
Kategorientheorie in MQL5 (Teil 14): Funktoren mit linearen Ordnungen
Einführung
Die von Samuel Eilenberg und Saunders Mac Lane in den 1950er Jahren eingeführte Kategorientheorie kann als ein Mittel zur Untersuchung von Systemen betrachtet werden, bei dem der Schwerpunkt auf der Transformation in jeder Phase und nicht auf den Phasen selbst liegt. Sie wurde in einem breiten Spektrum von Anwendungen eingesetzt, das von der funktionalen Programmierung mit Sprachen wie Haskell über die Linguistik, die die Struktur und Kompositionalität natürlicher Sprachen untersucht, bis hin zur algebraischen Topologie reicht, die einen einheitlichen Ansatz für das Verständnis verschiedener topologischer Konstruktionen und Invarianten bietet, um nur einige zu nennen.
In diesen Reihen war die Kategorientheorie bisher in dem Sinne lokalisiert, dass sie sich mit Informationen und Strukturen auf der Ebene der Unterkategorien befasste; in unserem Fall meist mit Mengen (Objekten). Wir haben ihre Beziehungen und Eigenschaften innerhalb einer Kategorie untersucht.
Der Zweck dieses Artikels und einiger ähnlicher Artikel ist es, aus einer Kategorie herauszugehen und die Beziehungen zwischen verschiedenen Kategorien zu betrachten. Formal werden diese als Funktoren (Mathematik) bezeichnet. Wir werden uns also verschiedene Kategorien und ihre möglichen Beziehungen ansehen. Innerhalb des Datensatzes eines Händlers gibt es mehrere Kandidaten für untersuchungswürdige Kategorien. Um jedoch die transzendenten Qualitäten der Kategorientheorie zu betonen, werden wir einen Schritt über den Tellerrand hinausgehen und in diesem Artikel eine Brücke zwischen den vor der kalifornischen Küste gesammelten Gezeitendaten und der Volatilität des NASDAQ-Index schlagen. Gibt es irgendetwas in den Meeresgezeiten, das auf die Volatilität dieses Indexes hindeutet? Wir hoffen, diese Frage bis zu einem gewissen Grad am Ende des Artikels beantworten zu können.
In diesem und den folgenden Artikeln werden keine neuen Konzepte vorgestellt, sondern es wird geprüft, was bereits behandelt wurde, und es wird versucht, es anders, d. h. in einem breiteren Rahmen, anzuwenden.
Meeresgezeiten und der NASDAQ-Index
Die Gezeitendaten werden von der National Oceanic and Atmospheric Administration (NOAA) auf ihrer Website veröffentlicht und der Öffentlichkeit zugänglich gemacht. Viermal am Tag werden die Höhe der Gezeiten des Ozeans ausgehend von einem Bezugspunkt protokolliert. Das ganze Jahr über werden für jeden Tag nur die Uhrzeit und die Höhe des jeweiligen Wasserstandes aufgezeichnet. Hier ist eine Vorschau:

Alle Ozeane sind in 4 Regionen unterteilt, wobei die Gezeitenwerte von einer Vielzahl von Messstationen innerhalb jeder Region erfasst werden. Für die Westküste Nord- und Südamerikas zum Beispiel, die sich von Südamerika über Chile bis nach Alaska erstreckt, gibt es 33 Stationen. Für unsere Analyse werden wir die Daten der Station Monterey in Kalifornien für das Jahr 2020 heranziehen.
Der NASDAQ ist eine etablierte Börse, aber wir betrachten ihn hier in erster Linie als Index, der sich aus einer Reihe von Tech-Unternehmen wie MSFT, AAPL, GOOG und AMZN zusammensetzt, die alle ihren Hauptsitz in Kalifornien haben. Dieser Index kann bei den meisten Brokern gehandelt werden, sodass wir anhand seiner Kurse feststellen können, ob die Marktkapitalisierung dieser Unternehmen, die Branchen revolutioniert haben und den Innovationsgeist Kaliforniens verkörpern, in irgendeiner Weise mit den vor der kalifornischen Küste gesammelten Gezeitendaten verbunden ist.
Abbildung von Daten mithilfe von Funktoren der Kategorientheory
Wir haben in dieser Reihe bisher nicht explizit über Funktoren gesprochen, aber in den Artikeln, in denen wir Monoide, monoide Gruppen, Graphen und Ordnungen besprochen haben, wurde impliziert, dass wir es mit Funktoren zu tun haben, weil jedes dieser Konzepte als Kategorie betrachtet werden kann und ihre Beziehungen oft die Grundlage der Artikel bilden, in denen sie vorkommen. So waren die Morphismen zwischen Monoiden z. B. defacto Funktoren.
Formal ist ein Funktor eine Abbildung zwischen Kategorien, die deren Struktur und Beziehungen, wie sie durch die Objekte und ihre Morphismen innerhalb jeder Kategorie definiert sind, bewahrt. Wenn C und D Kategorien sind, dann besteht der Funktor F von C nach D:
aus zwei Dingen, nämlich: für jedes Objekt c in C gibt es ein zugehöriges Objekt F(c) in D und für jede zwei Objekte gibt es in b, c in C mit einem Morphismus f:
![]()
einen zugehörigen Morphismus F(f):
in D. Funktoren haben auch das zusätzliche Axiom der Erhaltung der Komposition, was bedeutet, dass wir in C die Morphismen:
![]()
und:
haben, dann bewahrt F die Zusammensetzung in C so, dass:
und die Identitätsmorphismen in C für jedes abgebildete Objekt in D erhalten bleiben, sodass, wenn:
dann:
Die Bedeutung der Verknüpfung verschiedener Kategorien ergibt sich aus der Entdeckung. Für jedes System, das als Kategorie eingestuft wird, gibt es oft keine Möglichkeit, nicht nur eine Kategorie in eine andere zu übersetzen, sondern auch die „relative Position“ und vielleicht die Bedeutung jeder Kategorie in einem größeren Kontext zu bestimmen. Aus diesem Grund können Funktoren, die beispielsweise eine Kategorie handelbarer Wertpapiere mit einem eigenen Portfolio gewichteter Morphismen auf eine andere Kategorie von Handelsstrategien abbilden. Der Nutzen eines solchen Funktors für Händler könnte in der Perspektive liegen, aber wenn der Funktor über eine Zeitverzögerung abbildet, könnten wir entweder feststellen, welche Strategien wir angesichts unserer Portfoliowertpapiere anwenden sollten, oder welche Wertpapiere wir angesichts unserer aktuellen Strategie als Nächstes halten sollten.
Eine lineare oder totale Ordnung erfüllt nicht nur die Axiome der Transitivität und Reflexivität, sondern auch die Anforderungen der Antisymmetrie und der Vergleichbarkeit. Dies bedeutet in der Regel, dass alle Daten in einer linearen Ordnung numerisch sein sollten oder, wenn es sich um Text handelt, so diskret sein sollten, dass die binäre Operation „<=“ noch angewendet werden kann, ohne dass es zu Mehrdeutigkeiten oder einem undefinierten Ergebnis kommt. Die Gezeitendaten, wie sie auf der NOAA-Website dargestellt sind, sind mehrdimensional, wenn wir einen Tag als einen einzelnen Datenpunkt betrachten. Sie enthält 4 Datumseinträge für jede Höhe, 4 Fließkommawerte für die Höhen und den Datumseintrag für den Tag. Wenn wir unsere lineare Ordnung verwenden, um den Datumswert des Tages für jeden Datenpunkt zu vergleichen, dann werden die Meeresdaten zu einer einfachen Zeitreihe mit zwei Daten an jedem Punkt, dem Datum als datetime und der Gezeitenhöhe als Gleitkommadaten.
Die Darstellung dieser linearen Ordnung als Kategorie würde bedeuten, dass die binäre Operation zwischen zwei aufeinanderfolgenden Datenpunkten zu einem Morphismus wird und jeder Datenpunkt zu einem Objekt wird, das vier Daten enthält: die vier Zeitpunkte, an denen die Höhen aufgezeichnet wurden, und die vier Höhenwerte, wenn wir diese Daten nach Tagen gruppieren, da diese Gezeitenwerte täglich erfasst wurden. Wir müssen diese Daten jedoch etwas mehr normalisieren, da nicht alle Tage 4 Datenpunkte haben. Einige haben nur 3. Da unsere Kategorie einfache isomorphe Beziehungen haben wird, ist es wichtig, dass wir bei der Anzahl der Elemente in jedem Bereich (Tag) konsistent sind.
Die Volatilitätskategorie der NASDAQ würde ähnlich wie die Gezeiten des Ozeans verlaufen, indem wir Preisdatenpunkte auf der Grundlage der zeitlichen Abfolge als Morphismen miteinander verbinden.
Vergleichende Analyse und Einblicke
Wenn wir unsere Gezeiten-Kategorie der NASDAQ-Index-Kategorie zuordnen würden, müssten wir dies mit einer zeitlichen Verzögerung tun, um einen Prognosevorteil daraus zu ziehen. Zunächst müssen wir jedoch eine Instanz der Klasse ocean tide erstellen, die wie folgt dargestellt werden kann:
protected:
...
CCategory _category_ocean,_category_nasdaq;
CDomain<string> _domain_ocean,_domain_nasdaq;
CHomomorphism<string,string> _hmorph_ocean,_hmorph_nasdaq;
Da wir daran interessiert sind, diesen Funktor für die Vorhersage zu verwenden, wird unsere Kategorie dynamisch sein, da sie bei jedem neuen Balken neu definiert wird, aber der Funktor von ihr zur NASDAQ-Kategorie wird konstant sein. Da unsere Verzögerung einen Tag beträgt, können die drei oben erwähnten Morphismen, die die aufgezeichneten Meereshöhen miteinander verbinden, durch das Lesen der Gezeitendaten aus der csv-Datei wie folgt definiert werden:
void CTrailingCT::SetOcean(int Index)
{
...
if(_handle!=INVALID_HANDLE)
{
...
while(!FileIsLineEnding(_handle))
{
...
if(_date>_data_time)
{
_category_ocean.SetDomain(_category_ocean.Domains(),_domain_ocean);
break;
}
else if(__DATETIME.day_of_week!=6 && __DATETIME.day_of_week!=0 && datetime(int(_data_time)-int(_date))<=PeriodSeconds(PERIOD_D1))//_date<=_data_time && datetime(int(_data_time)-(1*PeriodSeconds(PERIOD_D1)))<=_date)
{
_element_value.Let();_element_value.Cardinality(1);_element_value.Set(0,DoubleToString(_value));
_domain_ocean.Cardinality(_elements);_domain_ocean.Set(_elements-1,_element_value);
_elements++;
}
}
FileClose(_handle);
}
else
{
printf(__FUNCSIG__+" failed to load file. Err: "+IntegerToString(GetLastError()));
}
}
In ähnlicher Weise werden wir unser Set für die NASDAQ-Volatilität mit der nachstehenden Auflistung erstellen:
void CTrailingCT::SetNasdaq(int Index)
{
m_high.Refresh(-1);
m_low.Refresh(-1);
_value=0.0;
_value=(m_high.GetData(Index+StartIndex()+m_high.MaxIndex(Index,_category_ocean.Homomorphisms()))-m_low.GetData(Index+StartIndex()+m_low.MinIndex(Index,_category_ocean.Homomorphisms())))/m_symbol.Point();
_element_value.Let();_element_value.Cardinality(1);_element_value.Set(0,DoubleToString(_value));
_domain_nasdaq.Cardinality(1);_domain_nasdaq.Set(0,_element_value);
_category_nasdaq.SetDomain(_category_nasdaq.Domains(),_domain_nasdaq);
}
Seine Morphismen werden ebenfalls auf nicht allzu unähnliche Weise zusammengesetzt. Nun bildet der Funktor, wie bereits in der Definition erwähnt, nicht nur die Objekte zwischen den beiden Kategorien ab, sondern auch die Morphismen. Das bedeutet, dass das eine das andere kontrolliert. Beginnen wir mit der Objektzuordnung, einem Teil unseres Funktors für Gezeitendaten nach NASDAQ, der wie folgt initialisiert wird:
double CTrailingCT::GetOutput()
{
...
...
_domain.Init(3+1,3);
for(int r=0;r<4;r++)
{
CDomain<string> _d;_d.Let();
_category_ocean.GetDomain(_category_ocean.Domains()-r-1,_d);
for(int c=0;c<_d.Cardinality();c++)
{
CElement<string> _e; _d.Get(c,_e);
string _s; _e.Get(0,_s);
_domain[r][c]=StringToDouble(_s);
}
}
_codomain.Init(3);
for(int r=0;r<3;r++)
{
CDomain<string> _d;
_category_nasdaq.GetDomain(_category_nasdaq.Domains()-r-1,_d);
CElement<string> _e; _d.Get(0,_e);
string _s; _e.Get(0,_s);
_codomain[r]=StringToDouble(_s);
}
_inputs.Init(3);_inputs.Fill(m_consant_morph);
M(_domain,_codomain,_inputs,_output,1);
return(_output);
}
Auf die gleiche Weise wird unsere Morphismus-Funktorkonstruktion die folgende Form annehmen:
double CTrailingCT::GetOutput()
{
...
...
_domain.Init(3+1,3);
for(int r=0;r<4;r++)
{
...
if(_category_ocean.Domains()-r-1-1>=0){ _category_ocean.GetDomain(_category_ocean.Domains()-r-1-1,_d_old); }
for(int c=0;c<_d_new.Cardinality();c++)
{
...
CElement<string> _e_old; _d_old.Get(c,_e_old);
string _s_old; _e_old.Get(0,_s_old);
_domain[r][c]=StringToDouble(_s_new)-StringToDouble(_s_old);
}
}
_codomain.Init(3);
for(int r=0;r<3;r++)
{
...
if(_category_nasdaq.Domains()-r-1-1>=0){ _category_nasdaq.GetDomain(_category_nasdaq.Domains()-r-1-1,_d_old); }
...
CElement<string> _e_old; _d_old.Get(0,_e_old);
string _s_old; _e_old.Get(0,_s_old);
_codomain[r]=StringToDouble(_s_new)-StringToDouble(_s_old);
}
_inputs.Init(3);_inputs.Fill(m_consant_morph);
M(_domain,_codomain,_inputs,_output,1);
return(_output);
}
Der größte Teil der Arbeit besteht darin, die Gezeitendaten für MQL5 zugänglich zu machen. Zu diesem Zweck wird auf die Daten aus einer csv-Datei im allgemeinen Datenordner in einem tabellarischen Format zugegriffen, das unserem Element in der Kategorie Meeresströmungen ähnelt. Das Datenformat enthält ein Datumsfeld zur Synchronisierung mit der Zeit unseres Handelsservers bei der Auswahl der richtigen Werte. MQL5 IDE hat andere Alternativen für den Zugriff auf solche sekundären Daten und eine davon ist über eine Datenbank, da ein natives Verbindungsdesign von der IDE aus möglich ist. Wenn Sie also eine Datenbank auf dem lokalen Rechner oder eine Cloud-Verbindung zu einer solchen haben, könnte dies untersucht werden. Für unsere Zwecke, da ich möchte, dass die Leser die hier veröffentlichten Testergebnisse leicht nachvollziehen können, wird eine csv-Datei im gemeinsamen Ordner verwendet.
Unser Funktor bildet zwei Dinge über die Kategorien hinweg ab, was bedeutet, dass wir, um Duplizität zu vermeiden, einfach eine Verbindung die andere überprüfen oder verifizieren lassen werden. Da wir zu Beginn nicht wissen, welches dieser Setups für unser Handelssystem ideal wäre, werden wir beide testen.
Im ersten Fall wird der Funktor über die Objekte die Morphismen zwischen den Objekten in der Codomain (NASDAQ-Menge) bestätigen oder verifizieren. Dies kann schematisch wie folgt dargestellt werden:
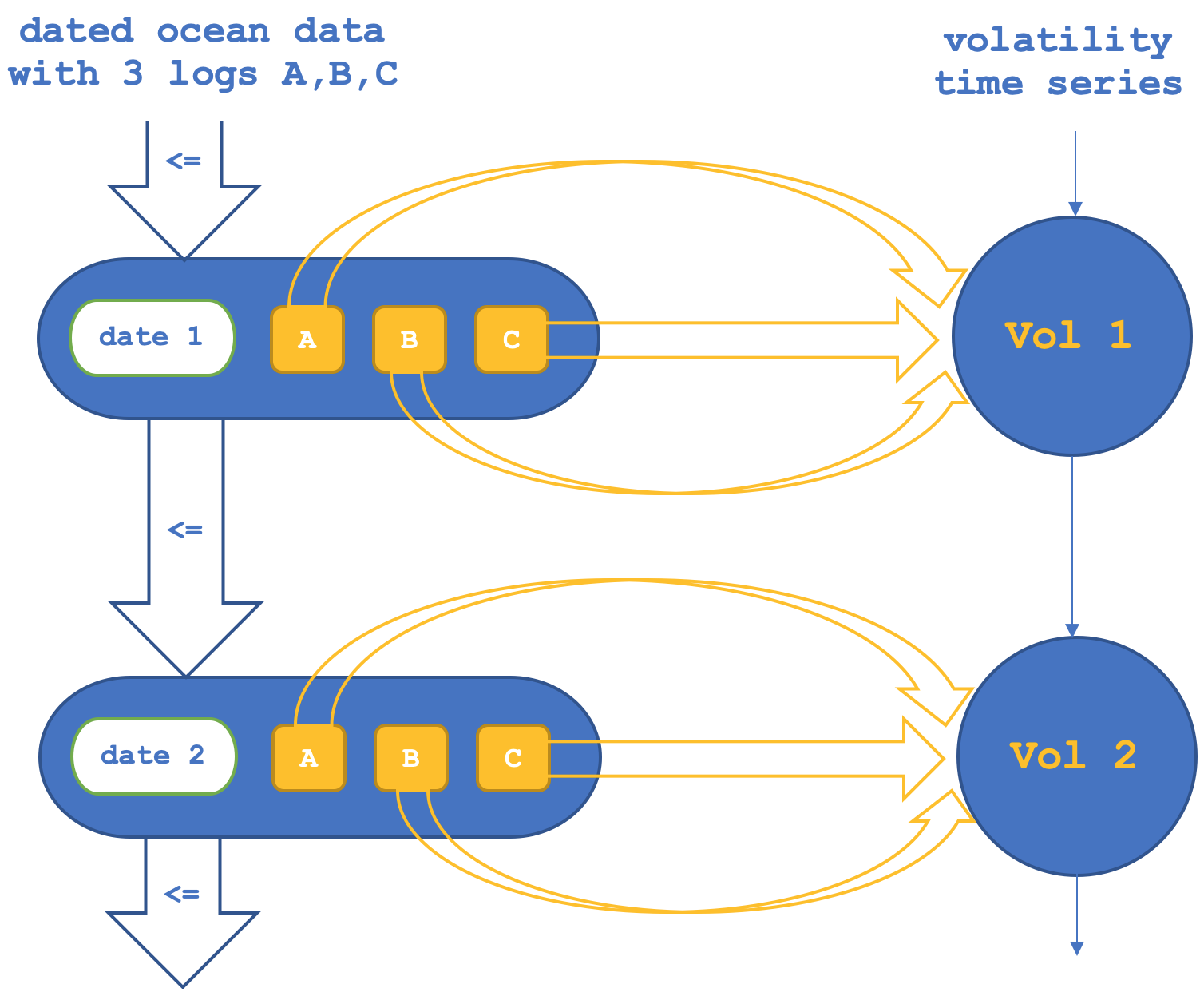
Wenn wir Tests zur Vorhersage der NASDAQ-Volatilität nur auf der Grundlage der Objektfunktionen durchführen, erhalten wir Berichte wie den folgenden (der Code hierfür ist als „TraillingCT_14_1a“ beigefügt):

Wenn wir, wie erwähnt, auch den umgekehrten Weg versuchen, indem wir uns auf die Funktoren über die Morphismen konzentrieren und dann die Objekte bestätigen, könnte dies wie folgt dargestellt werden:
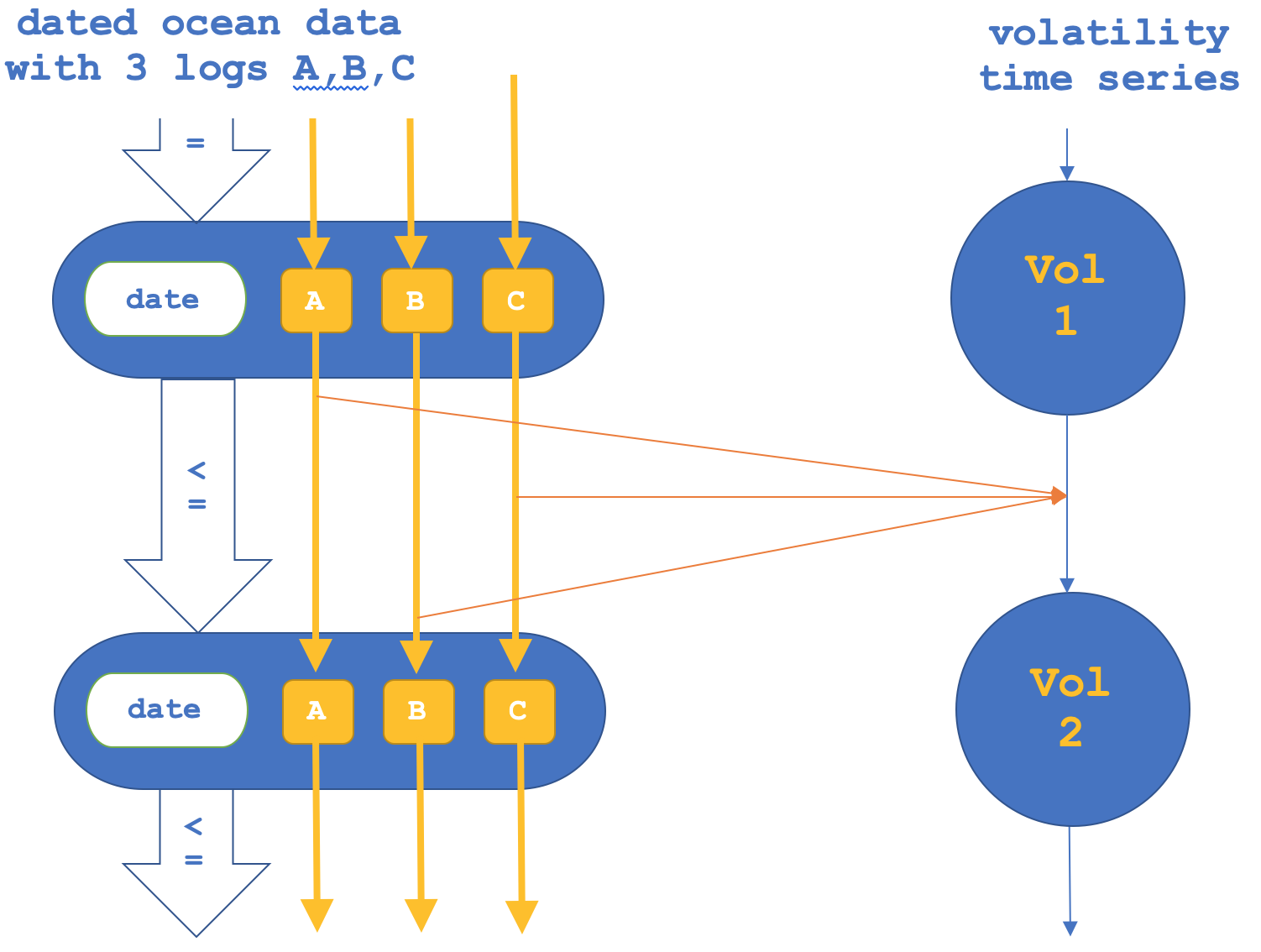
Ein Prüfbericht, nur für Morphismenfunktoren, ist unten angegeben:

Unsere beiden oben genannten Testoptionen, das Zuordnen von Objekten und das Zuordnen von Morphismen, ergaben selbst in dem sehr kurzen Testfenster vom 1. Januar 2020 bis zum 15. März desselben Jahres in einem täglichen Zeitrahmen unterschiedliche Ergebnisse. Welche der beiden Methoden für Händler bei der Erstellung von Prognosen jeglicher Art, nicht nur für die Volatilität, nützlicher ist, müsste über längere Zeiträume für den spezifischen Aspekt des getesteten Handelssystems getestet werden, sei es das Einstiegssignal, das Money Management oder der Trailing-Stop wie in diesem Fall.
Der für diesen Test gewählte Zeitraum war zwar sehr kurz, aber für den NASDAQ von großer Bedeutung, da der Index in dieser Zeit seinen Höchststand erreichte und dann, inmitten der einsetzenden Covid-Pandemie, ziemlich steil abfiel. Dieser Test deutet zwar auf eine mögliche Korrelation mit den Gezeitendaten hin, impliziert aber keineswegs eine Kausalität.
Wie in diesen Serien ist das verwendete Signal zu Eröffnung sehr einfach, in diesem Fall war es der eingebaute Awesome-Oszillator mit den Standardeinstellungen der jeweiligen Signaldatei. Auch die Positionsgröße wurde wie üblich auf eine feste Marge festgelegt. Wir haben den NASDAQ in einem täglichen Zeitrahmen getestet, da unsere Daten zu den Domänenkategorien täglich und in drei Intervallen erhoben wurden. Bei der Formatierung als kategorieäquivalente lineare Ordnung stellte also jeder Tag eine Domäne (ein Objekt) dar, die aus drei Elementen bestand, die, wie bereits erwähnt, die drei Datenpunkte eines jeden Tages waren.
Das Wichtigste dabei ist, dass disparate und scheinbar unzusammenhängende Datensätze untersucht und auf nützliche nachlaufende Beziehungen getestet werden können, die als Grundlage für Handelsentscheidungen dienen können. In unseren Tests betrug die Verzögerung nur einen Tag, bei Ihnen könnte sie länger sein. Mögliche alternative Datensätze zu dem, was wir hier verwendet haben, nämlich die Gezeiten des Ozeans, hätten gewählt werden können, und diese Liste ist sehr lang. Aber vielleicht wäre es hilfreich, ein paar Beispiele für Datensätze zu nennen, die die oben verwendeten Gezeitendaten ersetzen können und die ebenfalls mehr Einblicke in die Verflechtung unserer Märkte und exogenen Systeme geben würden.
Zu den alternativen Datensätzen könnten Rohstoffpreise gehören; Technologienachrichten, bei denen die Anzahl der Artikel über neue Technologietrends wie z. B. KI im Vergleich zu alternativen Nachrichtenartikeln, z. B. zum Thema Unterhaltung, mit einer Verzögerung auf mögliche Zusammenhänge hin verfolgt werden könnte; Stimmungsdaten aus den sozialen Medien über den Ton von Social-Media-Beiträgen, die mit lexikonbasierten Methoden quantifiziert werden, können ebenfalls auf Zusammenhänge mit der Volatilität der NASDAQ (oder eines anderen gehandelten Wertpapiers) untersucht werden, insbesondere, wenn es sich um Technologieaktien handelt. Auch diese Beispiele sind eher esoterischer Natur, um sich einen Vorteil zu verschaffen, aber man könnte auch Datensätze in Betracht ziehen, die näher an der Realität liegen, wie z. B. die Preise anderer Wertpapiere oder deren Indikatorwerte.
Schlussfolgerung
Zusammenfassend haben wir untersucht, wie Daten in einer linearen Ordnung durch einen Funktor mit Wertpapierkursen verknüpft werden können. In diesem Fall handelte es sich bei unseren Daten um einen unwahrscheinlichen Datensatz von Gezeitenhöhen vor der kalifornischen Küste, der über einen Funktor mit der Volatilität der NASDAQ mit einer Verzögerung von einem Tag verknüpft wurde. Diese Verknüpfung kann in zwei Formen erfolgen, entweder von Objekten zu Objekten oder von Morphismen zu Morphismen. Bei unseren Tests mit identischen Einstiegssignalen und Methoden zur Positionsgrößenbestimmung ergaben beide Formate angesichts des kurzen Testfensters deutlich unterschiedliche Ergebnisse.
Kategorientheoretische Funktoren sind wertvoll und können bei der Abbildung verschiedener Datentypen hilfreich sein. Wir haben für diesen Artikel einen ziemlich schwierigen Datensatz sortiert und zusammengestellt, aber der Leser kann sich auch leichtere Quellen ansehen, auch wenn sie ihm nicht unbedingt seinen Vorteil bringen, aber zu Testzwecken könnten sie aufschlussreich sein.
Künftige Möglichkeiten und Erweiterungen bei der Verknüpfung von linearen Ordnungen mit Mengen aus der Sicht des Händlers können in verschiedene Richtungen gehen. Dazu könnten gehören: Interdisziplinäre Anwendungen, die sich daraus ergeben könnten, dass Börsentrends auf andere Bereiche von Interesse übertragen werden, z. B. auf alternative Datensätze, wie oben angedeutet; prädiktive Modellierung, bei der Funktoren, die sich über sorgfältig festgelegte Zeitabstände erstrecken, wie sie in diesem Artikel getestet wurden, auch außerhalb der Finanzmärkte in Bereichen wie der Wettervorhersage angewendet werden könnten; Datenintegration und Wissensgraphen, bei denen die hier vorgestellten Konzepte die Darstellung in Bereichen wie der künstlichen Intelligenz verbessern könnten; maschinelles Lernen und Transferlernen, bei denen lineare Ordnungen, die sich auf Finanzdaten beziehen, weiterentwickelt werden könnten, z. B. wenn die zwischen zwei Kategorien gewonnenen Funktorengewichte getestet oder sogar in verschiedenen Bereichen angewandt werden könnten, wodurch die Modelle des maschinellen Lernens und ihre Wirksamkeit verbessert werden könnten.
Es gibt viele andere Möglichkeiten. Dazu gehören statistische Analysen und Datenfusion, zufällige Schlussfolgerungen und Korrelationsstudien, quantitative Finanzen mit algorithmischer Finanzierung, datengestützte Entscheidungsfindung usw., ohne Anspruch auf Vollständigkeit. Die Wahl der Anwendung hängt von der Perspektive oder der Herangehensweise an den Handel ab, wenn man selbst ein Händler ist.
Der Leser wird ermutigt, dieses Feld im Hinblick auf sein Fachgebiet und seine Herangehensweise an die Märkte zu erkunden, da die hier untersuchten Konzepte kaum an der Oberfläche kratzen. Der Bereich dieses Themas birgt viel Potenzial und lädt in gewisser Weise immer wieder dazu ein, in die Randbereiche der interdisziplinären Datenanalyse vorzudringen.
Platzieren Sie die Dateien ‚TrailingCT_14_1a.mqh‘ und ‚TrailingCT_14_1b.mqh‘ in den Ordner ‚MQL5\include\Expert\Trailing\‘ und ‚ct_14_1s.mqh‘ kann in den Ordner \Include liegen.
Es empfiehlt sich, diese Anleitung zur Erstellung eines Expert Advisors mit Hilfe des Assistenten zu befolgen, da Sie sie als Teil eines Expert Advisors zusammenstellen müssen. Wie im Artikel erwähnt, habe ich den Awesome Oscillator als Einstiegssignal und eine feste Losgröße für das Geldmanagement verwendet, die beide Teil der MQL5-Bibliothek sind. Wie immer ist das Ziel dieses Artikels nicht, Ihnen einen Gral zu präsentieren, sondern eine Idee, die Sie an Ihre eigene Strategie anpassen können. Die beigefügten MQL5-Dateien wurden vom Assistenten zusammengestellt, Sie können sie kompilieren oder Ihre eigenen Dateien zusammenstellen.
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/13018
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.