
Neuronale Netze leicht gemacht (Teil 65): Abstandsgewichtetes überwachtes Lernen (DWSL)

Einführung
Methoden zum Klonen von Verhalten, die weitgehend auf den Prinzipien des überwachten Lernens beruhen, zeigen recht gute Ergebnisse. Ihr Hauptproblem bleibt jedoch die Suche nach idealen Vorbildern, die manchmal sehr schwer zu finden sind. Die Methoden des Verstärkungslernens wiederum sind in der Lage, mit nicht-optimalen Rohdaten zu arbeiten. Gleichzeitig können sie aber auch suboptimale Strategien finden, um das Ziel zu erreichen. Bei der Suche nach einer optimalen Strategie stoßen wir jedoch häufig auf ein Optimierungsproblem, das in hochdimensionalen und stochastischen Umgebungen von größerer Bedeutung ist.
Um die Lücke zwischen diesen beiden Ansätzen zu schließen, schlug eine Gruppe von Wissenschaftlern die Methode des Abstandsgewichtetes überwachtes Lernen (Distance Weighted Supervised Learning, DWSL) vor und beschrieb sie in dem Artikel „Distance Weighted Supervised Learning for Offline Interaction Data“. Es handelt sich dabei um einen Algorithmus für offline-überwachtes Lernen für eine zielgerichtete Politik. Theoretisch konvergiert DWSL zu einer optimalen Strategie mit einer minimalen Rückkehrgrenze auf der Ebene der Trajektorien aus dem Trainingssatz. Die praktischen Beispiele in dem Artikel zeigen die Überlegenheit der vorgeschlagenen Methode gegenüber dem Imitationslernen und den Algorithmen des Verstärkungslernens. Ich schlage vor, dass Sie sich diesen DWSL-Algorithmus genauer ansehen. Wir werden ihre Stärken und Schwächen bei der Lösung unserer praktischen Probleme bewerten.
1. Der DWSL-Algorithmus
Die Autoren der Methode des abstandsgewichteten überwachten Lernens haben sich zum Ziel gesetzt, einen Algorithmus zu entwickeln, der in der Lage ist, die größtmögliche Menge an Daten für das Training zu verwenden. In diesem Paradigma gehen sie davon aus, dass der Agent in einem deterministischen Markov-Entscheidungsprozess handelt:
- Zustandsraum S;
- Aktionsraum A;
- deterministische Dynamik St+1 = F(St,At), wobei St+1 der neue Zustand ist, der sich aus der Durchführung der Aktion At im Zustand St ergibt;
- Zielraum G;
- spärlich besetzte zielbedingte Belohnungsfunktion R(S,A,G);
- Abwertungsfaktor γ.
Der Zielraum G ist ein Unterraum des Zustandsraums S mit einer Zielextraktionsfunktion G = φ(St), die oft identisch ist mit φ(St) = St+n. Das Ziel des Algorithmus ist es, eine zielorientierte Strategie π(A|S,G) zu erlernen, die die untersuchte Umgebung beherrscht und in der Lage ist, das gesetzte Ziel zu erreichen und dort zu bleiben. Um das gewünschte Ergebnis zu erzielen, maximieren wir den abgewerteten Ertrag aus der Belohnungsfunktion R(S,A,G) unter der Voraussetzung, dass das Ziel G aus der Zielverteilung p(G) erreicht wird.
Diese Problemstellung unterscheidet sich zwar von den zuvor besprochenen, weist aber starke Verbindungen zu zwei allgemeinen Problemstellungen auf: dem Stochastic Shortest Path Problem und GCRL.
Die Autoren der Methode weisen darauf hin, dass Arbeiten auf dem Gebiet der GCRL das Vorhandensein von Trajektorien mit markierten Unterzielen voraussetzen. Diese Teilziele werden durch die Absichtserklärung spezifiziert, die dem Modell Informationen über die Verteilung der Ziele p(G) während des Tests liefert. Dies schränkt die Daten ein, aus denen der Offline-GCRL lernen kann. Der Grund dafür ist, dass viele Offline-Datenquellen keine Zielkennzeichnungen (Unterziele) zusammen mit den einzelnen Trajektorien enthalten. Außerdem kann es schwierig sein, Ziele zu erreichen.
Um aus einer möglichst großen Menge von Offline-Daten zu lernen, betrachten die Autoren der Methode eine allgemeinere Situation. Die Situation beinhaltet keinen Zugang zu echten Umweltdynamiken, Belohnungskennzeichnungen oder der Zielverteilung zur Testzeit. In der Trainingsphase wird nur ein Satz von Trajektorien aus Zuständen und Aktionen eines beliebigen Optimalitätsniveaus verwendet. Die Verteilung p(G) ist die Verteilung der Ziele, die sich aus der Anwendung der Zielextraktionsfunktion φ(St) auf alle Zustände des Datensatzes ergibt. Es wird davon ausgegangen, dass bei den meisten praktischen Datensätzen die Ziele im Zusammenhang mit der Datenverteilung wahrscheinlich nahe an den Zielen für die Aufgaben von Interesse sind. Die DWSL-Methode kann eine beliebige spärliche Belohnungsfunktion verwenden, die rein aus vorhandenen Zustands-Aktions-Sequenzen berechnet werden kann. In der Praxis erwies sich die empirische Schätzung der Autoren jedoch ebenfalls als recht gut.
Intuitiv ist die beste Strategie zur Erreichung des Ziels G unter Verwendung der angegebenen Belohnungsfunktion die Verwendung des Pfads mit der geringsten Anzahl von Zeitschritten (kürzester Pfad), um das Ziel G vom aktuellen Zustand S aus zu erreichen. Allerdings folgen die Trajektorien im Trainingsdatensatz nicht unbedingt den kürzesten Wegen. Infolgedessen können Techniken zum Klonen von Verhalten ein suboptimales Verhalten aufweisen.
Um dieses Problem zu lösen, schätzt DWSL Abstände mit Hilfe von überwachtem Lernen, wobei die trainierten Modelle innerhalb der Verteilung des Trainingsdatensatzes bewertet werden. Das Modell lernt die gesamte Verteilung der paarweisen Abstände zwischen den Zuständen im Trainingsdatensatz. Anhand dieser Verteilung wird dann der Mindestabstand zum Ziel geschätzt, der in den Datensätzen der einzelnen Staaten enthalten ist. Danach lernt es, diese Wege zu beschreiten. Unten sehen Sie die Visualisierung der DWSL-Methode, die von den Autoren präsentiert wurde.

Zwischen zwei beliebigen Zuständen Si und Sj auf derselben Trajektorie gibt es für i < j mindestens einen Weg mit „j - i“ Zeitschritten. Mit dieser Eigenschaft erzeugen wir einen markierten Datensatz, der alle paarweisen Abstände zwischen Zuständen und Zielen im Trainingsdatensatz enthält. Für jedes Zustand-Ziel-Paar, das aus der neuen Verteilung entnommen wird, modellieren wir eine diskrete Verteilung über die Anzahl der Zeitschritte k vom aktuellen Zustand zum Ziel, wie in Abbildung 1 links dargestellt. Dies ermöglicht es uns, eine parametrisierte Schätzung dieser Verteilung mittels maximaler Wahrscheinlichkeit unter dem markierten Datensatz zu erhalten:
![]()
In der Praxis wird die Verteilung als diskreter Klassifikator über mögliche Abstände modelliert. Der kürzeste Weg zwischen dem Quell- und dem Zielzustand, der im markierten Datensatz enthalten ist, wird durch die minimale Anzahl von Zeitschritten k bestimmt. Da die Verteilung jedoch mit Hilfe einer Funktionsannäherung gelernt wird, werden bei der Schätzung des Mindestabstands auf diese Weise wahrscheinlich Modellierungsfehler ausgenutzt. Um diesen Fehler zu minimieren, schlagen die Autoren der Methode vor, LogSumExp über die Verteilung zu berechnen, um eine weiche Schätzung des Mindestabstands zu erhalten:
![]()
Beachten Sie, dass in der dargestellten Formel der Abstand mit „-1“ multipliziert wird, um die minimale Schätzung anstelle der maximalen zu erhalten. Dabei ist α der Temperatur-Hyperparameter. Wenn α gegen „0“ tendiert, nähert sich der Wert der Funktion d(s, g) dem Mindestabstand k.
Nach dem Erlernen von Mindestabstandsschätzungen wollen wir den bekannten Pfaden folgen, die von jedem Zustand ausgehen. Angenommen, der Agent befindet sich im Zustand S und muss das Ziel G erreichen. Im Ausgangszustand kann der Agent eine von zwei Aktionen durchführen (A1 oder A2), die zu den Zuständen S1 und S2 führen. Wir bevorzugen die erste Aktion, wenn sie den Beginn eines Weges zum Ziel mit einer minimalen Anzahl von Schritten darstellt (kleinerer geschätzte Abstand zum Ziel). Daher wollen wir die Wahrscheinlichkeit verschiedener Aktionen anhand ihres geschätzten Abstands zum Ziel (rechts in der Abbildung oben) gewichten. Eine naive Gewichtung der Aktionen auf diese Weise würde jedoch dazu führen, dass alle Datenpunkte, die sich in der Nähe des Ziels befinden, stärker gewichtet werden, da jeder Zustand, der weit vom Ziel entfernt ist, natürlich einen größeren Abstand aufweist. Stattdessen gewichten wir die Wahrscheinlichkeit von Aktionen entsprechend ihrer Verringerung des geschätzten Abstands zum Ziel, was die Autoren der Methode als Vorteil bezeichnen. Dies ermöglicht es uns, ein neues Ziel für das Training des Modells zu formulieren:
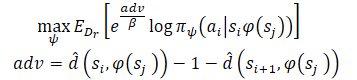
Die Autoren der Methode verwenden exponentielle Vorteile, um sicherzustellen, dass alle Gewichte positiv sind.
2. Implementierung mit MQL5
Nachdem wir uns mit den theoretischen Aspekten der Methode des Abstandsgewichteten überwachten Lernens vertraut gemacht haben, können wir zum praktischen Teil unseres Artikels übergehen, in dem wir eine Version der Methode in MQL5 implementieren werden. Wie immer werden wir versuchen, den vorgeschlagenen Algorithmus mit dem Wissen zu kombinieren, das wir bereits gesammelt haben. Wir werden auch versuchen, unsere Wahrnehmung der vorgeschlagenen Ansätze zu reproduzieren. Ich stimme zu, dass dieser Ansatz in gewissem Maße vom Algorithmus der Autoren abweicht und ihn nicht exakt wiedergibt. Folglich beziehen sich alle Schwachstellen, die bei den Tests festgestellt werden können, nur auf diese Implementierung.
Um es gleich vorweg zu sagen: Die Arbeit des Autors stellt Experimente zur Steuerung von Robotermanipulatoren vor. Unter solchen Bedingungen spielt die Zielsetzung eine entscheidende Rolle, um ein positives Ergebnis zu erzielen. Außerdem ist das Ziel in jedem einzelnen Fall klar. In meiner Implementierung konzentriere ich mich auf die Maximierung der Rentabilität des Roboters während der Trainingszeit. Um das Modell zu vereinfachen, habe ich beschlossen, nicht bei jedem Schritt ein Teilziel zu setzen. Das wiederum erlaubt es uns, kein Zielsetzungsmodell zu trainieren.
Hier werden wir das Modell mit Hilfe von Actor-Critic-Ansätzen trainieren. Für den Geber werden wir das Modell des Stochastic Marginal Actor-Critic (SMAC) verwenden. Wir werden sie durch andere Entwicklungen ergänzen. Insbesondere werden wir einen Mechanismus zum Abwägen von Trajektorien aus CWBC hinzufügen. Aber das Wichtigste zuerst. Wir beginnen unsere Arbeit mit einer Beschreibung der Architektur der Modelle.
2.1. Modell der Architektur
Wie immer wird die Architektur der trainierten Modelle in der Methode CreateDescriptions dargestellt. Als Parameter werden wir der Methode Zeiger auf dynamische Arrays von Architekturbeschreibungen von 3 Modellen übergeben:
- Actor (Akteur)
- Critic (Kritiker)
- Random encoder (Zufallscodierer)
Ich möchte hier daran erinnern, dass der SMAC-Algorithmus das Training eines stochastischen latenten Zustandscodierers vorsieht, den wir zuvor in die Actor-Architektur aufgenommen haben und der vom Critic verwendet werden kann. Wir werden diese Lösung in dieser Implementierung verwenden.
Im Hauptteil der Methode werden die empfangenen Zeiger überprüft und gegebenenfalls neue Objektinstanzen erstellt.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic, CArrayObj *convolution) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!convolution) { convolution = new CArrayObj(); if(!convolution) return false; }
Wir geben in den Actor historische Daten über Kursbewegungen und Indikatorwerte ein, was sich in der Größe seiner Rohdatenschicht widerspiegelt.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Wir speisen das Modell mit unbearbeiteten Rohdaten. Daher verwenden wir nach der Rohdatenebene eine Batch-Daten-Normalisierungsebene. Sie bringt die aus verschiedenen Quellen gewonnenen Rohdaten in eine vergleichbare Form.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Danach versuchen wir, mithilfe von Faltungsschichten stabile Datenmuster zu erkennen. Um eine probabilistische Darstellung der Zuordnung von Quelldaten zu stabilen Mustern zu erhalten, verwenden wir die SoftMax-Funktion.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = HistoryBars; descr.window = BarDescr; descr.step = BarDescr; int prev_wout = descr.window_out = BarDescr / 2; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.optimization = ADAM; descr.activation = None; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.optimization = ADAM; descr.activation = None; if(!convolution.Add(descr)) { delete descr; return false; }
Bitte beachten Sie, dass wir nach stabilen Mustern im Zusammenhang mit jeder einzelnen Kerze der historischen Daten suchen.
Die Ergebnisse der Mustersuche werden von zwei vollständig vernetzten Schichten analysiert.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Zu den erhaltenen Daten fügen wir eine Beschreibung des Kontostatus hinzu.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = 2 * LatentCount; descr.window = prev_count; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; }
Dann erzeugen wir den stochastischen latenten Zustand, der durch die SMAC-Methode bereitgestellt wird.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = LatentCount; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Danach folgt ein Entscheidungsblock mit 2 vollständig verbundenen Schichten.
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Am Ausgang des Akteurs setzen wir einen Variations-Autoencoder-Block, um die Politik stochastisch zu machen. Die Größe der Ergebnisschicht entspricht der Dimension des Aktionsvektors des Agenten.
//--- layer 12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 13 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Die Architektur des Kritikers wird unverändert übernommen. Der Input des Modells ist eine latente Repräsentation des Umgebungszustands aus der versteckten Schicht des Akteurs. Die gewonnenen Daten müssen nicht in eine vergleichbare Form gebracht werden. Aus diesem Grund wird in diesem Modell keine Batch-Normalisierungsschicht verwendet.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
Der latenten Repräsentation fügen wir die Aktionen des Akteurs hinzu.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = NActions; descr.optimization = ADAM; descr.activation = LReLU; if(!critic.Add(descr)) { delete descr; return false; }
Die verketteten Daten werden von einem Entscheidungsblock aus 3 vollständig verbundenen Schichten analysiert. Die Größe der letzten Schicht entspricht der Größe des zerlegten Belohnungsvektors.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.optimization = ADAM; descr.activation = None; if(!critic.Add(descr)) { delete descr; return false; }
Am Ende der CreateDescriptions-Methode fügen wir eine Beschreibung der zufälligen Encoder-Architektur hinzu. Ein wenig vorausschauend möchte ich sagen, dass wir den Encoder als Teil des Prozesses zur Bestimmung des Abstands zwischen Umweltzuständen verwenden werden. Um einen einzelnen Zustand der Umgebung zu beschreiben, verwenden wir 2 Vektoren:
- der historischen Preis- und Indikatordaten
- des Kontostands und der offenen Positionen
Wir werden den verketteten Vektor dieser beiden Entitäten in den Encoder einspeisen.
//--- Convolution convolution.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr) + AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; }
Das Encoder-Modell wird nicht trainiert. Daher wird die Verwendung einer Batch-Normalisierungsschicht nicht das gewünschte Ergebnis liefern. Um die Daten in eine vergleichbare Form zu bringen, werden wir daher eine vollständig verbundene Schicht verwenden. Dann werden wir die Daten mit Hilfe der SoftMax-Ebene normalisieren.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = HistoryBars * BarDescr; descr.optimization = ADAM; descr.activation = None; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = HistoryBars; descr.step = BarDescr; descr.optimization = ADAM; descr.activation = None; if(!convolution.Add(descr)) { delete descr; return false; }
Danach folgt ein Block von Faltungsschichten, der ebenfalls mit einer SoftMax-Schicht bedeckt ist.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = HistoryBars; descr.window = BarDescr; descr.step = BarDescr; prev_wout = descr.window_out = BarDescr / 2; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = prev_wout / 2; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = 2; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count * prev_wout; descr.optimization = ADAM; descr.activation = None; if(!convolution.Add(descr)) { delete descr; return false; }
Am Ausgang des Encoders verwenden wir eine voll verknüpfte Schicht, die die Einbettung des analysierten Zustands der Umgebung liefert.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- return true; }
2.2 Vorbereiten von Hilfsmethoden
Nachdem wir die Architektur der verwendeten Modelle beschrieben haben, arbeiten wir an der Implementierung des Algorithmus zum Training der Modelle. Doch bevor wir den Lernprozess implementieren, wollen wir die Methoden erörtern, mit denen einzelne Blöcke des allgemeinen Algorithmus umgesetzt werden.
Zunächst werden wir die Gewichtung und Priorisierung von Trajektorien verwenden, die im Rahmen der Methode CWBC diskutiert wurde. Zu diesem Zweck werden wir die Methoden GetProbTrajectories und SampleTrajectory migrieren. Ihr Algorithmus wurde im vorigen Artikel ausführlich beschrieben, sodass wir jetzt nicht näher darauf eingehen wollen.
Um den Akteur und die Kritiker zu trainieren, werden wir Belohnungen und Aktionen verwenden, die mit DWSL-Methoden gewichtet werden. Um wiederholte Operationen zu vermeiden, werden wir die Berechnung der Zielvektoren für beide Modelle in einer GetTargets-Methode zusammenfassen. Um die Möglichkeit zu schaffen, 2 Vektoren in einem Arbeitsgang zu übertragen, werden wir eine Struktur erstellen.
struct STarget { vector<float> rewards; vector<float> actions; };
Die Methode GetTargets erhält also Parameter:
- Perzentil zur Bestimmung der Anzahl der am nächsten liegenden analysierten Zustände aus der Trainingsmenge;
- Einbettung des analysierten Zustands;
- Matrix der Zustandseinbettungen in der Trainingsmenge;
- Matrix der Belohnungen aus der Trainingsmenge;
- Matrix der Agentenaktionen aus der Trainingsmenge.
Die letzten 3 Matrizen entsprechen sich gegenseitig.
Basierend auf den Ergebnissen der Arbeit gibt die Methode die Struktur ihrer 2 Zielvektoren zurück.
STarget GetTargets(int percentile, vector<float> &embedding, matrix<float> &state_embedding, matrix<float> &rewards, matrix<float> &actions ) { STarget result;
Im Hauptteil der Methode geben wir die Struktur der Ergebnisse an und überprüfen sofort die Übereinstimmung der Einbettungsgrößen des analysierten Zustands und der Matrix der Zustände aus dem Trainingssatz.
if(embedding.Size() != state_embedding.Cols()) { PrintFormat("%s -> %d Inconsistent embedding size", __FUNCTION__, __LINE__); return result; }
Als Nächstes bestimmen wir den Abstand zwischen dem analysierten Zustand und den Zuständen aus der Trainingsmenge. Zur Bestimmung des weichen Abstands verwenden wir LogSumExp, das von den Autoren der DWSL-Methode vorgeschlagen wurde.
ulong size = embedding.Size(); ulong states = state_embedding.Rows(); ulong k = ulong(states * percentile / 100); matrix<float> temp = matrix<float>::Zeros(states, size); for(ulong i = 0; i < size; i++) temp.Col(MathAbs(state_embedding.Col(i) - embedding[i]), i); float alpha=temp.Max(); vector<float> dist = MathLog(MathExp(temp/(-alpha)).Sum(1))*(-alpha);
Danach erstellen wir lokale Matrizen von Belohnungen, Aktionen und Einbettungen. Die Daten über die nächstgelegenen Staaten werden in diese Matrizen übertragen.
vector<float> min_dist = vector<float>::Zeros(k); matrix<float> k_rewards = matrix<float>::Zeros(k, NRewards); matrix<float> k_actions = matrix<float>::Zeros(k, NActions); matrix<float> k_embedding = matrix<float>::Zeros(k + 1, size); matrix<float> U, V; vector<float> S; float max = dist.Percentile(percentile); float min = dist.Min(); for(ulong i = 0, cur = 0; (i < states && cur < k); i++) { if(max < dist[i]) continue; min_dist[cur] = dist[i]; k_rewards.Row(rewards.Row(i), cur); k_actions.Row(actions.Row(i), cur); k_embedding.Row(state_embedding.Row(i), cur); cur++; } k_embedding.Row(embedding, k);
Um den Ziel-Belohnungsvektor für das Training zu erhalten, müssen wir die Matrix der ausgewählten Belohnungen auf der Grundlage des Abstands zum analysierten Zustand gewichten. Beachten Sie, dass der minimale Abstand das minimale Gewicht der entsprechenden Belohnung ergibt. Dies widerspricht jedoch der allgemeinen Logik: Der relevanteste Wert hat minimale Auswirkungen auf das Endergebnis. Dies kann leicht behoben werden. Wir werden den Abstandsvektor einfach mit „-1“ multiplizieren. Die Funktion SoftMax transformiert die erhaltenen Werte in die Wahrscheinlichkeitsebene. Nun müssen wir nur noch den resultierenden Wahrscheinlichkeitsvektor mit der gesammelten Belohnungsmatrix der nächstgelegenen Zustände multiplizieren.
vector<float> sf; (min_dist*(-1)).Activation(sf, AF_SOFTMAX); result.rewards = sf.MatMul(k_rewards);
Hier fügen wir auch Nukleus-Normen hinzu, um den Akteur zum Lernen zu ermutigen.
k_embedding.SVD(U, V, S); result.rewards[NRewards - 2] = S.Sum() / (MathSqrt(MathPow(k_embedding, 2.0f).Sum() * MathMax(k + 1, size))); result.rewards[NRewards - 1] = EntropyLatentState(Actor);
Als Nächstes bilden wir einen Zielvektor von Aktionen. Dieses Mal werden wir die Maßnahmen nach ihrer bevorzugten Belohnung abwägen. Ähnlich wie den Abstandsvektor berechnen wir den Belohnungsvektor mit der Funktion LogSumExp.
vector<float> act_sf; alpha=MathAbs(k_rewards).Max(); dist = MathLog(MathExp(k_rewards/(-alpha)).Sum(1))*(-alpha);
Dieses Mal sollte die maximale Belohnung die maximale Wirkung haben, sodass wir die Werte nicht umkehren müssen. Wir übertragen die Belohnungen einfach mit Hilfe der Funktion SoftMax in den Bereich der Wahrscheinlichkeitswerte. Anschließend wird der resultierende Vektor mit der Aktionsmatrix multipliziert. Das Ergebnis wird in die Struktur geschrieben. Dann geben wir beide Vektoren der Zielwerte an den Aufrufer zurück.
Damit sind die vorbereitenden Arbeiten abgeschlossen, und wir können mit der Implementierung des Hauptalgorithmus fortfahren.
2.3 Der Expert Advisor zum Training und der Datenerhebung
Als Nächstes gehen wir zu einem Datenerfassungsprogramm für das Offline-Modelltraining über. Diese Aufgabe wird wie bisher im Expert Advisor „...\DWSL\Research.mq5“ umgesetzt. Wir werden nicht den gesamten Code dieses EA überprüfen, da die meisten seiner Methoden bereits in früheren Artikeln verwendet und im Detail betrachtet wurden. Schauen wir uns die wichtigsten Merkmale an. Beginnen wir mit der Tick-Handling-Methode OnTick, in deren Hauptteil der Hauptalgorithmus implementiert ist.
Zu Beginn der Methode wird geprüft, ob ein neuer Balken geöffnet wurde, und gegebenenfalls werden historische Preis- und Indikatordaten geladen.
void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Anhand der gewonnenen Daten bilden wir einen Puffer von Ausgangsdaten:
float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
und einen Puffer mit den Kontoständen:
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bAccount.Clear(); bAccount.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bAccount.Add((float)(sState.account[1] / PrevBalance)); bAccount.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bAccount.Add(sState.account[2]); bAccount.Add(sState.account[3]); bAccount.Add((float)(sState.account[4] / PrevBalance)); bAccount.Add((float)(sState.account[5] / PrevBalance)); bAccount.Add((float)(sState.account[6] / PrevBalance)); double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(2.0 * M_PI * x));
Wir übertragen die gesammelten Daten an das Akteursmodell und rufen die Feed-Forward-Methode auf. Vergessen wir nicht, die Ausführung von Vorgängen zu kontrollieren.
if(bAccount.GetIndex() >= 0) if(!bAccount.BufferWrite()) return; //--- if(!Actor.feedForward(GetPointer(bState), 1, false, GetPointer(bAccount))) return;
Als Ergebnis des Feed-Forward-Durchgangs erzeugt das Akteursmodell einen Aktionsvektor, den wir entschlüsseln. Hier entfernen wir nur die Menge der Gegenoperationen, die keinen Gewinn bringen. Im Gegensatz zu anderen, bereits diskutierten Arbeiten fügen wir dem resultierenden Vektor kein Rauschen hinzu, um die Umgebung zu erkunden. Die stochastische Politik des Akteurs erzeugt zusammen mit der Stochastizität des latenten Zustands bereits eine ausreichende Anzahl von Aktionen, um die unmittelbare Umgebung des Aktionsraums zu erkunden.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Actor.getResults(temp); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; }
Anschließend vergleichen wir die bestehende Position mit der Prognose des Akteurs und führen gegebenenfalls Handelsoperationen durch. Zunächst für Kaufpositionen:
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()); double buy_sl = NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
dann wiederholen wir dies für Verkaufspositionen:
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()); double sell_sl = NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Am Ende der Methodenoperationen müssen alle Rückmeldungen aus der Umgebung gesammelt und die Daten in den Erfahrungswiedergabepuffer übertragen werden.
sState.rewards[0] = bAccount[0]; sState.rewards[1] = 1.0f - bAccount[1]; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; sState.rewards[3] = 0; sState.rewards[4] = 0; if(!Base.Add(sState)) ExpertRemove(); }
Zu diesem Zeitpunkt kann die Datenerhebung als abgeschlossen betrachtet werden. Die Arbeit an diesem Expert Advisor ist jedoch noch nicht abgeschlossen. Im Rahmen der Umsetzung der DWSL-Methode möchte ich Sie auf ein Detail aufmerksam machen. Im theoretischen Teil dieses Artikels haben wir erwähnt, dass die DWSL-Methode zur optimalen Politik konvergiert mit einer minimalen Rückkehrgrenze auf der Ebene der Trajektorien aus der Trainingsmenge. Bei der Suche nach dem optimalen Weg möchten wir natürlich die Mindestrentabilitätsgrenze so hoch wie möglich ansetzen. Zu diesem Zweck werden wir Änderungen am Prozess des Hinzufügens neuer Trajektorien zum Erfahrungswiedergabepuffer vornehmen. Nach dem anfänglichen Auffüllen des Puffers werden wir nach und nach die Durchläufe mit geringer Rentabilität durch rentablere ersetzen. Dieser Prozess ist in der Methode OnTesterPass implementiert, die das Ereignis für den Abschluss des Tests im Strategietester verarbeitet.
Im Hauptteil der Methode werden zunächst lokale Variablen initialisiert. Erstellen wir sofort eine Schleife zur Abfrage der Durchlaufbilder (frames).
void OnTesterPass() { //--- ulong pass; string name; long id; double value; STrajectory array[]; while(FrameNext(pass, name, id, value, array)) {
Im Hauptteil der Schleife wird geprüft, ob das Bild mit dem aktuellen Programm übereinstimmt.
int total = ArraySize(Buffer); if(name != MQLInfoString(MQL_PROGRAM_NAME)) continue; if(id <= 0) continue;
Danach verzweigt sich der Prozess, je nachdem wie der Erfahrungswiedergabepuffer gefüllt ist. Wenn der Puffer bereits bis zur angegebenen Maximalgröße gefüllt ist, suchen wir im Puffer nach einem Durchlauf mit der niedrigsten Ergebnis. Dabei kann es sich um den höchsten Verlust oder den niedrigsten Gewinn handeln.
if(total >= MaxReplayBuffer) { for(int a = 0; a < id; a++) { float min = FLT_MAX; int min_tr = 0; for(int i = 0; i < total; i++) { float prof = Buffer[i].States[Buffer[i].Total - 1].account[1]; if(prof < min) { min = MathMin(prof, min); min_tr = i; } }
Anschließend wird der resultierende Wert mit dem Ergebnis des letzten Durchgangs verglichen. Ist er höher, werden die Daten des neuen Durchgangs anstelle des niedrigsten gefundenen Rücklaufs geschrieben. Andernfalls fahren wir mit dem nächsten Durchgang fort.
float prof = array[a].States[array[a].Total - 1].account[1]; if(min <= prof) { Buffer[min_tr] = array[a]; PrintFormat("Replace %.2f to %.2f -> bars %d", min, prof, array[a].Total); } } }
Wenn der Puffer noch nicht voll ist, fügen wir einfach einen neuen Durchlauf ohne unnötige Kontrollvorgänge hinzu.
else { if(ArrayResize(Buffer, total + (int)id, 10) < 0) return; ArrayCopy(Buffer, array, total, 0, (int)id); } } }
Wir setzen die folgende Priorität:
- Maximale Füllung des Erfahrungswiedergabepuffers, um die trainierten Modelle mit möglichst vollständigen Informationen über die Umgebung zu versorgen.
- Nach dem Füllen des Erfahrungswiederholungspuffers wählen wir die profitabelsten Durchläufe aus, um eine optimale Strategie zu entwickeln.
Der vollständige Code des Expert Advisors und alle seine Methoden sind im Anhang zu finden. Die Anhänge enthalten auch den Code des Expert Advisors für den Modelltest „...\DWSL\Test.mq5“. Er hat einen ähnlichen Algorithmus wie die Tick-Verarbeitungsmethode, ist aber für einen einzigen Lauf im Strategietester gedacht. Wir werden ihn im Rahmen dieses Artikels nicht berücksichtigen.
2.4 EA für das Modelltraining
Das Modelltraining wird im Expert Advisor „...\DWSL\Study.mq5“ durchgeführt. Wir werden nicht im Detail auf alle Methoden eingehen. Sehen wir uns nur die Methode Train an, die den Hauptalgorithmus für das Training der Modelle organisiert.
Im Hauptteil der Methode legen wir die Größe des Erfahrungswiedergabepuffers fest und speichern sie in einer lokalen Tick-Counter-Zustandsvariablen, um die für die Operationen aufgewendete Zeit zu verfolgen.
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
Als Nächstes gehen wir in einer Schleife durch alle Trajektorien, um die Gesamtzahl der Zustände im Erfahrungswiedergabepuffer zu zählen. Auf diese Weise können wir Matrizen von ausreichender Größe erstellen, um die Zustandseinbettungen sowie die entsprechenden Belohnungen und Aktionen des Agenten aufzuzeichnen. Wir haben die Verwendung dieser Matrizen bereits in der GetTargets-Methode gesehen.
int total_states = Buffer[0].Total; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total; vector<float> temp, next; Convolution.getResults(temp); matrix<float> state_embedding = matrix<float>::Zeros(total_states, temp.Size()); matrix<float> rewards = matrix<float>::Zeros(total_states, NRewards); matrix<float> actions = matrix<float>::Zeros(total_states, NActions);
Der nächste Schritt ist das Ausfüllen dieser Matrizen. Zu diesem Zweck erstellen wir ein System von Schleifen mit einer vollständigen Suche aller Zustände aus dem Erfahrungswiedergabepuffer. Im Hauptteil dieses Schleifensystems sammeln wir eine Beschreibung jedes einzelnen Zustands in einem einzigen Datenpuffer.
int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total; st++) { State.AssignArray(Buffer[tr].States[st].state); float PrevBalance = Buffer[tr].States[MathMax(st - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(st - 1, 0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st].account[1] / PrevBalance); State.Add((Buffer[tr].States[st].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / PrevBalance); State.Add(Buffer[tr].States[st].account[5] / PrevBalance); State.Add(Buffer[tr].States[st].account[6] / PrevBalance); double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
Dann erzeugen wir im Feedforward-Durchlauf des Encoders dessen Einbettung.
if(!Convolution.feedForward(GetPointer(State), 1, false, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } Convolution.getResults(temp);
Der Ausgangsvektor wird in der Matrix state_embedding gespeichert.
if(!state_embedding.Row(temp, state)) continue;
Die relevanten Daten aus dem Erfahrungswiedergabepuffer werden in den Matrizen „rewards“ (Belohnungen) und „actions“ (Aktionen) des Agenten gespeichert.
if(!temp.Assign(Buffer[tr].States[st].rewards) || !next.Assign(Buffer[tr].States[st + 1].rewards) || !rewards.Row(temp - next * DiscFactor, state)) continue; if(!temp.Assign(Buffer[tr].States[st].action) || !actions.Row(temp, state)) continue;
Bitte beachten Sie, dass wir der Belohnungsmatrix nur Vorteile für den Wechsel in den nächsten Zustand hinzufügen. Außerdem brechen wir das Programm im Falle eines Fehlers nicht vollständig ab, sondern gehen einfach zum nächsten Zustand über. Wir schließen also nicht den gesamten Lernprozess ab, sondern reduzieren die Vergleichsbasis nur geringfügig.
Dann wird der Zähler der gespeicherten Einbettungen erhöht. Bevor wir zur nächsten Iteration unseres Schleifensystems übergehen, informieren wir den Nutzer über den Fortschritt des Zustandscodierungsprozesses.
state++; if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %6.2f%%", "Embedding ", state * 100.0 / (double)(total_states)); Comment(str); ticks = GetTickCount(); } } }
Sobald der Kodierungsprozess abgeschlossen ist, reduzieren wir unsere Matrizen auf die tatsächlich vorhandene Datenmenge.
if(state != total_states)
{
rewards.Resize(state, NRewards);
actions.Resize(state, NActions);
state_embedding.Reshape(state, state_embedding.Cols());
total_states = state;
}
Der nächste Schritt ist die Vorbereitung lokaler Variablen und die Organisation der Priorisierung von Trajektorien. Der Prozess der Berechnung der Wahrscheinlichkeiten für die Wahl der Trajektorien ist in einer separaten GetProbTrajectories-Methode implementiert, deren Algorithmus im vorherigen Artikel vorgestellt wurde.
vector<float> rewards1, rewards2, target_reward; STarget target; //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
Damit ist die Phase der Datenaufbereitung abgeschlossen. Als Nächstes gehen wir zum Algorithmus für das Modelltraining über, der ebenfalls in einer Schleife organisiert ist. Die Anzahl der Iterationen der Modell-Trainingsschleife wird in den externen Parametern des Expert Advisors angegeben.
Im Hauptteil der Schleife wird zunächst die Trajektorie unter Berücksichtigung der oben berechneten Wahrscheinlichkeiten abgetastet. Das Verfahren ist in der SampleTrajectory-Methode implementiert, deren Algorithmus ebenfalls im vorherigen Artikel vorgestellt wurde. Dann wird der Zustand auf der ausgewählten Trajektorie abgetastet.
vector<float> probability = GetProbTrajectories(Buffer, 0.9); int bar = (HistoryBars - 1) * BarDescr; for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { iter--; continue; }
Als Nächstes habe ich den Verzweigungsprozess in Abhängigkeit von den abgeschlossenen Trainingsiterationen organisiert. Ich schließe die Schätzung des späteren Zustands durch die Zielmodelle in der Anfangsphase aus, da die Schätzung von Zuständen durch untrainierte Modelle völlig zufällig ist und den Lernprozess in die falsche Richtung führen kann. Die Bewertung des späteren Zustands durch Modelle mit einem ausreichenden Genauigkeitsgrad ermöglicht es wiederum, den erwarteten künftigen Ertrag der in diesem Schritt eingesetzten Politik zu schätzen. Auf diese Weise können wir Maßnahmen unter Berücksichtigung der späteren Erträge priorisieren.
In diesem Block wird der anfängliche Datenpuffer mit einer Beschreibung des späteren Zustands der Umgebung gefüllt.
State.AssignArray(Buffer[tr].States[i + 1].state); float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
Generieren wir die Agentenaktionen unter Berücksichtigung der aktualisierten Politik.
if(Account.GetIndex() >= 0) Account.BufferWrite(); if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Bewerten wir dann die resultierende Aktion mit zwei Modellen von Zielkritikern.
if(!TargetCritic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !TargetCritic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Wir verwenden die minimale Schätzung, um die erwartete Belohnung zu berechnen.
TargetCritic1.getResults(rewards1); TargetCritic2.getResults(rewards2); target_reward.Assign(Buffer[tr].States[i + 1].rewards); if(rewards1.Sum() <= rewards2.Sum()) target_reward = rewards1 - target_reward; else target_reward = rewards2 - target_reward; target_reward[NRewards - 1] = EntropyLatentState(Actor); target_reward *= DiscFactor; }
In der nächsten Phase gehen wir zum Training der Kritikermodelle über. Diese Modelle werden anhand von Zuständen und Aktionen aus dem Erfahrungswiedergabepuffer trainiert.
Zunächst kopieren wir die Beschreibungen des aktuellen Zustands der Umgebung in den Quelldatenpuffer.
//--- Q-function study
State.AssignArray(Buffer[tr].States[i].state);
Dann erstellen wir einen Puffer für die Beschreibung des Kontostands.
float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(Account.GetIndex() >= 0) Account.BufferWrite();
Anhand der gesammelten Daten können wir einen Feedforward-Durchlauf des Akteurs durchführen.
if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Bitte beachten Sie, dass wir den Vorwärtsdurchgang des Akteurs vor dem Training der Kritiker durchführen. Während des Trainingsprozesses werden wir jedoch Aktionen aus dem Erfahrungswiedergabepuffer verwenden. Dies ist darauf zurückzuführen, dass der latente Zustand des Akteurs als Input für die Kritiker verwendet wird.
Als Nächstes füllen wir den Aktionspuffer aus der Trainingsdatenbank und rufen die Methoden der Vorwärtsdurchgänge unserer Kritiker auf.
Actions.AssignArray(Buffer[tr].States[i].action); if(Actions.GetIndex() >= 0) Actions.BufferWrite(); //--- if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions)) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Wir werden gewichtete Belohnungen als Zielwerte für das Training von Modellen verwenden. Um sie zu erhalten, fügen wir zunächst eine Beschreibung des Kontostands zum Puffer des aktuellen Zustands der Umgebung hinzu und erzeugen eine Einbettung des analysierten Zustands.
if(!State.AddArray(GetPointer(Account)) || !Convolution.feedForward(GetPointer(State), 1, false, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Convolution.getResults(temp);
Der zu diesem Zeitpunkt verfügbare Datensatz reicht aus, um die zuvor besprochene Methode GetTargets aufzurufen, die die Vektoren der gewichteten Belohnungen und Aktionen zurückgibt.
target = GetTargets(Percent, temp, state_embedding, rewards, actions);
Mit den Zieldaten in der Hand können wir den Backpropagation-Durchgang der Critic-Modelle durchführen. Zunächst wird jedoch der Fehlergradient mit der Methode CAGrad korrigiert.
Critic1.getResults(rewards1); Result.AssignArray(CAGrad(target.rewards + target_reward - rewards1) + rewards1); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Critic2.getResults(rewards2); Result.AssignArray(CAGrad(target.rewards + target_reward - rewards2) + rewards2); if(!Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Im nächsten Schritt aktualisieren wir die Politik des Akteurs. Wir haben den Vorwärtsdurchlauf des Modells bereits früher durchgeführt. Außerdem haben wir einen gewichteten Vektor der Zielhandlungen erhalten. Wir haben also alle notwendigen Daten, um einen Backpropagation-Durchgang im überwachten Lernmodus durchzuführen.
//--- Policy study Actor.getResults(rewards1); Result.AssignArray(CAGrad(target.actions - rewards1) + rewards1); if(!Actor.backProp(Result, GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Wie Sie sehen können, haben wir bei der Bildung des Vektors der Zielaktionen des Akteurs die Vorteile der direkt aus dem Erfahrungswiedergabepuffer extrahierten Aktionen verwendet. Daher wurden keine trainierten Critic-Modelle verwendet. Bitte beachten Sie, dass der Einfluss des Akteurs auf die Marktbewegungen unabhängig von seiner Politik minimal ist. Daher kann eine Überschätzung des Vorteils bei Verwendung eines angenäherten kritischen Wertes die Daten durch Modellierungsfehler verzerren. In einem solchen Paradigma mag das Training von kritischen Modellen unnötig erscheinen. Dennoch wollen wir die Auswirkungen der untersuchten Maßnahmen auf die erwarteten künftigen Erträge berücksichtigen. Zu diesem Zweck wählen wir den Kritiker aus, der als Ergebnis des Trainings den geringsten Fehler aufweist. Wir bewerten auch die Aktionen des Akteurs, die durch die neue Politik ausgelöst werden. Der Gradient der Abweichung der resultierenden Schätzung von der gewichteten Schätzung wird dann an den Actor weitergeleitet, um die Parameter zu optimieren.
CNet *critic = NULL; if(Critic1.getRecentAverageError() <= Critic2.getRecentAverageError()) critic = GetPointer(Critic1); else critic = GetPointer(Critic2); if(MathAbs(critic.getRecentAverageError()) <= MaxErrorActorStudy) { if(!critic.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } critic.getResults(rewards1); Result.AssignArray(CAGrad(target.rewards + target_reward - rewards1) + rewards1); critic.TrainMode(false); if(!critic.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); critic.TrainMode(true); break; } critic.TrainMode(true); }
Beachten Sie, dass diese Operationen nur dann durchgeführt werden, wenn wir sicher sind, dass der Kritiker eine angemessene Bewertung der Aktionen vornehmen wird. Um diesen Prozess zu regeln, haben wir einen zusätzlichen externen Parameter MaxErrorActorStudy eingeführt, der den maximalen Fehler der Bewertung des Kritikers für die Aktivierung des angegebenen Prozesses bestimmt.
Nach Abschluss des Modelltrainings kopieren wir die Parameter der trainierten Critic-Modelle in die Zielmodelle. An dieser Stelle sei auch darauf hingewiesen, dass wir in der Anfangsphase, bevor wir den Prozess der Bewertung der nachfolgenden Zustände ermöglichen, die Parameter der trainierten Modelle vollständig auf die Zielmodelle übertragen. Die Verwendung des Mechanismus zur Schätzung der Folgezustände ermöglicht das sanfte Kopieren von Parametern.
//--- Update Target Nets if(iter >= StartTargetIter) { TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); } else { TargetCritic1.WeightsUpdate(GetPointer(Critic1), 1); TargetCritic2.WeightsUpdate(GetPointer(Critic2), 1); }
Damit ist eine Iteration der Modellbildung abgeschlossen. Jetzt müssen wir den Nutzer nur noch über den Fortschritt des Modelltrainings informieren und zur nächsten Iteration übergehen.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); str += StringFormat("%-14s %5.2f%% -> Error %15.8f\n", "Actor", iter * 100.0 / (double)(Iterations), Actor.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Nachdem alle Iterationen des Modelltrainingszyklus erfolgreich abgeschlossen wurden, wird das Kommentarfeld im Chart gelöscht. Wir informieren den Nutzer über die Lernergebnisse und leiten die Beendigung des Expert Advisors ein.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); ExpertRemove(); //--- }
Damit ist der praktische Teil unseres Artikels abgeschlossen. Im Anhang finden Sie den vollständigen Code aller im Artikel verwendeten Programme. Wir gehen in die Testphase über.
3. Tests
Wir haben umfangreiche Arbeit geleistet, um unsere Vision der DWSL-Methode mit MQL5 umzusetzen. Ich muss zugeben, dass wir eine Art Konglomerat aus einer Reihe von zuvor diskutierten Methoden erhalten haben. Dies ist ein ziemlich großes Experiment. Die Wirksamkeit unserer Lösung kann anhand historischer Daten überprüft werden. Das werden wir jetzt tun.
Wie in allen vorherigen Fällen wird das Modell anhand der EURUSD-H1-Daten für die ersten sieben Monate des Jahres 2023 trainiert. Die Daten für die Trainingsmodelle wurden im MetaTrader 5 Strategie-Tester im Modus der vollständigen Parameteroptimierung gesammelt. In der ersten Phase sammeln wir 500 zufällige Trajektorien. Da wir den Algorithmus der Methode OnTesterPass optimiert haben, können wir etwas mehr Durchläufe durchführen. Diejenigen, die die besten Ergebnisse erzielen, werden für den Erfahrungswiedergabepuffer ausgewählt.
Bitte beachten Sie, dass wir nicht danach streben sollten, gewinnbringende Durchläufe von Zufallspolitiken zu erhalten. In diesem Stadium ist es ein eher zufälliger Prozess. Wie wir bereits gesehen haben, ist die Wahrscheinlichkeit, mit einer zufälligen Politik über das gesamte Intervall einen vollständig profitablen Durchgang zu erhalten, nahe bei 0. Glücklicherweise ist die DWSL-Methode in der Lage, mit Rohdaten jeglicher Qualität zu arbeiten.
Nach dem Sammeln des Trainingsdatensatzes führen wir unser Modell zum ersten Mal als Expert Advisor aus.
In diesem Stadium habe ich noch keine vollständig profitable Strategie entwickelt. Dies ist vor allem auf die geringe Anzahl von Pässen aus dem Trainingsdatensatz zurückzuführen. Es ist jedoch anzumerken, dass die erneute Ausführung des Expert Advisors, der mit der Umgebung interagiert, nach dem ersten Trainingszyklus zu Trajektorien mit deutlich höheren Renditen führte. Während des gesamten Ausbildungszeitraums gab es eine einzige, möglicherweise zufällige, gewinnbringende Fahrt. Dies beweist im Allgemeinen die Wirksamkeit der Methode und verspricht die Möglichkeit, bessere Ergebnisse zu erzielen.
Nach mehreren Iterationen des Sammelns von Trajektorien und des Trainings gelang es mir, ein Modell zu entwickeln, das durchgängig Gewinne erzielen konnte. Das resultierende Modell wurde anhand historischer Daten vom August 2023 getestet, die nicht in der Trainingsdaten enthalten waren. Da sie jedoch direkt auf den Trainingszeitraum folgten, können wir davon ausgehen, dass die Datensätze vergleichbar sind.


Den Testergebnissen zufolge konnte das Modell mit einem Profitfaktor von 1,3 einen Gewinn erzielen. Das Schaubild des Saldos zeigt ein recht schnelles Wachstum in der ersten Monatshälfte. Danach schwankte sie in einem recht engen Bereich. Die folgenden Testergebnisse können als positiv angesehen werden:
- Mehr als 50 % der Positionen sind gewinnbringend.
- Der maximale Gewinn ist fast viermal so hoch wie der maximale Verlust, und der durchschnittliche Gewinn ist fast ein Viertel höher als der durchschnittliche Verlust.
- Es wird in beide Richtungen gehandelt (60% verkauft und 40% gekauft). Fast 55 % der Verkaufs- und 46 % der Kaufpositionen wurden mit Gewinn geschlossen.
- Die längste Gewinnserie übertrifft die längste Verlustserie sowohl in der Anzahl der Positionen als auch im Betrag.
Die erzielten Ergebnisse vermitteln im Allgemeinen einen positiven Eindruck.
Schlussfolgerung
In diesem Artikel haben wir eine weitere interessante Methode zum Trainieren von Modellen vorgestellt, das abstandsgewichtete überwachte Lernen. Durch die Verwendung einer gewichteten Bewertung der verfügbaren Daten ermöglicht es die Offline-Optimierung von gesammelten nicht-optimalen Trajektorien und das Training von recht interessanten Strategien. Anschließend zeigen sie gute Ergebnisse.
Die Wirksamkeit des Verfahrens wird durch unsere praktischen Ergebnisse bestätigt. Während des Trainingsprozesses haben wir eine Strategie entwickelt, die in der Lage war, das gelernte Material auf neue Daten zu verallgemeinern. Infolgedessen erhielten wir während der Tests eine profitable Saldenkurve.
Ich möchte Sie jedoch noch einmal daran erinnern, dass alle in diesem Artikel vorgestellten Programme nur der Demonstration der Technologie dienen und nicht für den realen Handel geeignet sind.
Referenzen
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | EA | Beispielsammlung EA |
| 2 | Study.mq5 | EA | Trainings-EA des Agenten |
| 3 | Test.mq5 | EA | Modeltraining-EA |
| 4 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 5 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 6 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/13779
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.