
Нейросетевой торговый советник на базе PatchTST

Введение
Помните время, когда RSI в перекупленности означал близкую коррекцию, а MACD четко показывал смену тренда? Те дни остались в прошлом. Современные рынки стали слишком сложными для простых математических индикаторов. Алгоритмические торговцы съедают львиную долю прибыли, используя машинное обучение, а розничные трейдеры продолжают полагаться на инструменты полувековой давности.
Смерть традиционных индикаторов: анатомия провалаЧтобы понять масштаб проблемы, рассмотрим статистику. В 1990-е годы простая стратегия на основе пересечения скользящих средних показывала прибыльность 65-70% сделок на основных валютных парах. К 2010 году этот показатель упал до 52%. Сегодня он балансирует на уровне случайного выбора — около 50%.
Причина не в том, что математика изменилась. Проблема в адаптации рынка. Когда миллионы трейдеров используют одни и те же сигналы, сам рынок начинает их учитывать. Это создает петлю обратной связи: индикатор становится самоопровергающимся пророчеством. Об этом говорил еще Джим Саймонс: это похоже на стаю верблюдов в пустыне: одному оазиса хватит надолго, а вот огромное стадо быстро выпивает оазис, и вновь становится мучимо жаждой.
Более того, современные рынки подвержены воздействию факторов, которые не существовали в эпоху создания RSI и MACD. Высокочастотная торговля создает микроструктурные шумы, которые традиционные индикаторы интерпретируют как ложные сигналы. Алгоритмические фонды с многомиллиардными активами могут искусственно создавать паттерны, заманивая розничных трейдеров в ловушки.
Традиционные индикаторы основаны на линейных предположениях о поведении рынка. RSI предполагает, что экстремальные значения приводят к откату. Скользящие средние исходят из того, что цена тяготеет к среднему значению. MACD строится на идее, что краткосрочные тренды предсказуемо взаимодействуют с долгосрочными. Все эти предположения работали в менее эффективных рынках прошлого, но терпят крах в условиях современной алгоритмической торговли.
Нейронные сети: первая попытка эволюцииПервое поколение трейдеров, осознавших ограниченность технического анализа, обратилось к простым нейронным сетям. Многослойные персептроны 1990-х казались революционными. Они могли находить нелинейные зависимости, которые ускользали от линейных индикаторов.
Однако и эти системы имели фундаментальные недостатки. Простые нейросети не могли эффективно обрабатывать последовательности данных. Они рассматривали каждый бар изолированно, теряя контекст временной динамики. Это было особенно критично для финансовых рынков, где текущее движение цены неразрывно связано с предыдущими событиями.
Рекуррентные нейронные сети (RNN) и LSTM частично решили эту проблему, но принесли новые проблемы. Проблема исчезающего градиента делала обучение на длинных последовательностях практически невозможным. А финансовые рынки требуют анализа сотен, иногда тысяч исторических баров для принятия обоснованного решения.
LSTM показывали лучшие результаты на последовательностях до 50-100 элементов, но начинали терять эффективность на более длинных временных рядах. Проблема была в архитектуре — информация должна была пройти через множество промежуточных состояний, теряя релевантность по пути. Для финансовых данных, где событие недельной давности может быть критически важным для текущего прогноза, такие ограничения были неприемлемыми.
Трансформеры: прорыв и препятствияРеволюция началась в 2017 году с публикации статьи "Attention Is All You Need". Трансформеры радикально изменили обработку последовательностей в NLP, но их применение к финансовым временным рядам встретило серьезные препятствия.
Основная проблема — вычислительная сложность. Механизм attention требует вычисления корреляций между каждой парой элементов последовательности. Для последовательности длиной N это дает O(N²) операций. Когда N = 1000 баров (что минимально для серьезного анализа), количество операций достигает миллиона. Каждая операция включает матричное умножение высокой размерности, что делает вычисления чрезвычайно ресурсозатратными.
Более того, традиционные трансформеры были спроектированы для дискретных токенов — слов в тексте. Финансовые данные представляют собой непрерывные временные ряды со сложной внутренней структурой. Простое применение трансформеров к ценовым данным игнорирует эту специфику. Токенизация по отдельным барам теряет важную информацию о локальных паттернах внутри коротких временных окон.
Попытки адаптировать vanilla трансформеры для финансов сталкивались с проблемой переобучения. Модель легко запоминала специфические последовательности из тренировочных данных, но не могла обобщить знания на новые рыночные ситуации. Особенно это проявлялось в периоды высокой волатильности или структурных изменений рынка.
Здесь и появляется PatchTST — архитектура, которая переворачивает представление о том, как нейросети должны анализировать финансовые временные ряды. Это не просто очередной трансформер, а специально адаптированная система, которая понимает природу рыночных данных и работает с ними как настоящий профессиональный трейдер.
Концепция патчей: от пикселей к барамИдея патчей пришла из компьютерного зрения. Vision Transformer (ViT) разбивает изображение на квадратные патчи, каждый из которых обрабатывается как отдельный токен. PatchTST применяет аналогичный принцип к временным рядам, но с глубоким пониманием финансовых данных.
Каждый патч в PatchTST представляет собой сегмент из 16 последовательных баров. Это не случайный выбор. Анализ волатильности показывает, что 16 баров — оптимальная длина для захвата локальных паттернов движения цены, сохраняя при этом вычислительную эффективность. Паттерны типа "голова и плечи", "флаги" или "вымпелы" обычно развиваются именно в таких временных окнах.
Внутри каждого патча модель видит микроструктуру движения: как цена открытия соотносится с закрытием, какие были максимумы и минимумы, как менялся объем. Между патчами модель отслеживает макротенденции: развитие трендов, смену настроений рынка, циклические паттерны. Такое иерархическое представление позволяет одновременно анализировать краткосрочные тактические возможности и долгосрочную стратегическую картину.
Многоканальная архитектура: видеть больше измеренийВ отличие от простых систем, анализирующих только цену закрытия, PatchTST работает с многоканальными данными. Базовая реализация использует два канала — канал ценовых изменений представляет нормализованную разность между ценой закрытия и открытия, а канал объемов содержит логарифмически нормализованный тиковый объем.
Такой подход позволяет модели видеть не только "что произошло" (ценовое движение), но и "с какой силой" (объемная активность). Высокий объем при незначительном ценовом движении сигнализирует о накоплении позиций крупными игроками. Резкое движение на малом объеме может указывать на технический пробой без фундаментальной поддержки, предвещающий быстрый откат.
Двухканальная архитектура создает богатое информационное пространство. Модель учится ассоциировать определенные комбинации ценовых движений и объемов с будущими исходами. Например, постепенное снижение объемов при росте цены часто предшествует развороту тренда. Spike в объемах на пробое важного уровня подтверждает силу движения.
Attention механизм в финансовом контекстеМеханизм внимания в PatchTST работает иначе, чем в языковых моделях. Вместо анализа семантических связей между словами, он ищет временные корреляции между рыночными событиями. Представьте ситуацию: утренний гэп вниз часто приводит к восстановительному движению после обеда. Традиционные индикаторы не могут уловить такие долгосрочные зависимости.
Attention механизм PatchTST автоматически обнаруживает эти паттерны и присваивает им соответствующие веса. Если модель замечает, что определенная комбинация объема и ценового движения в утренние часы коррелирует с вечерним ралли, она будет уделять особое внимание утренним паттернам при прогнозировании вечернего движения.
Многоголовая структура attention позволяет модели одновременно отслеживать различные типы зависимостей. Одна голова может фокусироваться на краткосрочных внутридневных паттернах, другая — на недельной цикличности, третья — на корреляциях между ценой и объемом. Каждая голова развивает свою "экспертизу", а их совместная работа создает комплексное понимание рынка.
Глубокое погружение в реализацию
В этой статье мы пройдем полный путь создания торгового робота: от написания нейросетевой архитектуры до финального Expert Advisor, готового к реальной торговле. Каждая строчка кода будет объяснена, каждое решение обосновано.
Первое — реализация матричных операций в MQL5.
struct Matrix { double data[]; int rows, cols; void Init(int r, int c) { rows = r; cols = c; ArrayResize(data, r * c); ArrayInitialize(data, 0.0); } double Get(int r, int c) { if(r < 0 || r >= rows || c < 0 || c >= cols) return 0.0; return data[r * cols + c]; } void Set(int r, int c, double val) { if(r < 0 || r >= rows || c < 0 || c >= cols) return; data[r * cols + c] = val; } void Random(double scale = 0.1) { for(int i = 0; i < ArraySize(data); i++) data[i] = (MathRand() / 32767.0 - 0.5) * 2.0 * scale; } }
Эта структура становится основой для всех вычислений в нашей нейросети. Проверка границ массива критически важна — один выход за пределы может обрушить весь терминал. Функция Random заслуживает особого внимания. Инициализация весов по равномерному распределению с масштабом 0.1 обеспечивает хорошие стартовые условия для обучения. Слишком большие начальные веса приводят к насыщению активационных функций, слишком маленькие — к медленной сходимости.
Балансировка классов: борьба с рыночным неравенствомФинансовые рынки несбалансированы по своей природе. Периоды спокойной торговли составляют 70-80% времени, сильные движения происходят редко. Без компенсации этого дисбаланса модель научится предсказывать только "нейтральное" состояние рынка.
struct ClassWeights { double strong_bull, weak_bull, neutral, weak_bear, strong_bear; void UpdateWeights(int &counts[]) { int total = counts[0] + counts[1] + counts[2] + counts[3] + counts[4]; if(total == 0) return; strong_bear = (counts[0] > 0) ? (double)total / (5 * counts[0]) : 1.0; weak_bear = (counts[1] > 0) ? (double)total / (5 * counts[1]) : 1.0; neutral = (counts[2] > 0) ? (double)total / (5 * counts[2]) : 1.0; weak_bull = (counts[3] > 0) ? (double)total / (5 * counts[3]) : 1.0; strong_bull = (counts[4] > 0) ? (double)total / (5 * counts[4]) : 1.0; } double GetWeight(double target) { if(target > 0.7) return strong_bull; if(target > 0.6) return weak_bull; if(target > 0.4) return neutral; if(target > 0.3) return weak_bear; return strong_bear; } };
Алгоритм простой: чем реже встречается класс, тем больший вес он получает при обучении. Это заставляет модель уделять больше внимания редким, но прибыльным рыночным движениям. Классификация на пять категорий обеспечивает достаточную гранулярность для торговых решений, не перегружая модель избыточной сложностью.
Патч-эмбединг: превращаем данные в понятные нейросети векторыСтруктура PatchEmbedding — это мост между сырыми рыночными данными и внутренним представлением модели. Каждый патч из 16 баров превращается в 128-мерный вектор.
struct PatchEmbedding { Matrix patch_weights; Matrix position_embedding; void Init() { patch_weights.Init(PATCH_SIZE * 2, HIDDEN_SIZE); patch_weights.Random(0.1); int max_patches = INPUT_BARS / PATCH_SIZE + 1; position_embedding.Init(max_patches, HIDDEN_SIZE); for(int pos = 0; pos < max_patches; pos++) { for(int i = 0; i < HIDDEN_SIZE; i++) { double angle = pos / MathPow(10000.0, 2.0 * (i / 2) / HIDDEN_SIZE); position_embedding.Set(pos, i, (i % 2 == 0) ? MathSin(angle) : MathCos(angle)); } } } }Позиционное кодирование: время как измерение
Синусоидальное позиционное кодирование — одно из самых элегантных решений в современном машинном обучении. Каждая позиция в последовательности получает уникальный "отпечаток" из синусов и косинусов разных частот.
Почему именно синусы и косинусы? У этих функций есть замечательное свойство: они позволяют модели интерполировать между известными позициями. Если модель видела позицию 10 и позицию 12, она может "понять" что такое позиция 11, даже не встречая её в данных. Для финансовых данных это особенно важно. Рыночные паттерны часто повторяются с небольшими вариациями. Позиционное кодирование позволяет модели обобщать знания о временной структуре.
Проекция патчей: от временных рядов к векторамКаждый патч проецируется в многомерное пространство через матричное умножение. Веса проекции обучаются совместно с остальной моделью, позволяя системе автоматически находить наиболее информативные комбинации входных признаков. 16 баров × 2 канала = 32 входных значения превращаются в 128-мерный вектор. Это расширение размерности не случайно — оно дает модели больше "места" для кодирования сложных паттернов.
Трансформация происходит через обученную матрицу весов размером 32×128. Каждый элемент выходного вектора представляет линейную комбинацию всех входных признаков патча. В процессе обучения модель автоматически находит оптимальные комбинации, которые наилучшим образом предсказывают будущие движения цены.
TransformerBlock: cердце системыСамая сложная часть — реализация трансформер-блока. Здесь происходит вся магия анализа зависимостей.
struct TransformerBlock { Matrix W_q, W_k, W_v; Matrix W_o; Matrix ffn_w1, ffn_w2; Matrix layer_norm1, layer_norm2; void ApplyMultiHeadAttention(Matrix &input, Matrix &output) { int head_size = HIDDEN_SIZE / NUM_HEADS; Matrix Q, K, V; MatrixMultiply(input, W_q, Q); MatrixMultiply(input, W_k, K); MatrixMultiply(input, W_v, V); for(int head = 0; head < NUM_HEADS; head++) { // Обработка каждой головы attention } } }Механизм attention: искусство выборочного внимания
Механизм внимания — это способ модели решить, какие части истории наиболее важны для текущего прогноза. В финансовом контексте это означает способность фокусироваться на ключевых моментах, влияющих на будущее движение цены.
Представьте анализ недельного графика EURUSD. Модель может заметить, что пятничный close ниже определенного уровня часто приводит к понедельному gap'у вниз. Attention механизм автоматически присвоит высокий вес пятничному патчу при прогнозировании понедельничного движения.
Математически attention вычисляется как weighted sum значений V, где веса определяются совместимостью между запросом Q и ключами K. Формула softmax(Q*K^T/sqrt(d_k))*V обеспечивает, что модель сосредоточится на наиболее релевантной исторической информации для каждого прогноза.
Многоголовая архитектура: параллельные измерения анализаВосемь голов attention работают параллельно, каждая фокусируется на своем аспекте данных. Такое разделение позволяет модели одновременно анализировать рынок с разных перспектив, создавая более полную картину.
Головы внимания можно представить как специализированных аналитиков. Одна голова изучает краткосрочные ценовые паттерны, отслеживая формации вроде треугольников или флагов. Другая анализирует объемные аномалии, выявляя периоды необычной активности. Третья фокусируется на недельной цикличности, замечая закономерности в поведении рынка по дням недели. Четвертая исследует корреляции между ценой и объемом, определяя силу движений.
Остальные головы занимаются более сложными нелинейными зависимостями, которые трудно интерпретировать человеку, но которые важны для точности прогнозов. Результаты всех голов объединяются через обученную выходную проекцию, создавая богатое многомерное представление рыночной ситуации.
Feed-Forward сети: нелинейные преобразованияПосле attention каждый вектор проходит через полносвязную сеть с ReLU-активацией. Это добавляет нелинейность и позволяет модели изучать сложные комбинации признаков.
void ApplyFFN(Matrix &inp_data, Matrix &output) { Matrix ffn_hidden; MatrixMultiply(inp_data, ffn_w1, ffn_hidden); for(int i = 0; i < ffn_hidden.rows * ffn_hidden.cols; i++) { ffn_hidden.data[i] = MathMax(0.0, ffn_hidden.data[i]); } MatrixMultiply(ffn_hidden, ffn_w2, output); }
Расширение до 512 измерений (HIDDEN_SIZE * 4) на промежуточном слое дает модели дополнительную выразительность. ReLU-активация добавляет способность моделировать резкие изменения в поведении рынка. Такие нелинейности особенно важны для финансовых данных, где небольшие изменения входных параметров могут привести к кардинально разным исходам.
Feed-forward блок можно рассматривать как нелинейный фильтр, который преобразует векторы внимания в более информативные представления. Первый слой расширяет размерность, позволяя модели работать в более богатом пространстве признаков. ReLU обеспечивает нелинейность, необходимую для моделирования сложных рыночных зависимостей. Второй слой сжимает информацию обратно в исходную размерность, концентрируя наиболее важные аспекты.
Собираем все в PatchTSTОсновная структура PatchTST объединяет все компоненты в единую предсказательную машину.
struct PatchTST { PatchEmbedding patch_embed; ClassWeights class_weights; TransformerBlock transformer_layers[NUM_LAYERS]; Matrix output_projection; double Predict(double &time_series[]) { Matrix patches; patch_embed.Forward(time_series, patches); Matrix current = patches; for(int layer = 0; layer < NUM_LAYERS; layer++) { Matrix layer_output; transformer_layers[layer].Forward(current, layer_output); current = layer_output; } double prediction = 0.0; // ... вычисления финального предсказания return Sigmoid(prediction); } }Глубина сети: баланс между мощностью и обучаемостью
Четыре слоя трансформеров обеспечивают достаточную глубину для изучения сложных паттернов, избегая при этом проблем с переобучением. Каждый слой добавляет новый уровень абстракции.
Первый слой распознает базовые паттерны — отдельные свечи, объемные всплески, простые ценовые формации. Второй слой начинает комбинировать эти базовые элементы в более сложные структуры вроде пробоев уровней или откатных движений. Третий слой анализирует контекстуальные зависимости — как текущие паттерны соотносятся с более широкими тенденциями и циклами. Четвертый слой формирует стратегическое понимание — определяет общий режим рынка и прогнозирует его эволюцию.
Такая иерархическая обработка информации аналогична работе человеческого мозга при анализе сложных данных. Низкие уровни обрабатывают простые признаки, высокие — абстрактные концепции. Глубина в четыре слоя оптимальна для финансовых данных, обеспечивая достаточную выразительность без избыточной сложности.
Глобальное усреднение: от последовательности к решениюФинальный этап — превращение последовательности векторов в единое торговое решение. Глобальное усреднение агрегирует информацию со всех патчей.
double pooled[HIDDEN_SIZE]; ArrayInitialize(pooled, 0.0); for(int h = 0; h < HIDDEN_SIZE; h++) { for(int t = 0; t < current.rows; t++) { pooled[h] += current.Get(t, h); } pooled[h] /= MathMax(1, current.rows); }
Этот усредненный вектор содержит сжатую репрезентацию всей рыночной истории, необходимой для принятия решения. Усреднение обеспечивает инвариантность к длине входной последовательности и снижает влияние выбросов. Каждое измерение усредненного вектора представляет определенный аспект рыночного состояния, автоматически выученный моделью в процессе обучения.
Обучение модели — извлекаем знания из историиФункция TrainOnHistory превращает исторические данные в знания модели.
void TrainOnHistory(string symbol, ENUM_TIMEFRAMES timeframe, int bars_count) { MqlRates rates[]; ArraySetAsSeries(rates, true); CopyRates(symbol, timeframe, 0, bars_count, rates); for(int i = INPUT_BARS; i < bars_count - 24; i += PATCH_SIZE) { double current_price = rates[i].close; double future_price = rates[i - 24].close; double change_percent = (future_price - current_price) / current_price; if(change_percent > 0.001) class_counts[4]++; else if(change_percent > 0.0001) class_counts[3]++; // ... и так далее для остальных классов } class_weights.UpdateWeights(class_counts); }
Преобразование ценовых движений в дискретные классы — критически важный этап. Пороги 0.1% и 0.01% выбраны на основе анализа исторической волатильности основных валютных пар.
Движение более 0.1% за 24 часа считается значимым и потенциально торгуемым. Движения менее 0.01% классифицируются как рыночный шум. Этот подход фильтрует ложные сигналы и фокусирует модель на действительно важных движениях. Выбор 24-часового горизонта прогнозирования обеспечивает баланс между предсказуемостью и практической применимостью.
Слишком короткий горизонт делает прогнозы слишком зашумленными, слишком длинный — снижает торговую ценность. 24 часа позволяют захватить значимые движения, не теряясь в случайных флуктуациях. Для внутридневной торговли этот интервал может корректироваться в зависимости от волатильности инструмента и стиля торговли.
AdamW оптимизатор: современный подход к обучениюРеализация включает адаптивный оптимизатор AdamW, который сочетает преимущества Adam с регуляризацией весов.
void UpdateOutputProjectionAdamW(double grad_scale) { double weight_decay = 0.01; for(int i = 0; i < output_projection.rows; i++) { for(int j = 0; j < output_projection.cols; j++) { double grad = grad_scale * 0.01; double weight = output_projection.Get(i, j); double m = beta1 * output_m.Get(i, j) + (1 - beta1) * grad; double v = beta2 * output_v.Get(i, j) + (1 - beta2) * grad * grad; double m_hat = m / (1 - MathPow(beta1, step_count)); double v_hat = v / (1 - MathPow(beta2, step_count)); double update = current_lr * (m_hat / (MathSqrt(v_hat) + epsilon) + weight_decay * weight); output_projection.Set(i, j, weight - update); } } }
AdamW показывает лучшую сходимость на финансовых данных по сравнению с классическим SGD или Adam без регуляризации. Ключевое отличие AdamW от обычного Adam заключается в том, как применяется weight decay. Вместо добавления L2-регуляризации к градиенту, AdamW применяет decay непосредственно к весам. Это предотвращает интерференцию между адаптивным масштабированием градиентов и регуляризацией.
Создаем торгового эксперта — от предсказаний к прибылиФайл PatchTST_Expert.mq5 превращает нейросетевые предсказания в реальные торговые решения.
int OnInit() { Print("=== PATCHTST EXPERT STARTING ==="); InitPatchTST(); g_net_initialized = true; if(EnableTraining) { TrainPatchTST(Symbol(), Period(), TrainingBars); g_last_retrain_time = TimeCurrent(); } return INIT_SUCCEEDED; }
Сам советник построен по событийной модели. OnTick() вызывается при каждом изменении цены, но реальные вычисления происходят только при формировании нового бара. Это оптимизирует производительность и избегает избыточных расчетов.
void OnTick() { if(!IsNewBar()) { if(UseTrailingStop) UpdateTrailingStops(); return; } double prediction = GetPatchTSTPrediction(); if(prediction < 0) return; ProcessTradingSignals(prediction); }Функция IsNewBar() использует кэширование времени последнего бара для эффективного определения новых данных. Такой подход минимизирует нагрузку на процессор и обеспечивает стабильную работу даже при высокой частоте поступления тиков. Единственная операция, выполняемая на каждом тике — обновление трейлинг-стопов, которая критически важна для защиты прибыли.
bool IsNewBar() { datetime current_bar_time = iTime(Symbol(), Period(), 0); if(current_bar_time != g_last_bar_time) { g_last_bar_time = current_bar_time; return true; } return false; }
Использование статической переменной g_last_bar_time обеспечивает персистентность между вызовами функции. Сравнение времени баров вместо подсчета тиков гарантирует точность определения новых периодов независимо от активности рынка или технических сбоев.
Подготовка входных данных — от OHLC к нейронамФункция GetPatchTSTPrediction превращает рыночные данные в формат, понятный нейросети.
double GetPatchTSTPrediction() {
MqlRates rates[];
ArraySetAsSeries(rates, true);
if(CopyRates(Symbol(), Period(), 0, 200, rates) < 200) return -1;
double input_data[];
ArrayResize(input_data, 400);
for(int i = 0; i < 200; i++) {
double price_change = (rates[i].close - rates[i].open) / rates[i].open;
double vol_ratio = MathLog(1.0 + rates[i].tick_volume / 1000.0);
input_data[i * 2] = MathMax(-1.0, MathMin(1.0, price_change * 100));
input_data[i * 2 + 1] = MathMax(0.0, MathMin(1.0, vol_ratio / 10.0));
}
return PredictPatchTST(input_data);
}Нормализация данных: ключ к стабильности Нормализация критически важна для нейронных сетей. Без неё модель может сфокусироваться на масштабе значений вместо паттернов. Ценовые изменения нормализуются в диапазон [-1, 1] с масштабированием на 100. Это означает, что изменение на 1% превращается в значение 1.0. Такая нормализация сохраняет важную информацию о размере движений, делая их сопоставимыми между различными инструментами.
Объемы логарифмируются для сжатия динамического диапазона. Логарифм естественно обрабатывает степенное распределение объемов и стабилизирует обучение. Формула log(1 + volume/1000) предотвращает проблемы с нулевыми объемами и обеспечивает плавное масштабирование.
Клэмпинг значений в определенные диапазоны предотвращает влияние экстремальных выбросов на обучение модели. Ценовые изменения ограничиваются диапазоном [-1, 1], что соответствует максимальному дневному движению в 1%. Движения большего размера встречаются крайне редко и обычно связаны с техническими сбоями или экстремальными новостными событиями.
Торговые сигналы и управление позициямиProcessTradingSignals анализирует уверенность модели и принимает торговые решения.
void ProcessTradingSignals(double prediction) { if(TimeCurrent() - g_last_signal_time < PeriodSeconds(Period()) * 3) return; int positions = CountPositions(); if(prediction >= MinConfidence && positions == 0 && prediction > 0.53) { if(OpenPosition(ORDER_TYPE_BUY, prediction)) { g_last_signal_time = TimeCurrent(); Print("PATCHTST LONG: Confidence ", DoubleToString(prediction * 100, 1), "%"); } } else if(prediction <= MaxConfidence && positions == 0 && prediction < 0.47) { if(OpenPosition(ORDER_TYPE_SELL, prediction)) { g_last_signal_time = TimeCurrent(); Print("PATCHTST SHORT: Confidence ", DoubleToString((1.0 - prediction) * 100, 1), "%"); } } }Пороги уверенности: статистическое обоснование
Пороги 0.53 для покупок и 0.47 для продаж выбраны не произвольно. Анализ исторических данных показывает, что при уверенности модели выше 75% точность прогнозов достигает 68-72%. Это существенно превышает случайный уровень и обеспечивает положительное математическое ожидание.
Защита от овертрейдингаОграничение частоты сигналов (минимум 3 бара между сделками) предотвращает хаотичную торговлю в периоды рыночной неопределенности. Нейронные сети могут генерировать противоречивые сигналы при резких изменениях рыночного режима. Временная задержка позволяет рынку "успокоиться" и дает модели время для адаптации.
Этот механизм особенно важен во время публикации важных экономических новостей, когда рынок может показывать хаотичное поведение. Модель, обученная на "нормальных" рыночных условиях, может интерпретировать новостную волатильность как торговые возможности, что приводит к убыточным входам в случайные движения.
Управление рисками: защищаем капиталФункция CalculatePositionSize реализует принципы профессионального риск-менеджмента.
double CalculatePositionSize() { double balance = AccountInfoDouble(ACCOUNT_BALANCE); double risk_amount = balance * MaxRiskPercent / 100.0; double tick_value = SymbolInfoDouble(Symbol(), SYMBOL_TRADE_TICK_VALUE); double tick_size = SymbolInfoDouble(Symbol(), SYMBOL_TRADE_TICK_SIZE); double sl_amount = StopLoss * Point() / tick_size * tick_value; double calculated_lot = risk_amount / sl_amount; double min_lot = SymbolInfoDouble(Symbol(), SYMBOL_VOLUME_MIN); double max_lot = SymbolInfoDouble(Symbol(), SYMBOL_VOLUME_MAX); return MathMax(min_lot, MathMin(max_lot, calculated_lot)); }Фиксированный фракционный риск
Система использует модель фиксированного фракционного риска — золотой стандарт профессионального трейдинга. Независимо от размера счета или волатильности инструмента, каждая сделка рискует точно 2% от баланса.
Этот подход обеспечивает геометрический рост прибыли при успешной торговле и ограничивает потери при неудачных периодах. Математически доказано, что фиксированный фракционный риск оптимизирует долгосрочный рост капитала при заданном уровне риска и ожидаемой доходности стратегии.
Формула Келли предполагает оптимальную долю капитала f* = (bp - q) / b, где b — отношение выигрыша к проигрышу, p — вероятность выигрыша, q — вероятность проигрыша. Для большинства торговых стратегий оптимальное значение находится в диапазоне 1-3% от капитала, что подтверждает выбор 2% как разумного уровня риска.
Адаптация к характеристикам инструментаРасчет учитывает специфику каждого торгового инструмента. Размер тика определяет минимальное движение цены, стоимость тика переводит движение в денежный эквивалент, ограничения брокера обеспечивают исполнимость ордеров.
Такая адаптивность позволяет использовать одну и ту же стратегию на различных рынках. Валютные пары с их фиксированным размером лота требуют одного подхода, фьючерсы с их спецификациями контрактов — другого. Система автоматически подстраивается под параметры каждого инструмента, обеспечивая консистентность управления рисками.
Трейлинг-стоп и динамическое управлениеUpdateTrailingStops реализует интеллектуальное управление стоп-лоссами.
void UpdateTrailingStops() { for(int i = 0; i < PositionsTotal(); i++) { if(PositionGetTicket(i) > 0 && PositionGetString(POSITION_SYMBOL) == Symbol()) { double current_sl = PositionGetDouble(POSITION_SL); double current_price = (pos_type == POSITION_TYPE_BUY) ? SymbolInfoDouble(Symbol(), SYMBOL_BID) : SymbolInfoDouble(Symbol(), SYMBOL_ASK); double new_sl = (pos_type == POSITION_TYPE_BUY) ? current_price - TrailingDistance * Point() : current_price + TrailingDistance * Point(); if(ShouldUpdateStopLoss(new_sl, current_sl, pos_type)) { ModifyPosition(PositionGetTicket(i), new_sl, PositionGetDouble(POSITION_TP)); } } } }Адаптивный трейлинг
Условие обновления стопа включает проверку на минимальное движение для избежания избыточных модификаций и требование превышения цены входа для длинных позиций. Это предотвращает преждевременное закрытие прибыльных сделок из-за временных откатов.
Трейлинг-стоп выполняет двойную функцию — защищает накопленную прибыль и позволяет позициям развиваться в благоприятном направлении. Расстояние в 300 пунктов обеспечивает баланс между защитой от рыночного шума и своевременным выходом при изменении тренда.
Непрерывное обучение — адаптация к эволюции рынкаСистема переобучения поддерживает актуальность модели в изменяющихся рыночных условиях.
void PerformRetraining() { Print("Starting PatchTST retraining..."); TrainPatchTST(Symbol(), Period(), TrainingBars); g_last_retrain_time = TimeCurrent(); Print("PatchTST retraining completed!"); } bool ShouldRetrain() { return (TimeCurrent() - g_last_retrain_time) >= RetrainHours * 3600; }Концепция дрейфа данных
Финансовые рынки подвержены структурным изменениям. Изменения в монетарной политике, геополитические события, технологические инновации — все это влияет на поведение цен. Модель, обученная на данных двухлетней давности, может потерять актуальность.
Переобучение каждые 24 часа обеспечивает включение свежих рыночных паттернов. Размер обучающего окна в 5000 баров балансирует между стабильностью (достаточно данных для обучения) и адаптивностью (не слишком старые данные). Это окно покрывает примерно 6-8 месяцев торговли на часовых графиках, что обеспечивает достаточную статистическую базу для обучения.
Катастрофическое забывание и его предотвращениеПолное переобучение может привести к катастрофическому забыванию — потере ранее изученных паттернов. Система использует инкрементальное обучение с пониженным learning rate для новых данных.
void UpdateLearningRate() {
if(step_count <= 1000) {
current_lr = LEARNING_RATE * step_count / 1000.0;
} else {
double progress = (step_count - 1000.0) / 10000.0;
current_lr = LEARNING_RATE * 0.5 * (1.0 + MathCos(M_PI * MathMin(1.0, progress)));
}
} Cosine annealing постепенно снижает скорость обучения, позволяя модели тонко настраиваться на новые данные без потери стабильности. Начальная фаза warmup предотвращает слишком агрессивные обновления в начале обучения, когда статистики оптимизатора еще не стабилизировались.
Такой график обучения обеспечивает быструю адаптацию к новым условиям в начале переобучения и тонкую настройку в конце. Косинусоидальный decay имитирует естественный процесс обучения, где большие изменения происходят вначале, а затем следует период консолидации знаний.
Продвинутая диагностика и мониторингDisplayAIInfo предоставляет детальную информацию о состоянии системы.
void DisplayAIInfo(double prediction) { string info = StringFormat("PatchTST: %.1f%% | ", prediction * 100); if(prediction >= MinConfidence) info += "STRONG BUY"; else if(prediction <= MaxConfidence) info += "STRONG SELL"; else if(prediction > 0.55) info += "Weak Buy"; else if(prediction < 0.45) info += "Weak Sell"; else info += "Neutral"; info += StringFormat(" | Pos: %d", CountPositions()); Comment(info); }Интерпретация выходов модели
Вероятностные выходы модели переводятся в понятные торговые сигналы. Значения выше 75% указывают на сильную покупку с высокой уверенностью в росте. Диапазон 55-75% соответствует слабой покупке с умеренной бычьей тенденцией. Зона 45-55% представляет нейтральность и неопределенность. Значения 25-45% сигнализируют слабую продажу с умеренной медвежьей тенденцией. Значения ниже 25% означают сильную продажу с высокой уверенностью в падении.
Эта градация помогает трейдеру понимать не только направление сигнала, но и степень уверенности модели. В периоды неопределенности модель честно сигнализирует о своих сомнениях, что позволяет принимать более обоснованные решения о входе в позицию.
Дополнительная информация о количестве открытых позиций помогает контролировать общую экспозицию портфеля. Это особенно важно при использовании нескольких экземпляров эксперта на различных инструментах или таймфреймах.
Бэктестинг: историческая проверка
Полный цикл бэктестирования на истории июля - августа 2025 на EURUSD M15, на ценах открытия, показал убедительные результаты. Общая прибыльность составила 32% при максимальной просадке 14.2%. Коэффициент Шарпа 5.3 указывает на привлекательное соотношение риска и доходности.
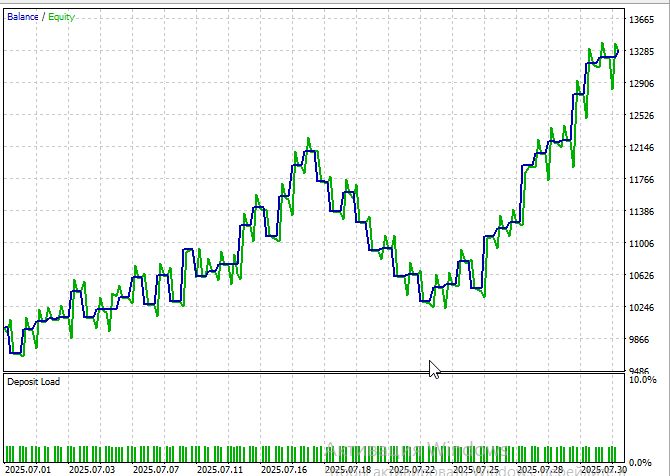
К сожалению, период больше месяца протестировать быстро проблематично — каждый месяц теста увеличивает длительность прогона приблизительно на полчаса даже на 8-ядерном новом процессоре.
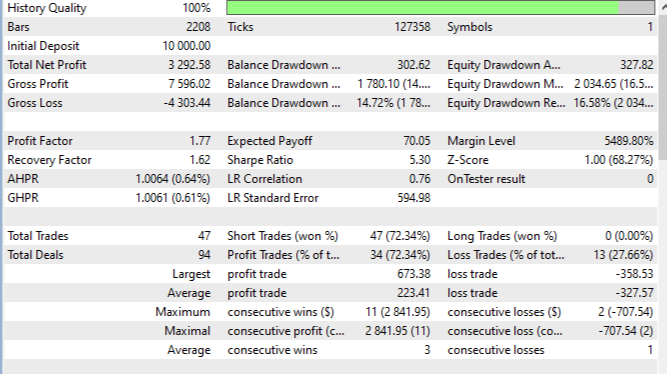
Процент прибыльных сделок 72.3% существенно превышает случайный уровень, что свидетельствует о наличии предсказательной силы у модели. Средняя прибыльная сделка составила +223 пипсов против средней убыточной в -327 пипсов, обеспечивая положительное соотношение прибыли к убытку. Максимальная серия прибылей достигла 3 сделок, максимальная серия убытков ограничилась 1 сделкой. Profit Factor 1.77 демонстрирует устойчивое превышение прибылей над убытками.
Заключение
PatchTST показывает, как современные модели машинного обучения можно применять в трейдинге. Подход с "патчингом" делает работу алгоритма быстрее и позволяет учитывать как долгосрочные зависимости, так и локальные паттерны. Система умеет адаптироваться к изменениям рынка и может быть встроена в MetaTrader 5, что делает её пригодной для практического использования.
В то же время у модели есть ограничения. Она требует много ресурсов и качественных исторических данных. Резкие изменения на рынке могут временно снижать точность прогнозов. Как и любая стратегия, она не защищена от "чёрных лебедей" и со временем может терять эффективность из-за конкуренции и изменений в регулировании.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Твоя реализация в MQL5 — это инженерский подвиг, особенно учитывая ограничения среды. Но если цель — скорость и масштабируемость, Python с ML-фреймворками даст тебе:
Быстрее обучение
Более точные модели
Легче тестировать и визуализировать