
Neuronale Netze leicht gemacht (Teil 33): Quantilsregression im verteilten Q-Learning

Inhaltsverzeichnis
- Einführung
- 1. Quantile Regression
- 2. Implementation in MQL5
- 3. Tests
- Schlussfolgerung
- Referenzen
- Programme, die im diesem Artikel verwendet werden
Einführung
Im vorangegangenen Artikel haben wir uns mit dem verteilten Q-Learning vertraut gemacht, das es ermöglicht, die Wahrscheinlichkeitsverteilung der vorhergesagten Belohnung zu lernen. Wir haben gelernt, wie man die Wahrscheinlichkeit vorhersagen kann, den erwarteten Gewinn in einem bestimmten Wertebereich zu erhalten. Die Anzahl solcher Bereiche und die Streuung der Belohnungswerte sind jedoch Hyperparameter des Modells. Daher ist Expertenwissen über die Verteilung der Belohnungswerte erforderlich, um die optimalen Parameter zu wählen. Außerdem müssen wir bestimmte Tests durchführen, um optimale Hyperparameter auszuwählen.
Es muss gesagt werden, dass der Ansatz, die gesamte Bandbreite möglicher Werte in gleiche Bereiche aufzuteilen, den wir zuvor betrachtet haben, auch seine Nachteile hat. Wir haben ein Neuron identifiziert, das die Wahrscheinlichkeit, eine Belohnung in jedem der einzelnen Bereiche zu erhalten, für jede Handlung vorhersagt. In der Praxis ist die Wahrscheinlichkeit, eine Belohnung in einer großen Anzahl von Bereichen zu erhalten, jedoch häufig gleich 0. Das bedeutet, dass wir unsere Ressourcen ineffizient nutzen. Wir könnten einige Bereiche kombinieren, um die Anzahl der Operationen zu verringern. Dies würde das Modelltraining und die Ausführung beschleunigen. Gleichzeitig ist die Wahrscheinlichkeit, Belohnungen in anderen Bereichen zu erhalten, recht hoch. Um ein vollständigeres Bild zu erhalten, können wir diesen Bereich in kleinere Komponenten aufteilen. Dies würde die Genauigkeit der Vorhersage der erwarteten Belohnung verbessern. Unser Ansatz erlaubt es jedoch nicht, verschiedene Größenbereiche zu erstellen. Diese Nachteile können gelöst werden unter Verwendung der Quantilen Regression, wie sie im Oktober 2017 in dem Artikel „Distributional Reinforcement Learning with Quantile Regression“ vorgestellt wurde.
1. Quantile Regression
Die Quantilsregression modelliert die Beziehung zwischen der Verteilung der erklärenden Variablen und bestimmten Quantilen der Zielvariablen.
Bevor wir uns mit der Verwendung der Quantilsregression beim verteilten Q-Learning befassen, sollte erwähnt werden, dass der vorgeschlagene Algorithmus die Bewertung der probabilistischen Verteilung der erwarteten Belohnung von der anderen Seite her angeht. Zuvor haben wir den Bereich der möglichen Belohnungswerte in verschiedene Abschnitte unterteilt. Im neuen Algorithmus teilen wir die Menge der erhaltenen Belohnungen in mehrere gleich wahrscheinliche Quantile ein. Was sind die Vorteile davon?
Wir haben noch einen Hyperparameter für die Anzahl der analysierten Quantile. Gleichzeitig schränken wir aber die Bandbreite der möglichen Belohnungswerte nicht ein. Stattdessen trainieren wir unser Modell, um die Medianwerte der Quantile vorherzusagen. Da wir gleichwahrscheinliche Quantile verwenden, gibt es keine Quantile mit einer Wahrscheinlichkeit von Null. Außerdem erhalten wir im Bereich der spärlichen Belohnungswerte größere Quantile. In Bereichen, in denen es viele Belohnungen geben wird, werden die Quantile in kleinere Teile aufgeteilt. Auf diese Weise erhalten wir ein vollständigeres Bild der Wahrscheinlichkeitsverteilung der erwarteten Belohnung. Darüber hinaus ermöglicht dieser Ansatz die Identifizierung von nicht-statischen Bereichen mit geringer und erhöhter Dichte von Belohnungswerten. Sie können je nach dem Zustand der Umwelt variieren.
Es bleibt jedoch das gleiche Q-Learning. Das Verfahren selbst basiert auf der Bellman-Optimierungsgleichung.

Diesmal müssen wir jedoch nicht nur einen Wert definieren, sondern die gesamte Verteilung. Aber im Grunde bleibt die Aufgabe dieselbe. Schauen wir uns die Aufgabe einmal genauer an.
Wie oben erwähnt, teilen wir die gesamte Belohnungsverteilung der Trainingsstichprobe in N gleichwertige Quantile auf. Jedes Quantil ist das Niveau, das von der analysierten Zufallsvariablen mit einer bestimmten Wahrscheinlichkeit nicht überschritten wird. Dabei sind gleichwahrscheinliche Quantile die Quantile mit einem konstanten Schrittweite, während alle Quantile zusammen den gesamten Trainingsdatensatz umfassen.
In der Praxis, wenn wir einen Trainingsdatensatz haben, ist die Wahrscheinlichkeit, eines der Elemente aus dem Datensatz zu erhalten 1. Es kann keine andere Möglichkeit geben, da alle Elemente aus dem Trainingsdatensatz stammen.
Die Aufteilung der Menge in N gleichwahrscheinliche Quantile bedeutet, dass der gesamte Trainingsdatensatz in N gleiche Teile aufgeteilt wird. Jedes von ihnen enthält die gleiche Anzahl von Elementen. Die Wahrscheinlichkeit, ein Element aus einer der Teilmengen zu wählen, beträgt 1/N.
Ein separates Quantil ist durch 2 Parameter gekennzeichnet: die Wahrscheinlichkeit der Auswahl eines Elements und die Obergrenze seiner Elementwerte. Eine zusätzliche Bedingung für Quantile ist ihre Sortierung in aufsteigender Reihenfolge bei der Akkumulation von Wahrscheinlichkeiten. Das bedeutet, dass die Obergrenze der Werte jedes nachfolgenden Quantils höher ist als die des vorherigen Quantils. Die Wahrscheinlichkeit eines Quantils schließt die Wahrscheinlichkeit der vorherigen Quantile ein. Zum Beispiel haben wir für eine bestimmte Verteilung ein Quantil von 0,2 mit einem Niveau von 15. Dies bedeutet, dass der Wert von 20 % der Elemente der gesamten Verteilung 15 nicht übersteigt. Die Abstufung der Wahrscheinlichkeiten und die Höhe der maximalen Quantilwerte sind möglicherweise nicht proportional, da sie von der jeweiligen Verteilung abhängen.
Der von uns in Betracht gezogene Algorithmus sieht eine Aufteilung des Datensatzes in Quantile mit einem festen Wahrscheinlichkeitsschritt vor. Anstelle von Obergrenzen werden wir das Modell so trainieren, dass es die Medianwerte der Quantile vorhersagt.
Um das Modell zu trainieren, benötigen wir Zielwerte. Wenn wir einen vollständigen Satz von Elementen eines bestimmten Datensatzes haben, können wir leicht den Durchschnittswert ermitteln.
Aber wir haben in der Praxis keinen vollständigen Satz. Wir erhalten nur dann Belohnungen von der Umwelt, wenn wir eine Handlung ausführen und in einen neuen Zustand übergehen. Wie Sie sehen, hat die Verwendung eines neuen Algorithmus für das Modelltraining keine Auswirkungen auf die Interaktion mit der Umwelt. Beim ursprünglichen Q-Learning haben wir das Modell so trainiert, dass es die durchschnittliche erwartete Belohnung vorhersagt. Wir taten dies, indem wir die Ergebnisse unseres Modells mit einem kleinen Lernkoeffizienten iterativ an die Zielwerte heranführten. Wie Sie sehen können, wird unser Modellergebnis während des Lernprozesses ständig durch eine Verschiebekraft in Richtung des aktuellen Zielwertes beeinflusst. Der Durchschnittswert wird in dem Moment erreicht, in dem sich die multidirektionalen Kräfte die Waage halten (wie in der Abbildung dargestellt).

Wir können einen ähnlichen Ansatz bei der Lösung von Problemen des neuen Algorithmus verwenden. Aber es gibt eine Sache. Mit diesem Algorithmus können wir den Durchschnittswert der Menge ermitteln. Dies entspricht einem Quantil von 0,5. Wenn wir es in seiner reinsten Form anwenden, erhalten wir auf allen Neuronen der Ergebnisschicht des Modells die gleichen Werte. Sie werden alle synchron arbeiten, wie ein einziges Neuron. Wir sollten jedoch die wahre Verteilung der Werte über die analysierten Quantile erhalten.
Schauen wir uns die Art des Quantils an. Nehmen wir zum Beispiel ein Quantil von 0,25, was einem Viertel des analysierten Datensatzes entspricht. Wenn wir den Abstand zwischen den Werten der Elemente vernachlässigen, dann sollte es für jedes 1 Element des Quantils 3 Elemente aus der Gesamtmenge geben, die nicht in dieses Quantil fallen. Um zu unserem obigen Beispiel zurückzukehren: Um ein Gleichgewicht am 0,25-Quantilspunkt zu erreichen, muss die Kraft der Wertminderung dreimal so groß sein wie die Kraft der Wertsteigerung für das Quantil.
Um den Wert eines jeden spezifischen Quantils zu ermitteln, müssen wir daher lediglich einen Korrekturfaktor in die Bellman-Gleichung einführen. Der Faktor hängt vom Quantilsniveau und der Richtung der Abweichung ab.
![]()
wobei τ das probabilistische Merkmal des Quantils ist.
Im Lernprozess verwenden wir alle Heuristiken des klassischen Q-Learning-Algorithmus in Form von Erfahrungsreproduktion und Target Net.
2. Implementation in MQL5
Nachdem wir uns mit den theoretischen Aspekten des Algorithmus beschäftigt haben, kommen wir nun zum praktischen Teil unseres Artikels. Wir werden prüfen, wie der Algorithmus mit MQL5 implementiert werden kann. Bei der Implementierung des Algorithmus werden wir keine neuen Architekturen von neuronalen Schichten erstellen. Wir werden jedoch die Prozessorganisation in die eigene Klasse CQRDQN verschieben. Dadurch wird die Verwendung der Methode in Expert Advisors vereinfacht und der Nutzer vor einigen Implementierungsdetails geschützt. Die Struktur der neuen Klasse ist unten dargestellt.
class CQRDQN : protected CNet { private: uint iCountBackProp; protected: uint iNumbers; uint iActions; uint iUpdateTarget; matrix<float> mTaus; //--- CNet cTargetNet; public: /** Constructor */ CQRDQN(void); CQRDQN(CArrayObj *Description) { Create(Description, iActions); } bool Create(CArrayObj *Description, uint actions); /** Destructor */~CQRDQN(void); bool feedForward(CArrayFloat *inputVals, int window = 1, bool tem = true) { return CNet::feedForward(inputVals, window, tem); } bool backProp(CBufferFloat *targetVals, float discount, CArrayFloat *nextState, int window = 1, bool tem = true); void getResults(CBufferFloat *&resultVals); int getAction(void); int getSample(void); float getRecentAverageError() { return recentAverageError; } bool Save(string file_name, datetime time, bool common = true) { return CNet::Save(file_name, getRecentAverageError(), (float)iActions, 0, time, common); } virtual bool Save(const int file_handle); virtual bool Load(string file_name, datetime &time, bool common = true); virtual bool Load(const int file_handle); //--- virtual int Type(void) const { return defQRDQN; } virtual bool TrainMode(bool flag) { return CNet::TrainMode(flag); } virtual bool GetLayerOutput(uint layer, CBufferFloat *&result) { return CNet::GetLayerOutput(layer, result); } //--- virtual void SetUpdateTarget(uint batch) { iUpdateTarget = batch; } virtual bool UpdateTarget(string file_name); //--- virtual bool SetActions(uint actions); };
Die neue Klasse ist von der Klasse CNet abgeleitet, die die Arbeit unserer neuronalen Netzmodelle organisiert. Das bedeutet, dass wir einen neuen Algorithmus für die Arbeit mit dem Modell entwickeln werden.
Um die wichtigsten Parameter unseres Algorithmus zu speichern, werden wir die folgenden Variablen erstellen:
- iNumbers — die Anzahl der Neuronen in der Menge, die die Verteilung einer Handlung beschreibt
- iActions — die Anzahl der möglichen Aktionsvarianten
- iUpdateTarget — Häufigkeit der Aktualisierung der Modellparameter Target Net
- mTaus — Matrix zum Schreiben probabilistischer Merkmale von Quantilen
- cTargetNet — Zeiger auf das Objekt Target Net
Achten Sie darauf, dass wir in der Matrix mTaus die Medianwerte der Wahrscheinlichkeiten der einzelnen Quantile eintragen.
Im Klassenkonstruktor legen wir die Anfangswerte für diese Variablen fest.
CQRDQN::CQRDQN() : iNumbers(31), iActions(2), iUpdateTarget(1000) { mTaus = matrix<float>::Ones(1, iNumbers) / iNumbers; mTaus[0, 0] /= 2; mTaus = mTaus.CumSum(0); cTargetNet.Create(NULL); Create(NULL, iActions); }
So wie in der Klasse CNet, die das Modell des neuronalen Netzes organisiert, werden wir zusätzlich zum Konstruktor ohne Parameter eine Methodenüberladung mit der Spezifikation der Architektur des Modells, das wir erstellen, erstellen.
CQRDQN(CArrayObj *Description) { Create(Description, iActions); }
Die Methode wird in der Methode Create erstellt. Die Methode erhält als Parameter einen Zeiger auf ein Array, das die Modellarchitektur und die Anzahl der möglichen Aktionen des Agenten beschreibt.
bool CQRDQN::Create(CArrayObj *Description, uint actions) { if(actions <= 0 || !CNet::Create(Description)) return false;
In der Methode prüfen wir, ob die Anzahl der Agentenaktionen korrekt angegeben ist. Wir rufen die Methode der übergeordneten Klasse mit demselben Namen auf. Sie enthält alle notwendigen Steuerelemente für das Objekt, das die Modellarchitektur beschreibt, und implementiert den Prozess der Modellerstellung. Hier prüfen wir nur das logische Ergebnis der Operationen der übergeordneten Klasse.
Nachdem wir erfolgreich ein neues Modell erstellt haben, nehmen wir die Ergebnisebene des erstellten Modells. Auf der Grundlage der Informationen über die Größe und die Anzahl der möglichen Agentenaktionen füllen wir die Matrix mTaus der probabilistischen Quantileigenschaften aus. Die Anzahl der Zeilen in dieser Matrix ist gleich der Größe der Wahrscheinlichkeitsverteilung der Belohnung für eine Aktion. Da die Wahrscheinlichkeiten jedes Quantils, die vor Beginn des Trainings festgelegt werden, für alle möglichen Aktionen des Agenten mit einem gleichen festen Schritt gleich sind, verwenden wir eine Vektormatrix mit einer Zeile. Wir verwenden eine Matrix anstelle eines Vektors, weil die Lösung weiter entwickelt wird und später variable Wahrscheinlichkeitsverteilungen für Aktionen implizieren kann.
int last_layer = Description.Total() - 1; CLayer *layer = layers.At(last_layer); if(!layer) return false; CNeuronBaseOCL *neuron = layer.At(0); if(!neuron) return false; iActions = actions; iNumbers = neuron.Neurons() / actions; mTaus = matrix<float>::Ones(1, iNumbers) / iNumbers; mTaus[0, 0] /= 2; mTaus = mTaus.CumSum(0); cTargetNet.Create(NULL); //--- return true; }
Beachten Sie, dass wir im ersten Schritt Target Net zurücksetzen. Dieser Ansatz verhindert, dass ein neues Modell auf absolut zufälligen Werten eines nicht trainierten Modells trainiert wird.
Zur Implementierung des Vorwärtsdurchlaufs wird eine ähnliche Methode der übergeordneten Klasse verwendet.
bool feedForward(CArrayFloat *inputVals, int window = 1, bool tem = true) { return CNet::feedForward(inputVals, window, tem); }
Was die Methode für den Rückwärtsdurchgang backProp betrifft, so müssen wir ein wenig mit ihr arbeiten. Ich möchte Sie daran erinnern, dass die Umgebung auf jede Aktion des Agenten mit einer Belohnung reagiert. Im klassischen Prozess Q-Learning haben wir eine Belohnungspolitik definiert. Da sich die möglichen Handlungen der Agenten beim Handel gegenseitig ausschließen und entgegengesetzter Natur sind, können wir die Belohnung für die entgegengesetzte Handlung anhand der Belohnung bestimmen, die die Umgebung für die ausgeführte Handlung zurückgegeben hat. Auf der Grundlage dieser Funktion können wir die Zielwerte für alle möglichen Aktionen bei jeder Iteration des Rückwärtsdurchlaufs übergeben. Dadurch wird der Lernprozess schneller und stabiler. Im verteilten Q-Learning-Prozess haben wir es jedoch mit einem ganzen Vektor von Zielwerten für jede Aktion zu tun. Im vorigen Artikel haben wir ein neues Verfahren zur Erstellung eines Tensors der Modellziele im EA des Modelltrainings entwickelt. Wir haben auch einen neuen Block zur Dekodierung der Modellergebnisse erstellt, bevor wir eine Aktion im Trading EA durchführen, um zu überprüfen, wie das trainierte Modell funktioniert.
Durch die Erstellung einer neuen Klasse können wir diesen Vorgang vor dem Nutzer verbergen. Dadurch wird die Arbeit mit dem Modell einfacher und übersichtlicher. Im Grunde ist es ähnlich wie beim klassischen Q-Learning, bei dem die Umgebung nur einen diskreten Belohnungswert pro Aktion liefert, während der gesamte Prozess der Umwandlung dieser diskreten Belohnung in einen Verteilungsvektor für jede Aktion im Körper der Feed-Backward-Methode implementiert ist.
Ich muss noch einen weiteren Vorteil der Verwendung einer neuen Klasse zur Implementierung des Prozesses erwähnen. Wie Sie wissen, verwendet das Q-Learning-Verfahren das Target Net, um zukünftige Belohnungen vorherzusagen. Zuvor musste der Nutzer mit zwei Modellen arbeiten. Jetzt können wir alle Arbeiten mit Target Net innerhalb der Methoden unserer Klasse verstecken. Das macht die Arbeit angenehmer. Dies erforderte jedoch eine Änderung der Parameter der Feed-Backward-Methode. Um den Durchgang der Backpropagation (feed backward) korrekt auszuführen, erwarten wir in diesem Fall vom Nutzer die Zielwerte sowie einen neuen Zustand des Systems.
Im Hauptteil der Methode für den Rückwärtsdurchlauf überprüfen wir zunächst die Korrektheit des empfangenen Zeigers auf den Zielwertevektor. Außerdem sollte die Größe des resultierenden Vektors gleich der Anzahl der möglichen Aktionen des Agenten sein.
bool CQRDQN::backProp(CBufferFloat *targetVals, float discount, CArrayFloat *nextState=NULL, int window = 1, bool tem = true) { //--- if(!targetVals) return false; vectorf target; if(!targetVals.GetData(target) || target.Size() != iActions) return false;
Dann überprüfen wir die Korrektheit des Zeigers auf den Vektor, der den neuen Systemzustand beschreibt. Falls erforderlich, implementieren wir ein Vorwärtsdurchlauf Target Net. Danach bestimmen wir die maximal mögliche Belohnung und passen die von der Umwelt erhaltene Belohnung unter Berücksichtigung des Abzinsungsfaktors an das zukünftige Einkommen an.
if(!!nextState) { if(!cTargetNet.feedForward(nextState, window, tem)) return false; vectorf temp; cTargetNet.getResults(targetVals); if(!targetVals.GetData(temp)) return false; matrixf q = matrixf::Zeros(1, temp.Size()); if(!q.Row(temp, 0) || !q.Reshape(iActions, iNumbers)) return false; temp = q.Mean(0); target = target + discount * temp.Max(); }
Wir verwenden die folgende Formel, um die Modellparameter zu aktualisieren.
![]()
Bitte beachten Sie jedoch, dass wir bei der Implementierung der obigen Formel in den Methodenkörper den Lernfaktor nicht verwenden werden. Hier gibt es einen kleinen Trick. Der Punkt ist, dass wir im Hauptteil der Methode, so seltsam es auch erscheinen mag, keine Modellparameter aktualisieren. Für unser Modell erstellen wir nur einen Vektor von Zielergebnissen. Die Modellparameter werden in der Methode der übergeordneten Klasse (die denselben Namen hat) aktualisiert. Wir werden den vollständigen Tensor der Zielmodellergebnisse an die Methoden der übergeordneten Klasse übergeben. Bei der Aktualisierung der Modellparameter werden wir den Lernkoeffizienten berücksichtigen.
In diesem Stadium haben wir bereits eine Belohnung von der Umwelt erhalten, einschließlich möglicher zukünftiger Vorteile. Um einen Vektor von Zielwerten zu erstellen, benötigen wir nur die letzten Ergebnisse des Feedforward-Durchgangs des Modells. Sie werden in die lokale Q-Matrix geladen.
vectorf quantils; getResults(targetVals); if(!targetVals.GetData(quantils)) return false; matrixf Q = matrixf::Zeros(1, quantils.Size()); if(!Q.Row(quantils, 0) || !Q.Reshape(iActions, iNumbers)) return false;
Danach können wir den erforderlichen Puffer für die Zielwerte des Modells erstellen. Zu diesem Zweck wird in einer Schleife ein Vektor mit den Zielwerten der Quantilniveaus für jede einzelne Aktion des Agenten aus den möglichen Aktionen erstellt. Bitte beachten Sie, dass die Verwendung von Matrix- und Vektoroperationen einige Tricks und Änderungen der Ansätze bei der Erstellung von Algorithmen erfordert. Andererseits wird der Einsatz von Schleifen reduziert. Dies erhöht im Allgemeinen die Geschwindigkeit der Programmausführung.
In diesem Fall entfällt durch die Verwendung von Vektoroperationen die Notwendigkeit, das System der verschachtelten Schleifen zu verwenden, in dem wir über alle Aktionen und alle Elemente der Verteilung für jede mögliche Aktion iterieren würden. Stattdessen verwenden wir nur eine Schleife für die möglichen Aktionen des Agenten. Die Anzahl der Iterationen der Schleife wird in den meisten Fällen um ein Vielfaches geringer sein als die Anzahl der Iterationen der eliminierten Schleife. Der Preis dafür ist jedoch, dass wir den Bedingungsoperator nicht verwenden können. Wir können nicht einfach zwei Elemente von Vektoren vergleichen und je nach Ergebnis eine Aktion auswählen.
Wir müssen beide Operationszweige für alle Elemente der Vektoren ausführen. Um das erwartete Ergebnis der Operationen nicht zu verfälschen, werden wir zwei Vektoren der Differenzen zwischen der von der Umgebung erhaltenen Belohnung und dem Ergebnis des letzten Vorwärtsdurchlaufs erstellen. Danach setzen wir in einem Vektor die negativen Werte zurück und im zweiten Vektor die positiven. Nach Multiplikation der erhaltenen Vektoren mit den entsprechenden Koeffizienten, die den Einfluss auf den durchschnittlichen Quantilwert regulieren, erhalten wir die gewünschten Korrekturwerte. Die Summe der empfangenen Vektoren und der letzten Ergebnisse des Vorwärtsdurchlaufs ergibt die Zielwerte, die wir für den Rückwärtsdurchlauf des Modells benötigen.
for(uint a = 0; a < iActions; a++) { vectorf q = Q.Row(a); vectorf dp = q - target[a], dn = dp; if(!dp.Clip(0, FLT_MAX) || !dn.Clip(-FLT_MAX, 0)) return false; dp = (mTaus.Row(0) - 1) * dp; dn = mTaus.Row(0) * dn * (-1); if(!Q.Row(dp + dn + q, a)) return false; } if(!targetVals.AssignArray(Q)) return false;
Sobald alle Schleifenwiederholungen abgeschlossen sind, aktualisieren wir die Werte im Zielwertpuffer.
Als Nächstes werden wir eine kleine Hilfestellung für die Arbeit mit Target Net geben. Wir werden einen Iterationszähler für Rückwärtsdurchläufe implementieren. Wenn der Schwellenwert für die Anzahl der Iterationen erreicht ist, wird das Modell Target net aktualisiert.
if(iCountBackProp >= iUpdateTarget) { #ifdef FileName if(UpdateTarget(FileName + ".nnw")) #else if(UpdateTarget("QRDQN.upd")) #endif iCountBackProp = 0; } else iCountBackProp++;
Achten Sie auf die Makro-Substitutionen im Vergleichsoperator, wenn der Schwellenwert für die Rückwärtsiteration erreicht ist. Wie bisher werden bei der Aktualisierung von Target Net die Parameter nicht direkt von einem Modell in ein anderes kopiert. Stattdessen speichern wir das Modell und stellen es dann aus einer Datei wieder her. Um diese Operation durchzuführen, benötigen wir einen Dateinamen.
In allen meinen Modellen habe ich die Makrosubstitution FileName verwendet, um einen eindeutigen Dateinamen zu generieren, der vom verwendeten Expert Advisor, Handelsinstrument und Zeitrahmen abhängt. Diese Makro-Substitution wird direkt im Expert Advisor zugewiesen. Die hier implementierte Makro-Substitution ermöglicht es uns, die Zuordnung der Makro-Substitution zur Erzeugung eines Dateinamens im Expert Advisor zu überprüfen. Und wenn es eine gibt, werden wir sie zum Speichern und Wiederherstellen der Datei verwenden. Andernfalls wird der Standarddateiname verwendet.
#define FileName Symb.Name()+"_"+EnumToString(TimeFrame)+"_"+StringSubstr(__FILE__,0,StringFind(__FILE__,".",0))
Am Ende unserer Methode rufen wir die Feed-Backward-Methode der übergeordneten Klasse auf und geben den vorbereiteten Tensor der Ziel-Ergebnisse als Parameter in sie ein. Das logische Ergebnis der Methodenoperationen der Elternklasse wird an das aufrufende Programm zurückgegeben.
return CNet::backProp(targetVals);
}
So haben wir dem Nutzer die Verwendung eines Wahrscheinlichkeitsverteilungsmodells bei der Durchführung eines Feed-Backward-Passes verborgen. Die Umwelt gibt nur eine diskrete Belohnung für jede Aktion. Der Aufruf der Feed-Backward-Methode erfolgt nun ähnlich wie beim klassischen Q-Learning-Algorithmus. Allerdings ersparen wir dem Nutzer die Steuerung des zweiten Modells von Target Net. Ich denke, dass dies die Nutzerfreundlichkeit des Modells erhöht. Die Frage des Vorwärtspasses bleibt jedoch offen.
Wie bereits erwähnt, wird für die Feed-Forward-Methode die Methode der übergeordneten Klasse verwendet. Dies hat keine negativen Auswirkungen auf direkte Vorwärtsoperationen, da die Vorwärtsdurchgangsmethode nur das logische Ergebnis der Operation zurückgibt. Die Frage stellt sich, wenn man versucht, die Ergebnisse des Vorwärtspasses zu erhalten. Die Methoden der übergeordneten Klasse geben die gesamte vom Modell erzeugte Wahrscheinlichkeitsverteilung zurück. Hier klafft eine Lücke zwischen Vorwärts- und Rückwärtszielen. Daher müssen wir die Methode zur Gewinnung der Vorwärtsergebnisse neu definieren, damit sie mit den Zielwerten des Rückwärtspasses vergleichbar werden.
Hier ist die Verwendung von Gleichwahrscheinlichkeitsquantilen hilfreich. Sie ermöglichen es uns, einfach den Durchschnittswert aus der gesamten erzeugten Verteilung über jede mögliche Aktion des Agenten zu finden und diesen Wert als erwartete Belohnung zurückzugeben. Auch hier verwenden wir Matrixoperationen, die den Aufbau des gesamten Algorithmusverfahrens ohne Schleifen ermöglichen.
Zu Beginn der Methode rufen wir die gleichnamige Methode der Elternklasse auf, die alle erforderlichen Steuerelemente und Operationen im Zusammenhang mit dem Kopieren der Ergebnisse des Vorwärtspasses in den Datenpuffer implementiert. Übertragen wir die erhaltenen Daten in die Matrix. Die Matrix wird in eine tabellarische Matrix umgewandelt, wobei die Anzahl der Zeilen der Anzahl der möglichen Agentenaktionen entspricht. In diesem Fall ist jede Zeile ein Vektor mit der Wahrscheinlichkeitsverteilung der erwarteten Belohnung für jede einzelne Handlung. Daher benötigen wir nur eine Matrixfunktion, Mean, um die Durchschnittswerte für alle möglichen Aktionen des Agenten zu bestimmen. Wir müssen nur noch das Ergebnis in den Datenpuffer übertragen und an den Aufrufer zurückgeben.
void CQRDQN::getResults(CBufferFloat *&resultVals) { CNet::getResults(resultVals); if(!resultVals) return; vectorf temp; if(!resultVals.GetData(temp)) { delete resultVals; return; } matrixf q; if(!q.Init(1, temp.Size()) || !q.Row(temp, 0) || !q.Reshape(iActions, iNumbers)) { delete resultVals; return; } //--- if(!resultVals.AssignArray(q.Mean(1))) { delete resultVals; return; } //--- }
Sie werden sich vielleicht fragen, warum wir das alles gemacht haben, wenn wir zum Durchschnittswert zurückgekehrt sind, den das ursprüngliche Q-Learning trainiert. Ohne mich in mathematische Erklärungen zu vertiefen, möchte ich eines sagen, das durch praktische Ergebnisse bestätigt wurde. Die Wahrscheinlichkeit des Mittelwerts der Menge ist nicht gleich dem Mittelwert der Wahrscheinlichkeiten der Teilmengen derselben Menge. Der ursprüngliche Q-Learning-Algorithmus lernt die Wahrscheinlichkeit des Mittelwerts der Menge. Das verteilte Q-Training lernt jedoch mehrere Mittelwerte für jedes Quantil. Und dann wird der Durchschnitt dieser Wahrscheinlichkeitswerte ermittelt.
Wie wissenschaftliche Arbeiten und die Praxis zeigen, wird die Quantilsregression im Allgemeinen weniger von verschiedenen Ausreißern beeinflusst. Dadurch wird der Prozess der Modellbildung stabiler. Außerdem sind die Ergebnisse einer solchen Ausbildung weniger verzerrt. Die Autoren der Methode präsentierten die Ergebnisse des Lernens der Arbeit der trainierten Modelle an 57 Atari-Spielen im Vergleich zu den Leistungen der Modelle, die mit anderen Algorithmen trainiert wurden. Die Daten zeigen, dass das durchschnittliche Ergebnis fast viermal höher ist als das Ergebnis des ursprünglichen Q-Learnings(DQN). Nachstehend finden Sie eine Tabelle mit den Ergebnissen aus dem Originalartikel
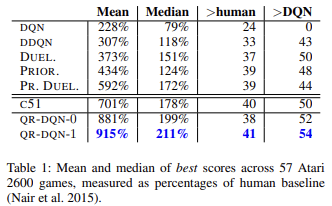
Die Verbesserung der Nutzerfreundlichkeit des Modells. Bei der Erstellung von EAs zum Testen aller Reinforcement-Learning-Modelle haben wir verschiedene Methoden zur Auswahl einer Aktion auf der Grundlage der Feedforward-Ergebnisse des trainierten Modells entwickelt. Die Erstellung der neuen Klasse ermöglicht es uns, Methoden zu implementieren, die diese Funktion erfüllen. Für eine gierige Aktionsauswahl auf der Grundlage der maximalen erwarteten Belohnung erstellen wir die Methode getAction. Der Algorithmus ist recht einfach. Wir werden die oben beschriebene Methode getResults nur verwenden, um die Ergebnisse des Vorwärtsdurchlaufs zu erhalten. Aus dem resultierenden Puffer wählen wir das Element mit dem höchsten Wert aus.
int CQRDQN::getAction(void) { CBufferFloat *temp; getResults(temp); if(!temp) return -1; //--- return temp.Maximum(0, temp.Total()); }
Wir setzen die Strategie der ɛ-greedy Handlungswahl nicht ein, da sie im Trainingsprozess des Modells verwendet wird, um den Lerngrad der Umgebung zu erhöhen. Aufgrund unserer Belohnungspolitik ist es nicht notwendig, diese Methoden anzuwenden. Im Lernprozess geben wir Ziele für alle möglichen Aktionen des Agenten vor.
Die zweite Methode getSample wird für eine zufällige Auswahl einer Aktion aus der Wahrscheinlichkeitsverteilung verwendet, bei der eine größere Belohnung eine größere Wahrscheinlichkeit hat. Um unnötiges Kopieren von Daten zwischen Matrizen und Datenpuffern zu vermeiden, wird der Algorithmus der Methode getResults teilweise wiederholt.
int CQRDQN::getSample(void) { CBufferFloat* resultVals; CNet::getResults(resultVals); if(!resultVals) return -1; vectorf temp; if(!resultVals.GetData(temp)) { delete resultVals; return -1; } delete resultVals; matrixf q; if(!q.Init(1, temp.Size()) || !q.Row(temp, 0) || !q.Reshape(iActions, iNumbers)) { delete resultVals; return -1; }
Anschließend werden die Ergebnisse des Vorwärtsdurchlaufs mit der SoftMax-Funktion normalisiert. Dies sind die Wahrscheinlichkeiten für die Auswahl der Maßnahmen.
if(!q.Mean(1).Activation(temp, AF_SOFTMAX)) return -1; temp = temp.CumSum();
Wir sammeln den Vektor der kumulativen Summen der Wahrscheinlichkeiten und führen eine Stichprobe aus dem resultierenden Vektor der Wahrscheinlichkeitsverteilung durch.
int err_code; float random = (float)Math::MathRandomNormal(0.5, 0.5, err_code); if(random >= 1) return (int)temp.Size() - 1; for(int i = 0; i < (int)temp.Size(); i++) if(random <= temp[i] && temp[i] > 0) return i; //--- return -1; }
Rückgabe des Stichprobenergebnisses an das aufrufende Programm.
Wir haben uns mit Vorwärts- und Rückwärtsmethoden sowie mit Methoden zur Gewinnung der Modellergebnisse befasst. Es gibt jedoch noch eine Reihe unbeantworteter Fragen. Eine davon ist die Modellaktualisierungsmethode Target Net — UpdateTarget. Wir haben diese Methode bei der Diskussion über die Backpropagation-Methode erwähnt. Obwohl diese Methode von einer anderen Klassenmethode aufgerufen wird, habe ich beschlossen, sie öffentlich zu deklarieren und dem Nutzer den Zugriff darauf zu ermöglichen. Es stimmt, wir haben die Notwendigkeit beseitigt, den Zustand von Target Net von der Nutzerseite aus zu kontrollieren. Allerdings schränken wir die Wahlfreiheit nicht ein. Falls erforderlich, kann der Nutzer alles kontrollieren.
Der Algorithmus der Methode ist recht einfach. Wir rufen einfach zuerst die Speichermethode des aktuellen Objekts auf. Dann rufen wir die Datenwiederherstellung Target Net auf. Für jeden Vorgang kontrollieren wir den Ausführungsprozess. Sobald Target Net erfolgreich aktualisiert wurde, setzen wir den Zähler für die Rückwärtsiterationen zurück.
bool CQRDQN::UpdateTarget(string file_name) { if(!Save(file_name, 0, false)) return false; float error, undefine, forecast; datetime time; if(!cTargetNet.Load(file_name, error, undefine, forecast, time, false)) return false; iCountBackProp = 0; //--- return true; }
Achten Sie auf den Unterschied zwischen den Objektklassen. Wir arbeiten mit der neuen Klasse CQRDQN, während Target Net eine Instanz der übergeordneten Klasse CNet ist. Der Punkt ist, dass wir nur die Feed Forward-Funktionalität von Target Net verwenden. Diese Methode wurde in unserer Klasse nicht geändert. Daher sollte es kein Problem sein, die übergeordnete Klasse zu verwenden. Gleichzeitig wird bei Verwendung einer Instanz der Klasse CQRDQN für Target Net das innere Objekt Target Net für die neue Instanz rekursiv erstellt. Ein solcher wiederkehrender Prozess kann zu kritischen Fehlern führen. Daher kann ein so unbedeutendes Detail erhebliche Auswirkungen auf die Funktionsweise des gesamten Programms haben.
Wir haben die Hauptfunktionalität der neuen Klasse CQRDQN betrachtet, die den Quantilsregressionsalgorithmus im verteilten Q-Learning (QR-DQN) implementiert. Die Methode wurde im Oktober 2017 in dem Artikel „Distributional Reinforcement Learning with Quantile Regression" vorgestellt.
In der Klasse sind auch die Methoden zum Speichern des Modells — Save — und zum späteren Wiederherstellen — Load — implementiert. Die Änderungen bei diesen Methoden sind nicht so kompliziert. Sie können sie in dem unten beigefügten Code studieren. Jetzt schlage ich vor, die neue Klasse zu testen.
3. Tests
Testen wir nun die neue Klasse, indem wir das Modell trainieren. Zum Trainieren des Modells wurde der spezielle EA QRDQN-learning.mq5 erstellt. Der EA wurde auf der Grundlage des ursprünglichen EAs in Q-learning Q-learning.mq5 erstellt. In dieser EA haben wir die Klasse des zu trainierenden Modells geändert und die Deklaration der Instanz des Modells Target Net entfernt.
CSymbolInfo Symb;
MqlRates Rates[];
CQRDQN StudyNet;
CBufferFloat *TempData;
CiRSI RSI;
CiCCI CCI;
CiATR ATR;
CiMACD MACD;
In der EA-Initialisierungsmethode laden wir das Modell aus einer zuvor erstellten Datei, erzwingen die Aktivierung des Lernmodus für alle neuronalen Schichten, definieren die Tiefe der analysierten Historie entsprechend der Größe der Quelldatenschicht, geben die Größe des Bereichs der zulässigen Aktionen in das Modell ein. Wir geben auch den Aktualisierungszeitraum für Target Net an. In diesem Fall habe ich einen absichtlich zu hoch angesetzten Wert angegeben, da ich vorhabe, den Prozess der Modellaktualisierung selbst zu steuern.
int OnInit() { //--- ......... ......... //--- if(!StudyNet.Load(FileName + ".nnw", dtStudied, false)) return INIT_FAILED; if(!StudyNet.TrainMode(true)) return INIT_FAILED; //--- if(!StudyNet.GetLayerOutput(0, TempData)) return INIT_FAILED; HistoryBars = TempData.Total() / 12; if(!StudyNet.SetActions(Actions)) return INIT_PARAMETERS_INCORRECT; StudyNet.SetUpdateTarget(1000000); //--- ........ //--- return(INIT_SUCCEEDED); }
Der Prozess des Modelllernens selbst wird in der Funktion Train mit folgenden Parametern durchgeführt.
void Train(void) { //--- MqlDateTime start_time; TimeCurrent(start_time); start_time.year -= StudyPeriod; if(start_time.year <= 0) start_time.year = 1900; datetime st_time = StructToTime(start_time);
In der Funktion legen wir den Trainingszeitraum fest und laden die historischen Daten. Dieser Prozess ist in seiner ursprünglichen Form vollständig erhalten.
int bars = CopyRates(Symb.Name(), TimeFrame, st_time, TimeCurrent(), Rates); if(!RSI.BufferResize(bars) || !CCI.BufferResize(bars) || !ATR.BufferResize(bars) || !MACD.BufferResize(bars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } if(!ArraySetAsSeries(Rates, true)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh();
Als Nächstes implementieren wir ein System von verschachtelten Schleifen für den Modellbildungsprozess. Die äußere Schleife zählt die Trainingsepochen für die Aktualisierung des Modells Target Net herunter.
int total = bars - (int)HistoryBars - 240; bool use_target = false; //--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int i = 0; uint ticks = GetTickCount(); int count = 0; int total_max = 0;
In der verschachtelten Schleife werden die Vorwärts- und Rückwärtsdurchläufe durchgeführt. Hier werden wir zunächst historische Daten aufbereiten, um die beiden nachfolgenden Zustände des Systems zu beschreiben. Eine davon wird für den Feedforward-Durchlauf des zu trainierenden Modells verwendet. Die zweite wird für Target Net verwendet.
for(int batch = 0; batch < (Batch * UpdateTarget); batch++) { i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * total + 240); State1.Clear(); State2.Clear(); int r = i + (int)HistoryBars; if(r > bars) continue; for(int b = 0; b < (int)HistoryBars; b++) { int bar_t = r - b; float open = (float)Rates[bar_t].open; TimeToStruct(Rates[bar_t].time, sTime); float rsi = (float)RSI.Main(bar_t); float cci = (float)CCI.Main(bar_t); float atr = (float)ATR.Main(bar_t); float macd = (float)MACD.Main(bar_t); float sign = (float)MACD.Signal(bar_t); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- if(!State1.Add((float)Rates[bar_t].close - open) || !State1.Add((float)Rates[bar_t].high - open) || !State1.Add((float)Rates[bar_t].low - open) || !State1.Add((float)Rates[bar_t].tick_volume / 1000.0f) || !State1.Add(sTime.hour) || !State1.Add(sTime.day_of_week) || !State1.Add(sTime.mon) || !State1.Add(rsi) || !State1.Add(cci) || !State1.Add(atr) || !State1.Add(macd) || !State1.Add(sign)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } if(!use_target) continue; //--- bar_t --; open = (float)Rates[bar_t].open; TimeToStruct(Rates[bar_t].time, sTime); rsi = (float)RSI.Main(bar_t); cci = (float)CCI.Main(bar_t); atr = (float)ATR.Main(bar_t); macd = (float)MACD.Main(bar_t); sign = (float)MACD.Signal(bar_t); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- if(!State2.Add((float)Rates[bar_t].close - open) || !State2.Add((float)Rates[bar_t].high - open) || !State2.Add((float)Rates[bar_t].low - open) || !State2.Add((float)Rates[bar_t].tick_volume / 1000.0f) || !State2.Add(sTime.hour) || !State2.Add(sTime.day_of_week) || !State2.Add(sTime.mon) || !State2.Add(rsi) || !State2.Add(cci) || !State2.Add(atr) || !State2.Add(macd) || !State2.Add(sign)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } }
Implementieren wir das Feed-Forward des Modells, das wir trainieren.
if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } if(State1.Total() < (int)HistoryBars * 12 || (use_target && State2.Total() < (int)HistoryBars * 12)) continue; if(!StudyNet.feedForward(GetPointer(State1), 12, true)) return;
Danach erzeugen wir einen Stapel von Belohnungen für alle möglichen Aktionen des Agenten und rufen die Feed-Backward-Methode des Hauptmodells auf.
Rewards.BufferInit(Actions, 0); double reward = Rates[i].close - Rates[i].open; if(reward >= 0) { if(!Rewards.Update(0, (float)(2 * reward))) return; if(!Rewards.Update(1, (float)(-5 * reward))) return; if(!Rewards.Update(2, (float) - reward)) return; } else { if(!Rewards.Update(0, (float)(5 * reward))) return; if(!Rewards.Update(1, (float)(-2 * reward))) return; if(!Rewards.Update(2, (float)reward)) return; }
Bitte beachten Sie, dass wir gemäß der überschriebenen Feed-Backward-Methode nicht nur den Belohnungspuffer, sondern auch den aktuellen Zustand in die Methode eingeben, der dann folgt. Wir haben auch den Block der Operationen und der Belohnungsanpassungen von Target Net für das erwartete Einkommen zukünftiger Zustände entfernt.
if(!StudyNet.backProp(GetPointer(Rewards), DiscountFactor, (use_target ? GetPointer(State2) : NULL), 12, true)) return;
Wir geben die Informationen über den Prozessfortschritt in der Symboltabelle aus.
if(GetTickCount() - ticks > 500) { Comment(StringFormat("%.2f%%", batch * 100.0 / (double)(Batch * UpdateTarget))); ticks = GetTickCount(); } }
Damit sind die verschachtelten Schleifenoperationen abgeschlossen. Und nachdem alle Iterationen abgeschlossen sind, überprüfen wir den aktuellen Modellfehler. Wenn die zuvor erzielten Ergebnisse verbessert wurden, speichern wir den aktuellen Modellstatus und aktualisieren Target Net.
if(StudyNet.getRecentAverageError() <= min_loss) { if(!StudyNet.UpdateTarget(FileName + ".nnw")) continue; use_target = true; min_loss = StudyNet.getRecentAverageError(); } PrintFormat("Iteration %d, loss %.8f", iter, StudyNet.getRecentAverageError()); } Comment(""); //--- PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); }
Damit sind die Operationen der äußeren Schleife und die Lernfunktion als Ganzes abgeschlossen. Der Rest des EA-Codes hat sich nicht geändert. Der vollständige Code aller Klassen und Programme ist im Anhang zu finden.
Ein Trainingsmodell wurde mit dem Hilfsmittel NetCreator erstellt. Die Architektur des Modells ist die gleiche wie die des Trainingsmodells aus dem vorherigen Artikel. Ich habe die letzte SoftMax-Normalisierungsschicht entfernt, damit der Bereich mit den Modellergebnissen alle Ergebnisse der verwendeten Belohnungspolitik wiedergeben kann.
Wie zuvor wurde das Modell mit historischen EURUSD-Daten im H1-Zeitrahmen trainiert. Als Trainingsdatensatz wurden historische Daten der letzten 2 Jahre verwendet.
Die Arbeit des trainierten Modells wurde mit dem Strategietester getestet. Zu Testzwecken wurde der separate EA QRDQN-learning-test.mq5 erstellt. Der EA wurde auch auf der Grundlage ähnlicher EAs aus früheren Artikeln erstellt. Der Code hat sich nicht wesentlich geändert. Der gesamte EA-Code ist im Anhang zu finden.
Im Strategietester zeigte das Modell die Fähigkeit, innerhalb eines kurzen Zeitraums von 2 Wochen Gewinne zu erzielen. Mehr als die Hälfte der Positionen wurde mit einem Gewinn abgeschlossen. Der durchschnittliche Gewinn pro Handel war fast doppelt so hoch wie der durchschnittliche Verlust.


Schlussfolgerung
In diesem Artikel haben wir eine weitere Methode des Reinforcement Learning kennengelernt. Wir haben eine Klasse erstellt, um diese Methode zu implementieren. Wir haben das Modell trainiert und seine Handelsergebnisse im Strategietester überprüft. Auf der Grundlage der erzielten Ergebnisse können wir schließen, dass es möglich ist, den Quantilsregressionsalgorithmus im verteilten Q-Learning zu verwenden, um Modelle zu implementieren, die reale Marktprobleme lösen können.
Ich möchte Sie noch einmal darauf hinweisen, dass alle in diesem Artikel vorgestellten Programme nur zu Demonstrationszwecken dienen. Die Modelle und EAs müssen weiter verbessert und umfassend getestet werden, bevor sie im realen Handel eingesetzt werden können.
Referenzen
- Neuronale Netze leicht gemacht (Teil 26): Reinforcement-Learning
- Neuronale Netze leicht gemacht (Teil 27): Tiefes Q-Learning (DQN)
- Neuronale Netze leicht gemacht (Teil 28): Policy Gradient Algorithmus
- Neuronale Netze leicht gemacht (Teil 32): Verteiltes Q-Learning
- A Distributional Perspective on Reinforcement Learning
- Distributional Reinforcement Learning with Quantile Regression
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | QRDQN-learning.mq5 | EA | EA zur Optimierung des Modells |
| 2 | QRDQN-learning-test.mq5 | EA | Ein Expert Advisor zum Testen des Modells im Strategy Tester |
| 3 | QRDQN.mqh | Klassenbibliothek | QR-DQN-Modellklasse |
| 4 | NeuroNet.mqh | Klassenbibliothek | Bibliothek zur Erstellung neuronaler Netzmodelle |
| 5 | NeuroNet.cl | Code Base | OpenCL-Programmcode-Bibliothek zur Erstellung neuronaler Netzwerkmodelle |
| 6 | NetCreator.mq5 | EA | Tool für die Modellbildung |
| 7 | NetCreatotPanel.mqh | Klassenbibliothek | Klassenbibliothek zur Erstellung des Tools |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/11752
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Hallo,
danke für deine harte Arbeit, ich weiß deine Zeit und Mühe zu schätzen.
hatte VAE aus Artikel # 22 zu greifen, wenn ich versucht, QRDQN zu kompilieren.
Aber ich bin auf diesen Fehler gestoßen,
'MathRandomNormal' - nicht deklarierter Bezeichner VAE.mqh 92 8
Ich vermute, die VAE-Bibliothek in #22 ist veraltet?
Hallo,
vielen Dank für Ihre harte Arbeit, ich weiß Ihre Zeit und Mühe zu schätzen.
hatte VAE aus Artikel # 22 zu greifen, wenn ich versucht, QRDQN zu kompilieren.
aber in diesen Fehler laufen,
'MathRandomNormal' - nicht deklarierter Bezeichner VAE.mqh 92 8
Ich vermute, die VAE-Bibliothek in #22 ist veraltet?
Hallo, Sie können aktualisierte Dateien aus diesem Artikel laden https://www.mql5.com/de/articles/11619
Hallo, Sie können aktualisierte Dateien aus diesem Artikel laden https://www.mql5.com/en/articles/11619
vielen Dank für Ihre Antwort,
Ich habe das getan und der Fehler ist behoben, aber 2 weitere sind aufgetreten.
einer
Create' - Ausdruck vom Typ 'void' ist illegal QRDQN.mqh 85 30
2
''AssignArray' - keine der Überladungen kann auf den Funktionsaufruf angewendet werden QRDQN.mqh 149 19