
Python, ONNX und MetaTrader 5: Erstellen eines RandomForest-Modells mit RobustScaler und PolynomialFeatures zur Datenvorverarbeitung

Welche Basis werden wir verwenden? Was ist Random Forest?
Die Geschichte der Methode des Random Forest (zufälliger Wald) reicht weit zurück und ist mit der Arbeit prominenter Wissenschaftler im Bereich des maschinellen Lernens und der Statistik verbunden. Um die Grundsätze und die Anwendung dieser Methode besser zu verstehen, stellen wir uns eine große Gruppe von Menschen (Entscheidungsbäume) vor, die zusammenarbeiten.
Die Random-Forest-Methode hat ihre Wurzeln in den Entscheidungsbäumen. Entscheidungsbäume dienen der grafischen Darstellung eines Entscheidungsalgorithmus, bei dem jeder Knoten einen Test auf eines der Attribute darstellt, jeder Zweig das Ergebnis dieses Tests und die Blätter die vorhergesagte Ausgabe. Entscheidungsbäume wurden Mitte des 20. Jahrhunderts entwickelt und haben sich zu beliebten Klassifizierungs- und Regressionsinstrumenten entwickelt.
Der nächste wichtige Schritt war das Konzept des Bagging (Bootstrap Aggregating), das 1996 von Leo Breiman vorgeschlagen wurde. Bagging bedeutet, dass ein Trainingsdatensatz in mehrere Bootstrap-Stichproben (Teilstichproben) aufgeteilt wird und für jede dieser Stichproben separate Modelle trainiert werden. Die Ergebnisse der Modelle werden dann gemittelt oder kombiniert, um robustere und genauere Vorhersagen zu erhalten. Diese Methode hat es ermöglicht, die Varianz der Modelle zu verringern und ihre Verallgemeinerungsfähigkeit zu verbessern.
Die Random-Forest-Methode wurde von Leo Breiman und Adele Cutler in den frühen 2000er Jahren vorgeschlagen. Es basiert auf der Idee, mehrere Entscheidungsbäume unter Verwendung von Bagging und zusätzlicher Zufälligkeit zu kombinieren. Jeder Baum wird aus einer zufälligen Unterstichprobe des Trainingsdatensatzes erstellt, und bei der Erstellung jedes Knotens im Baum wird ein zufälliger Satz von Merkmalen ausgewählt. Dies macht jeden Baum einzigartig und reduziert die Korrelation zwischen den Bäumen, was zu einer verbesserten Verallgemeinerungsfähigkeit führt.
Random Forest hat sich aufgrund seiner hohen Leistung und der Fähigkeit, sowohl Klassifizierungs- als auch Regressionsprobleme zu bewältigen, schnell zu einer der beliebtesten Methoden des maschinellen Lernens entwickelt. Bei Klassifizierungsproblemen wird sie verwendet, um zu entscheiden, zu welcher Klasse ein Objekt gehört, und bei der Regression wird sie verwendet, um numerische Werte vorherzusagen.
Random Forest wird heute in verschiedenen Bereichen wie Finanzen, Medizin, Datenanalyse und vielen anderen eingesetzt. Es wird für seine Robustheit und seine Fähigkeit, komplexe Probleme des maschinellen Lernens zu bewältigen, geschätzt.
Random Forest ist ein leistungsfähiges Werkzeug im Werkzeugkasten des maschinellen Lernens. Um besser zu verstehen, wie das funktioniert, stellen wir uns vor, dass eine große Gruppe von Menschen zusammenkommt und gemeinsam Entscheidungen trifft. Anstelle von realen Personen ist jedoch jedes Mitglied dieser Gruppe ein unabhängiger Klassifikator oder Prädiktor der aktuellen Situation. Innerhalb dieser Gruppe ist eine Person ein Entscheidungsbaum, der in der Lage ist, Entscheidungen auf der Grundlage bestimmter Eigenschaften zu treffen. Wenn der Random Forest eine Entscheidung trifft, nutzt er Demokratie und Abstimmung: Jeder Baum äußert seine Meinung, und die Entscheidung wird auf der Grundlage mehrerer Stimmen getroffen.
Random Forest wird in einer Vielzahl von Bereichen eingesetzt und eignet sich aufgrund seiner Flexibilität sowohl für Klassifizierungs- als auch für Regressionsprobleme. Bei einer Klassifizierungsaufgabe entscheidet das Modell, zu welcher der vordefinierten Klassen der aktuelle Zustand gehört. Auf dem Finanzmarkt könnte dies beispielsweise eine Entscheidung zum Kauf (Klasse 1) oder Verkauf (Klasse 0) eines Vermögenswerts auf der Grundlage einer Vielzahl von Indikatoren bedeuten.
In diesem Artikel werden wir uns jedoch auf Regressionsprobleme konzentrieren. Die Regression beim maschinellen Lernen ist ein Versuch, die zukünftigen numerischen Werte einer Zeitreihe auf der Grundlage ihrer vergangenen Werte vorherzusagen. Im Gegensatz zur Klassifizierung, bei der wir Objekte bestimmten Klassen zuordnen, versuchen wir bei der Regression, bestimmte Zahlen vorherzusagen. Dies könnte zum Beispiel die Vorhersage von Aktienkursen, die Vorhersage der Temperatur oder jede andere numerische Variable sein.
Erstellen eines grundlegenden RF-Modells
Um ein einfaches Random Forest-Modell zu erstellen, verwenden wir die Pythons Bibliothek sklearn (Scikit-learn). Nachfolgend finden Sie eine einfache Codevorlage für das Training eines Random Forest Regressionsmodells. Bevor Sie diesen Code ausführen, sollten Sie die Bibliotheken, die für die Ausführung von sklearn benötigt werden, mit dem Python Package Installer Tool installieren.
pip install onnx
pip install skl2onnx
pip install MetaTrader5
Als Nächstes müssen Bibliotheken importiert und Parameter festgelegt werden. Wir importieren die erforderlichen Bibliotheken, darunter „pandas“ für die Arbeit mit Daten, „gdown“ zum Laden von Daten aus Google Drive sowie Bibliotheken für die Datenverarbeitung und die Erstellung eines Random Forest-Modells. Wir legen auch die Anzahl der Zeitschritte (n_steps) in der Datenfolge fest, die je nach den spezifischen Anforderungen bestimmt wird:
import pandas as pd import gdown import numpy as np import joblib import random import onnx import os import shutil from sklearn.ensemble import RandomForestRegressor from sklearn.metrics import mean_squared_error, r2_score from sklearn.utils import shuffle from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType from sklearn.pipeline import Pipeline from sklearn.preprocessing import RobustScaler, MinMaxScaler, PolynomialFeatures, PowerTransformer import MetaTrader5 as mt5 from datetime import datetime # Set the number of time steps according to requirements n_steps = 100
Im nächsten Schritt laden und verarbeiten wir die Daten. In unserem konkreten Beispiel laden wir Kursdaten aus dem MetaTrader 5 und verarbeiten sie. Wir legen den Zeitindex fest und wählen nur die Schlusskurse aus (mit denen wir arbeiten werden):
Hier ist der Teil des Codes, der für die Aufteilung unserer Daten in Trainings- und Testdatensätze sowie für die Kennzeichnung des Satzes für das Modelltraining verantwortlich ist. Wir teilen die Daten in Trainings- und Testsätze auf. Anschließend werden die Daten für die Regression etikettiert, was bedeutet, dass jedes Etikett den tatsächlichen zukünftigen Preiswert darstellt. Die Funktion labelling_relabeling_regression wird zur Erstellung von gekennzeichneten Daten verwendet.mt5.initialize() SYMBOL = 'EURUSD' TIMEFRAME = mt5.TIMEFRAME_H1 START_DATE = datetime(2000, 1, 1) STOP_DATE = datetime(2023, 1, 1) # Set the number of time steps according to your requirements n_steps = 100 # Process data data = pd.DataFrame(mt5.copy_rates_range(SYMBOL, TIMEFRAME, START_DATE, STOP_DATE), columns=['time', 'close']).set_index('time') data.index = pd.to_datetime(data.index, unit='s') data = data.dropna() data = data[['close']] # Work only with close prices
# Define train_data_initial training_size = int(len(data) * 0.70) train_data_initial = data.iloc[:training_size] test_data_initial = data.iloc[training_size:] # Function for creating and assigning labels for regression (changes made for regression, not classification) def labelling_relabeling_regression(dataset, min_value=1, max_value=1): future_prices = [] for i in range(dataset.shape[0] - max_value): rand = random.randint(min_value, max_value) future_pr = dataset['<CLOSE>'].iloc[i + rand] future_prices.append(future_pr) dataset = dataset.iloc[:len(future_prices)].copy() dataset['future_price'] = future_prices return dataset # Apply the labelling_relabeling_regression function to raw data to get labeled data train_data_labeled = labelling_relabeling_regression(train_data_initial) test_data_labeled = labelling_relabeling_regression(test_data_initial)
Als Nächstes erstellen wir Trainingsdatensätze aus bestimmten Sequenzen. Das Wichtigste ist, dass das Modell alle Cloe-Preise in unserer Sequenz als Merkmale berücksichtigt. Es wird die gleiche Sequenzgröße verwendet wie die Größe der Daten, die in das ONNX-Modell eingegeben werden. In dieser Phase findet keine Normalisierung statt; sie wird in der Trainingspipeline als Teil der Modellpipeline-Operation durchgeführt.
# Create datasets of features and target variables for training x_train = np.array([train_data_labeled['<CLOSE>'].iloc[i - n_steps:i].values[-n_steps:] for i in range(n_steps, len(train_data_labeled))]) y_train = train_data_labeled['future_price'].iloc[n_steps:].values # Create datasets of features and target variables for testing x_test = np.array([test_data_labeled['<CLOSE>'].iloc[i - n_steps:i].values[-n_steps:] for i in range(n_steps, len(test_data_labeled))]) y_test = test_data_labeled['future_price'].iloc[n_steps:].values # After creating x_train and x_test, define n_features as follows: n_features = x_train.shape[1] # Now use n_features to determine the ONNX input data type initial_type = [('float_input', FloatTensorType([None, n_features]))]
Erstellen einer Pipeline für die Datenvorverarbeitung
Unser nächster Schritt ist die Erstellung eines Random Forest-Modells. Dieses Modell sollte als Pipeline aufgebaut sein.
Die Pipeline in der Bibliothek scikit-learn (sklearn) bietet eine Möglichkeit, eine sequentielle Kette von Transformationen und Modellen für die Datenanalyse und das maschinelle Lernen zu erstellen. Eine Pipeline ermöglicht es Ihnen, mehrere Datenverarbeitungs- und Modellierungsphasen in einem einzigen Objekt zu kombinieren, mit dem Sie die Daten effizient und sequentiell bearbeiten können.
In unserem Codebeispiel erstellen wir die folgende Pipeline:
# Create a pipeline with MinMaxScaler, RobustScaler, PolynomialFeatures and RandomForestRegressor
pipeline = Pipeline([
('MinMaxScaler', MinMaxScaler()),
('robust', RobustScaler()),
('poly', PolynomialFeatures()),
('rf', RandomForestRegressor(
n_estimators=20,
max_depth=20,
min_samples_split=5000,
min_samples_leaf=5000,
random_state=1,
verbose=2
))
])
# Train the pipeline
pipeline.fit(x_train, y_train)
# Make predictions
predictions = pipeline.predict(x_test)
# Evaluate model using R2
r2 = r2_score(y_test, predictions)
print(f'R2 score: {r2}')
Wie Sie sehen, ist eine Pipeline eine Abfolge von Datenverarbeitungs- und Modellierungsschritten, die in einer Kette zusammengefasst sind. In diesem Code wird die Pipeline mit Hilfe der Bibliothek Scikit-Learn erstellt. Sie umfasst die folgenden Schritte:
-
MinMaxScaler skaliert die Daten in einem Bereich von 0 bis 1. Dies ist nützlich, um sicherzustellen, dass alle Merkmale einen einheitlichen Maßstab haben.
-
RobustScaler führt ebenfalls eine Datenskalierung durch, ist aber robuster gegenüber Ausreißern im Datensatz. Für die Skalierung werden der Median und der Interquartilsbereich verwendet.
-
PolynomialFeatures wendet eine polynomiale Transformation auf die Merkmale an. Dadurch werden polynomiale Merkmale hinzugefügt, die dem Modell helfen können, nichtlineare Beziehungen in den Daten zu berücksichtigen.
-
RandomForestRegressor definiert ein Random-Forest-Modell mit einer Reihe von Hyperparametern:
- n_estimators (Anzahl der Bäume im Forest). Angenommen, Sie haben eine Gruppe von Experten, von denen jeder auf die Vorhersage von Preisen auf dem Finanzmarkt spezialisiert ist. Die Anzahl der Bäume im Random Forest (n_estimators) bestimmt, wie viele solcher Experten es in Ihrer Gruppe geben wird. Je mehr Bäume Sie haben, desto mehr verschiedene Meinungen und Vorhersagen werden bei der Entscheidungsfindung des Modells berücksichtigt.
- max_depth (maximale Tiefe der einzelnen Bäume). Dieser Parameter legt fest, wie tief jeder Experte (Baum) in die Datenanalyse „eintauchen“ kann. Wenn Sie z. B. die maximale Tiefe auf 20 einstellen, trifft jeder Baum Entscheidungen auf der Grundlage von höchstens 20 Merkmalen oder Eigenschaften.
- min_samples_split (Mindestanzahl von Stichproben für die Aufteilung eines Baumknotens). Dieser Parameter gibt an, wie viele Stichproben (Beobachtungen) in einem Baumknoten vorhanden sein müssen, damit der Baum weiter in kleinere Knoten unterteilt wird. Wenn Sie z. B. die Mindestanzahl der aufzuteilenden Stichproben auf 5000 festlegen, werden die Knoten nur aufgeteilt, wenn es mehr als 5000 Beobachtungen pro Knoten gibt.
- min_samples_leaf (Mindestanzahl von Stichproben in einem Blattknoten der Baumstruktur). Dieser Parameter bestimmt, wie viele Proben in einem Blattknoten des Baums vorhanden sein müssen, damit dieser Knoten ein Blatt wird und nicht weiter aufgeteilt wird. Wenn Sie z. B. die Mindestanzahl von Stichproben in einem Blattknoten auf 5000 festlegen, enthält jedes Blatt des Baums mindestens 5000 Beobachtungen.
- random_state (legt den Ausgangszustand für die Zufallsgenerierung fest, um reproduzierbare Ergebnisse zu gewährleisten). Dieser Parameter wird zur Steuerung von Zufallsprozessen innerhalb des Modells verwendet. Wenn Sie ihn auf einen festen Wert (z. B. 1) setzen, sind die Ergebnisse bei jeder Ausführung des Modells gleich. Dies ist für die Reproduzierbarkeit der Ergebnisse nützlich.
- verbose (ermöglicht die Ausgabe von Informationen über den Modellbildungsprozess). Beim Training eines Modells kann es nützlich sein, Informationen über den Prozess zu sehen. Mit dem Parameter „verbose“ können Sie den Detaillierungsgrad dieser Informationen steuern. Je höher der Wert (z. B. 2), desto mehr Informationen werden während des Trainingsprozesses ausgegeben.
Nach der Erstellung der Pipeline verwenden wir die Fit-Methode, um sie anhand der Trainingsdaten zu trainieren. Dann machen wir mit der Methode „predict“ Vorhersagen für die Testdaten. Abschließend bewerten wir die Qualität des Modells anhand des R2-Maßes, das die Anpassung des Modells an die Daten misst.
Die Pipeline wird trainiert und dann anhand der R2-Metrik bewertet. Wir verwenden Normalisierung, entfernen Ausreißer aus den Daten und erstellen polynomiale Merkmale. Dies sind die einfachsten Methoden der Datenvorverarbeitung. In zukünftigen Artikeln werden wir uns ansehen, wie Sie Ihre eigene Vorverarbeitungsfunktion mit Function Transformer erstellen können.
Exportieren des Modells nach ONNX, Schreiben der Exportfunktion
Nach dem Training der Pipeline speichern wir sie im joblib-Format, das wir mit Hilfe der Bibliothek skl2onnx im ONNX-Format speichern.
# Save the pipeline
joblib.dump(pipeline, 'rf_pipeline.joblib')
# Convert pipeline to ONNX
onnx_model = convert_sklearn(pipeline, initial_types=initial_type)
# Save the model in ONNX format
model_onnx_path = "rf_pipeline.onnx"
onnx.save_model(onnx_model, model_onnx_path)
# Save the model in ONNX format
model_onnx_path = "rf_pipeline.onnx"
onnx.save_model(onnx_model, model_onnx_path)
# Connect Google Drive (if you work in Colab and this is necessary)
from google.colab import drive
drive.mount('/content/drive')
# Specify the path to Google Drive where you want to move the model
drive_path = '/content/drive/My Drive/' # Make sure the path is correct
rf_pipeline_onnx_drive_path = os.path.join(drive_path, 'rf_pipeline.onnx')
# Move ONNX model to Google Drive
shutil.move(model_onnx_path, rf_pipeline_onnx_drive_path)
print('The rf_pipeline model is saved in the ONNX format on Google Drive:', rf_pipeline_onnx_drive_path)
So haben wir das Modell trainiert und in ONNX gespeichert. Das ist es, was wir nach Abschluss des Trainings sehen werden:
Das Modell wird im ONNX-Format im Basisverzeichnis von Google Drive gespeichert. ONNX kann als eine Art „Diskette“ für maschinelle Lernmodelle betrachtet werden. In diesem Format können Sie trainierte Modelle speichern und für die Verwendung in verschiedenen Anwendungen konvertieren. Dies ist vergleichbar mit dem Speichern von Dateien auf einem Flash-Laufwerk, die dann auf anderen Geräten gelesen werden können. In unserem Fall wird das ONNX-Modell in der MetaTrader 5-Umgebung zur Vorhersage von Finanzmarktpreisen verwendet. Die ONNX-„Diskette“ selbst kann in einer Anwendung eines Drittanbieters gelesen werden, zum Beispiel in MetaTrader 5. Das werden wir jetzt tun.
Überprüfen des Modells im MetaTrader 5 Tester
Wir haben das ONNX-Modell zuvor auf Google Drive gespeichert. Laden wir sie nun von dort herunter. Um dieses Modell in MetaTrader 5 zu verwenden, müssen wir einen Expert Advisor erstellen, der dieses Modell liest und anwendet, um Handelsentscheidungen zu treffen. Legen Sie im vorgestellten Expert Advisor-Code Handelsparameter fest, z. B. das Lot-Volumen, die Verwendung von Stop-Orders, Take-Profit- und Stop-Loss-Niveaus. Hier ist der Code des EA, der unser ONNX-Modell „lesen“ wird:
//+------------------------------------------------------------------+ //| ONNX Random Forest.mq5 | //| Copyright 2023 | //| Evgeniy Koshtenko | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Evgeniy Koshtenko" #property link "https://www.mql5.com" #property version "0.90" static vectorf ExtOutputData(1); vectorf output_data(1); #include <Trade\Trade.mqh> CTrade trade; input double InpLots = 1.0; // Lot volume to open a position input bool InpUseStops = true; // Trade with stop orders input int InpTakeProfit = 500; // Take Profit level input int InpStopLoss = 500; // Stop Loss level #resource "Python/rf_pipeline.onnx" as uchar ExtModel[] #define SAMPLE_SIZE 100 long ExtHandle=INVALID_HANDLE; int ExtPredictedClass=-1; datetime ExtNextBar=0; datetime ExtNextDay=0; CTrade ExtTrade; #define PRICE_UP 1 #define PRICE_SAME 2 #define PRICE_DOWN 0 // Function for closing all positions void CloseAll(int type=-1) { for(int i=PositionsTotal()-1; i>=0; i--) { if(PositionSelectByTicket(PositionGetTicket(i))) { if(PositionGetInteger(POSITION_TYPE)==type || type==-1) { trade.PositionClose(PositionGetTicket(i)); } } } } // Expert Advisor initialization int OnInit() { if(_Symbol!="EURUSD" || _Period!=PERIOD_H1) { Print("The model should work with EURUSD, H1"); return(INIT_FAILED); } ExtHandle=OnnxCreateFromBuffer(ExtModel,ONNX_DEFAULT); if(ExtHandle==INVALID_HANDLE) { Print("Error creating model OnnxCreateFromBuffer ",GetLastError()); return(INIT_FAILED); } const long input_shape[] = {1,100}; if(!OnnxSetInputShape(ExtHandle,ONNX_DEFAULT,input_shape)) { Print("Error setting the input shape OnnxSetInputShape ",GetLastError()); return(INIT_FAILED); } const long output_shape[] = {1,1}; if(!OnnxSetOutputShape(ExtHandle,0,output_shape)) { Print("Error setting the output shape OnnxSetOutputShape ",GetLastError()); return(INIT_FAILED); } return(INIT_SUCCEEDED); } // Expert Advisor deinitialization void OnDeinit(const int reason) { if(ExtHandle!=INVALID_HANDLE) { OnnxRelease(ExtHandle); ExtHandle=INVALID_HANDLE; } } // Process the tick function void OnTick() { if(TimeCurrent()<ExtNextBar) return; ExtNextBar=TimeCurrent(); ExtNextBar-=ExtNextBar%PeriodSeconds(); ExtNextBar+=PeriodSeconds(); PredictPrice(); if(ExtPredictedClass>=0) if(PositionSelect(_Symbol)) CheckForClose(); else CheckForOpen(); } // Check position opening conditions void CheckForOpen(void) { ENUM_ORDER_TYPE signal=WRONG_VALUE; if(ExtPredictedClass==PRICE_DOWN) signal=ORDER_TYPE_SELL; else { if(ExtPredictedClass==PRICE_UP) signal=ORDER_TYPE_BUY; } if(signal!=WRONG_VALUE && TerminalInfoInteger(TERMINAL_TRADE_ALLOWED)) { double price,sl=0,tp=0; double bid=SymbolInfoDouble(_Symbol,SYMBOL_BID); double ask=SymbolInfoDouble(_Symbol,SYMBOL_ASK); if(signal==ORDER_TYPE_SELL) { price=bid; if(InpUseStops) { sl=NormalizeDouble(bid+InpStopLoss*_Point,_Digits); tp=NormalizeDouble(ask-InpTakeProfit*_Point,_Digits); } } else { price=ask; if(InpUseStops) { sl=NormalizeDouble(ask-InpStopLoss*_Point,_Digits); tp=NormalizeDouble(bid+InpTakeProfit*_Point,_Digits); } } ExtTrade.PositionOpen(_Symbol,signal,InpLots,price,sl,tp); } } // Check position closing conditions void CheckForClose(void) { if(InpUseStops) return; bool tsignal=false; long type=PositionGetInteger(POSITION_TYPE); if(type==POSITION_TYPE_BUY && ExtPredictedClass==PRICE_DOWN) tsignal=true; if(type==POSITION_TYPE_SELL && ExtPredictedClass==PRICE_UP) tsignal=true; if(tsignal && TerminalInfoInteger(TERMINAL_TRADE_ALLOWED)) { ExtTrade.PositionClose(_Symbol,3); CheckForOpen(); } } // Function to get the current spread double GetSpreadInPips(string symbol) { double spreadPoints = SymbolInfoInteger(symbol, SYMBOL_SPREAD); double spreadPips = spreadPoints * _Point / _Digits; return spreadPips; } // Function to predict prices void PredictPrice() { static vectorf output_data(1); static vectorf x_norm(SAMPLE_SIZE); double spread = GetSpreadInPips(_Symbol); if (!x_norm.CopyRates(_Symbol, _Period, COPY_RATES_CLOSE, 1, SAMPLE_SIZE)) { ExtPredictedClass = -1; return; } if (!OnnxRun(ExtHandle, ONNX_NO_CONVERSION, x_norm, output_data)) { ExtPredictedClass = -1; return; } float predicted = output_data[0]; if (spread < 0.000005 && predicted > iClose(Symbol(), PERIOD_CURRENT, 1)) { ExtPredictedClass = PRICE_UP; } else if (spread < 0.000005 && predicted < iClose(Symbol(), PERIOD_CURRENT, 1)) { ExtPredictedClass = PRICE_DOWN; } else { ExtPredictedClass = PRICE_SAME; } }
Bitte beachten Sie, dass die folgende Eingabegröße:
const long input_shape[] = {1,100};
mit der Dimension in unserem Python-Modell übereinstimmen muss:
# Set the number of time steps to your requirements n_steps = 100
Als Nächstes beginnen wir mit dem Testen des Modells in der MetaTrader 5-Umgebung. Anhand der Vorhersagen des Modells bestimmen wir die Richtung der Kursbewegungen. Wenn das Modell einen Kursanstieg vorhersagt, bereiten wir uns darauf vor, eine Long-Position (Kauf) zu eröffnen, und umgekehrt, wenn das Modell einen Kursrückgang vorhersagt, bereiten wir uns darauf vor, eine Short-Position (Verkauf) zu eröffnen. Testen wir das Modell mit einem Take-Profit von 1000 und einem Stop Loss von 500:
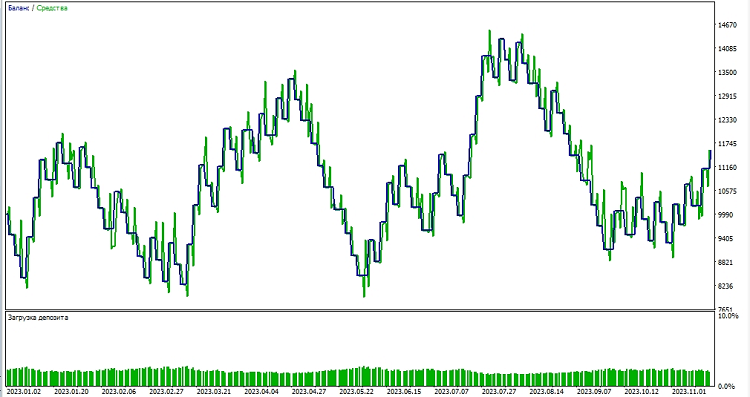
Schlussfolgerung
In diesem Artikel haben wir uns angesehen, wie man ein Random-Forest-Modell in Python erstellt und trainiert, wie man Daten direkt im Modell vorverarbeitet, wie man es in den ONNX-Standard exportiert und wie man das Modell dann im MetaTrader 5 öffnet und verwendet.
ONNX ist ein hervorragendes Modell-Import-Export-System. Es ist universell und einfach. Das Speichern eines Modells in ONNX ist viel einfacher, als es aussieht. Auch die Vorverarbeitung der Daten ist sehr einfach.
Natürlich ist unser Modell mit nur 20 Entscheidungsbäumen sehr einfach, und das Random-Forest-Modell selbst ist bereits eine recht alte Lösung. In weiteren Artikeln werden wir komplexere und modernere Modelle erstellen, die eine komplexere Datenvorverarbeitung verwenden. Ich möchte auch auf die Möglichkeit hinweisen, ein Ensemble von Modellen sofort in Form einer Sklearn-Pipeline zu erstellen, gleichzeitig mit dem Preprocessing. Dies kann unsere Möglichkeiten, auch bei Klassifizierungsproblemen, erheblich erweitern.
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/13725
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Nur der Wald wurde als einfaches Beispiel gewählt)Busting im nächsten Artikel, ich bin gerade dabei, es ein wenig zu optimieren)
Gut)
Es wäre interessant, das Thema Förderer und ihre Umwandlung in ONNX mit anschließender Verwendung in Metatrader weiter zu entwickeln. Ist es zum Beispiel möglich, der Pipeline benutzerdefinierte Transformationen hinzuzufügen, und kann das aus einer solchen Pipeline gewonnene ONNX-Modell in Metatrader geöffnet werden? Imho ist das Thema mehrere Artikel wert.
Es wäre interessant, das Thema Förderer und ihre Umwandlung in ONNX mit anschließender Verwendung in Metatrader weiter zu entwickeln. Ist es zum Beispiel möglich, der Pipeline benutzerdefinierte Transformationen hinzuzufügen, und kann das aus einer solchen Pipeline gewonnene ONNX-Modell in Metatrader geöffnet werden? Imho ist das Thema mehrere Artikel wert.