Artigos sobre análise de dados e estatísticas na MQL5
Muitos traders apreciam artigos sobre modelos matemáticos e teoria das probabilidades. Afinal de contas, a matemática é a base dos indicadores técnicos, e o conhecimento em estatística é necessário para analisar os resultados das operações e desenvolver estratégias.
Leia sobre lógica fuzzy, filtros digitais, perfil do mercado, mapas de Kohonen, redes neurais e muitas outras ferramentas que podem ser usadas para negociação.
Novo artigo

Você está perdendo oportunidades de negociação:
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Registro
Login
Você concorda com a política do site e com os termos de uso
Se você não tem uma conta, por favor registre-se

Desenvolvendo um sistema de Replay - Simulação de mercado (Parte 24): FOREX (V)
Aqui estamos retirando o bloqueio de simulação baseada na plotagem LAST, e adicionando um ponto de entrada para este tipo de simulação. Agora prestem atenção ao fato de que todo o funcionamento, irá se basear no sistema do forex. Sendo que a única diferença, aqui nesta rotina, é o fato de que estaremos separando uma simulação BID, de uma LAST. Mas a questão de randomização do tempo e a sua correção para ser utilizado pela classe C_Replay, é a mesma em ambos modos de simulação. Isto é uma coisa boa, já que se modificarmos um dos modos, o outro irá se beneficiar, pelo menos no que rege a parte do tempo entre os tickets

Desenvolvendo um sistema de Replay (Parte 66): Dando play no serviço (VII)
Aqui neste artigo, vamos implementar uma primeira solução, para que possamos saber o momento em que uma nova barra poderá vim a surgir no gráfico. Esta solução se adequa a diversas situações. Porém entender como a mesma foi desenvolvida pode lhe ajudar a entender diversas questões. O conteúdo exposto aqui, visa e tem como objetivo, pura e simplesmente a didática. De modo algum deve ser encarado como sendo, uma aplicação cuja finalidade não venha a ser o aprendizado e estudo dos conceitos mostrados.

Algoritmo de recompra: modelo matemático para aumentar a eficiência
Neste artigo, usaremos o algoritmo de recompra como um guia para um entendimento mais profundo da eficiência dos sistemas de negociação e começaremos a trabalhar com os princípios gerais de aumentar a eficiência de negociação usando matemática e lógica, bem como aplicar os métodos mais inovadores para aumentar a eficiência no contexto de usar qualquer sistema de negociação.

Redes neurais de maneira fácil (Parte 21): Autocodificadores variacionais (VAE)
No último artigo, analisamos o algoritmo do autocodificador. Como qualquer outro algoritmo, tem suas vantagens e desvantagens. Na implementação original, o autocodificador executa a tarefa de separar os objetos da amostra de treinamento o máximo possível. E falaremos sobre como lidar com algumas de suas deficiências neste artigo.

Trabalhando com séries temporais na biblioteca DoEasy (Parte 54): classes herdeiras do indicador base abstrato
Neste artigo, analisaremos a criação de classes de objetos herdeiros do indicador base abstrato. Esses objetos nos darão acesso à capacidade de criar EAs de indicador, coletar e receber estatísticas sobre valores de dados de diferentes indicadores e preços. Também criaremos uma coleção de objetos-indicadores a partir da qual será possível acessar as propriedades e dados de cada indicador criado no programa.

Desenvolvendo um sistema de Replay - Simulação de mercado (Parte 13): Nascimento do SIMULADOR (III)
Aqui iremos dar uma leve otimizada nas coisas. Isto para facilitar o que iremos fazer no próximo artigo. Mas também irei explicar como você pode visualizar o que o simulador está gerando em termos de aleatoriedade.
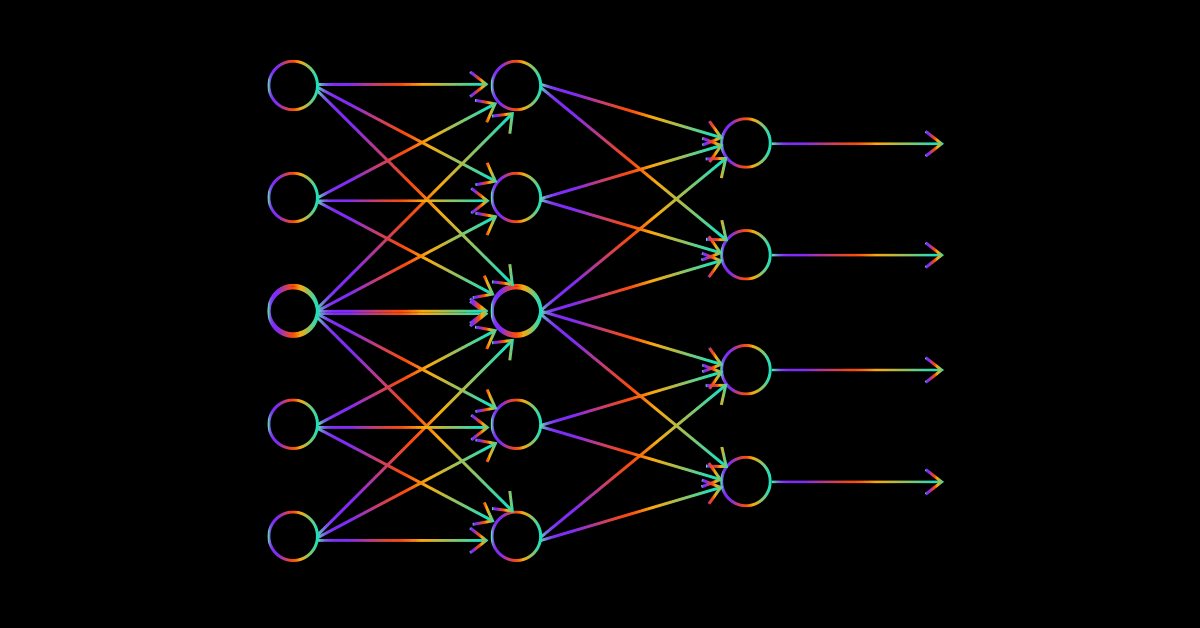
Ciência de Dados e Aprendizado de Máquina — Redes Neurais (Parte 02): Arquitetura das Redes Neurais Feed Forward
Há detalhes a serem abordadas na rede neural feed-forward antes de finalizarmos este assunto, a arquitetura é uma delas. Vamos ver como nós podemos construir e desenvolver uma rede neural flexível para as nossas entradas, o número de camadas ocultas e os nós para cada rede.
Fatorando Matrizes — O Básico
Como o intuito aqui é ser didático. Vou manter a coisa no seu padrão mais simples. Ou seja, iremos implementar apenas e somente o que será preciso. A multiplicação de matrizes. E você verá que isto será o suficiente para simular a multiplicação de uma matriz por um escalar. A grande dificuldade que muita gente tem em implementar um código usando fatoração de matrizes, é que diferente de uma fatoração escalar, onde em quase todos os casos a ordem dos fatores não altera o resultado. Quando se usa matrizes, a coisa não é bem assim.

Análise quantitativa no MQL5: implementando um algoritmo promissor
Vamos explorar o que é a análise quantitativa, como os grandes players a utilizam e criar um dos algoritmos de análise quantitativa na linguagem MQL5.

Data Science e Machine Learning (Parte 24): Previsão de Séries Temporais no Forex Usando Modelos de IA Clássicos
Nos mercados de forex, é muito desafiador prever a tendência futura sem ter uma ideia do passado. Poucos modelos de machine learning são capazes de fazer previsões futuras considerando valores passados. Neste artigo, vamos discutir como podemos usar modelos clássicos (não específicos para séries temporais) de Inteligência Artificial para superar o mercado.
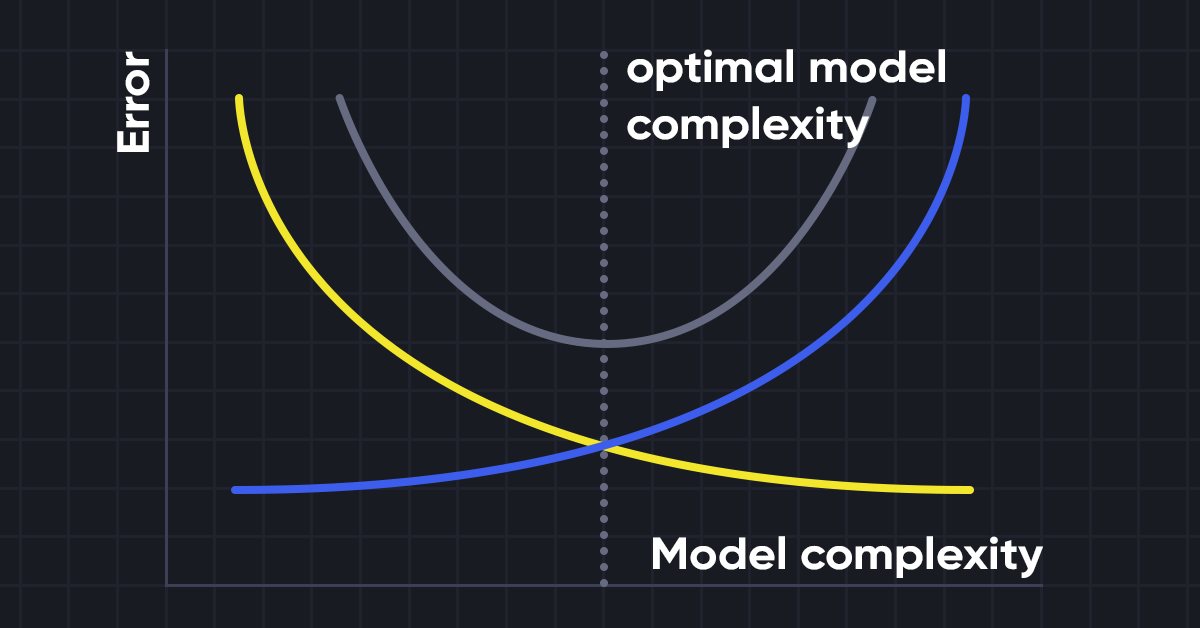
Ciência de dados e Aprendizado de Máquina (parte 10): Regressão de Ridge
A regressão de Ridge é uma técnica simples para reduzir a complexidade do modelo e evitar o ajuste excessivo que pode resultar da regressão linear simples

Desenvolvendo um sistema de Replay - Simulação de mercado (Parte 15): Nascimento do SIMULADOR (V) - RANDOM WALK
Neste artigo iremos finalizar a fase, onde estamos desenvolvendo o simulador para o nosso sistema. O principal proposito aqui será ajustar o algoritmo visto no artigo anterior. Tal algoritmo tem como finalidade criar o movimento de RANDOM WALK. Por conta disto, o entendimento do conteúdo dos artigos anteriores, é primordial para acompanhar o que será explicado aqui. Se você não acompanhou o desenvolvimento do simulador, aconselho você a ver esta sequência desde o inicio. Caso contrário, poderá ficar perdido no que será explicado aqui.

Desenvolvendo um sistema de Replay - Simulação de mercado (Parte 14): Nascimento do SIMULADOR (IV)
Neste artigo continuaremos a fase de desenvolvimento do simulador. Mas agora, vamos ver como criar de fato um movimento do tipo RANDOM WALK. Este tipo de movimentação é muito interessante, pois tudo envolvido no mercado de capitais tem como base este tipo de movimentação. Além do mais você vai começar a entender alguns conceitos importantes para quem faz estáticas de mercado.

Desenvolvendo um sistema de Replay (Parte 67): Refinando o Indicador de controle
Neste artigo mostrarei o que um pouco de refinamento no código é capaz de fazer. Tal refinamento tem como objetivo tornar mais simples o nosso código. Fazer um maior uso das chamadas de biblioteca do MQL5. Mas principalmente fazer com que o nosso código se torne bem mais estável, seguro e fácil de ser usado por outras classe, ou outros códigos que por ventura construiremos. O conteúdo exposto aqui, visa e tem como objetivo, pura e simplesmente a didática. De modo algum deve ser encarado como sendo, uma aplicação cuja finalidade não venha a ser o aprendizado e estudo dos conceitos mostrados.

Ciência de Dados e ML (Parte 27): Redes Neurais Convolucionais (CNNs) em Bots de Trading no MetaTrader 5 — Vale a Pena?
As Redes Neurais Convolucionais (CNNs) são renomadas por sua capacidade de detectar padrões em imagens e vídeos, com aplicações em diversos campos. Neste artigo, exploramos o potencial das CNNs para identificar padrões valiosos nos mercados financeiros e gerar sinais de trading eficazes para bots de negociação no MetaTrader 5. Vamos descobrir como essa técnica de aprendizado profundo pode ser aproveitada para decisões de trading mais inteligentes.

Redes neurais de maneira fácil (Parte 14): Agrupamento de dados
Devo confessar que já se passou mais de um ano desde que o último artigo foi publicado. Em um período tão longo como esse, é possível reconsiderar muitas coisas, desenvolver novas abordagens. E neste novo artigo, gostaria de me afastar um pouco do método de aprendizado supervisionado usado anteriormente, e sugerir um pouco de mergulho nos algoritmos de aprendizado não supervisionado. E, em particular, desejaria analisar um dos algoritmos de agrupamento, o k-médias (k-means).

Algoritmos de otimização populacionais: salto de sapo embaralhado
O artigo apresenta uma descrição detalhada do algoritmo salto de sapo embaralhado (Shuffled Frog Leaping Algorithm, SFL) e suas capacidades na solução de problemas de otimização. O algoritmo SFL é inspirado no comportamento dos sapos em seu ambiente natural e oferece uma nova abordagem para a otimização de funções. O algoritmo SFL é uma ferramenta eficaz e flexível, capaz de lidar com diversos tipos de dados e alcançar soluções ótimas.

Desenvolvendo um sistema de Replay (Parte 65): Dando play no serviço (VI)
Aqui neste artigo mostrarei como faremos para conseguir implementar o avanço rápido, assim como também resolveremos o problema do indicador de mouse, quando este está sendo usando junto com a aplicação de replay / simulação. O conteúdo exposto aqui, visa e tem como objetivo, pura e simplesmente a didática. De modo algum deve ser encarado como sendo, uma aplicação cuja finalidade não venha a ser o aprendizado e estudo dos conceitos mostrados.

Desenvolvimento de robô em Python e MQL5 (Parte 2): Escolha do modelo, criação e treinamento, testador customizado Python
Continuamos o ciclo de artigos sobre a criação de um robô de trading em Python e MQL5. Hoje, vamos resolver a tarefa de escolher e treinar o modelo, testá-lo, implementar a validação cruzada, busca em grade, além de abordar o ensemble de modelos.

Algoritmos populacionais de otimização: Evolução diferencial (Differential Evolution, DE)
Neste artigo, falaremos sobre o algoritmo que apresenta os resultados mais contraditórios de todos os examinados anteriormente, o de evolução diferencial (DE).

Algoritmos de otimização populacionais: Enxame de partículas (PSO)
Neste artigo vamos analisar o popular algoritmo de otimização por enxame de partículas (PSO). Anteriormente, discutimos características importantes de algoritmos de otimização, como convergência, velocidade de convergência, estabilidade, escalabilidade e desenvolvemos uma bancada de testes. Também analisamos um algoritmo simples baseado em geradores de números aleatórios (GNA).

Modelos ocultos de Markov em sistemas de trading com aprendizado de máquina
Os modelos ocultos de Markov (HMM) representam uma classe poderosa de modelos probabilísticos, destinados à análise de dados sequenciais, nos quais os eventos observáveis dependem de alguma sequência de estados não observáveis (ocultos), que formam um processo de Markov. As principais suposições dos HMM incluem a propriedade de Markov para os estados ocultos, o que significa que a probabilidade de transição para o próximo estado depende apenas do estado atual, e a independência das observações, desde que o estado oculto atual seja conhecido.
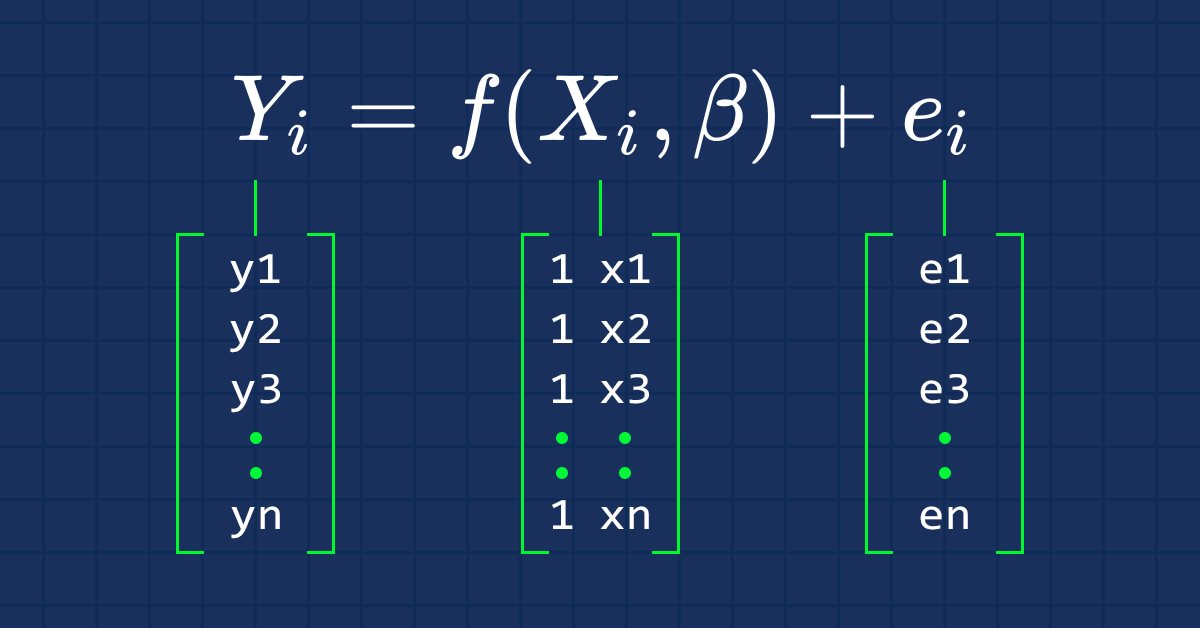
Ciência de Dados e Aprendizado de Máquina (Parte 03): Regressões Matriciais
Desta vez nossos modelos estão sendo feitos por matrizes, o que permite flexibilidade ao mesmo tempo que nos permite fazer modelos poderosos que podem manipular não apenas cinco variáveis independentes, mas também muitas variáveis, desde que permaneçamos dentro dos limites de cálculos de um computador, este artigo será uma leitura interessante, isso é certo.

Matrix Utils, estendendo as matrizes e a funcionalidade da biblioteca padrão de vetores
As matrizes servem como base para os algoritmos de aprendizado de máquina e computação em geral devido à sua capacidade de lidar efetivamente com grandes operações matemáticas. A biblioteca padrão tem tudo o que é necessário, mas vamos ver como podemos estendê-la introduzindo várias funções no arquivo utils, ainda não disponível na biblioteca


Desenvolvendo um sistema de Replay - Simulação de mercado (Parte 10): Usando apenas dados reais na replay
Aqui vamos ver como você pode utilizar dados mais fieis ( tickets negociados ) no sistema de replay, sem necessariamente ter que se preocupar se eles estão ou não ajustados.

Desenvolvendo um sistema de Replay - Simulação de mercado (Parte 09): Eventos Customizados
Aqui vamos ver como disparar eventos customizados e melhorar a questão sobre como o indicador informa o status do serviço de replay/simulação.

Algoritmos de otimização populacionais: Algoritmo do morcego
Hoje estudaremos o algoritmo do morcego (Bat algorithm, BA), que possui convergência incrível em funções suaves.

Desenvolvendo um sistema de Replay — Simulação de mercado (Parte 05): Adicionando Previas
Conseguimos desenvolver, uma forma de fazer com que o replay de mercado, fosse executado dentro de um tempo bastante realista e aceitável. Vamos continuar nosso projeto. Agora iremos adicionar dados de forma a ter um comportamento melhor do replay.

Redes neurais de maneira fácil (Parte 27): Aprendizado Q profundo (DQN)
Continuamos nosso estudo sobre aprendizado por reforço. E, neste artigo, vamos nos familiarizar com o método de aprendizado Q profundo. Com esse método, a equipe do DeepMind criou um modelo que pode superar um humano ao jogar jogos do Atari. Acho que será útil avaliar as possibilidades de tal tecnologia para resolver problemas de negociação.

Desenvolvendo um sistema de Replay (Parte 48): Entendendo e compreendendo alguns conceitos
Que tal aprender algo novo. Neste artigo você irá aprender como transformar Scripts e Serviços e qual a utilidade em se fazer isto.

Modelos de regressão da biblioteca Scikit-learn e sua exportação para ONNX
Neste artigo, exploraremos a aplicação de modelos de regressão do pacote Scikit-learn, tentaremos convertê-los para o formato ONNX e usaremos os modelos resultantes em programas MQL5. Além disso, compararemos a precisão dos modelos originais com suas versões ONNX para ambas as precisões float e double. Além disso, examinaremos a representação ONNX dos modelos de regressão, com o objetivo de fornecer uma melhor compreensão de sua estrutura interna e princípios operacionais.

Desenvolvendo um sistema de Replay - Simulação de mercado (Parte 16): Um novo sistema de classes
Precisamos nos organizar melhor. O código está crescendo e se não o organizarmos agora, será impossível fazer isto depois. Então agora vamos dividir para conquistar. O fato de que o MQL5, nos permite usar classes, nos ajudará nesta tarefa. Mas para fazer isto é preciso que você tenha algum conhecimento sobre algumas coisas envolvidas nas classes. E talvez a que mais deixe, aspirantes e iniciantes perdidos seja a herança. Então neste artigo, irei de forma prática e simples como fazer uso de tais mecanismos.

Metamodelos em aprendizado de máquina e negociação: Tempo original das ordens de negociação
Metamodelos em aprendizado de máquina: Criação automática de sistemas de negociação com quase nenhum envolvimento humano, o próprio modelo decide como operar e quando operar.
Outras classes na biblioteca DoEasy (Parte 70): extensão da funcionalidade e atualização automática da coleção de objetos-gráficos
Neste artigo, vamos expandir a funcionalidade dos objetos-gráficos, criaremos a navegação em gráficos, geraremos capturas de tela, salvaremos e aplicaremos modelos aos gráficos. Faremos também uma atualização automática da coleção de objetos-gráficos, suas janelas e indicadores.

Desenvolvendo um sistema de Replay (Parte 38): Pavimentando o Terreno (II)
Muita gente que se diz programador de MQL5, não tem as bases que estarei apresentando aqui, neste artigo. Muitos consideram o MQL5 algo limitado, mas tudo isto se deve a falta de conhecimento. Então, não fique com vergonha por não saber. Mas tenha vergonha de não perguntar. Mas o simples fato, de forçar, e obrigar o MetaTrader 5 a não permitir que um indicador seja duplicado. Não nos dá de maneira alguma meios de efetivar uma comunicação bilateral entre o indicador e o EA. Ainda estamos um pouco longe disto. Mas o simples fato de que o indicador não estará duplicado no gráfico, já nos garante uma certa tranquilidade.

Desenvolvendo um fator de qualidade para os EAs
Nesse artigo vamos explicar como desenvolver um fator de qualidade para ser retornado pelo seu EA no testador de estratégia. Iremos mostrar duas formas de cálculo conhecidas (Van Tharp e Sunny Harris).

Desenvolvendo um sistema de Replay (Parte 63): Dando play no serviço (IV)
Neste arquivo vamos finalmente resolver os problemas de simulação dos ticks, em uma barra de um minuto, de forma que eles possam conviver junto com ticks reais. Isto para evitar que venhamos a ter problemas depois. O conteúdo exposto aqui, visa e tem como objetivo, pura e simplesmente a didática. De modo algum deve ser encarado como sendo, uma aplicação cuja finalidade não venha a ser o aprendizado e estudo dos conceitos mostrados.
Redes neurais de maneira fácil (Parte 34): Função quantil totalmente parametrizada
Continuamos a estudar os algoritmos de aprendizado Q distribuído. Em artigos anteriores, já discutimos os algoritmos de aprendizado Q distribuído e de quantil. No primeiro, aprendemos as probabilidades de determinados intervalos de valores. No segundo, aprendemos intervalos com uma probabilidade específica. Em ambos os algoritmos, utilizamos o conhecimento prévio de uma distribuição e ensinamos a outra. Neste artigo, vamos examinar um algoritmo que permite que o modelo aprenda ambas as distribuições.

Algoritmos de otimização populacionais: Busca por cardume de peixes (FSS - Fish School Search)
O FSS (Fish School Search) é um algoritmo avançado de otimização inspirado no comportamento dos peixes que nadam em cardumes. Aproximadamente 80% desses peixes nadam em comunidades organizadas de parentes, o que tem sido comprovado como uma estratégia importante para melhorar a eficiência de procura por alimento e proteção contra predadores.

Regressões Espúrias em Python
Regressões espúrias ocorrem quando duas séries temporais exibem um alto grau de correlação puramente por acaso, levando a resultados enganosos na análise de regressão. Em tais casos, embora as variáveis possam parecer relacionadas, a correlação é coincidencial e o modelo pode ser pouco confiável.