
Uso de reglas de asociación en el análisis de datos de Forex

Introducción al concepto de reglas de asociación
El comercio algorítmico moderno requiere nuevos enfoques de análisis. El mercado está en constante cambio, y los métodos clásicos de análisis técnico ya no son capaces de identificar las complejas relaciones del mercado.
Llevo mucho tiempo trabajando con datos y he observado que muchas ideas exitosas provienen de áreas relacionadas. Hoy quiero compartir mi experiencia sobre el uso de reglas de asociación en el trading. Este método ha demostrado su eficacia en el análisis minorista, permitiéndonos encontrar conexiones entre compras, transacciones, movimientos de precios y oferta y demanda futuras. ¿Qué pasa si lo aplicamos al mercado de divisas?
La idea básica es simple: buscamos patrones estables de comportamiento de precios, indicadores y sus combinaciones. Por ejemplo, ¿con qué frecuencia un aumento del EURUSD sigue a una caída del USDJPY? ¿O qué condiciones preceden con mayor frecuencia a los movimientos fuertes?
En este artículo, mostraré el proceso completo de creación de un sistema de trading basado en esta idea. Haremos lo siguiente:
- Recopilar datos históricos en MQL5.
- Analizarlos en Python.
- Encontrar patrones significativos.
- Transformarlos en señales de trading.
¿Por qué esta combinación en particular? MQL5 es ideal para trabajar con datos bursátiles y automatizar operaciones bursátiles. A su vez, Python proporciona potentes herramientas para el análisis. Por mi experiencia, puedo decir que esa combinación es muy eficaz para desarrollar sistemas de trading.
Habrá muchas cosas interesantes en el código, concretamente en el ámbito de la aplicación de reglas de asociación al mercado de divisas.
Recopilación y preparación de datos históricos sobre el mercado de divisas (Forex).
Para nosotros es sumamente importante recopilar y preparar todos los datos que necesitamos. Tomemos como base los datos H1 de los principales pares de divisas de los últimos dos años (desde 2022).
Ahora crearemos un script MQL5, que recopilará y exportará los datos que necesitamos en formato CSV:
//+------------------------------------------------------------------+ //| Dataset.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { string pairs[] = {"EURUSD", "GBPUSD", "USDJPY", "USDCHF"}; datetime startTime = D'2022.01.01 00:00'; datetime endTime = D'2024.01.01 00:00'; for(int i=0; i<ArraySize(pairs); i++) { string filename = pairs[i] + "_H1.csv"; int fileHandle = FileOpen(filename, FILE_WRITE|FILE_CSV); if(fileHandle != INVALID_HANDLE) { // Set headers FileWrite(fileHandle, "DateTime", "Open", "High", "Low", "Close", "Volume"); MqlRates rates[]; ArraySetAsSeries(rates, true); int copied = CopyRates(pairs[i], PERIOD_H1, startTime, endTime, rates); for(int j=copied-1; j>=0; j--) { FileWrite(fileHandle, TimeToString(rates[j].time), DoubleToString(rates[j].open, 5), DoubleToString(rates[j].high, 5), DoubleToString(rates[j].low, 5), DoubleToString(rates[j].close, 5), IntegerToString(rates[j].tick_volume) ); } FileClose(fileHandle); } } } //+------------------------------------------------------------------+
Procesamiento de datos en Python
Después de formar un conjunto de datos, es importante manejar los datos correctamente.
Para este propósito, creé la clase especial ForexDataProcessor, que se encarga de todo el trabajo sucio. Echemos un vistazo a sus componentes principales.
Comenzaremos cargando los datos. Nuestra función trabaja con datos por hora para los principales pares de divisas: EURUSD, GBPUSD, USDJPY y USDCHF. Los datos deben estar en formato CSV con las principales características del precio.
import pandas as pd
import numpy as np
from datetime import datetime
import os
import warnings
warnings.filterwarnings('ignore')
class ForexDataProcessor:
def __init__(self):
self.pairs = ["EURUSD", "GBPUSD", "USDJPY", "USDCHF"]
self.data = {}
self.processed_data = {}
def load_data(self):
"""Load data for all currency pairs"""
success = True
for pair in self.pairs:
filename = f"{pair}_H1.csv"
try:
df = pd.read_csv(filename,
encoding='utf-16',
sep='\t',
names=['DateTime', 'Open', 'High', 'Low', 'Close', 'Volume'])
# Remove lines with duplicate headers
df = df[df['DateTime'] != 'DateTime']
# Convert data types
df['DateTime'] = pd.to_datetime(df['DateTime'], format='%Y.%m.%d %H:%M')
for col in ['Open', 'High', 'Low', 'Close']:
df[col] = pd.to_numeric(df[col], errors='coerce')
df['Volume'] = pd.to_numeric(df['Volume'], errors='coerce')
# Remove NaN strings
df = df.dropna()
df.set_index('DateTime', inplace=True)
self.data[pair] = df
print(f"Loaded {pair} data successfully. Shape: {df.shape}")
except Exception as e:
print(f"Error loading {pair} data: {str(e)}")
success = False
return success
def safe_qcut(self, series, q, labels):
"""Safe quantization with error handling"""
try:
if series.nunique() <= q:
# If there are fewer unique values than quantiles, use regular categorization
return pd.qcut(series, q=q, labels=labels, duplicates='drop')
return pd.qcut(series, q=q, labels=labels)
except Exception as e:
print(f"Warning: Error in qcut - {str(e)}. Using manual categorization.")
