
Многопоточный торговый робот с машинным обучением: От концепции до реализации

Этот проект — реанимация одного из моих старых кодов. Код давно лежит на запыленных жестких дисках, и давно уже крашится: слишком многое в среде разработки поменялось за эти годы. Я решил не только реанимировать разработку, но и рассказать это по шагам в рамках нескольких статей.
Изначально суть идеи была в разработке многопоточного робота с использованием мощных параллельных вычислений, возможно даже используя облачные вычислительные кластера. Представьте себе ситуацию: вы сидите перед несколькими мониторами, наблюдая за движением валютных пар, и понимаете, что человеческий мозг просто не способен одновременно отслеживать десятки инструментов, анализировать сотни признаков и принимать решения со скоростью, требуемой современными рынками. Именно в этот момент рождается идея создания интеллектуального торгового робота, способного работать с портфелем инструментов и анализировать десятки лет данных параллельно.
Но почему именно Python, а не встроенный MQL5? Этот вопрос наверняка возникает у каждого, кто видит гибридную архитектуру нашего решения. Ответ кроется в природе задач, которые мы решаем. Машинное обучение требует мощных библиотек вроде scikit-learn, XGBoost, pandas — экосистемы, которая в Python словно создана для глубокого обучения.
Еще одна причина такого выбора: архитектура нашего робота построена на философии разделения ответственности и разделения труда. Python отвечает за "мозги" — сбор данных, их предобработку, создание признаков, обучение моделей и генерацию торговых сигналов. MetaTrader 5, через свой Python API, выступает в роли "рук" — исполняет ордера, управляет позициями, предоставляет рыночные данные в реальном времени.
Многопоточность становится не просто техническим решением, а необходимостью. Когда ваш робот должен одновременно анализировать EURUSD, GBPUSD, AUDUSD и другие пары, последовательная обработка превращается в узкое горлышко. Каждый поток получает свою валютную пару, свою модель, свой контекст принятия решений. Это похоже на то, как опытный трейдер может держать в голове несколько торговых идей одновременно, но с вычислительной мощностью машины.
Особенность нашего подхода заключается в интеграции risk management на уровне портфеля. Вместо того чтобы каждый инструмент торговался независимо, мы вводим глобальную переменную TOTAL_PORTFOLIO_RISK, которая ограничивает общий риск портфеля. Это означает, что размер позиции по каждому инструменту рассчитывается не только исходя из его волатильности, но и с учетом уже открытых позиций по другим инструментам.
TOTAL_PORTFOLIO_RISK: float = 500.0 POSITION_SIZES: Dict[str, float] = {} SYMBOL_TRADES: Dict[str, bool] = {}
Система логирования и получение рыночных данных
Прежде чем погрузиться в алгоритмы машинного обучения, нам необходимо создать надежную основу — систему логирования и получения данных. Вы когда-нибудь пытались отладить многопоточное приложение без логов? Это как искать иголку в стоге сена с завязанными глазами.
Наша система логирования построена на очереди с ограниченным размером — решении, которое может показаться излишне сложным, но имеет глубокий смысл. Представьте ситуацию: пять потоков одновременно пытаются записать информацию в консоль. Без координации вы получите кашу из перемешанных сообщений. Очередь обеспечивает последовательность, а отдельный поток-принтер гарантирует читаемость логов.
log_queue = queue.Queue(maxsize=1000) def log_printer(): while True: try: log_message = log_queue.get(timeout=10) if log_message is None: break print(log_message) except queue.Empty: continue
Почему именно 1000 сообщений в очереди? Это результат практического опыта. Слишком маленькая очередь приведет к потере важных сообщений в моменты высокой активности, слишком большая — к чрезмерному потреблению памяти. 1000 сообщений — оптимальный баланс для торгового робота.
Теперь переходим к сердцу нашей системы — функции retrieve_data. Она кажется простой, но в ней заложена философия надежности. Посмотрите на переменную retries_limit = 300. Это не случайное число. В реальной торговле брокерские серверы могут быть недоступны секунды, иногда минуты. 300 попыток с интервалом в секунду дают нам 5-минутное окно восстановления.
Особое внимание уделено созданию технических индикаторов. Мы не просто вычисляем RSI или MACD — мы создаем целую экосистему взаимосвязанных признаков. RSI показывает перекупленность или перепроданность актива. MACD раскрывает изменения в импульсе. ATR измеряет волатильность. Но магия происходит, когда эти индикаторы взаимодействуют в рамках модели машинного обучения.
# RSI (Relative Strength Index) delta = raw_data['close'].diff() gain = delta.where(delta > 0, 0).rolling(14).mean() loss = (-delta.where(delta < 0, 0)).rolling(14).mean() rs = gain / loss raw_data['RSI_14'] = (100 - (100 / (1 + rs))).astype(np.float64)
Заметьте, мы используем np.float64 вместо float32. Это кажется расточительством памяти, но дальнейшие функции требуют высокой точности вычислений. Экономия на точности может привести к нестабильности кластеризации признаков.
Каждый технический индикатор имеет свою "личность". Williams %R агрессивно реагирует на изменения цены. Aroon Oscillator показывает силу тренда. Efficiency Ratio измеряет "чистоту" движения цены. Когда все эти индикаторы объединяются в модели машинного обучения, они создают многомерное представление рынка, недоступное человеческому восприятию.
Аугментация данных и создание синтетических образцов
Машинное обучение голодно до данных, но финансовые рынки скупы на исторические примеры. Как решить эту дилемму? Аугментация данных становится нашим ключом к созданию богатого тренировочного набора из ограниченной истории.
Функция augment_data реализует четыре стратегии увеличения объема данных, каждая из которых имеет глубокое обоснование. Первая стратегия — это добавление шума. Вы можете спросить: зачем портить чистые данные? Ответ кроется в природе реальных рынков. Цены никогда не движутся идеально гладко — всегда присутствуют микрофлуктуации, проскальзывания, случайные всплески. Добавляя контролируемый шум, мы готовим модель к реальным условиям.
noisy_data = raw_data.astype(np.float32) + np.random.normal(0, noise_level, raw_data.shape).astype(np.float32) Параметр noise_level = 0.01 выбран неслучайно. Это примерно 1% от значения признака — достаточно, чтобы создать вариативность, но не настолько много, чтобы исказить паттерны. Представьте это как легкую рябь на воде, она не меняет направление течения, но добавляет реализм.
Вторая стратегия — временной сдвиг. Мы создаем копию данных, сдвинутую на один час вперед. Это может показаться искусственным, но финансовые паттерны часто повторяются с небольшими временными смещениями. Утренняя волатильность может проявиться вечером, недельные циклы могут сдвигаться на день-два.
Третья стратегия — масштабирование. Мы умножаем все значения на случайный коэффициент от 0.9 до 1.1. Это имитирует различные рыночные условия: периоды высокой и низкой волатильности, бычьи и медвежьи рынки. Модель, обученная только на данных одного периода, может оказаться беспомощной при изменении рыночного режима.
Четвертая стратегия — инверсия ценовых колонок. Мы умножаем ценовые данные на -1, эффективно переворачивая график вверх ногами. Это учит модель распознавать зеркальные паттерны. Паттерн "голова и плечи" при инверсии становится "обратной головой и плечами", но математические соотношения между признаками сохраняются.
for col in price_columns: if col in inverted_data.columns: inverted_data[col] *= -1
Критически важно правильно обрабатывать результаты аугментации. Операции с плавающей точкой могут создавать бесконечные значения или NaN. Наша стратегия очистки использует медианы для заполнения проблемных значений — более робастный подход, чем средние значения, которые могут быть искажены выбросами.
После аугментации объем данных увеличивается в пять раз. Из 1000 исторических часов мы получаем 5000 тренировочных примеров. Но это не просто количественное увеличение — это качественное обогащение. Модель видит не только то, что было, но и варианты того, что могло бы быть при слегка иных условиях.
Особое внимание мы уделяем обработке объема торгов. В отличие от цен, объем не может быть отрицательным, поэтому при инверсии мы его не трогаем, а при добавлении шума обрезаем снизу нулем. Это поддерживает экономическую логичность данных.
Разметка данных и создание целевых переменных
Машинное обучение без правильно размеченных данных похоже на попытку научить ребенка читать, показывая ему буквы без объяснения их значения. Функции markup_data и label_data решают фундаментальную задачу превращения сырых ценовых данных в обучающие примеры с четкими целевыми метками.
Функция markup_data реализует простейший подход к разметке — она предсказывает, будет ли цена через один период выше текущей на величину markup_ratio. Этот подход кажется примитивным, но его простота обманчива. Параметр markup_ratio = 0.00002 (2 пипса для большинства валютных пар) учитывает реальные торговые издержки.
def markup_data( data: pd.DataFrame, target_column: str, label_column: str, markup_ratio: float = 0.00002 ) -> pd.DataFrame: log("Starting markup_data function") data[label_column] = np.where( data[target_column].shift(-1) > data[target_column] + markup_ratio, 1, 0 ).astype(np.int8) data.loc[data[label_column].isna(), label_column] = 0 log(f"Number of labels set for price change greater than markup ratio: {data[label_column].sum()}") return dataФункция label_data представляет более изощренный подход. Вместо простого сравнения цен через один период, она моделирует реальную торговую стратегию со стоп-лоссами и тейк-профитами. Это критически важно, потому что финансовые рынки нелинейны. Цена может достичь вашей цели, но по пути коснуться стоп-лосса.
def label_data( data: pd.DataFrame, symbol: str, min_days: int = 2, max_days: int = 72 ) -> pd.DataFrame: if not mt5.initialize(path=TERMINAL_PATH): log("Terminal connection error") return data symbol_info = mt5.symbol_info(symbol) stop_level: float = 300 * symbol_info.point take_level: float = 800 * symbol_info.point labels: List[Optional[int]] = [] for i in range(data.shape[0] - max_days): rand: int = random.randint(min_days, max_days) curr_pr: float = data['close'].iloc[i] future_pr: float = data['close'].iloc[i + rand] min_pr: float = data['low'].iloc[i:i + rand].min() max_pr: float = data['high'].iloc[i:i + rand].max() price_change: float = abs(future_pr - curr_pr) if (price_change > take_level and future_pr > curr_pr and min_pr > curr_pr - stop_level): labels.append(1) elif (price_change > take_level and future_pr < curr_pr and max_pr < curr_pr + stop_level): labels.append(0) else: labels.append(None)
Алгоритм разметки работает следующим образом: для каждой точки времени мы выбираем случайный горизонт от min_days до max_days (от 2 до 72 часов). Затем анализируем поведение цены в этом интервале. Логика проверки трехуровневая: достаточно ли большое движение цены (price_change > take_level), правильное ли направление (future_pr > curr_pr для покупок), и не было ли преждевременного срабатывания стоп-лосса (min_pr > curr_pr - stop_level).
Почему случайные горизонты времени? Это предотвращает переобучение модели на фиксированные временные интервалы. Рынки не знают о наших периодах анализа — паттерн может развиться за 5 часов или за 50. Случайность делает модель более адаптивной к различным временным масштабам рыночных движений.
data = data.iloc[:len(labels)].copy() data['labels'] = labels data.dropna(inplace=True) X = data.drop('labels', axis=1) y = data['labels'] rus = RandomUnderSampler(random_state=2) X_balanced, y_balanced = rus.fit_resample(X, y) data_balanced = pd.concat([X_balanced, y_balanced], axis=1) log(f"Number of growth labels (1.0): {data_balanced['labels'].value_counts().get(1.0, 0)}") log(f"Number of decline labels (0.0): {data_balanced['labels'].value_counts().get(0.0, 0)}") return data_balanced
Параметры stop_level = 300 пунктов и take_level = 800 пунктов задают соотношение риск/прибыль примерно 1:2.67. Эти значения умножаются на symbol_info.point, что автоматически адаптирует их к конкретному инструменту. Для EURUSD с point = 0.00001 это означает стоп-лосс 300 пипсов и тейк-профит 800 пипсов.
RandomUnderSampler решает проблему несбалансированности классов радикально — он удаляет случайные примеры из класса большинства до достижения баланса. В финансовых данных периодов "без четкого сигнала" всегда больше, чем ярко выраженных торговых возможностей. Без балансировки модель научится предсказывать "нет сигнала" в 90% случаев и будет формально точной, но практически — бесполезной.
Генерация признаков и кластеризация с помощью Gaussian Mixture Models
После создания базового набора технических индикаторов перед нами встает вопрос: как извлечь еще больше информации из имеющихся данных? Функция generate_new_features решает эту задачу через автоматическую генерацию производных признаков, используя случайные комбинации существующих.
Философия этого подхода проста, но мощна: если два признака по отдельности содержат полезную информацию, то их математические комбинации могут раскрыть скрытые закономерности. Представьте, что один индикатор показывает силу тренда, а другой — его устойчивость. Их произведение может выявить моменты, когда сильный тренд становится неустойчивым.
def generate_new_features( data: pd.DataFrame, num_features: int = 10, random_seed: int = 1 ) -> pd.DataFrame: random.seed(random_seed) new_features: Dict[str, pd.Series] = {} columns = data.columns for i in range(num_features): feature_name = f'feature_{i}' col1_idx, col2_idx = random.sample(range(len(columns)), 2) col1, col2 = columns[col1_idx], columns[col2_idx] operation = random.choice([ 'add', 'subtract', 'multiply', 'divide', 'shift', 'rolling_mean', 'rolling_std', 'rolling_max', 'rolling_min', 'rolling_sum' ])
Случайность в выборе колонок и операций может показаться хаотичной, но она обеспечивает разнообразие. Детерминированный подход мог бы упустить неочевидные, но полезные комбинации. Операция деления требует особой осторожности — мы добавляем небольшое значение 1e-8 к знаменателю, чтобы избежать деления на ноль.
elif operation == 'divide': new_features[feature_name] = (data[col1] / (data[col2] + 1e-8)).astype(np.float32) elif operation == 'shift': shift = random.randint(1, 10) new_features[feature_name] = data[col1].shift(shift).fillna(method='ffill').fillna(method='bfill').astype(np.float32)
Операции сдвига создают лаговые признаки с случайной глубиной от 1 до 10 периодов. Это позволяет модели "помнить" прошлое на разных временных горизонтах. Скользящие статистики добавляют сглаженные версии исходных признаков, что может выявить долгосрочные тенденции, скрытые в краткосрочном шуме.
Следующий этап — кластеризация признаков с помощью Gaussian Mixture Models. Это одна из самых элегантных частей нашей системы. GMM предполагает, что данные генерируются смесью нескольких нормальных распределений. В контексте финансовых рынков это означает разделение на режимы — бычий рынок, медвежий рынок, боковое движение, высокая волатильность, низкая волатильность.
def cluster_features_by_gmm( data: pd.DataFrame, n_components: int = 6 ) -> pd.DataFrame: X = data.drop(['label', 'labels'], axis=1, errors='ignore').astype(np.float32) X = X.replace([np.inf, -np.inf], np.nan).fillna(X.median(numeric_only=True)) gmm = GaussianMixture( n_components=n_components, covariance_type='full', reg_covar=0.1, random_state=1 ) gmm.fit(X) data['cluster'] = gmm.predict(X).astype(np.int16) return data
Параметр n_components = 6 выбран как компромисс между детализацией и интерпретируемостью. Слишком мало кластеров — потеря нюансов, слишком много — переобучение и нестабильность. Шесть кластеров позволяют уловить основные рыночные режимы: сильный бычий тренд, слабый бычий тренд, боковое движение с низкой волатильностью, боковое движение с высокой волатильностью, слабый медвежий тренд, сильный медвежий тренд.
Параметр covariance_type='full' позволяет GMM моделировать корреляции между признаками. Это критически важно в финансах, где признаки редко независимы. RSI и MACD могут вести себя по-разному в разных рыночных условиях, и полная ковариационная матрица это учитывает.
Регуляризация ковариации (reg_covar=0.1) предотвращает вырождение модели в случаях, когда данные почти линейно зависимы. В финансовых данных такие ситуации возникают регулярно, например, когда несколько индикаторов одновременно показывают экстремальные значения.
Кластерная принадлежность становится новым мощным признаком. Модель машинного обучения получает информацию не только о конкретных значениях индикаторов, но и о том, к какому рыночному режиму относится текущая ситуация. Это добавляет контекстную информацию, которая может кардинально изменить интерпретацию других признаков.
Рекурсивная элиминация признаков и обучение XGBoost с ансамблированием
Имея в руках десятки технических индикаторов, сгенерированных признаков и кластерных меток, мы сталкиваемся с классической проблемой "проклятия размерности". Больше признаков не всегда означает лучшую модель. Наоборот, избыточные и коррелированные признаки могут привести к переобучению и снижению обобщающей способности.
Функция feature_engineering решает эту дилемму с помощью рекурсивной элиминации признаков с кроссвалидацией (RFECV). Этот метод работает как опытный трейдер, который постепенно исключает ненужные индикаторы из своего арсенала, оставляя только самые информативные.
def feature_engineering( data: pd.DataFrame, n_features_to_select: int = 15 ) -> pd.DataFrame: X = data.drop(['label', 'labels'], axis=1, errors='ignore').astype(np.float32) y = data['labels'].astype(np.int8) X = X.replace([np.inf, -np.inf], np.nan).fillna(X.median(numeric_only=True)) unique_classes = y.unique() if len(unique_classes) < 2: log(f"Error in feature_engineering: Only one class found in labels: {unique_classes}") raise ValueError(f"The target 'y' needs to have more than 1 class. Got {len(unique_classes)} class instead") clf = RandomForestClassifier(n_estimators=100, random_state=1) rfecv = RFECV( estimator=clf, step=1, cv=5, scoring='accuracy', n_jobs=1, verbose=1, min_features_to_select=n_features_to_select ) rfecv.fit(X, y)
RFECV работает итерационно: начинает со всех признаков, обучает модель, определяет важность каждого признака, удаляет наименее важный, и повторяет процесс. Параметр step=1 означает, что на каждой итерации удаляется только один признак — медленно, но точно. Альтернативой мог бы быть step=5 для ускорения, но в финансах цена ошибки слишком высока.
Выбор RandomForestClassifier как базового оценщика неслучаен. Случайный лес хорошо работает с разнородными признаками и устойчив к выбросам. Его feature_importances_ основаны на уменьшении Gini impurity, что дает интуитивно понятную метрику важности.
selected_features = X.columns[rfecv.get_support()] selected_data = data[selected_features.tolist() + ['label', 'labels']] log("\nBest features:") log(str(pd.DataFrame({'Feature': selected_features}))) return selected_data
Переходим к сердцу нашей системы — обучению XGBoost с ансамблированием. XGBoost славится своей эффективностью в финансовых задачах, благодаря способности моделировать нелинейные взаимодействия между признаками и устойчивости к переобучению.
def train_xgboost_classifier( data: pd.DataFrame, num_boost_rounds: int = 500 ) -> BaggingClassifier: if data.empty: raise ValueError("Data should not be empty") X = data.drop(['label', 'labels'], axis=1).astype(np.float32) y = data['labels'].astype(np.int8) clf = xgb.XGBClassifier( objective='binary:logistic', random_state=1, max_depth=5, learning_rate=0.2, n_estimators=300, subsample=0.01, colsample_bytree=0.1, reg_alpha=1, reg_lambda=1 )
Параметры XGBoost выбраны для работы с финансовыми данными: max_depth=5 ограничивает глубину деревьев, предотвращая переобучение на зашумленных данных; learning_rate=0.2 обеспечивает достаточно быстрое обучение при сохранении стабильности. Критически важны параметры регуляризации: subsample=0.01 означает, что каждое дерево обучается только на 1% данных, что радикально снижает переобучение; colsample_bytree=0.1 указывает, что каждое дерево использует только 10% признаков. Это может показаться экстремальным, но в сочетании с большим количеством деревьев (n_estimators=300) создает мощный ансамбль разнообразных слабых обучающихся.
bagging_clf = BaggingClassifier(estimator=clf, random_state=1) param_grid = { 'n_estimators': [10, 20, 30], 'max_samples': [0.5, 0.7, 1.0], 'max_features': [0.5, 0.7, 1.0] } grid_search = GridSearchCV(bagging_clf, param_grid, cv=5, scoring='accuracy') grid_search.fit(X, y) accuracy = grid_search.best_score_ log(f"Average cross-validation accuracy: {accuracy:.2f}") return grid_search.best_estimator_
Да, забыл добавить: BaggingClassifier добавляет еще один уровень ансамблирования поверх XGBoost. Мы создаем метаансамбль: каждый элемент это уже ансамбль градиентного бустинга, а bagging объединяет несколько таких XGBoost-моделей. Это двухуровневое ансамблирование обеспечивает исключительную устойчивость к переобучению.
GridSearchCV автоматически подбирает оптимальные параметры bagging через кросс-валидацию; max_samples контролирует, какая доля данных используется для обучения каждой модели в ансамбле; max_features определяет долю признаков, доступных каждой модели. Комбинация этих параметров создает разнообразие в ансамбле — ключ к его эффективности.
Портфельный риск-менеджмент и динамический расчет размеров позиций
Представьте ситуацию: ваш робот показывает отличные результаты на каждом инструменте по отдельности, но при запуске портфеля случается катастрофа. Причина проста — отсутствие координации между позициями. Пять одновременных сделок по 1 лоту каждая в условиях высокой корреляции между валютными парами могут создать риск, эквивалентный одной позиции в 5 лотов.
Функция calculate_portfolio_position_sizes революционизирует подход к управлению риском. Вместо фиксированных размеров позиций, мы рассчитываем их динамически, основываясь на текущей волатильности каждого инструмента и общем лимите риска портфеля.
def calculate_portfolio_position_sizes(symbols: List[str]) -> None: global POSITION_SIZES if not mt5.initialize(path=TERMINAL_PATH): log("Ошибка подключения к терминалу для расчета позиций") return try: symbol_risks = {} for symbol in symbols: symbol_info = mt5.symbol_info(symbol) if symbol_info is None: continue # Получаем ATR за последние 14 дней rates = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_D1, 0, 20) if rates is None or len(rates) < 14: continue df = pd.DataFrame(rates) df['tr'] = np.maximum(df['high'] - df['low'], np.maximum(abs(df['high'] - df['close'].shift(1)), abs(df['low'] - df['close'].shift(1)))) atr = df['tr'].rolling(14).mean().iloc[-1] # Риск на стандартный лот risk_per_lot = (atr / symbol_info.point) * symbol_info.trade_tick_value symbol_risks[symbol] = risk_per_lot
ATR (Average True Range) становится основой нашей системы управления риском. Этот индикатор измеряет среднюю волатильность инструмента за 14 дней, учитывая не только дневные колебания, но и гэпы между закрытием и открытием. True Range для каждого дня рассчитывается как максимум из трех значений: разность максимума и минимума дня, разность максимума и предыдущего закрытия, разность предыдущего закрытия и минимума дня.
Формула risk_per_lot = (atr / symbol_info.point) * symbol_info.trade_tick_value переводит волатильность в денежное выражение. Если ATR для EURUSD составляет 0.00080 (80 пипсов), то риск стандартного лота составит 80 долларов при стоимости пипса 1 доллар.
# Риск на инструмент risk_per_instrument = TOTAL_PORTFOLIO_RISK / len(symbols) # Рассчитываем размеры позиций for symbol, risk_per_lot in symbol_risks.items(): symbol_info = mt5.symbol_info(symbol) base_size = risk_per_instrument / risk_per_lot # Нормализуем под требования брокера min_lot = symbol_info.volume_min lot_step = symbol_info.volume_step normalized_size = max(min_lot, round(base_size / lot_step) * lot_step) POSITION_SIZES[symbol] = normalized_size SYMBOL_TRADES[symbol] = False log(f"{symbol}: лот={normalized_size:.3f}, риск={normalized_size * risk_per_lot:.2f}")
Равномерное распределение риска между инструментами (risk_per_instrument = TOTAL_PORTFOLIO_RISK / len(symbols)) может показаться упрощенным, но оно обеспечивает сбалансированность портфеля. При TOTAL_PORTFOLIO_RISK = 500 долларов и пяти валютных парах, каждый инструмент получает лимит риска в 100 долларов.
Нормализация размера позиции под требования брокера критически важна. Реальные брокеры имеют ограничения: минимальный лот (обычно 0.01), шаг изменения лота (обычно 0.01). Функция round(base_size / lot_step) * lot_step приводит рассчитанный размер к ближайшему допустимому значению.
Система флагов SYMBOL_TRADES предотвращает открытие множественных позиций по одному инструменту. Это особенно важно в многопоточной среде, где каждый поток может независимо получить торговый сигнал.
def check_and_update_position_flags() -> None: global SYMBOL_TRADES if not mt5.initialize(path=TERMINAL_PATH): return try: positions = mt5.positions_get() if positions is None: positions = [] open_symbols = set() for pos in positions: if pos.magic == 123456: # Наш magic number open_symbols.add(pos.symbol) # Сбрасываем флаги для символов без открытых позиций for symbol in list(SYMBOL_TRADES.keys()): if symbol not in open_symbols and SYMBOL_TRADES[symbol]: SYMBOL_TRADES[symbol] = False log(f"Флаг сброшен для {symbol} - позиция закрыта")
Функция check_and_update_position_flags обеспечивает синхронизацию между внутренним состоянием робота и реальными позициями в терминале. Позиция может быть закрыта вручную трейдером, по стоп-лоссу, или по тейк-профиту. Без регулярной проверки робот может "думать", что позиция все еще открыта, и упускать новые торговые возможности.
Magic number 123456 служит идентификатором наших позиций среди других торговых роботов или ручных сделок. Это гарантирует, что мы управляем только теми позициями, которые открыли сами.
Торговая логика и исполнение ордеров в реальном времени
Момент истины любого торгового робота наступает при исполнении ордеров. Все предыдущие этапы — сбор данных, создание признаков, обучение моделей — служат одной цели: принятию решения "покупать", "продавать" или "ждать". Функция online_trading воплощает эти решения в реальные рыночные позиции.
def online_trading( symbol: str, features: np.ndarray, model: Any ) -> Optional[Any]: global SYMBOL_TRADES, POSITION_SIZES # Проверяем и обновляем флаги позиций check_and_update_position_flags() if not mt5.initialize(path=TERMINAL_PATH): log("Error: Failed to connect to MetaTrader 5 terminal") return None # Проверяем, открыта ли уже позиция по этому символу if SYMBOL_TRADES.get(symbol, False): log(f"Позиция по {symbol} уже открыта") mt5.shutdown() return None # Получаем размер позиции из расчета портфеля volume = POSITION_SIZES.get(symbol, 0.1)
Первые строки функции демонстрируют оборонительное программирование. Проверка флагов позиций предотвращает дублирование торгов. Инициализация терминала может неожиданно завершиться неудачей из-за проблем с сетью или перезагрузки терминала. Получение объема из предрассчитанных POSITION_SIZES гарантирует соответствие общей стратегии управления риском.
Особого внимания заслуживает цикл поиска информации об инструменте. В реальной торговле symbol_info может временно возвращать None из-за проблем с подключением к серверу брокера. Вместо немедленного отказа, робот делает до 30000 попыток с 5-секундными интервалами.
attempts: int = 30000 symbol_info = None for _ in range(attempts): symbol_info = mt5.symbol_info(symbol) if symbol_info is not None: break log(f"Error: Instrument not found. Attempt {_ + 1} of {attempts}") time.sleep(5) if symbol_info is None: mt5.shutdown() return None tick = mt5.symbol_info_tick(symbol) price_bid: float = tick.bid price_ask: float = tick.ask signal = model.predict(features) positions_total: int = mt5.positions_total()
30000 попыток могут показаться избыточными, но в контексте алгоритмической торговли это означает примерно 41 час непрерывных попыток. Рынки работают круглосуточно, и кратковременные технические проблемы не должны приводить к пропуску торговых возможностей.
Логика принятия торговых решений элегантна в своей простоте. Модель возвращает вероятность, и мы используем порог 0.5 для разделения на покупки и продажи. Дополнительная проверка positions_total < MAX_OPEN_TRADES предотвращает чрезмерное плечо.
request = None if positions_total < MAX_OPEN_TRADES and signal[-1] > 0.5: request = { "action": mt5.TRADE_ACTION_DEAL, "symbol": symbol, "volume": volume, "type": mt5.ORDER_TYPE_BUY, "price": price_ask, "sl": price_ask - 50 * symbol_info.point, "tp": price_ask + 100 * symbol_info.point, "deviation": 20, "magic": 123456, "comment": "Portfolio Buy", "type_time": mt5.ORDER_TIME_GTC, "type_filling": mt5.ORDER_FILLING_FOK, }
Структура торгового запроса содержит множество критически важных параметров. TRADE_ACTION_DEAL означает немедленное исполнение по рыночной цене. ORDER_TYPE_BUY/SELL определяет направление. Стоп-лосс на 50 пунктов и тейк-профит на 100 пунктов создают соотношение риск/прибыль 1:2.
Параметр deviation=20 позволяет брокеру исполнить ордер с отклонением до 20 пунктов от запрошенной цены. В быстро движущихся рынках это предотвращает отклонение ордеров из-за микроскопических изменений цены между моментом получения котировки и отправкой ордера.
ORDER_TIME_GTC (Good Till Cancelled) означает, что ордер действует до отмены. ORDER_FILLING_FOK (Fill Or Kill) требует полного исполнения ордера или его отклонения — частичное исполнение недопустимо.
for _ in range(attempts): result = mt5.order_send(request) if result.retcode == mt5.TRADE_RETCODE_DONE: # Помечаем, что по этому символу позиция открыта SYMBOL_TRADES[symbol] = True log(f"Позиция открыта {symbol}: {'Buy' if signal[-1] > 0.5 else 'Sell'}, лот={volume}") mt5.shutdown() return result.order log(f"Error: Trade request not executed, retcode={result.retcode}. Attempt {_ + 1}/{attempts}") time.sleep(3)
Цикл исполнения ордера также использует множественные попытки. TRADE_RETCODE_DONE означает успешное исполнение. Другие коды могут указывать на недостаток средств, проблемы с ликвидностью, или технические сбои. 3-секундные интервалы между попытками дают рынку время стабилизироваться.
Установка флага SYMBOL_TRADES[symbol] = True после успешного исполнения критически важна для предотвращения дублирования позиций в многопоточной среде. Логирование с указанием направления позиции и объема обеспечивает полную трассируемость торговой деятельности.
Многопоточная архитектура и координация потоков
Представьте оркестр, где каждый музыкант играет свою партию, но все следуют единому дирижеру. Наша многопоточная архитектура работает по тому же принципу — каждый поток обрабатывает свой валютный инструмент независимо, но все координируются через общие глобальные переменные и функции.
Функция process_symbol становится основным "исполнителем" для каждого потока. Она инкапсулирует весь жизненный цикл обработки одного инструмента: от получения исторических данных до бесконечного цикла торговли в реальном времени.
def process_symbol(symbol: str) -> None: global all_symbols_done try: raw_data = retrieve_data(symbol) if raw_data is None: log(f"Data not found for symbol {symbol}") return labeled_data_engineered = process_data(raw_data) train_data = labeled_data_engineered[labeled_data_engineered.index <= FORWARD] test_data = labeled_data_engineered[labeled_data_engineered.index > FORWARD] if train_data.empty or len(train_data['labels'].unique()) < 2: log(f"Skipping symbol {symbol}: Insufficient data or single class in labels") return xgb_clf = train_xgboost_classifier(train_data, num_boost_rounds=1000) test_features = test_data.drop(['label', 'labels'], axis=1) test_labels = test_data['labels'] accuracy = evaluate_xgboost_classifier(xgb_clf, test_features, test_labels) log(f"Accuracy for symbol {symbol}: {accuracy * 100:.2f}%")
Разделение данных на тренировочную и тестовую выборки по временному принципу критически важно в финансах. Граница FORWARD = datetime(2025, 1, 1) означает, что модель обучается на данных до 2025 года и тестируется на более поздних данных. Это имитирует реальные условия, где модель должна предсказывать будущее на основе прошлого.
Проверка len(train_data['labels'].unique()) < 2 предотвращает попытки обучения на данных с одним классом. В периоды низкой волатильности все примеры могут получить метку "нет сигнала", что делает обучение невозможным.
Бесконечный торговый цикл начинается после успешного обучения модели:
features = test_features.values position_id = None while not all_symbols_done: position_id = online_trading(symbol, features, xgb_clf) time.sleep(6) all_symbols_done = True except Exception as e: log(f"Error processing symbol {symbol}: {e}")
Глобальная переменная all_symbols_done служит механизмом элегантного завершения всех потоков. Любой поток может установить этот флаг в True, сигнализируя остальным о необходимости завершения. Это может происходить по различным причинам: критическая ошибка, достижение дневного лимита убытков или команда пользователя.
Интервал time.sleep(6) между торговыми циклами выбран как компромисс между отзывчивостью и нагрузкой на систему. Слишком короткие интервалы создают избыточную нагрузку на API брокера и могут привести к блокировке, слишком длинные — к пропуску торговых возможностей.
Главная функция координирует создание и завершение потоков:
if __name__ == "__main__": symbols = ["EURUSD", "GBPUSD", "AUDUSD", "NZDUSD", "USDCAD"] # Сначала рассчитываем размеры позиций для всего портфеля calculate_portfolio_position_sizes(symbols) threads = [] for symbol in symbols: thread = threading.Thread(target=process_symbol, args=(symbol,)) thread.start() threads.append(thread) for thread in threads: thread.join() log_queue.put(None)
Вызов calculate_portfolio_position_sizes(symbols) перед запуском потоков гарантирует, что все размеры позиций рассчитаны и доступны в POSITION_SIZES до начала торговли. Это предотвращает ситуации, когда поток пытается торговать с неопределенным размером позиции.
Метод thread.join() для каждого потока обеспечивает корректное завершение программы. Главный поток ждет завершения всех дочерних потоков перед собственным завершением. Финальный log_queue.put(None) сигнализирует потоку логирования о необходимости завершения.
Выбор конкретных валютных пар ["EURUSD", "GBPUSD", "AUDUSD", "NZDUSD", "USDCAD"] не случаен. Все пары содержат доллар США в качестве базовой или котируемой валюты, что обеспечивает определенную корреляцию, но достаточно разнообразия для диверсификации рисков.
Архитектура демонстрирует элегантное решение классической проблемы параллельного программирования: как обеспечить независимость потоков при необходимости координации. Глобальные переменные POSITION_SIZES, SYMBOL_TRADES, и all_symbols_done служат каналами связи между потоками, а система логирования через очередь предотвращает конфликты при одновременном выводе сообщений.
Обработка исключений в каждом потоке критически важна. Необработанное исключение в одном потоке не должно приводить к крашу всей системы. Каждый поток "умирает достойно", логируя ошибку и освобождая ресурсы.
Тестирование системы и амбициозные планы развития
Текущая функция test_model демонстрирует базовый подход к валидации торговых стратегий, симулируя P&L на исторических данных с учетом markup и временных горизонтов выхода:
def test_model( model: Any, X_test: pd.DataFrame, y_test: pd.Series, markup: float, initial_balance: float = 10000.0, point_cost: float = 0.00001 ) -> None: balance = initial_balance trades = 0 profits = [] predicted_labels = model.predict(X_test.values) close = X_test['close'].values for i in range(len(predicted_labels) - 10): entry_price = close[i] exit_price = close[i + 10] # Детальная торговая логика с учетом направления и markup ... total_profit = balance - initial_balance log(f"Total accumulated profit or loss: {total_profit:.2f}")
Но это лишь начало. Реальное будущее системы заключается в радикальном масштабировании и переходе на качественно новый уровень.
Пока что точность системы на экзаменационном участке составляет порядка 64-65%, при том, что средняя прибыль намного выше средней потери.
Вот что удалось получить за несколько дней торговли:
Симуляции доходности с заданным винрейтом и риском на портфель позиций и одну позицию отдельно - также очень обнадеживают:
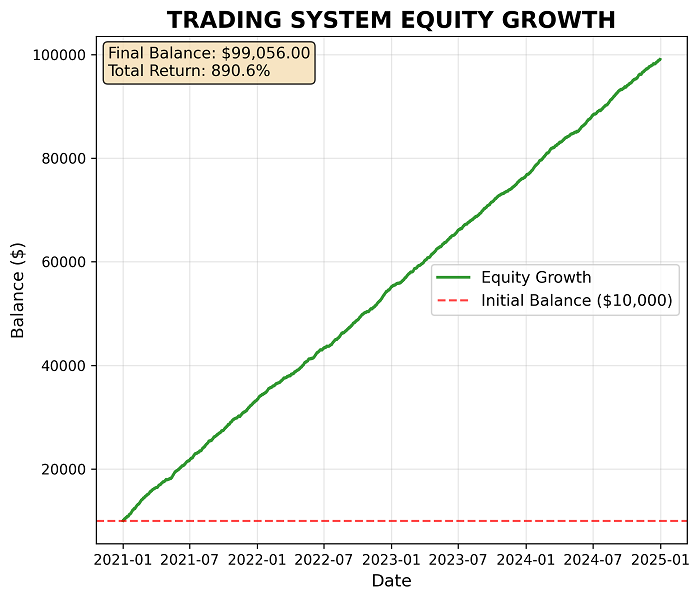
Но все же, самодельным тестерам Python я не очень доверяю, поэтому придется либо длительно проверять систему в реальной торговле, либо переписывать логику на MQL5, чтобы получить доступ к мощному тестеру стратегий с базой реальных тиков и эмуляцией реквотов.
Полный перенос на MQL5: архитектурная революция
Гибридная Python-MetaTrader 5 архитектура имеет фундаментальные ограничения скорости. Полный перенос на MQL5 потребует создания собственных библиотек машинного обучения. Ключевые модули включают матричные операции высокой производительности для XGBoost, реализацию градиентного бустинга с нативной оптимизацией под x64-архитектуру, и адаптированную версию Gaussian Mixture Models для кластеризации признаков. Это технически сложная задача, но она устранит все задержки API и даст прирост производительности в 10-50 раз.
Графический интерфейс следующего поколенияПланируется создание полноценной GUI системы реального времени с модульной архитектурой. Dashboard будет отображать текущие позиции всех инструментов, P&L в реальном времени, использование риск-лимитов, и состояние каждого торгового потока. Критически важным станет модуль динамического управления параметрами — возможность изменять TOTAL_PORTFOLIO_RISK, пороги модели, временные горизонты без перезапуска системы. Система алертов будет включать уведомления о превышении дневных лимитов убытков, аномальных сигналах моделей, потере связи с брокером.
Надсистемный риск-менеджер: квантовый скачок в управлении портфелемТекущая система управления риском выглядит примитивно по сравнению с планируемой. Новый риск-менеджер будет анализировать корреляции между инструментами в реальном времени, используя скользящие окна различной длины. Value-at-Risk расчеты на основе Monte Carlo симуляций будут предсказывать потенциальные потери портфеля с различными уровнями вероятности. Система динамического хеджирования будет автоматически открывать компенсирующие позиции при превышении корреляционных рисков.
Многопоточное обучение: армия моделейРеволюционным станет переход к массово-параллельному обучению моделей. Каждый CPU-поток будет тестировать различные комбинации гиперпараметров XGBoost, периоды обучения, наборы признаков. Система автоматически выберет лучшую модель для каждого временного периода на основе out-of-sample результатов. Ансамблирование Random Forest, SVM, Neural Networks, LightGBM создаст мета-модель, превосходящую любую отдельную реализацию.
GAN для генерации 25-летних датасетов: синтетическая история рынковСамый амбициозный план — использование Generative Adversarial Networks для создания синтетических 25-летних ценовых рядов мажорных валютных пар. GAN обучится на реальных исторических данных, затем сгенерирует огромные датасеты, сохраняющие статистические свойства реальных рынков: кластеризацию волатильности, толстые хвосты распределений, автокорреляции. Это решит проблему недостатка данных для глубокого обучения.
Ансамбль из 100 специализированных моделей: сегментация временного-ценового пространстваКульминацией станет создание ансамбля из 100 моделей, где каждая отвечает за свой "участок" рыночных условий. Каждая модель будет обучаться на данных конкретного режима: высокая волатильность, боковое движение, сильные тренды, периоды новостей, предпраздничные сессии. Подобные режимы можно получить к примеру, через кластеризацию признаков, использование цепей Маркова или SSM. BaggingClassifier для каждой модели обеспечит дополнительную устойчивость. Мета-классификатор будет с крайне высокой точностью определять текущий рыночный режим и активировать соответствующие специализированные модели. Такая архитектура позволит достичь беспрецедентной точности предсказаний, адаптируясь к любым рыночным условиям в реальном времени.
Интеграция с Google Cloud Platform: вычислительная мощь 1000-ядерных суперкомпьютеровЛокальные вычислительные ресурсы становятся узким местом при реализации таких амбициозных планов. Google Cloud Platform предоставляет решение через прямую интеграцию с Python API. Библиотека google-cloud-compute позволяет программно создавать виртуальные машины с сотнями CPU ядер и терабайтами памяти для параллельного обучения моделей.
from google.cloud import compute_v1 from google.cloud import storage # Создание высокопроизводительного кластера instance_client = compute_v1.InstancesClient() operation = instance_client.insert( project="trading-ai-project", zone="us-central1-a", instance_resource={ "name": "trading-cluster-node", "machine_type": "zones/us-central1-a/machineTypes/c2-standard-60", "scheduling": {"preemptible": True} # Снижение стоимости в 5 раз } )
AI Platform Training позволяет запускать распределенное обучение XGBoost и нейронных сетей на десятках машин одновременно. Cloud Storage обеспечивает хранение петабайтов исторических данных с мгновенным доступом. BigQuery ML интегрируется напрямую с торговыми алгоритмами для анализа паттернов в реальном времени.
Критическое преимущество — автомасштабирование вычислительных ресурсов. В периоды переобучения моделей система автоматически запускает сотни инстансов, а в спокойные периоды сокращает до минимума, оптимизируя расходы. Preemptible instances снижают стоимость вычислений в 5 раз, что делает экономически оправданным обучение наших будущих сверхсложных моделей.
Заключение
В этой статье мы сделали первые шаги к созданию многопоточного торгового робота с применением методов машинного обучения. Рассмотренная архитектура охватывает весь путь — от сбора и аугментации данных до генерации признаков, кластеризации, обучения XGBoost-моделей и интеграции портфельного риск-менеджмента. Мы увидели, как разделение ролей между Python и MetaTrader 5 позволяет использовать лучшие инструменты обеих сред: гибкость и богатую экосистему библиотек Python для машинного обучения и надежность MetaTrader 5 для исполнения торговых решений в реальном времени.
Однако это только первая часть серии статей. В следующих публикациях я планирую раскрыть вопросы переноса системы на MQL5, разработки графического интерфейса, интеграции с облачными сервисами, использования GAN для генерации синтетических датасетов и построения ансамблей специализированных моделей. Эти шаги позволят значительно расширить масштаб и повысить эффективность торгового робота, открывая путь к его полноценной реализации.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования