
Desenvolvimento de robô em Python e MQL5 (Parte 2): Escolha do modelo, criação e treinamento, testador customizado Python

Resumo breve do artigo anterior
Então, no artigo anterior, falamos um pouco sobre aprendizado de máquina, fizemos a ampliação dos dados, criamos características para o futuro modelo e selecionamos as melhores delas. Agora é hora de avançar e criar um modelo de aprendizado de máquina funcional, que aprenderá com nossas características e realizará negociações (esperamos, com sucesso). Para avaliar o modelo, escreveremos um testador customizado em Python, que nos ajudará a avaliar a eficiência do modelo e a beleza dos gráficos de teste. Para gráficos de teste mais elegantes e maior robustez do modelo, também desenvolveremos algumas técnicas clássicas de aprendizado de máquina.
Nosso objetivo final é criar um modelo funcional e o mais lucrativo possível para prever preços e realizar negociações. Todo o código será em Python, com inclusões da biblioteca MQL5.
Versão do Python e módulos necessários
Foi utilizada a versão 3.10.10 do Python. O código anexado ao artigo contém várias funções para o pré-processamento de dados, extração de características e treinamento do modelo de aprendizado de máquina. Especificamente, ele inclui:
- Função para clusterização de características utilizando Gaussian Mixture Model (GMM) da biblioteca sklearn
- Função para seleção de características utilizando Recursive Feature Elimination with Cross-Validation (RFECV) da biblioteca sklearn
- Função para treinar o classificador XGBoost
Para executar esse código, é necessário instalar os seguintes módulos Python:
- pandas
- numpy
- sklearn
- xgboost
- matplotlib
- seaborn
- MetaTrader5
- tqdm
Você pode instalá-los usando o pip, a ferramenta de instalação de pacotes do Python. Aqui está um exemplo de comando para instalar todos os módulos necessários:
pip install pandas numpy sklearn xgboost matplotlib seaborn tqdm MetaTrader5
Vamos lá!
Classificação ou regressão?
Uma das questões eternas na previsão de dados. A classificação é mais adequada para tarefas binárias, quando é necessário uma resposta clara de "sim-não". Há também a classificação multiclasse, que abordaremos em futuros artigos do ciclo. Este tema é interessante e pode fortalecer significativamente os modelos.
A regressão é adequada para prever um valor específico de uma série contínua no futuro, incluindo preços. Por um lado, isso pode ser mais conveniente, mas por outro, a rotulagem de dados para regressão, assim como os labels, é um desafio intelectual, já que há pouco o que inventar além de simplesmente pegar o preço futuro do ativo.
Pessoalmente, prefiro a classificação devido à facilidade de trabalhar com a rotulagem de dados. Muita coisa pode ser enquadrada nas condições "sim-não", e em classificações multiclasse, é possível até incluir sistemas de trading manuais complexos, como o Smart Money. No entanto, o código de rotulagem de dados que você já viu no artigo anterior claramente se adequa à classificação binária. Portanto, este é o esquema de modelo que adotaremos.
Agora, só falta decidir o modelo a ser usado.
Escolha do modelo de classificação
É necessário escolher um modelo de classificação adequado para os nossos dados com as características selecionadas. A escolha depende do número de características, tipos de dados e número de classes.
Modelos populares como exemplo: regressão logística para classificação binária, floresta aleatória para grandes dimensões e não linearidades, redes neurais para tarefas complexas. A variedade é grande, e é fácil se perder diante de tantas opções. Após testar várias abordagens, cheguei à conclusão de que, nas condições atuais, o mais eficiente é o boosting e os modelos baseados nele.
Decidi utilizar o modelo avançado XGBoost – boosting sobre árvores de decisão com regularização, paralelismo e uma ampla gama de configurações. O XGBoost frequentemente vence em competições de data science devido à sua alta precisão. Esse foi o principal critério para a escolha do modelo para este trabalho.
