
Desenvolvendo um fator de qualidade para os EAs
Introdução
Neste artigo, vamos explicar como desenvolver um fator de qualidade para ser retornado pelo seu Expert Advisor (EA) no testador de estratégia. Como pode ser observado ser observado na Figura 1 abaixo, o valor de "OnTester result" foi retornado com o valor 1.0639375 como um exemplo de qualidade do sistema que foi executado. Ao longo deste artigo, você irá aprender duas possíveis abordagens de calcular a qualidade de sistemas e verá também como imprimir no log ambos os valores já que só podemos retornar um deles.
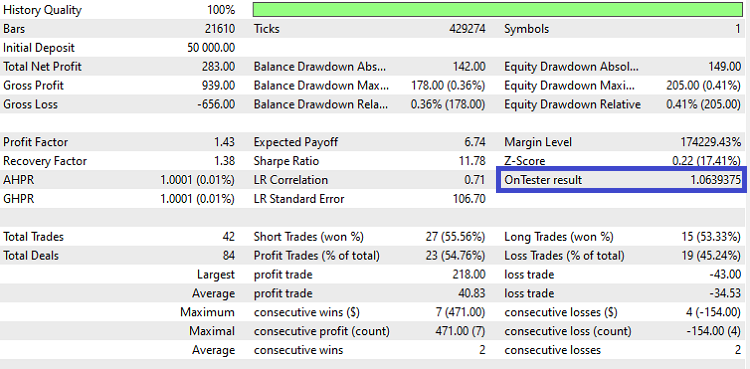
Figura 1: Mostrando o campo "OnTester result" em destaque.
Começando com um modelo de negócios ou construindo um EA
Antes de iniciarmos a tratar sobre fator de qualidade do sistema, é necessário estabelecer um sistema básico para ser usado nos testes. Optamos por um sistema simples: faremos um sorteio de um número aleátorio e, caso o número seja par, entraremos em uma posição comprada; Caso contrário, entraremos em uma posição vendida já que o número é impar.
Para realizar o sorteio, será utilizada a função MathRand(), que fornecerá um número entre 0 (zero) e 32767.Além disso, para tornar o sistema mais equilibrado, adicionaremos duas regras complementares. Assim, com essas 3 regras tentaremos garantir um sistema mais confiável. Veja:
- Quando não está posicionado, devemos sortear um número;
- Se o número for 0 (zero) ou 32767, não faremos nada;
- Se o número for par, compraremos quantidade do ativo correspondente ao lote mínimo;
- Se o número for ímpar, venderemos quantidade do ativo correspondente ao lote mínimo;
- Quando estivemos posicionado moveremos o stop a favor cada nova vela que exceda a anterior a favor do movimento;
- O stop utilizado se baseará no indicador ATR com 1 período sendo normalizado com uma EMA 8. Além disso, o resultado será colocado na extremidade mais afastada das duas velas utilizadas para análise;
- Caso o horário esteja fora do intervalo das 11h até as 16h não estaremos autorizados à abrir posição e às 16h30, a posição deverá ser obrigatoriamente encerrada.
O código utilizado para desenvolver essas regras pode ser visto a seguir.
