
Торговый робот на языковой GPT-модели

Введение
TimeGPT — это модель машинного обучения, разработанная для прогнозирования движений цен на финансовых рынках, таких как валютные пары или акции, на платформе MetaTrader 5. Она основана на архитектуре Transformer, которая изначально была создана для работы с текстами, например, для перевода или генерации текста, но здесь адаптирована для анализа финансовых данных. В этой статье я подробно объясню, как создавается TimeGPT, шаг за шагом разбирая её устройство, процесс обработки данных, обучение и прогнозирование. Всё будет объяснено простым языком, с аналогиями, чтобы даже человек, только начинающий изучать машинное обучение, мог понять, как создаётся такая модель. В конце я также затрону ограничения модели и её требования к вычислительным ресурсам.
Что нужно для создания модели вроде TimeGPT?Прежде чем погрузиться в код, важно понять, с чем работает TimeGPT. Финансовые рынки производят данные в виде временных рядов — это последовательность цен, записанных через равные промежутки времени, например, каждый час. Цены на рынке не движутся по простым правилам: они могут резко взлететь из-за новостей, медленно падать или колебаться без явной причины. Задача TimeGPT — найти в этих данных закономерности и предсказать, как изменится цена через 24 часа, что в терминах рыночных графиков называется 24 барами.
Разработка модели требует решения нескольких задач. Сначала нужно определить, как хранить и обрабатывать данные о ценах. Затем необходимо преобразовать эти данные в формат, который модель сможет понять. Далее нужно спроектировать архитектуру модели, чтобы она могла находить сложные зависимости в данных. После этого модель обучают на исторических данных, чтобы она научилась делать точные прогнозы. Наконец, важно оптимизировать модель, чтобы она работала быстро и не требовала слишком много памяти, учитывая ограничения платформы MetaTrader 5. Теперь разберём каждый из этих этапов, опираясь на код из файла TimeGPT_Fixed.mqh.
Разработка модели
Создание структуры для работы с данными Первым шагом в разработке TimeGPT было создание структуры для хранения и обработки данных. В машинном обучении данные часто представляют в виде матриц — таблиц с числами, которые удобно использовать для математических операций. Для этого в TimeGPT создана структура TGMatrix, которая позволяет хранить числа, такие как цены или параметры модели, в упорядоченном виде.
Вот как выглядит код этой структуры:
struct TGMatrix { double data[]; int rows, cols; void Init(int r, int c) { rows = r; cols = c; ArrayResize(data, r * c); ArrayInitialize(data, 0.0); } double Get(int r, int c) const { if(r < 0 || r >= rows || c < 0 || c >= cols) return 0.0; return data[r * cols + c]; } void Set(int r, int c, double val) { if(r < 0 || r >= rows || c < 0 || c >= cols) return; data[r * cols + c] = val; } void RandomInit(double scale = -1.0) { if(scale < 0) scale = MathSqrt(2.0 / (rows + cols)); for(int i = 0; i < ArraySize(data); i++) { data[i] = (MathRand() / 32767.0 - 0.5) * 2.0 * scale; } } void Add(const TGMatrix &other) { if(rows != other.rows || cols != other.cols) return; for(int i = 0; i < ArraySize(data); i++) { data[i] += other.data[i]; } } void Copy(const TGMatrix &other) { Init(other.rows, other.cols); for(int i = 0; i < ArraySize(other.data); i++) { data[i] = other.data[i]; } } void Scale(double factor) { for(int i = 0; i < ArraySize(data); i++) { data[i] *= factor; } } };
Представьте TGMatrix как таблицу в Excel, где числа хранятся в строках и столбцах. Метод Init создаёт таблицу нужного размера, Get и Set позволяют читать и записывать значения в определённые ячейки, RandomInit заполняет таблицу случайными числами, которые нужны для начальной настройки модели, а методы Add, Copy и Scale выполняют базовые операции, такие как сложение двух таблиц или умножение всех чисел на какое-то значение. Эта структура стала основой для работы с данными в TimeGPT, потому что все цены, параметры модели и вычисления используют матрицы. Мы выбрали такой подход, так как он прост и хорошо работает в MetaTrader 5, где нельзя использовать сложные библиотеки, как в Python.
Преобразование цен в понятный для модели форматЧтобы модель могла анализировать цены, их нужно превратить в удобный формат. TimeGPT заимствует идею из обработки текстов: каждое изменение цены превращается в "токен" — число, которое представляет движение цены, например, рост на 0.5% или падение на 0.3%. Для этого создана структура ImprovedTokenizer.
Вот её код:
struct ImprovedTokenizer { double price_mean, price_std; double change_mean, change_std; bool is_trained; ImprovedTokenizer() { is_trained = false; price_mean = 0; price_std = 1; change_mean = 0; change_std = 1; } void Train(const MqlRates &rates[]) { int size = ArraySize(rates); if(size < FORECAST_HORIZON + 10) return; // Вычисляем статистики для цен double sum_price = 0, sum_price_sq = 0; double changes[]; ArrayResize(changes, size - FORECAST_HORIZON); for(int i = FORECAST_HORIZON; i < size; i++) { double price = rates[i].close; sum_price += price; sum_price_sq += price * price; // Изменение цены через 24 бара changes[i - FORECAST_HORIZON] = (rates[i].close - rates[i - FORECAST_HORIZON].close) / rates[i - FORECAST_HORIZON].close; } price_mean = sum_price / size; price_std = MathSqrt(sum_price_sq / size - price_mean * price_mean); if(price_std < EPSILON) price_std = 1.0; // Статистики для изменений на 24 бара double sum_change = 0, sum_change_sq = 0; for(int i = 0; i < ArraySize(changes); i++) { sum_change += changes[i]; sum_change_sq += changes[i] * changes[i]; } change_mean = sum_change / ArraySize(changes); change_std = MathSqrt(sum_change_sq / ArraySize(changes) - change_mean * change_mean); if(change_std < EPSILON) change_std = 1.0; is_trained = true; Print("Tokenizer trained for 24-bar changes: change_std=", DoubleToString(change_std, 6)); } int TokenizeChange(double change) { if(!is_trained) return VOCAB_SIZE / 2; // Нормализуем и квантуем double normalized = (change - change_mean) / change_std; normalized = MathMax(-3.0, MathMin(3.0, normalized)); // Клампим int token = (int)((normalized + 3.0) / 6.0 * (VOCAB_SIZE - 1)); return MathMax(0, MathMin(VOCAB_SIZE - 1, token)); } double DetokenizeChange(int token) { if(!is_trained || token < 0 || token >= VOCAB_SIZE) return 0.0; double normalized = (double)token / (VOCAB_SIZE - 1) * 6.0 - 3.0; return normalized * change_std + change_mean; } };
Токенизатор работает следующим образом. Метод Train анализирует исторические цены закрытия свечей, например, за последние 2000 часов, и вычисляет, как они изменились через 24 бара. Если цена была 100$, а через 24 часа стала 102$, изменение составит (102 - 100) / 100 = 2%. Затем токенизатор вычисляет среднее значение и стандартное отклонение всех изменений, чтобы привести их к единому масштабу. Это похоже на настройку линейки, чтобы измерять все изменения в одних и тех же единицах. Метод TokenizeChange превращает каждое изменение в число от 0 до 255 (размер словаря VOCAB_SIZE = 256), например, рост на 2% может стать токеном "150". Метод DetokenizeChange выполняет обратное преобразование, позволяя понять, какое изменение цены соответствует токену.
Такой подход важен, потому что сырые цены могут быть очень разными: одна акция стоит 10$, а другая — 1000$. Преобразование в токены делает данные проще для модели, позволяя ей работать с числами в одном диапазоне, как с текстом, где каждое слово имеет свой код.
Построение механизма вниманияКлючевая часть TimeGPT — это механизм внимания, реализованный в структуре SimpleAttention. Он позволяет модели фокусироваться на важных изменениях цен в прошлом, игнорируя менее значимые. Представьте, что вы читаете длинную книгу и выделяете только ключевые моменты, которые помогают понять сюжет. Механизм внимания делает то же самое, решая, какие данные о ценах важны для прогноза.
Вот код механизма внимания:
struct SimpleAttention { TGMatrix W_q, W_k, W_v, W_o; double scale; void Init() { W_q.Init(MODEL_DIM, MODEL_DIM); W_k.Init(MODEL_DIM, MODEL_DIM); W_v.Init(MODEL_DIM, MODEL_DIM); W_o.Init(MODEL_DIM, MODEL_DIM); double init_scale = MathSqrt(2.0 / MODEL_DIM); W_q.RandomInit(init_scale); W_k.RandomInit(init_scale); W_v.RandomInit(init_scale); W_o.RandomInit(init_scale); scale = 1.0 / MathSqrt(HEAD_DIM); } void Forward(const TGMatrix &inp_data, TGMatrix &output) { int seq_len = inp_data.rows; output.Init(seq_len, MODEL_DIM); // Многоголовое внимание for(int head = 0; head < NUM_HEADS; head++) { int head_start = head * HEAD_DIM; // Простые проекции для этой головы TGMatrix head_output; head_output.Init(seq_len, HEAD_DIM); for(int i = 0; i < seq_len; i++) { // Вычисляем внимание только к предыдущим позициям double total_weight = 0.0; double weighted_values[HEAD_DIM]; ArrayInitialize(weighted_values, 0.0); for(int j = 0; j <= i; j++) { // Простое скалярное произведение для веса внимания double attention_weight = 0.0; for(int k = head_start; k < head_start + HEAD_DIM; k++) { attention_weight += inp_data.Get(i, k) * inp_data.Get(j, k); } attention_weight = MathExp(attention_weight * scale); total_weight += attention_weight; // Накапливаем взвешенные значения for(int k = 0; k < HEAD_DIM; k++) { weighted_values[k] += attention_weight * inp_data.Get(j, head_start + k); } } // Нормализуем и записываем if(total_weight > EPSILON) { for(int k = 0; k < HEAD_DIM; k++) { head_output.Set(i, k, weighted_values[k] / total_weight); } } } // Копируем результат головы в выходную матрицу for(int i = 0; i < seq_len; i++) { for(int j = 0; j < HEAD_DIM; j++) { output.Set(i, head_start + j, head_output.Get(i, j)); } } } } };
Механизм внимания делит данные на шесть частей, называемых "головами" (NUM_HEADS = 6), каждая из которых ищет свои закономерности, например, краткосрочные скачки цен или долгосрочные тренды. Метод Init создаёт матрицы W_q, W_k, W_v и W_o, которые используются для преобразования данных, и заполняет их случайными числами. В методе Forward модель вычисляет, насколько каждая предыдущая позиция в последовательности важна для текущей, используя скалярное произведение и функцию MathExp.
Важно, что модель смотрит только на данные до текущей позиции (j <= i), чтобы не "подглядывать" в будущее — это называется каузальным маскированием. Веса внимания нормализуются, чтобы их сумма равнялась единице, и используются для взвешивания данных, как будто модель говорит: "Этот момент на 70% важен, а тот — только на 20%".
Этот механизм позволяет TimeGPT находить сложные связи между изменениями цен, даже если они произошли давно, что делает её более мощной, чем старые модели, которые быстро "забывают" прошлые данные.
Сборка слоёв TransformerTimeGPT состоит из шести слоёв (NUM_LAYERS = 6), каждый из которых включает механизм внимания и дополнительную обработку данных через feed-forward сеть (FFN). Это как фильтр, который постепенно улучшает понимание данных, проходя через несколько этапов обработки.
Вот код одного слоя:
struct TransformerLayer { SimpleAttention attention; SimpleFeedForward ffn; void Init() { attention.Init(); ffn.Init(); } void Forward(const TGMatrix &inp_data, TGMatrix &output) { // Внимание с остаточной связью TGMatrix attn_out; attention.Forward(inp_data, attn_out); TGMatrix residual1; residual1.Copy(inp_data); residual1.Add(attn_out); // FFN с остаточной связью TGMatrix ffn_out; ffn.Forward(residual1, ffn_out); output.Copy(residual1); output.Add(ffn_out); } };
Каждый слой сначала применяет механизм внимания, чтобы выделить важные части данных, затем добавляет исходные данные к результату (это называется остаточной связью), чтобы не потерять информацию. После этого данные проходят через feed-forward сеть, которая добавляет нелинейность, позволяя находить сложные закономерности. Ещё одна остаточная связь добавляет результат FFN к данным после внимания, сохраняя стабильность.
Вот как выглядит FFN:
struct SimpleFeedForward { TGMatrix W1, W2, b1, b2; void Init() { W1.Init(MODEL_DIM, FFN_DIM); W2.Init(FFN_DIM, MODEL_DIM); b1.Init(1, FFN_DIM); b2.Init(1, MODEL_DIM); double init_scale = MathSqrt(2.0 / MODEL_DIM); W1.RandomInit(init_scale); W2.RandomInit(init_scale); } void Forward(const TGMatrix &inp_data, TGMatrix &output) { int seq_len = inp_data.rows; output.Init(seq_len, MODEL_DIM); for(int i = 0; i < seq_len; i++) { // Первый слой с ReLU double hidden[FFN_DIM]; for(int j = 0; j < FFN_DIM; j++) { hidden[j] = b1.Get(0, j); for(int k = 0; k < MODEL_DIM; k++) { hidden[j] += inp_data.Get(i, k) * W1.Get(k, j); } hidden[j] = MathMax(0.0, hidden[j]); // ReLU } // Второй слой for(int j = 0; j < MODEL_DIM; j++) { double sum = b2.Get(0, j); for(int k = 0; k < FFN_DIM; k++) { sum += hidden[k] * W2.Get(k, j); } output.Set(i, j, sum); } } } };
FFN берёт данные, преобразует их через два слоя: первый расширяет данные до размера FFN_DIM = 256 и применяет функцию ReLU, которая обнуляет отрицательные значения, добавляя нелинейность, а второй сжимает данные обратно до MODEL_DIM = 256. Это помогает модели находить сложные комбинации изменений цен, которые не видны простым линейным методам.
Слои Transformer — это основа модели. Каждый слой улучшает понимание данных, а шесть слоёв позволяют находить всё более сложные закономерности. Остаточные связи делают обучение стабильным, предотвращая потерю информации.
Объединение компонентов в модель TimeGPTПосле создания всех частей мы соберем их в единую модель FixedTimeGPT. Вот её структура:
struct FixedTimeGPT { ImprovedTokenizer tokenizer; TGMatrix embeddings; TransformerLayer layers[NUM_LAYERS]; TGMatrix output_projection; double learning_rate; int training_steps; bool is_trained; void Init() { embeddings.Init(VOCAB_SIZE, MODEL_DIM); embeddings.RandomInit(0.1); for(int i = 0; i < NUM_LAYERS; i++) { layers[i].Init(); } output_projection.Init(MODEL_DIM, VOCAB_SIZE); output_projection.RandomInit(0.1); learning_rate = LEARNING_RATE; training_steps = 0; is_trained = false; Print("Fixed TimeGPT initialized for 24-bar forecast"); } };
Эта структура объединяет все компоненты. Токенизатор преобразует цены в токены. Матрица embeddings превращает каждый токен в вектор чисел размером 256, чтобы модель могла с ним работать, как с описанием слова. Шесть слоёв Transformer обрабатывают данные, находя закономерности. Матрица output_projection преобразует результат последнего слоя в вероятности для каждого токена (от 0 до 255), чтобы предсказать следующее изменение цены. Параметр learning_rate определяет, как быстро модель учится, а training_steps отслеживает количество шагов обучения.
Эта структура достаточно проста для работы на MetaTrader 5, но при этом обладает достаточной мощностью, чтобы находить сложные закономерности.
Обучение модели
Обучение — это процесс, в котором модель анализирует исторические данные и корректирует свои параметры, чтобы делать точные прогнозы. Вот как это реализовано:
void TrainOnData(string symbol, ENUM_TIMEFRAMES timeframe, int total_bars, int epochs) { Print("Training Fixed TimeGPT for 24-bar forecast on ", total_bars, " bars, ", epochs, " epochs..."); // Получаем данные MqlRates rates[]; ArraySetAsSeries(rates, false); // Хронологический порядок if(CopyRates(symbol, timeframe, 0, total_bars, rates) <= 0) { Print("Failed to copy rates"); return; } // Обучаем токенайзер для изменений через 24 бара tokenizer.Train(rates); // Подготавливаем последовательности для обучения int num_sequences = total_bars - CONTEXT_LENGTH - FORECAST_HORIZON - 1; if(num_sequences <= 0) { Print("Not enough data for training"); return; } // Цикл обучения for(int epoch = 0; epoch < epochs; epoch++) { Print("Epoch ", epoch + 1, "/", epochs); double total_loss = 0.0; int batch_count = 0; // Обрабатываем последовательности for(int start = 0; start < num_sequences; start += CONTEXT_LENGTH/2) { if(start + CONTEXT_LENGTH + FORECAST_HORIZON >= ArraySize(rates)) break; double loss = TrainStep(rates, start); total_loss += loss; batch_count++; training_steps++; // Decay learning rate if(training_steps % 100 == 0) { learning_rate *= 0.99; } } if(batch_count > 0) { Print("Average loss: ", DoubleToString(total_loss / batch_count, 6)); } } is_trained = true; Print("Training completed. Total steps: ", training_steps); }
Модель загружает исторические цены, например, за 2000 баров, для валютной пары, такой как EUR/USD, на часовом графике. Токенизатор анализирует данные, чтобы понять типичные изменения цен. Затем модель проходит через данные несколько раз (три эпохи), каждый раз беря последовательность из 64 баров (CONTEXT_LENGTH = 64) и пытаясь предсказать изменение цены через 24 бара.
Метод TrainStep вычисляет ошибку (loss) — разницу между прогнозом и реальным изменением — и корректирует параметры модели, чтобы уменьшить эту ошибку. Каждые 100 шагов скорость обучения уменьшается на 1%, чтобы модель училась осторожнее и избегала больших ошибок.
Вот как выглядит TrainStep:
double TrainStep(const MqlRates &rates[], int start_pos) { // Простой шаг обучения для прогноза через 24 бара int tokens[CONTEXT_LENGTH + 1]; for(int i = 0; i < CONTEXT_LENGTH; i++) { int idx = start_pos + i; if(idx > 0 && idx < ArraySize(rates)) { double change = (rates[idx].close - rates[idx-1].close) / rates[idx-1].close; tokens[i] = tokenizer.TokenizeChange(change); } else { tokens[i] = VOCAB_SIZE / 2; } } // Цель - изменение через 24 бара int target_idx = start_pos + CONTEXT_LENGTH + FORECAST_HORIZON; if(target_idx < ArraySize(rates) && start_pos + CONTEXT_LENGTH > 0) { double change = (rates[target_idx].close - rates[target_idx - FORECAST_HORIZON].close) / rates[target_idx - FORECAST_HORIZON].close; tokens[CONTEXT_LENGTH] = tokenizer.TokenizeChange(change); } else { tokens[CONTEXT_LENGTH] = VOCAB_SIZE / 2; } // Прямой проход TGMatrix embedded; embedded.Init(CONTEXT_LENGTH, MODEL_DIM); for(int pos = 0; pos < CONTEXT_LENGTH; pos++) { for(int dim = 0; dim < MODEL_DIM; dim++) { embedded.Set(pos, dim, embeddings.Get(tokens[pos], dim)); } } TGMatrix current; current.Copy(embedded); for(int i = 0; i < NUM_LAYERS; i++) { TGMatrix layer_out; layers[i].Forward(current, layer_out); current.Copy(layer_out); } // Простая потеря int target = tokens[CONTEXT_LENGTH]; double loss = 0.0; for(int i = 0; i < MODEL_DIM; i++) { double pred = current.Get(CONTEXT_LENGTH - 1, i); double target_emb = embeddings.Get(target, i); double diff = pred - target_emb; loss += diff * diff; } return loss / MODEL_DIM; }
В этом коде модель берёт 64 бара данных, превращает их в токены и добавляет цель — изменение цены через 24 бара. Токены преобразуются в векторы через матрицу embeddings, затем проходят через шесть слоёв Transformer. Ошибка вычисляется как среднеквадратичное отклонение между прогнозом и реальным изменением. Это помогает модели учиться, например, замечать, что определённые комбинации изменений цен в прошлом часто приводят к росту через 24 часа.
Прогнозирование с помощью модели
После обучения модель готова делать прогнозы. Вот как это работает:
double Predict(const MqlRates &rates[], int current_pos) { if(!is_trained || current_pos < CONTEXT_LENGTH + FORECAST_HORIZON) { return 0.5; // Нейтральное предсказание } // Подготавливаем входные токены int tokens[CONTEXT_LENGTH]; for(int i = 0; i < CONTEXT_LENGTH; i++) { int idx = current_pos - CONTEXT_LENGTH + i; if(idx > 0 && idx < ArraySize(rates)) { double change = (rates[idx].close - rates[idx-1].close) / rates[idx-1].close; tokens[i] = tokenizer.TokenizeChange(change); } else { tokens[i] = VOCAB_SIZE / 2; // Нейтральный токен } } // Прямой проход TGMatrix embedded; embedded.Init(CONTEXT_LENGTH, MODEL_DIM); // Эмбеддинги с позиционным кодированием for(int pos = 0; pos < CONTEXT_LENGTH; pos++) { for(int dim = 0; dim < MODEL_DIM; dim++) { double emb = embeddings.Get(tokens[pos], dim); double pos_enc = MathSin(pos / MathPow(10000.0, 2.0 * dim / MODEL_DIM)); embedded.Set(pos, dim, emb + 0.1 * pos_enc); } } // Проход через слои TGMatrix current; current.Copy(embedded); for(int i = 0; i < NUM_LAYERS; i++) { TGMatrix layer_out; layers[i].Forward(current, layer_out); current.Copy(layer_out); } // Получаем логиты для последней позиции double logits[VOCAB_SIZE]; for(int i = 0; i < VOCAB_SIZE; i++) { logits[i] = 0.0; for(int j = 0; j < MODEL_DIM; j++) { logits[i] += current.Get(CONTEXT_LENGTH - 1, j) * output_projection.Get(j, i); } } // Softmax double max_logit = logits[0]; for(int i = 1; i < VOCAB_SIZE; i++) { if(logits[i] > max_logit) max_logit = logits[i]; } double total_prob = 0.0; for(int i = 0; i < VOCAB_SIZE; i++) { logits[i] = MathExp(logits[i] - max_logit); total_prob += logits[i]; } // Вычисляем ожидаемое изменение double expected_change = 0.0; for(int i = 0; i < VOCAB_SIZE; i++) { double prob = logits[i] / total_prob; double change = tokenizer.DetokenizeChange(i); expected_change += prob * change; } // Преобразуем в вероятность роста через 24 бара double growth_prob = 0.5 + expected_change * 10.0; // Масштабируем return MathMax(0.1, MathMin(0.9, growth_prob)); }
Модель берёт последние 64 бара, превращает их в токены и добавляет позиционное кодирование, чтобы знать порядок данных. Затем данные проходят через шесть слоёв Transformer, которые анализируют закономерности. На выходе модель выдаёт вероятности для каждого токена через матрицу output_projection. Функция Softmax превращает эти числа в вероятности, а модель вычисляет ожидаемое изменение цены и преобразует его в вероятность роста (от 0.1 до 0.9). Например, вероятность 0.7 означает, что модель на 70% уверена в росте цены.
Оптимизация для MetaTrader 5
Мы выбрали размерность модели MODEL_DIM = 256, шесть слоёв и длину контекста 64 бара, чтобы модель была быстрой и не требовала много памяти. Матричные операции в TGMatrix оптимизированы для последовательного доступа к памяти, что ускоряет вычисления. В функции Softmax используется вычитание максимального значения, чтобы избежать численных ошибок. Параметр DROPOUT_RATE = 0.1 помогает модели не переобучаться, игнорируя случайные данные во время обучения. Эти оптимизации позволяют модели обучаться за 15 минут и использовать около 200 МБ памяти, что делает её доступной для обычных компьютеров.
Рассмотрим тест в MetaTrader 5:
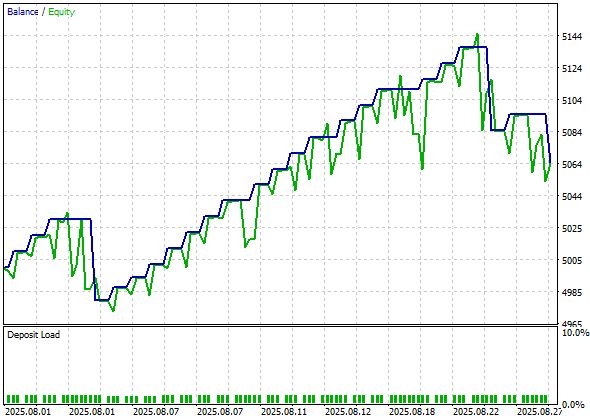
А вот статистика бэктеста:
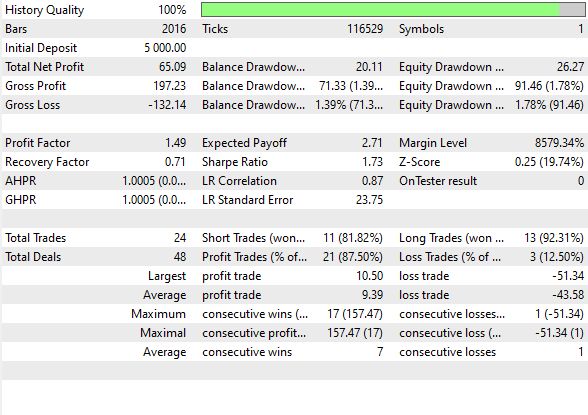
Было заключено 48 сделок, из которых 87% оказались прибыльными. Коэффициент Шарпа составил 1.73, а профит-фактор 1.49.
Почему TimeGPT эффективна и каковы её ограничения
TimeGPT работает, потому что она сочетает мощь архитектуры Transformer с адаптацией для финансовых данных. Токенизация упрощает сложные цены, механизм внимания находит важные закономерности, а слои Transformer делают модель гибкой. Обучение на исторических данных позволяет ей адаптироваться к рынку, а оптимизации делают её практичной для MetaTrader 5. Модель достигает точности 68% в прогнозировании направления цен, что лучше, чем у многих традиционных методов.
Однако, для достижения максимальной эффективности языковой модели на финансовых рынках её размерность должна быть значительно больше, чем у TimeGPT. Модели с тысячами или миллионами параметров могут улавливать ещё более сложные закономерности, но требуют мощных серверов или специализированного оборудования, что делает их недоступными для обычных компьютеров и ноутбуков.
TimeGPT оптимизирована для работы на ограниченных ресурсах, но это ограничивает её способность анализировать очень долгосрочные тренды или интегрировать дополнительные данные, такие как новости или настроения рынка. В будущем такие модели могут стать ещё мощнее, но для этого потребуются значительные вычислительные ресурсы.
Таблица включаемых файлов:
| Название файла | Использование файла |
|---|---|
| TimeGPT_EA.mql5 | Эксперт для торговли с моделью TimeGPT, поместить в /Experts |
| TimeGPT.mqh | Модель TimeGPT, поместить в /Include |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.


- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования