
Verwendung des Algorithmus PatchTST für maschinelles Lernen zur Vorhersage der Kursentwicklung in den nächsten 24 Stunden
Einführung
Ich stieß zum ersten Mal auf einen Algorithmus namens PatchTST, als ich begann, mich mit den KI-Fortschritten im Zusammenhang mit Zeitreihenvorhersagen auf Huggingface.co zu beschäftigen. Wie jeder, der mit großen Sprachmodellen (LLMs) gearbeitet hat, weiß, hat die Erfindung von Transformatoren die Entwicklung von Tools für die Verarbeitung natürlicher Sprache, Bilder und Videos entscheidend beeinflusst. Aber was ist mit Zeitreihen? Ist es etwas, das einfach zurückgelassen wird? Oder findet der Großteil der Forschung einfach hinter verschlossenen Türen statt? Es hat sich gezeigt, dass es viele neuere Modelle gibt, die Transformatoren erfolgreich für die Vorhersage von Zeitreihen einsetzen. In diesem Artikel werden wir uns eine solche Implementierung ansehen.
Das Beeindruckende an PatchTST ist, wie schnell ein Modell trainiert werden kann und wie einfach es ist, das trainierte Modell mit MQL zu verwenden. Ich gebe offen zu, dass ich mit dem Konzept der neuronalen Netze noch nicht vertraut bin. Aber als ich diesen Prozess durchlief und die in diesem Artikel beschriebene Implementierung von PatchTST für MQL5 in Angriff nahm, hatte ich das Gefühl, dass ich einen riesigen Sprung nach vorne gemacht habe, was das Lernen und Verstehen der Entwicklung, Fehlersuche, Schulung und Verwendung dieser komplexen neuronalen Netzwerke angeht. Es ist, als würde man ein Kind, das gerade erst laufen lernt, in eine Profifußballmannschaft stecken und von ihm erwarten, dass es im Finale der Fußballweltmeisterschaft das Siegestor schießt.
PatchTST Überblick
Nachdem ich PatchTST entdeckt hatte, begann ich, mich mit dem Papier zu befassen, in dem das Design erläutert wird: „A Time Series is Worth 64 Words: Long-term Forecasting with Transformers“. Der Titel war interessant. Als ich anfing, mehr in das Papier hineinzulesen, dachte ich, wow, das sieht nach einer faszinierenden Struktur aus - sie hat viele Elemente, über die ich schon immer etwas lernen wollte. Deshalb wollte ich es natürlich ausprobieren und sehen, wie die Vorhersagen funktionieren. Das hat mein Interesse an diesem Algorithmus noch verstärkt:
- Mit PatchTST können Sie Eröffnungs-, Hoch-, Tief- und Schlusskurse vorhersagen. Bei PatchTST hatte ich das Gefühl, dass man es mit allen Daten füttern kann, die anfallen - Eröffnungs-, Hoch-, Tief- und Schlusskurse und sogar das Volumen. Sie können davon ausgehen, dass es die Muster in den Daten finden wird, da alle Daten in so genannte „Patches“ umgewandelt werden. Mehr dazu, was Patches sind, etwas später in diesem Artikel. Im Moment ist es nur wichtig zu wissen, dass Patches ansprechend sind und dazu beitragen, die Vorhersagen zu verbessern.
- Minimale Anforderungen an die Datenvorverarbeitung mit PatchTST. Als ich anfing, den Algorithmus näher zu untersuchen, wurde mir klar, dass die Autoren etwas verwenden, das „RevIn“ genannt wird, was eine umgekehrte Instanznormalisierung ist. RevIn stammt aus einem Artikel mit dem Titel: „Reversible instance normalization for accurate time-series forecasting against distribution shift“. RevIn versucht, das Problem der Verteilungsverschiebung bei Zeitreihenprognosen zu lösen. Als algorithmische Händler kennen wir das Gefühl nur zu gut, wenn unser trainierter EA den Markt nicht mehr vorherzusagen scheint und wir gezwungen sind, unsere Parameter neu zu optimieren und zu aktualisieren. Betrachten Sie RevIn als eine Möglichkeit, das Gleiche zu tun.
- Bei dieser Methode werden die übergebenen Daten anhand der folgenden Formel normalisiert:
x = (x - mean) / std
Wenn das Modell dann eine Vorhersage machen muss, denormalisiert es die Daten unter Verwendung der entgegengesetzten Eigenschaft:
x = x * std + mean
RevIn hat auch eine weitere Eigenschaft namens affine_bias. Vereinfacht ausgedrückt handelt es sich dabei um einen erlernbaren Parameter, der die im Datensatz vorhandene Schiefe, Kurtosis usw. ausgleicht.
x = x * affine_weight + affine_bias
Die Struktur von PatchTST lässt sich wie folgt zusammenfassen:
Input Data -> RevIn -> Series Decomposition -> Trend Component -> PatchTST Backbone -> TSTiEncoder -> Flatten_Head -> Trend Forecaster -> Residual Component -> Add Trend and Residual -> Final Forecast
Wir gehen davon aus, dass unsere Daten von MT5 bereitgestellt werden. Wir haben auch besprochen, wie RevIn funktioniert.
PatchTST funktioniert folgendermaßen: Angenommen, Sie laden 80.000 Balken von EURUSD-Daten für den H1-Zeitrahmen. Das sind Daten aus rund 13 Jahren. Mit PatchTST segmentieren Sie die Daten in so genannte „Patches“. Als Analogie kann man sich Patches so vorstellen, wie Vision Transformers (ViTs) für Bilder funktionieren, aber angepasst für Zeitreihendaten. Beträgt die Länge des Feldes beispielsweise 16, so würde jedes Feld 16 aufeinander folgende Preise enthalten. Dies ist so, als würde man kleine Teile der Zeitreihe auf einmal betrachten, was dem Modell hilft, sich auf lokale Muster zu konzentrieren, bevor es das globale Muster betrachtet.
Als Nächstes enthalten die Flecken eine Positionskodierung, um die Reihenfolge beizubehalten, was dem Modell hilft, sich die Position jedes Flecks in der Sequenz zu merken.
Der Transformator leitet die normalisierten und kodierten Patches durch einen Stapel von Kodierschichten. Jede Encoderschicht enthält eine Mehrkopf-Aufmerksamkeitsschicht und eine Feedforward-Schicht. Die Multi-Head-Attention-Schicht ermöglicht es dem Modell, auf verschiedene Teile der Eingabesequenz zu achten, während die Feed-Forward-Schicht dem Modell erlaubt, komplexe nicht-lineare Transformationen der Daten zu lernen.
Schließlich gibt es noch die Komponenten Trend und Residuen. Für die Trendkomponente und die Residualkomponente werden dieselben Patching-, Normalisierungs-, Positionskodierungs- und Transformationsschichten verwendet. Anschließend addieren wir die Ergebnisse der Trend- und der Residualkomponente, um die endgültige Prognose zu erstellen.
PatchTST Offizielle Repository-Ausgaben
Das offizielle Repository für PatchTST finden Sie auf GitHub unter dem folgenden Link: PatchTST (ICLR 2023). Es gibt zwei verschiedene Versionen - überwacht und unüberwacht. In diesem Artikel werden wir den Ansatz des überwachten Lernens verwenden. Wie wir wissen, müssen wir jedes Modell in das ONNX-Format konvertieren, um es mit MQL5 verwenden zu können. Die Autoren von PatchTST haben dies jedoch nicht berücksichtigt. Ich musste die folgenden Änderungen an ihrem Basiscode vornehmen, damit das Modell mit MQL5 funktioniert:
Ursprünglicher Code:
class PatchTST_backbone(nn.Module): def __init__(self, c_in:int, context_window:int, target_window:int, patch_len:int, stride:int, max_seq_len:Optional[int]=1024, n_layers:int=3, d_model=128, n_heads=16, d_k:Optional[int]=None, d_v:Optional[int]=None, d_ff:int=256, norm:str='BatchNorm', attn_dropout:float=0., dropout:float=0., act:str="gelu", key_padding_mask:bool='auto', padding_var:Optional[int]=None, attn_mask:Optional[Tensor]=None, res_attention:bool=True, pre_norm:bool=False, store_attn:bool=False, pe:str='zeros', learn_pe:bool=True, fc_dropout:float=0., head_dropout = 0, padding_patch = None, pretrain_head:bool=False, head_type = 'flatten', individual = False, revin = True, affine = True, subtract_last = False, verbose:bool=False, **kwargs): super().__init__() # RevIn self.revin = revin if self.revin: self.revin_layer = RevIN(c_in, affine=affine, subtract_last=subtract_last) # Patching self.patch_len = patch_len self.stride = stride self.padding_patch = padding_patch patch_num = int((context_window - patch_len)/stride + 1) if padding_patch == 'end': # can be modified to general case self.padding_patch_layer = nn.ReplicationPad1d((0, stride)) patch_num += 1 # Backbone self.backbone = TSTiEncoder(c_in, patch_num=patch_num, patch_len=patch_len, max_seq_len=max_seq_len, n_layers=n_layers, d_model=d_model, n_heads=n_heads, d_k=d_k, d_v=d_v, d_ff=d_ff, attn_dropout=attn_dropout, dropout=dropout, act=act, key_padding_mask=key_padding_mask, padding_var=padding_var, attn_mask=attn_mask, res_attention=res_attention, pre_norm=pre_norm, store_attn=store_attn, pe=pe, learn_pe=learn_pe, verbose=verbose, **kwargs) # Head self.head_nf = d_model * patch_num self.n_vars = c_in self.pretrain_head = pretrain_head self.head_type = head_type self.individual = individual if self.pretrain_head: self.head = self.create_pretrain_head(self.head_nf, c_in, fc_dropout) # custom head passed as a partial func with all its kwargs elif head_type == 'flatten': self.head = Flatten_Head(self.individual, self.n_vars, self.head_nf, target_window, head_dropout=head_dropout) def forward(self, z): # z: [bs x nvars x seq_len] # norm if self.revin: z = z.permute(0,2,1) z = self.revin_layer(z, 'norm') z = z.permute(0,2,1) # do patching if self.padding_patch == 'end': z = self.padding_patch_layer(z) z = z.unfold(dimension=-1, size=self.patch_len, step=self.stride) # z: [bs x nvars x patch_num x patch_len] z = z.permute(0,1,3,2) # z: [bs x nvars x patch_len x patch_num] # model z = self.backbone(z) # z: [bs x nvars x d_model x patch_num] z = self.head(z) # z: [bs x nvars x target_window] # denorm if self.revin: z = z.permute(0,2,1) z = self.revin_layer(z, 'denorm') z = z.permute(0,2,1) return z
Der obige Code ist das wichtigste Grundgerüst. Wie Sie sehen können, verwendet der Code die Funktion „unfold“ in der Zeile:
z = z.unfold(dimension=-1, size=self.patch_len, step=self.stride) # z: [bs x nvars x patch_num x patch_len]
Die Konvertierung von unfold wird von ONNX nicht unterstützt. Sie erhalten eine Fehlermeldung wie:
Unsupported: ONNX export of operator Unfold, input size not accessible. Please feel free to request support or submit a pull request on PyTorch GitHub: https://github.com/pytorch/pytorch/issues
Also musste ich diesen Abschnitt des Codes ersetzen durch:
# Manually unfold the input tensor batch_size, n_vars, seq_len = z.size() patches = [] for i in range(0, seq_len - self.patch_len + 1, self.stride): patches.append(z[:, :, i:i+self.patch_len])
Beachten Sie, dass die obige Ersetzung etwas weniger effizient ist, da sie eine for-Schleife für das Training eines Neuronalen Netzes verwendet. Die Ineffizienzen können sich über viele Epochen und große Datensätze hinweg summieren. Das ist aber notwendig, weil das Modell sonst einfach nicht konvertiert wird und wir es nicht mit MQL5 verwenden können.
Ich bin speziell auf diese Frage eingegangen. Dieser Vorgang dauerte am längsten. Ich habe dann alles in einer Datei namens patchTST.py zusammengefasst, die sich in der an diesen Artikel angehängten Zip-Datei befindet. Dies ist die Datei, die wir für unser Modelltraining verwenden werden.
Voraussetzungen für die Arbeit mit PatchTST in Python
In diesem Abschnitt werde ich Ihnen die Voraussetzungen für die Arbeit mit PatchTST in Python erläutern. Diese Anforderungen lassen sich wie folgt zusammenfassen:
Erstellen wir eine virtuelle Umgebung:
python -m venv myenv
Wir aktivieren die virtuelle Umgebung (Windows)
.\myenv\Scripts\activate
Wir installieren die Datei requirements.txt, die in der an diesen Artikel angehängten Zip-Datei enthalten ist:
pip install -r requirements.txt
Die Anforderungen für die Durchführung dieses Projekts sind im Einzelnen:
MetaTrader5
pandas
numpy
torch
plotly
datetime Modell für die Entwicklung eines Ausbildungscodes - Schritt für Schritt
Für den folgenden Code können Sie mir mit einem Jupyter-Notizbuch folgen, das in der ZIP-Datei enthalten ist: PatchTST Schritt-für-Schritt.ipynb. Im Folgenden werden die einzelnen Schritte zusammengefasst:
-
Import der notwendigen Bibliotheken: Wir importieren die erforderlichen Bibliotheken, einschließlich MetaTrader 5, Pandas, Numpy, Torch und dem PatchTST-Modell.
# Step 1: Import necessary libraries import MetaTrader5 as mt5 import pandas as pd import numpy as np import torch from torch.utils.data import TensorDataset, DataLoader from patchTST import Model as PatchTST
-
Initialisieren und Abrufen von Daten aus MetaTrader 5: Die Funktion fetch_mt5_data initialisiert MT5, holt die Daten für das angegebene Symbol, den Zeitrahmen und die Anzahl der Bars und gibt dann einen Datenrahmen mit den Spalten Open, High, Low und Close zurück.
# Step 2: Initialize and fetch data from MetaTrader 5 def fetch_mt5_data(symbol, timeframe, bars): if not mt5.initialize(): print("MT5 initialization failed") return None timeframe_dict = { 'M1': mt5.TIMEFRAME_M1, 'M5': mt5.TIMEFRAME_M5, 'M15': mt5.TIMEFRAME_M15, 'H1': mt5.TIMEFRAME_H1, 'D1': mt5.TIMEFRAME_D1 } rates = mt5.copy_rates_from_pos(symbol, timeframe_dict[timeframe], 0, bars) mt5.shutdown() df = pd.DataFrame(rates) df['time'] = pd.to_datetime(df['time'], unit='s') df.set_index('time', inplace=True) return df[['open', 'high', 'low', 'close']] # Fetch data data = fetch_mt5_data('EURUSD', 'H1', 80000)
-
Vorhersagedaten mit Schiebefenster vorbereiten: Die Funktion prepare_forecasting_data erstellt den Datensatz mit Hilfe eines Schiebefenster-Ansatzes, der Sequenzen von historischen Daten (X) und den entsprechenden zukünftigen Daten (y) erzeugt.
# Step 3: Prepare forecasting data using sliding window def prepare_forecasting_data(data, seq_length, pred_length): X, y = [], [] for i in range(len(data) - seq_length - pred_length): X.append(data.iloc[i:(i + seq_length)].values) y.append(data.iloc[(i + seq_length):(i + seq_length + pred_length)].values) return np.array(X), np.array(y) seq_length = 168 # 1 week of hourly data pred_length = 24 # Predict next 24 hours X, y = prepare_forecasting_data(data, seq_length, pred_length)
-
Aufteilung der Daten in Trainings- und Testgruppen: Aufteilung der Daten in einen Trainings- und einen Testsatz, wobei 80 % für das Training und 20 % für den Test verwendet werden.
# Step 4: Split data into training and testing sets split = int(len(X) * 0.8) X_train, X_test = X[:split], X[split:] y_train, y_test = y[:split], y[split:]
-
Daten in PyTorch-Tensoren umwandeln: Konvertierung der NumPy-Arrays in PyTorch-Tensoren, die für das Training mit PyTorch benötigt werden. Wir setzen einen manuellen Seed für Torch, um die Reproduzierbarkeit der Ergebnisse zu gewährleisten.
# Step 5: Convert data to PyTorch tensors X_train = torch.tensor(X_train, dtype=torch.float32) y_train = torch.tensor(y_train, dtype=torch.float32) X_test = torch.tensor(X_test, dtype=torch.float32) y_test = torch.tensor(y_test, dtype=torch.float32) torch.manual_seed(42)
-
Gerät zur Berechnung einstellen: Einstellung des Geräts auf CUDA, falls verfügbar, ansonsten Verwendung der CPU. Dies ist wichtig, um die GPU-Beschleunigung während des Trainings zu nutzen, insbesondere wenn sie verfügbar ist.
# Step 6: Set device for computation device = torch.device("cuda" if torch.cuda.is_available() else "cpu") print(f"Using device: {device}")
-
Data Loader für Trainingsdaten erstellen: Erstellung eines Datenladers, der das Stapeln und Mischen der Trainingsdaten übernimmt.
# Step 7: Create DataLoader for training data train_dataset = TensorDataset(X_train, y_train) train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
-
Definition der Konfigurationsklasse für das Modell: Definition einer Konfigurationsklasse Config zur Speicherung aller für das PatchTST-Modell erforderlichen Hyperparameter und Einstellungen.
# Step 8: Define the configuration class for the model class Config: def __init__(self): self.enc_in = 4 # Adjusted for 4 columns (open, high, low, close) self.seq_len = seq_length self.pred_len = pred_length self.e_layers = 3 self.n_heads = 4 self.d_model = 64 self.d_ff = 256 self.dropout = 0.1 self.fc_dropout = 0.1 self.head_dropout = 0.1 self.individual = False self.patch_len = 24 self.stride = 24 self.padding_patch = True self.revin = True self.affine = False self.subtract_last = False self.decomposition = True self.kernel_size = 25 configs = Config()
-
Initialisieren Sie das PatchTST-Modell: Initialisierung des PatchTST-Modells mit der definierten Konfiguration und Übertragung auf das ausgewählte Gerät.
# Step 9: Initialize the PatchTST model model = PatchTST( configs=configs, max_seq_len=1024, d_k=None, d_v=None, norm='BatchNorm', attn_dropout=0.1, act="gelu", key_padding_mask='auto', padding_var=None, attn_mask=None, res_attention=True, pre_norm=False, store_attn=False, pe='zeros', learn_pe=True, pretrain_head=False, head_type='flatten', verbose=False ).to(device)
-
Definition des Optimierers und der Verlustfunktion: Einrichten des Optimierers (Adam) und der Verlustfunktion (mittlerer quadratischer Fehler) für das Training des Modells.
# Step 10: Define optimizer and loss function optimizer = torch.optim.Adam(model.parameters(), lr=0.001) loss_fn = torch.nn.MSELoss() num_epochs = 100
-
Training des Modells: Wir trainieren das Modell über die angegebene Anzahl von Epochen. Für jeden Datenstapel führt das Modell einen Vorwärtsdurchlauf durch, berechnet den Verlust, führt einen Rückwärtsdurchlauf durch, um die Gradienten zu berechnen, und aktualisiert die Modellparameter.
# Step 11: Train the model for epoch in range(num_epochs): model.train() total_loss = 0 for batch_X, batch_y in train_loader: optimizer.zero_grad() batch_X = batch_X.to(device) batch_y = batch_y.to(device) outputs = model(batch_X) outputs = outputs[:, -pred_length:, :4] loss = loss_fn(outputs, batch_y) loss.backward() optimizer.step() total_loss += loss.item() print(f"Epoch {epoch+1}/{num_epochs}, Loss: {total_loss/len(train_loader):.10f}")
-
Speichern des Modells im PyTorch-Format: Wir speichern das Zustandswörterbuch des trainierten Modells in einer Datei. Wir können diese Datei verwenden, um direkt in Python Vorhersagen zu treffen.
# Step 12: Save the model in PyTorch format torch.save(model.state_dict(), 'patchtst_model.pth')
-
Bereiten wir eine Dummy-Eingabe für den ONNX-Export vor: Erstellung eines Dummy-Eingabetensors, der für den Export des Modells in das ONNX-Format verwendet wird.
# Step 13: Prepare a dummy input for ONNX export dummy_input = torch.randn(1, seq_length, 4).to(device)
-
Exportieren des Modells in das ONNX-Format: Wir exportieren das trainierte Modells in das ONNX-Format. Wir benötigen diese Datei, um mit MQL5 Vorhersagen zu treffen.
# Step 14: Export the model to ONNX format torch.onnx.export(model, dummy_input, "patchtst_model.onnx", opset_version=13, input_names=['input'], output_names=['output'], dynamic_axes={'input': {0: 'batch_size'}, 'output': {0: 'batch_size'}}) print("Model trained and saved in PyTorch and ONNX formats.")
Ergebnisse des Modelltrainings
Hier sind die Ergebnisse, die ich beim Training des Modells erhalten habe.
Epoch 1/100, Loss: 0.0000283705 Epoch 2/100, Loss: 0.0000263274 Epoch 3/100, Loss: 0.0000256321 Epoch 4/100, Loss: 0.0000252389 Epoch 5/100, Loss: 0.0000249340 Epoch 6/100, Loss: 0.0000246715 Epoch 7/100, Loss: 0.0000244293 Epoch 8/100, Loss: 0.0000241942 Epoch 9/100, Loss: 0.0000240157 Epoch 10/100, Loss: 0.0000236776 Epoch 11/100, Loss: 0.0000233954 Epoch 12/100, Loss: 0.0000230437 Epoch 13/100, Loss: 0.0000226635 Epoch 14/100, Loss: 0.0000221875 Epoch 15/100, Loss: 0.0000216960 Epoch 16/100, Loss: 0.0000213242 Epoch 17/100, Loss: 0.0000208693 Epoch 18/100, Loss: 0.0000204956 Epoch 19/100, Loss: 0.0000200573 Epoch 20/100, Loss: 0.0000197222 Epoch 21/100, Loss: 0.0000193516 Epoch 22/100, Loss: 0.0000189223 Epoch 23/100, Loss: 0.0000186635 Epoch 24/100, Loss: 0.0000184025 Epoch 25/100, Loss: 0.0000180468 Epoch 26/100, Loss: 0.0000177854 Epoch 27/100, Loss: 0.0000174621 Epoch 28/100, Loss: 0.0000173247 Epoch 29/100, Loss: 0.0000170032 Epoch 30/100, Loss: 0.0000168594 Epoch 31/100, Loss: 0.0000166609 Epoch 32/100, Loss: 0.0000164818 Epoch 33/100, Loss: 0.0000162424 Epoch 34/100, Loss: 0.0000161265 Epoch 35/100, Loss: 0.0000159775 Epoch 36/100, Loss: 0.0000158510 Epoch 37/100, Loss: 0.0000156571 Epoch 38/100, Loss: 0.0000155327 Epoch 39/100, Loss: 0.0000154742 Epoch 40/100, Loss: 0.0000152778 Epoch 41/100, Loss: 0.0000151757 Epoch 42/100, Loss: 0.0000151083 Epoch 43/100, Loss: 0.0000150182 Epoch 44/100, Loss: 0.0000149140 Epoch 45/100, Loss: 0.0000148057 Epoch 46/100, Loss: 0.0000147672 Epoch 47/100, Loss: 0.0000146499 Epoch 48/100, Loss: 0.0000145281 Epoch 49/100, Loss: 0.0000145298 Epoch 50/100, Loss: 0.0000144795 Epoch 51/100, Loss: 0.0000143969 Epoch 52/100, Loss: 0.0000142840 Epoch 53/100, Loss: 0.0000142294 Epoch 54/100, Loss: 0.0000142159 Epoch 55/100, Loss: 0.0000140837 Epoch 56/100, Loss: 0.0000140005 Epoch 57/100, Loss: 0.0000139986 Epoch 58/100, Loss: 0.0000139122 Epoch 59/100, Loss: 0.0000139010 Epoch 60/100, Loss: 0.0000138351 Epoch 61/100, Loss: 0.0000138050 Epoch 62/100, Loss: 0.0000137636 Epoch 63/100, Loss: 0.0000136853 Epoch 64/100, Loss: 0.0000136191 Epoch 65/100, Loss: 0.0000136272 Epoch 66/100, Loss: 0.0000135552 Epoch 67/100, Loss: 0.0000135439 Epoch 68/100, Loss: 0.0000135200 Epoch 69/100, Loss: 0.0000134461 Epoch 70/100, Loss: 0.0000133950 Epoch 71/100, Loss: 0.0000133979 Epoch 72/100, Loss: 0.0000133059 Epoch 73/100, Loss: 0.0000133242 Epoch 74/100, Loss: 0.0000132816 Epoch 75/100, Loss: 0.0000132145 Epoch 76/100, Loss: 0.0000132803 Epoch 77/100, Loss: 0.0000131212 Epoch 78/100, Loss: 0.0000131809 Epoch 79/100, Loss: 0.0000131538 Epoch 80/100, Loss: 0.0000130786 Epoch 81/100, Loss: 0.0000130651 Epoch 82/100, Loss: 0.0000130255 Epoch 83/100, Loss: 0.0000129917 Epoch 84/100, Loss: 0.0000129804 Epoch 85/100, Loss: 0.0000130086 Epoch 86/100, Loss: 0.0000130156 Epoch 87/100, Loss: 0.0000129557 Epoch 88/100, Loss: 0.0000129013 Epoch 89/100, Loss: 0.0000129018 Epoch 90/100, Loss: 0.0000128864 Epoch 91/100, Loss: 0.0000128663 Epoch 92/100, Loss: 0.0000128411 Epoch 93/100, Loss: 0.0000128514 Epoch 94/100, Loss: 0.0000127915 Epoch 95/100, Loss: 0.0000127778 Epoch 96/100, Loss: 0.0000127787 Epoch 97/100, Loss: 0.0000127623 Epoch 98/100, Loss: 0.0000127452 Epoch 99/100, Loss: 0.0000127141 Epoch 100/100, Loss: 0.0000127229
Die Ergebnisse lassen sich wie folgt veranschaulichen:

Wir erhalten auch die folgende Ausgabe ohne Fehler und Warnungen, was bedeutet, dass unser Modell erfolgreich in das ONNX-Format konvertiert wurde.
Model trained and saved in PyTorch and ONNX formats.
Erstellung von Vorhersagen mit Python - Schritt für Schritt
Schauen wir uns nun den Vorhersagecode an:
- Schritt 1. Erforderliche Bibliotheken importieren: Wir beginnen damit, alle erforderlichen Bibliotheken zu importieren.
# Import required libraries import MetaTrader5 as mt5 import pandas as pd import numpy as np import torch from datetime import datetime, timedelta import plotly.graph_objects as go from plotly.subplots import make_subplots from patchTST import Model as PatchTST
- Schritt 2. Daten aus Metatrader 5 holen: Wir definieren eine Funktion, um Daten aus MetaTrader 5 zu holen und sie in einen DataFrame zu konvertieren. Wir holen 168 frühere Balken ab, weil dies die Voraussetzung für eine Vorhersage mit unserem Modell ist.
# Function to fetch data from MetaTrader 5 def fetch_mt5_data(symbol, timeframe, bars): if not mt5.initialize(): print("MT5 initialization failed") return None timeframe_dict = { 'M1': mt5.TIMEFRAME_M1, 'M5': mt5.TIMEFRAME_M5, 'M15': mt5.TIMEFRAME_M15, 'H1': mt5.TIMEFRAME_H1, 'D1': mt5.TIMEFRAME_D1 } rates = mt5.copy_rates_from_pos(symbol, timeframe_dict[timeframe], 0, bars) mt5.shutdown() df = pd.DataFrame(rates) df['time'] = pd.to_datetime(df['time'], unit='s') df.set_index('time', inplace=True) return df[['open', 'high', 'low', 'close']] # Fetch the latest week of data historical_data = fetch_mt5_data('EURUSD', 'H1', 168)
- Schritt 3. Vorbereitung der Eingabedaten: Wir definieren eine Funktion zur Vorbereitung der Eingabedaten für das Modell, indem wir die letzten seq_length-Datenzeilen nehmen. Beim Abrufen der Daten benötigen wir nur die letzten 168 Stunden der 1-Stunden-Daten, um Prognosen für die nächsten 24 Stunden zu erstellen. Das liegt daran, dass wir das Modell auf diese Weise trainiert haben.
# Function to prepare input data def prepare_input_data(data, seq_length): X = [] X.append(data.iloc[-seq_length:].values) return np.array(X) # Prepare the input data seq_length = 168 # 1 week of hourly data input_data = prepare_input_data(historical_data, seq_length)
- Schritt 4. Definition der Konfiguration: Wir definieren eine Konfigurationsklasse, um die Parameter für das Modell festzulegen. Diese Einstellungen sind die gleichen, die wir für das Training des Modells verwenden.
# Define the configuration class class Config: def __init__(self): self.enc_in = 4 # Adjusted for 4 columns (open, high, low, close) self.seq_len = seq_length self.pred_len = 24 # Predict next 24 hours self.e_layers = 3 self.n_heads = 4 self.d_model = 64 self.d_ff = 256 self.dropout = 0.1 self.fc_dropout = 0.1 self.head_dropout = 0.1 self.individual = False self.patch_len = 24 self.stride = 24 self.padding_patch = True self.revin = True self.affine = False self.subtract_last = False self.decomposition = True self.kernel_size = 25 # Initialize the configuration config = Config()
- Schritt 5. Laden des trainierten Modells: Wir definieren eine Funktion zum Laden des trainierten PatchTST-Modells. Dies sind die gleichen Einstellungen, die wir für das Training des Modells verwendet haben.
# Function to load the trained model def load_model(model_path, config): model = PatchTST( configs=config, max_seq_len=1024, d_k=None, d_v=None, norm='BatchNorm', attn_dropout=0.1, act="gelu", key_padding_mask='auto', padding_var=None, attn_mask=None, res_attention=True, pre_norm=False, store_attn=False, pe='zeros', learn_pe=True, pretrain_head=False, head_type='flatten', verbose=False ) model.load_state_dict(torch.load(model_path)) model.eval() return model # Load the trained model model_path = 'patchtst_model.pth' device = torch.device("cuda" if torch.cuda.is_available() else "cpu") model = load_model(model_path, config).to(device)
- Schritt 6. Vorhersagen treffen: Wir definieren eine Funktion, die mit dem geladenen Modell und den Eingabedaten Vorhersagen macht.
# Function to make predictions def predict(model, input_data, device): with torch.no_grad(): input_data = torch.tensor(input_data, dtype=torch.float32).to(device) output = model(input_data) return output.cpu().numpy() # Make predictions predictions = predict(model, input_data, device)
- Schritt 7. Post-Processing und Visualisierung: Wir verarbeiten die Vorhersagen, erstellen einen Datenrahmen und visualisieren die historischen und vorhergesagten Daten mit Plotly.
# Ensure predictions have the correct shape if predictions.shape[2] != 4: predictions = predictions[:, :, :4] # Adjust based on actual number of columns required # Check the shape of predictions print("Shape of predictions:", predictions.shape) # Create a DataFrame for predictions pred_index = pd.date_range(start=historical_data.index[-1] + pd.Timedelta(hours=1), periods=24, freq='H') pred_df = pd.DataFrame(predictions[0], columns=['open', 'high', 'low', 'close'], index=pred_index) # Combine historical data and predictions combined_df = pd.concat([historical_data, pred_df]) # Create the plot fig = make_subplots(rows=1, cols=1, shared_xaxes=True, vertical_spacing=0.03, subplot_titles=('EURUSD OHLC')) # Add historical candlestick fig.add_trace(go.Candlestick(x=historical_data.index, open=historical_data['open'], high=historical_data['high'], low=historical_data['low'], close=historical_data['close'], name='Historical')) # Add predicted candlestick fig.add_trace(go.Candlestick(x=pred_df.index, open=pred_df['open'], high=pred_df['high'], low=pred_df['low'], close=pred_df['close'], name='Predicted')) # Add a vertical line to separate historical data from predictions fig.add_vline(x=historical_data.index[-1], line_dash="dash", line_color="gray") # Update layout fig.update_layout(title='EURUSD OHLC Chart with Predictions', yaxis_title='Price', xaxis_rangeslider_visible=False) # Show the plot fig.show() # Print predictions (optional) print("Predicted prices for the next 24 hours:", predictions)
Code für Training und Vorhersage in Python
Wenn Sie nicht daran interessiert sind, die Codebasis in einem Jupyter-Notebook auszuführen, habe ich in den Anhängen einige Dateien bereitgestellt, die Sie direkt ausführen können:
- model_training.py
- model_prediction.py
Sie können das Modell nach Belieben konfigurieren und es ohne Jupyter ausführen.
Ergebnisse der Vorhersage
Nachdem ich das Modell trainiert und den Vorhersagecode in Python ausgeführt hatte, erhielt ich das folgende Diagramm. Die Vorhersagen wurden am 8.7.2024 gegen 12:30 Uhr (MESZ + 3) Zeit erstellt. Dies ist direkt der Eröffnungskurs am Sonntagnacht/Montagmorgen. Wir können eine Lücke im Chart sehen, da EURUSD mit einer Lücke eröffnet hat. Das Modell sagt voraus, dass EURUSD einen Aufwärtstrend erleben sollte, der diese Lücke größtenteils füllen könnte. Nachdem die Kurslücke geschlossen wurde, dürfte die Kursbewegung gegen Ende des Tages nach unten drehen.

Wir haben auch den Rohwert der Ergebnisse ausgedruckt, der unten zu sehen ist:
Predicted prices for the next 24 hours: [[[1.0789319 1.08056 1.0789403 1.0800443] [1.0791171 1.080738 1.0791024 1.0802013] [1.0792702 1.0807946 1.0792127 1.0802455] [1.0794896 1.0809869 1.07939 1.0804181] [1.0795166 1.0809793 1.0793561 1.0803629] [1.0796498 1.0810834 1.079427 1.0804263] [1.0798903 1.0813211 1.0795883 1.0805805] [1.0800778 1.081464 1.0796818 1.0806502] [1.0801392 1.0815498 1.0796598 1.0806476] [1.0802988 1.0817037 1.0797216 1.0807337] [1.080521 1.0819166 1.079835 1.08086 ] [1.0804708 1.0818571 1.079683 1.0807351] [1.0805807 1.0819991 1.079669 1.0807738] [1.0806456 1.0820425 1.0796478 1.0807805] [1.080733 1.0821087 1.0796758 1.0808226] [1.0807986 1.0822101 1.0796862 1.08086 ] [1.0808219 1.0821983 1.0796905 1.0808747] [1.0808604 1.082247 1.0797052 1.0808727] [1.0808146 1.082188 1.0796149 1.0807893] [1.0809066 1.0822624 1.0796828 1.0808471] [1.0809724 1.0822903 1.0797662 1.0808889] [1.0810378 1.0823163 1.0797914 1.0809084] [1.0810691 1.0823379 1.0798224 1.0809308] [1.0810966 1.0822875 1.0797993 1.0808865]]]
Das vortrainierte Modell zu MQL5 bringen
In diesem Abschnitt werden wir einen Vorläufer für einen Indikator erstellen, der uns helfen wird, die vorhergesagte Preisaktion auf unseren Charts zu visualisieren. Ich habe das Skript absichtlich rudimentär und mit offenem Ende gestaltet, weil unsere Leserinnen und Leser unterschiedliche Ziele und Strategien für die Nutzung dieser komplexen neuronalen Netze haben können. Der Indikator ist im MQL5 Expert Advisor Format entwickelt. Hier ist das vollständige Skript:
//+------------------------------------------------------------------+ //| PatchTST Predictor | //| Copyright 2024 | //+------------------------------------------------------------------+ #property copyright "Copyright 2024" #property link "https://www.mql5.com" #property version "1.00" #resource "\\PatchTST\\patchtst_model.onnx" as uchar PatchTSTModel[] #define SEQ_LENGTH 168 #define PRED_LENGTH 24 #define INPUT_FEATURES 4 long ModelHandle = INVALID_HANDLE; datetime ExtNextBar = 0; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Load the ONNX model ModelHandle = OnnxCreateFromBuffer(PatchTSTModel, ONNX_DEFAULT); if (ModelHandle == INVALID_HANDLE) { Print("Error creating ONNX model: ", GetLastError()); return(INIT_FAILED); } // Set input shape const long input_shape[] = {1, SEQ_LENGTH, INPUT_FEATURES}; if (!OnnxSetInputShape(ModelHandle, ONNX_DEFAULT, input_shape)) { Print("Error setting input shape: ", GetLastError()); return(INIT_FAILED); } // Set output shape const long output_shape[] = {1, PRED_LENGTH, INPUT_FEATURES}; if (!OnnxSetOutputShape(ModelHandle, 0, output_shape)) { Print("Error setting output shape: ", GetLastError()); return(INIT_FAILED); } return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { if (ModelHandle != INVALID_HANDLE) { OnnxRelease(ModelHandle); ModelHandle = INVALID_HANDLE; } } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { if (TimeCurrent() < ExtNextBar) return; ExtNextBar = TimeCurrent(); ExtNextBar -= ExtNextBar % PeriodSeconds(); ExtNextBar += PeriodSeconds(); // Prepare input data float input_data[]; if (!PrepareInputData(input_data)) { Print("Error preparing input data"); return; } // Make prediction float predictions[]; if (!MakePrediction(input_data, predictions)) { Print("Error making prediction"); return; } // Draw hypothetical future bars DrawFutureBars(predictions); } //+------------------------------------------------------------------+ //| Prepare input data for the model | //+------------------------------------------------------------------+ bool PrepareInputData(float &input_data[]) { MqlRates rates[]; ArraySetAsSeries(rates, true); int copied = CopyRates(_Symbol, PERIOD_H1, 0, SEQ_LENGTH, rates); if (copied != SEQ_LENGTH) { Print("Failed to copy rates data. Copied: ", copied); return false; } ArrayResize(input_data, SEQ_LENGTH * INPUT_FEATURES); for (int i = 0; i < SEQ_LENGTH; i++) { input_data[i * INPUT_FEATURES + 0] = (float)rates[SEQ_LENGTH - 1 - i].open; input_data[i * INPUT_FEATURES + 1] = (float)rates[SEQ_LENGTH - 1 - i].high; input_data[i * INPUT_FEATURES + 2] = (float)rates[SEQ_LENGTH - 1 - i].low; input_data[i * INPUT_FEATURES + 3] = (float)rates[SEQ_LENGTH - 1 - i].close; } return true; } //+------------------------------------------------------------------+ //| Make prediction using the ONNX model | //+------------------------------------------------------------------+ bool MakePrediction(const float &input_data[], float &output_data[]) { ArrayResize(output_data, PRED_LENGTH * INPUT_FEATURES); if (!OnnxRun(ModelHandle, ONNX_NO_CONVERSION, input_data, output_data)) { Print("Error running ONNX model: ", GetLastError()); return false; } return true; } //+------------------------------------------------------------------+ //| Draw hypothetical future bars | //+------------------------------------------------------------------+ void DrawFutureBars(const float &predictions[]) { datetime current_time = TimeCurrent(); for (int i = 0; i < PRED_LENGTH; i++) { datetime bar_time = current_time + PeriodSeconds(PERIOD_H1) * (i + 1); double open = predictions[i * INPUT_FEATURES + 0]; double high = predictions[i * INPUT_FEATURES + 1]; double low = predictions[i * INPUT_FEATURES + 2]; double close = predictions[i * INPUT_FEATURES + 3]; string obj_name = "FutureBar_" + IntegerToString(i); ObjectCreate(0, obj_name, OBJ_RECTANGLE, 0, bar_time, low, bar_time + PeriodSeconds(PERIOD_H1), high); ObjectSetInteger(0, obj_name, OBJPROP_COLOR, close > open ? clrGreen : clrRed); ObjectSetInteger(0, obj_name, OBJPROP_FILL, true); ObjectSetInteger(0, obj_name, OBJPROP_BACK, true); } ChartRedraw(); }
Um das obige Skript auszuführen, beachten Sie bitte, wie die folgende Zeile definiert ist:
#resource "\\PatchTST\\patchtst_model.onnx" as uchar PatchTSTModel[]
Das bedeutet, dass wir innerhalb des Expert Advisor-Ordners einen Unterordner mit dem Titel PatchTST erstellen müssen. Im Unterordner PatchTST müssen wir die ONNX-Datei vom Modelltraining speichern. Der Haupt-EA wird jedoch im Stammordner selbst gespeichert.
Die Parameter, die wir zum Trainieren unseres Modells verwendet haben, werden ebenfalls am Anfang des Skripts definiert:
#define SEQ_LENGTH 168 #define PRED_LENGTH 24 #define INPUT_FEATURES 4
In unserem Fall wollen wir 168 frühere Bars verwenden, sie in das ONNX-Modell einspeisen und eine Vorhersage für die nächsten 24 Bars in der Zukunft erhalten. Es gibt 4 Eingabemerkmale: open, high, low, und close.
Bitte beachten Sie auch den folgenden Code innerhalb der Funktion OnTick():
if (TimeCurrent() < ExtNextBar) return; ExtNextBar = TimeCurrent(); ExtNextBar -= ExtNextBar % PeriodSeconds(); ExtNextBar += PeriodSeconds();
Da ONNX-Modelle sehr rechenintensiv sind, sorgt dieser Code dafür, dass nur einmal pro Balken eine neue Vorhersage erstellt wird. In unserem Fall, da wir mit stündlichen Balken arbeiten, werden die Prognosen einmal pro Stunde aktualisiert.
Schließlich werden wir in diesem Code die zukünftigen Balken auf dem Bildschirm zeichnen, indem wir die Zeichenfunktionen von MQL5 verwenden:
void DrawFutureBars(const float &predictions[]) { datetime current_time = TimeCurrent(); for (int i = 0; i < PRED_LENGTH; i++) { datetime bar_time = current_time + PeriodSeconds(PERIOD_H1) * (i + 1); double open = predictions[i * INPUT_FEATURES + 0]; double high = predictions[i * INPUT_FEATURES + 1]; double low = predictions[i * INPUT_FEATURES + 2]; double close = predictions[i * INPUT_FEATURES + 3]; string obj_name = "FutureBar_" + IntegerToString(i); ObjectCreate(0, obj_name, OBJ_RECTANGLE, 0, bar_time, low, bar_time + PeriodSeconds(PERIOD_H1), high); ObjectSetInteger(0, obj_name, OBJPROP_COLOR, close > open ? clrGreen : clrRed); ObjectSetInteger(0, obj_name, OBJPROP_FILL, true); ObjectSetInteger(0, obj_name, OBJPROP_BACK, true); } ChartRedraw(); }
Nach der Implementierung dieses Codes in MQL5, der Kompilierung des Modells und der Platzierung des resultierenden EA auf dem H1-Zeitrahmen, sollten Sie einige zusätzliche Balken in der Zukunft auf Ihrem Chart sehen. In meinem Fall sieht das folgendermaßen aus:
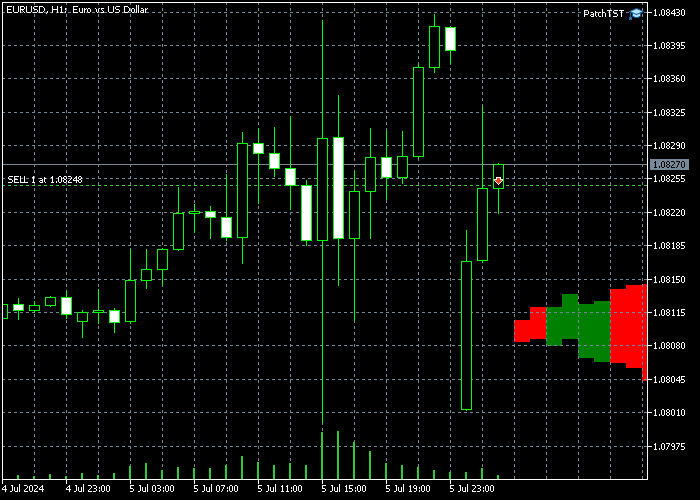
Bitte beachten Sie: Wenn Sie die neu gezeichneten Balken nicht rechts sehen, müssen Sie eventuell auf die Schaltfläche „Ende des Charts vom rechten Rand verschieben“ klicken. ![]()
Schlussfolgerung
In diesem Artikel haben wir das im Jahr 2023 eingeführte PatchTST-Modell Schritt für Schritt trainiert. Wir haben einen allgemeinen Eindruck davon bekommen, wie der PatchTST-Algorithmus funktioniert. Der Basiscode hatte einige Probleme, die mit der ONNX-Konvertierung zusammenhingen. Insbesondere wird der Operator „unfold“ nicht unterstützt. Wir haben dieses Problem behoben, um den Code ONNX-freundlicher zu machen. Wir haben auch den Zweck des Artikels händlerfreundlich gehalten, indem wir uns auf die Grundlagen des Modells, die Datenerfassung, das Training des Modells und die Vorhersage für die nächsten 24 Stunden konzentriert haben. Dann haben wir die Vorhersage in MQL5 implementiert, sodass wir das vollständig trainierte Modell mit unseren bevorzugten Indikatoren und Expertenberatern verwenden können. Ich freue mich, meinen gesamten Code mit der MQL-Gemeinschaft in der beigefügten Zip-Datei zu teilen. Bitte lassen Sie mich wissen, wenn Sie Fragen oder Anmerkungen haben.
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/15198
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.
 Erstellen einer interaktiven grafischen Nutzeroberfläche in MQL5 (Teil 1): Erstellen des Panels
Erstellen einer interaktiven grafischen Nutzeroberfläche in MQL5 (Teil 1): Erstellen des Panels
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Ich stelle oft fest, dass die vorhergesagten Ergebnisse dieses Modells nicht ganz mit der tatsächlichen Situation übereinstimmen. Ich habe keine Änderungen am Code dieses Modells vorgenommen. Könnten Sie mir bitte einen Rat geben? Ich danke Ihnen.
Vielen Dank, dass Sie uns Ihre Erfahrungen mit dem Modell mitteilen. Sie sprechen einen wichtigen Punkt bezüglich der Konsistenz der Vorhersagen an. Das PatchTST-Modell funktioniert am besten, wenn es in einen umfassenden Handelsansatz integriert ist, der mehrere Marktfaktoren berücksichtigt. Ich empfehle Ihnen, die Vorhersagen des Modells effektiver zu nutzen:
Einige zusätzliche persönliche Beobachtungen:
Die Vorhersagen des Modells sollten als eine Komponente Ihrer Analyse verwendet werden und nicht als alleinige Entscheidungsgrundlage. Durch die Einbeziehung dieser Elemente können Sie die Konsistenz Ihrer Handelsergebnisse bei der Verwendung des PatchTST-Modells potenziell verbessern.
Ich hoffe, dies hilft Ihnen.
Fair Value Gap (FVG) Script, das ich erwähnt habe (diese Gaps funktionieren meiner Erfahrung nach ähnlich wie Angebots- und Nachfragezonen):
Vielen Dank für Ihr Interesse! Ja, diese Änderungen an den Parametern würden im Prinzip funktionieren, aber es gibt ein paar wichtige Überlegungen beim Wechsel zu M1-Daten:
1. Datenmenge: Das Training mit 10080 Minuten (1 Woche) M1-Daten bedeutet, dass wesentlich mehr Datenpunkte verarbeitet werden als bei H1. Dies wird:
2. Anpassungen der Modellarchitektur: In Schritt 8 des Modelltrainings und Schritt 4 des Vorhersagecodes sollten Sie möglicherweise andere Parameter anpassen, um die größere Eingabesequenz zu berücksichtigen:
3. Vorhersagequalität: Sie erhalten zwar detailliertere Vorhersagen, sollten sich aber bewusst sein, dass M1-Daten in der Regel mehr Rauschen enthalten. Sie sollten mit verschiedenen Sequenzlängen und Vorhersagefenstern experimentieren, um die optimale Balance zu finden.Vielen Dank für den Einblick. Mein Computer ist mit 256 GB und 64 physischen Kernen einigermaßen leistungsfähig. Er könnte allerdings einen besseren Grafikprozessor gebrauchen.
Sobald ich die GPU aktualisiert habe, werde ich die aktualisierten Konfigurationseinstellungen ausprobieren.
Vielen Dank, dass Sie uns Ihre Erfahrungen mit dem Modell mitteilen. Sie sprechen einen wichtigen Punkt bezüglich der Konsistenz der Vorhersagen an. Das PatchTST-Modell funktioniert am besten, wenn es in einen umfassenden Handelsansatz integriert ist, der mehrere Marktfaktoren berücksichtigt. Ich empfehle Ihnen, die Vorhersagen des Modells effektiver zu nutzen:
Einige zusätzliche persönliche Beobachtungen:
Die Vorhersagen des Modells sollten als eine Komponente Ihrer Analyse verwendet werden und nicht als alleinige Entscheidungsgrundlage. Durch die Einbeziehung dieser Elemente können Sie die Konsistenz Ihrer Handelsergebnisse bei der Verwendung des PatchTST-Modells potenziell verbessern.
Ich hoffe, dies hilft Ihnen.
Fair Value Gap (FVG) Script, das ich erwähnt habe (diese Gaps funktionieren meiner Erfahrung nach ähnlich wie Angebots- und Nachfragezonen):
Vielen Dank für Ihre geduldige Antwort und Ihren selbstlosen Austausch. Ich habe noch nie so detaillierte und professionelle Antworten gesehen. Ich werde Ihren Artikel wiederholt lesen. Dieses Wissen ist für mich besonders wertvoll. Herzliche Grüße an Sie.
Ich danke Ihnen. Ihre freundlichen Worte bedeuten mir sehr viel!! Bitte melden Sie sich, wenn Sie weitere Unterstützung benötigen!