//--- Indicador utilizado para stop ATR(1) com EMA(8)... int ind_atr = iATR(_Symbol, PERIOD_CURRENT, 1); int ind_ema = iMA(_Symbol, PERIOD_CURRENT, 8, 0, MODE_EMA, ind_atr); //--- Vamos definir uma variavel para dizer que teve um negocio... bool tem_tick = false; //--- Variavel auxiliar para abrir posicao. #include<Trade/Trade.mqh> #include<Trade/SymbolInfo.mqh> CTrade negocios; CSymbolInfo info; //--- Vamos definir no OnInit() o uso do timer a cada segundo //--- e vamos iniciar o CTrade. int OnInit() { //--- Colocamos o filling como deixar a ordem pendente ate ser //--- totalmente executada. negocios.SetTypeFilling(ORDER_FILLING_RETURN); //--- Vamos deixar o deviation setado, ele não é usado na B3 negocios.SetDeviationInPoints(5); //--- Vamos setar o simbolo do CSymbolInfo... info.Name(_Symbol); //--- Criamos o timer... EventSetTimer(1); //--- Vamos definir a base do numero randomico para termos testes iguais... MathSrand(0xDEAD); return(INIT_SUCCEEDED); } //--- Como definimos um timer, vamos destruí-lo no OnDeInit() void OnDeinit(const int reason) { EventKillTimer(); } //--- A função OnTick só informará que teve um negocio novo. void OnTick() { tem_tick = true; } //+------------------------------------------------------------------+ //| Função principal do EA | //+------------------------------------------------------------------+ void OnTimer() { MqlRates cotacao[]; bool fechar_tudo = false; bool negocios_autorizados = false; //--- Teve um negocio novo? if(tem_tick == false) return ; //--- Vamos copiar as informacoes das 3 velas mais recentes para checagem... if(CopyRates(_Symbol, PERIOD_CURRENT, 0, 3, cotacao) != 3) return ; //--- Teve uma vela nova desde a ultima verificacao? if(tem_vela_nova(cotacao[2]) == false) return ; //--- Recupera dados da janela de negocios e fechamento... negocios_autorizados = esta_na_janela_de_negocios(cotacao[2], fechar_tudo); //--- Se for pra fechar tudo, se houver posicao encerramos... if(fechar_tudo) { negocios.PositionClose(_Symbol); return ; } //--- Se nao for para fechar tudo, vamos mover o stop se houver posicao... if(arruma_stop_em_posicoes(cotacao)) return ; if (negocios_autorizados == false) // estamos fora da janela de negocios? return ; //--- Estamos na janela de negocio, tentaremos abrir posicao! int sorteio = MathRand(); //--- Regra de entrada 1.1 if(sorteio == 0 || sorteio == 32767) return ; if(MathMod(sorteio, 2) == 0) // Regra de sorteio 1.2 -- número par compra { negocios.Buy(info.LotsMin(), _Symbol); } else // Regra de sorteio 1.3 -- número ímpar venda { negocios.Sell(info.LotsMin(), _Symbol); } } //--- Verifica se tem uma vela nova... bool tem_vela_nova(const MqlRates &rate) { static datetime vela_anterior = 0; datetime vela_atual = rate.time; if(vela_atual != vela_anterior) // eh um horario diferente do salvo? { vela_anterior = vela_atual; return true; } return false; } //--- Verifica se o horario esta no periodo de negocios ou fechamento de posicao... bool esta_na_janela_de_negocios(const MqlRates &rate, bool &close_positions) { MqlDateTime mdt; bool ret = false; close_positions = true; if(TimeToStruct(rate.time, mdt)) { if(mdt.hour >= 11 && mdt.hour < 16) { ret = true; close_positions = false; } else { if(mdt.hour == 16) close_positions = (mdt.min >= 30); } } return ret; } //--- bool arruma_stop_em_posicoes(const MqlRates &cotacoes[]) { if(PositionsTotal()) // ha uma posicao? { double offset[1] = { 0 }; if(CopyBuffer(ind_ema, 0, 1, 1, offset) == 1 // EMA copiada com sucesso? && PositionSelect(_Symbol)) // selecione a posicao existente! { ENUM_POSITION_TYPE tipo = (ENUM_POSITION_TYPE) PositionGetInteger(POSITION_TYPE); double SL = PositionGetDouble(POSITION_SL); double TP = info.NormalizePrice(PositionGetDouble(POSITION_TP)); if(tipo == POSITION_TYPE_BUY) { if (cotacoes[1].high > cotacoes[0].high) { double sl = MathMin(cotacoes[0].low, cotacoes[1].low) - offset[0]; info.NormalizePrice(sl); if (sl > SL) { negocios.PositionModify(_Symbol, sl, TP); } } } else // tipo == POSITION_TYPE_SELL { if (cotacoes[1].low < cotacoes[0].low) { double sl = MathMax(cotacoes[0].high, cotacoes[1].high) + offset[0]; info.NormalizePrice(sl); if (SL == 0 || (sl > 0 && sl < SL)) { negocios.PositionModify(_Symbol, sl, TP); } } } } return true; } // nao havia nenhuma posicao return false; }
Vamos comentar brevemente o código acima, utilizaremos a média que foi calculada a partir do ATR para definir o tamanho dos stops que serão colocados nas extremidades das velas quando encontrarmos uma vela que excedeu a anterior. Isso acontece na função arruma_stop_em_posicoes. Sempre que houver um valor verdadeiro retornado há uma posição e devemos não avançar no código principal em OnTimer. Utilizo essa função e não a OnTick por causa que não preciso de uma função grande executando a cada negócio realizado e sim somente a cada nova vela do período definido. Entretanto, no OnTick uma variável é configurada para verdadeiro para indicar um negócio anterior. Isso é necessário se não no período em que o mercado não está aberto o testador de estratégia iria realizar pausas já que ele executaria a função mesmo sem ter um negócio anterior.
Veja que até aqui tudo seguiu estritamente o definido, inclusive as duas janelas definidas. A primeira é a janela de abertura de negócios que é entre 11h e 16h, a segunda de gerência permite o algoritmo gerenciar a operação aberta movendo os stops até as 16h30 quando ele deve encerrar todos os negócios do dia.
Note que se operarmos esse EA agora o "OnTester result" será zero como pode ser visto na Figura 2, já que não disponibilizamos a função de cálculo para esse valor.
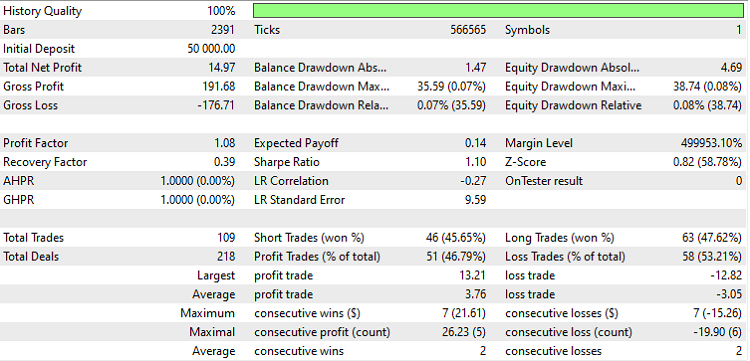
Figura 2: EA executado no USDJPY em H1 no modo OHLC 1 minuto entre as datas de 2023-01-01 à 2023-05-19.
Sobre o fator de qualidade
Para o valor de "OnTester result" vir configurado precisamos definir uma função chamada OnTester que retornará um valor double. Simples assim! Com isso, conseguimos o resultado da Figura 3 utilizando o código que está logo em seguida.

Figura 3: EA executado no USDJPY em H1 no modo OHLC 1 minuto entre as datas de 2023-01-01 à 2023-05-19.
O código a seguir é colocado no final do código anterior. Nele, calculamos a relação média entre o risco e o retorno das operações. Essa relação é frequentemente expressa pelo retorno obtido, uma vez que o risco é considerado constante em 1. Sendo assim, podemos interpretar a relação risco:retorno de 1:1.23 ou, também, 1.23 e um outrou exemplo 0.43. No primeiro exemplo, para cada 1 dólar arriscado ganhamos 1.23, já no segundo para cada 1 dólar arriscado perdemos 0.43. Portanto, quando o retorno é 1 ou próximo disso quer dizer que ficamos em um empate e acima quer dizer que estamos ganhando.
Como nas estatísticas não é provido o valor médio ganhodo ou perdido então utilizaremos o valor bruto normalizado pela quantidade de negócios em cada lado (compra ou venda). No recuperar os valores de negócios realizados para ser utilizado é somado 1. Dessa forma, caso não tenha operações com lucro ou não tenha operações com prejuízo o programa não encerrará por conta de divisão por zero durante o cálculo. Além disso, para evitar a exibição de uma grande quantidade de dígitos grandes como anteriormente na Figura 1 que possuía mais de 5 dígitos foi usada a função NormalizeDouble para deixar o resultado com somente com 2 dígitos.
double OnTester() { //--- Media de Lucro double lucro_medio=TesterStatistics(STAT_GROSS_PROFIT)/(TesterStatistics(STAT_PROFIT_TRADES)+1); //--- Media de Prejuizo double prejuizo_medio=-TesterStatistics(STAT_GROSS_LOSS)/(TesterStatistics(STAT_LOSS_TRADES)+1); //--- Calculo do Risco:Retorno que sera retornado double rr_medio = lucro_medio / prejuizo_medio; //--- return NormalizeDouble(rr_medio, 2); }
A função OnTester deve estar em cada código de EA para ser exibido o valor no relátorio. Para minimar esse trabalho de copiar diversas linhas de código, iremos isolar a função em um arquivo separado e, com isso, precisaremos somente copiar uma única linha toda vez. Como pode ser visto:
#include "ARTICLE_METRICS.mq5"
Assim, teremos um código mais conciso! No arquivo mencionado, a função será definida por uma definição. Isso é necessário para permitir que, caso queiramos utilizar o include, possamos alterar o nome da função a ser incluída sem complicações, evitando assim possíveis erros de duplicidade caso a função OnTester já esteja definida. Dessa forma, podemos considerar isso como um mecanismo para dar preferência ao OnTester que seria inserido diretamente no código do EA. Se quisermos fazer a utilização por meio do include, basta comentar a função OnTester no código do EA e comentar a definição correspondente. Voltaremos a isso, antes do artigo terminar.
O arquivo "ARTICLE_METRICS.mq5" ficaria inicialmente assim:
//--- Calcula o Risco:Retorno medio das operacoes double rr_medio() { //--- Media de Lucro double lucro_medio=TesterStatistics(STAT_GROSS_PROFIT)/(TesterStatistics(STAT_PROFIT_TRADES)+1); //--- Media de Prejuizo double prejuizo_medio=-TesterStatistics(STAT_GROSS_LOSS)/(TesterStatistics(STAT_LOSS_TRADES)+1); //--- Calculo do Risco:Retorno que sera retornado double rr_medio = lucro_medio / prejuizo_medio; //--- return NormalizeDouble(rr_medio, 2); } //+------------------------------------------------------------------+ //| OnTester | //+------------------------------------------------------------------+ #ifndef SQN_TESTER_ON_TESTER #define SQN_TESTER_ON_TESTER OnTester #endif double SQN_TESTER_ON_TESTER() { return rr_medio(); }
Note que o nome correto do arquivo deveria ser com extensão "mqh". Entretanto, como planejo manter o arquivo dentro do diretório de EAs deixei a extensão de código propositalmente. Fica a seu critério.
Primeira versão do cálculo de qualidade
Nossa primeira versão do cálculo de qualidade que vamos mostrar é baseada na abordagem criada por Sunny Harris intitulado CPC Index. Esse cálculo utiliza três métricas que são multiplicadas entre si: risco:retorno médio, taxa de acerto e fator de lucro.No entanto, vamos modifica-lo para não utilizar o fator de lucro e, sim, o menor valor entre o fator de lucro e o fator de recuperação. Embora, se considerarmos a diferença entre as duas deveriamos optar pelo fator de recuperação preferi deixar assim porque já leva a um aprimoramento do cálculo.
O trecho de código a seguir implementa a abordagem mencionada no paragrafo anterior. Bastando para isso trocar para chama-la na função OnTester. Note que aqui na quantidade de negócios não foi somado 1 porque o valor provido é o total e esperamos que haja ao menos 1 negócio a ser avaliado.
//--- Calcula o CPC Index da Sunny Harris double CPCIndex() { double taxa_acerto=TesterStatistics(STAT_PROFIT_TRADES)/TesterStatistics(STAT_TRADES); double fator=MathMin(TesterStatistics(STAT_PROFIT_FACTOR), TesterStatistics(STAT_RECOVERY_FACTOR)); return NormalizeDouble(fator * taxa_acerto * rr_medio(), 5); }
Segunda versão do cálculo de qualidade
O segundo fator de qualidade que abordaremos é denominado System Quality Number (SQN) e foi criado por Van Tharp. Realizaremos o cálculo para as operações realizadas mês a mês e realizaremos uma média simples de todos os meses da simulação. O SQN difere do abordagem explicada na seção anterior, pois busca enfatizar a estabilidade do sistema de negociação.
Assim, uma característica importante do SQN é que ele penaliza sistemas que podem ter solavancos. Dessa forma, se o sistema possuir uma serie de operações pequenas e uma grande ele será penalizado. Isso quer dizer que se tivermos um sistema com pequenas perdas e grandes ganhos iremos penaliza-lo. Também será penalizado o contrário, pequenos ganhos e grandes perdas. Esse último é o pior para quem negócia.
Lembre-se que negociar é uma corrida de longo prazo e foque sempre na estabilidade de obdecer seu sistema! Não no dinheiro no final do mês que aparece, já que isso pode ter uma grande variabilidade.
//--- desvio padrao dos negocios realizados pelo resultado monetario double dp_por_negocio(uint primeiro_negocio, uint ultimo_negocio, double media_dos_resultados, double quantidade_negocios) { ulong ticket=0; double dp=0.0; for(uint i=primeiro_negocio; i < ultimo_negocio; i++) { //--- try to get deals ticket if((ticket=HistoryDealGetTicket(i))>0) { //--- get deals properties double profit=HistoryDealGetDouble(ticket,DEAL_PROFIT); //--- create price object if(profit!=0) { dp += MathPow(profit - media_dos_resultados, 2.0); } } } return MathSqrt(dp / quantidade_negocios); } //--- Calcula o System Quality Number, SQN, de Van Tharp double sqn(uint primeiro_negocio, uint ultimo_negocio, double lucro_acumulado, double quantidade_negocios) { double lucro_medio = lucro_acumulado / quantidade_negocios; double dp = dp_por_negocio(primeiro_negocio, ultimo_negocio, lucro_medio, quantidade_negocios); if(dp == 0.0) { // Como o desvio padrao retornou um valor zero que nao eh esperado // modificamos ele para o lucro_medio já que não tem desvio, o que // fara o sistema ficar proximo do resultado 1. dp = lucro_medio; } //--- A quantidade de negocios aqui eh limitada ate 100 para o resultado //--- nao ser maximizado em funcao de uma grande quantidade de negocios. double res = (lucro_medio / dp) * MathSqrt(MathMin(100, quantidade_negocios)); return NormalizeDouble(res, 2); } //--- retorna se um novo mes foi encontrado bool eh_um_novo_mes(datetime timestamp, int &mes_anterior) { MqlDateTime mdt; TimeToStruct(timestamp, mdt); if(mes_anterior < 0) { mes_anterior=mdt.mon; } if(mes_anterior != mdt.mon) { mes_anterior = mdt.mon; return true; } return false; } //--- SQN Mensal double sqn_mes(void) { double sqn_acumulado = 0.0; double lucro_acumulado = 0.0; double quantidade_negocios = 0.0; int sqn_n = 0; int mes = -1; uint primeiro_negocio = 0; uint total_negocios; //--- requisitando o historico de negocios if(HistorySelect(0,TimeCurrent()) == false) return 0.0; total_negocios = HistoryDealsTotal(); //--- para cada negocio, vamos calcular a media de cada mes for(uint i=primeiro_negocio; i < total_negocios; i++) { ulong ticket=0; //--- Selecionamos o ticket desejado para pegar as informacoes if((ticket=HistoryDealGetTicket(i))>0) { datetime time = (datetime)HistoryDealGetInteger(ticket, DEAL_TIME); double lucro = HistoryDealGetDouble(ticket,DEAL_PROFIT); if(lucro == 0) { //--- Se nao houver resultado seguimos pro proximo negocio continue; } if(eh_um_novo_mes(time, mes)) { //--- Se tivermos negocios calculamos o sqn, se nao ele eh zero... if(quantidade_negocios>0) { sqn_acumulado += sqn(primeiro_negocio, i, lucro_acumulado, quantidade_negocios); } //--- A quantidade de sqns calculada eh atualizada sempre! sqn_n++; primeiro_negocio=i; lucro_acumulado = 0.0; quantidade_negocios = 0; } lucro_acumulado += lucro; quantidade_negocios++; } } //--- ao sair do for podemos ter algum rescaldo pendente if(quantidade_negocios>0) { sqn_acumulado += sqn(primeiro_negocio, total_negocios, lucro_acumulado, quantidade_negocios); sqn_n++; } //--- fazemos a media simples dos sqns return NormalizeDouble(sqn_acumulado / sqn_n, 2); }
Vamos explicar o código de baixo para cima:
A primeira função realiza o cálculo do desvio padrão do conjunto de negócios. Aqui, seguimos a recomendação de Van Tharp, que enfatiza a inclusão de todos os negócios no cálculo do desvio padrão. No entanto, na fórmula final que se encontra na função seguinte, limitamos o número de negócios a 100. Isso é feito para evitar que o resultado seja distorcido devido à quantidade de negócios, tornando-o mais prático e significativo.
Por fim, temos a função sqn_mes que verifica se estamos em um novo mês e acumula alguns dados necessários para as funções anteriores. No final dessa função é feita a média dos SQNs mensais para o período que a simulação ocorreu. Essa breve explicação visa tentar dar um apanhado geral do código e o o*bjetivo de cada função. Seguindo essa abordagem, é possível entender melhor o cálculo do SQN.
double SQN_TESTER_ON_TESTER() { PrintFormat("%G,%G,%G", rr_medio(), CPCIndex(), sqn_mes()); return NormalizeDouble(sqn_mes() * CPCIndex(), 5); }
Antes de encerrar
Vamos voltar antes de encerrar este artigo no assunto do include e sobre como evitar o erro de duplicidade. Vamos dizer que voce tenha um código de EA com a função OnTester e deseje colocar o include do arquivo mencionado. Ficaria algo como abaixo (ignore o conteúdo do OnTester desse exemplo).
//+------------------------------------------------------------------+ double OnTester() { return __LINE__; } //+------------------------------------------------------------------+ #include "ARTICLE_METRICS.mq5"
Esse código resultará em um erro de função duplicada por causa que tanto o EA tem em seu código uma função OnTester quanto o arquivo de include possui uma função com mesmo nome. Entretanto, podemos utilizar duas definições para alterar o nome de uma delas e simular um mecanismo de habilitar ou desabilitar qual função deveria ser utilizada. Veja o exemplo abaixo.
//+------------------------------------------------------------------+ #define OnTester disable //#define SQN_TESTER_ON_TESTER disable double OnTester() { return __LINE__; } #undef OnTester //+------------------------------------------------------------------+ #include "ARTICLE_METRICS.mq5"
Nesse novo formato não teremos erro de função duplicada por causa que a definição irá renomear a função no código do EA de OnTester para disable. Agora se comentarmos a primeira e descomentarmos a segunda definição, teremos como resultado a função dentro do arquivo, ARTICLE_METRICS, sendo alterada para o nome disable e a função do arquivo do EA mantendo-se nomeada como OnTester.
Essa abordagem parece ser uma maneira simples de intercalar entre ambas as funções que não envolve comentar diversas linhas de código. Mesmo ela sendo um pouco mais invasiva acredito que pode ser considerada pelo usuário. Outra coisa a ser considerada pelo usuário, seria se tem necessidade de manter a função junto do EA dado que já existiria uma em um arquivo dado include pode se tornar confuso.
Conclusões
Chegamos ao final deste artigo, no qual apresentamos um modelo de EA que opera aleatoriamente para servir de exemplo na demonstração dos cálculos de fator de qualidade. Sendo assim, 2 possíveis cálculos foram abordados: Van Tharp e Sunny Harris. Além de um fator introdutório utilizando a relação risco e retorno. Além de ter demonstrado como a utilização de includes pode deixar facilitar alternar entre diferentes funções disponíveis.
Se tiver alguma dúvidas ou achou um erro? Comente no tópico do artigo! Os códigos mencionados tanto do EA quanto do arquivo de métricas estão no zip em anexo para seu estudo!
Voce utiliza uma outra métrica de qualidade? Compartilhe comentando aqui no tópico do artigo para conhece-lá! Muito obrigado pelo ler este artigo.
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso