Artikel über maschinelles Lernen im Handel.
Erstellen von KI-basierten Handelsrobotern: native Integration der Bibliotheken für Python, Matrizen und Vektoren, Mathematik und Statistik und vieles mehr.
Finden Sie heraus, wie Sie maschinelles Lernen im Handel einsetzen können. Neuronen, Perzeptronen, Faltungs- und rekurrente Netze, Vorhersagemodelle – beginnen Sie mit den Grundlagen und arbeiten Sie sich bis zur Entwicklung Ihrer eigenen KI vor. Sie lernen, wie man neuronale Netze für den algorithmischen Handel auf Finanzmärkten trainiert und anwendet.
Neuer Artikel

Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich

Neuronale Netze leicht gemacht (Teil 75): Verbesserung der Leistung von Modellen zur Vorhersage einer Trajektorie
Die Modelle, die wir erstellen, werden immer größer und komplexer. Dies erhöht nicht nur die Kosten für ihr Training, sondern auch für ihren Betrieb. Die Zeit, die für eine Entscheidung benötigt wird, ist jedoch oft entscheidend. In diesem Zusammenhang sollten wir Methoden zur Optimierung der Modellleistung ohne Qualitätseinbußen in Betracht ziehen.

Beispiel für CNA (Causality Network Analysis), SMOC (Stochastic Model Optimal Control) und Nash Game Theory mit Deep Learning
Wir werden Deep Learning zu den drei Beispielen hinzufügen, die in früheren Artikeln veröffentlicht wurden, und die Ergebnisse mit den vorherigen vergleichen. Das Ziel ist es, zu lernen, wie man DL zu anderen EAs hinzufügt.
Beispiel eines neuen Indikators und eines Conditional LSTM
Dieser Artikel befasst sich mit der Entwicklung eines Expert Advisors (EA) für den automatisierten Handel, der technische Analyse mit Deep Learning-Vorhersagen kombiniert.

Neuronale Netze leicht gemacht (Teil 88): Zeitreihen-Dense-Encoder (TiDE)
In dem Bestreben, möglichst genaue Prognosen zu erhalten, verkomplizieren die Forscher häufig die Prognosemodelle. Dies wiederum führt zu höheren Kosten für Training und Wartung der Modelle. Ist eine solche Erhöhung immer gerechtfertigt? In diesem Artikel wird ein Algorithmus vorgestellt, der die Einfachheit und Schnelligkeit linearer Modelle nutzt und Ergebnisse liefert, die mit den besten Modellen mit einer komplexeren Architektur vergleichbar sind.

Datenwissenschaft und ML (Teil 32): KI-Modelle auf dem neuesten Stand halten, Online-Lernen
In der sich ständig verändernden Welt des Handels ist die Anpassung an Marktveränderungen nicht nur eine Option, sondern eine Notwendigkeit. Täglich entstehen neue Muster und Trends, die es selbst den fortschrittlichsten Modellen für maschinelles Lernen erschweren, angesichts der sich verändernden Bedingungen effektiv zu bleiben. In diesem Artikel erfahren Sie, wie Sie Ihre Modelle durch ein automatisches Neu-Training relevant halten und auf neue Marktdaten reagieren können.
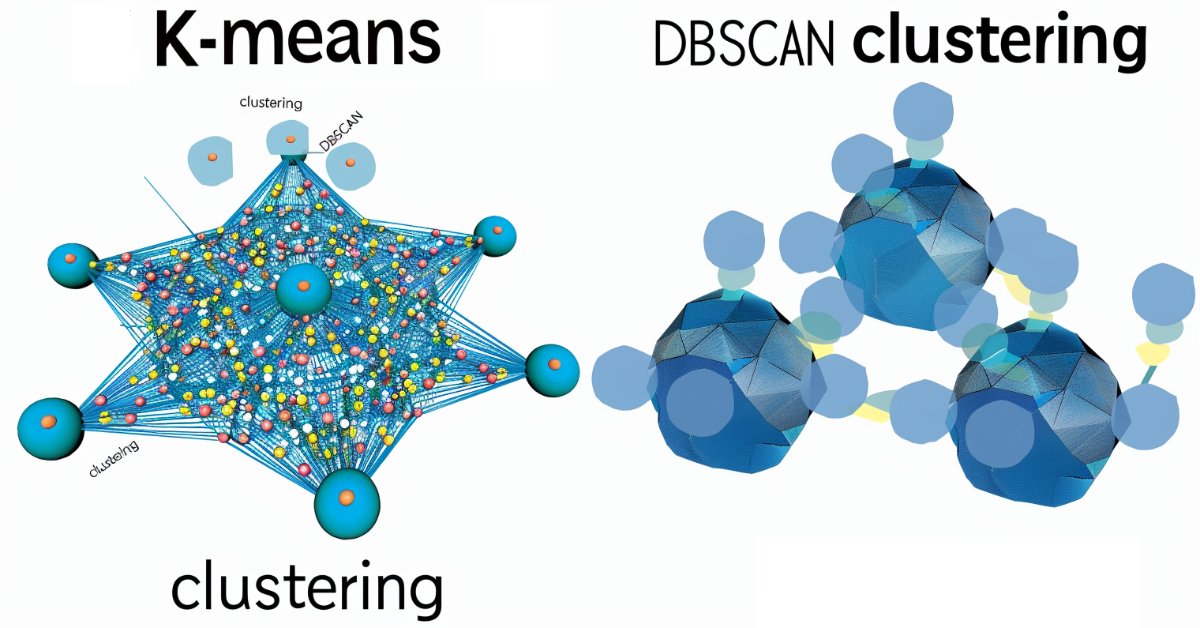
MQL5-Assistenten-Techniken, die Sie kennen sollten (Teil 13): DBSCAN für eine Klasse für Expertensignale
Density Based Spatial Clustering for Applications with Noise (DBSCAN) ist eine unüberwachte Form der Datengruppierung, die kaum Eingabeparameter benötigt, außer 2, was im Vergleich zu anderen Ansätzen wie K-Means ein Segen ist. Wir gehen der Frage nach, wie dies für das Testen und schließlich den Handel mit den von Wizard zusammengestellten Expert Advisers konstruktiv sein kann

MQL5-Assistenten-Techniken, die Sie kennen sollten (Teil 08): Perceptrons
Perceptrons, Netze mit einer einzigen ausgeblendeten Schicht, sind ein guter Einstieg für alle, die mit den Grundlagen des automatisierten Handels vertraut sind und sich mit neuronalen Netzen vertraut machen wollen. Wir sehen uns Schritt für Schritt an, wie dies in einer Signalklassen-Assembly realisiert werden könnte, die Teil der MQL5 Wizard-Klassen für Expert Advisors ist.
Neuronale Netze leicht gemacht (Teil 77): Cross-Covariance Transformer (XCiT)
In unseren Modellen verwenden wir häufig verschiedene Aufmerksamkeitsalgorithmen. Und am häufigsten verwenden wir wahrscheinlich Transformers. Ihr größter Nachteil ist der Ressourcenbedarf. In diesem Artikel wird ein neuer Algorithmus vorgestellt, der dazu beitragen kann, die Rechenkosten ohne Qualitätseinbußen zu senken.

Algorithmen zur Optimierung mit Populationen: Shuffled Frog-Leaping Algorithmus (SFL)
Der Artikel enthält eine detaillierte Beschreibung des Shuffled-Frog-Leaping-Algorithmus (SFL) und seiner Fähigkeiten bei der Lösung von Optimierungsproblemen. Der SFL-Algorithmus ist vom Verhalten der Frösche in ihrer natürlichen Umgebung inspiriert und bietet einen neuen Ansatz zur Funktionsoptimierung. Der SFL-Algorithmus ist ein effizientes und flexibles Werkzeug, das eine Vielzahl von Datentypen verarbeiten und optimale Lösungen erzielen kann.

MQL5-Assistenten-Techniken, die Sie kennen sollten (Teil 10). Die unkonventionelle RBM
Restriktive Boltzmann-Maschinen (RBM) sind im Grunde genommen ein zweischichtiges neuronales Netz, das durch Dimensionsreduktion eine unbeaufsichtigte Klassifizierung ermöglicht. Wir nehmen die Grundprinzipien und untersuchen, ob wir durch eine unorthodoxe Umgestaltung und ein entsprechendes Training einen nützlichen Signalfilter erhalten können.

Neuronale Netze im Handel: Praktische Ergebnisse der Methode TEMPO
Wir beschäftigen uns weiter mit TEMPO. In diesem Artikel werden wir die tatsächliche Wirksamkeit der vorgeschlagenen Ansätze anhand realer historischer Daten bewerten.

Datenwissenschaft und maschinelles Lernen (Teil 14): Mit Kohonenkarten den Weg in den Märkten finden
Sind Sie auf der Suche nach einem innovativen Ansatz für den Handel, der Ihnen hilft, sich auf den komplexen und sich ständig verändernden Märkten zurechtzufinden? Kohonenkarten (Kohonen maps), eine innovative Form künstlicher neuronaler Netze, können Ihnen helfen, verborgene Muster und Trends in Marktdaten aufzudecken. In diesem Artikel werden wir untersuchen, wie Kohonenkarten funktionieren und wie sie zur Entwicklung intelligenter und effektiverer Handelsstrategien genutzt werden können. Egal, ob Sie ein erfahrener Trader sind oder gerade erst anfangen, Sie werden diesen aufregenden neuen Ansatz für den Handel nicht verpassen wollen.

Datenkennzeichnung für die Zeitreihenanalyse (Teil 5):Anwendung und Test in einem EA mit Socket
In dieser Artikelserie werden verschiedene Methoden zur Kennzeichnung (labeling) von Zeitreihen vorgestellt, mit denen Daten erstellt werden können, die den meisten Modellen der künstlichen Intelligenz entsprechen. Eine gezielte und bedarfsgerechte Kennzeichnung von Daten kann dazu führen, dass das trainierte Modell der künstlichen Intelligenz besser mit dem erwarteten Design übereinstimmt, die Genauigkeit unseres Modells verbessert wird und das Modell sogar einen qualitativen Sprung machen kann!

MQL5-Assistenten-Techniken, die Sie kennen sollten (Teil 36): Q-Learning mit Markov-Ketten
Reinforcement Learning ist neben dem überwachten und dem unüberwachten Lernen eine der drei Hauptrichtungen des maschinellen Lernens. Es geht also um die optimale Steuerung oder das Erlernen der besten langfristigen Strategie, die der Zielfunktion am besten entspricht. Vor diesem Hintergrund untersuchen wir die mögliche Rolle, die ein MLP für den Lernprozess eines von einem Assistenten zusammengestellten Expertenberaters spielt.

Hochfrequenz-Arbitrage-Handelssystem in Python mit MetaTrader 5
In diesem Artikel werden wir ein Arbitrationssystem erstellen, das in den Augen der Broker legal bleibt, Tausende von synthetischen Preisen auf dem Forex-Markt erstellt, sie analysiert und erfolgreich mit Gewinn handelt.

Datenwissenschaft und ML (Teil 37): Mit Kerzenmustern und AI den Markt schlagen
Kerzenmuster helfen Händlern, die Marktpsychologie zu verstehen und Trends auf den Finanzmärkten zu erkennen. Sie ermöglichen fundiertere Handelsentscheidungen, die zu besseren Ergebnissen führen können. In diesem Artikel werden wir untersuchen, wie man Kerzenmuster mit KI-Modellen nutzen kann, um eine optimale Handelsperformance zu erzielen.

Algorithmen zur Optimierung mit Populationen: Binärer genetischer Algorithmus (BGA). Teil I
In diesem Artikel werden wir verschiedene Methoden untersuchen, die in binären genetischen und anderen Populationsalgorithmen verwendet werden. Wir werden uns die Hauptkomponenten des Algorithmus, wie Selektion, Crossover und Mutation, und ihre Auswirkungen auf die Optimierung ansehen. Darüber hinaus werden wir Methoden der Datendarstellung und ihre Auswirkungen auf die Optimierungsergebnisse untersuchen.

Integration des AI-Modells in eine bereits bestehende MQL5-Handelsstrategie
Dieses Thema konzentriert sich auf die Einbindung eines trainierten KI-Modells (z. B. eines Verstärkungslernmodells wie LSTM oder eines auf maschinellem Lernen basierenden Prognosemodells) in eine bestehende MQL5-Handelsstrategie.

Neuronale Netze leicht gemacht (Teil 57): Stochastic Marginal Actor-Critic (SMAC)
Hier werde ich den relativ neuen Algorithmus Stochastic Marginal Actor-Critic (SMAC) vorstellen, der es ermöglicht, Strategien mit latenten Variablen im Rahmen der Entropiemaximierung zu entwickeln.

Kategorientheorie in MQL5 (Teil 20): Ein Abstecher über die Selbstaufmerksamkeit (Self-Attention) und den Transformer
Wir schweifen in unserer Serie ab, indem wir über einen Teil des Algorithmus zu chatGPT nachdenken. Gibt es Ähnlichkeiten oder Konzepte, die den natürlichen Transformationen entlehnt sind? Wir versuchen, diese und andere Fragen in einem unterhaltsamen Stück zu beantworten, mit unserem Code in einem Signalklassenformat.

MQL5-Assistenten-Techniken, die Sie kennen sollten (Teil 29): Fortsetzung zu Lernraten mit MLPs
Zum Abschluss unserer Betrachtung der Empfindlichkeit der Lernrate für die Leistung von Expert Advisors untersuchen wir in erster Linie die adaptiven Lernraten. Diese Lernraten sollen für jeden Parameter in einer Schicht während des Trainingsprozesses angepasst werden, und so bewerten wir die potenziellen Vorteile gegenüber der erwarteten Leistungsgebühr.

Verschaffen Sie sich einen Vorteil gegenüber jedem Markt (Teil V): FRED EURUSD Alternative Daten
In der heutigen Diskussion haben wir alternative tägliche Daten der St. Louis Federal Reserve zum Broad US-Dollar Index und eine Reihe anderer makroökonomischer Indikatoren verwendet, um den zukünftigen EURUSD-Wechselkurs vorherzusagen. Obwohl die Daten nahezu perfekt zu korrelieren scheinen, konnten wir leider keine wesentlichen Verbesserungen der Modellgenauigkeit feststellen, was uns möglicherweise zu der Annahme veranlasst, dass Anleger stattdessen besser auf gewöhnliche Marktnotierungen zurückgreifen sollten.

Kategorientheorie in MQL5 (Teil 17): Funktoren und Monoide
Dieser Artikel, der letzte in unserer Reihe zum Thema Funktoren, befasst sich erneut mit Monoiden als Kategorie. Monoide, die wir in dieser Serie bereits vorgestellt haben, werden hier zusammen mit mehrschichtigen Perceptrons zur Unterstützung der Positionsbestimmung verwendet.

Bewältigung der Herausforderungen bei der ONNX-Integration
ONNX ist ein großartiges Werkzeug für die Integration von komplexem KI-Code zwischen verschiedenen Plattformen. Es ist ein großartiges Werkzeug, das einige Herausforderungen mit sich bringt, die man angehen muss, um das Beste daraus zu machen.

Statistische Arbitrage mit Vorhersagen
Wir werden uns mit statistischer Arbitrage beschäftigen, wir werden mit Python nach Korrelations- und Kointegrationssymbolen suchen, wir werden einen Indikator für den Pearson-Koeffizienten erstellen und wir werden einen EA für den Handel mit statistischer Arbitrage mit Vorhersagen erstellen, die mit Python und ONNX-Modellen gemacht werden.

Deep Learning GRU model with Python to ONNX with EA, and GRU vs LSTM models
We will guide you through the entire process of DL with python to make a GRU ONNX model, culminating in the creation of an Expert Advisor (EA) designed for trading, and subsequently comparing GRU model with LSTN model.

Propensity Score in der Kausalinferenz
Der Artikel befasst sich mit dem Thema Abgleich von Kausalschlüssen. Der Abgleich wird für den Vergleich sich ähnlichen Beobachtungen in einem Datensatz. Dies ist notwendig, um kausale Wirkungen korrekt zu bestimmen und Verzerrungen zu beseitigen. Der Autor erklärt, wie dies beim Aufbau von Handelssystemen auf der Grundlage des maschinellen Lernens hilft, die bei neuen Daten, auf denen sie nicht trainiert wurden, stabiler werden. Der Propensity Score (Tendenzbewertung) spielt eine zentrale Rolle und wird häufig bei Kausalschlüssen verwendet.

MQL5-Assistenz-Techniken, die Sie kennen sollten (Teil 07): Dendrogramme
Die Klassifizierung von Daten zu Analyse- und Prognosezwecken ist ein sehr vielfältiger Bereich des maschinellen Lernens, der eine große Anzahl von Ansätzen und Methoden umfasst. Dieser Beitrag befasst sich mit einem solchen Ansatz, der Agglomerativen Hierarchischen Klassifikation.
Beherrschen der Modellinterpretation: Gewinnen Sie tiefere Einblicke in Ihren Machine Learning-Modelle
Maschinelles Lernen ist ein komplexes und lohnendes Gebiet für jeden, unabhängig von seiner Erfahrung. In diesem Artikel tauchen wir tief in die inneren Mechanismen ein, die den von Ihnen erstellten Modellen zugrunde liegen. Wir erforschen die komplizierte Welt der Merkmale, Vorhersagen und wirkungsvollen Entscheidungen, um die Komplexität zu entschlüsseln und ein sicheres Verständnis der Modellinterpretation zu erlangen. Lernen Sie die Kunst, Kompromisse zu finden, Vorhersagen zu verbessern, die Wichtigkeit von Merkmalen einzustufen und gleichzeitig eine solide Entscheidungsfindung zu gewährleisten. Diese wichtige Lektüre hilft Ihnen, mehr Leistung aus Ihren maschinellen Lernmodellen herauszuholen und mehr Wert aus dem Einsatz von maschinellen Lernmethoden zu ziehen.

Datenwissenschaft und ML (Teil 28): Vorhersage mehrerer Futures für EURUSD mithilfe von KI
Bei vielen Modellen der künstlichen Intelligenz ist es üblich, einen einzigen Zukunftswert vorherzusagen. In diesem Artikel werden wir uns jedoch mit der leistungsstarken Technik der Verwendung von maschinellen Lernmodellen zur Vorhersage mehrerer zukünftiger Werte befassen. Dieser Ansatz, der als mehrstufige Prognose bekannt ist, ermöglicht es uns, nicht nur den Schlusskurs von morgen, sondern auch den von übermorgen und darüber hinaus vorherzusagen. Durch die Beherrschung mehrstufiger Prognosen können Händler und Datenwissenschaftler tiefere Einblicke gewinnen und fundiertere Entscheidungen treffen, was ihre Vorhersagefähigkeiten und strategische Planung erheblich verbessert.

Datenwissenschaft und ML(Teil 30): Das Power-Paar für die Vorhersage des Aktienmarktes, Convolutional Neural Networks (CNNs) und Recurrent Neural Networks (RNNs)
In diesem Artikel untersuchen wir die dynamische Integration von Convolutional Neural Networks (CNNs) und Recurrent Neural Networks (RNNs) in der Börsenprognose. Nutzen wir die Fähigkeit von CNNs, Muster zu extrahieren, und die Fähigkeit der RNNs, sequentielle Daten zu verarbeiten. Wir wollen sehen, wie diese leistungsstarke Kombination die Genauigkeit und Effizienz von Handelsalgorithmen verbessern kann.

MetaTrader 5 Machine Learning Blueprint (Teil 1): Datenlecks und Zeitstempelfehler
Bevor wir überhaupt damit beginnen können, ML für unseren Handel auf dem MetaTrader 5 zu nutzen, müssen wir uns mit einem der am meisten übersehenen Fallstricke befassen - dem Datenleck. In diesem Artikel wird erläutert, wie Datenlecks, insbesondere die Falle von MetaTrader 5-Zeitstempel, die Leistung unseres Modells verzerren und zu unzuverlässigen Handelssignalen führen können. Indem wir uns mit den Mechanismen dieses Problems befassen und Strategien zu seiner Vermeidung vorstellen, ebnen wir den Weg für den Aufbau robuster Modelle für maschinelles Lernen, die zuverlässige Vorhersagen in Live-Handelsumgebungen liefern.

Сode Lock Algorithmus (CLA)
In diesem Artikel werden wir Zahlenschlösser (Code Locks) neu überdenken und sie von Sicherheitsmechanismen in Werkzeuge zur Lösung komplexer Optimierungsprobleme verwandeln. Entdecken Sie die Welt der Zahlenschlösser, die nicht als einfache Sicherheitsvorrichtungen betrachtet werden, sondern als Inspiration für einen neuen Ansatz zur Optimierung. Wir werden eine ganze Population von Zahlenschlössern (Locks) erstellen, wobei jedes Schloss eine einzigartige Lösung für das Problem darstellt. Wir werden dann einen Algorithmus entwickeln, der diese Schlösser „knackt“ und optimale Lösungen in einer Vielzahl von Bereichen findet, vom maschinellen Lernen bis zur Entwicklung von Handelssystemen.
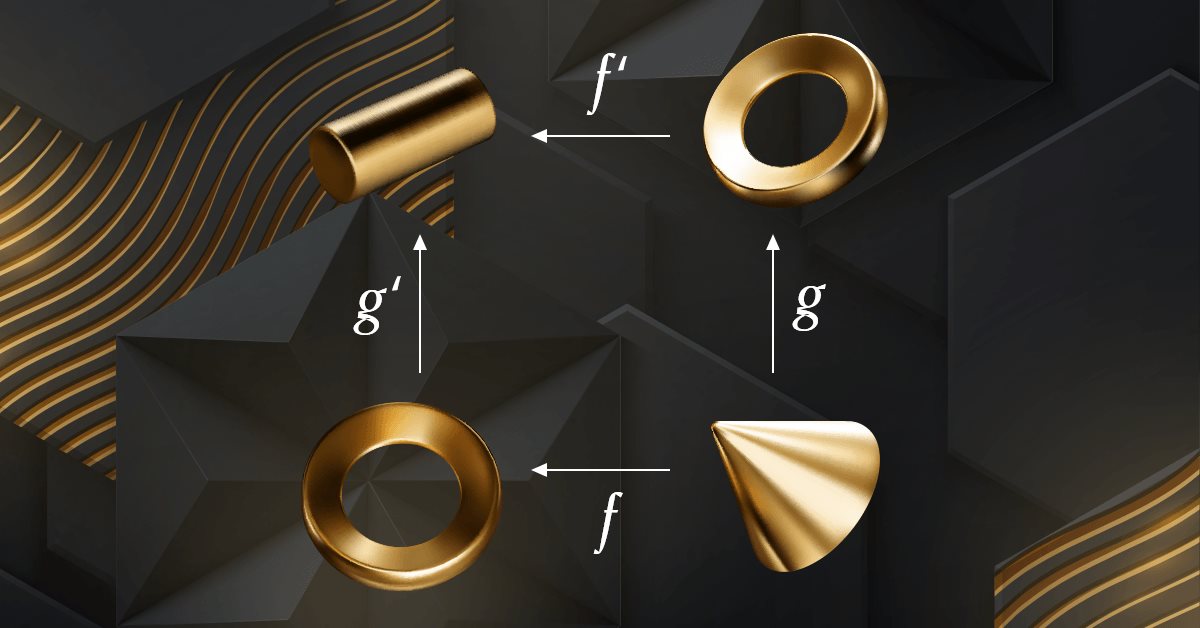
Kategorientheorie in MQL5 (Teil 6): Monomorphe Pullbacks und epimorphe Pushouts
Die Kategorientheorie ist ein vielfältiger und expandierender Zweig der Mathematik, der erst seit kurzem in der MQL5-Gemeinschaft Beachtung findet. In dieser Artikelserie sollen einige der Konzepte und Axiome erforscht und untersucht werden, mit dem übergeordneten Ziel, eine offene Bibliothek einzurichten, die Einblicke gewährt und hoffentlich auch die Nutzung dieses bemerkenswerten Bereichs für die Strategieentwicklung von Händlern fördert.

Neuronales Netz in der Praxis: Pseudoinverse (I)
Heute werden wir uns damit beschäftigen, wie man die Berechnung der Pseudoinverse in der reinen MQL5-Sprache implementiert. Der Code, den wir uns ansehen werden, wird für Anfänger viel komplexer sein, als ich erwartet hatte, und ich bin noch dabei herauszufinden, wie ich ihn auf einfache Weise erklären kann. Betrachten Sie dies also als eine Gelegenheit, einen ungewöhnlichen Code zu lernen. Ruhig und aufmerksam. Obwohl es nicht auf eine effiziente oder schnelle Anwendung abzielt, soll es so didaktisch wie möglich sein.

Selbstoptimierende Expert Advisors mit MQL5 und Python erstellen (Teil II): Abstimmung tiefer neuronaler Netze
Modelle für maschinelles Lernen verfügen über verschiedene einstellbare Parameter. In dieser Artikelserie werden wir untersuchen, wie Sie Ihre KI-Modelle mithilfe der SciPy-Bibliothek an Ihren spezifischen Markt anpassen können.

Integration von MQL5 in Datenverarbeitungspakete (Teil 1): Fortgeschrittene Datenanalyse und statistische Verarbeitung
Die Integration ermöglicht einen nahtlosen Arbeitsablauf, bei dem Finanzrohdaten aus MQL5 in Datenverarbeitungspakete wie Jupyter Lab für erweiterte Analysen einschließlich statistischer Tests importiert werden können.

Kategorientheorie in MQL5 (Teil 2)
Die Kategorientheorie ist ein vielfältiger und expandierender Zweig der Mathematik, der in der MQL-Gemeinschaft noch relativ unentdeckt ist. In dieser Artikelserie sollen einige der Konzepte vorgestellt und untersucht werden, mit dem übergeordneten Ziel, eine offene Bibliothek einzurichten, die zu Kommentaren und Diskussionen anregt und hoffentlich die Nutzung dieses bemerkenswerten Bereichs für die Strategieentwicklung der Händler fördert.

Datenkennzeichnung für Zeitreihenanalyse (Teil 6): Anwendung und Test des EAs, der ONNX verwendet
In dieser Artikelserie werden verschiedene Methoden zur Kennzeichnung von Zeitreihen vorgestellt, mit denen Daten erstellt werden können, die den meisten Modellen der künstlichen Intelligenz entsprechen. Eine gezielte und bedarfsgerechte Kennzeichnung von Daten kann dazu führen, dass das trainierte Modell der künstlichen Intelligenz besser mit dem erwarteten Design übereinstimmt, die Genauigkeit unseres Modells verbessert wird und das Modell sogar einen qualitativen Sprung machen kann!
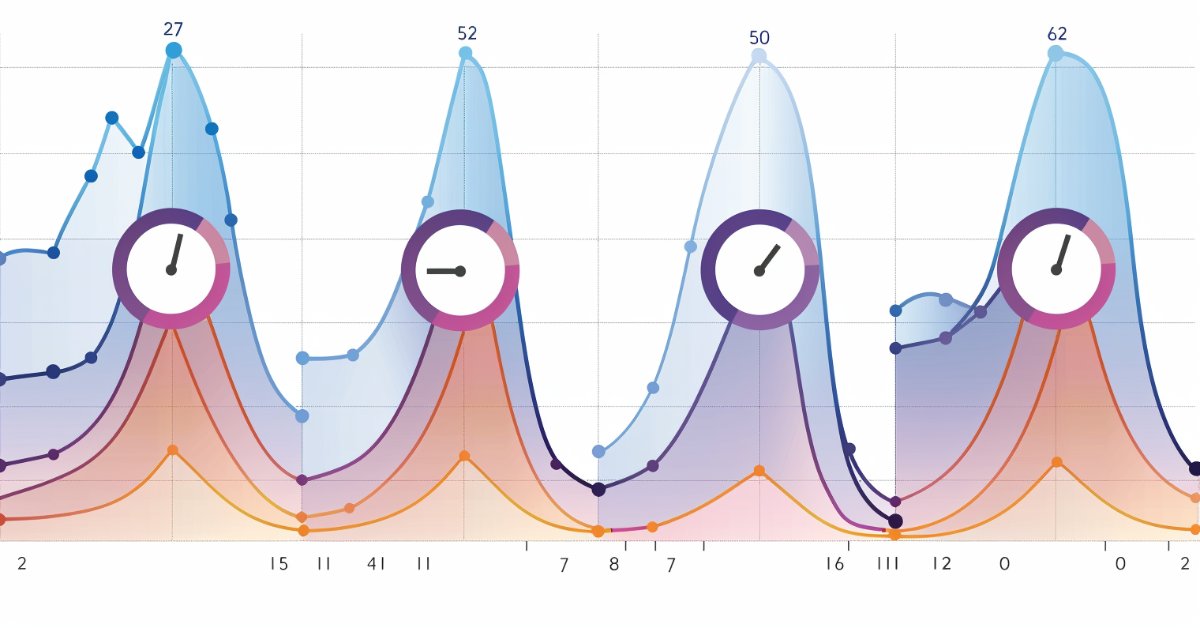
Saisonale Filterung und Zeitabschnitt für Deep Learning ONNX Modelle mit Python für EA
Können wir bei der Erstellung von Modellen für Deep Learning mit Python von der Saisonalität profitieren? Hilft das Filtern von Daten für die ONNX-Modelle, um bessere Ergebnisse zu erzielen? Welchen Zeitabschnitt sollten wir verwenden? Wir werden all dies in diesem Artikel behandeln.