Criação do código do modelo de classificação
O código utiliza o modelo avançado XGBoost – gradient boosting sobre árvores de decisão. A particularidade do XGBoost é a aplicação de segundas derivadas para otimização, o que aumenta a eficiência e a precisão em comparação com outros modelos.
A função train_xgboost_classifier recebe os dados e o número de rodadas de boosting. Ela divide os dados em características (X) e rótulos (y), cria o modelo XGBClassifier configurado com hiperparâmetros e o treina com o método fit().
Os dados são divididos em treino/teste, e o modelo é treinado no conjunto de treino por meio da função. O modelo é testado no restante dos dados, e a acurácia das previsões é calculada.
As principais vantagens do XGBoost são a combinação de vários modelos em um de alta precisão, com o uso de gradient boosting, e a otimização pelas segundas derivadas para eficiência.
Para utilizá-lo, você também precisará instalar a biblioteca OpenMP runtime. Para instalar a biblioteca XGBoost, é necessário instalar o OpenMP runtime. No Windows, será necessário baixar o Microsoft Visual C++ Redistributable correspondente à sua versão do Python.
Agora vamos ao código. No início do código, importamos a biblioteca xgboost da seguinte forma:
import xgboost as xgb O restante do código:
import xgboost as xgb def train_xgboost_classifier(data, num_boost_rounds=500): # Check if data is not empty if data.empty: raise ValueError("Data should not be empty") # Check if all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Data is missing required columns: {required_columns}") # Remove the 'label' column as it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check if all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create an XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', max_depth=10, learning_rate=0.3, n_estimators=num_boost_rounds, random_state=1) # Train the model on the data clf.fit(X, y) # Return the trained model return clf labeled_data_engineered = feature_engineering(labeled_data_clustered, n_features_to_select=20) # Get all data raw_data = labeled_data_engineered # Test the model on all data train_data = raw_data[raw_data.index <= FORWARD] # Test the model on all data test_data = raw_data[raw_data.index >= FORWARD] # Train the XGBoost model on the filtered data xgb_clf = train_xgboost_classifier(train_data, num_boost_rounds=100) # Test the model on all data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] predicted_labels = xgb_clf.predict(X_test) # Calculate prediction accuracy accuracy = (predicted_labels == y_test).mean() print(f"Prediction accuracy: {accuracy:.2f}")
Treinamos o modelo e analisamos a acurácia, que é de 52%.
Portanto, nossa acurácia de classificação atual é de 53% para os rótulos lucrativos. Vale notar que estamos prevendo situações em que o preço variou mais do que o valor do take (200 pips), e não atingiu o stop (100 pips). Na prática, obteremos um profit factor em torno de três, o que é suficiente para negociações lucrativas. O próximo passo será escrever um testador customizado em Python para analisar a lucratividade dos modelos, especificamente em dólares, e não em pontos. Precisamos entender se o modelo gera lucro considerando o markup, ou se está apenas queimando o capital.
Escrita da função do testador customizado em Python
def test_model(model, X_test, y_test, markup, initial_balance=10000.0, point_cost=0.00001): balance = initial_balance trades = 0 profits = [] # Test the model on the test data predicted_labels = model.predict(X_test) for i in range(len(predicted_labels) - 48): if predicted_labels[i] == 1: # Open a long position entry_price = X_test.iloc[i]['close'] exit_price = X_test.iloc[i+48]['close'] if exit_price > entry_price + markup: # Close the long position with profit profit = (exit_price - entry_price - markup) / point_cost balance += profit trades += 1 profits.append(profit) else: # Close the long position with loss loss = (entry_price - exit_price + markup) / point_cost balance -= loss trades += 1 profits.append(-loss) elif predicted_labels[i] == 0: # Open a short position entry_price = X_test.iloc[i]['close'] exit_price = X_test.iloc[i+48]['close'] if exit_price < entry_price - markup: # Close the short position with profit profit = (entry_price - exit_price - markup) / point_cost balance += profit trades += 1 profits.append(profit) else: # Close the short position with loss loss = (exit_price - entry_price + markup) / point_cost balance -= loss trades += 1 profits.append(-loss) # Calculate the cumulative profit or loss total_profit = balance - initial_balance # Plot the balance change over the number of trades plt.plot(range(trades), [balance + sum(profits[:i]) for i in range(trades)]) plt.title('Balance Change') plt.xlabel('Trades') plt.ylabel('Balance ($)') plt.xticks(range(0, len(X_test), int(len(X_test)/10)), X_test.index[::int(len(X_test)/10)].strftime('%Y-%m-%d')) # Add dates to the x-axis plt.axvline(FORWARD, color='r', linestyle='--') # Add a vertical line for the FORWARD date plt.show() # Print the results print(f"Cumulative profit or loss: {total_profit:.2f} $") print(f"Number of trades: {trades}") # Get test data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] # Test the model with markup and target labels initial_balance = 10000.0 markup = 0.00001 test_model(xgb_clf, X_test, y_test, markup, initial_balance)
O código cria uma função para testar o modelo de aprendizado de máquina nos dados de teste e analisar sua lucratividade levando em conta o markup (aqui devem ser incluídas as perdas com spread e diferentes tipos de comissões). Os swaps não são considerados, pois são dinâmicos e dependem das taxas de juros. Eles podem ser considerados simplesmente adicionando alguns pips ao markup.
A função recebe o modelo, os dados de teste, o markup e o saldo inicial. Usando as previsões do modelo, a negociação é simulada: long com 1, short com 0. Se o lucro superar o markup, a posição é fechada e o lucro é adicionado ao saldo.
É feito o acompanhamento das transações e do lucro/prejuízo de cada uma. Um gráfico do saldo é gerado. O lucro/prejuízo acumulado é calculado.
No final, são obtidos os dados de teste, e as colunas desnecessárias são removidas. O modelo treinado xgb_clf é testado com o markup definido e o saldo inicial. Vamos testá-lo!
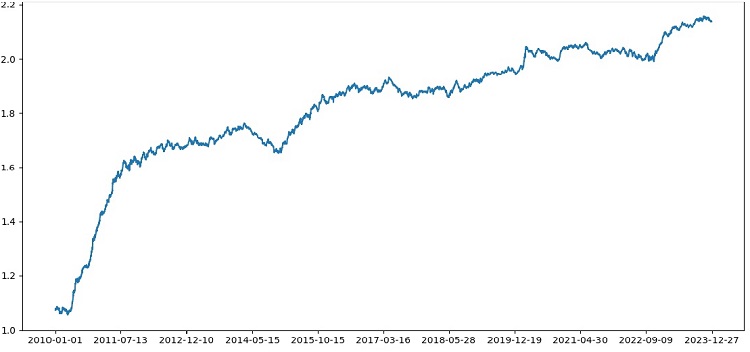
Assim, o testador funciona com sucesso e vemos um gráfico de lucro bastante bonito. Este é o testador customizado para análise da lucratividade do modelo de aprendizado de máquina, levando em consideração o markup e os rótulos.
Implementação de validação cruzada no modelo
Para obter uma avaliação mais confiável da qualidade do modelo de aprendizado de máquina, é necessário usar a validação cruzada. A validação cruzada permite avaliar o modelo em vários subconjuntos de dados, o que ajuda a evitar o overfitting e obter uma avaliação mais objetiva.
No nosso caso, usaremos validação cruzada de 5 dobras para avaliar o modelo XGBoost. Para isso, utilizaremos a função cross_val_score da biblioteca sklearn.
Alteraremos o código da função train_xgboost_classifier da seguinte maneira:
def train_xgboost_classifier(data, num_boost_rounds=500): # Check that data is not empty if data.empty: raise ValueError("Data should not be empty") # Check that all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Data is missing required columns: {required_columns}") # Drop the 'label' column since it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check that all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', max_depth=10, learning_rate=0.3, n_estimators=num_boost_rounds, random_state=1) # Train the model on the data using cross-validation scores = cross_val_score(clf, X, y, cv=5) # Calculate the mean accuracy of the predictions accuracy = scores.mean() print(f"Mean prediction accuracy on cross-validation: {accuracy:.2f}") # Train the model on the data without cross-validation clf.fit(X, y) # Return the trained model return clf labeled_data_engineered = feature_engineering(labeled_data_clustered, n_features_to_select=20) # Get all data raw_data = labeled_data_engineered # Train data train_data = raw_data[raw_data.index <= FORWARD] # Train the XGBoost model on the filtered data xgb_clf = train_xgboost_classifier(train_data, num_boost_rounds=100) # Test data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] predicted_labels = xgb_clf.predict(X_test) # Calculate the accuracy of the predictions accuracy = (predicted_labels == y_test).mean() print(f"Accuracy: {accuracy:.2f}")
Durante o treinamento do modelo, a função train_xgboost_classifier executará a validação cruzada de 5 dobras e exibirá a precisão média da previsão. O treinamento ainda será feito com os dados anteriores à data FORWARD.
A validação cruzada é usada apenas para avaliação do modelo, mas não para seu treinamento. O treinamento será realizado com todos os dados até a data FORWARD, sem validação cruzada.
A validação cruzada permite obter uma avaliação mais confiável e objetiva da qualidade do modelo, o que teoricamente aumentará sua robustez em novos dados de preço. Ou não? Vamos verificar e ver o funcionamento do testador.
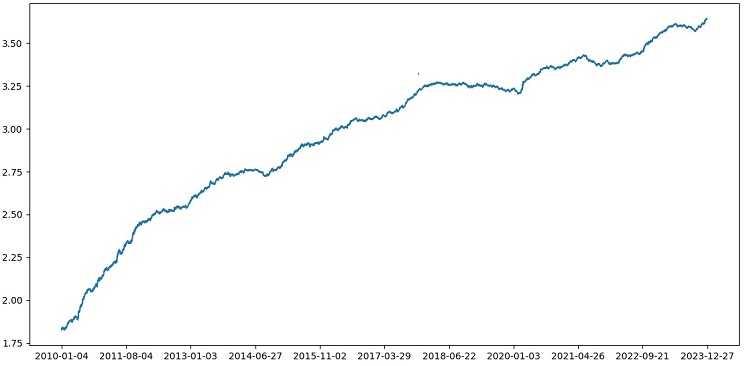
Testando o XGBoost com validação cruzada nos dados de 1990 a 2024, obtivemos uma precisão de 56% no teste após 2010. O modelo demonstrou uma boa robustez em novos dados logo na primeira tentativa. A precisão também aumentou de forma satisfatória, o que é animador.
Otimização de hiperparâmetros do modelo em grade
A otimização de hiperparâmetros é uma etapa importante no desenvolvimento de um modelo de aprendizado de máquina para maximizar sua precisão e desempenho. Ela é semelhante à otimização de EAs no MQL5, só que, em vez de um EA, temos um modelo de aprendizado de máquina, e com a busca em grade você encontra os parâmetros que funcionam melhor.
Vamos abordar a otimização de hiperparâmetros do XGBoost usando a grade com o Scikit-learn.
Utilizaremos o GridSearchCV do Scikit-learn para a validação cruzada do modelo em todos os conjuntos de hiperparâmetros da grade. Será escolhido o conjunto com a maior precisão média na validação cruzada.
O código para otimização:
from sklearn.model_selection import GridSearchCV
# Define the grid of hyperparameters
param_grid = {
'max_depth': [3, 5, 7, 10],
'learning_rate': [0.1, 0.3, 0.5],
'n_estimators': [100, 500, 1000]
}
# Create XGBoost model
clf = xgb.XGBClassifier(objective='binary:logistic', random_state=1)
# Perform grid search to find the best hyperparameters
grid_search = GridSearchCV(clf, param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)
# Print the best hyperparameters
print("Best hyperparameters:", grid_search.best_params_)
# Print the mean accuracy of the predictions on cross-validation for the best hyperparameters
print("Mean prediction accuracy on cross-validation:", grid_search.best_score_)
Aqui, definimos a grade de hiperparâmetros param_grid, criamos o modelo XGBoost clf e realizamos a busca pelos hiperparâmetros ideais na grade usando o método GridSearchCV. Em seguida, exibimos os melhores hiperparâmetros grid_search.best_params_ e a precisão média da previsão na validação cruzada grid_search.best_score_.
Vale ressaltar que, neste código, usamos validação cruzada para otimização dos hiperparâmetros. Isso nos permite obter uma avaliação mais confiável e objetiva da qualidade do modelo.
Após executar esse código, obteremos os melhores hiperparâmetros para o nosso modelo XGBoost e a precisão média da previsão na validação cruzada. Em seguida, podemos treinar o modelo com todos os dados usando os melhores hiperparâmetros e testá-lo em novos dados.
Portanto, a otimização dos hiperparâmetros do modelo via grade é uma tarefa crucial ao criar modelos de aprendizado de máquina. Usando o método GridSearchCV da biblioteca Scikit-learn, podemos automatizar esse processo e encontrar os melhores hiperparâmetros para um modelo e conjunto de dados específicos.
def train_xgboost_classifier(data, num_boost_rounds=1000): # Check that data is not empty if data.empty: raise ValueError("Data should not be empty") # Check that all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Data is missing required columns: {required_columns}") # Drop the 'label' column since it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check that all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', random_state=1) # Define hyperparameters for grid search param_grid = { 'max_depth': [3, 5, 7, 10], 'learning_rate': [0.05, 0.1, 0.2, 0.3, 0.5], 'n_estimators': [50, 100, 600, 1200, 2000] } # Train the model on the data using cross-validation and grid search grid_search = GridSearchCV(clf, param_grid, cv=5, scoring='accuracy') grid_search.fit(X, y) # Calculate the mean accuracy of the predictions accuracy = grid_search.best_score_ print(f"Mean prediction accuracy on cross-validation: {accuracy:.2f}") # Return the trained model with the best hyperparameters return grid_search.best_estimator_
Ensemble de modelos
Chegou a hora de deixar nosso modelo ainda melhor! O ensemble de modelos é uma abordagem poderosa no aprendizado de máquina, que combina vários modelos para aumentar a precisão das previsões. Métodos populares: bagging (criação de modelos em diferentes subconjuntos de dados) e boosting (treinamento sequencial de modelos para corrigir os erros dos anteriores).
Em nossa tarefa, utilizamos o ensemble XGBoost com bagging e boosting. Criamos vários XGBoosts, treinados em diferentes subconjuntos, e combinamos suas previsões. Otimizamos os hiperparâmetros de cada modelo com GridSearchCV.
Vantagens do ensemble: maior precisão, redução da variância, melhoria da qualidade geral do modelo.
A função final de treinamento do modelo usa validação cruzada, ensemble e otimização de hiperparâmetros de bagging via grade.
def train_xgboost_classifier(data, num_boost_rounds=1000): # Check that data is not empty if data.empty: raise ValueError("Data should not be empty") # Check that all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Missing required columns in data: {required_columns}") # Remove the 'label' column as it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check that all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', random_state=1) # Define hyperparameters for grid search param_grid = { 'max_depth': [3, 7, 12], 'learning_rate': [0.1, 0.3, 0.5], 'n_estimators': [100, 600, 1200] } # Train the model on the data using cross-validation and hyperparameter tuning grid_search = GridSearchCV(clf, param_grid, cv=5, scoring='accuracy') grid_search.fit(X, y) # Calculate the mean accuracy of the predictions accuracy = grid_search.best_score_ print(f"Mean accuracy on cross-validation: {accuracy:.2f}") # Return the trained model return grid_search.best_estimator_ labeled_data_engineered = feature_engineering(labeled_data_clustered, n_features_to_select=20) # Get all data raw_data = labeled_data_engineered # Train data train_data = raw_data[raw_data.index <= FORWARD] # Test data test_data = raw_data[raw_data.index <= EXAMWARD] # Train the XGBoost model on the filtered data xgb_clf = train_xgboost_classifier(train_data, num_boost_rounds=100) # Test the model on all data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] predicted_labels = xgb_clf.predict(X_test) # Calculate the accuracy of the predictions accuracy = (predicted_labels == y_test).mean() print(f"Prediction accuracy: {accuracy:.2f}")
Implementamos o ensemble de modelos com bagging, testamos e obtemos o seguinte resultado no nosso teste:
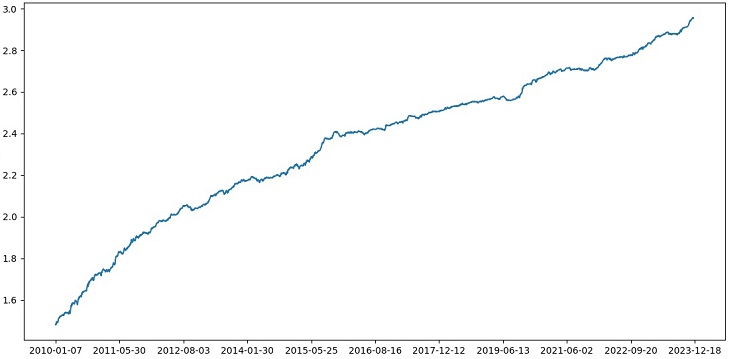
A precisão da classificação das operações com risco-retorno de 1:8 subiu para 73%. Ou seja, o ensemble e a busca em grade nos deram um aumento significativo na precisão da classificação, em comparação com a versão anterior do código. Considero isso um excelente resultado, e pelos gráficos anteriores do desempenho do modelo no conjunto forward, é evidente como ele se fortaleceu ao longo da evolução do código.
Implementação do conjunto de teste e verificação da robustez do modelo
Agora, utilizo para o teste dados após a data EXAMWARD. Isso me permite verificar o desempenho do modelo em dados totalmente novos, que não foram usados no treinamento e no teste do modelo. Assim, posso avaliar objetivamente como o modelo se comportará em condições reais.
Testar em um conjunto de teste é uma etapa crucial para validar um modelo de aprendizado de máquina. Isso garante que o modelo funciona bem em novos dados e oferece uma visão sobre sua eficácia no mundo real. É necessário definir corretamente o tamanho da amostra e garantir sua representatividade.
No meu caso, utilizo dados após EXAMWARD para testar o modelo em dados completamente desconhecidos, fora dos conjuntos de treino e teste. Isso me dá uma avaliação objetiva da eficácia e prontidão do modelo para aplicação real.
Treinei o modelo com dados de 2000-2010, testei de 2010-2019, e o conjunto de teste foi após 2019. O teste imita negociações em um futuro desconhecido.
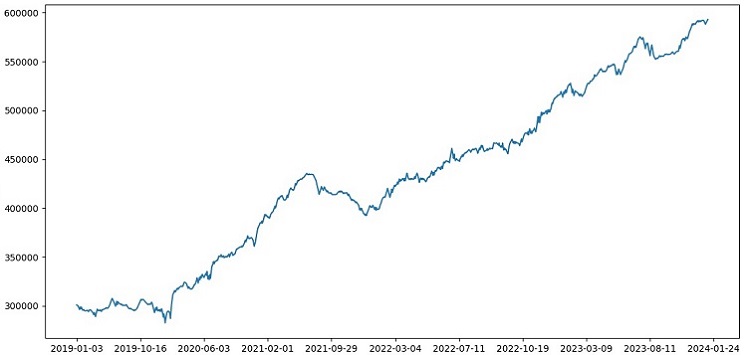
No geral, tudo parece bem. A precisão no teste caiu para 60%, mas o principal é que o modelo é lucrativo e bastante robusto, sem grandes quedas. É animador ver que o modelo está aprendendo o conceito de risco/retorno – ele prevê situações com baixo risco e grande potencial de lucro (utilizamos uma razão risco-retorno de 1:8).
Conclusão
Assim, concluímos o segundo artigo do ciclo sobre o desenvolvimento de um robô de trading em Python. Até o momento, conseguimos resolver as tarefas de manipulação de dados, criação de características, seleção e até geração de novas características, além da escolha e treinamento do modelo. Também desenvolvemos um testador customizado, que testa o modelo, e, aparentemente, tudo está funcionando muito bem. A propósito, experimentei outras características, incluindo as mais simples, ao tentar simplificar os dados. Não consegui obter bons resultados. Modelos com essas características acabaram falhando completamente em nosso próprio testador. Isso confirma mais uma vez que as características e os dados são tão importantes quanto a sofisticação do modelo. Pode-se ter um modelo excelente e aplicar diversos tipos de melhorias e métodos, mas se as características forem inúteis, o modelo irá, sem dúvida, esgotar seu capital em dados desconhecidos. Com boas características, até mesmo modelos menos sofisticados podem produzir resultados estáveis.
Planos para o futuro
No futuro, planejo criar uma versão customizada de negociação online no terminal MetaTrader 5 para operar diretamente via Python. Isso é conveniente. Lembro que o primeiro sinal que me levou a criar uma versão para Python foi a dificuldade em transferir as características para o MQL5. Com as características, sua seleção, rotulagem dos dados e ampliação dos dados, é muito mais rápido e prático trabalhar em Python.
Acredito que a biblioteca MQL5 para Python é subestimada, e claramente poucos a utilizam. No entanto, ela é muito poderosa, e com sua ajuda é possível criar modelos verdadeiramente impressionantes, que agradam tanto aos olhos quanto ao bolso!
Também gostaria de implementar uma versão que aprenda com dados históricos do livro de ofertas, em uma bolsa real, como a de Chicago ou a de Moscou. Esse é outro caminho promissor.
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/14910
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Eugene, a partir de seus artigos, comecei a estudar o ML em relação à negociação, muito obrigado por isso.
Você poderia explicar os seguintes pontos.
Depois que a função label_data processa os dados, seu volume é significativamente reduzido (obtemos um conjunto aleatório de barras que satisfazem as condições da função). Em seguida, os dados passam por várias funções e os dividimos em amostras de treinamento e teste. O modelo é treinado na amostra de treinamento. Depois disso, as colunas ['labels'] são removidas da amostra de teste e tentamos prever seus valores para estimar o modelo. Não há substituição de conceitos nos dados de teste? Afinal, para os testes, usamos dados que passaram pela função label_data (ou seja, um conjunto de barras não sequenciais selecionadas antecipadamente por uma função que leva em conta dados futuros). E então, no testador, há o parâmetro 10, que, pelo que entendi, deve ser responsável por quantas barras devem ser fechadas, mas como temos um conjunto não sequencial de barras, não está claro o que obtemos.
Surgem as seguintes perguntas: Onde estou errando? Por que nem todas as barras >= FORWARD são usadas para os testes? E se não usarmos todas as barras >= FORWARD, como podemos escolher as barras necessárias para a previsão sem conhecer o futuro?
Obrigado.
Ótimo trabalho, muito interessante, prático e direto ao ponto. É difícil ver um artigo tão bom com exemplos reais e não apenas teoria sem resultados. Muito obrigado por seu trabalho e compartilhamento, estarei acompanhando e aguardando ansiosamente essa série.
Muito obrigado! Sim, ainda há muitas implementações de ideias pela frente, incluindo a expansão desta com a tradução para ONNX)
Falhas críticas:
Recomendações para aprimoramento: