
在外汇数据分析中使用关联规则

关联规则概念介绍
现代算法交易需要新的分析方法。市场不断变化,经典的技术分析方法已不再能够识别复杂的市场关系。
我长期从事数据工作,发现许多成功的理念都来自相关领域。今天,我想分享我在交易中使用关联规则的经验。这种方法在零售分析中已经证明了自己,使我们能够找到购买、交易、价格走势以及未来供需之间的联系。如果我们将这种方法应用于外汇市场,会怎样呢?
基本的想法很简单——我们正在寻找价格行为、指标及其组合的稳定模式。例如,欧元兑美元(EURUSD)的上涨有多频繁地跟随美元兑日元(USDJPY)的下跌?或者,哪些条件最常先于强烈的走势?
在本文中将展示基于这一想法创建交易系统的完整过程。我们将:
- 在MQL5中收集历史数据
- 在Python中分析它们
- 找到重要的模式
- 将它们转化为交易信号
为什么选择这一特定的技术栈?MQL5非常适合处理证券交易所数据和交易自动化。反过来,Python提供了强大的分析工具。从我的经验来看,这种组合对于开发交易系统非常有效。
代码中将有许多有趣的内容,特别是在将关联规则应用于外汇的领域。
收集和准备历史外汇数据
对我们来说,收集和准备所有需要的数据至关重要。让我们以过去两年(自2022年起)主要货币对的1小时(H1)数据为基础。
现在,我们将编写一个MQL5脚本,该脚本将收集并以CSV格式导出我们需要的数据:
//+------------------------------------------------------------------+ //| Dataset.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { string pairs[] = {"EURUSD", "GBPUSD", "USDJPY", "USDCHF"}; datetime startTime = D'2022.01.01 00:00'; datetime endTime = D'2024.01.01 00:00'; for(int i=0; i<ArraySize(pairs); i++) { string filename = pairs[i] + "_H1.csv"; int fileHandle = FileOpen(filename, FILE_WRITE|FILE_CSV); if(fileHandle != INVALID_HANDLE) { // Set headers FileWrite(fileHandle, "DateTime", "Open", "High", "Low", "Close", "Volume"); MqlRates rates[]; ArraySetAsSeries(rates, true); int copied = CopyRates(pairs[i], PERIOD_H1, startTime, endTime, rates); for(int j=copied-1; j>=0; j--) { FileWrite(fileHandle, TimeToString(rates[j].time), DoubleToString(rates[j].open, 5), DoubleToString(rates[j].high, 5), DoubleToString(rates[j].low, 5), DoubleToString(rates[j].close, 5), IntegerToString(rates[j].tick_volume) ); } FileClose(fileHandle); } } } //+------------------------------------------------------------------+
在Python中进行数据处理
在形成数据集之后,正确处理数据非常重要。
为此,我创建了一个特殊的ForexDataProcessor类,它负责处理所有繁琐的工作。让我们来看看它的主要组成部分。
我们从加载数据开始。我们的函数处理主要货币对(EURUSD、GBPUSD、USDJPY和USDCHF)的小时数据。数据应以CSV格式存储,并包含主要的价格特征。
import pandas as pd
import numpy as np
from datetime import datetime
import os
import warnings
warnings.filterwarnings('ignore')
class ForexDataProcessor:
def __init__(self):
self.pairs = ["EURUSD", "GBPUSD", "USDJPY", "USDCHF"]
self.data = {}
self.processed_data = {}
def load_data(self):
"""Load data for all currency pairs"""
success = True
for pair in self.pairs:
filename = f"{pair}_H1.csv"
try:
df = pd.read_csv(filename,
encoding='utf-16',
sep='\t',
names=['DateTime', 'Open', 'High', 'Low', 'Close', 'Volume'])
# Remove lines with duplicate headers
df = df[df['DateTime'] != 'DateTime']
# Convert data types
df['DateTime'] = pd.to_datetime(df['DateTime'], format='%Y.%m.%d %H:%M')
for col in ['Open', 'High', 'Low', 'Close']:
df[col] = pd.to_numeric(df[col], errors='coerce')
df['Volume'] = pd.to_numeric(df['Volume'], errors='coerce')
# Remove NaN strings
df = df.dropna()
df.set_index('DateTime', inplace=True)
self.data[pair] = df
print(f"Loaded {pair} data successfully. Shape: {df.shape}")
except Exception as e:
print(f"Error loading {pair} data: {str(e)}")
success = False
return success
def safe_qcut(self, series, q, labels):
"""Safe quantization with error handling"""
try:
if series.nunique() <= q:
# If there are fewer unique values than quantiles, use regular categorization
return pd.qcut(series, q=q, labels=labels, duplicates='drop')
return pd.qcut(series, q=q, labels=labels)
except Exception as e:
print(f"Warning: Error in qcut - {str(e)}. Using manual categorization.")
# Manual categorization as a backup option
percentiles = np.percentile(series, [20, 40, 60, 80])
return pd.cut(series,
bins=[-np.inf] + list(percentiles) + [np.inf],
labels=labels)
def calculate_indicators(self, df):
"""Calculate technical indicators for a single dataframe"""
result = df.copy()
# Basic calculations
result['Returns'] = result['Close'].pct_change()
result['Log_Returns'] = np.log(result['Close']/result['Close'].shift(1))
result['Range'] = result['High'] - result['Low']
result['Range_Pct'] = result['Range'] / result['Open'] * 100
# SMA calculations
for period in [5, 10, 20, 50, 200]:
result[f'SMA_{period}'] = result['Close'].rolling(window=period).mean()
# EMA calculations
for period in [5, 10, 20, 50]:
result[f'EMA_{period}'] = result['Close'].ewm(span=period, adjust=False).mean()
# Volatility
result['Volatility'] = result['Returns'].rolling(window=20).std() * np.sqrt(20)
# RSI
delta = result['Close'].diff()
gain = (delta.where(delta > 0, 0)).rolling(window=14).mean()
loss = (-delta.where(delta < 0, 0)).rolling(window=14).mean()
rs = gain / loss
result['RSI'] = 100 - (100 / (1 + rs))
# MACD
exp1 = result['Close'].ewm(span=12, adjust=False).mean()
exp2 = result['Close'].ewm(span=26, adjust=False).mean()
result['MACD'] = exp1 - exp2
result['MACD_Signal'] = result['MACD'].ewm(span=9, adjust=False).mean()
result['MACD_Hist'] = result['MACD'] - result['MACD_Signal']
# Bollinger Bands
result['BB_Middle'] = result['Close'].rolling(window=20).mean()
result['BB_Upper'] = result['BB_Middle'] + (result['Close'].rolling(window=20).std() * 2)
result['BB_Lower'] = result['BB_Middle'] - (result['Close'].rolling(window=20).std() * 2)
result['BB_Width'] = (result['BB_Upper'] - result['BB_Lower']) / result['BB_Middle']
# Discretization for association rules
# SMA-based trend
result['Trend'] = 'Sideways'
result.loc[result['Close'] > result['SMA_50'], 'Trend'] = 'Uptrend'
result.loc[result['Close'] < result['SMA_50'], 'Trend'] = 'Downtrend'
# RSI zones
result['RSI_Zone'] = pd.cut(result['RSI'].fillna(50),
bins=[-np.inf, 30, 45, 55, 70, np.inf],
labels=['Oversold', 'Weak', 'Neutral', 'Strong', 'Overbought'])
# Secure quantization for other parameters
labels = ['Very_Low', 'Low', 'Medium', 'High', 'Very_High']
result['Volatility_Zone'] = self.safe_qcut(
result['Volatility'].fillna(result['Volatility'].mean()),
5, labels)
result['Price_Zone'] = self.safe_qcut(
result['Close'],
5, labels)
result['Volume_Zone'] = self.safe_qcut(
result['Volume'],
5, labels)
# Candle patterns
result['Body'] = result['Close'] - result['Open']
result['Upper_Shadow'] = result['High'] - result[['Open', 'Close']].max(axis=1)
result['Lower_Shadow'] = result[['Open', 'Close']].min(axis=1) - result['Low']
result['Body_Pct'] = result['Body'] / result['Open'] * 100
body_mean = abs(result['Body_Pct']).mean()
result['Candle_Pattern'] = 'Normal'
result.loc[abs(result['Body_Pct']) < body_mean * 0.1, 'Candle_Pattern'] = 'Doji'
result.loc[result['Body_Pct'] > body_mean * 2, 'Candle_Pattern'] = 'Long_Bullish'
result.loc[result['Body_Pct'] < -body_mean * 2, 'Candle_Pattern'] = 'Long_Bearish'
return result
def process_all_pairs(self):
"""Process all currency pairs and create combined dataset"""
if not self.load_data():
return None
# Handling each pair
for pair in self.pairs:
if not self.data[pair].empty:
print(f"Processing {pair}...")
self.processed_data[pair] = self.calculate_indicators(self.data[pair])
# Add a pair prefix to the column names
self.processed_data[pair].columns = [f"{pair}_{col}" for col in self.processed_data[pair].columns]
else:
print(f"Skipping {pair} - no data")
# Find the common time range for non-empty data
common_dates = None
for pair in self.pairs:
if pair in self.processed_data and not self.processed_data[pair].empty:
if common_dates is None:
common_dates = set(self.processed_data[pair].index)
else:
common_dates &= set(self.processed_data[pair].index)
if not common_dates:
print("No common dates found")
return None
# Align all pairs by common dates
aligned_data = {}
for pair in self.pairs:
if pair in self.processed_data and not self.processed_data[pair].empty:
aligned_data[pair] = self.processed_data[pair].loc[sorted(common_dates)]
# Combine all pairs
combined_df = pd.concat([aligned_data[pair] for pair in aligned_data], axis=1)
return combined_df
def save_data(self, data, suffix='combined'):
"""Save processed data to CSV"""
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
filename = f"forex_data_{suffix}_{timestamp}.csv"
try:
data.to_csv(filename, sep='\t', encoding='utf-16')
print(f"Saved processed data to: {filename}")
return True
except Exception as e:
print(f"Error saving data: {str(e)}")
return False
if __name__ == "__main__":
processor = ForexDataProcessor()
# Handling all pairs
combined_data = processor.process_all_pairs()
if combined_data is not None:
# Save the combined dataset
processor.save_data(combined_data)
# Display dataset info
print("\nCombined dataset shape:", combined_data.shape)
print("\nFeatures for association rules analysis:")
for col in combined_data.columns:
if any(x in col for x in ['_Zone', '_Pattern', 'Trend']):
print(f"- {col}")
# Save individual pairs
for pair in processor.pairs:
if pair in processor.processed_data and not processor.processed_data[pair].empty:
processor.save_data(processor.processed_data[pair], pair)
在成功加载数据之后,到了最有意思的部分——计算技术指标。在这里,我依赖于一系列经过时间检验的工具。移动平均线有助于识别不同持续时间的趋势。SMA(50)通常作为动态支撑或阻力。RSI振荡器,其经典周期为14,适用于确定市场的超买和超卖区域。MACD对于识别动量和反转点是不可或缺的。布林带能清晰地展示当前市场的波动性。
# Volatility and RSI calculation example result['Volatility'] = result['Returns'].rolling(window=20).std() * np.sqrt(20) delta = result['Close'].diff() gain = (delta.where(delta > 0, 0)).rolling(window=14).mean() loss = (-delta.where(delta < 0, 0)).rolling(window=14).mean() rs = gain / loss result['RSI'] = 100 - (100 / (1 + rs))
数据离散化值得特别关注。所有连续值都需要被划分为清晰的类别。在这个问题上,找到一个平衡点至关重要——过于粗糙的划分会使模式搜索变得复杂,而过于精细的划分则会导致丢失重要的市场细节。例如,为了确定趋势,更简单的划分方式效果更好——根据价格相对于平均值的位置:
# Defining a trend result['Trend'] = 'Sideways' result.loc[result['Close'] > result['SMA_50'], 'Trend'] = 'Uptrend' result.loc[result['Close'] < result['SMA_50'], 'Trend'] = 'Downtrend'
K线模式也需要一个特别的方法来分析。基于统计分析,我根据最小的K线实体的大小区分出十字星(Doji),以及在极端价格波动下的长阳线(Long_Bullish)和长阴线(Long_Bearish)。这种分类使我们能够清晰地识别市场犹豫不决的时刻以及强烈的冲动走势。
在处理的最后阶段,所有货币对被合并到一个具有统一时间尺度的单一数据数组中。这一步至关重要——它为我们提供了在不同工具之间寻找复杂关系的可能性。现在我们可以看到一个货币对的趋势如何影响另一个货币对的波动性,或者K线模式如何与整个市场的交易量相关。
在Python中实现Apriori算法
在准备好数据之后,我们进入关键阶段——在金融数据中实现Apriori算法以寻找关联规则。我们将原本用于分析购物车的Apriori算法改编为适用于货币对时间序列的算法。
在外汇市场的背景下,“交易”是在某一特定时间点上各种指标和货币对状态的集合。例如:- EURUSD_Trend = Uptrend
- GBPUSD_RSI_Zone = Overbought
- USDJPY_Volatility_Zone = High
该算法搜索此类状态的组合频度,基于这些组合形成交易规则。
import pandas as pd import numpy as np from collections import defaultdict from itertools import combinations import time import logging # Setting up logging logging.basicConfig( level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s', handlers=[ logging.FileHandler('apriori_forex_advanced.log'), logging.StreamHandler() ] ) class AdvancedForexApriori: def __init__(self, min_support=0.01, min_confidence=0.7, max_length=3): self.min_support = min_support self.min_confidence = min_confidence self.max_length = max_length def find_patterns(self, df): start_time = time.time() logging.info("Starting advanced pattern search...") # Group columns by type for more meaningful analysis column_groups = { 'trend': [col for col in df.columns if 'Trend' in col], 'rsi': [col for col in df.columns if 'RSI_Zone' in col], 'volume': [col for col in df.columns if 'Volume_Zone' in col], 'price': [col for col in df.columns if 'Price_Zone' in col], 'pattern': [col for col in df.columns if 'Pattern' in col] } # Create a list of all columns for analysis pattern_cols = [] for cols in column_groups.values(): pattern_cols.extend(cols) logging.info(f"Found {len(pattern_cols)} pattern columns in {len(column_groups)} groups") # Prepare data pattern_df = df[pattern_cols] n_rows = len(pattern_df) # Find single patterns logging.info("Finding single patterns...") single_patterns = {} for col in pattern_cols: value_counts = pattern_df[col].value_counts() value_counts = value_counts[value_counts/n_rows >= self.min_support] for value, count in value_counts.items(): pattern = f"{col}={value}" single_patterns[pattern] = count/n_rows # Find pair and triple patterns logging.info("Finding complex patterns...") complex_rules = [] # Generate column combinations for analysis column_combinations = [] for i in range(2, self.max_length + 1): column_combinations.extend(combinations(pattern_cols, i)) total_combinations = len(column_combinations) for idx, cols in enumerate(column_combinations, 1): if idx % 10 == 0: logging.info(f"Processing combination {idx}/{total_combinations}") # Create a cross-table for the selected columns grouped = pattern_df.groupby([*cols]).size().reset_index(name='count') grouped['support'] = grouped['count'] / n_rows # Sort by minimum support grouped = grouped[grouped['support'] >= self.min_support] for _, row in grouped.iterrows(): # Form all possible combinations of antecedents and consequents items = [f"{col}={row[col]}" for col in cols] for i in range(1, len(items)): for antecedent in combinations(items, i): consequent = tuple(set(items) - set(antecedent)) # Calculate the support of the antecedent ant_support = self._calculate_support(pattern_df, antecedent) if ant_support > 0: # Avoid division by zero confidence = row['support'] / ant_support if confidence >= self.min_confidence: # Count the lift cons_support = self._calculate_support(pattern_df, consequent) lift = confidence / cons_support if cons_support > 0 else 0 # Adding additional metrics to evaluate rules leverage = row['support'] - (ant_support * cons_support) conviction = (1 - cons_support) / (1 - confidence) if confidence < 1 else float('inf') rule = { 'antecedent': antecedent, 'consequent': consequent, 'support': row['support'], 'confidence': confidence, 'lift': lift, 'leverage': leverage, 'conviction': conviction } # Sort the rules by additional criteria if self._is_meaningful_rule(rule): complex_rules.append(rule) # Sort the rules by complex metric complex_rules.sort(key=self._rule_score, reverse=True) end_time = time.time() logging.info(f"Pattern search completed in {end_time - start_time:.2f} seconds") logging.info(f"Found {len(complex_rules)} meaningful rules") return complex_rules def _calculate_support(self, df, items): """Calculate support for a set of elements""" mask = pd.Series(True, index=df.index) for item in items: col, val = item.split('=') mask &= (df[col] == val) return mask.mean() def _is_meaningful_rule(self, rule): """Check the rule for its relevance to trading""" # The rule should have the high lift and 'leverage' if rule['lift'] < 1.5 or rule['leverage'] < 0.01: return False # At least one element should be related to a trend or RSI has_trend_or_rsi = any('Trend' in item or 'RSI' in item for item in rule['antecedent'] + rule['consequent']) if not has_trend_or_rsi: return False return True def _rule_score(self, rule): """Calculate the rule complex evaluation""" return (rule['lift'] * 0.4 + rule['confidence'] * 0.3 + rule['support'] * 0.2 + rule['leverage'] * 0.1) # Load data logging.info("Loading data...") data = pd.read_csv('forex_data_combined_20241116_074242.csv', sep='\t', encoding='utf-16', index_col='DateTime') logging.info(f"Data loaded, shape: {data.shape}") # Apply the algorithm apriori = AdvancedForexApriori(min_support=0.01, min_confidence=0.7, max_length=3) rules = apriori.find_patterns(data) # Display results logging.info("\nTop 10 trading rules:") for i, rule in enumerate(rules[:10], 1): logging.info(f"\nRule {i}:") logging.info(f"IF {' AND '.join(rule['antecedent'])}") logging.info(f"THEN {' AND '.join(rule['consequent'])}") logging.info(f"Support: {rule['support']:.3f}") logging.info(f"Confidence: {rule['confidence']:.3f}") logging.info(f"Lift: {rule['lift']:.3f}") logging.info(f"Leverage: {rule['leverage']:.3f}") logging.info(f"Conviction: {rule['conviction']:.3f}") # Save results results_df = pd.DataFrame(rules) results_df.to_csv('forex_rules_advanced.csv', index=False, sep='\t', encoding='utf-16') logging.info("Results saved to forex_rules_advanced.csv")
将关联规则应用于货币对分析的适配
在我将Apriori算法适配到外汇市场的过程中,我遇到了一些有趣的挑战。尽管这种方法最初是为分析店内购买行为而创建的,但我认为它在外汇市场的潜力是值得期待的。
主要的困难在于,外汇市场与普通商店购物有着根本的不同。在金融市场工作多年后,我已经习惯了处理不断变化的价格和指标。但是,如何将一个通常只是在超市收据上寻找香蕉和牛奶之间联系的算法应用到外汇市场上呢?
经过我的实验,诞生了一个由五个指标组成的系统。我对每一个指标都进行了彻底的测试。
“支持度”(Support)被证明是一个非常棘手的指标。我曾经差点将一条表现优异的规则纳入交易系统,但它的支持度仅为0.02。幸运的是,我及时注意到了这一点——实际上,这样的规则每百年才会触发一次!
“置信度”(Confidence)则相对简单。当你在市场中工作时,你会很快意识到,即使是70%的概率也是一个非常出色的指标。关键是要合理地管理剩余的30%的风险。我们始终应该牢记风险管理。没有它,即使你手中有圣杯,你也会面临回撤甚至资金耗尽的风险。
“提升度”(Lift)成了我最喜欢的指标。经过数百小时的测试,我注意到一个模式——提升度超过1.5的规则实际上在真实市场中是有效的。这一发现深刻地影响了我对信号筛选的方法。
处理“杠杆”(Leverage)的过程相当有趣。起初,我甚至想完全从系统中排除它,认为它毫无用处。但在市场特别波动的一个时期,它帮助我筛选出了大部分虚假信号。
“确信度”(Conviction)是在研究论坛后最后加入的。它帮助我理解了这个指标在评估所发现模式的实际重要性方面的重要性。
最让我惊讶的是,算法能够发现不同货币对之间意想不到的联系。例如,谁能想到EURUSD中的某些模式能够如此准确地预测USDJPY的走势呢?在市场中交易了9年,我都没有注意到算法发现的许多关系。尽管货币对交易、一揽子货币交易和套利曾经是我的专长,但我仍然记得cmillion刚开始基于货币对间的相互走势开发其EA的时候。
现在,我继续我的研究,测试新的指标组合和时间周期。市场不断变化,每一天都有新的发现。下周,我计划发布在年度数据上测试系统的成果,以及算法在实时模拟交易中的首批成果。那里有一些非常有趣的发现。
说实话,我甚至没想到这个项目会进展到这一步。这一切始于一个简单的数据挖掘实验,尝试为分类算法的需要严格分类所有市场走势,最终发展成了一个完整的交易系统。我认为我刚刚开始理解这种方法的真正潜力。
外汇交易中的实现细节
让我们稍微回顾一下代码本身。我们的代码有几个重要的细节,用于处理金融数据:
column_groups = {
'trend': [col for col in df.columns if 'Trend' in col],
'rsi': [col for col in df.columns if 'RSI_Zone' in col],
'volume': [col for col in df.columns if 'Volume_Zone' in col],
'price': [col for col in df.columns if 'Price_Zone' in col],
'pattern': [col for col in df.columns if 'Pattern' in col]
}
这种分组有助于找到更有意义的指标组合,并降低计算复杂性。
def _is_meaningful_rule(self, rule): if rule['lift'] < 1.5 or rule['leverage'] < 0.01: return False has_trend_or_rsi = any('Trend' in item or 'RSI' in item for item in rule['antecedent'] + rule['consequent']) if not has_trend_or_rsi: return False return True
我们只选择具有强统计显著性(提升度 > 1.5)且必须包含趋势指标或RSI的规则。
def _rule_score(self, rule): return (rule['lift'] * 0.4 + rule['confidence'] * 0.3 + rule['support'] * 0.2 + rule['leverage'] * 0.1)
加权评分有助于根据其对交易的潜在有用性对规则进行排名。
可视化发现的规则
在找到关联规则后,我们应该正确地对它们进行可视化和分析。为此,我开发了一个特殊的ForexRulesVisualizer类,它提供了几种对找到的模式进行视觉分析的方法。
规则指标的分布
分析的第一步是了解找到的规则的主要指标的分布情况。“支持度”、“置信度”、“提升度”和“杠杆”的分布图有助于评估找到的规则的质量,并在必要时调整算法参数。
特别有用的工具是交互式网络图,它清晰地显示了不同市场条件之间的联系。在这个图中,节点是指标状态(例如“EURUSD_Trend=Uptrend”或“USDJPY_RSI_Zone=Overbought”),边代表找到的规则,其中边的厚度与“提升度”值成正比。
货币对相互作用的热力图 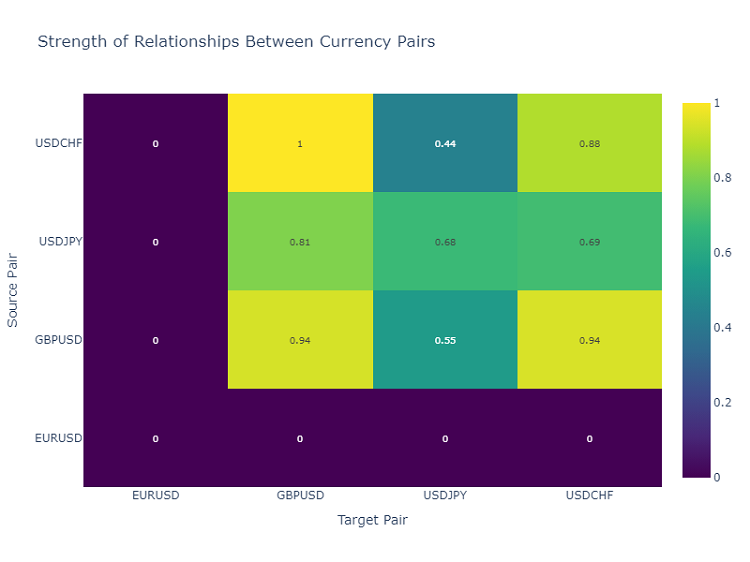
为了分析货币对之间的关系,我使用热力图,它显示了不同工具之间的关系强度。这有助于识别最常相互影响的货币对,这对于构建多样化的交易组合至关重要。
创建交易信号
在找到并可视化了关联规则之后,下一步重要的步骤是将它们转化为交易信号。为此,我开发了ForexSignalGenerator类,它分析市场的当前状态,并根据找到的规则生成交易信号。
import pandas as pd import numpy as np from datetime import datetime import logging class ForexSignalGenerator: def __init__(self, rules_df, min_rule_strength=0.5): """ Signal generator initialization Parameters: rules_df: DataFrame with association rules min_rule_strength: minimum rule strength to generate a signal """ self.rules_df = rules_df self.min_rule_strength = min_rule_strength self.active_signals = {} def calculate_rule_strength(self, rule): """ Comprehensive assessment of the rule strength Takes into account all metrics with different weights """ strength = ( rule['lift'] * 0.4 + # Main weight on 'lift' rule['confidence'] * 0.3 + # Rule confidence rule['support'] * 0.2 + # Occurrence frequency rule['leverage'] * 0.1 # Improvement over randomness ) # Additional bonus for having trend indicators if any('Trend' in item for item in rule['antecedent']): strength *= 1.2 return strength def analyze_market_state(self, current_data): """ Current market state analysis Parameters: current_data: DataFrame with current indicator values """ signals = [] state = self._create_market_state(current_data) # Find all the matching rules matching_rules = self._find_matching_rules(state) # Grouping rules by currency pairs for pair in ['EURUSD', 'GBPUSD', 'USDJPY', 'USDCHF']: pair_rules = [r for r in matching_rules if any(pair in c for c in r['consequent'])] if pair_rules: signal = self._generate_pair_signal(pair, pair_rules) signals.append(signal) return signals def _create_market_state(self, data): """Forming the current market state""" state = [] for col in data.columns: if any(x in col for x in ['_Zone', '_Pattern', 'Trend']): state.append(f"{col}={data[col].iloc[-1]}") return set(state) def _find_matching_rules(self, state): """Searching for rules that match the current state""" matching_rules = [] for _, rule in self.rules_df.iterrows(): # Check if all the rule conditions are met if all(cond in state for cond in rule['antecedent']): strength = self.calculate_rule_strength(rule) if strength >= self.min_rule_strength: rule['calculated_strength'] = strength matching_rules.append(rule) return matching_rules def _generate_pair_signal(self, pair, rules): """Generating a signal for a specific currency pair""" # Divide the rules by signal type trend_signals = defaultdict(float) for rule in rules: # Looking for trend-related consequents trend_cons = [c for c in rule['consequent'] if pair in c and 'Trend' in c] if trend_cons: for cons in trend_cons: trend = cons.split('=')[1] trend_signals[trend] += rule['calculated_strength'] # Determine the final signal if trend_signals: strongest_trend = max(trend_signals.items(), key=lambda x: x[1]) return { 'pair': pair, 'signal': strongest_trend[0], 'strength': strongest_trend[1], 'timestamp': datetime.now() } return None # Usage example def run_trading_system(data, rules_df): """ Trading system launch Parameters: data: DataFrame with historical data rules_df: DataFrame with association rules """ signal_generator = ForexSignalGenerator(rules_df) # Simulate a pass along historical data signals_history = [] for i in range(len(data) - 1): current_slice = data.iloc[i:i+1] signals = signal_generator.analyze_market_state(current_slice) for signal in signals: if signal: signals_history.append({ 'datetime': current_slice.index[0], 'pair': signal['pair'], 'signal': signal['signal'], 'strength': signal['strength'] }) return pd.DataFrame(signals_history) # Loading historical data and rules data = pd.read_csv('forex_data_combined_20241116_090857.csv', sep='\t', encoding='utf-16', index_col='DateTime', parse_dates=True) rules_df = pd.read_csv('forex_rules_advanced.csv', sep='\t', encoding='utf-16') rules_df['antecedent'] = rules_df['antecedent'].apply(eval) rules_df['consequent'] = rules_df['consequent'].apply(eval) # Launch the test signals_df = run_trading_system(data, rules_df) # Analyze the results print("Generated signals statistics:") print(signals_df.groupby('pair')['signal'].value_counts())
评估规则的有效性
在长时间进行规则可视化实验后,现在到了最困难的部分——创建实际的交易信号。我承认,这项任务让我费了不少力气。在图表上找到漂亮的模式是一回事,而将其转化为可运作的交易系统则是另一回事。
我决定创建一个单独的模块 ForexSignalGenerator。起初,我只是想根据最强的规则生成信号,但很快意识到事情要复杂得多。市场在不断变化,昨天效果很好的规则今天可能会失效。
我不得不认真对待规则有效性的评估。经过几次失败的实验后,我开发了一个评分系统。在选择比例方面我遇到了最大的困难——我可能尝试了数十种组合。最终,我确定了“提升度”占最终评估的40%(这是一个真正关键的指标),“置信度”占30%,“支持度”占20%,“杠杆率”占10%。
有趣的是,当规则包含趋势成分时,往往能获得最强的信号。我甚至为这样的规则增加了20%的特殊奖励,实践证明这是合理的。
在分析当前市场状态时,我也付出了不少努力。起初,我只是简单地将当前指标值与规则条件进行比较。但后来我意识到需要考虑更广泛的背景。例如,我添加了对过去几个周期内整体趋势的验证、波动状态,甚至是一天中的时间段。
目前,该系统会对每种货币对大约20个不同的参数进行分析。我找到的一些模式真的让我感到惊讶。
诚然,该系统仍然远非完美。有时,我会想是否需要添加基本面因素。然而,我留待以后再处理这个问题。首先,我想完成当前版本。
信号排序和聚合
在系统开发过程中,我很快意识到仅仅找到规则是不够的——我们需要对信号质量进行严格控制。经过几次不成功的交易后,很明显,排序甚至比找到模式本身更重要。
我开始采用一个简单的最低规则有效性阈值。起初我将其设置为0.5,但我不断得到误报。经过两周的测试后,我将阈值提高到0.7,情况明显改善。信号数量减少了大约三分之一,但质量显著提高。
第二级排序是在一次特别令人沮丧的事件之后出现的。有一个表现优异的规则,我根据它开仓,但市场却朝着完全相反的方向发展。当我开始调查时,发现当时其他规则正在发出相反的信号。从那时起,我都会检查一致性,只有在多个规则指向同一方向时才会开仓。
处理波动性变得很有趣。我注意到在平稳时期系统运行得像钟表一样精确,但一旦市场变得更加活跃,问题就开始出现。因此,我添加了基于ATR的动态过滤器。如果过去20天的波动性超过第75百分位数,我们会提高对规则强度的要求20%。
最困难的部分是检查冲突信号。有时一些规则建议买入,另一些建议卖出,而所有规则都有良好的参数。我尝试了不同的方法,但最终确定了一个简单的解决方案:如果信号存在显著矛盾,我们就跳过这种情况。这样做我们会失去一些机会,但会显著降低风险。
下个月,我计划添加时间筛选规则。我注意到在某些时段规则的表现明显更差。这在流动性较低和发布重要新闻的时期尤其如此。我认为,这应该会进一步提高成功交易的比例。
测试结果
在系统开发几个月后,我遇到了一个关键问题——如何正确评估每个找到的规则的有效性?理论上看起来很简单,但真实市场很快暴露了初始方法的所有弱点。
经过长时间的实验,我得出了一套不同因素的权重系统。我让“提升度”成为主要组成部分(影响40%)——实践证明这是一个真正至关重要的指标。“置信度”占30%——毕竟规则的置信度也很重要。“支持度”和“杠杆率”被赋予了较小的权重——它们更多地起到过滤作用。
信号排序成了一个独立的规则。起初,我尝试按顺序交易所有规则,但很快意识到自己的错误。因此,我不得不引入一个多级排序系统。首先,我们根据最低强度阈值筛选出弱规则。然后我们检查信号是否由多个规则确认——通常单个规则可靠性较低。
考虑波动性被证明尤为重要。在市场平稳时期,系统运行完美,但一旦波动性飙升,误报数量急剧增加。我不得不添加动态过滤器,随着波动性增加而变得更加严格。
系统测试几乎花了三个月。我对其进行了为期两年的四对主要货币对的回测。结果相当出乎意料。例如,USDJPY表现最佳——65%的交易盈利,风险回报率1.6。但GBPUSD令人失望——只有58%,风险回报率1.4。
有趣的是,提升度超过2.0且置信度超过0.8的规则对所有货币对都始终表现出最佳结果。显然,这些水平在汇市中确实是一些自然显著性阈值。
进一步改进
目前,我看到系统有几个改进方向。首先,规则的参数需要更加动态——市场在变化,系统需要适应。其次,明显缺乏对宏观经济和新闻背景的考虑。是的,这会使系统复杂化,但潜在的收益值得这样做。
应用自适应过滤器似乎特别有趣。不同的市场阶段显然需要不同的系统设置。目前实现得比较粗糙,但我已经看到几种改进方法。
下周我计划开始测试一个具有动态优化仓位大小的新版本。历史数据上的初步结果看起来很有希望,但真实市场,一如既往,会做出自己的调整。
结论
在算法交易中使用关联规则为发现市场中不明显模式开辟了新的机会。成功的关键在于适当的数据准备、仔细选择规则以及一个设计良好的信号生成系统。
重要的是要记住,任何交易系统都需要持续监控并适应不断变化的市场条件。关联规则是一个强大的分析工具,但它们需要与其他技术分析和基本面分析方法结合使用。
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/16061
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

显然,我们假定读者已经对这种方法有所了解,如果不是呢?
我尤其不理解其中提到的指标:
提升率已成为我最喜欢的指标。经过数百小时的测试,我发现了一个规律--升水高于 1.5 的规则在实际市场中确实有效。这一发现严重影响了我的信号过滤 方法。
如果我对该方法理解正确的话,相关信号是在量子段中搜索的。但我不明白下一步该怎么做。目标信号是什么?我猜测是根据目标检查生成的规则,并根据度量标准进行评估。
如果是这样的话,这与我的方法不谋而合,而且评估性能和效率也很有趣。