
Разрабатываем мультивалютный советник (Часть 20): Приводим в порядок конвейер этапов автоматической оптимизации проектов (I)
Введение
Напомним, что в рамках данного цикла статей мы пытаемся создать систему автоматической оптимизации, позволяющую без участия человека найти хорошие комбинации параметров одной торговой стратегии, которые затем будут объединены в один итоговый советник. Более детально постановка задачи описана в части 9 и части 11. Сам процесс такого поиска будет управляться одним советником (оптимизирующий советник), и все данные, которые будет необходимо сохранять в процессе его работы, записываются в основную базу данных.
В базе данных у нас есть таблицы для хранения информации о нескольких классах объектов. У некоторых есть поле статуса, которое может принимать значения из фиксированного набора значений ("В очереди", "Выполняется", "Завершён"), но не для всех классов это поле используется. Точнее пока что оно используется только для задач оптимизации (task). Наш оптимизирующий советник ищет в таблице задач (tasks) задачи со статусом "В очереди", чтобы выбрать следующую задачу для запуска. После завершения выполнения каждой задачи её статус в базе данных меняется на "Выполнена".
Давайте попробуем реализовать автоматическое обновление статусов не только для задач, но и для всех остальных классов объектов (работ, этапов, проектов) и организовать автоматическое выполнение всех необходимых этапов вплоть до получения итогового советника, который сможет работать самостоятельно без подключения к базе данных.
Намечаем путь
Первым делом мы внимательно посмотрим на все классы объектов в базе данных, у которых статус есть, и сформулируем чёткие правила смены статуса. Если это получится сделать, то мы можем реализовать эти правила в виде вызова дополнительных SQL-запросов или из оптимизирующего советника, или советников этапов. Либо может быть получится реализовать их в виде триггеров в базе данных, срабатывающих при наступлении определённых событий изменения данных.
Далее надо договориться о способе определения очерёдности выполнения задач. До этого этот вопрос особо не возникал, так как мы в процессе разработки тренировались каждый раз на новой базе данных, и добавляли этапы проекта, работы и задачи как раз в том порядке, в котором они должны были выполняться. Но при переходе к хранению в базе данных информации о нескольких проектах или даже автоматическом добавлении новых проектов, полагаться на такой способ определения порядка очерёдности задач будет уже нельзя. Поэтому какое-то время посвятим этому вопросу.
Чтобы протестировать работу всего конвейера, на котором будут по очереди выполняться все задачи проекта автоматической оптимизации, нам не хватает автоматизации ещё нескольких действий. До этого мы выполняли их вручную. Так, например, после завершения второго этапа оптимизации мы имеем возможность выбрать самые хорошие группы для использования в итоговом советнике. Эту операцию мы выполняли, запуская советник третьего этапа вручную, то есть вне конвейера автоматической оптимизации. Для задания параметров запуска этого советника мы также вручную отбирали идентификаторы проходов второго этапа с лучшими результатами, пользуясь сторонним по отношению к MQL5 интерфейсом доступа к базе данных. Попробуем и с этим что-то сделать.
Так что после внесённых изменений мы рассчитываем сделать наконец полностью готовый конвейер выполнения этапов автоматической оптимизации для получения итогового советника. Попутно рассмотрим ещё некоторые вопросы, связанные с повышением эффективности организации работы. Например, похоже, что советники второго и последующих этапов будут одинаковыми для разных торговых стратегий. Проверим, так ли это. Также посмотрим, что окажется удобнее — создавать разные более мелкие проекты или в более крупном проекте создавать большее количество этапов или работ.
Правила изменения статусов
Начнём с формулирования правил изменения статусов. Напомним, что в нашей базе данных представлена информация о следующих объектах, обладающих полем статуса (status):
- Проект. Объединяет один или несколько этапов, хранится в таблице projects;
- Этап. Объединяет одну или несколько работ, хранится в таблице stages;
- Работа. Объединяет одну или несколько задач, хранится в таблице jobs;
- Задача. Как правило, объединяет множество проходов тестера, хранится в таблице tasks.
Возможные значения статуса одинаковы для каждого из этих четырёх классов объектов, и могут быть одним из следующих:
- Queued. Объект поставлен в очередь на обработку;
- Process. Объект находится в процессе обработки;
- Done. Обработка данного объекта завершена или не начиналась.
Опишем правила изменения статусов объектов в базе данных в соответствии с нормальным циклом конвейера автоматической оптимизации проекта. Цикл начинается, когда проект ставится в очередь на оптимизацию, то есть ему присваивается статус Queued.
Когда статус проекта меняется на Queued:
- устанавливаем статус всех этапов этого проекта равным Queued.
Когда статус этапа меняется на Queued:
- устанавливаем статус всех работ этого этапа равным Queued.
Когда статус работы меняется на Queued:
- устанавливаем статус всех задач этой работы равным Queued.
Когда статус задачи меняется на Queued:
- очищаем дату начала и окончания.
Таким образом, смена статуса проекта на Queued приведёт к каскадному обновлению статусов всех этапов, работ и задач этого проекта на Queued. В этом статусе все эти объекты будут находиться до запуска советника Optimization.ex5.
После запуска должна быть найдена хотя бы одна задача в статусе Queued. Про порядок сортировки, если задач несколько, мы поговорим позже. Этой задаче статус меняется на Process. Это вызывает следующие действия:
Когда статус задачи меняется на Process:
- устанавливаем дату начала равной текущему времени;
- удаляем все проходы, выполненные ранее в рамках данной задачи;
- устанавливаем статус работы, связанной с этой задачей, равным Process.
Когда статус работы меняется на Process:
- устанавливаем статус этапа, связанного с этой работой, равным Process.
Когда статус этапа меняется на Process:
- устанавливаем статус проекта, связанного с этим этапом, равным Process.
После этого в рамках работ этапов проекта будут последовательно выполняться задачи. Дальнейшие изменения статусов могут происходить только после завершения выполнения очередной задачи. В этот момент статус задачи меняется на Done и может повлечь за собой каскадное установление этого статуса и для вышестоящих объектов.
Когда статус задачи меняется на Done:
- устанавливаем дату окончания равной текущему времени;
- получаем список всех задач, входящих в состав работы, в рамках которой выполняется эта задача, и находящихся в статусе Queued. Если таковых нет, то устанавливаем статус работы, связанной с этой задачей, равным Done.
Когда статус работы меняется на Done:
- получаем список всех работ, входящих в состав этапа, в рамках которой выполняется эта работа, и находящихся в статусе Queued. Если таковых нет, то устанавливаем статус этапа, связанного с этой работой, равным Done.
Когда статус этапа меняется на Done:
- получаем список всех этапов, входящих в состав проекта, в рамках которой выполняется этот этап, и находящихся в статусе Queued. Если таковых нет, то устанавливаем статус проекта, связанного с этим этапом, равным Done.
Таким образом, когда будет выполнена последняя задача последней работы последнего этапа, то и сам проект перейдёт в состояние выполненного.
Теперь, когда все правила сформулированы, можно переходить к созданию триггеров в базе данных, реализующих данные действия.
Создание триггеров
Начнём по порядку — с триггера обработки смены статуса проекта на Queued. Вот один из возможных способов его реализации:
CREATE TRIGGER upd_project_status_queued AFTER UPDATE OF status ON projects WHEN NEW.status = 'Queued' BEGIN UPDATE stages SET status = 'Queued' WHERE id_project = NEW.id_project; END;
После его выполнения статусы для этапов данного проекта будут тоже изменены на Queued. Тем самым мы должны запустить соответствующие триггеры для этапов, работ и задач:
CREATE TRIGGER upd_stage_status_queued
AFTER UPDATE
ON stages
WHEN NEW.status = 'Queued' AND
OLD.status <> NEW.status
BEGIN
UPDATE jobs
SET status = 'Queued'
WHERE id_stage = NEW.id_stage;
END;
CREATE TRIGGER upd_job_status_queued
AFTER UPDATE OF status
ON jobs
WHEN NEW.status = 'Queued'
BEGIN
UPDATE tasks
SET status = 'Queued'
WHERE id_job = NEW.id_job;
END;
CREATE TRIGGER upd_task_status_queued
AFTER UPDATE OF status
ON tasks
WHEN NEW.status = 'Queued'
BEGIN
UPDATE tasks
SET start_date = NULL,
finish_date = NULL
WHERE id_task = NEW.id_task;
END; Запуск задачи будет обрабатываться следующим триггером, устанавливающим дату начала выполнения задачи, очищающим данные проходов, полученных в прошлый запуск данной задачи, и обновляющим статус работы на Process:
CREATE TRIGGER upd_task_status_process
AFTER UPDATE OF status
ON tasks
WHEN NEW.status = 'Process'
BEGIN
UPDATE tasks
SET start_date = DATETIME('NOW')
WHERE id_task = NEW.id_task;
DELETE FROM passes
WHERE id_task = NEW.id_task;
UPDATE jobs
SET status = 'Process'
WHERE id_job = NEW.id_job;
END;
Далее каскадно обновляются до Process статусы этапа и проекта, в рамках которых выполняется данная работа:
CREATE TRIGGER upd_job_status_process AFTER UPDATE OF status ON jobs WHEN NEW.status = 'Process' BEGIN UPDATE stages SET status = 'Process' WHERE id_stage = NEW.id_stage; END; CREATE TRIGGER upd_stage_status_process AFTER UPDATE OF status ON stages WHEN NEW.status = 'Process' BEGIN UPDATE projects SET status = 'Process' WHERE id_project = NEW.id_project; END;
В триггере, срабатывающем при обновлении статуса задачи до значения Done, то есть при завершении задачи, мы обновим дату окончания выполнения задачи и затем, в зависимости от наличия или отсутствия других задач в очереди на выполнение в рамках работы текущей задачи, обновим статус работы либо на Process, либо на Done:
CREATE TRIGGER upd_task_status_done
AFTER UPDATE OF status
ON tasks
WHEN NEW.status = 'Done'
BEGIN
UPDATE tasks
SET finish_date = DATETIME('NOW')
WHERE id_task = NEW.id_task;
UPDATE jobs
SET status = (
SELECT CASE WHEN (
SELECT COUNT( * )
FROM tasks t
WHERE t.status = 'Queued' AND
t.id_job = NEW.id_job
)
= 0 THEN 'Done' ELSE 'Process' END
)
WHERE id_job = NEW.id_job;
END; Аналогично поступим и со статусами этапов и проектов:
CREATE TRIGGER upd_job_status_done AFTER UPDATE OF status ON jobs WHEN NEW.status = 'Done' BEGIN UPDATE stages SET status = ( SELECT CASE WHEN ( SELECT COUNT( * ) FROM jobs j WHERE j.status = 'Queued' AND j.id_stage = NEW.id_stage ) = 0 THEN 'Done' ELSE 'Process' END ) WHERE id_stage = NEW.id_stage; END; CREATE TRIGGER upd_stage_status_done AFTER UPDATE OF status ON stages WHEN NEW.status = 'Done' BEGIN UPDATE projects SET status = ( SELECT CASE WHEN ( SELECT COUNT( * ) FROM stages s WHERE s.status = 'Queued' AND s.name <> 'Single tester pass' AND s.id_project = NEW.id_project ) = 0 THEN 'Done' ELSE 'Process' END ) WHERE id_project = NEW.id_project; END;
Предусмотрим также возможность перевести все объекты проекта в состояние Done при установке этого статуса самому проекту. Этот сценарий мы не включили в перечень правил выше, так как это не является обязательным действием при нормальном ходе автоматической оптимизации. В этом триггере мы устанавливаем статус всех невыполненных или выполняющихся задач в Done, что повлечёт за собой установку такого же статуса для всех работ и этапов проекта:
CREATE TRIGGER upd_project_status_done AFTER UPDATE OF status ON projects WHEN NEW.status = 'Done' BEGIN UPDATE tasks SET status = 'Done' WHERE id_task IN ( SELECT t.id_task FROM tasks t JOIN jobs j ON j.id_job = t.id_job JOIN stages s ON s.id_stage = j.id_stage JOIN projects p ON p.id_project = s.id_project WHERE p.id_project = NEW.id_project AND t.status <> 'Done' ); END;
После того, как все эти триггеры созданы, разберёмся, как нам определять очерёдность выполнения задач.
Конвейер
Пока мы работали только с одним проектом в базе данных, поэтому начнём с рассмотрения правил определения очерёдности выполнения задач для этого случая. Когда у нас появится понимание, как определить очерёдность выполнения задач для одного проекта, можно будет подумать уже и об очерёдности выполнения задач для нескольких проектов, запускаемых одновременно.
Очевидно, что задачи оптимизации, относящиеся к одной работе и отличающиеся только критерием оптимизации, можно выполнять в любом порядке: последовательный запуск генетической оптимизации на разных критериях не использует информацию с предыдущих оптимизаций. Использование разных критериев оптимизации используется для повышения разнообразия находимых хороших комбинаций параметров. Было замечено, что процессы генетической оптимизации с одинаковыми диапазонами перебираемых входных параметров, но с разными критериями, сходится к разным комбинациям.
Поэтому добавлять какое-то поле сортировки к таблице задач необходимости нет. Можно использовать тот порядок, в котором задачи одной работы были добавлены в базу данных, то есть сортировать их по id_task.
Если же в рамках одной работы есть только одна задача, то порядок выполнения будет зависеть от порядка выполнения работ. Работы задумывались для группировки или, точнее, разделения задач по разным комбинациям символов и таймфреймов. Если мы рассмотрим пример, что у нас есть три символа (EURGBP, EURUSD, GBPUSD) и два таймфрейма (H1, M30) и два этапа (Stage1, Stage2), то мы можем выбрать два возможных порядка:
- Группировка по символу и таймфрейму:
- EURGBP H1 Stage1
- EURGBP H1 Stage2
- EURGBP M30 Stage1
- EURGBP M30 Stage2
- EURUSD H1 Stage1
- EURUSD H1 Stage2
- EURUSD M30 Stage1
- EURUSD M30 Stage2
- GBPUSD H1 Stage1
- GBPUSD H1 Stage2
- GBPUSD M30 Stage1
- GBPUSD M30 Stage2
- Группировка по этапу:
- Stage1 EURGBP H1
- Stage1 EURGBP M30
- Stage1 EURUSD H1
- Stage1 EURUSD M30
- Stage1 GBPUSD H1
- Stage1 GBPUSD M30
- Stage2 EURGBP H1
- Stage2 EURGBP M30
- Stage2 EURUSD H1
- Stage2 EURUSD M30
- Stage2 GBPUSD H1
- Stage2 GBPUSD M30
При первом способе группировки (по символу и таймфрейму) мы сможем после каждого завершения работы второго этапа получать уже что-то готовое, то есть итоговый советник. В него будут входить наборы одиночных экземпляров торговых стратегий по тем символам и таймфреймам, которые уже прошли оба этапа оптимизации.
При втором способе группировки (по этапу) итоговый советник у нас сможет появиться не раньше, чем закончатся все работы первого этапа и хотя бы одна работа второго этапа.
Для работ, которые используют только результаты предыдущих этапов для такого же символа и таймфрейма, разницы между этими двумя способами не будет. Но если посмотреть немного вперед, то там появится ещё один этап, на котором будут объединяться результаты вторых этапов для разных символов и таймфреймов. Мы просто ещё не дошли до его реализации в виде этапа автоматической оптимизации, но уже подготовили для него советник этапа и даже запускали его, но вручную. Для такого этапа первый способ группировки не подходит, поэтому будем использовать второй способ.
Стоит отметить, что если мы всё-таки захотим использовать первый способ, то, возможно, нам достаточно будет создать несколько проектов для каждой комбинации символа и таймфрейма. Но пока что выгода от этого представляется неясной.
Итак, если у нас есть несколько работ внутри одного этапа, то порядок их выполнения может быть любым, а для работ разных этапов порядок очерёдности будет определяться порядком очерёдности этапов. То есть, как и для задач, добавлять какое-то поле сортировки к таблице работ нет необходимости. Можно использовать тот порядок, в котором работы одного этапа были добавлены в базу данных, то есть сортировать их по id_job.
Для определения очерёдности этапов мы тоже можем воспользоваться уже имеющимися данными в таблице этапов (stages). С самого начала мы добавили в эту таблицу поле родительского этапа (id_parent_stage), но, из-за отсутствия необходимости, пока что им не пользовались. Действительно, когда у нас в таблице всего две строки для двух этапов, нет никакой сложности в том, чтобы создать их в нужном порядке — сначала строку для первого этапа, а потом для второго. Когда же их становится больше, да ещё и появляются этапы для других проектов, то поддерживать вручную правильный порядок становится сложнее.
Поэтому давайте воспользуемся возможностью построить иерархию выполняющихся этапов, когда каждый этап будет выполняться после завершения своего родительского этапа. При этом, хотя бы один этап должен не иметь родителя, чтобы занимать верхнее положение в иерархии. Напишем тестовый SQL-запрос, который будет соединять данные из таблиц задач, работ и этапов и показывать все задачи текущего этапа. В список столбцов этого запроса добавим все поля, чтобы мы видели максимально полную информацию.
SELECT t.id_task,
t.optimization_criterion,
t.status AS task_status,
j.id_job,
j.symbol AS job_symbol,
j.period AS job_period,
j.tester_inputs AS job_tester_inputs,
j.status AS job_status,
s.id_stage,
s.name AS stage,
s.expert AS stage_expert,
s.status AS stage_status,
ps.name AS parent_stage,
ps.status AS parent_stage_status,
p.id_project,
p.status AS project_status
FROM tasks t
JOIN
jobs j ON j.id_job = t.id_job
JOIN
stages s ON s.id_stage = j.id_stage
LEFT JOIN
stages ps ON ps.id_stage = s.id_parent_stage
JOIN
projects p ON p.id_project = s.id_project
WHERE t.id_task > 0 AND
t.status IN ('Queued', 'Process') AND
(ps.id_stage IS NULL OR
ps.status = 'Done')
ORDER BY j.id_stage,
j.symbol,
j.period,
t.status,
t.id_task;

Рис 1. Результаты запроса на получение задач текущего этапа после запуска одной задачи
В дальнейшем мы сократим количество отображаемых столбцов, когда будем использовать подобный запрос для нахождения очередной задачи. А пока убедимся, что мы правильно получаем очередной этап (вместе е его работами и задачами). Показанные на рисунке 1 результаты соответствуют моменту времени, когда была запущена задача с id_task=3, относящаяся к работе с id_job=10, входящей в состав этапа с id_stage=10. Этот этап называется "First", относится к проекту с id_project=1 и не имеет родительского этапа (parent_stage=NULL). Можно заметить, что наличие одной запущенной задачи приводит к появлению статуса Process и у работы и у проекта, в рамках которых эта работа выполняется. Но у другой работы с id_job=5 статус пока что остался равным Queued, так как ни одна задача этой работы ещё не была запущена.
Попробуем теперь завершить первую задачу (просто поставив в таблице в поле status значение Done) и посмотрим на результаты этого же запроса:

Рис 2. Результаты запроса на получение задач текущего этапа после завершения запущенной задачи
Как видно, завершённая задача пропала из этого списка, а самую верхнюю строку занимает теперь другая задача, которую можно запускать следующей. Пока всё верно. Теперь запустим и завершим верхние две задачи из этого списка, а третью задачу с id_task=7 запустим на выполнение:

Рис 3. Результаты запроса на получение задач текущего этапа после завершения задач первой работы и запуска следующей задачи
Теперь уже работа с id_job=5 получила статус Process. Далее мы запустим и завершим эти три задачи, которые сейчас показаны в результатах последнего запроса. Они будут поочерёдно исчезать из результатов запроса. После завершения последней, снова запустим этот запрос и получим следующее:

Рис 4. Результаты запроса на получение задач текущего этапа после завершения всех задач первого этапа
Теперь в результаты запроса попали уже задачи из работ, относящихся к следующим этапам. Этап с id_stage=2 — это кластеризация результатов первого этапа, а этап с id_stage=3 — это второй этап, на котором производится отбор в группы хороших экземпляров торговых стратегий, полученных на первом этапе. Этот этап не использует кластеризацию, поэтому он может запускаться сразу после первого этапа. Таким образом, его присутствие в этом списке не является ошибкой. У обоих этапов родительским является этап с именем "First", который теперь находится в состоянии Done.
Промоделируем запуск и завершение первых двух задач и снова посмотрим на результаты запроса:

Рис 5. Результаты запроса на получение задач после завершения всех задач этапа кластеризации
Верхние строчки результатов ожидаемо заняты двумя задачами второго этапа (с именем "Second"), а вот две последние строки теперь содержат задачи второго этапа с кластеризацией (с именем "Second with clustering"). Их появление несколько неожиданно, но не противоречит допустимому порядку. В самом деле, если мы уже провели этап кластеризации, то можно запускать и этап, который будет использовать результаты кластеризации. Показанные в результатах запроса два этапа независимы друг от друга, поэтому их можно выполнять в любом порядке.
Снова произведём запуск и завершение каждой задачи, выбирая каждый раз самую верхнюю в результатах. Получаемый после каждой смены статуса список задач вёл себя как нужно, статусы работ и этапов менялись правильно. После завершения последней задачи результаты запроса оказались пустыми, так как все поставленные задачи всех работ всех этапов оказались выполненными, и проект перешёл в состояние Done.
Давайте интегрируем этот запрос в оптимизирующий советник.
Модификация оптимизирующего советника
Нам потребуется внести изменения в метод получения идентификатора следующей задачи оптимизатора, где уже есть SQL-запрос, выполняющий эту задачу. Возьмём разработанный выше запрос и уберём из него получение лишних полей, оставив только поле идентификатора задачи id_task. Можно ещё заменить сортировку по паре полей таблицы работ (j.symbol, j.period) на сортировку по идентификатору работы (j.id_job), так как у каждой работы есть только одно значение этих двух полей. В конце добавим ограничение на количество возвращаемых строк. Нам нужно получать только одну строку.
С учётом сказанного, метод GetNextTaskId() станет выглядеть так:
//+------------------------------------------------------------------+ //| Получение идентификатора следующей задачи оптимизации из очереди | //+------------------------------------------------------------------+ ulong COptimizer::GetNextTaskId() { // Результат ulong res = 0; // Запрос на получение очередной задачи оптимизации из очереди string query = "SELECT t.id_task" " FROM tasks t " " JOIN " " jobs j ON j.id_job = t.id_job " " JOIN " " stages s ON s.id_stage = j.id_stage " " LEFT JOIN " " stages ps ON ps.id_stage = s.id_parent_stage " " JOIN " " projects p ON p.id_project = s.id_project " " WHERE t.id_task > 0 AND " " t.status IN ('Queued', 'Process') AND " " (ps.id_stage IS NULL OR " " ps.status = 'Done') " " ORDER BY j.id_stage, " " j.id_job, " " t.status, " " t.id_task" " LIMIT 1;"; // ... тут получаем результат запроса return res; }
Раз уж мы решили поработать с этим файлом, то внесём попутно ещё такую правку: уберём из метода получения количества задач в очереди передачу статуса через параметр метода. Действительно, мы нигде не используем этот метод для получения количества задач со статусом Queued и Process, которые затем будут использованы по отдельности, а не в виде суммы. Поэтому модифицируем SQL-запрос в методе TotalTasks() так, чтобы он всегда возвращал общее количество задач с этими двумя статусами, и уберем входной параметр status у метода:
//+------------------------------------------------------------------+ //| Получение количества задач с заданным статусом | //+------------------------------------------------------------------+ int COptimizer::TotalTasks() { // Результат int res = 0; // Запрос на получение количества задач с заданным статусом string query = "SELECT COUNT(*)" " FROM tasks t" " JOIN" " jobs j ON t.id_job = j.id_job" " JOIN" " stages s ON j.id_stage = s.id_stage" " WHERE t.status IN ('Queued', 'Process') " " ORDER BY s.id_stage, j.id_job, t.status LIMIT 1;"; // ... тут получаем результат запроса return res; }
Сохраним сделанные изменения в файле Optimizer.mqh в текущей папке.
Помимо этих модификаций, нам потребуется ещё исправить в нескольких файлах старое название статуса "Processing" на "Process", так как выше мы договорились использовать именно его.
Ещё отметим на будущее, что желательно предусмотреть возможность получить какую-то информацию об ошибках, которые могли возникнуть в процессе выполнения задачи, запускающей программу на Python. Сейчас при нештатном завершении такой программы оптимизирующий советник просто застревает на этапе ожидания завершения выполнения задачи, а точнее — появления информации в базе данных об этом событии. Если же программа завершилась с ошибкой, то она не смогла обновить статус задачи в базе данных. Поэтому на этом этапе конвейер не сможет продвинуться дальше.
Пока что единственным способом преодолеть такое застревание является повторный ручной запуск программы на Python с заданными в задаче параметрами, анализ причин ошибок, их устранение и повторный запуск, который уже завершается успешно.
Модификация SimpleVolumesStage3.mq5
Далее мы наметили провести автоматизацию третьего этапа, на котором для каждой работы второго этапа (отличающихся использованным символом и таймфреймом) мы выбираем лучший проход для включения в итоговый советник.
Пока что советник третьего этапа принимал в качестве входных параметров список идентификаторов проходов со второго этапа, и нам необходимо было вручную каким-то образом эти идентификаторы выбрать из базы данных. Кроме этого, этот советник выполнял только создание, оценку просадки и сохранение в библиотеку группы из этих проходов. Итоговый советник в результате запуска советника третьего этапа у нас не появлялся, так как было необходимо выполнить ещё ряд действий. К автоматизации этих действий мы вернёмся позже, а пока займёмся модификацией советника третьего этапа.
Для автоматического выбора идентификаторов проходов можно использовать разные способы.
Например, из всех результатов проходов, полученных в рамках одной работы второго этапа, можно выбрать самый лучший по показателю нормированной среднегодовой прибыли. Один такой проход в свою очередь будет являться результатом группы из 16 одиночных экземпляров торговых стратегий. Тогда в итоговый советник войдет группа из нескольких групп экземпляров одиночных стратегий. Если мы взяли три символа и два таймфрейма, то на втором этапе у нас было 6 работ. Тогда на третьем этапе мы получим группу, в которую войдёт 6 * 16 = 96 экземпляров одиночных стратегий. Этот способ является самым простым в реализации.
Примером более сложного способа отбора является такой: для каждой работы второго этапа мы берём некоторое количество самых лучших проходов и пробуем разные сочетания из всех выбранных проходов. Это очень похоже на то, что мы делали на втором этапе, только теперь у нас будет набираться группа не из 16 одиночных экземпляров, а из 6 групп, причём в первую из шести групп мы будем брать один из лучших проходов первой работы, во вторую — один из лучших проходов второй работы и так далее. Этот способ уже сложнее, однако заранее сказать, что это позволит заметно улучшить результаты, нельзя.
Поэтому реализуем сначала более простой способ, а усложнение отложим на более позднее время.
На этом этапе нам уже не понадобится выполнять оптимизацию параметров советника, теперь это будет одиночный проход. Для этого в настройках этапа в базе данных нужно указать соответствующие параметры: в столбце optimization должен стоять 0.

Рис 6. Содержимое таблицы этапов
В коде советника добавим во входные параметры идентификатор задачи оптимизации, чтобы этот советник можно было запускать в конвейере с корректным сохранением результатов прохода в базу данных:
//+------------------------------------------------------------------+ //| Входные параметры | //+------------------------------------------------------------------+ sinput int idTask_ = 0; // - Идентификатор задачи оптимизации sinput string fileName_ = "database911.sqlite"; // - Файл с основной базой данных input group "::: Отбор в группу" input string passes_ = ""; // - Идентификаторы проходов через запятую input group "::: Сохранение в библиотеку" input string groupName_ = ""; // - Название группы (если пустое - не сохранять)
Параметр passes_ можно было бы убрать, но мы пока его оставим на всякий случай. Напишем SQL-запрос, получающий список идентификаторов лучших проходов для работ второго этапа. Если параметр passes_ будет пустым, то мы будем брать идентификаторы лучших проходов. Если же в параметре passes_ мы передадим какие-то конкретные идентификаторы, то будут браться именно они.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Устанавливаем параметры в классе управления капиталом CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); CTesterHandler::TesterInit(idTask_, fileName_); // Строка инициализации с наборами параметров стратегий string strategiesParams = NULL; // Если соединение с основной базой данных установлено, то if(DB::Connect(fileName_)) { // Формируем запрос на получение проходов с указанными идетификаторами string query = (passes_ == "" ? StringFormat("SELECT DISTINCT FIRST_VALUE(p.params) OVER (PARTITION BY p.id_task ORDER BY custom_ontester DESC) AS params " " FROM passes p " " WHERE p.id_task IN (" " SELECT pt.id_task " " FROM tasks t " " JOIN " " jobs j ON j.id_job = t.id_job " " JOIN " " stages s ON s.id_stage = j.id_stage " " JOIN " " jobs pj ON pj.id_stage = s.id_parent_stage " " JOIN " " tasks pt ON pt.id_job = pj.id_job " " WHERE t.id_task = %d " " ) ", idTask_) : StringFormat("SELECT params" " FROM passes " " WHERE id_pass IN (%s);", passes_) ); Print(query); int request = DatabasePrepare(DB::Id(), query); if(request != INVALID_HANDLE) { // Структура для чтения результатов struct Row { string params; } row; // Для всех строк результата запроса, соединяем строки инициализации while(DatabaseReadBind(request, row)) { strategiesParams += row.params + ","; } } DB::Close(); } // ... // Успешная инициализация return(INIT_SUCCEEDED); }
Сохраним сделанные изменения в файле SimpleVolumesStage3.mq5 в текущей папке.
На этом модификация советника третьего этапа завершена. Переведём проект в базе данных в состояние Queued и запустим оптимизирующий советник.
Результаты конвейера оптимизации
Несмотря на то что мы ещё не реализовали все запланированные этапы, сейчас у нас уже есть инструмент, дающий в автоматическом режиме почти готовый итоговый советник. После завершения третьего этапа, в библиотеке параметров (таблице strategy_groups) появилось две записи:

Первая содержит идентификатор прохода, в котором объединены лучшие группы второго этапа без кластеризации. Вторая — идентификатор прохода, в котором объединены лучшие группы второго этапа с кластеризацией. Соответственно, мы можем из таблицы passes для этих идентификаторов проходов получить строки инициализации и посмотреть на результаты таких двух объединений.
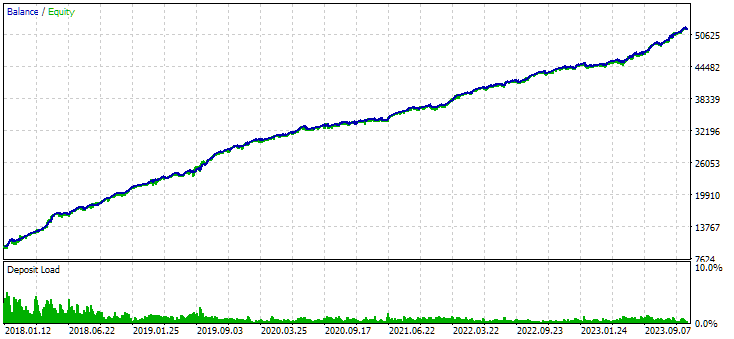
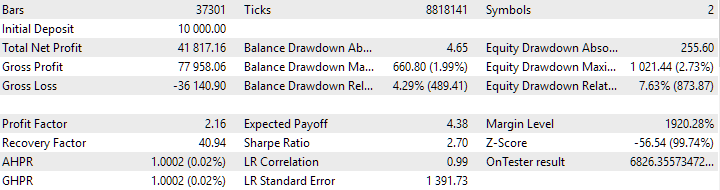
Рис. 7. Результаты объединённой группы экземпляров, полученной без использования кластеризации
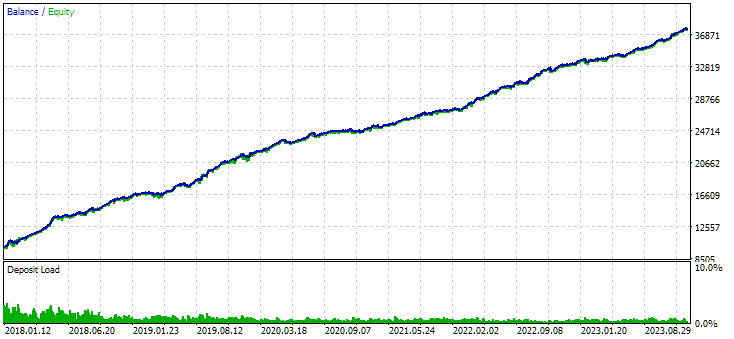
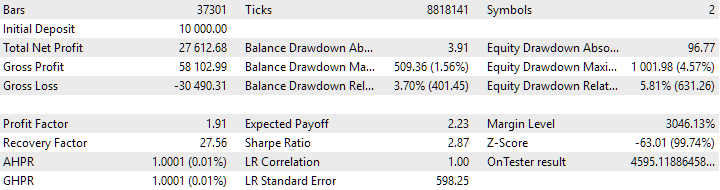
Рис. 8. Результаты объединённой группы экземпляров, полученной с использованием кластеризации
В варианте без кластеризации прибыль получилась больше, зато в варианте с кластеризацией выше коэффициент Шарпа и лучше линейность. Но мы пока не будем детально анализировать эти результаты, так как они ещё не окончательные.
По намеченному плану далее следует добавление этапов сборки итогового советника. Необходимо выполнить экспорт библиотеки для получения включаемого файла ExportedGroupsLibrary.mqh в папке данных. Затем скопировать этот файл в рабочую папку. Эту операцию можно выполнить либо при помощи программы на Python, либо используя системные функции копирования из DLL. На последнем этапе нам остаётся скомпилировать итоговый советник и запустить терминал с новой версией советника.
Всё это потребует заметного времени на реализацию, поэтому продолжим её описание уже в следующей статье.
Заключение
Итак, давайте посмотрим на то, что у нас получилось. Мы привели в порядок автоматическое выполнение первых этапов конвейера автоматической оптимизации, добившись их корректной работы. Мы можем посмотреть на промежуточные результаты и решить, например, отказаться от использования этапа кластеризации. Либо наоборот, оставить его, а убрать вариант без кластеризации.
Наличие такого инструмента поможет нам в дальнейшем провести эксперименты и попытаться ответить на непростые вопросы. Например, предположим, что мы проводим оптимизацию на разных диапазонах входных параметров на первом этапе. Что лучше — объединять их по отдельности или вместе по одинаковым символам и таймфреймам?
Добавляя этапы в конвейер, мы можем реализовать постепенную сборку всё более сложных советников.
Наконец, мы можем подумать над вопросом частичной переоптимизации и даже непрерывной переоптимизации, проведя соответствующий эксперимент. Под переоптимизаций здесь подразумевается повторная оптимизация на другом временном интервале. Но об этом уже в следующий раз.
Спасибо за внимание, до встречи!
Важное предупреждение
Все результаты, изложенные в этой статье и всех предшествующих статьях цикла, основываются только на данных тестирования на истории и не являются гарантией получения хоть какой-то прибыли в будущем. Работа в рамках данного проекта носит исследовательский характер. Все опубликованные результаты могут быть использованы всеми желающими на свой страх и риск.
Содержание архива
| # | Имя | Версия | Описание | Последние изменения |
|---|---|---|---|---|
| MQL5/Experts/Article.16134 | ||||
| 1 | Advisor.mqh | 1.04 | Базовый класс эксперта | Часть 10 |
| 2 | ClusteringStage1.py | 1.01 | Программа кластеризации результатов первого этапа оптимизации | Часть 20 |
| 3 | Database.mqh | 1.07 | Класс для работы с базой данных | Часть 19 |
| 4 | database.sqlite.schema.sql | 1.05 | Схема базы данных | Часть 20 |
| 5 | ExpertHistory.mqh | 1.00 | Класс для экспорта истории сделок в файл | Часть 16 |
| 6 | ExportedGroupsLibrary.mqh | — | Генерируемый файл с перечислением имён групп стратегий и массивом их строк инициализации | Часть 17 |
| 7 | Factorable.mqh | 1.02 | Базовый класс объектов, создаваемых из строки | Часть 19 |
| 8 | GroupsLibrary.mqh | 1.01 | Класс для работы с библиотекой отобранных групп стратегий | Часть 18 |
| 9 | HistoryReceiverExpert.mq5 | 1.00 | Советник воспроизведения истории сделок с риск-менеджером | Часть 16 |
| 10 | HistoryStrategy.mqh | 1.00 | Класс торговой стратегии воспроизведения истории сделок | Часть 16 |
| 11 | Interface.mqh | 1.00 | Базовый класс визуализации различных объектов | Часть 4 |
| 12 | LibraryExport.mq5 | 1.01 | Советник, сохраняющий строки инициализации выбранных проходов из библиотеки в файл ExportedGroupsLibrary.mqh | Часть 18 |
| 13 | Macros.mqh | 1.02 | Полезные макросы для операций с массивами | Часть 16 |
| 14 | Money.mqh | 1.01 | Базовый класс управления капиталом | Часть 12 |
| 15 | NewBarEvent.mqh | 1.00 | Класс определения нового бара для конкретного символа | Часть 8 |
| 16 | Optimization.mq5 | 1.03 | Советник, управляющей запуском задач оптимизации | Часть 19 |
| 17 | Optimizer.mqh | 1.01 | Класс для менеджера автоматической оптимизации проектов | Часть 20 |
| 18 | OptimizerTask.mqh | 1.01 | Класс для задачи оптимизации | Часть 20 |
| 19 | Receiver.mqh | 1.04 | Базовый класс перевода открытых объемов в рыночные позиции | Часть 12 |
| 20 | SimpleHistoryReceiverExpert.mq5 | 1.00 | Упрощённый советник воспроизведения истории сделок | Часть 16 |
| 21 | SimpleVolumesExpert.mq5 | 1.20 | Советник для параллельной работы нескольких групп модельных стратегий. Параметры будут браться из встроенной библиотеки групп. | Часть 17 |
| 22 | SimpleVolumesStage1.mq5 | 1.18 | Советник оптимизации одиночного экземпляра торговой стратегии (Этап 1) | Часть 19 |
| 23 | SimpleVolumesStage2.mq5 | 1.02 | Советник оптимизации группы экземпляров торговых стратегий (Этап 2) | Часть 19 |
| 24 | SimpleVolumesStage3.mq5 | 1.02 | Советник, сохраняющий сформированную нормированную группу стратегий в библиотеку групп с заданным именем. | Часть 20 |
| 25 | SimpleVolumesStrategy.mqh | 1.09 | Класс торговой стратегии с использованием тиковых объемов | Часть 15 |
| 26 | Strategy.mqh | 1.04 | Базовый класс торговой стратегии | Часть 10 |
| 27 | TesterHandler.mqh | 1.05 | Класс для обработки событий оптимизации | Часть 19 |
| 28 | VirtualAdvisor.mqh | 1.07 | Класс эксперта, работающего с виртуальными позициями (ордерами) | Часть 18 |
| 29 | VirtualChartOrder.mqh | 1.01 | Класс графической виртуальной позиции | Часть 18 |
| 30 | VirtualFactory.mqh | 1.04 | Класс фабрики объектов | Часть 16 |
| 31 | VirtualHistoryAdvisor.mqh | 1.00 | Класс эксперта воспроизведения истории сделок | Часть 16 |
| 32 | VirtualInterface.mqh | 1.00 | Класс графического интерфейса советника | Часть 4 |
| 33 | VirtualOrder.mqh | 1.07 | Класс виртуальных ордеров и позиций | Часть 19 |
| 34 | VirtualReceiver.mqh | 1.03 | Класс перевода открытых объемов в рыночные позиции (получатель) | Часть 12 |
| 35 | VirtualRiskManager.mqh | 1.02 | Класс управления риском (риск-менеждер) | Часть 15 |
| 36 | VirtualStrategy.mqh | 1.05 | Класс торговой стратегии с виртуальными позициями | Часть 15 |
| 37 | VirtualStrategyGroup.mqh | 1.00 | Класс группы торговых стратегий или групп торговых стратегий | Часть 11 |
| 38 | VirtualSymbolReceiver.mqh | 1.00 | Класс символьного получателя | Часть 3 |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Hi Yuriy
I have used Google Translate to get me to Part 20. Google "Google Translate" and put it on a new tab in the browser. It will place an icon in the search bar at the far right. Load the page in its native language and press the icon to select the article language and the one to translate into it. Presto,I am at part 20! It does not do a perfect job but the translation is 99% useful.
I loaded your Archive Source into Excel and added a few columns to sort on to arrange the contents. In addition to sorting in Excel, the spreadsheet can be imported into an OutLook database directly
I am having problems identifying the starting article to establish the SQL database. I tried running Simple Volume Stage 1 and got a flat line which indicates to me that I probably need to backtrack and create another SQL data base. It would be extremely helpful to have a table of the order of executions of the necessary programs to get a working system. Perhaps you could add it to the Archive Source table.
Another tiny request is to use the <> option for include file specifications instead of "". I am keeping your system separate in my Experts and Include directories, #include <!! MultiCurrency\VirtualAdvisor.mqh>, so this change will make it easier to add the subdirectory specification/
Thanks for your input
CapeCoddah
Здравствуйте.
Про начальное заполнение базы данных информацией о проекте, этапах, работах и задачах можно посмотреть в частях 13, 18, 19. Это не является основной темой, поэтому нужная вам информация будет где-то ближе к концу статей. Например, в части 18:
Или в части 19:
Или вы можете подождать следующую статью, которая будет посвящена в том числе и вопросу первоначального наполнения базы данных с помощью вспомогательного скрипта.
Переход на использование папки include для хранения файлов библиотек есть в планах, но пока до этого дело не дошло.
Hello.
About the initial filling of the database with information about the project, stages, works and tasks can be found in parts 13, 18, 19. This is not a major topic, so the information you need will be somewhere closer to the end of the articles. For example, in part 18:
Or in part 19:
Or you can wait for the next article, which will be devoted, among other things, to the question of the initial filling of the database using the auxiliary script.
The transition to using the include folder for storing library in the plans, but so far it has not come to it.
many thanks
Hi Yuriy,
Have you submitted the next article or know when it will be published?