
Entwicklung eines Expertenberaters für mehrere Währungen (Teil 18): Automatisierte Gruppenauswahl unter Berücksichtigung der Vorwärtszeitraum
Einführung
In Teil 7 habe ich die Auswahl einer Gruppe einzelner Handelsstrategien mit dem Ziel betrachtet, die Ergebnisse zu verbessern, wenn sie zusammenarbeiten. Ich habe zwei Ansätze für die Auswahl verwendet. Im ersten Ansatz erfolgte die Gruppenauswahl anhand der Optimierungsergebnisse, die über das gesamte Optimierungszeitintervall erzielt wurden. Ich habe versucht, die einzelnen Instanzen in die Gruppe aufzunehmen, die im Optimierungsintervall die besten Ergebnisse zeigten. Im zweiten Ansatz wurde ein kleines Stück aus dem Optimierungszeitintervall zugewiesen, auf dem die Optimierung einzelner Instanzen nicht durchgeführt wurde. Das zugewiesene Zeitintervall wurde dann für die Auswahl der Gruppen unter verwendet: Ich habe versucht, diejenigen Einzelbeispiele in die Gruppe aufzunehmen, die im Optimierungsintervall gute (aber nicht die besten) Ergebnisse zeigten und gleichzeitig im ausgewählten Teil des Zeitintervalls annähernd die gleichen Ergebnisse zeigten.
Die Ergebnisse waren wie folgt:
- Ich konnte keinen eindeutigen Vorteil der ersten Methode gegenüber der zweiten Methode erkennen. Dies könnte auf den kurzen historischen Zeitraum zurückzuführen sein, in dem wir die Ergebnisse der beiden Methoden verglichen haben. Drei Monate reichen nicht aus, um eine Strategie zu bewerten, die lange Zeiträume mit flachen Bewegungen aufweisen kann.
- Die zweite Methode hat gezeigt, dass für dem ausgewählten Teil des Zeitintervalls die Ergebnisse besser sind, wenn wir die Auswahl in eine Gruppe gemäß dem im Artikel beschriebenen Algorithmus zum Auffinden einzelner Instanzen von Handelsstrategien mit ähnlichen Ergebnissen anwenden. Wenn wir sie einfach auf der Grundlage der bestmöglichen Ergebnisse über das Optimierungsintervall auswählen (wie bei der ersten Methode, aber nur über ein kürzeres Intervall), dann waren die Ergebnisse der ausgewählten Gruppe deutlich schlechter.
- Es ist möglich, beide Methoden zu kombinieren, d. h. zwei auf unterschiedliche Weise ausgewählte Gruppen zu bilden und die beiden daraus resultierenden Gruppen zu einer Gruppe zusammenzufassen.
In Teil 13 haben wir die zweite Phase der Optimierung automatisiert. In diesem Rahmen wurden einzelne Exemplare der in der ersten Phase ermittelten Handelsstrategien zu einer Gruppe zusammengefasst. Wir haben eine einfache Suche mit dem genetischen Algorithmus des Standardoptimierers im Strategietester durchgeführt. Es wurde kein Pre-Clustering einzelner Instanzen (in Teil 6 besprochen) durchgeführt. So haben wir die Auswahl der Gruppen auf die erste Weise automatisiert. Damals war es nicht möglich, die Auswahl der Gruppen nach dem zweiten Ansatz durchzuführen, aber jetzt ist es an der Zeit, auf dieses Thema zurückzukommen. In diesem Artikel werden wir versuchen, die Fähigkeit zur automatischen Auswahl einzelner Instanzen von Handelsstrategien in Gruppen zu erreichen, unter Berücksichtigung ihres Verhaltens in der Vorwärtszeitraum.
Der Weg ist vorgezeichnet
Wie immer sollten wir uns zunächst ansehen, was wir bereits haben und was noch fehlt, um das Problem zu lösen. Wir können die Aufgabe, eine Handelsstrategie zu optimieren, über ein beliebiges Zeitintervall stellen. Die Worte „eine Aufgabe einstellen“ sind wörtlich zu nehmen: Dazu erstellen wir die notwendigen Einträge in der Tabelle „tasks“ unserer Datenbank. Dementsprechend können wir zunächst eine Optimierung für ein Zeitintervall (z. B. von 2018 bis einschließlich 2022) und dann für ein anderes Intervall (z. B. für 2023) durchführen.
Aber mit diesem Ansatz können wir die erzielten Ergebnisse nicht in der gewünschten Weise nutzen. In jedem der beiden Zeitintervalle wird die Optimierung unabhängig voneinander durchgeführt, sodass es nichts zu vergleichen gibt: Die Durchläufe der zweiten Optimierung wiederholen nicht die Durchläufe der ersten Optimierung in Bezug auf die Werte der Eingangsparameter. Das Gleiche gilt für die von uns verwendete genetische Optimierung. Es ist klar, dass dies für die vollständige Optimierung nicht gilt, aber wir haben sie nie verwendet und werden sie aufgrund der großen Anzahl von Kombinationen optimierter Parameter höchstwahrscheinlich auch in Zukunft nicht verwenden.
Daher ist es notwendig, den Start der Optimierung mit der angegebenen Vorwärtszeitraum zu nutzen. In diesem Fall verwendet der Prüfer für die Vorwärtszeitraum die gleichen Kombinationen von Eingängen wie für die Hauptlaufzeit. Wir haben jedoch noch nicht versucht, die automatische Optimierung mit einem Vorwärtszeitraum durchzuführen, und wir wissen nicht, wie diese Ergebnisse in unsere Datenbank gelangen werden. Werden wir dann in der Lage sein, zwischen Läufen in dem Hauptzeitraum und Läufen in dem Vorwärtszeitraum zu unterscheiden? Wir sollten das überprüfen.
Sobald wir sicher sind, dass die Datenbank alle notwendigen Informationen über die Durchläufe sowohl für den Haupt- als auch für den Vorwärtszeitraum enthält, können wir zum nächsten Schritt übergehen. In Teil 7, nachdem ich diese Ergebnisse erhalten hatte, führte ich die Analyse und Auswahl manuell mit Excel durch. Im Zusammenhang mit der Automatisierung erscheint ihr Einsatz jedoch ineffizient. Wir versuchen, jegliche manuelle Manipulation der Daten bei der Erstellung des endgültigen EA zu vermeiden. Glücklicherweise können alle Aktionen, die wir in Excel durchgeführt haben (Neuberechnung einiger Ergebnisse, Berechnung des Verhältnisses der Bestehensquoten für verschiedene Testperioden, Ermittlung der Endpunktzahl für jede Strategiegruppe und Sortierung danach), in einem MQL5-Programm durch SQL-Abfragen an unsere Datenbank oder durch Ausführen eines Python-Skripts durchgeführt werden.
Nachdem wir nach der endgültigen Bewertung sortiert haben, nehmen wir nur die oberste Gruppe in die endgültige EA auf. Wir werden ähnliche Aktionen für alle Kombinationen von ausgewählten Symbolen und Zeitrahmen durchführen. Nach der Normalisierung der Gesamtgruppe, einschließlich der besten Gruppen für alle Symbol-Zeitrahmen-Paare, ist der endgültige EA fertig.
Fangen wir mit der Implementierung an, aber zuerst müssen wir den entdeckten Fehler beheben.
Behebung eines Speicherfehlers
Als ich den EA zur Automatisierung der ersten Phase (Optimierung einzelner Instanzen von Handelsstrategien) entwickelt habe, habe ich nur eine Datenbank verwendet. Es stellte sich also nicht die Frage, aus welcher Datenbank wir Daten erhalten oder in welcher wir Daten speichern sollten. In der zweiten Phase der Optimierung wurde eine neue Hilfsdatenbank hinzugefügt, die den minimal erforderlichen Auszug aus der Hauptdatenbank enthielt. Diese gekürzte Version der Datenbank wurde im Rahmen der zweiten Optimierungsphase an die Testagenten verschickt.
Aber aufgrund des Ansatzes, den ich bereits bei der Implementierung einer statischen Klasse für die Arbeit mit der Datenbank gewählt hatte, musste ich eine etwas unbequeme Lösung verwenden, die es erlaubt, den Datenbanknamen bei Bedarf zu ändern. Nach der Änderung des Namens wurde bei allen nachfolgenden Aufrufen der Datenbankverbindungsmethode der neue Name verwendet. Hier trat der Fehler bei der Addition der Durchgangsergebnisse der zweiten und dritten Phase auf. Der Grund dafür war, dass nicht überall, wo es nötig war, auf die Hauptbasis zurückgegriffen werden konnte.
Um dies zu beheben, habe ich dem EA jeder Phase und dem EA der automatischen Projektoptimierung einen zusätzlichen Eingang hinzugefügt. Diese Eingabe gibt den Namen der Hauptdatenbank an. Abgesehen von der Behebung des Fehlers ist dies auch nützlich, weil wir die in verschiedenen Artikeln verwendeten Datenbanken besser trennen können. In diesem Teil wurde zum Beispiel eine neue Hauptdatenbank verwendet, da wir beschlossen haben, die Zusammensetzung der Optimierungsaufgaben zu reduzieren, aber die bestehende Datenbank nicht löschen wollten:
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ sinput string fileName_ = "database683.sqlite"; // - File with the main database
In derFunktion OnInit() des EA SimpleVolumesStage2.mq5 der zweiten Phase wurde innerhalb des Aufrufs der Funktion LoadParams() eine Verbindung zu einer Hilfsdatenbank hergestellt, da die Daten über die Eingaben einzelner Instanzen von Handelsstrategien für den Zusammenschluss zu einer Gruppe daraus entnommen werden sollten. Nachdem der Durchlauf abgeschlossen war, wurde die Funktion OnTester() aufgerufen. In der Funktion musste die Speicherung der Ergebnisse der Gruppenpassage in der Hauptdatenbank erfolgen. Da es jedoch keinen Wechsel zurück zur Hauptdatenbank gab, wurde versucht, die vollständigen Ergebnisse des Durchlaufs (48 Spalten) in eine Tabelle in der Hilfsdatenbank (2 Spalten) einzufügen.
Also haben wir den fehlenden Schalter in der Funktion OnInit() der zweiten Phase des EA SimpleVolumesStage2.mq5 zur Hauptdatenbank hinzugefügt:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { ... // Load strategy parameter sets string strategiesParams = LoadParams(indexes); // Connect to the main database DB::Connect(fileName_); DB::Close(); ... // Create an EA handling virtual positions expert = NEW(expertParams); if(!expert) return INIT_FAILED; return(INIT_SUCCEEDED); }
In den EA der ersten und dritten Optimierungsphase, die keine Hilfsdatenbank verwenden, fügten wir dem ersten Aufruf der Datenbankverbindungsmethode den Datenbanknamen aus der neuen Eingabe des EA hinzu:
DB::Connect(fileName_)
Eine andere Art von Fehler trat auf, als ich nach der Fertigstellung einen der Läufe separat ausführen wollte. Der Durchlauf wurde normal ausgeführt, aber die Ergebnisse wurden nicht in die Datenbank eingegeben. Der Grund dafür war, dass bei einem solchen Start die Aufgabenkennung gleich 0 blieb, während in der Datenbank die Tabelle passes nur eine Zeichenkette mit der Kennung einer bestehenden Aufgabe in der Tabelle tasks akzeptiert.
Dies könnte entweder dadurch behoben werden, dass die Task-ID den Wert aus den EA-Eingaben übernimmt (aus denen sie während der Optimierung entnommen wird), oder durch Hinzufügen einer Dummy-Task mit der ID 0 zur Datenbank. Ich habe mich für die zweite Option entschieden, damit meine einzelnen manuell gestarteten Durchläufe nicht als Durchläufe im Rahmen einer bestimmten Optimierungsaufgabe gezählt werden. Für die hinzugefügte Dummy-Aufgabe musste eine beliebige ID eines bestehenden Prozesses angegeben werden, um die Fremdschlüssel-Beschränkungen nicht zu verletzen, und der Status „Done“, damit diese Aufgabe während der automatischen Optimierung nicht gestartet wird.
Nachdem wir diese Korrekturen vorgenommen haben, kehren wir zu unserer Hauptaufgabe zurück.
Vorbereiten des Codes und der Datenbank
Wir nehmen eine Kopie der bestehenden Datenbank und löschen die Daten über Durchgänge, Aufgaben und Aufträge. Dann ändern wir die Daten der ersten Phase, indem wir das Startdatum des Vorwärtszeitraums hinzufügen. Wir können die zweite Phase aus der Phasentabelle stages entfernen. Wir erstellen einen Eintrag in der Tabelle jobs für die erste Phase, wobei wir das Symbol und den Zeitraum (EURGBP H1) sowie die Parameter des Strategietesters angeben. Für die Optimierung verwenden wir nur einem einzigen Parameter, damit die Anzahl der Durchläufe gering ist. So können wir schneller Ergebnisse erzielen. Dem erstellten Auftrag fügen wir in der Aufgabentabelle tasks eine Aufgabe mit einem komplexen Optimierungskriterium hinzu.
Wir starten die automatische Projektoptimierung EA, indem wir die erstellte Datenbank im Eingabeparameter angeben. Nach dem ersten Start stellte sich heraus, dass der EA für die automatische Optimierung verbessert werden musste, da er von der Datenbank keine Informationen über die Notwendigkeit der Verwendung des Vorwärtszeitraums erhielt. Nach den Ergänzungen sah der Code für die Funktion zum Abrufen der nächsten Optimierungsaufgabe aus der Datenbank wie folgt aus (die hinzugefügten Zeichenfolgen sind farblich hervorgehoben):
//+------------------------------------------------------------------+ //| Get the next optimization task from the queue | //+------------------------------------------------------------------+ ulong GetNextTask(string &setting) { // Result ulong res = 0; // Request to get the next optimization task from the queue string query = "SELECT s.expert," " s.optimization," " s.from_date," " s.to_date," " s.forward_mode," " s.forward_date," " j.symbol," " j.period," " j.tester_inputs," " t.id_task," " t.optimization_criterion" " FROM tasks t" " JOIN" " jobs j ON t.id_job = j.id_job" " JOIN" " stages s ON j.id_stage = s.id_stage" " WHERE t.status IN ('Queued', 'Processing')" " ORDER BY s.id_stage, j.id_job, t.status LIMIT 1;"; // Open the database if(DB::Connect()) { // Execute the request int request = DatabasePrepare(DB::Id(), query); // If there is no error if(request != INVALID_HANDLE) { // Data structure for reading a single string of a query result struct Row { string expert; int optimization; string from_date; string to_date; int forward_mode; string forward_date; string symbol; string period; string tester_inputs; ulong id_task; int optimization_criterion; } row; // Read data from the first result string if(DatabaseReadBind(request, row)) { setting = StringFormat( "[Tester]\r\n" "Expert=%s\r\n" "Symbol=%s\r\n" "Period=%s\r\n" "Optimization=%d\r\n" "Model=1\r\n" "FromDate=%s\r\n" "ToDate=%s\r\n" "ForwardMode=%d\r\n" "ForwardDate=%s\r\n" "Deposit=10000\r\n" "Currency=USD\r\n" "ProfitInPips=0\r\n" "Leverage=200\r\n" "ExecutionMode=0\r\n" "OptimizationCriterion=%d\r\n" "[TesterInputs]\r\n" "idTask_=%d\r\n" "fileName_=%s\r\n" "%s\r\n", GetProgramPath(row.expert), row.symbol, row.period, row.optimization, row.from_date, row.to_date, row.forward_mode, row.forward_date, row.optimization_criterion, row.id_task, fileName_, row.tester_inputs ); res = row.id_task; } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: Reading row for request \n%s\nfailed with code %d", query, GetLastError()); } } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } // Close the database DB::Close(); } return res; }
Wir haben auch eine Funktion hinzugefügt, die den Pfad zur Datei des optimierten EAs aus dem aktuellen Ordner relativ zum Stammordner der Terminal EAs ermittelt:
//+------------------------------------------------------------------+ //| Getting the path to the file of the optimized EA from the current| //| folders relative to the root folder of terminal EAs | //+------------------------------------------------------------------+ string GetProgramPath(string name) { string path = MQLInfoString(MQL_PROGRAM_PATH); string programName = MQLInfoString(MQL_PROGRAM_NAME) + ".ex5"; string terminalPath = TerminalInfoString(TERMINAL_DATA_PATH) + "\\MQL5\\Experts\\"; path = StringSubstr(path, StringLen(terminalPath), StringLen(path) - (StringLen(terminalPath) + StringLen(programName))); return path + name; }
Dadurch konnte die Datenbank in der Stages-Tabelle nur den Dateinamen des optimierten EAs angeben, ohne die Namen der Ordner aufzulisten, in denen er relativ zum EA-Stammordner \MQL5\Experts\ verschachtelt ist.
Die folgenden Durchläufe der automatischen Projektoptimierung EA zeigten, dass die Ergebnisse des Vorwärtszeitraums erfolgreich zusammen mit den Ergebnissen der regulären Übergänge in die Übergangstabelle aufgenommen wurden. Nach Abschluss der Etappe ist es jedoch recht schwierig zu erkennen, welche Durchläufe zu welcher Periode (Haupt- oder Vorlauf) gehören. Natürlich kann man sich die Tatsache zunutze machen, dass die Durchläufe des Vorwärtszeitraums immer nach den regulären Durchgängen kommen, aber das funktioniert nicht mehr, wenn die Ergebnisse mehrerer Optimierungsprobleme mit einer Vorwärtszeitraum in der Tabelle passes erscheinen. Fügen wir also die Spalte is_forward zur Tabelle passes hinzu, um zwischen regulären Durchläufe und Vorwärtsdurchläufe zu unterscheiden. Wir werden auch die Spalte is_optimzation hinzufügen, um die Unterscheidung zwischen regulären Durchläufen und Durchläufen, die im Rahmen einer Optimierung durchgeführt werden, zu erleichtern.
