Farbe bedeutet, dass ein verkürzter Teil des Datensatzes ab START_DATE für das Basismodell verwendet wird. Frühere Daten nehmen nicht an seiner Ausbildung teil. Sie ist jedoch an der Ausbildung des Metamodells beteiligt. Außerdem zeigt diese Farbe, dass zwei verschiedene Modelle trainiert werden - Base und Meta.
Die rosa Farbe hebt den Teil hervor, in dem die Vorhersagen beider Modelle extrahiert werden. Mit Hilfe dieser Vorhersagen wird ein neuer Datensatz gebildet. Der Datensatz wird weiter durch den Code geschoben. Die Kennzeichnungen der schlechten Metamodelle werden auch dem Buch mit den schlechten Beispielen hinzugefügt.
Danach werden beide Modelle im nutzerdefinierten Tester getestet, der zusätzlich die Metamodell-Labels für die nächste Trainingsiteration neu kennzeichnet (anpasst). Für das Basismodell wird auf dem korrigierten Datensatz ein weiteres Relabeling durchgeführt.
In der letzten Phase wird der Datensatz zusätzlich mit Hilfe des Buches der schlechten Proben angepasst und von der Funktion für die nächste Trainingsiteration zurückgegeben.
Trotz der Fülle an Python-Code arbeitet es schnell, da es keine verschachtelten Schleifen gibt und eine Optimierung durchgeführt wurde. Das Training von CatBoost-Klassifikatoren nimmt die meiste Zeit in Anspruch. Die Trainingszeit steigt mit der Anzahl der Attribute und der Länge des Datensatzes.
Iterative Umschulung von Modellen
Dies waren die wichtigsten Details des neuen Konzepts. Nun ist es an der Zeit, mit dem Trainingszyklus des Modells fortzufahren. Schauen wir uns einmal an, was in den einzelnen Phasen passiert.
# make dataset
pr = get_prices()
pr = labelling_relabeling(pr, relabeling=False)
a, b = tester(pr, MARKUP, use_meta=False, plot=False)
pr['meta_labels'] = b
pr = pr.dropna()
pr = labelling_relabeling(pr, relabeling=True)
# iterative learning
res = []
BAD_SAMPLES_BOOK = pd.DatetimeIndex([])
for i in range(25):
res.append(brute_force(pr[pr.columns[1:]], bad_samples_fraction=0.7))
print('Iteration: {}, R^2: {}'.format(i, res[-1][0]))
pr = res[-1][3]
Mit den ersten beiden Zeichenfolgen wird einfach der Trainingsdatensatz erstellt, genau wie in den Beispielen aus den vorherigen Artikeln.
>>> pr = get_prices(START_DATE, STOP_DATE) >>> pr = labelling_relabeling(pr, relabeling=False) >>> pr close 0 1 2 3 4 5 6 labels time 2020-05-06 20:00:00 1.08086 0.000258 -0.000572 -0.001667 -0.002396 -0.004554 -0.007759 -0.009549 1.0 2020-05-06 21:00:00 1.08032 -0.000106 -0.000903 -0.002042 -0.002664 -0.004900 -0.008039 -0.009938 1.0 2020-05-06 22:00:00 1.07934 -0.001020 -0.001568 -0.002788 -0.003494 -0.005663 -0.008761 -0.010778 1.0 2020-05-06 23:00:00 1.07929 -0.000814 -0.001319 -0.002624 -0.003380 -0.005485 -0.008559 -0.010684 1.0 2020-05-07 00:00:00 1.07968 -0.000218 -0.000689 -0.002065 -0.002873 -0.004894 -0.007929 -0.010144 1.0 ... ... ... ... ... ... ... ... ... ... 2021-04-13 23:00:00 1.19474 0.000154 0.002590 0.003375 0.003498 0.004095 0.004273 0.004888 0.0 2021-04-14 00:00:00 1.19492 0.000108 0.002337 0.003398 0.003565 0.004183 0.004410 0.005001 0.0 2021-04-14 01:00:00 1.19491 -0.000038 0.002023 0.003238 0.003433 0.004076 0.004353 0.004908 0.0 2021-04-14 02:00:00 1.19537 0.000278 0.002129 0.003534 0.003780 0.004422 0.004758 0.005286 0.0 2021-04-14 03:00:00 1.19543 0.000356 0.001783 0.003423 0.003700 0.004370 0.004765 0.005259 0.0 [5670 rows x 9 columns]
Nun müssen wir Kennzeichnungen für das Metamodell hinzufügen. Wie Sie sich vielleicht erinnern, gibt die Funktion tester() den R^2-Wert und einen Rahmen mit gekennzeichneten Geschäften zurück. Daher führen wir den Tester aus und fügen das resultierende Bild zu den Originaldaten hinzu.
>>> a, b = tester(pr, MARKUP, use_meta=False, plot=False) >>> pr['meta_labels'] = b >>> pr = pr.dropna() >>> pr close 0 1 2 ... 5 6 labels meta_labels time ... 2020-05-06 20:00:00 1.08086 0.000258 -0.000572 -0.001667 ... -0.007759 -0.009549 1.0 1.0 2020-05-06 21:00:00 1.08032 -0.000106 -0.000903 -0.002042 ... -0.008039 -0.009938 1.0 1.0 2020-05-06 22:00:00 1.07934 -0.001020 -0.001568 -0.002788 ... -0.008761 -0.010778 1.0 1.0 2020-05-06 23:00:00 1.07929 -0.000814 -0.001319 -0.002624 ... -0.008559 -0.010684 1.0 1.0 2020-05-07 00:00:00 1.07968 -0.000218 -0.000689 -0.002065 ... -0.007929 -0.010144 1.0 1.0 ... ... ... ... ... ... ... ... ... ... 2021-04-13 18:00:00 1.19385 0.001442 0.003437 0.003198 ... 0.003637 0.004279 0.0 1.0 2021-04-13 19:00:00 1.19379 0.000546 0.003121 0.003015 ... 0.003522 0.004166 0.0 1.0 2021-04-13 20:00:00 1.19423 0.000622 0.003269 0.003349 ... 0.003904 0.004555 0.0 1.0 2021-04-13 21:00:00 1.19465 0.000820 0.003315 0.003640 ... 0.004267 0.004929 0.0 1.0 2021-04-13 22:00:00 1.19552 0.001112 0.003733 0.004311 ... 0.005092 0.005733 1.0 1.0 [5665 rows x 10 columns]
Die Daten sind nun bereit für das Training. Wir können eine zusätzliche Umetikettierung der Hauptkennzeichen („labels“) entsprechend den zweiten Kennzeichen („meta_labels“) vornehmen. Mit anderen Worten, wir können alle Geschäfte, die sich als unrentabel erwiesen haben, aus dem Datensatz entfernen.
pr = labelling_relabeling(pr, relabeling=True) Die Daten sind fertig, nun wollen wir uns den Trainingszyklus der beiden Modelle ansehen.
# iterative learning
res = []
BAD_SAMPLES_BOOK = pd.DatetimeIndex([])
for i in range(25):
res.append(brute_force(pr[pr.columns[1:]], bad_samples_fraction=0.7))
print('Iteration: {}, R^2: {}'.format(i, res[-1][0]))
pr = res[-1][3]
Zunächst müssen wir das Buch der schlechten Geschäfte zurücksetzen, wenn nach der letzten Schulung noch etwas darin steht. Anschließend wird die erforderliche Anzahl von Iterationen in der Schleife festgelegt. Bei jeder Iteration werden die verschachtelten Listen mit den gespeicherten Modellen (und alles andere, was die Funktion brute_force() zurückgibt) in die Liste res[] geschrieben. Zum Beispiel können wir zusätzlich die wichtigsten Metriken der Modelle bei jeder Iteration ausgeben.
Die Variable pr enthält den konvertierten und zurückgegebenen Datensatz, der bei der nächsten Iteration zum Training verwendet wird.
Es ist möglich, die Trainingszeit des Basismodells zu erhöhen, wie im theoretischen Teil vorgeschlagen. Zu diesem Zweck wird das Datum des Ausbildungsbeginns um die angegebene Anzahl von Tagen verschoben. Gleichzeitig sollte seine Größe die Größe des TSTART_DATE-Intervalls, auf dem das Metamodell trainiert wird, nicht überschreiten.
Nach dem Start des Trainings sehen Sie etwas, das dem folgenden Bild ähnelt:
Iteration: 0, R^2: 0.30121038659012245 Iteration: 1, R^2: 0.7400055934041012 Iteration: 2, R^2: 0.6221261327516192 Iteration: 3, R^2: 0.8892813889403367 Iteration: 4, R^2: 0.787251984980149 Iteration: 5, R^2: 0.794241109825588 Iteration: 6, R^2: 0.9167876214355855 Iteration: 7, R^2: 0.903399695678254 Iteration: 8, R^2: 0.8273236332747745 Iteration: 9, R^2: 0.8646088124681762 Iteration: 10, R^2: 0.8614746864767437 Iteration: 11, R^2: 0.7900599001415054 Iteration: 12, R^2: 0.8837049280116869 Iteration: 13, R^2: 0.784793801426211 Iteration: 14, R^2: 0.941340102099874 Iteration: 15, R^2: 0.8715065229034792 Iteration: 16, R^2: 0.8104990158946458 Iteration: 17, R^2: 0.8542444489379808 Iteration: 18, R^2: 0.8307365677342298 Iteration: 19, R^2: 0.9092509787525882
Der erste Durchlauf ist in der Regel nicht sehr gut. Dann versucht das Modell, sich mit jedem neuen Durchgang zu verbessern. Die Modelle werden dann in aufsteigender R^2-Reihenfolge sortiert und können anhand neuer Daten getestet werden. Wir können uns zunächst die Entwicklung der Modelle ansehen, anstatt gleich eine Sortierung vorzunehmen. Ein charakteristisches Zeichen für die Entwicklung ist der Rückgang der Anzahl von Geschäften beim Testen von Modellen.
Ich habe zum Beispiel das letzte trainierte Modell getestet und folgendes Ergebnis erhalten (alle Ergebnisse basieren auf neuen Daten):
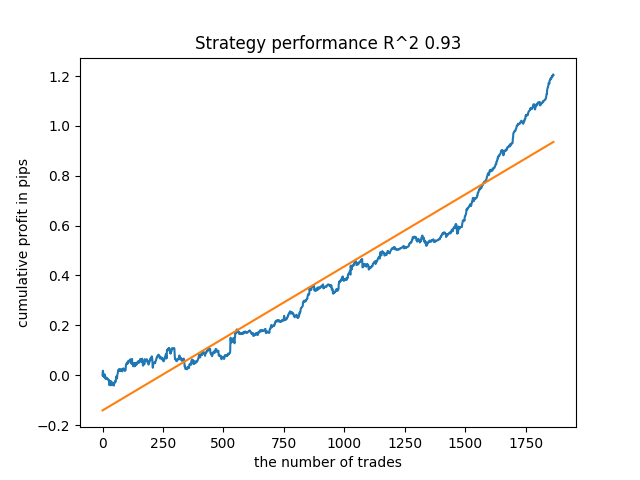
Das fünfte Modell von hinten wird mehr Angebote haben, und so weiter:
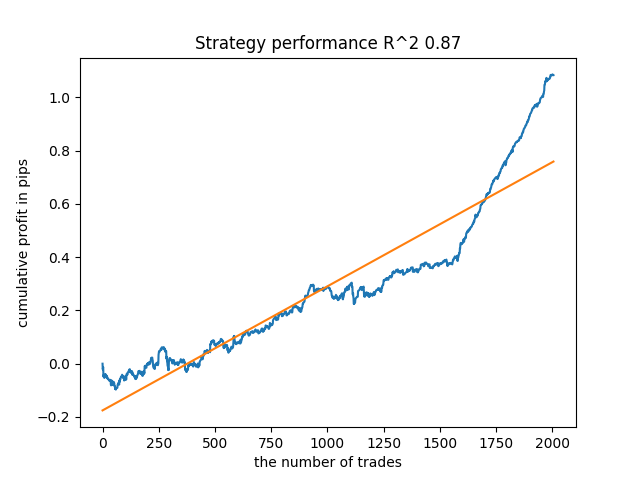
Abhängig von der Anzahl der Iterationen und dem Parameter bad_samples_fraction sowie von der Größe der Trainings- und Teststichproben können wir Modelle erhalten, die auf neuen Daten stabil sind. Im Großen und Ganzen erwies sich die Idee als funktionsfähig, wenn auch recht schwierig zu verstehen und umzusetzen. Ungefähr die gleiche Situation trat mit dem aktivierten Parameter use_GMM_resampling auf. Die Anzahl der Geschäfte hängt direkt von der Anzahl der Iterationen ab, aber es kann auch Ausnahmen geben. Ich habe das Resampling aus der Bibliothek entfernt, da es zu viel Trainingszeit beansprucht und die Ergebnisse bei der Anwendung des Ansatzes nicht wesentlich verbessert hat.
Mir hat zum Beispiel das fünfte Ergebnis vom Ende her gefallen:
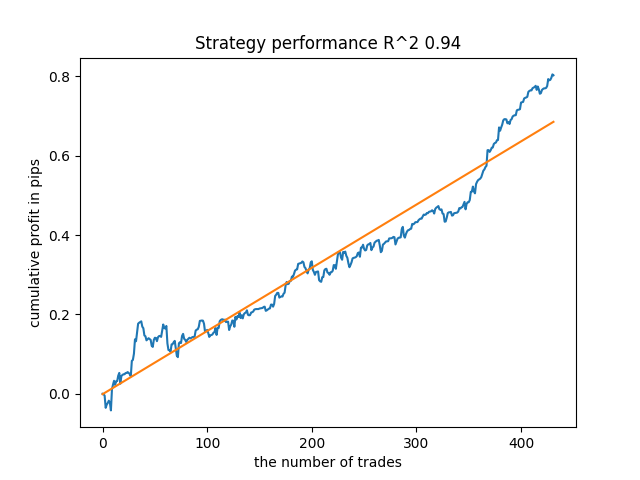
Das siebte Ergebnis erwies sich jedoch als vorteilhafter, was die Zahl der Positionen anbelangt, die doppelt so hoch ausfiel. Der Gesamtgewinn in Punkten ist ebenfalls gestiegen:
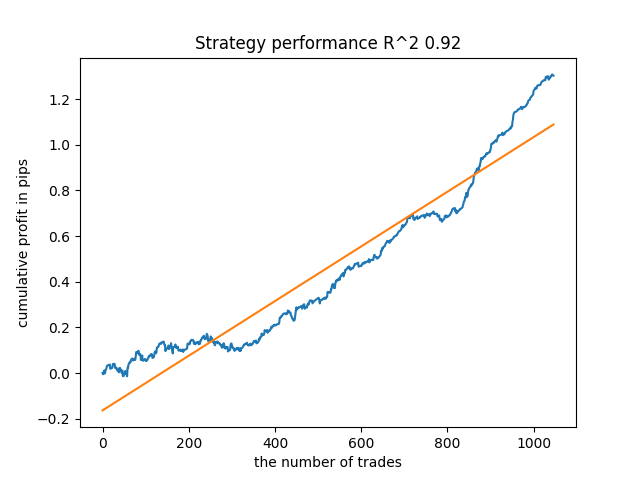
Exportieren von Modellen in das MQL5-Format und Kompilieren eines Handels-EAs
Die beiden Modelle sind nun zu speichern: Basis- und Metamodell. Wie bisher steuert das Basismodell Kauf- und Verkaufssignale, während das Metamodell den Handel zu bestimmten Zeitpunkten verbietet oder erlaubt.
# add CatBosst base model code += 'double catboost_model' + '(const double &features[]) { \n' code += ' ' with open('catmodel.h', 'r') as file: data = file.read() code += data[data.find("unsigned int TreeDepth") :data.find("double Scale = 1;")] code += '\n\n' code += 'return ' + \ 'ApplyCatboostModel(features, TreeDepth, TreeSplits , BorderCounts, Borders, LeafValues); } \n\n' # add CatBosst meta model code += 'double catboost_meta_model' + '(const double &features[]) { \n' code += ' ' with open('meta_catmodel.h', 'r') as file: data = file.read() code += data[data.find("unsigned int TreeDepth") :data.find("double Scale = 1;")] code += '\n\n' code += 'return ' + \ 'ApplyCatboostModel(features, TreeDepth, TreeSplits , BorderCounts, Borders, LeafValues); } \n\n'
Der Handels-EA wurde leicht verändert. Die Funktion catboost_meta_model(), die ein Signal erzeugt, wird aufgerufen. Liegt er über 0,5, ist der Handel erlaubt.
void OnTick() { //--- if(!isNewBar()) return; TimeToStruct(TimeCurrent(), hours); double features[]; fill_arays(features); if(ArraySize(features) !=ArraySize(MAs)) { Print("No history availible, will try again on next signal!"); return; } double sig = catboost_model(features); double meta_sig = catboost_meta_model(features); // close positions by an opposite signal if(meta_sig > 0.5) if(count_market_orders(0) || count_market_orders(1)) for(int b = OrdersTotal() - 1; b >= 0; b--) if(OrderSelect(b, SELECT_BY_POS) == true) { if(OrderType() == 0 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig > 0.5) if(OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red)) { } if(OrderType() == 1 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig < 0.5) if(OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red)) { } } // open positions and pending orders by signals if(meta_sig > 0.5) if(countOrders() == 0 && CheckMoneyForTrade(_Symbol,LotsOptimized(),ORDER_TYPE_BUY)) { double l = LotsOptimized(); if(sig < 0.5) { OrderSend(Symbol(),OP_BUY,l, Ask, 0, Bid-stoploss*_Point, Ask+takeprofit*_Point, NULL, OrderMagic); } else { OrderSend(Symbol(),OP_SELL,l, Bid, 0, Ask+stoploss*_Point, Bid-takeprofit*_Point, NULL, OrderMagic); } } }
Ergänzungen
Für MAC- und Linux-Benutzer ist die Terminal-API zum Laden von Kursen nicht verfügbar. Ich schlage vor, eine andere Funktion zu verwenden, die die vom MetaTrader 5-Terminal in eine Datei geladenen Kurse akzeptiert. Die Datei sollte im Arbeitsverzeichnis gespeichert werden.
def get_prices() -> pd.DataFrame:
p = pd.read_csv('EURUSDMT5.csv', delim_whitespace=True)
pFixed = pd.DataFrame(columns=['time', 'close'])
pFixed['time'] = p['<DATE>'] + ' ' + p['<TIME>']
pFixed['time'] = pd.to_datetime(pFixed['time'], infer_datetime_format=True)
pFixed['close'] = p['<CLOSE>']
pFixed.set_index('time', inplace=True)
pFixed.index = pd.to_datetime(pFixed.index, unit='s')
pFixed = pFixed.dropna()
pFixedC = pFixed.copy()
count = 0
for i in MA_PERIODS:
pFixed[str(count)] = pFixedC - pFixedC.rolling(i).mean()
count += 1
return pFixed.dropna()
Es werden jetzt drei Daten verwendet. Damit ist es nun möglich, Modelle sowohl nach Rückwärts- als auch nach Vorwärtstests zu sortieren. Der Beginn des Termins wird durch die globale Variable STOP_DATE festgelegt. Die Daten nach diesem Datum werden nicht für die Ausbildung verwendet. Stattdessen wird es in Tests verwendet. In ähnlicher Weise ist alles vor TSTART_DATE ein Backtest.
START_DATE = datetime(2021, 1, 1) TSTART_DATE = datetime(2017, 1, 1) STOP_DATE = datetime(2022, 1, 1)
Beachten Sie, dass das Basismodell für den Zeitraum START_DATUM - STOPP_DATUM trainiert wird, während das Metamodell für die Daten TSTART_DATUM - STOPP_DATUM trainiert wird. Alle anderen Daten, die in der Datei verbleiben, nehmen nur an Back- und Forward-Tests teil.
Einige weitere Tests
Ich beschloss, die vorgeschlagene Trainingsmethode an einigen Cross-Rates zu testen, zum Beispiel GBPJPY H1. Kurse aus dem Jahr 2010 wurden vom Terminal heruntergeladen. Die Anzahl der Attribute und Zeiträume für die Ausbildung sind wie folgt:
MA_PERIODS = [i for i in range(15, 500, 15)] MARKUP = 0.00002 START_DATE = datetime(2021, 1, 1) TSTART_DATE = datetime(2018, 1, 1) STOP_DATE = datetime(2022, 1, 1)
Das Basismodell wird von 2021 bis Anfang 2022 trainiert, während das Metamodell von 2018 bis 2022 trainiert wird. Alle anderen Daten werden für Tests mit neuen Daten, d. h. von 2010 bis 2022.06.15, verwendet.
Es werden Stichproben von Geschäften mit einer zufälligen Dauer im Bereich von 15-35 ausgewählt.
def labelling_relabeling(dataset, min=15, max=35, relabeling=False):
Es werden 25 Trainingsiterationen gewählt. Der Multiplikator für schlechte Beispiele für das Beispielbuch ist gleich 0,5:
# iterative learning res = [] BAD_SAMPLES_BOOK = pd.DatetimeIndex([]) for i in range(25): res.append(brute_force(pr[pr.columns[1:]], bad_samples_fraction=0.5)) print('Iteration: {}, R^2: {}'.format(i, res[-1][0])) pr = res[-1][3] # test best model res.sort() p = test_model(res[-1])
Beim Training wurden die folgenden R^2-Werte für den gesamten Datensatz seit 2010 erzielt:
Iteration: 0, R^2: 0.8364212812476872 Iteration: 1, R^2: 0.8265960950867208 Iteration: 2, R^2: 0.8710535097094494 Iteration: 3, R^2: 0.820894300254345 Iteration: 4, R^2: 0.7271704621597865 Iteration: 5, R^2: 0.8746302835797399 Iteration: 6, R^2: 0.7746283871087961 Iteration: 7, R^2: 0.870806543378866 Iteration: 8, R^2: 0.8651222653557956 Iteration: 9, R^2: 0.9452164577256995 Iteration: 10, R^2: 0.867541289963404 Iteration: 11, R^2: 0.9759544230548619 Iteration: 12, R^2: 0.9063804006221455 Iteration: 13, R^2: 0.9609701853129079 Iteration: 14, R^2: 0.9666262255426672 Iteration: 15, R^2: 0.7046628448822643 Iteration: 16, R^2: 0.7750941894554821 Iteration: 17, R^2: 0.9436968900331276 Iteration: 18, R^2: 0.8961403809578388 Iteration: 19, R^2: 0.9627553719743711 Iteration: 20, R^2: 0.9559809326980575 Iteration: 21, R^2: 0.9578579606050637 Iteration: 22, R^2: 0.8095556721129047 Iteration: 23, R^2: 0.654147043077418 Iteration: 24, R^2: 0.7538928969905255
Anschließend wurden die Modelle nach dem höchsten R^2 sortiert. Hier sind die besten von ihnen in absteigender Reihenfolge der Punktzahl.
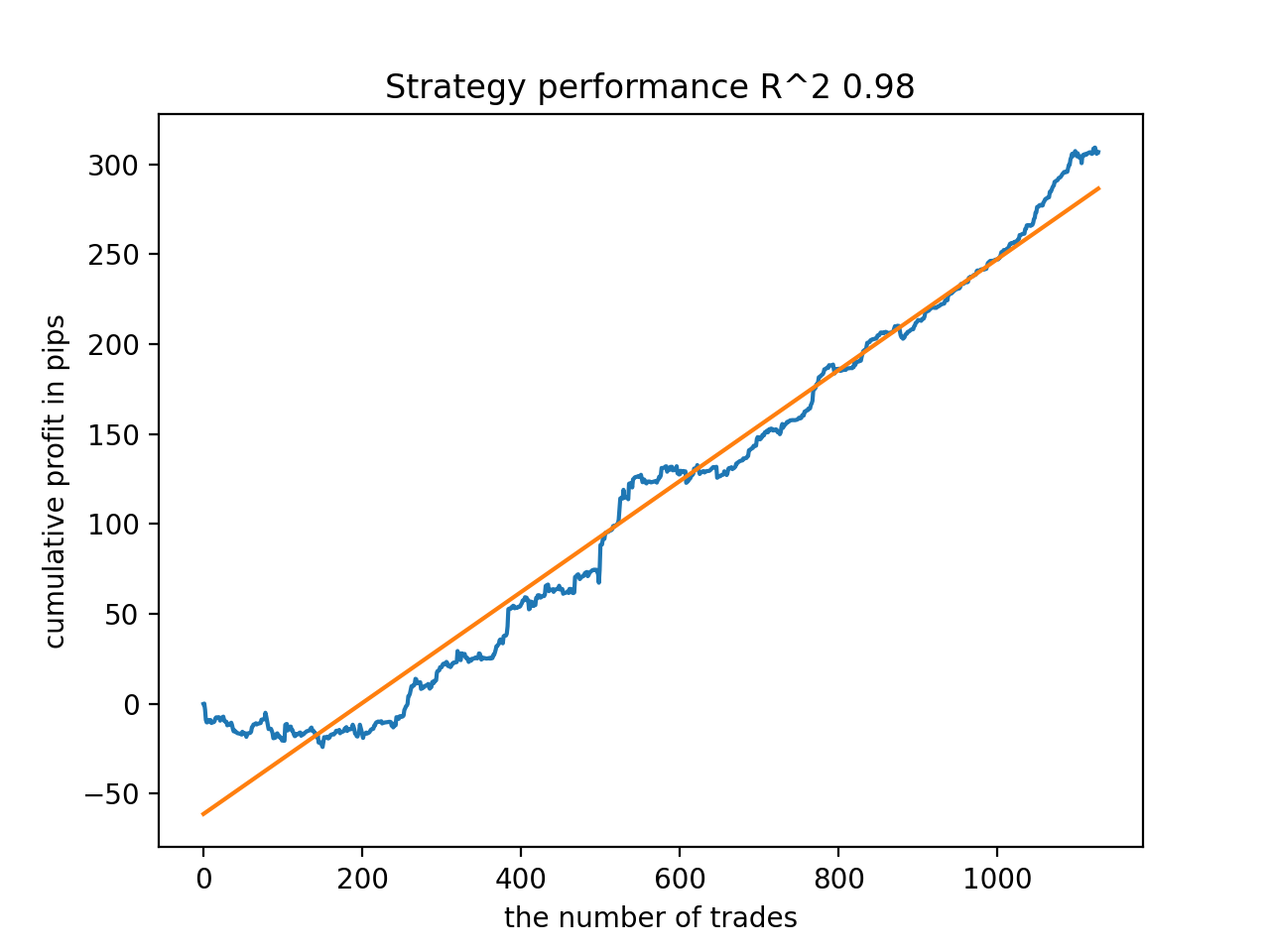
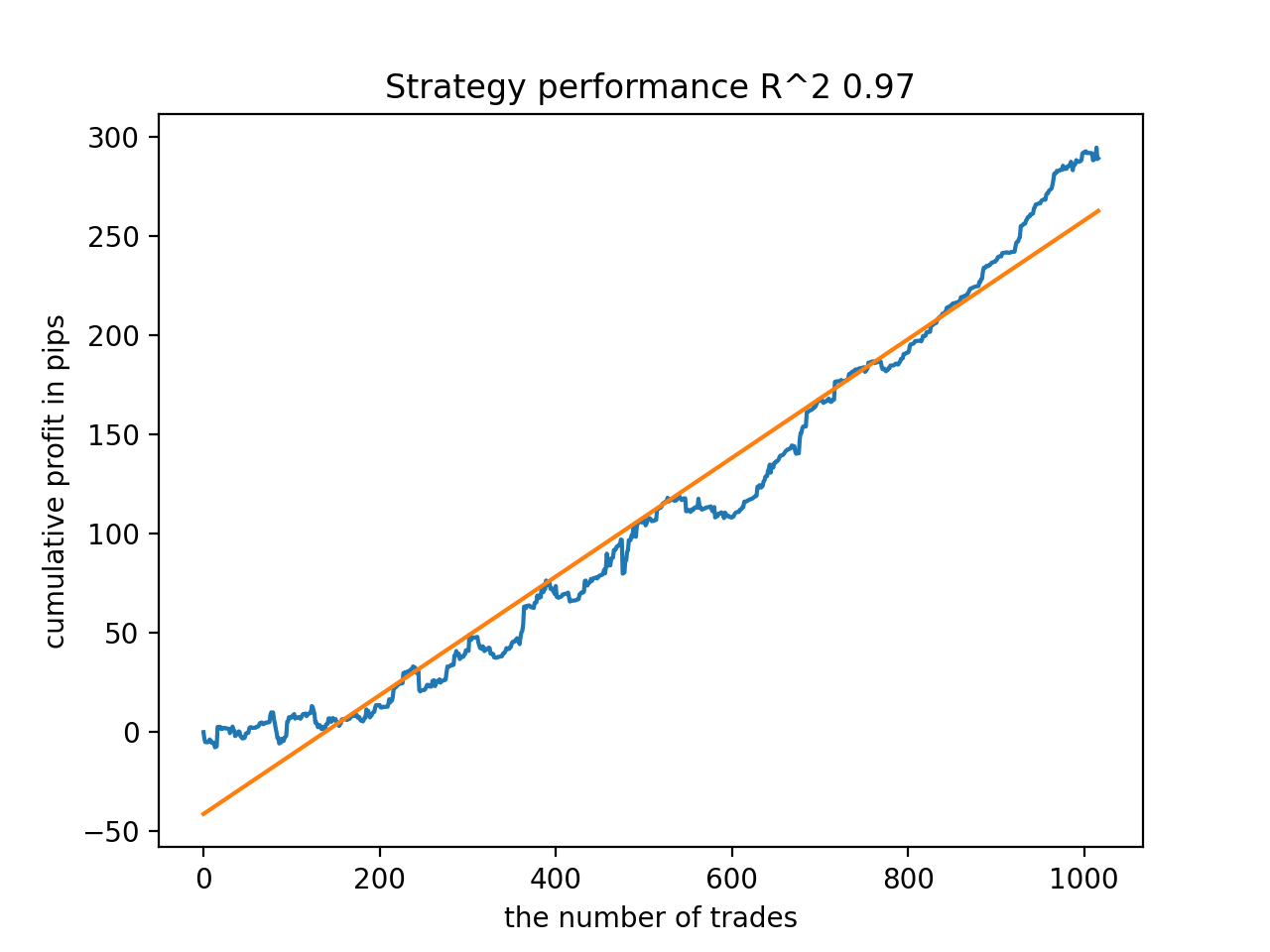
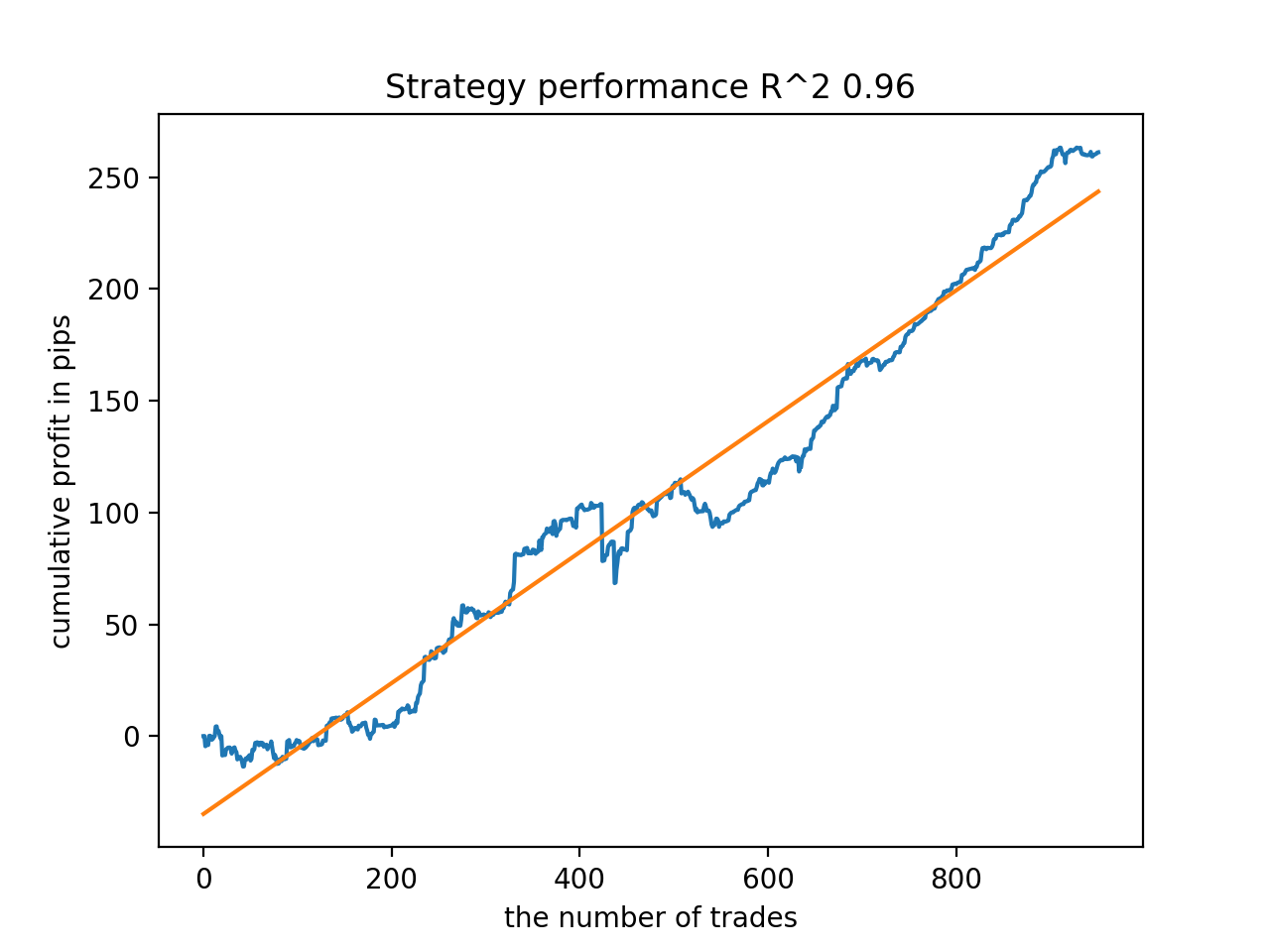
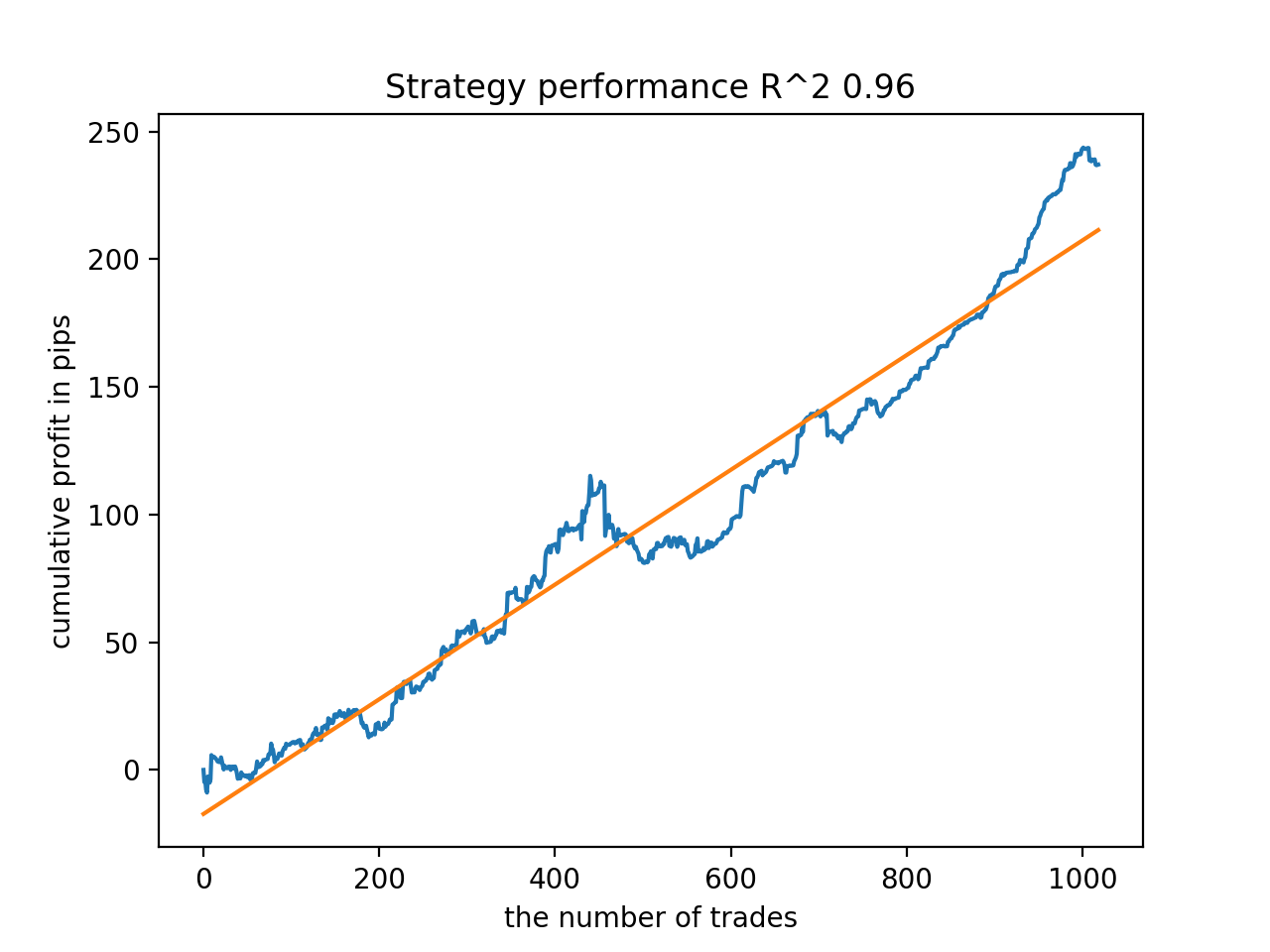
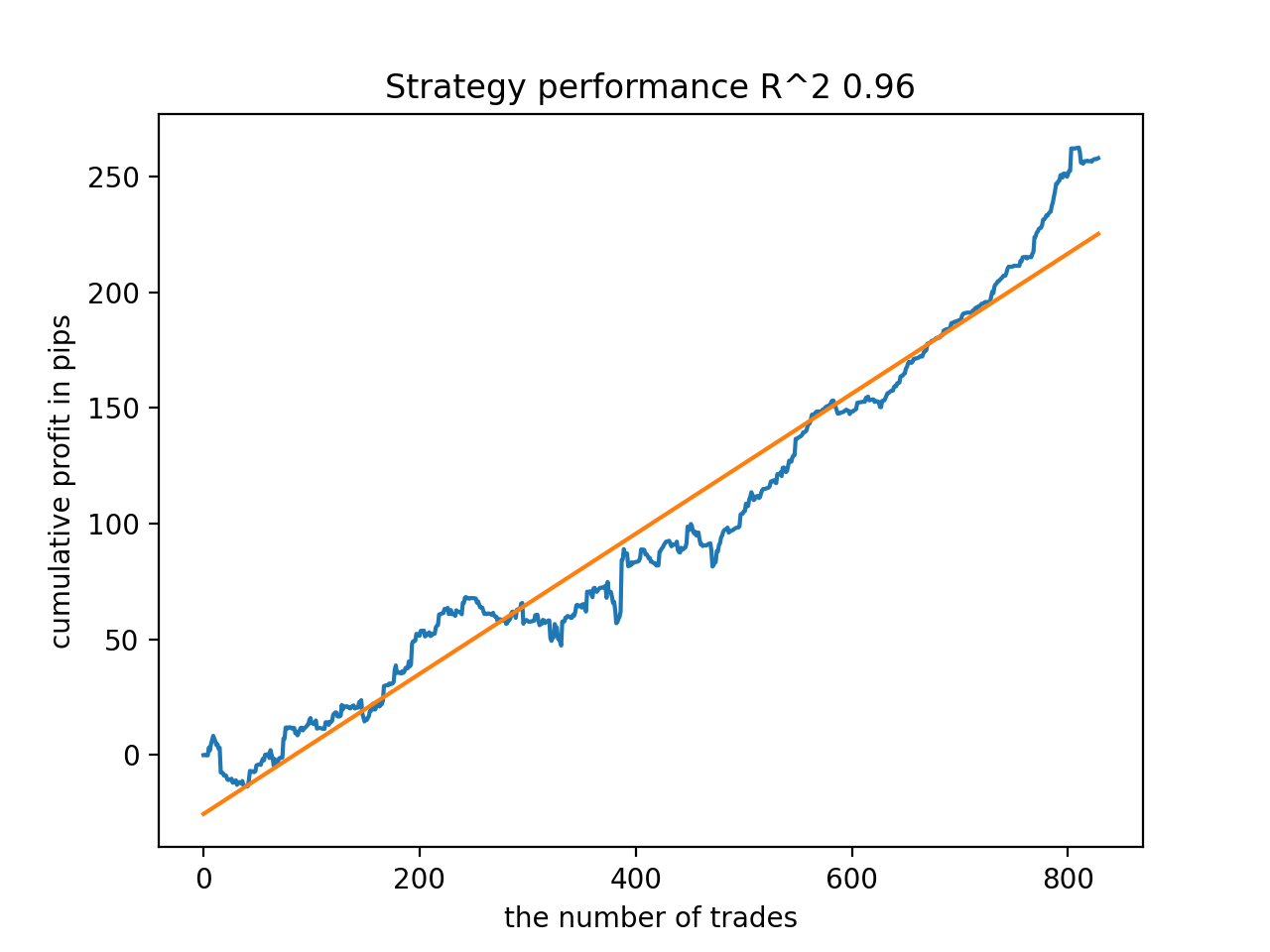
Alle Muster sind im Allgemeinen über den Zeitraum seit 2010 recht stabil, auch wenn die Diagramme keine perfekten Kurven darstellen.
In der letzten Phase exportieren wir die interessanten Modelle in den MetaTrader 5 für weitere Tests oder die Verwendung im Handel. Die Exportfunktion nimmt ein Modell als Eingabe (in diesem Fall das beste vom Ende) und eine Modellnummer, um den Dateinamen zu ändern, sodass Sie mehrere Modelle gleichzeitig aufnehmen können.
export_model_to_MQL_code(res[-1], str(1))
Kompilieren Sie den Bot und überprüfen Sie ihn im MetaTrader 5 Strategie-Tester.
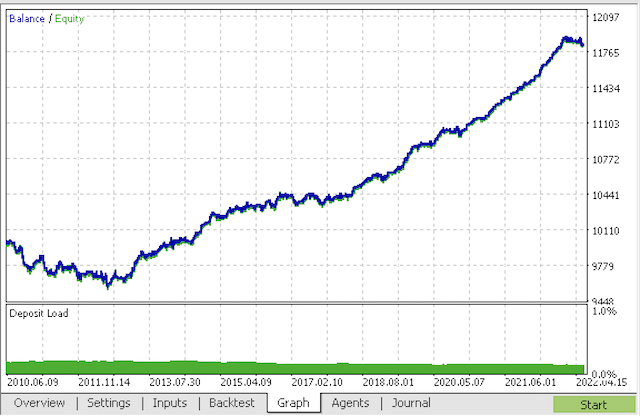
Im Endstadium können Sie bereits mit Modellen im vertrauten MetaTrader 5-Terminal arbeiten.
Schlussfolgerung
Der Artikel demonstriert das wahrscheinlich komplexeste und anspruchsvollste Zeitreihenklassifizierungsmodell, das ich je zu implementieren hatte. Ein interessanter Punkt ist die Möglichkeit, schwer zu klassifizierende Teile der Geschichte mit Hilfe des Metamodells automatisch zu verwerfen. Solche Modelle übertreffen manchmal sogar saisonale Modelle, die für den Handel zu einer bestimmten Tageszeit oder an einem bestimmten Wochentag mit stark ausgeprägten saisonalen Zyklen trainiert wurden. Hier erfolgt die Sortierung automatisch und ohne menschliches Zutun.
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/9138
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.
 Datenwissenschaft und maschinelles Lernen - Neuronales Netzwerk (Teil 01): Entmystifizierte Feed Forward Neurale Netzwerke
Datenwissenschaft und maschinelles Lernen - Neuronales Netzwerk (Teil 01): Entmystifizierte Feed Forward Neurale Netzwerke
 Einen handelnden Expert Advisor von Grund auf neu entwickeln (Teil 19): Neues Auftragssystem (II)
Einen handelnden Expert Advisor von Grund auf neu entwickeln (Teil 19): Neues Auftragssystem (II)
 Lernen Sie, wie man ein Handelssystem mit Bears Power entwirft
Lernen Sie, wie man ein Handelssystem mit Bears Power entwirft
 Lernen Sie, wie man ein Handelssystem mit dem Force Index entwirft
Lernen Sie, wie man ein Handelssystem mit dem Force Index entwirft
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Mein Code funktioniert etwas schneller als der Originalcode :) So ist das Training noch schneller. Aber ich benutze GPU.
Bitte klären Sie, ob dies ein Fehler im Code ist
Der richtige Ausdruck scheint zu sein
Ansonsten macht die erste Zeile einfach keinen Sinn, da in der zweiten Zeile die Bedingung des Kopierens der Daten erneut ausgeführt wird, was zu einem Kopieren ohne Filterung nach dem Ziel "1" des Metamodells führt.
Ich lerne gerade und könnte mit diesem Python falsch liegen, deshalb frage ich.....
Ja, Sie haben richtig bemerkt, Ihr Code ist korrekt.
Ich habe auch eine schnellere und eine etwas andere Version, ich wollte sie als mb-Artikel hochladen.Ja, Sie haben richtig bemerkt, Ihr Code ist korrekt.
Ich habe auch eine schnellere und eine etwas andere Version, ich wollte es als mb Artikel hochladen.Schreiben, es wird interessant sein.
Das Beste, was ich über die Ausbildung bekommen konnte.
Und dies ist auf einem separaten Beispiel
Ich habe den Prozess der Initialisierung durch Training hinzugefügt.
Schreiben Sie, das wird interessant.
Das Beste an der Ausbildung, die ich machen konnte, war
Und das ist auf einer separaten Probe
Ich habe den Prozess der Initialisierung durch Training hinzugefügt.
Na bitte, Sie kennen Python bereits
.
Ich würde nicht behaupten, dass ich ein Experte bin - alles mit einem "Wörterbuch".
Ich war daran interessiert, einen Effekt dieses Ansatzes zu finden. Bis jetzt habe ich noch nicht feststellen können, ob es einen gibt. Im Allgemeinen wird CatBoost auf der Probe trainiert, ohne irgendeine "Magie" - die Balance ist unten auf dem Bild. Daher habe ich ein aussagekräftigeres Ergebnis erwartet.
Ich würde nicht behaupten, dass ich mich auskenne - alles mit einem "Wörterbuch".
Ich war daran interessiert, eine Wirkung dieses Ansatzes zu finden. Bis jetzt habe ich noch nicht festgestellt, ob es einen gibt. Also, CatBoost wird auf die Probe trainiert, im Allgemeinen, ohne irgendeine "Magie" - die Balance ist unten auf dem Bild. Deshalb habe ich ein aussagekräftigeres Ergebnis erwartet.