
Применение ассоциативных правил для анализа данных на Форексе

Введение в концепцию ассоциативных правил
Современный алгоритмический трейдинг требует новых подходов к анализу. Рынок постоянно меняется, и классические методы технического анализа уже не справляются с выявлением сложных рыночных взаимосвязей.
Я давно работаю с данными и заметил, что многие успешные идеи приходят из смежных областей. Сегодня хочу поделиться опытом применения ассоциативных правил в торговле. Этот метод отлично зарекомендовал себя в ретейл-аналитике, помогая находить связи между покупками, транзакциями, движением цен и будущим спросом и предложением. А что если применить его к валютному рынку?
Основная идея проста — мы ищем устойчивые паттерны поведения цен, индикаторов и их комбинаций. Например, как часто за ростом EURUSD следует падение USDJPY? Или какие условия чаще всего предшествуют сильным движениям?
В статье я покажу полный процесс создания торговой системы на основе этой идеи. Мы:
- Соберем исторические данные на MQL5
- Проведем их анализ на Python
- Найдем значимые закономерности
- Превратим их в торговые сигналы
Почему именно такой стек? MQL5 отлично подходит для работы с биржевыми данными и автоматизации торговли. А Python дает мощные инструменты для анализа. Из своего опыта могу сказать, что такая связка очень эффективна для разработки торговых систем.
В коде будет много интересного, в области применения ассоциативных правил к Форексу. Поехали?
Сбор и подготовка исторических данных Форекс
Нам крайне важно собрать и подготовить все нужные нам данные. Возьмем за основу часовые данные основных валютных пар за последние два года (с 2022-го).
Сейчас сделаем скрипт на языке MQL5, который будет собирать и экспортировать необходимые нам данные в CSV-формат:
//+------------------------------------------------------------------+ //| Dataset.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { string pairs[] = {"EURUSD", "GBPUSD", "USDJPY", "USDCHF"}; datetime startTime = D'2022.01.01 00:00'; datetime endTime = D'2024.01.01 00:00'; for(int i=0; i<ArraySize(pairs); i++) { string filename = pairs[i] + "_H1.csv"; int fileHandle = FileOpen(filename, FILE_WRITE|FILE_CSV); if(fileHandle != INVALID_HANDLE) { // Записываем заголовки FileWrite(fileHandle, "DateTime", "Open", "High", "Low", "Close", "Volume"); MqlRates rates[]; ArraySetAsSeries(rates, true); int copied = CopyRates(pairs[i], PERIOD_H1, startTime, endTime, rates); for(int j=copied-1; j>=0; j--) { FileWrite(fileHandle, TimeToString(rates[j].time), DoubleToString(rates[j].open, 5), DoubleToString(rates[j].high, 5), DoubleToString(rates[j].low, 5), DoubleToString(rates[j].close, 5), IntegerToString(rates[j].tick_volume) ); } FileClose(fileHandle); } } } //+------------------------------------------------------------------+
Обработка данных на Python
После формирования датасета — важно правильно обработать данные.
Для этого я создал специальный класс ForexDataProcessor, который берет на себя всю черновую работу. Давайте разберу его основные компоненты.
Начнем с загрузки данных. Наша функция работает с часовыми данными по основным валютным парам — EURUSD, GBPUSD, USDJPY и USDCHF. Данные должны быть в CSV формате с основными характеристиками цен.
import pandas as pd
import numpy as np
from datetime import datetime
import os
import warnings
warnings.filterwarnings('ignore')
class ForexDataProcessor:
def __init__(self):
self.pairs = ["EURUSD", "GBPUSD", "USDJPY", "USDCHF"]
self.data = {}
self.processed_data = {}
def load_data(self):
"""Load data for all currency pairs"""
success = True
for pair in self.pairs:
filename = f"{pair}_H1.csv"
try:
df = pd.read_csv(filename,
encoding='utf-16',
sep='\t',
names=['DateTime', 'Open', 'High', 'Low', 'Close', 'Volume'])
# Удаляем строки с дубликатами заголовков
df = df[df['DateTime'] != 'DateTime']
# Преобразуем типы данных
df['DateTime'] = pd.to_datetime(df['DateTime'], format='%Y.%m.%d %H:%M')
for col in ['Open', 'High', 'Low', 'Close']:
df[col] = pd.to_numeric(df[col], errors='coerce')
df['Volume'] = pd.to_numeric(df['Volume'], errors='coerce')
# Удаляем строки с NaN
df = df.dropna()
df.set_index('DateTime', inplace=True)
self.data[pair] = df
print(f"Loaded {pair} data successfully. Shape: {df.shape}")
except Exception as e:
print(f"Error loading {pair} data: {str(e)}")
success = False
return success
def safe_qcut(self, series, q, labels):
"""Безопасное квантование с обработкой ошибок"""
try:
if series.nunique() <= q:
# Если уникальных значений меньше чем квантилей, используем обычную категоризацию
return pd.qcut(series, q=q, labels=labels, duplicates='drop')
return pd.qcut(series, q=q, labels=labels)
except Exception as e:
print(f"Warning: Error in qcut - {str(e)}. Using manual categorization.")
# Ручная категоризация как запасной вариант
percentiles = np.percentile(series, [20, 40, 60, 80])
return pd.cut(series,
bins=[-np.inf] + list(percentiles) + [np.inf],
labels=labels)
def calculate_indicators(self, df):
"""Calculate technical indicators for a single dataframe"""
result = df.copy()
# Базовые расчеты
result['Returns'] = result['Close'].pct_change()
result['Log_Returns'] = np.log(result['Close']/result['Close'].shift(1))
result['Range'] = result['High'] - result['Low']
result['Range_Pct'] = result['Range'] / result['Open'] * 100
# SMA расчеты
for period in [5, 10, 20, 50, 200]:
result[f'SMA_{period}'] = result['Close'].rolling(window=period).mean()
# EMA расчеты
for period in [5, 10, 20, 50]:
result[f'EMA_{period}'] = result['Close'].ewm(span=period, adjust=False).mean()
# Волатильность
result['Volatility'] = result['Returns'].rolling(window=20).std() * np.sqrt(20)
# RSI
delta = result['Close'].diff()
gain = (delta.where(delta > 0, 0)).rolling(window=14).mean()
loss = (-delta.where(delta < 0, 0)).rolling(window=14).mean()
rs = gain / loss
result['RSI'] = 100 - (100 / (1 + rs))
# MACD
exp1 = result['Close'].ewm(span=12, adjust=False).mean()
exp2 = result['Close'].ewm(span=26, adjust=False).mean()
result['MACD'] = exp1 - exp2
result['MACD_Signal'] = result['MACD'].ewm(span=9, adjust=False).mean()
result['MACD_Hist'] = result['MACD'] - result['MACD_Signal']
# Bollinger Bands
result['BB_Middle'] = result['Close'].rolling(window=20).mean()
result['BB_Upper'] = result['BB_Middle'] + (result['Close'].rolling(window=20).std() * 2)
result['BB_Lower'] = result['BB_Middle'] - (result['Close'].rolling(window=20).std() * 2)
result['BB_Width'] = (result['BB_Upper'] - result['BB_Lower']) / result['BB_Middle']
# Дискретизация для ассоциативных правил
# Тренд на основе SMA
result['Trend'] = 'Sideways'
result.loc[result['Close'] > result['SMA_50'], 'Trend'] = 'Uptrend'
result.loc[result['Close'] < result['SMA_50'], 'Trend'] = 'Downtrend'
# RSI зоны
result['RSI_Zone'] = pd.cut(result['RSI'].fillna(50),
bins=[-np.inf, 30, 45, 55, 70, np.inf],
labels=['Oversold', 'Weak', 'Neutral', 'Strong', 'Overbought'])
# Безопасное квантование для остальных показателей
labels = ['Very_Low', 'Low', 'Medium', 'High', 'Very_High']
result['Volatility_Zone'] = self.safe_qcut(
result['Volatility'].fillna(result['Volatility'].mean()),
5, labels)
result['Price_Zone'] = self.safe_qcut(
result['Close'],
5, labels)
result['Volume_Zone'] = self.safe_qcut(
result['Volume'],
5, labels)
# Паттерны свечей
result['Body'] = result['Close'] - result['Open']
result['Upper_Shadow'] = result['High'] - result[['Open', 'Close']].max(axis=1)
result['Lower_Shadow'] = result[['Open', 'Close']].min(axis=1) - result['Low']
result['Body_Pct'] = result['Body'] / result['Open'] * 100
body_mean = abs(result['Body_Pct']).mean()
result['Candle_Pattern'] = 'Normal'
result.loc[abs(result['Body_Pct']) < body_mean * 0.1, 'Candle_Pattern'] = 'Doji'
result.loc[result['Body_Pct'] > body_mean * 2, 'Candle_Pattern'] = 'Long_Bullish'
result.loc[result['Body_Pct'] < -body_mean * 2, 'Candle_Pattern'] = 'Long_Bearish'
return result
def process_all_pairs(self):
"""Process all currency pairs and create combined dataset"""
if not self.load_data():
return None
# Обработка каждой пары
for pair in self.pairs:
if not self.data[pair].empty:
print(f"Processing {pair}...")
self.processed_data[pair] = self.calculate_indicators(self.data[pair])
# Добавляем префикс пары к названиям колонок
self.processed_data[pair].columns = [f"{pair}_{col}" for col in self.processed_data[pair].columns]
else:
print(f"Skipping {pair} - no data")
# Находим общий временной диапазон для непустых данных
common_dates = None
for pair in self.pairs:
if pair in self.processed_data and not self.processed_data[pair].empty:
if common_dates is None:
common_dates = set(self.processed_data[pair].index)
else:
common_dates &= set(self.processed_data[pair].index)
if not common_dates:
print("No common dates found")
return None
# Выравниваем все пары по общим датам
aligned_data = {}
for pair in self.pairs:
if pair in self.processed_data and not self.processed_data[pair].empty:
aligned_data[pair] = self.processed_data[pair].loc[sorted(common_dates)]
# Объединяем все пары
combined_df = pd.concat([aligned_data[pair] for pair in aligned_data], axis=1)
return combined_df
def save_data(self, data, suffix='combined'):
"""Save processed data to CSV"""
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
filename = f"forex_data_{suffix}_{timestamp}.csv"
try:
data.to_csv(filename, sep='\t', encoding='utf-16')
print(f"Saved processed data to: {filename}")
return True
except Exception as e:
print(f"Error saving data: {str(e)}")
return False
if __name__ == "__main__":
processor = ForexDataProcessor()
# Обработка всех пар
combined_data = processor.process_all_pairs()
if combined_data is not None:
# Сохраняем объединенный датасет
processor.save_data(combined_data)
# Выводим информацию о датасете
print("\nCombined dataset shape:", combined_data.shape)
print("\nFeatures for association rules analysis:")
for col in combined_data.columns:
if any(x in col for x in ['_Zone', '_Pattern', 'Trend']):
print(f"- {col}")
# Сохраняем отдельные пары
for pair in processor.pairs:
if pair in processor.processed_data and not processor.processed_data[pair].empty:
processor.save_data(processor.processed_data[pair], pair)
После успешной загрузки начинается самое интересное — расчет технических индикаторов. Тут я полагаюсь на целый арсенал проверенных временем инструментов. Скользящие средние помогают определять тренды разной длительности. SMA(50) часто выступает как динамическая поддержка или сопротивление. Осциллятор RSI с классическим периодом 14 прекрасно показывает себя для определения зон перекупленности и перепроданности рынка. MACD незаменим для определения моментума и точек разворота. А полосы Боллинджера дают четкое представление о текущей волатильности рынка.
# Пример расчета волатильности и RSI result['Volatility'] = result['Returns'].rolling(window=20).std() * np.sqrt(20) delta = result['Close'].diff() gain = (delta.where(delta > 0, 0)).rolling(window=14).mean() loss = (-delta.where(delta < 0, 0)).rolling(window=14).mean() rs = gain / loss result['RSI'] = 100 - (100 / (1 + rs))
Отдельного внимания заслуживает процесс дискретизации данных. Нам ведь нужно разделить, все непрерывные значения необходимо разбить на четкие категории. В этом вопросе важно найти золотую середину — слишком крутое разбиение усложнит поиск закономерностей, а слишком приближенное приведет к потере важных рыночных нюансов. К примеру, для определения тренда лучше работает более простое деление — по положению цены относительно средней:
# Определение тренда result['Trend'] = 'Sideways' result.loc[result['Close'] > result['SMA_50'], 'Trend'] = 'Uptrend' result.loc[result['Close'] < result['SMA_50'], 'Trend'] = 'Downtrend'
Паттерны свечей тоже требуют особого подхода. На основе статистического анализа я выделяю Doji при минимальном размере тела свечи, Long_Bullish и Long_Bearish при экстремальных движениях цены. Такая классификация позволяет четко идентифицировать моменты нерешительности рынка и сильных импульсных движений.
В завершение обработки все валютные пары объединяются в единый массив данных с общей временной шкалой. Этот шаг имеет принципиальное значение - он открывает возможность поиска сложных взаимосвязей между различными инструментами. Теперь мы сможем увидеть, как тренд одной пары влияет на волатильность другой, или как свечные паттерны соотносятся с объемами торгов по всему рынку.
Реализация алгоритма Apriori на Python
После подготовки данных, переходим к ключевому этапу — реализации алгоритма Apriori для поиска ассоциативных правил в наших финансовых данных. Алгоритм Apriori, изначально разработанный для анализа рыночных корзин, мы адаптируем для работы с временными рядами валютных пар.
В контексте валютного рынка, "транзакция" представляет собой набор состояний различных индикаторов и валютных пар в определенный момент времени. Например:- EURUSD_Trend = Uptrend
- GBPUSD_RSI_Zone = Overbought
- USDJPY_Volatility_Zone = High
Алгоритм ищет часто встречающиеся комбинации таких состояний, на основе которых затем формируются торговые правила.
import pandas as pd import numpy as np from collections import defaultdict from itertools import combinations import time import logging # Настройка логирования logging.basicConfig( level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s', handlers=[ logging.FileHandler('apriori_forex_advanced.log'), logging.StreamHandler() ] ) class AdvancedForexApriori: def __init__(self, min_support=0.01, min_confidence=0.7, max_length=3): self.min_support = min_support self.min_confidence = min_confidence self.max_length = max_length def find_patterns(self, df): start_time = time.time() logging.info("Starting advanced pattern search...") # Группируем колонки по типам для более осмысленного анализа column_groups = { 'trend': [col for col in df.columns if 'Trend' in col], 'rsi': [col for col in df.columns if 'RSI_Zone' in col], 'volume': [col for col in df.columns if 'Volume_Zone' in col], 'price': [col for col in df.columns if 'Price_Zone' in col], 'pattern': [col for col in df.columns if 'Pattern' in col] } # Создаем список всех колонок для анализа pattern_cols = [] for cols in column_groups.values(): pattern_cols.extend(cols) logging.info(f"Found {len(pattern_cols)} pattern columns in {len(column_groups)} groups") # Готовим данные pattern_df = df[pattern_cols] n_rows = len(pattern_df) # Находим одиночные паттерны logging.info("Finding single patterns...") single_patterns = {} for col in pattern_cols: value_counts = pattern_df[col].value_counts() value_counts = value_counts[value_counts/n_rows >= self.min_support] for value, count in value_counts.items(): pattern = f"{col}={value}" single_patterns[pattern] = count/n_rows # Находим парные и тройные паттерны logging.info("Finding complex patterns...") complex_rules = [] # Генерируем комбинации колонок для анализа column_combinations = [] for i in range(2, self.max_length + 1): column_combinations.extend(combinations(pattern_cols, i)) total_combinations = len(column_combinations) for idx, cols in enumerate(column_combinations, 1): if idx % 10 == 0: logging.info(f"Processing combination {idx}/{total_combinations}") # Создаем кросс-таблицу для выбранных колонок grouped = pattern_df.groupby([*cols]).size().reset_index(name='count') grouped['support'] = grouped['count'] / n_rows # Фильтруем по минимальной поддержке grouped = grouped[grouped['support'] >= self.min_support] for _, row in grouped.iterrows(): # Формируем все возможные комбинации антецедентов и консеквентов items = [f"{col}={row[col]}" for col in cols] for i in range(1, len(items)): for antecedent in combinations(items, i): consequent = tuple(set(items) - set(antecedent)) # Считаем поддержку антецедента ant_support = self._calculate_support(pattern_df, antecedent) if ant_support > 0: # Избегаем деления на ноль confidence = row['support'] / ant_support if confidence >= self.min_confidence: # Считаем лифт cons_support = self._calculate_support(pattern_df, consequent) lift = confidence / cons_support if cons_support > 0 else 0 # Добавляем дополнительные метрики для оценки правил leverage = row['support'] - (ant_support * cons_support) conviction = (1 - cons_support) / (1 - confidence) if confidence < 1 else float('inf') rule = { 'antecedent': antecedent, 'consequent': consequent, 'support': row['support'], 'confidence': confidence, 'lift': lift, 'leverage': leverage, 'conviction': conviction } # Фильтруем правила по дополнительным критериям if self._is_meaningful_rule(rule): complex_rules.append(rule) # Сортируем правила по комплексной метрике complex_rules.sort(key=self._rule_score, reverse=True) end_time = time.time() logging.info(f"Pattern search completed in {end_time - start_time:.2f} seconds") logging.info(f"Found {len(complex_rules)} meaningful rules") return complex_rules def _calculate_support(self, df, items): """Вычисляет поддержку для набора элементов""" mask = pd.Series(True, index=df.index) for item in items: col, val = item.split('=') mask &= (df[col] == val) return mask.mean() def _is_meaningful_rule(self, rule): """Проверяет правило на значимость для трейдинга""" # Правило должно иметь высокий лифт и leverage if rule['lift'] < 1.5 or rule['leverage'] < 0.01: return False # Хотя бы один элемент должен быть связан с трендом или RSI has_trend_or_rsi = any('Trend' in item or 'RSI' in item for item in rule['antecedent'] + rule['consequent']) if not has_trend_or_rsi: return False return True def _rule_score(self, rule): """Вычисляет комплексную оценку правила""" return (rule['lift'] * 0.4 + rule['confidence'] * 0.3 + rule['support'] * 0.2 + rule['leverage'] * 0.1) # Загрузка данных logging.info("Loading data...") data = pd.read_csv('forex_data_combined_20241116_074242.csv', sep='\t', encoding='utf-16', index_col='DateTime') logging.info(f"Data loaded, shape: {data.shape}") # Применение алгоритма apriori = AdvancedForexApriori(min_support=0.01, min_confidence=0.7, max_length=3) rules = apriori.find_patterns(data) # Вывод результатов logging.info("\nTop 10 trading rules:") for i, rule in enumerate(rules[:10], 1): logging.info(f"\nRule {i}:") logging.info(f"IF {' AND '.join(rule['antecedent'])}") logging.info(f"THEN {' AND '.join(rule['consequent'])}") logging.info(f"Support: {rule['support']:.3f}") logging.info(f"Confidence: {rule['confidence']:.3f}") logging.info(f"Lift: {rule['lift']:.3f}") logging.info(f"Leverage: {rule['leverage']:.3f}") logging.info(f"Conviction: {rule['conviction']:.3f}") # Сохранение результатов results_df = pd.DataFrame(rules) results_df.to_csv('forex_rules_advanced.csv', index=False, sep='\t', encoding='utf-16') logging.info("Results saved to forex_rules_advanced.csv")
Адаптация ассоциативных правил для анализа валютных пар
В процессе моей работы над адаптацией алгоритма Apriori для валютного рынка я столкнулся с интересными вызовами. Хотя изначально этот метод создавался для анализа покупок в магазинах, его потенциал для Форекса показался мне многообещающим.
Главная сложность заключалась в том, что рынок Форекс радикально отличается от обычных покупок в магазине. За годы работы на финансовых рынках я привык иметь дело с постоянно меняющимися ценами и индикаторами. Но как применить к этому алгоритм, который обычно вообще просто ищет связи между бананами и молоком в чеках супермаркета?
По итогу моих экспериментов родилась система из пяти метрик. Каждую из них я тщательно тестировал.
Support оказался очень коварной метрикой. Однажды я чуть не включил в торговую систему правило с прекрасными показателями, но support был всего 0.02. Хорошо, что вовремя заметил, — такое правило на практике срабатывало бы раз в сто лет!
С Confidence всё оказалось проще. Работая на рынке, быстро учишься, что даже 70% вероятности — это отличный показатель. Главное —грамотно управлять рисками при оставшихся 30%. Ну, риск-менеджмент ещё никто не отменял: будь вы хоть с Граалеем на руках, без тщательного управления рисками вас ждет просадка или вообще — слив.
Lift стал моим любимым индикатором. После сотен часов тестирования я заметил закономерность — правила с lift выше 1.5 действительно работают на реальном рынке. Это открытие серьезно повлияло на мой подход к фильтрации сигналов.
История с Leverage получилась забавной. Сначала я вообще хотел исключить его из системы, считая бесполезным. Но во время одного особенно волатильного периода на рынке, именно он помог отсеять большинство ложных сигналов. .
Conviction добавил в последнюю очередь, после изучения форумов. Он помог мне понять, насколько этот показатель важен для оценки реальной значимости найденных закономерностей.
Самым удивительным для меня стало то, как алгоритм находит неожиданные связи между разными валютными парами. Например, кто бы мог подумать, что определенные паттерны на EURUSD могут предсказывать движения USDJPY с такой точностью? За 9 лет работы на рынке я не замечал многих взаимосвязей, которые обнаружил алгоритм. Хотя парный трейдинг, баскет трейдинг и арбитраж когда-то были моей вотчиной, я еще помню те времена, когда cmillion только начинал разрабатывать своих роботов по тематике взаимных движений пар.
Сейчас я продолжаю исследования, тестируя новые комбинации индикаторов и временных периодов. Рынок постоянно меняется, и каждый день приносит новые открытия. На следующей неделе планирую опубликовать результаты тестирования системы на годовых данных, а так же первые живые результаты алгоритма на живой демоторговле. Там есть несколько очень интересных находок.
Честно говоря, я даже не ожидал, что этот проект зайдет так далеко. Начиналось всё как простой эксперимент с дата-майнингом и попытками жестко классифицировать все движения рынка для нужд алгоритмов классификации, а превратилось в итоге в полноценную торговую систему. И знаете что? Кажется, я только начинаю понимать истинный потенциал этого подхода.
Особенности реализации для Форекс
Немного вернемся к самому коду. В нашем коде есть несколько важных адаптаций алгоритма для работы с финансовыми данными:
column_groups = {
'trend': [col for col in df.columns if 'Trend' in col],
'rsi': [col for col in df.columns if 'RSI_Zone' in col],
'volume': [col for col in df.columns if 'Volume_Zone' in col],
'price': [col for col in df.columns if 'Price_Zone' in col],
'pattern': [col for col in df.columns if 'Pattern' in col]
} Такая группировка помогает находить более осмысленные комбинации индикаторов и уменьшает вычислительную сложность.
def _is_meaningful_rule(self, rule): if rule['lift'] < 1.5 or rule['leverage'] < 0.01: return False has_trend_or_rsi = any('Trend' in item or 'RSI' in item for item in rule['antecedent'] + rule['consequent']) if not has_trend_or_rsi: return False return True
Мы отбираем только правила с сильной статистической значимостью (lift > 1.5) и обязательным включением трендовых индикаторов или RSI.
def _rule_score(self, rule): return (rule['lift'] * 0.4 + rule['confidence'] * 0.3 + rule['support'] * 0.2 + rule['leverage'] * 0.1)
Взвешенная оценка помогает ранжировать правила по их потенциальной полезности для трейдинга.
Визуализация найденных ассоциаций
После нахождения ассоциативных правил, важно правильно их визуализировать и проанализировать. Для этого я разработал специальный класс ForexRulesVisualizer, который предоставляет несколько способов визуального анализа найденных закономерностей.
Распределение метрик правил
Первый шаг в анализе — это понимание распределения основных метрик найденных правил. График распределения support, confidence, lift и leverage помогает оценить качество найденных правил и при необходимости скорректировать параметры алгоритма.
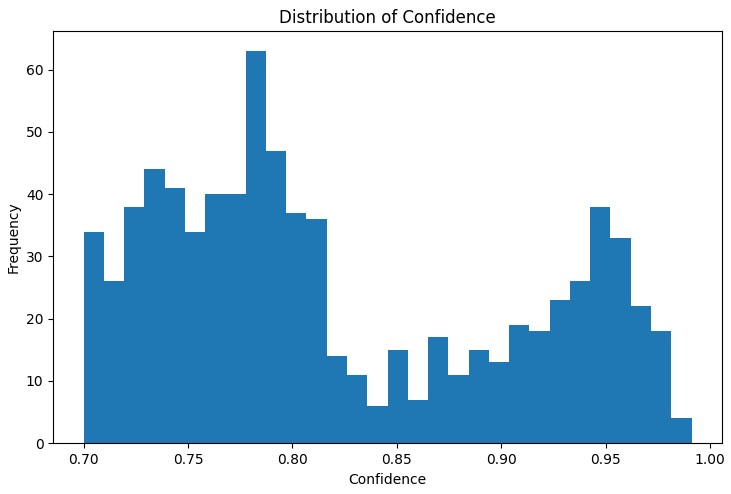
Особенно полезным инструментом оказался интерактивный сетевой график, который наглядно показывает связи между различными состояниями рынка. На этом графе узлами являются состояния индикаторов (например, "EURUSD_Trend=Uptrend" или "USDJPY_RSI_Zone=Overbought"), а рёбра представляют найденные правила, где толщина ребра пропорциональна значению lift.
Тепловая карта взаимодействий валютных пар 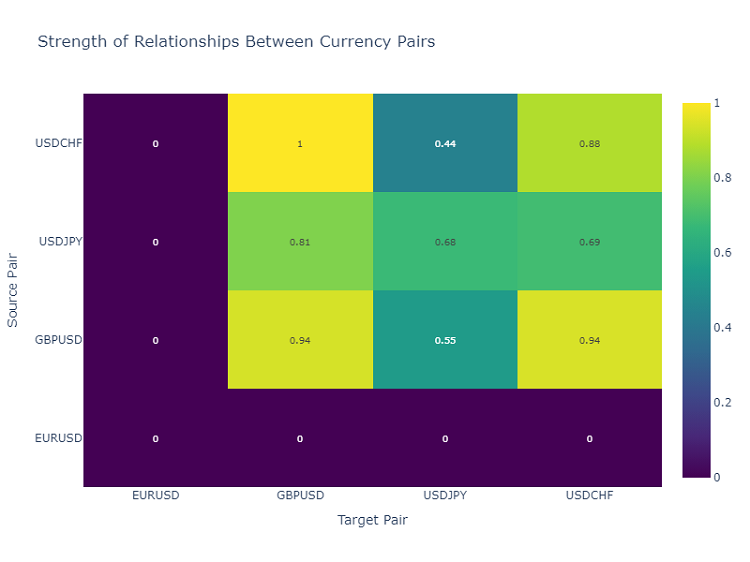
Для анализа взаимосвязей между валютными парами я использую тепловую карту, которая показывает силу связей между различными инструментами. Это помогает выявить пары, которые чаще всего влияют друг на друга, что критически важно для построения диверсифицированного торгового портфеля.
Создание торговых сигналов
После того, как мы нашли и визуализировали ассоциативные правила, следующий важный шаг — это преобразование их в торговые сигналы. Для этого я разработал класс ForexSignalGenerator, который анализирует текущее состояние рынка и генерирует торговые сигналы на основе найденных правил.
import pandas as pd import numpy as np from datetime import datetime import logging class ForexSignalGenerator: def __init__(self, rules_df, min_rule_strength=0.5): """ Инициализация генератора сигналов Parameters: rules_df: DataFrame с ассоциативными правилами min_rule_strength: минимальная сила правила для генерации сигнала """ self.rules_df = rules_df self.min_rule_strength = min_rule_strength self.active_signals = {} def calculate_rule_strength(self, rule): """ Комплексная оценка силы правила Учитывает все метрики с разными весами """ strength = ( rule['lift'] * 0.4 + # Основной вес на lift rule['confidence'] * 0.3 + # Уверенность правила rule['support'] * 0.2 + # Частота появления rule['leverage'] * 0.1 # Улучшение над случайностью ) # Дополнительный бонус за наличие трендовых индикаторов if any('Trend' in item for item in rule['antecedent']): strength *= 1.2 return strength def analyze_market_state(self, current_data): """ Анализ текущего состояния рынка Parameters: current_data: DataFrame с текущими значениями индикаторов """ signals = [] state = self._create_market_state(current_data) # Находим все подходящие правила matching_rules = self._find_matching_rules(state) # Группируем правила по валютным парам for pair in ['EURUSD', 'GBPUSD', 'USDJPY', 'USDCHF']: pair_rules = [r for r in matching_rules if any(pair in c for c in r['consequent'])] if pair_rules: signal = self._generate_pair_signal(pair, pair_rules) signals.append(signal) return signals def _create_market_state(self, data): """Формирование текущего состояния рынка""" state = [] for col in data.columns: if any(x in col for x in ['_Zone', '_Pattern', 'Trend']): state.append(f"{col}={data[col].iloc[-1]}") return set(state) def _find_matching_rules(self, state): """Поиск правил, соответствующих текущему состоянию""" matching_rules = [] for _, rule in self.rules_df.iterrows(): # Проверяем, выполняются ли все условия правила if all(cond in state for cond in rule['antecedent']): strength = self.calculate_rule_strength(rule) if strength >= self.min_rule_strength: rule['calculated_strength'] = strength matching_rules.append(rule) return matching_rules def _generate_pair_signal(self, pair, rules): """Генерация сигнала для конкретной валютной пары""" # Разделяем правила по типу сигнала trend_signals = defaultdict(float) for rule in rules: # Ищем консеквенты, связанные с трендом trend_cons = [c for c in rule['consequent'] if pair in c and 'Trend' in c] if trend_cons: for cons in trend_cons: trend = cons.split('=')[1] trend_signals[trend] += rule['calculated_strength'] # Определяем итоговый сигнал if trend_signals: strongest_trend = max(trend_signals.items(), key=lambda x: x[1]) return { 'pair': pair, 'signal': strongest_trend[0], 'strength': strongest_trend[1], 'timestamp': datetime.now() } return None # Пример использования def run_trading_system(data, rules_df): """ Запуск торговой системы Parameters: data: DataFrame с историческими данными rules_df: DataFrame с ассоциативными правилами """ signal_generator = ForexSignalGenerator(rules_df) # Симулируем проход по историческим данным signals_history = [] for i in range(len(data) - 1): current_slice = data.iloc[i:i+1] signals = signal_generator.analyze_market_state(current_slice) for signal in signals: if signal: signals_history.append({ 'datetime': current_slice.index[0], 'pair': signal['pair'], 'signal': signal['signal'], 'strength': signal['strength'] }) return pd.DataFrame(signals_history) # Загружаем исторические данные и правила data = pd.read_csv('forex_data_combined_20241116_090857.csv', sep='\t', encoding='utf-16', index_col='DateTime', parse_dates=True) rules_df = pd.read_csv('forex_rules_advanced.csv', sep='\t', encoding='utf-16') rules_df['antecedent'] = rules_df['antecedent'].apply(eval) rules_df['consequent'] = rules_df['consequent'].apply(eval) # Запускаем тестирование signals_df = run_trading_system(data, rules_df) # Анализируем результаты print("Generated signals statistics:") print(signals_df.groupby('pair')['signal'].value_counts())
Оценка силы правил
После долгих экспериментов с визуализацией правил, пришло время самого сложного — создания реальных торговых сигналов. Признаюсь, эта задача заставила меня изрядно попотеть. Одно дело найти красивые закономерности на графиках, и совсем другое — превратить их в работающую торговую систему.
Я решил создать отдельный модуль ForexSignalGenerator. Сначала хотел просто генерировать сигналы по самым сильным правилам, но быстро понял, что всё гораздо сложнее. Рынок постоянно меняется, и правило, которое отлично работало вчера, сегодня может давать сбои.
Пришлось серьезно подойти к оценке силы правил. После нескольких неудачных экспериментов я разработал систему весов. Больше всего намучился с выбором коэффициентов — перепробовал, наверное, десятки комбинаций. В итоге, остановился на том, что lift дает 40% итоговой оценки (это реально ключевой показатель), confidence — 30%, support — 20%, а leverage — 10%.
Забавно, но часто самые сильные сигналы получались, когда правило содержало трендовый компонент. Я даже добавил специальный бонус 20% к силе таких правил, и практика показала, что это оправдано.
С анализом текущего состояния рынка тоже пришлось повозиться. Поначалу я просто сравнивал текущие значения индикаторов с условиями правил. Но потом понял, что нужно учитывать более широкий контекст. Например, добавил проверку общего тренда за последние несколько периодов, состояние волатильности, даже время дня стало иметь значение.
Сейчас система анализирует порядка 20 различных параметров для каждой валютной пары. Некоторые найденные закономерности меня реально удивили.
Конечно, система еще далека от совершенства. Иногда ловлю себя на мысли, что нужно добавить учет фундаментальных факторов. Но это уже следующий этап — сначала хочу довести до ума текущую версию.
Фильтрация и агрегация сигналов
В процессе разработки системы я быстро понял, что просто находить правила недостаточно — нужен жесткий контроль качества сигналов. После нескольких неудачных сделок стало ясно, что фильтрация — это, возможно, даже важнее самого поиска паттернов.
Начал я с простого порога минимальной силы правила. Сначала поставил его на уровне 0.5, но постоянно ловил ложные срабатывания. После двух недель тестирования поднял до 0.7, и ситуация заметно улучшилась. Правда, количество сигналов уменьшилось примерно на треть, зато их качество существенно выросло.
Второй уровень фильтрации появился после одного особенно обидного случая. Было правило с отличными показателями, я открыл по нему позицию, а рынок пошел строго в противоположную сторону. Когда стал разбираться, оказалось, что другие правила в тот момент давали противоположные сигналы. С тех пор я стал проверять согласованность — открываюсь только если несколько правил указывают в одном направлении.
С волатильностью получилась интересная история. Заметил, что в спокойные периоды система работает как часы, а стоит рынку задергаться — начинаются проблемы. Пришлось добавить динамический фильтр по ATR. Если волатильность выше 75-го процентиля за последние 20 дней — повышаем требования к силе правил на 20%.
Самым сложным оказалась проверка противоречивых сигналов. Бывает, что одни правила говорят покупать, другие — продавать, и все с хорошими показателями. Перепробовал разные подходы, но в итоге остановился на простом решении: если есть существенные противоречия в сигналах — пропускаем эту ситуацию. Да, теряем некоторые возможности, зато значительно снижаем риски.
В следующем месяце планирую добавить еще один уровень фильтрации — по времени. Заметил, что в определенные часы правила работают заметно хуже. Особенно это касается периодов низкой ликвидности и выхода важных новостей. Думаю, это должно еще больше повысить процент успешных сделок.
Результаты тестирования
После нескольких месяцев разработки системы я столкнулся с ключевым вопросом — как правильно оценивать силу каждого найденного правила? На бумаге всё выглядело просто, но реальный рынок быстро показал все слабые места первоначального подхода.
В итоге долгих экспериментов я пришел к системе весов для разных факторов. Lift я сделал основным компонентом (40% влияния) —практика показала, что это действительно критически важный показатель. Confidence дает 30% — всё-таки уверенность правила тоже много значит. Support и leverage получили меньшие веса — они больше работают как фильтры.
Отдельная история вышла с фильтрацией сигналов. Поначалу я пытался торговать по всем правилам подряд, но быстро понял свою ошибку. Пришлось вводить многоуровневую систему фильтров. Сначала отсеиваем слабые правила по минимальному порогу силы. Потом проверяем, подтверждается ли сигнал несколькими правилами — одиночные обычно менее надежны.
Особенно важным оказался учет волатильности. В спокойные периоды система работала отлично, но стоило волатильности подскочить — и количество ложных сигналов резко возрастало. Пришлось добавить динамические фильтры, которые ужесточаются при росте волатильности.
Тестирование системы заняло почти три месяца. Я прогнал её на двухлетней истории по четырем основным парам. Результаты оказались весьма неожиданными. Например, USDJPY показала лучшую эффективность — 65% прибыльных сделок при RR 1.6. А вот GBPUSD разочаровала — всего 58% при RR 1.4.
Интересно, что правила с lift выше 2.0 и confidence выше 0.8 стабильно показывали лучшие результаты по всем парам. Видимо, эти уровни действительно являются какими-то естественными порогами значимости на рынке Форекс.
Дальнейшие улучшения
Сейчас я вижу несколько направлений для улучшения системы. Во-первых, нужно сделать параметры правил более динамичными — рынок меняется, и система должна адаптироваться. Во-вторых, явно не хватает учета макроэкономики и новостного фона. Да, это усложнит систему, но потенциальный выигрыш того стоит.
Особенно интересным мне кажется направление с адаптивными фильтрами. На разных рыночных фазах явно нужны разные настройки системы. Пока это реализовано довольно грубо, но я уже вижу несколько способов это улучшить.
На следующей неделе планирую начать тестирование новой версии с динамической оптимизацией размера позиций. Предварительные результаты на исторических данных выглядят многообещающе, но реальный рынок, как всегда, внесет свои коррективы.
Заключение
Применение ассоциативных правил в алгоритмическом трейдинге открывает интересные возможности для поиска неочевидных рыночных закономерностей. Ключ к успеху здесь — это правильная подготовка данных, тщательный отбор правил и продуманная система генерации сигналов.
Важно помнить, что любая торговая система требует постоянного мониторинга и адаптации к меняющимся рыночным условиям. Ассоциативные правила — это мощный инструмент анализа, но его нужно использовать в комплексе с другими методами технического и фундаментального анализа.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Видимо, предполагается, что у читающего должны быть уже знания определённые по такому методу, а если их нет?
Мне вот непонятно, что за метрики о которых говорится, в частности:
Lift стал моим любимым индикатором. После сотен часов тестирования я заметил закономерность — правила с lift выше 1.5 действительно работают на реальном рынке. Это открытие серьезно повлияло на мой подход к фильтрации сигналов.
Если я вообще правильно понял метод, то ищутся коррелирующие сигналы по сути в квантовых отрезках. Но я не понял, что дальше. Какая целевая? Предполагаю, что полученные правила проверяются по целевой и происходит их оценка по метрикам.
Если так, то перекликается с моим методом, и интересно оценить производительность и эффективность.