Dabei wurde eine Ungenauigkeit entdeckt: Bei der Erstellung einer SQL-Abfragezeichenfolge zum Einfügen von Daten mit den Ergebnissen eines Durchlaufs wurde die Durchlaufnummer als vorzeichenbehaftete Ganzzahl mit dem %d-Spezifikator ersetzt. Die Durchlaufnummer ist jedoch eine Ganzzahl vom Typ long ohne Vorzeichen. Um ihren Wert korrekt in die Zeichenkette einzufügen, sollten wir den %I64u-Spezifikator verwenden.
Fügen wir den Wert der entsprechenden Funktion zur Bestimmung des Flags des Vorwärtszeitraums in den Code für die Generierung der SQL-Abfrage zum Einfügen der Passdaten ein:
string CTesterHandler::GetInsertQuery(string values, string inputs, ulong pass) { return StringFormat("INSERT INTO passes " "VALUES (NULL, %d, %I64u, %d, %s,\n'%s',\n'%s') RETURNING rowid;", s_idTask, pass, (int) MQLInfoInteger(MQL_FORWARD), values, inputs, TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS)); }
Es stellte sich jedoch heraus, dass dies nicht wie erwartet funktionieren würde. Der Punkt ist, dass diese Funktion von dem im Hauptterminal gestarteten EA im Datenerfassungsmodus aufgerufen wird. Daher gibt das Ergebnis des Aufrufs MQLInfoInteger(MQL_FORWARD) immer false zurück.
Daher sollte der Indikator für die vorwärts gerichtete Periode im Code, der auf den Test-Agenten läuft, und nicht im Hauptterminal auf dem Chart, d. h. im Ereignis-Handler für den Abschluss des Testdurchlaufs, ermittelt werden. Außerdem wurde in der Nähe ein Optimierungsschild angebracht.
//+------------------------------------------------------------------+ //| Handling completion of tester pass for agent | //+------------------------------------------------------------------+ void CTesterHandler::Tester(double custom, // Custom criteria string params // Description of EA parameters in the current pass ) { ... // Generate a string with pass data data = StringFormat("%d, %d, %s,'%s'", MQLInfoInteger(MQL_OPTIMIZATION), MQLInfoInteger(MQL_FORWARD), data, params); ... }
Nachdem wir diese Änderungen vorgenommen und die automatische Optimierung EA neu gestartet hatten, sahen wir endlich das gewünschte Bild in der Tabelle der Durchläufe:
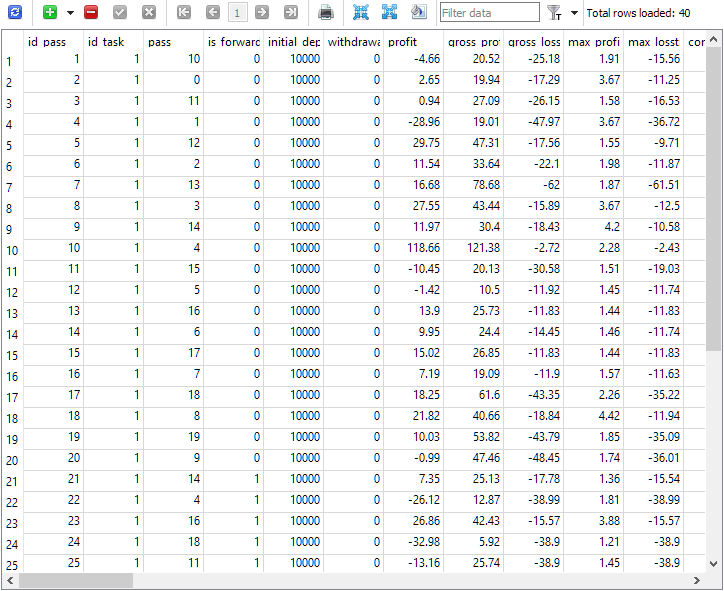
Abb. 1. Die Tabelle passes nach Beendigung der Optimierungsaufgabe in einer Vorwärtszeitraum
Wie zu sehen ist, wurden nur 40 Durchläufe im Rahmen der Optimierungsaufgabe mit id_task = 1. Zwanzig davon waren normal (die ersten 20 Strings mit is_forward = 0), während die restlichen 20 Durchläufe die Vorwärtszeitraum betreffen (is_forward = 1). Die Zahlen für das Bestehen der Prüfung in der Spalte pass nehmen Werte von 1 bis 20 an und treten jeweils genau zweimal auf (einmal für den Hauptzeitraum, das zweite Mal für den Vorwärtszeitraum).
Vorbereitungen für die Einführung der vollständigen Optimierung
Nachdem wir uns vergewissert haben, dass die Ergebnisse der Vorbeifahrten korrekt in die Datenbank eingegeben wurden, werden wir einen Test der automatischen Optimierung durchführen, der den realen Bedingungen näher kommt. Zu diesem Zweck werden wir der bereinigten Datenbank zwei Phasen hinzufügen. Die erste optimiert eine einzelne Instanz der Handelsstrategie, aber nur für ein Symbol und einen Zeitraum (EURGBP H1) über den Zeitraum von 2018 bis 2023. Die Vorwärtszeitraum wird in diesem Stadium nicht genutzt. In der zweiten Phase wird die in der ersten Phase gewonnene Gruppe von guten Einzelinstanzen optimiert. Jetzt wird der Vorwärtszeitraum bereits genutzt: Das gesamte Jahr 2023 ist dafür vorgesehen.

Abb. 2. Die Tabelle Stages mit zwei Phasen
Wir legen für jede Phase in der Tabelle jobs Jobs an, die innerhalb dieser Phase ausgeführt werden sollen. In dieser Tabelle sind neben dem Symbol und der Periode auch die Eingaben für die optimierten EAs mit Bereichen und Schrittweiten angegeben.
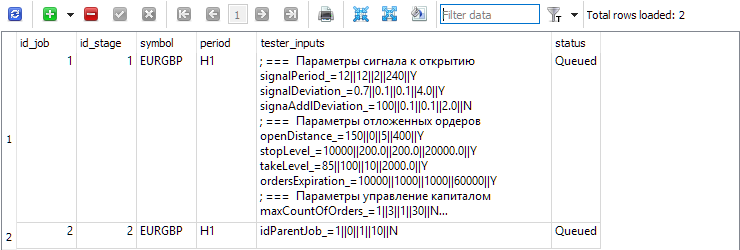
Abb. 3. Die Tabelle Jobs mit zwei Aufträgen für die erste bzw. zweite Phase
Zuerst (id_job = 1) erstellen wir mehrere Optimierungsprobleme, die sich durch den Wert des Optimierungskriteriums (optimization_criterion = 0 ... 7) unterscheiden. Wir gehen alle Kriterien der Reihe nach durch und verwenden das komplexe Kriterium zweimal: am Anfang und am Ende des ersten Auftrags (optimization_criterion = 7). Für die Aufgabe, die im Rahmen des zweiten Auftrags (id_job = 2) ausgeführt wird, wird ein nutzerdefiniertes Optimierungskriterium verwendet (optimization_criterion = 6).
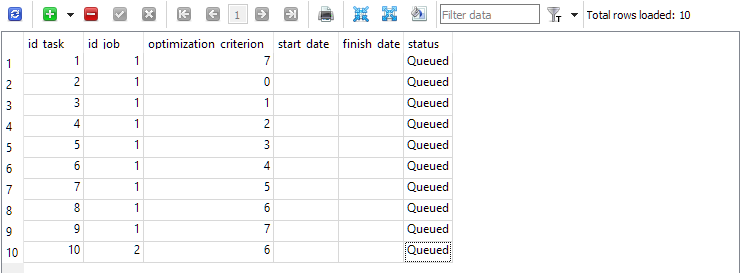
Abb. 4. Die Tabelle tasks mit den Aufgaben für den ersten und zweiten Auftrag
Wir starten den automatischen Optimierungs-EA auf einem beliebigen Terminal-Chart und warten wir, bis alle zugewiesenen Aufgaben erledigt sind. Mit den vorhandenen Agenten dauerte der Vorgang insgesamt etwa 4 Stunden.
Vorläufige Analyse der Ergebnisse
Bei der abgeschlossenen automatischen Optimierung gab es nur eine Optimierungsaufgabe, die eine Vorwärtszeitraum verwendete. Das Optimierungskriterium dafür war unser eigenes Kriterium, das den standardisierten durchschnittlichen Jahresgewinn für einen bestimmten Durchgang berechnet. Schauen wir uns die Punktwolke mit den Werten dieses Kriteriums für den Hauptzeitraum an.
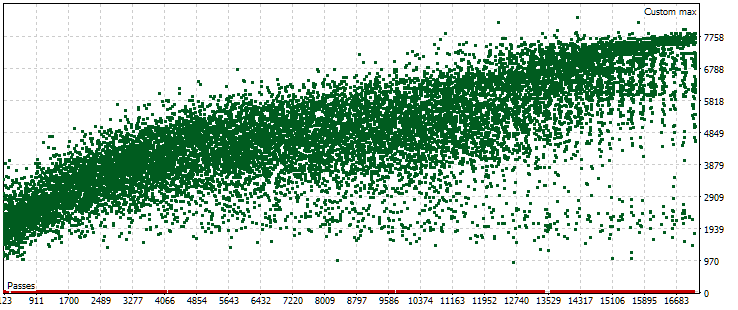
Abb. 5. Punktwolke mit den Werten des normalisierten durchschnittlichen Jahresgewinns für verschiedene Durchgänge im Hauptzeitraum
Die Grafik zeigt, dass der Wert unseres Kriteriums zwischen 1000 und 8000 USD liegt. Die roten Punkte, die 0 entsprechen, entstehen, weil einige Kombinationen einzelner Instanzindizes in den Eingabeparametern zu duplizierten Werten führen. Solche Eingaben werden als ungültige Strategiegruppen betrachtet, und es werden keine Ergebnisse aus diesen Durchgängen erzielt. Es ist ein allgemeiner Trend zu einem Anstieg des normalisierten durchschnittlichen Jahresgewinns in späteren Durchgängen erkennbar. Im Durchschnitt sind die besten Ergebnisse etwa doppelt so hoch wie die Ergebnisse der ersten Durchgänge, bei denen die Parameter fast zufällig gewählt werden.
Betrachten wir nun die Punktwolke mit den Ergebnissen der Pässe in der Vorwärtszeitraum. Es wird weniger davon geben (etwa 13.000 statt 17.000), da die Kombinationen von Parametern in der Hauptphase eliminiert und als falsch erkannt werden.
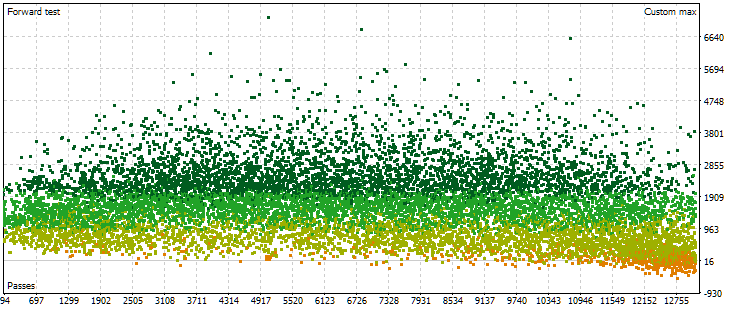
Abb. 6. Punktwolke mit den Werten des normalisierten durchschnittlichen Jahresgewinns für verschiedene Durchgänge im Vorwärtszeitraum
Hier ist das Bild der Punktelage schon anders. Es gibt keinen signifikanten Anstieg der Ergebnisse mit zunehmender Durchlaufzahl. Im Gegenteil: Mit zunehmender Anzahl der Durchläufe erreichen die Ergebnisse zunächst höhere Werte als zu Beginn, und dann kehrt sich der Trend um. Mit einer weiteren Erhöhung der Passzahl beginnen die Ergebnisse im Durchschnitt zu sinken, und die Abnahmerate nimmt zu, je mehr man sich dem rechten Rand der Zahlen nähert.
Wie sich jedoch herausstellt, wird dieses Bild nicht immer der Fall sein. Bei anderen Einstellungen der Parameterbereiche, die während der Optimierung iteriert werden, können die Punktwolken für die Durchgänge in der Haupt- und Vorwärtszeitraum wie folgt aussehen:
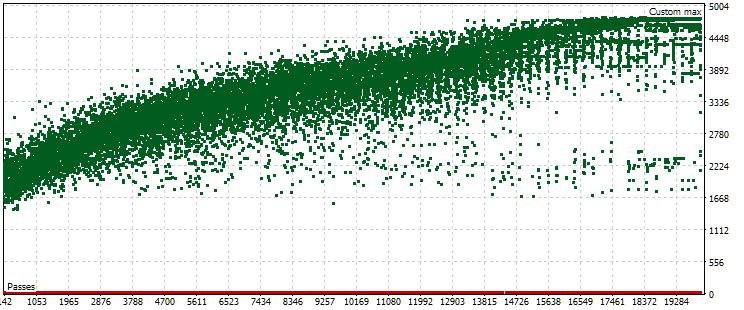
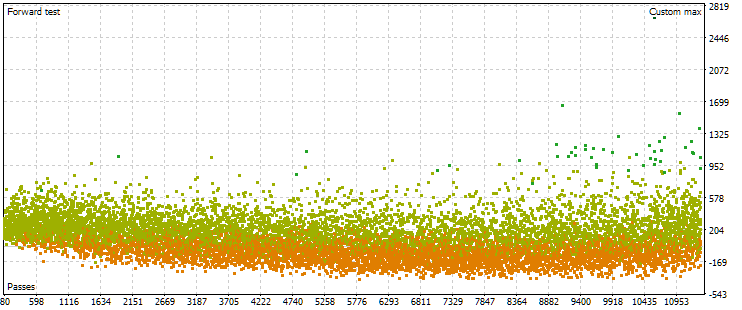
Abb. 7. Punktwolke mit den Werten des normierten durchschnittlichen Jahresgewinns für die Haupt- und Vorwärtszeitraum im Falle anderer Optimierungseinstellungen
Wie wir sehen, ist das Bild im Hauptzeitraum in etwa dasselbe, nur der Kriterienbereich ist jetzt etwas anders: von 1500 bis 5000 USD. In der Zukunft ist die Art der Wolke jedoch eine völlig andere. Die Maximalwerte werden nicht bei den Durchgängen erreicht, die ungefähr in der Mitte der Optimierung liegen, sondern näher am Ende. Außerdem sind die Kriteriumswerte in dem Vorwärtszeitraum im Durchschnitt etwa 10-mal kleiner als im ersten Optimierungsprozess, nämlich 3-mal.
Die Intuition legt nahe, dass man eine Gruppe auswählen sollte, deren Ergebnisse in der Haupt- und in dem Vorwärtszeitraum annähernd gleich sind, um die Stabilität der über verschiedene Perioden erzielten Ergebnisse zu erhöhen. Die erzielten Ergebnisse ließen mich jedoch stark daran zweifeln, dass wir auf diese Weise etwas Brauchbares erhalten würden. Vor allem dann, wenn sogar der Höchstwert des Kriteriums in dem Vorwärtszeitraum deutlich geringer ist als die mittelmäßigen Werte des Kriteriums in dem Hauptzeitraum. Versuchen wir es trotzdem. Suchen wir nach bedingt „engen“ Durchläufe im Haupt- und im Vorwärtszeitraum und betrachten wir deren Ergebnisse im Haupt- und im Vorwärtszeitraum sowie im Jahr 2024.
Auswahl der Durchläufe
Erinnern wir uns daran, wie wir die beste Gruppe auf der Grundlage der Ergebnisse in dem Vorwärtszeitraum in Teil 7 ausgewählt haben. Hier ist eine Zusammenfassung des Algorithmus mit kleinen Anpassungen:
- Passen wir den Wert des normalisierten durchschnittlichen Jahresgewinns für die Durchläufe in dem Vorwärtszeitraum an, indem wir für die Berechnung den maximalen Drawdown von zwei Werten nehmen: in der Haupt- und Vorwärtszeitraum. Wir erhalten den Wert von OOS_ForwardResultCorrected.
- In der kombinierten Tabelle der Optimierungsergebnisse für 2018-2022 (Hauptzeitraum) und für 2023 (Vorwärtszeitraum) berechnen wir das Verhältnis der Werte in dem Haupt- und Vorwärtszeitraum für alle Parameter.
Zum Beispiel für die Anzahl der Handelsgeschäfte: TradesRatio = OOS_Trades / IS_Trades, während für den normalisierten, durchschnittlichen Jahresgewinn: ResultRatio = OOS_ForwardResultCorrected / IS_BackResult.
Je näher diese Verhältnisse bei 1 liegen, desto identischer sind die Werte dieser Indikatoren in den beiden Zeiträumen. - Berechnen wir für alle diese Beziehungen die Summe ihrer Abweichungen von der Einheit. Dieser Wert ist unser Maß für die Differenz zwischen den Ergebnissen der einzelnen Gruppen im Haupt- und in der Vorwärtszeitraum:
SumDiff = |1 - ResultRatio| + ... + |1 - TradesRatio|. -
Vergessen wir nicht, dass der Drawdown für jeden Durchlauf in der Haupt- und der Vorwärtszeitraum unterschiedlich sein kann. Wählen wir den maximalen Drawdown aus zwei Perioden und berechnen daraus den Skalierungsfaktor für die Größe der eröffneten Positionen, um den standardisierten Drawdown von 10 % zu erreichen:
Scale = 10 / MAX(OOS_EquityDD, IS_EquityDD).
-
Jetzt wollen wir die Gruppen auswählen, in denen SumDiff nicht so häufig vorkommt wie Scale. Dazu wird der letzte Parameter berechnet:
Res = Scale / SumDiff.
-
Sortieren wir alle Gruppen nach dem im vorherigen Schritt berechneten Wert Res in absteigender Reihenfolge. In diesem Fall befinden sich die Gruppen, deren Ergebnisse in der Haupt- und in dem Vorwärtszeitraum ähnlicher waren und der Rückstand in beiden Perioden geringer war, an der Spitze der Tabelle.
Als Nächstes schlugen wir vor, die Auswahl der Gruppen mehrmals zu wiederholen und dabei zunächst diejenigen Gruppen zu entfernen, die die Anzahl der einzelnen Exemplare von Handelsstrategien enthalten, die bereits in den ausgewählten Gruppen enthalten sind. Dieser Schritt ist jedoch für das vorläufige Clustering einzelner Instanzen von Bedeutung, sodass unterschiedliche Indizes Instanzen entsprechen, die sich in ihren Ergebnissen unterscheiden. Da wir bei der automatischen Optimierung noch nicht zum Clustering gekommen sind, überspringen wir diesen Schritt.
Stattdessen können wir eine zweite Ebene der Gruppierung nach verschiedenen Zeitrahmen für jedes Symbol und eine dritte Ebene nach verschiedenen Symbolen hinzufügen.
Wir werden den vorgegebenen Algorithmus leicht abändern. Beginnen wir mit der Tatsache, dass wir im Wesentlichen verstehen wollen, wie weit zwei Ergebnismengen des Durchgangs in einem Raum mit einer Dimension gleich der Anzahl der verglichenen Ergebnisse (Merkmale) voneinander entfernt sind. Zu diesem Zweck wurde die Norm erster Ordnung mit einem Skalierungsfaktor verwendet, um den Abstand zwischen dem Punkt mit den Koordinaten der verglichenen Ergebnisse und einem festen Punkt mit Einheitskoordinaten zu ermitteln. Unter diesen Beziehungen kann es jedoch sowohl solche geben, die nahe bei 1 liegen, als auch solche, die sehr weit entfernt sind. Letzteres kann die Gesamtentfernungsschätzung unangemessen verschlechtern. Versuchen wir daher, die zuvor vorgeschlagene Option durch die Berechnung des üblichen euklidischen Abstands zwischen zwei Ergebnisvektoren zu ersetzen, für die wir zunächst eine Min-Max-Skalierung anwenden.
Am Ende werden wir eine ziemlich komplexe SQL-Abfrage schreiben müssen (obwohl es noch viel komplexere Abfragen geben kann). Schauen wir uns den Prozess der Erstellung der erforderlichen Abfrage genauer an. Wir werden mit einfachen Abfragen beginnen und sie nach und nach komplexer gestalten. Einige der Ergebnisse werden in temporären Tabellen gespeichert, die in weiteren Abfragen verwendet werden. Nach jeder Anfrage werden wir zeigen, wie die Ergebnisse aussehen.
Die Quelldaten, aus denen wir etwas herausholen müssen, befinden sich also hauptsächlich in der Tabelle der Durchläufe, passes. Vergewissern wir uns, dass sie wirklich da sind, und wählen wir sofort nur die Durchgänge aus, die im Rahmen der gewünschten Optimierungsaufgabe durchgeführt wurden. In unserem speziellen Fall hatte die Aufgabenkennung id_task, die der zweiten Optimierungsphase für EURGBP H1 entspricht, den Wert 10. Deshalb werden wir ihn im Auftragstext verwenden:
-- Request 1
SELECT *
FROM passes p0
WHERE p0.id_task = 10;
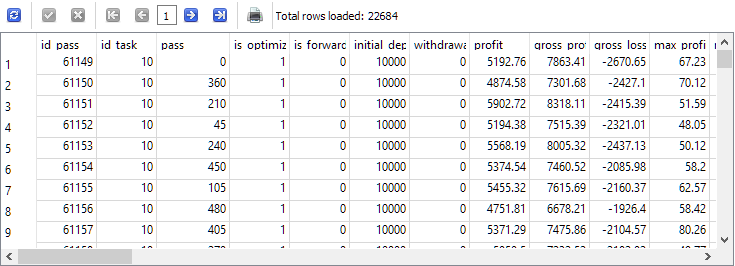
Wir können sehen, dass mehr als 22 Tausend Einträge in der Tabelle passes für diese Aufgabe mit id_task=10 vorhanden sind.
Der nächste Schritt besteht darin, die Ergebnisse aus zwei Zeilen dieses Datensatzes, die der gleichen Anzahl von Prüfdurchläufen, aber unterschiedlichen Zeiträumen entsprechen, in einem String zu kombinieren: dem Haupt- und dem Vorwärtszeitraum. Wir werden die Anzahl der angezeigten Spalten im Ergebnis vorübergehend begrenzen. Wir lassen nur diejenigen übrig, die zur Überprüfung der Gültigkeit der Auswahl von Zeichenketten verwendet werden können. Benennen wir die resultierenden Spalten nach folgender Regel: Wir fügen dem Spaltennamen das Präfix „I_“ für den Hauptzeitraum (In-Sample) und das Präfix „O_“ für die Vorwärtszeitraum (Out-Of-Sample) hinzu:
-- Request 2 SELECT p0.id_pass AS I_id_pass, p0.is_forward AS I_is_forward, p0.custom_ontester AS I_custom_ontester, p1.id_pass AS O_id_pass, p1.is_forward AS O_is_forward, p1.custom_ontester AS O_custom_ontester FROM passes p0 JOIN passes p1 ON p0.pass = p1.pass AND p0.is_forward = 0 AND p1.is_forward = 1 WHERE p0.id_task = 10 AND p1.id_task = 10
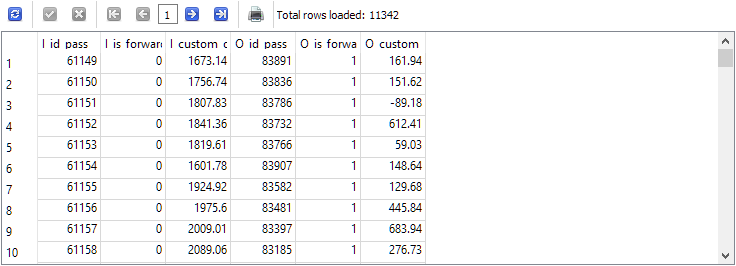
Die Anzahl der Zeilen wurde dadurch genau um die Hälfte reduziert, d. h. für jeden Durchgang in dem Hauptzeitraum in der Tabelle passes gab es genau einen Durchlauf in dem Vorwärtszeitraum und umgekehrt.
Kehren wir nun zur ersten Anforderung zurück, um eine Normalisierung durchzuführen. Wenn wir die Normalisierung erst später vornehmen, wenn wir bereits getrennte Spalten für denselben Parameter in der Haupt- und in dem Vorwärtszeitraum haben, wird es für uns schwieriger sein, den Mindest- und den Höchstwert für beide gleichzeitig zu berechnen. Wählen wir zunächst eine kleine Anzahl von Parametern aus, anhand derer wir den „Abstand“ zwischen den Ergebnissen im Haupt- und im Vorwärtszeitraum bewerten werden. Zum Beispiel üben wir zunächst die Berechnung des Abstands für drei Parameter: custom_ontester, equity_dd_relative, profit_factor.
Wir müssen die Spalten mit den Werten dieser Parameter in Spalten mit Werten zwischen 0 und 1 umwandeln. Verwenden wir die Fensterfunktionen, um die Mindest- und Höchstwerte für Spalten in einer Abfrage zu ermitteln. Für Spaltennamen mit skalierten Werten fügen wir das Präfix „s_“ an den ursprünglichen Spaltennamen an. Auf der Grundlage der von dieser Abfrage zurückgegebenen Ergebnisse erstellen und füllen wir eine neue Tabelle mit dem Befehl
CREATE TABLE ... AS SELECT ... ;
Schauen wir uns den Inhalt der erstellten und gefüllten neuen Tabelle an:
-- Request 3
DROP TABLE IF EXISTS t0;
CREATE TABLE t0 AS
SELECT id_pass,
pass,
is_forward,
custom_ontester,
(custom_ontester - MIN(custom_ontester) OVER () ) / (MAX(custom_ontester) OVER () - MIN(custom_ontester) OVER () ) AS s_custom_ontester,
equity_dd_relative,
(equity_dd_relative - MIN(equity_dd_relative) OVER () ) / (MAX(equity_dd_relative) OVER () - MIN(equity_dd_relative) OVER () ) AS s_equity_dd_relative,
profit_factor,
(profit_factor - MIN(profit_factor) OVER () ) / (MAX(profit_factor) OVER () - MIN(profit_factor) OVER () ) AS s_profit_factor
FROM passes
WHERE id_task=10;
SELECT * FROM t0;
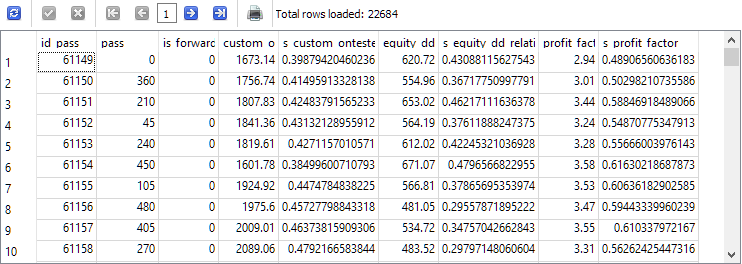
Wie Sie sehen können, erscheint neben jedem geschätzten Parameter eine neue Spalte mit dem Wert dieses Parameters, der auf den Bereich von 0 bis 1 reduziert ist.
Lassen Sie uns nun den Text der zweiten Abfrage ein wenig umgestalten, sodass er Daten aus der neuen Tabelle t0 statt aus passes nimmt und die Ergebnisse in eine neue Tabelle t1 stellt. Wir nehmen bereits skalierte Werte und runden sie der Einfachheit halber. Wir lassen nur die Zeichenketten übrig, bei denen die Werte des normalisierten Gewinns in der Haupt- und der Vorwärtszeitraum positiv sind:
-- Request 4 DROP TABLE IF EXISTS t1; CREATE TABLE t1 AS SELECT p0.id_pass AS I_id_pass, p0.is_forward AS I_is_forward, ROUND(p0.s_custom_ontester, 4) AS I_custom_ontester, ROUND(p0.s_equity_dd_relative, 4) AS I_equity_dd_relative, ROUND(p0.s_profit_factor, 4) AS I_profit_factor, p1.id_pass AS O_id_pass, p1.is_forward AS O_is_forward, ROUND(p1.s_custom_ontester, 4) AS O_custom_ontester, ROUND(p1.s_equity_dd_relative, 4) AS O_equity_dd_relative, ROUND(p1.s_profit_factor, 4) AS O_profit_factor FROM t0 p0 JOIN t0 p1 ON p0.pass = p1.pass AND p0.is_forward = 0 AND p1.is_forward = 1 AND p0.custom_ontester > 0 AND p1.custom_ontester > 0; SELECT * FROM t1;
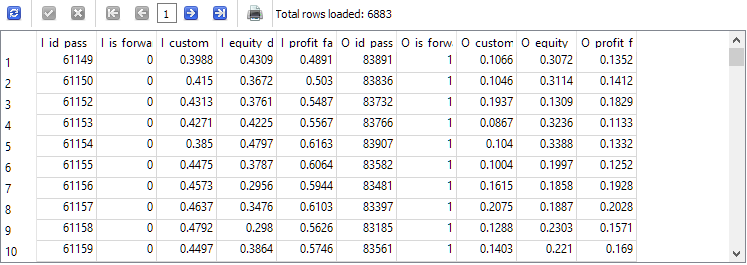
Die Anzahl der Zeilen hat sich im Vergleich zur zweiten Abfrage um etwa ein Drittel verringert, aber jetzt bleiben nur noch die Durchläufe übrig, bei denen sowohl im Haupt- als auch im Vorwärtszeitraum Gewinne erzielt haben.
Wir haben endlich den letzten Schritt in der Entwicklung der Abfrage erreicht. Es bleibt nur noch, den Abstand zwischen den Parameterkombinationen für den Haupt- und den Vorwärtszeitraum in jeder Zeile der Tabelle t1 zu berechnen und sie nach zunehmendem Abstand zu sortieren:
-- Request 5 SELECT ROUND(POW((I_custom_ontester - O_custom_ontester), 2) + POW( (I_equity_dd_relative - O_equity_dd_relative), 2) + POW( (I_profit_factor - O_profit_factor), 2), 4) AS dist, * FROM t1 ORDER BY dist ASC;
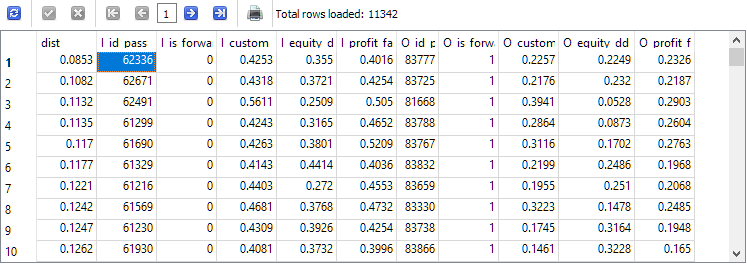
Die ID des Durchgangs I_id_pass aus der obersten Zeile der erhaltenen Ergebnisse entspricht dem Durchgang mit dem geringsten Abstand zwischen den Werten der Ergebnisse in dem Haupt- und dem Vorwärtszeitraum.
Nehmen wir sie und die ID des besten Passes für den normalisierten Gewinn in dem Hauptzeitraum. Sie stimmen nicht überein, also werden wir eine Bibliothek von Parametern für den endgültigen EA erstellen, wie im vorherigen Artikel beschrieben. Wir mussten einige kleinere Änderungen an den im vorherigen Artikel hinzugefügten Dateien vornehmen, um die Möglichkeit zu schaffen, beim Erstellen und Exportieren einer Bibliothek von Parametersätzen eine bestimmte Datenbank anzugeben.
Ergebnisse
Wir haben also zwei Einstellungsmöglichkeiten in der Bibliothek. Der erste heißt „Best for dist(IS, OS) (2018-2023) “ - der beste Optimierungsdurchlauf mit dem geringsten Abstand zwischen den Parameterwerten. Die zweite Option heißt „Best on IS (2018-2022) “ - der beste Optimierungsdurchlauf für den normalisierten Gewinn in dem Hauptzeitraum von 2018 bis 2022.
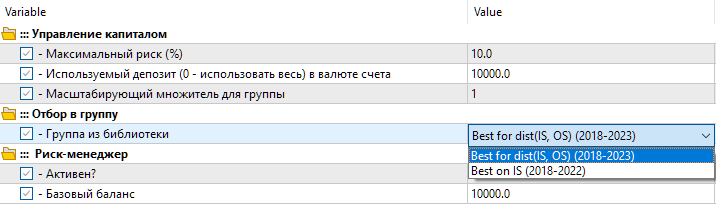
Abb. 8. Auswählen einer Gruppe von Einstellungen aus der Bibliothek im endgültigen EA
Betrachten wir die Ergebnisse dieser beiden Gruppen für den Zeitraum 2018-2023, der vollständig in die Optimierung einbezogen wurde.
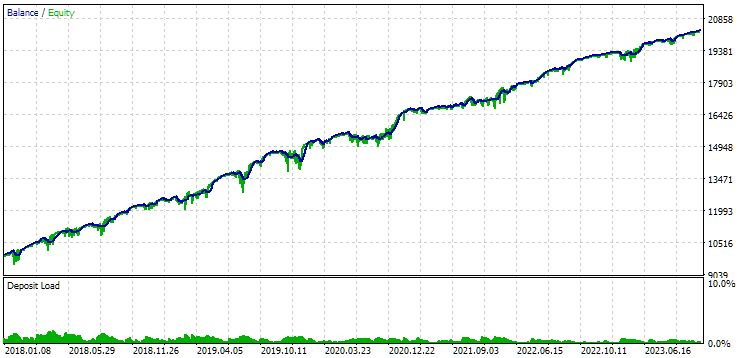
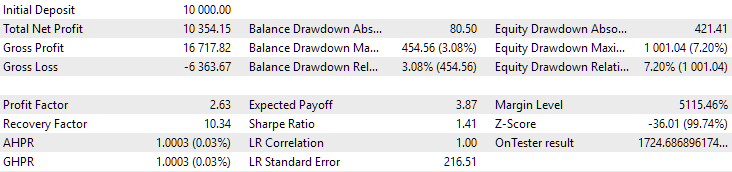
Abb. 9. Ergebnisse der ersten Gruppe (Besten nach der Distanz) für den Zeitraum von 2018 bis 2023
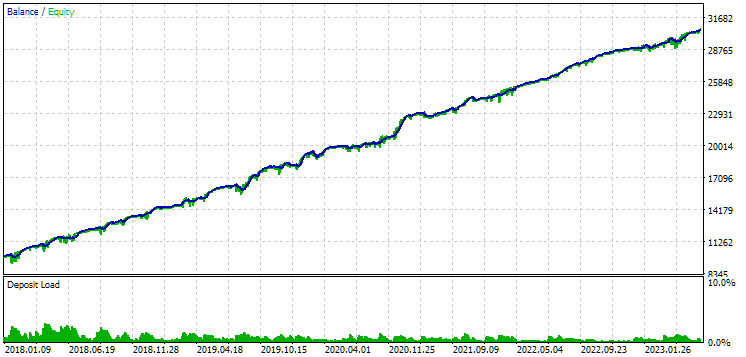
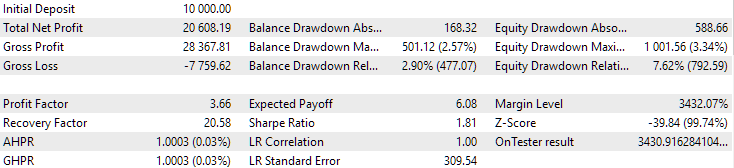
Abb. 10. Ergebnisse der zweiten Gruppe (Besten nach dem Gewinn) für den Zeitraum von 2018 bis 2023
Wir sehen, dass beide Gruppen über diesen Zeitraum gut normalisiert sind (der maximale Drawdown beträgt in beiden Fällen 1000 USD). Allerdings ist der durchschnittliche Jahresgewinn des ersten Unternehmens etwa doppelt so hoch wie der des zweiten (1724 USD gegenüber 3430 USD). Die Vorteile der ersten Gruppe sind hier noch nicht sichtbar.
Betrachten wir nun die Ergebnisse dieser beiden Gruppen für das Jahr 2024 (vor Oktober), die nicht an der Optimierung teilgenommen haben.
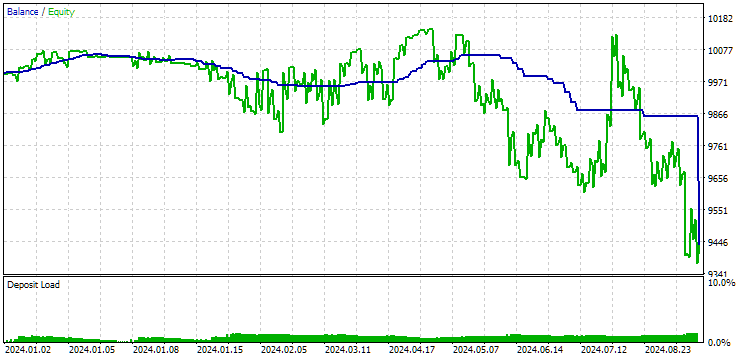
Fig. 11. Ergebnisse der ersten Gruppe (Beste nach Distanz) für den Zeitraum bis 2024
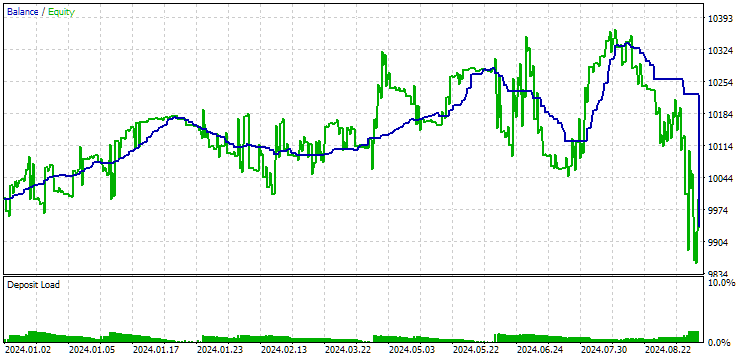
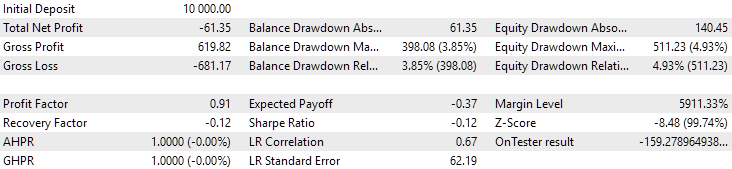
Abb. 12. Ergebnisse der zweiten Gruppe (Beste nach Gewinn) für den Zeitraum bis 2024
Zu diesem Zeitpunkt sind beide Ergebnisse negativ, aber das zweite sieht immer noch besser aus als das erste. Es ist erwähnenswert, dass der maximale Drawdown in diesem Zeitraum immer unter 1000 USD lag.
Da 2024 kein besonders erfolgreiches Jahr für dieses Symbol war, wollen wir sehen, wie die Ergebnisse nicht nach, sondern vor dem Optimierungszeitraum aussehen werden. Nehmen wir einen längeren Zeitraum, da wir eine solche Gelegenheit haben (drei Jahre von 2015 bis 2017).
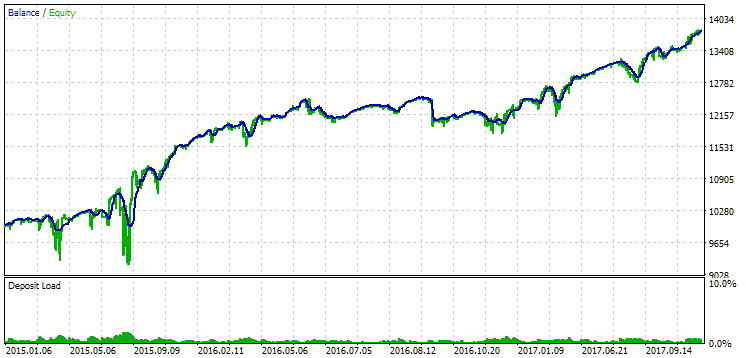
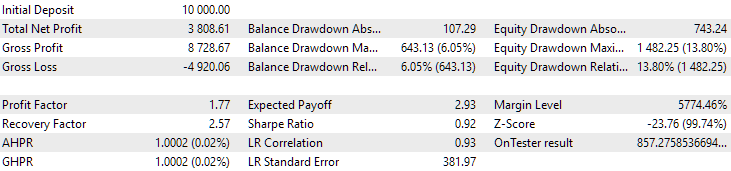
Abb. 13. Ergebnisse der ersten Gruppe (Beste nach Distanz) für den Zeitraum von 2015 bis 2017
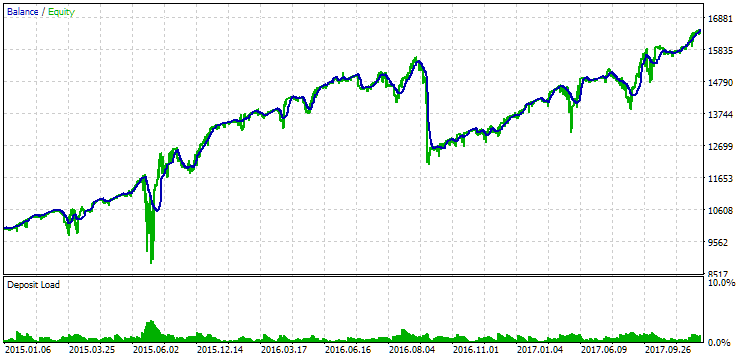
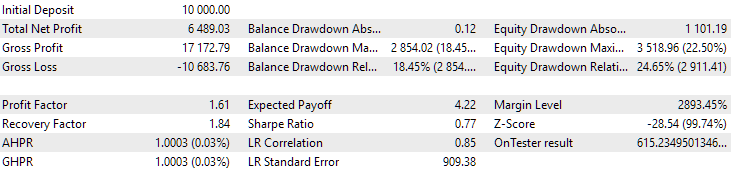
Abb. 14. Ergebnisse der zweiten Gruppe (Beste nach Gewinn) für den Zeitraum von 2015 bis 2017
In diesem Zeitraum hat die Inanspruchnahme bereits den zulässigen Rechenwert überschritten. In der ersten Version war sie etwa 1,5 mal größer, in der zweiten - etwa 3,5 mal größer. In dieser Hinsicht ist die erste Option etwas besser, da der übermäßige Drawdown deutlich geringer als bei der zweiten Option und insgesamt nicht sehr groß ist. Außerdem ist in der ersten Version in der Mitte des Diagramms kein deutlicher Einbruch zu erkennen, wie in der zweiten Version. Mit anderen Worten, die erste Option zeigte eine bessere Anpassungsfähigkeit an einen unbekannten Zeitraum der Geschichte als die zweite Option. In Bezug auf den normalisierten durchschnittlichen Jahresgewinn ist der Unterschied zwischen diesen beiden Optionen jedoch nicht so groß (857 USD gegenüber 615 USD). Leider können wir diesen Wert nicht im Voraus für einen unbekannten Zeitraum berechnen.
Daher wird in diesem Zeitraum weiterhin die erste Option bevorzugt werden. Fassen wir das Ganze zusammen.
Schlussfolgerung
Wir haben eine Automatisierung der zweiten Optimierungsphase unter Verwendung der Vorwärtszeitraum eingeführt. Auch hier wurden keine eindeutigen Vorteile festgestellt. Die Aufgabe erwies sich als viel umfangreicher und zeitaufwändiger, als wir ursprünglich erwartet hatten. Dabei sind viele neue Fragen aufgetaucht, die noch auf ihre Beantwortung warten.
Wir konnten feststellen, dass wir nicht in der Lage sind, gute Parameterkombinationen auszuwählen, wenn eine Vorwärtszeitraum auf eine erfolglose Periode der Arbeit des EA fällt.
Wenn die Dauer der Handelsgeschäfte lang ist, können die Ergebnisse des Durchgangs mit einer Unterbrechung an der Grenze zwischen Haupt- und Vorwärtszeitraum erheblich von den Ergebnissen des kontinuierlichen Durchgangs abweichen. Dies wirft auch die Frage auf, ob es ratsam ist, die Vorwärtszeitraum in dieser Form zu verwenden - nicht als Vorwärtszeitraum im Allgemeinen, sondern speziell als Mittel zur automatischen Auswahl von Parametern, die mit größerer Wahrscheinlichkeit in der Zukunft vergleichbare Ergebnisse zeigen werden.
Hier haben wir eine einfache Methode verwendet, um den Abstand zwischen den Ergebnissen der Durchgänge zu berechnen. Es ist möglich, dass sich die Ergebnisse verbessern, wenn diese Methode komplexer gestaltet wird. Wir haben auch noch nicht damit begonnen, eine Implementierung der automatischen Auswahl des besten Passes für die Aufnahme in eine Gruppe von Sets für verschiedene Symbole und Zeitrahmen zu schreiben. Fast alles ist bereit für die Umsetzung. Es reicht aus, die von uns entwickelten SQL-Abfragen aus dem EA aufzurufen. Da aber sicherlich noch Änderungen an ihnen vorgenommen werden, werden wir diese Automatisierung auf die Zukunft verschieben.
Vielen Dank für Ihre Aufmerksamkeit! Bis bald!
Wichtige Warnung
Alle in diesem Artikel und in allen vorangegangenen Artikeln dieser Reihe vorgestellten Ergebnisse beruhen lediglich auf historischen Testdaten und sind keine Garantie für zukünftige Gewinne. Die Arbeiten im Rahmen dieses Projekts haben Forschungscharakter. Alle veröffentlichten Ergebnisse können von jedermann auf eigenes Risiko verwendet werden.
Inhalt des Archivs
| # | Name | Version | Beschreibung | Jüngste Änderungen |
|---|---|---|---|---|
| MQL5/Experts/Article.15683 | ||||
| 1 | Advisor.mqh | 1.04 | EA-Basisklasse | Teil 10 |
| 2 | Database.mqh | 1.05 | Klasse für den Umgang mit der Datenbank | Teil 18 |
| 3 | database.sqlite.schema.sql | — | Struktur der Datenbank | Teil 18 |
| 4 | ExpertHistory.mqh | 1.00. | Klasse für den Export der Handelshistorie in eine Datei | Teil 16 |
| 5 | ExportedGroupsLibrary.mqh | — | Generierte Datei mit den Namen der Strategiegruppen und dem Array ihrer Initialisierungszeichenfolgen | Teil 17 |
| 6 | Factorable.mqh | 1.01 | Basisklasse von Objekten, die aus einer Zeichenkette erstellt werden | Teil 10 |
| 7 | GroupsLibrary.mqh | 1.01 | Klasse für die Arbeit mit einer Bibliothek ausgewählter Strategiegruppen | Teil 18 |
| 8 | HistoryReceiverExpert.mq5 | 1.00. | EA für die Wiedergabe der Historie von Geschäften mit dem Risikomanager | Teil 16 |
| 9 | HistoryStrategy.mqh | 1.00. | Klasse der Handelsstrategie für die Wiederholung der Handelshistorie | Teil 16 |
| 10 | Interface.mqh | 1.00. | Basisklasse zur Visualisierung verschiedener Objekte | Teil 4 |
| 11 | LibraryExport.mq5 | 1.01 | EA, der Initialisierungszeichenfolgen ausgewählter Durchläufe aus der Bibliothek in der Datei ExportedGroupsLibrary.mqh speichert | Teil 18 |
| 12 | Macros.mqh | 1.02 | Nützliche Makros für Array-Operationen | Teil 16 |
| 13 | Money.mqh | 1.01 | Grundkurs Geldmanagement | Teil 12 |
| 14 | NewBarEvent.mqh | 1.00. | Klasse zur Definition eines neuen Balkens für ein bestimmtes Symbol | Teil 8 |
| 15 | Optimization.mq5 | 1.02 | EA verwaltet die Einleitung von Optimierungsaufgaben | Teil 18 |
| 16 | Receiver.mqh | 1.04 | Basisklasse für die Umwandlung von offenen Volumina in Marktpositionen | Teil 12 |
| 17 | SimpleHistoryReceiverExpert.mq5 | 1.00. | Vereinfachter EA für die Wiedergabe des Geschäftsverlaufs | Teil 16 |
| 18 | SimpleVolumesExpert.mq5 | 1.20 | EA für den parallelen Betrieb von mehreren Gruppen von Modellstrategien. Die Parameter werden aus der integrierten Gruppenbibliothek übernommen. | Teil 17 |
| 19 | SimpleVolumesStage1.mq5 | 1.17 | Handelsstrategie Einzelinstanzoptimierung EA (Phase 1) | Teil 18 |
| 20 | SimpleVolumesStage2.mq5 | 1.01 | Handelsstrategien Instanzen Gruppe Optimierung EA (Phase 2) | Teil 18 |
| 21 | SimpleVolumesStage3.mq5 | 1.01 | Der EA, der eine generierte standardisierte Gruppe von Strategien in einer Bibliothek von Gruppen mit einem bestimmten Namen speichert. | Teil 18 |
| 22 | SimpleVolumesStrategy.mqh | 1.09 | Klasse der Handelsstrategie mit Tick-Volumen | Teil 15 |
| 23 | Strategy.mqh | 1.04 | Handelsstrategie-Basisklasse | Teil 10 |
| 24 | TesterHandler.mqh | 1.04 | Klasse zur Behandlung von Optimierungsereignissen | Teil 18 |
| 25 | VirtualAdvisor.mqh | 1.07 | Klasse des EA, der virtuelle Positionen (Aufträge) bearbeitet | Teil 18 |
| 26 | VirtualChartOrder.mqh | 1.01 | Grafische virtuelle Positionsklasse | Teil 18 |
| 27 | VirtualFactory.mqh | 1.04 | Objekt-Fabrik-Klasse | Teil 16 |
| 28 | VirtualHistoryAdvisor.mqh | 1.00. | Die Klasse des EA zur Wiederholung des Handelsverlaufs | Teil 16 |
| 29 | VirtualInterface.mqh | 1.00. | EA GUI-Klasse | Teil 4 |
| 30 | VirtualOrder.mqh | 1.04 | Klasse der virtuellen Aufträge und Positionen | Teil 8 |
| 31 | VirtualReceiver.mqh | 1.03 | Klasse für die Umwandlung von offenen Volumina in Marktpositionen (Empfänger) | Teil 12 |
| 32 | VirtualRiskManager.mqh | 1.02 | Klasse Risikomanagement (Risikomanager) | Teil 15 |
| 33 | VirtualStrategy.mqh | 1.05 | Klasse einer Handelsstrategie mit virtuellen Positionen | Teil 15 |
| 34 | VirtualStrategyGroup.mqh | 1.00. | Klasse der Handelsstrategien Gruppe(n) | Teil 11 |
| 35 | VirtualSymbolReceiver.mqh | 1.00. | Symbol-Empfängerklasse | Teil 3 |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/15683
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.
 Entwicklung eines Handelssystems auf der Grundlage des Orderbuchs (Teil I): Der Indikator
Entwicklung eines Handelssystems auf der Grundlage des Orderbuchs (Teil I): Der Indikator
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Der neue Artikel Entwicklung von Multiwährungs-EAs (Teil 18): Berücksichtigung der automatischen Gruppenauswahl für Termingeschäfte wurde veröffentlicht:
Von Yuriy Bykov