# Manual categorization as a backup option
percentiles = np.percentile(series, [20, 40, 60, 80])
return pd.cut(series,
bins=[-np.inf] + list(percentiles) + [np.inf],
labels=labels)
def calculate_indicators(self, df):
"""Calculate technical indicators for a single dataframe"""
result = df.copy()
# Basic calculations
result['Returns'] = result['Close'].pct_change()
result['Log_Returns'] = np.log(result['Close']/result['Close'].shift(1))
result['Range'] = result['High'] - result['Low']
result['Range_Pct'] = result['Range'] / result['Open'] * 100
# SMA calculations
for period in [5, 10, 20, 50, 200]:
result[f'SMA_{period}'] = result['Close'].rolling(window=period).mean()
# EMA calculations
for period in [5, 10, 20, 50]:
result[f'EMA_{period}'] = result['Close'].ewm(span=period, adjust=False).mean()
# Volatility
result['Volatility'] = result['Returns'].rolling(window=20).std() * np.sqrt(20)
# RSI
delta = result['Close'].diff()
gain = (delta.where(delta > 0, 0)).rolling(window=14).mean()
loss = (-delta.where(delta < 0, 0)).rolling(window=14).mean()
rs = gain / loss
result['RSI'] = 100 - (100 / (1 + rs))
# MACD
exp1 = result['Close'].ewm(span=12, adjust=False).mean()
exp2 = result['Close'].ewm(span=26, adjust=False).mean()
result['MACD'] = exp1 - exp2
result['MACD_Signal'] = result['MACD'].ewm(span=9, adjust=False).mean()
result['MACD_Hist'] = result['MACD'] - result['MACD_Signal']
# Bollinger Bands
result['BB_Middle'] = result['Close'].rolling(window=20).mean()
result['BB_Upper'] = result['BB_Middle'] + (result['Close'].rolling(window=20).std() * 2)
result['BB_Lower'] = result['BB_Middle'] - (result['Close'].rolling(window=20).std() * 2)
result['BB_Width'] = (result['BB_Upper'] - result['BB_Lower']) / result['BB_Middle']
# Discretization for association rules
# SMA-based trend
result['Trend'] = 'Sideways'
result.loc[result['Close'] > result['SMA_50'], 'Trend'] = 'Uptrend'
result.loc[result['Close'] < result['SMA_50'], 'Trend'] = 'Downtrend'
# RSI zones
result['RSI_Zone'] = pd.cut(result['RSI'].fillna(50),
bins=[-np.inf, 30, 45, 55, 70, np.inf],
labels=['Oversold', 'Weak', 'Neutral', 'Strong', 'Overbought'])
# Secure quantization for other parameters
labels = ['Very_Low', 'Low', 'Medium', 'High', 'Very_High']
result['Volatility_Zone'] = self.safe_qcut(
result['Volatility'].fillna(result['Volatility'].mean()),
5, labels)
result['Price_Zone'] = self.safe_qcut(
result['Close'],
5, labels)
result['Volume_Zone'] = self.safe_qcut(
result['Volume'],
5, labels)
# Candle patterns
result['Body'] = result['Close'] - result['Open']
result['Upper_Shadow'] = result['High'] - result[['Open', 'Close']].max(axis=1)
result['Lower_Shadow'] = result[['Open', 'Close']].min(axis=1) - result['Low']
result['Body_Pct'] = result['Body'] / result['Open'] * 100
body_mean = abs(result['Body_Pct']).mean()
result['Candle_Pattern'] = 'Normal'
result.loc[abs(result['Body_Pct']) < body_mean * 0.1, 'Candle_Pattern'] = 'Doji'
result.loc[result['Body_Pct'] > body_mean * 2, 'Candle_Pattern'] = 'Long_Bullish'
result.loc[result['Body_Pct'] < -body_mean * 2, 'Candle_Pattern'] = 'Long_Bearish'
return result
def process_all_pairs(self):
"""Process all currency pairs and create combined dataset"""
if not self.load_data():
return None
# Handling each pair
for pair in self.pairs:
if not self.data[pair].empty:
print(f"Processing {pair}...")
self.processed_data[pair] = self.calculate_indicators(self.data[pair])
# Add a pair prefix to the column names
self.processed_data[pair].columns = [f"{pair}_{col}" for col in self.processed_data[pair].columns]
else:
print(f"Skipping {pair} - no data")
# Find the common time range for non-empty data
common_dates = None
for pair in self.pairs:
if pair in self.processed_data and not self.processed_data[pair].empty:
if common_dates is None:
common_dates = set(self.processed_data[pair].index)
else:
common_dates &= set(self.processed_data[pair].index)
if not common_dates:
print("No common dates found")
return None
# Align all pairs by common dates
aligned_data = {}
for pair in self.pairs:
if pair in self.processed_data and not self.processed_data[pair].empty:
aligned_data[pair] = self.processed_data[pair].loc[sorted(common_dates)]
# Combine all pairs
combined_df = pd.concat([aligned_data[pair] for pair in aligned_data], axis=1)
return combined_df
def save_data(self, data, suffix='combined'):
"""Save processed data to CSV"""
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
filename = f"forex_data_{suffix}_{timestamp}.csv"
try:
data.to_csv(filename, sep='\t', encoding='utf-16')
print(f"Saved processed data to: {filename}")
return True
except Exception as e:
print(f"Error saving data: {str(e)}")
return False
if __name__ == "__main__":
processor = ForexDataProcessor()
# Handling all pairs
combined_data = processor.process_all_pairs()
if combined_data is not None:
# Save the combined dataset
processor.save_data(combined_data)
# Display dataset info
print("\nCombined dataset shape:", combined_data.shape)
print("\nFeatures for association rules analysis:")
for col in combined_data.columns:
if any(x in col for x in ['_Zone', '_Pattern', 'Trend']):
print(f"- {col}")
# Save individual pairs
for pair in processor.pairs:
if pair in processor.processed_data and not processor.processed_data[pair].empty:
processor.save_data(processor.processed_data[pair], pair)
Después de una carga exitosa, comienza la parte más interesante: el cálculo de indicadores técnicos. Aquí me baso en todo un arsenal de herramientas probadas con el tiempo. Las medias móviles ayudan a identificar tendencias de diversa duración. La SMA (50) suele actuar como soporte o resistencia dinámica. El oscilador RSI con un período clásico de 14 es bueno para determinar zonas de mercado de sobrecompra y sobreventa. El MACD es indispensable para identificar puntos de impulso y reversión. Las bandas de Bollinger brindan una imagen clara de la volatilidad actual del mercado.
# Volatility and RSI calculation example result['Volatility'] = result['Returns'].rolling(window=20).std() * np.sqrt(20) delta = result['Close'].diff() gain = (delta.where(delta > 0, 0)).rolling(window=14).mean() loss = (-delta.where(delta < 0, 0)).rolling(window=14).mean() rs = gain / loss result['RSI'] = 100 - (100 / (1 + rs))
La discretización de datos merece especial atención. Todos los valores continuos deben desglosarse en categorías claras. En este asunto, es importante encontrar un término medio: una división demasiado marcada complicará la búsqueda de patrones, y una división demasiado estrecha provocará la pérdida de matices importantes del mercado. Por ejemplo, para determinar la tendencia, funciona mejor una división más simple: por la posición del precio en relación con la media:
# Defining a trend result['Trend'] = 'Sideways' result.loc[result['Close'] > result['SMA_50'], 'Trend'] = 'Uptrend' result.loc[result['Close'] < result['SMA_50'], 'Trend'] = 'Downtrend'
Los patrones de velas también requieren un enfoque especial. Basándome en el análisis estadístico, distingo Doji en el tamaño mínimo del cuerpo de la vela, Long_Bullish y Long_Bearish en movimientos extremos de precios. Esta clasificación nos permite identificar claramente los momentos de indecisión del mercado y los movimientos impulsivos fuertes.
Al final del procesamiento, todos los pares de divisas se combinan en una única matriz de datos con una escala de tiempo común. Este paso es de importancia fundamental, ya que abre la posibilidad de buscar relaciones complejas entre diferentes instrumentos. Ahora podemos ver cómo la tendencia de un par afecta a la volatilidad de otro, o cómo los patrones de velas japonesas se relacionan con los volúmenes de negociación en todo el mercado.
Implementación del algoritmo Apriori en Python
Después de preparar los datos, pasamos a la etapa clave: implementar el algoritmo Apriori para encontrar reglas de asociación en nuestros datos financieros. Adaptamos el algoritmo Apriori, desarrollado originalmente para analizar cestas de la compra, para que funcione con series temporales de pares de divisas.
En el contexto del mercado de divisas, una «transacción» es un conjunto de estados de diversos indicadores y pares de divisas en un momento determinado. Por ejemplo:- EURUSD_Trend = Tendencia alcista
- GBPUSD_RSI_Zone = Sobrecomprado
- USDJPY_Volatility_Zone = Alto
El algoritmo busca combinaciones frecuentes de dichos estados, a partir de las cuales se establecen las reglas de negociación.
import pandas as pd import numpy as np from collections import defaultdict from itertools import combinations import time import logging # Setting up logging logging.basicConfig( level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s', handlers=[ logging.FileHandler('apriori_forex_advanced.log'), logging.StreamHandler() ] ) class AdvancedForexApriori: def __init__(self, min_support=0.01, min_confidence=0.7, max_length=3): self.min_support = min_support self.min_confidence = min_confidence self.max_length = max_length def find_patterns(self, df): start_time = time.time() logging.info("Starting advanced pattern search...") # Group columns by type for more meaningful analysis column_groups = { 'trend': [col for col in df.columns if 'Trend' in col], 'rsi': [col for col in df.columns if 'RSI_Zone' in col], 'volume': [col for col in df.columns if 'Volume_Zone' in col], 'price': [col for col in df.columns if 'Price_Zone' in col], 'pattern': [col for col in df.columns if 'Pattern' in col] } # Create a list of all columns for analysis pattern_cols = [] for cols in column_groups.values(): pattern_cols.extend(cols) logging.info(f"Found {len(pattern_cols)} pattern columns in {len(column_groups)} groups") # Prepare data pattern_df = df[pattern_cols] n_rows = len(pattern_df) # Find single patterns logging.info("Finding single patterns...") single_patterns = {} for col in pattern_cols: value_counts = pattern_df[col].value_counts() value_counts = value_counts[value_counts/n_rows >= self.min_support] for value, count in value_counts.items(): pattern = f"{col}={value}" single_patterns[pattern] = count/n_rows # Find pair and triple patterns logging.info("Finding complex patterns...") complex_rules = [] # Generate column combinations for analysis column_combinations = [] for i in range(2, self.max_length + 1): column_combinations.extend(combinations(pattern_cols, i)) total_combinations = len(column_combinations) for idx, cols in enumerate(column_combinations, 1): if idx % 10 == 0: logging.info(f"Processing combination {idx}/{total_combinations}") # Create a cross-table for the selected columns grouped = pattern_df.groupby([*cols]).size().reset_index(name='count') grouped['support'] = grouped['count'] / n_rows # Sort by minimum support grouped = grouped[grouped['support'] >= self.min_support] for _, row in grouped.iterrows(): # Form all possible combinations of antecedents and consequents items = [f"{col}={row[col]}" for col in cols] for i in range(1, len(items)): for antecedent in combinations(items, i): consequent = tuple(set(items) - set(antecedent)) # Calculate the support of the antecedent ant_support = self._calculate_support(pattern_df, antecedent) if ant_support > 0: # Avoid division by zero confidence = row['support'] / ant_support if confidence >= self.min_confidence: # Count the lift cons_support = self._calculate_support(pattern_df, consequent) lift = confidence / cons_support if cons_support > 0 else 0 # Adding additional metrics to evaluate rules leverage = row['support'] - (ant_support * cons_support) conviction = (1 - cons_support) / (1 - confidence) if confidence < 1 else float('inf') rule = { 'antecedent': antecedent, 'consequent': consequent, 'support': row['support'], 'confidence': confidence, 'lift': lift, 'leverage': leverage, 'conviction': conviction } # Sort the rules by additional criteria if self._is_meaningful_rule(rule): complex_rules.append(rule) # Sort the rules by complex metric complex_rules.sort(key=self._rule_score, reverse=True) end_time = time.time() logging.info(f"Pattern search completed in {end_time - start_time:.2f} seconds") logging.info(f"Found {len(complex_rules)} meaningful rules") return complex_rules def _calculate_support(self, df, items): """Calculate support for a set of elements""" mask = pd.Series(True, index=df.index) for item in items: col, val = item.split('=') mask &= (df[col] == val) return mask.mean() def _is_meaningful_rule(self, rule): """Check the rule for its relevance to trading""" # The rule should have the high lift and 'leverage' if rule['lift'] < 1.5 or rule['leverage'] < 0.01: return False # At least one element should be related to a trend or RSI has_trend_or_rsi = any('Trend' in item or 'RSI' in item for item in rule['antecedent'] + rule['consequent']) if not has_trend_or_rsi: return False return True def _rule_score(self, rule): """Calculate the rule complex evaluation""" return (rule['lift'] * 0.4 + rule['confidence'] * 0.3 + rule['support'] * 0.2 + rule['leverage'] * 0.1) # Load data logging.info("Loading data...") data = pd.read_csv('forex_data_combined_20241116_074242.csv', sep='\t', encoding='utf-16', index_col='DateTime') logging.info(f"Data loaded, shape: {data.shape}") # Apply the algorithm apriori = AdvancedForexApriori(min_support=0.01, min_confidence=0.7, max_length=3) rules = apriori.find_patterns(data) # Display results logging.info("\nTop 10 trading rules:") for i, rule in enumerate(rules[:10], 1): logging.info(f"\nRule {i}:") logging.info(f"IF {' AND '.join(rule['antecedent'])}") logging.info(f"THEN {' AND '.join(rule['consequent'])}") logging.info(f"Support: {rule['support']:.3f}") logging.info(f"Confidence: {rule['confidence']:.3f}") logging.info(f"Lift: {rule['lift']:.3f}") logging.info(f"Leverage: {rule['leverage']:.3f}") logging.info(f"Conviction: {rule['conviction']:.3f}") # Save results results_df = pd.DataFrame(rules) results_df.to_csv('forex_rules_advanced.csv', index=False, sep='\t', encoding='utf-16') logging.info("Results saved to forex_rules_advanced.csv")
Adaptación de reglas de asociación para el análisis de pares de divisas
En el transcurso de mi trabajo de adaptación del algoritmo Apriori al mercado de divisas, me encontré con retos interesantes. Aunque este método se creó originalmente para analizar las compras en tiendas físicas, su potencial para el mercado Forex me pareció prometedor.
La principal dificultad era que el mercado Forex es radicalmente diferente a las compras habituales en una tienda. A lo largo de los años que llevo trabajando en los mercados financieros, me he acostumbrado a lidiar con precios e indicadores en constante cambio. Pero, ¿cómo se aplica un algoritmo que normalmente solo busca conexiones entre plátanos y leche en los tickets de caja de los supermercados?
Como resultado de mis experimentos, surgió un sistema de cinco métricas. Probé cada uno de ellos a fondo.
«Support» resultó ser una métrica muy complicada. Una vez estuve a punto de incluir una regla con un rendimiento excelente en un sistema de trading, pero el soporte era solo de 0.02. Afortunadamente, me di cuenta a tiempo: en la práctica, ¡esa regla solo se activaría una vez cada cien años!
«Confidence» resultó ser más sencillo. Cuando trabajas en el mercado, aprendes rápidamente que incluso una probabilidad del 70% es un indicador excelente. Lo más importante es gestionar los riesgos de forma inteligente con el 30% restante. Siempre debemos tener presente la gestión de riesgos. Sin él, te enfrentarás a una reducción o incluso a un agotamiento, aunque tengas el Santo Grial en tus manos.
«Lift» se ha convertido en mi indicador favorito. Después de cientos de horas de pruebas, observé una tendencia: las reglas con un apalancamiento superior a 1,5 realmente funcionan en el mercado real. Este descubrimiento tuvo un profundo impacto en mi enfoque de la clasificación de señales.
Tratar con «Leverage» resultó ser divertido. Al principio quería excluirlo por completo del sistema, ya que lo consideraba inútil. Pero durante un periodo especialmente volátil en el mercado, ayudó a descartar la mayoría de las señales falsas.
«Conviction» se añadió al final tras investigar en los foros. Me ayudó a comprender lo importante que es este indicador para evaluar la verdadera relevancia de los patrones encontrados.
Lo que más me sorprendió fue cómo el algoritmo encuentra conexiones inesperadas entre diferentes pares de divisas. Por ejemplo, ¿quién hubiera pensado que ciertos patrones en el EURUSD podrían predecir los movimientos del USDJPY con tanta precisión? En 9 años trabajando en el mercado, no me di cuenta de muchas de las relaciones que descubrió el algoritmo. Aunque el trading de pares, el trading de cestas y el arbitraje fueron en su día mi especialidad, aún recuerdo los tiempos en los que cmillion empezaba a desarrollar sus robots basados en los movimientos mutuos de los pares.
Ahora continúo mi investigación, probando nuevas combinaciones de indicadores y períodos de tiempo. El mercado está en constante cambio y cada día trae consigo nuevos descubrimientos. La próxima semana planeo publicar los resultados de las pruebas del sistema con datos anuales, así como los primeros resultados en vivo del algoritmo en operaciones de demostración en vivo. Allí se encuentran varios hallazgos muy interesantes.
Para ser honesto, ni siquiera esperaba que este proyecto llegara tan lejos. Todo comenzó como un simple experimento con minería de datos e intentos de clasificar rígidamente todos los movimientos del mercado para las necesidades de los algoritmos de clasificación, y finalmente se convirtió en un sistema comercial completo. Creo que apenas estoy empezando a comprender el verdadero potencial de este enfoque.
Características de implementación para Forex
Volvamos un poco al código en sí. Nuestro código tiene varias adaptaciones importantes del algoritmo para el manejo de datos financieros:
column_groups = {
'trend': [col for col in df.columns if 'Trend' in col],
'rsi': [col for col in df.columns if 'RSI_Zone' in col],
'volume': [col for col in df.columns if 'Volume_Zone' in col],
'price': [col for col in df.columns if 'Price_Zone' in col],
'pattern': [col for col in df.columns if 'Pattern' in col]
}
Esta agrupación ayuda a encontrar combinaciones más significativas de indicadores y reduce la complejidad computacional.
def _is_meaningful_rule(self, rule): if rule['lift'] < 1.5 or rule['leverage'] < 0.01: return False has_trend_or_rsi = any('Trend' in item or 'RSI' in item for item in rule['antecedent'] + rule['consequent']) if not has_trend_or_rsi: return False return True
Seleccionamos únicamente reglas con una fuerte significación estadística (lift > 1.5) y la inclusión obligatoria de indicadores de tendencia o RSI.
def _rule_score(self, rule): return (rule['lift'] * 0.4 + rule['confidence'] * 0.3 + rule['support'] * 0.2 + rule['leverage'] * 0.1)
La puntuación ponderada ayuda a clasificar las reglas en función de su utilidad potencial para el trading.
Visualización de las asociaciones encontradas
Después de encontrar las reglas de asociación, debemos visualizarlas y analizarlas correctamente. Para este propósito, he desarrollado la clase especial ForexRulesVisualizer, que proporciona varias formas de análisis visual de los patrones encontrados.
Distribución de métricas de reglas
El primer paso en el análisis es comprender la distribución de las principales métricas de las reglas encontradas. El gráfico de distribución de 'support', 'confidence', 'lift' y 'leverage' ayuda a evaluar la calidad de las reglas encontradas y, si es necesario, ajustar los parámetros del algoritmo.
Una herramienta especialmente útil fue el gráfico de red interactivo, que muestra claramente las conexiones entre las diferentes condiciones del mercado. En este gráfico, los nodos son los estados indicadores (por ejemplo, «EURUSD_Trend=Tendencia alcista» o «USDJPY_RSI_Zone=Sobrecomprado»), y los bordes representan las reglas encontradas, donde el grosor del borde es proporcional al valor «lift».
Mapa de calor de las interacciones entre pares de divisas 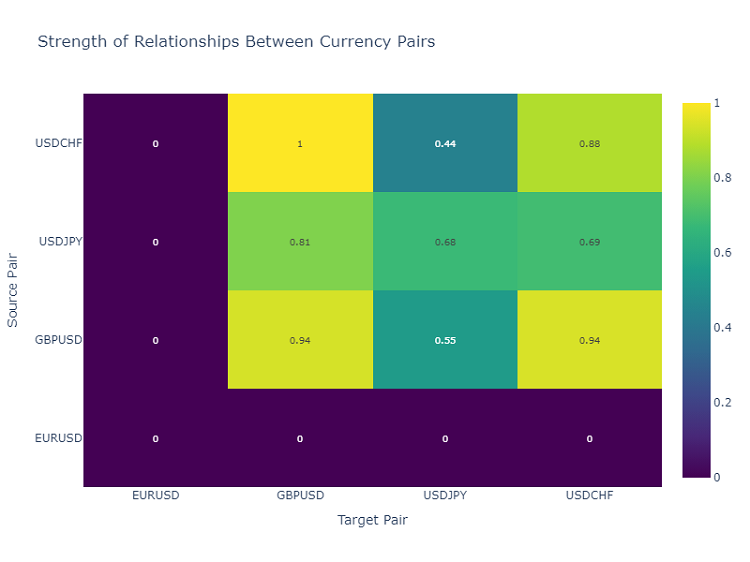
Para analizar las relaciones entre los pares de divisas, utilizo un mapa de calor, que muestra la fuerza de las relaciones entre los diferentes instrumentos. Esto ayuda a identificar los pares que más se influyen entre sí, lo cual es fundamental para construir una cartera de trading diversificada.
Creación de señales de trading
Una vez que hemos encontrado y visualizado las reglas de asociación, el siguiente paso importante es transformarlas en señales de trading. Para este fin, desarrollé la clase ForexSignalGenerator, que analiza el estado actual del mercado y genera señales de trading basadas en las reglas encontradas.
import pandas as pd import numpy as np from datetime import datetime import logging class ForexSignalGenerator: def __init__(self, rules_df, min_rule_strength=0.5): """ Signal generator initialization Parameters: rules_df: DataFrame with association rules min_rule_strength: minimum rule strength to generate a signal """ self.rules_df = rules_df self.min_rule_strength = min_rule_strength self.active_signals = {} def calculate_rule_strength(self, rule): """ Comprehensive assessment of the rule strength Takes into account all metrics with different weights """ strength = ( rule['lift'] * 0.4 + # Main weight on 'lift' rule['confidence'] * 0.3 + # Rule confidence rule['support'] * 0.2 + # Occurrence frequency rule['leverage'] * 0.1 # Improvement over randomness ) # Additional bonus for having trend indicators if any('Trend' in item for item in rule['antecedent']): strength *= 1.2 return strength def analyze_market_state(self, current_data): """ Current market state analysis Parameters: current_data: DataFrame with current indicator values """ signals = [] state = self._create_market_state(current_data) # Find all the matching rules matching_rules = self._find_matching_rules(state) # Grouping rules by currency pairs for pair in ['EURUSD', 'GBPUSD', 'USDJPY', 'USDCHF']: pair_rules = [r for r in matching_rules if any(pair in c for c in r['consequent'])] if pair_rules: signal = self._generate_pair_signal(pair, pair_rules) signals.append(signal) return signals def _create_market_state(self, data): """Forming the current market state""" state = [] for col in data.columns: if any(x in col for x in ['_Zone', '_Pattern', 'Trend']): state.append(f"{col}={data[col].iloc[-1]}") return set(state) def _find_matching_rules(self, state): """Searching for rules that match the current state""" matching_rules = [] for _, rule in self.rules_df.iterrows(): # Check if all the rule conditions are met if all(cond in state for cond in rule['antecedent']): strength = self.calculate_rule_strength(rule) if strength >= self.min_rule_strength: rule['calculated_strength'] = strength matching_rules.append(rule) return matching_rules def _generate_pair_signal(self, pair, rules): """Generating a signal for a specific currency pair""" # Divide the rules by signal type trend_signals = defaultdict(float) for rule in rules: # Looking for trend-related consequents trend_cons = [c for c in rule['consequent'] if pair in c and 'Trend' in c] if trend_cons: for cons in trend_cons: trend = cons.split('=')[1] trend_signals[trend] += rule['calculated_strength'] # Determine the final signal if trend_signals: strongest_trend = max(trend_signals.items(), key=lambda x: x[1]) return { 'pair': pair, 'signal': strongest_trend[0], 'strength': strongest_trend[1], 'timestamp': datetime.now() } return None # Usage example def run_trading_system(data, rules_df): """ Trading system launch Parameters: data: DataFrame with historical data rules_df: DataFrame with association rules """ signal_generator = ForexSignalGenerator(rules_df) # Simulate a pass along historical data signals_history = [] for i in range(len(data) - 1): current_slice = data.iloc[i:i+1] signals = signal_generator.analyze_market_state(current_slice) for signal in signals: if signal: signals_history.append({ 'datetime': current_slice.index[0], 'pair': signal['pair'], 'signal': signal['signal'], 'strength': signal['strength'] }) return pd.DataFrame(signals_history) # Loading historical data and rules data = pd.read_csv('forex_data_combined_20241116_090857.csv', sep='\t', encoding='utf-16', index_col='DateTime', parse_dates=True) rules_df = pd.read_csv('forex_rules_advanced.csv', sep='\t', encoding='utf-16') rules_df['antecedent'] = rules_df['antecedent'].apply(eval) rules_df['consequent'] = rules_df['consequent'].apply(eval) # Launch the test signals_df = run_trading_system(data, rules_df) # Analyze the results print("Generated signals statistics:") print(signals_df.groupby('pair')['signal'].value_counts())
Evaluación de la solidez de las normas
Tras largos experimentos con la visualización de las reglas, ha llegado el momento de la parte más difícil: crear señales de trading reales. Lo admito, esta tarea me hizo sudar bastante. Una cosa es encontrar patrones bonitos en los gráficos y otra muy distinta es convertirlos en un sistema de trading que funcione.
Decidí crear un módulo independiente llamado ForexSignalGenerator. Al principio, solo quería generar señales según las reglas más estrictas, pero pronto me di cuenta de que todo es mucho más complicado. El mercado cambia constantemente, y una regla que funcionaba bien ayer puede fallar hoy.
Tuve que adoptar un enfoque serio para evaluar la solidez de las normas. Tras varios experimentos fallidos, desarrollé un sistema de escala. Lo que más me costó fue elegir las proporciones; probablemente probé docenas de combinaciones. Al final, decidí que «lift» representaría el 40% de la evaluación final (este es un indicador realmente clave), «confidence», el 30%, «support», el 20%, y «leverage», el 10%.
Curiosamente, a menudo las señales más fuertes se obtenían cuando la regla contenía un componente de tendencia. Incluso añadí una bonificación especial del 20% a la fuerza de dichas normas, y la práctica ha demostrado que esto está justificado.
También tuve que trabajar duro al analizar la situación actual del mercado. Al principio, simplemente comparé los valores actuales de los indicadores con las condiciones de las reglas. Pero entonces me di cuenta de que tenía que tener en cuenta el contexto más amplio. Por ejemplo, añadí la verificación de la tendencia general durante los últimos periodos, el estado de volatilidad e incluso la hora del día.
Actualmente, el sistema analiza unos 20 parámetros diferentes para cada par de divisas. Algunos de los patrones que encontré realmente me sorprendieron.
Por supuesto, el sistema aún está lejos de ser perfecto. A veces me sorprendo pensando que necesito añadir factores fundamentales. Sin embargo, lo he dejado para más adelante. Primero, quiero terminar la versión actual.
Ordenación y agregación de señales
Durante el desarrollo del sistema, rápidamente me di cuenta de que simplemente encontrar reglas no es suficiente: necesitamos un control estricto de la calidad de las señales. Después de algunos intentos fallidos, quedó claro que la clasificación es quizás incluso más importante que encontrar patrones.
Comencé con un umbral simple de la fuerza mínima de la regla. Al principio lo configuré en 0.5, pero seguí obteniendo falsos positivos. Después de dos semanas de pruebas, lo aumenté a 0.7 y la situación mejoró notablemente. El número de señales ha disminuido en aproximadamente un tercio, pero su calidad ha aumentado significativamente.
El segundo nivel de clasificación apareció después de un incidente particularmente ofensivo. Había una regla con un rendimiento excelente, abrí una posición de acuerdo con ella, pero el mercado fue estrictamente en la dirección opuesta. Cuando comencé a investigar, resultó que otras reglas en ese momento estaban dando señales opuestas. Desde entonces, he estado comprobando la coherencia abriendo sólo si varias reglas apuntan en la misma dirección.
Lidiar con la volatilidad resultó ser interesante. He observado que durante los períodos de calma el sistema funciona como un reloj, pero tan pronto como el mercado se vuelve más animado, comienzan los problemas. Entonces, agregué un filtro dinámico por ATR. Si la volatilidad está por encima del percentil 75 en los últimos 20 días, aumentamos los requisitos de solidez de las reglas en un 20%.
La parte más difícil fue comprobar las señales conflictivas. Sucede que algunas reglas dicen comprar, otras dicen vender, y todas las reglas tienen buenos parámetros. Probé distintos enfoques, pero finalmente me decidí por una solución simple: si hay contradicciones significativas en las señales, saltamos esta situación. Al hacer eso perdemos algunas oportunidades, pero reducimos significativamente los riesgos.
El próximo mes voy a añadir la clasificación por tiempo. He notado que a determinadas horas las reglas funcionan notablemente peor. Esto es especialmente cierto durante períodos de baja liquidez y de publicación de noticias importantes. Pienso que esto debería aumentar aún más el porcentaje de operaciones exitosas.
Resultados de la prueba
Después de varios meses de desarrollar el sistema, me enfrenté a una pregunta clave: ¿cómo evaluar correctamente la fuerza de cada regla encontrada? Todo parecía sencillo en el papel, pero el mercado real rápidamente expuso todas las debilidades del enfoque inicial.
Como resultado de largos experimentos, llegué a un sistema de pesos para diferentes factores. Hice de «Lift» el componente principal (40% de influencia): la práctica ha demostrado que se trata de un indicador realmente crucial. «Confidence» aporta un 30%; al fin y al cabo, la confianza en la norma también es muy importante. Se ha otorgado menos peso a «Support» y «leverage», que actúan más bien como filtros.
La clasificación de señales resultó ser una historia aparte. Al principio intenté operar siguiendo todas las reglas seguidas, pero rápidamente me di cuenta de mi error. Entonces tuve que introducir un sistema de clasificación de varios niveles. En primer lugar, clasificamos las reglas débiles en función del umbral de fuerza mínimo. Luego verificamos si la señal está confirmada por varias reglas (las reglas individuales suelen ser menos confiables).
Tener en cuenta la volatilidad resultó ser especialmente importante. Durante los períodos de calma, el sistema funcionó perfectamente, pero tan pronto como la volatilidad saltó, el número de señales falsas aumentó drásticamente. Tuve que agregar filtros dinámicos que se vuelven más estrictos a medida que aumenta la volatilidad.
La prueba del sistema tardó casi tres meses. Lo ejecuté en un historial de dos años para cuatro pares principales. Los resultados fueron bastante inesperados. Por ejemplo, el USDJPY mostró el mejor desempeño: 65% de operaciones rentables con un RR de 1,6. Pero el GBPUSD fue decepcionante: sólo un 58% con un RR de 1,4.
Curiosamente, las reglas con un «lift» superior a 2,0 y una «confidence» superior a 0,8 mostraron sistemáticamente los mejores resultados para todos los pares. Aparentemente, estos niveles son realmente una especie de umbrales de importancia natural en el mercado Forex.
Mejoras adicionales
Actualmente, veo varias direcciones para mejorar el sistema. En primer lugar, es necesario dinamizar los parámetros de las reglas: el mercado está cambiando y el sistema necesita adaptarse. En segundo lugar, hay una clara falta de consideración de la macroeconomía y del contexto noticioso. Sí, complicará el sistema, pero las ganancias potenciales valen la pena.
La aplicación de filtros adaptativos parece especialmente interesante. Las diferentes fases del mercado claramente requieren diferentes configuraciones del sistema. Por el momento está implementado de forma rudimentaria, pero ya puedo ver varias formas de mejorarlo.
La próxima semana planeo comenzar a probar una nueva versión con optimización dinámica del tamaño de las posiciones. Los resultados preliminares basados en datos históricos parecen prometedores, pero el mercado real, como siempre, hará sus propios ajustes.
Conclusión
El uso de reglas de asociación en el trading algorítmico abre oportunidades interesantes para encontrar patrones de mercado no obvios. La clave del éxito aquí es una preparación adecuada de los datos, una selección cuidadosa de las reglas y un sistema de generación de señales bien pensado.
Es importante recordar que cualquier sistema de trading requiere un seguimiento constante y una adaptación a las condiciones cambiantes del mercado. Las reglas asociativas son una herramienta de análisis poderosa, pero deben utilizarse junto con otros métodos de análisis técnico y fundamental.
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/16061
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Al parecer, se da por supuesto que el lector ya debe tener algún conocimiento de dicho método, y si no?
No entiendo las métricas que se mencionan, en particular:
Lift se ha convertido en mi indicador favorito. Después de cientos de horas de pruebas, me di cuenta de un patrón - las reglas con lift por encima de 1,5 realmente funcionan en el mercado real. Este descubrimiento influyó seriamente en mi enfoque del filtrado de señales.
Si entendí bien el método, se buscan señales correlacionadas en segmentos cuánticos. Pero no entendía el siguiente paso. ¿Cuál es el objetivo? Supongo que las reglas resultantes se cotejan con el objetivo y se evalúan en función de las métricas.
Si es así, se hace eco de mi método, y es interesante para evaluar el rendimiento y la eficiencia.