
Metamodelos em aprendizado de máquina e negociação: Tempo original das ordens de negociação
Introdução
Uma característica distintiva de alguns sistemas de negociação é que eles não estão constantemente no mercado, e operam de forma seletiva. Em grande parte, isso se deve à presença de padrões em determinados momentos, que em outras ocasiões estariam ausentes ou não estariam definidos.
Em artigos anteriores, discutimos em detalhes as várias maneiras pelas quais os modelos de aprendizado de máquina podem ser aplicados a problemas de classificação de séries temporais. Todos esses modelos foram treinados "tal qual como estavam" na amostra de treinamento e compilados em bots após o aprendizado. A rotulagem do conjunto de dados de treinamento e a escolha do melhor modelo foram automatizadas ao máximo, o que praticamente eliminou o fator humano. Com toda a elegância das abordagens propostas, estes modelos apresentam dois inconvenientes que seriam difíceis de corrigir sem introduzir funcionalidades adicionais.
Eu me propus a expandir a abordagem para casos em que o modelo pode:
- adaptar-se ao conjunto de dados de treinamento, escolhendo os melhores exemplos para o aprendizado
- filtrar as partes da série temporal que são difíceis de classificar e pulá-las no processo de aprendizado e de negociação
Essa expansão me fez reconsiderar parcialmente a abordagem de treinamento. Acontece que o uso de apenas um classificador não atendia às novas exigências: ele não podia se ajustar no processo de aprendizagem. Por isso, apresento um novo trabalho com a funcionalidade alterada para os casos acima.
Aspectos teóricos da nova abordagem
No início desta seção, gostaria de fazer uma pequena observação. Como no processo de desenvolvimento de sistemas de negociação (incluindo o uso de aprendizado de máquina) o pesquisador lida com a incerteza, é impossível explicar rigorosamente o que se busca em última instância. Trata-se de algumas dependências mais ou menos estáveis no espaço multidimensional, difíceis de interpretar em linguagem humana ou mesmo matemática. É difícil realizar uma análise detalhada do que obtemos na saída de sistemas de autoaprendizagem altamente parametrizados. Tais algoritmos exigem um certo grau de confiança nos resultados de backtest, mas não esclarecem a própria essência ou mesmo a natureza do padrão detetado.
Queremos escrever um algoritmo que seja capaz de analisar e corrigir seus próprios erros, melhorando iterativamente seus resultados. Para isso, propõe-se pegar um agrupamento formado por dois classificadores e treiná-los seguidamente, como sugerido no esquema abaixo. A seguir, veremos uma descrição detalhada da ideia e uma explicação do esquema.
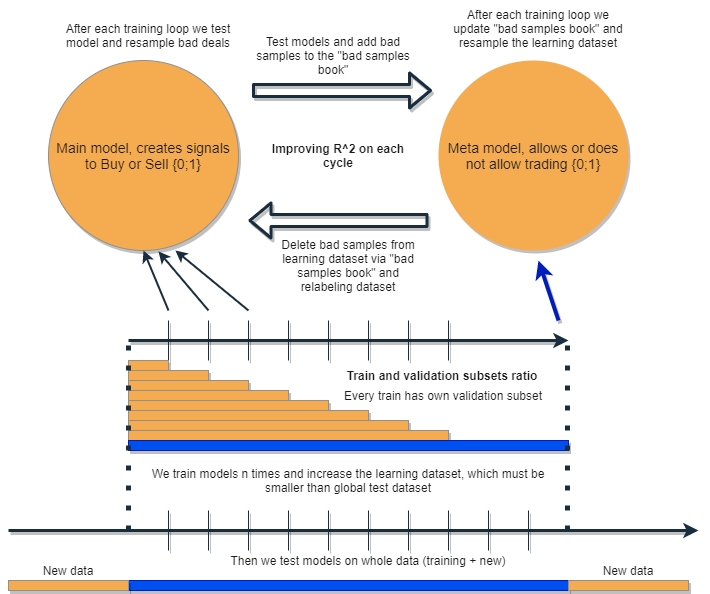
Cada um dos classificadores é treinado em seu próprio conjunto de dados, que possui tamanhos diferentes. A linha horizontal azul representa a profundidade condicional do histórico para o metamodelo e as linhas laranja para o modelo base. Em outras palavras, a profundidade do histórico para um metamodelo é sempre maior que para o modelo base e é igual ao intervalo de tempo estimado (teste) em que a combinação desses modelos será testada.
Um agrupamento de modelos é retreinado várias vezes, enquanto o conjunto de dados de treinamento para o modelo base pode aumentar gradualmente (aumentando o comprimento das colunas laranja a cada nova iteração), mas seu comprimento não deve exceder o comprimento do azul. Após cada iteração, todos os exemplos que foram classificados pelo metamodelo como falsos (ou zero) são removidos da amostra de treinamento do modelo base. O metamodelo, por sua vez, continua a aprender com todos os exemplos.
O que se entende por trás desta abordagem é que os negócios não lucrativos são erros de classificação do primeiro tipo para o modelo base, na terminologia da matriz de descoordenação (confusion matrix). Ou seja, esses são os casos que ela classifica como falsos positivos. O metamodelo filtra esses casos e dá uma pontuação de 1 para verdadeiros positivos e 0 para todo o resto. Com a filtragem do conjunto de dados através do metamodelo para treinar o modelo base, aumentamos sua Precision, ou seja, o número de disparadores de compra e venda correto. Ao mesmo tempo, o metamodelo aumenta sua Recall classificando o maior número possível de resultados diferentes.
Quanto maior a Precision e a Recall, mais preciso é o modelo. Mas em situações reais, uma melhoria em um indicador leva a uma deterioração em outro dentro do mesmo classificador, então usar um pacote de dois classificadores parece uma ideia interessante, que provoca uma melhora em ambos os indicadores.
Conforme planejado, os dois modelos são treinados nas mesmas características e, portanto, possuem interação adicional. Dado o aumento da amostra para o metamodelo (coluna horizontal azul, em comparação à laranja), ele deixa boas situações de negociação, com a filtragem dos erros do modelo base quanto aos dados que são novos para ele. Ao interagir uns com os outros, os modelos são melhorados de forma iterativa devido à nova rotulagem, e a pontuação R^2 na amostra de validação está em constante crescimento. Mas o metamodelo pode ser treinado em suas próprias características como um filtro para o modelo base, porém tal pacote não se encaixa perfeitamente no escopo da abordagem proposta, portanto não será considerado neste artigo.
O modelo base deve funcionar bem devido à constante "manutenção" do metamodelo, mas o próprio metamodelo também pode estar errado. Por exemplo, na primeira iteração, foram classificados os casos em que não faz sentido negociar. Na segunda iteração, após retreinar o modelo base e ajustar os exemplos para o metamodelo, exemplos ruins podem diferir daqueles da iteração anterior. Por causa disso, o metamodelo pode tender a rotular nova e constantemente os exemplos que diferem de iteração para iteração. Esse comportamento pode nunca atingir o ideal. Para corrigir esta falha, é criada uma tabela "bad samples book", que é atualizada com exemplos de todas as iterações anteriores. Mais especificamente, ela registrará valores de características em pontos marcados como ruins para negociação durante todas as iterações de treinamento anteriores. Isso permitirá atualizar o conjunto de dados do metamodelo antes de cada um de seus retreinamentos de forma que todos os momentos malsucedidos de iterações anteriores também sejam marcados como ruins (zeros).
O "bad samples book" também tem sua desvantagem, pois muitas iterações adicionarão muitos zeros (negócios ruins), o número de exemplos diminuirá significativamente a cada nova iteração de aprendizado. Portanto, é necessário encontrar um equilíbrio entre o número de iterações e o número de exemplos adicionados ao livro de maus exemplos. Parcialmente, a situação pode ser resolvida calculando a média do número de exemplos ruins dependendo do momento de sua ocorrência e filtrando apenas os mais comuns. Graças a isso, o conjunto de dados para o metamodelo não será corrompido (haverá um equilíbrio entre zeros e uns). Seria uma boa ajuda gerar um excesso de amostragem se as classes se mostrarem altamente desequilibradas.
Após várias iterações, esse grupo de modelos mostrará excelentes resultados nos dados de treinamento e de validação. E o resultado melhorará de iteração para iteração. Após o treinamento, o pacote de modelos deve ser testado com dados completamente novos, que podem ser localizados mais cedo ou mais tarde do que a subamostra de treinamento. Não há teoria para dizer com clareza qual parte do histórico deve ser escolhida para testes em séries temporais financeiras não estacionárias. Mesmo assim, prevê-se que o desempenho da abordagem proposta melhorará com os novos dados, e a prática demonstrará o resto.
Muito bem, nós treinamos um modelo, corrigimos seus erros com novos dados com outro modelo e repetimos este processo várias vezes. Por que isso deveria melhorar a estabilidade dos classificadores com base em novos dados? Não há uma resposta única para esta pergunta. Existe a hipótese de que existe um padrão, e se houver um padrão, ele será encontrado, enquanto situações sem um padrão serão filtradas. Se o padrão for estável, o modelo também trabalhará com novos dados.
Essa abordagem, em teoria, deveria matar dois coelhos com uma cajadada só:
- tem uma alta expectativa de negócios lucrativos
- faz o "timing" automático do sistema de negociação, operando apenas em determinados pontos altamente eficazes no tempo
Já que estamos falando sobre o timing do sistema de negociação, devemos tocar em mais um ponto interessante. A dependência da escolha de características (features) para o modelo diminuiu.
A abordagem básica e a marcação supervisionada implica uma atitude escrupulosa em relação à escolha de preditores e alvos, na verdade este é o principal problema com esta abordagem. A preparação e análise dos dados sempre vem em primeiro lugar, e a qualidade dos modelos depende diretamente do profissionalismo do analista no campo em questão, em particular FOREX.
A abordagem proposta deve encontrar automaticamente eventos de timing, preditores e rótulos interrelacionados e usar padrões encontrados automaticamente. A escolha de preditores e a rotulagem de negócios ocorrem automaticamente. Ainda assim, é necessário cumprir uma série de condições, por exemplo, os sinais devem ser estacionários e ter pelo menos uma relação indireta com o instrumento financeiro. Mas quando os verdadeiros padrões são desconhecidos para nós e não há onde extrair informações, tal abordagem parece justificada.
Naturalmente, com evidentes características "corrompidas" que não têm relação causal com os negócios, este algoritmo funcionará de forma aleatória. Mas isso já é uma questão da presença/ausência de relações causais como tais. Não tratamos intencionalmente da construção de outras características além dos incrementos (a diferença entre a média móvel e o preço) neste artigo, pois este é um tema separado e abundante que pode ser abordado em outros artigos. Pode-se sugerir que uma abordagem analítica à seleção de características informativas deve aumentar significativamente a robustez deste algoritmo em novos dados.
Implementação prática da abordagem proposta
Tudo parece ótimo em teoria (como sempre), agora vamos verificar que efeito a combinação dos dois classificadores realmente tem. Para fazer isso, você precisa reescrever o código.
Função de rotulagem automática de negócios
Foram feitas mudanças, agora é possível rotular novamente o modelo base com base nos rótulos dos metamodelos:
def labelling_relabeling(dataset, min=15, max=15, relabeling=False) -> pd.DataFrame: labels = [] for i in range(dataset.shape[0]-max): rand = random.randint(min, max) curr_pr = dataset['close'][i] future_pr = dataset['close'][i + rand] if relabeling: m_labels = dataset['meta_labels'][i:rand+1].values if relabeling and 0.0 in m_labels: labels.append(2.0) else: if future_pr + MARKUP < curr_pr: labels.append(1.0) elif future_pr - MARKUP > curr_pr: labels.append(0.0) else: labels.append(2.0) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() dataset = dataset.drop( dataset[dataset.labels == 2].index) return dataset
O código destacado verifica o sinalizador de rerrotulagem, se for True e a metarrotulagem atual com o horizonte de negócios contiver zeros, então o metamodelo rejeitará a negociação naquela área. Assim, esses negócios são rotulados como 2.0 e removidas do conjunto de dados. Desta forma, é possível remover iterativamente amostras indesejadas da amostra de treinamento para o modelo base, reduzindo seu erro de aprendizado.
Função de testador personalizado
Agora existe uma funcionalidade estendida que permite testar dois modelos ao mesmo tempo (base e meta). Além disso, o testador personalizado agora pode rotular novamente o metamodelo para melhorá-lo na próxima iteração.
def tester(dataset: pd.DataFrame, markup=0.0, use_meta=False, plot=False): last_deal = int(2) last_price = 0.0 report = [0.0] meta_labels = dataset['labels'].copy() for i in range(dataset.shape[0]): pred = dataset['labels'][i] meta_labels[i] = np.nan if use_meta: pred_meta = dataset['meta_labels'][i] # 1 = allow trades if last_deal == 2 and ((use_meta and pred_meta==1) or not use_meta): last_price = dataset['close'][i] last_deal = 0 if pred <= 0.5 else 1 continue if last_deal == 0 and pred > 0.5 and ((use_meta and pred_meta==1) or not use_meta): last_deal = 2 report.append(report[-1] - markup + (dataset['close'][i] - last_price)) if report[-1] > report[-2]: meta_labels[i] = 1 else: meta_labels[i] = 0 continue if last_deal == 1 and pred < 0.5 and ((use_meta and pred_meta==1) or not use_meta): last_deal = 2 report.append(report[-1] - markup + (last_price - dataset['close'][i])) if report[-1] > report[-2]: meta_labels[i] = 1 else: meta_labels[i] = 0 y = np.array(report).reshape(-1, 1) X = np.arange(len(report)).reshape(-1, 1) lr = LinearRegression() lr.fit(X, y) l = lr.coef_ if l >= 0: l = 1 else: l = -1 if(plot): plt.plot(report) plt.plot(lr.predict(X)) plt.title("Strategy performance R^2 " + str(format(lr.score(X, y) * l,".2f"))) plt.xlabel("the number of trades") plt.ylabel("cumulative profit in pips") plt.show() return lr.score(X, y) * l, meta_labels.fillna(method='backfill')
O Expert Advisor funciona da seguinte maneira:
Se o sinalizador para levar em conta o metamodelo for definido durante o teste, sua condição de presença de sinal (um) será verificada. Se o sinal existir, o modelo base poderá abrir e fechar negócios, caso contrário, ele não poderá operar. Marcador verde claro marca os momentos de adição de novos rótulos para o metamodelo, dependendo do resultado do negócio fechado. Se o resultado for positivo, então um é adicionado, caso contrário o negócio é marcado como 0 (sem sucesso).
Função de força bruta
As mudanças mais extensas foram feitas aqui. Eu as marcarei na lista em cores diferentes e as descreverei para entender o que está acontecendo.
def brute_force(dataset, bad_samples_fraction=0.5): # features for model\meta models. We learn main model only on filtered labels X = dataset[dataset['meta_labels']==1] X = dataset[dataset.columns[:-2]] X = X[X.index >= START_DATE] X = X[X.index <= STOP_DATE] X_meta = dataset[dataset.columns[:-2]] X_meta = X_meta[X_meta.index >= TSTART_DATE] X_meta = X_meta[X_meta.index <= STOP_DATE] # labels for model\meta models y = dataset[dataset['meta_labels']==1] y = dataset[dataset.columns[-2]] y = y[y.index >= START_DATE] y = y[y.index <= STOP_DATE] y_meta = dataset[dataset.columns[-1]] y_meta = y_meta[y_meta.index >= TSTART_DATE] y_meta = y_meta[y_meta.index <= STOP_DATE] # train\test split train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.5, test_size=0.5, shuffle=True,) # learn main model with train and validation subsets model = CatBoostClassifier(iterations=1000, depth=6, learning_rate=0.1, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU', random_seed=13) model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=50, plot=False) # train\test split train_X, test_X, train_y, test_y = train_test_split( X_meta, y_meta, train_size=0.5, test_size=0.5, shuffle=True) # learn meta model with train and validation subsets meta_model = CatBoostClassifier(iterations=1000, depth=6, learning_rate=0.1, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU', random_seed=13) meta_model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=50, plot=False) # predict on new data (validation plus learning) pr_tst = get_prices() X = pr_tst[pr_tst.columns[1:]] X.columns = [''] * len(X.columns) X_meta = X.copy() # predict the learned models (base and meta) p = model.predict_proba(X) p_meta = meta_model.predict_proba(X_meta) p2 = [x[0] < 0.5 for x in p] p2_meta = [x[0] < 0.5 for x in p_meta] pr2 = pr_tst.iloc[:len(p2)].copy() pr2['labels'] = p2 pr2['meta_labels'] = p2_meta pr2['labels'] = pr2['labels'].astype(float) pr2['meta_labels'] = pr2['meta_labels'].astype(float) full_pr = pr2.copy() pr2 = pr2[pr2.index >= TSTART_DATE] pr2 = pr2[pr2.index <= STOP_DATE] # add bad samples of this iteratin (bad meta labels) global BAD_SAMPLES_BOOK BAD_SAMPLES_BOOK = BAD_SAMPLES_BOOK.append(pr2[pr2['meta_labels']==0.0].index) # test mdels and resample meta labels R2, meta_labels = tester(pr2, MARKUP, use_meta=True, plot=False) pr2['meta_labels'] = meta_labels # resample labels based on meta labels pr2 = labelling_relabeling(pr2, relabeling=True) pr2['labels'] = pr2['labels'].astype(float) pr2['meta_labels'] = pr2['meta_labels'].astype(float) # mark bad labels from bad_samples_book if BAD_SAMPLES_BOOK.value_counts().max() > 1: to_mark = BAD_SAMPLES_BOOK.value_counts() mean = to_mark.mean() marked_idx = to_mark[to_mark > mean*bad_samples_fraction].index pr2.loc[pr2.index.isin(marked_idx), 'meta_labels'] = 0.0 else: pr2.loc[pr2.index.isin(BAD_SAMPLES_BOOK), 'meta_labels'] = 0.0 R2, _ = tester(full_pr, MARKUP, use_meta=True, plot=False) return [R2, model, meta_model, pr2]
BAD_SAMPLES_BOOK e o restante do código, marcado com o marcador respectivo, é responsável pela implementação do livro de maus exemplos. A cada nova iteração de retreinamento dos dois modelos, ele é reabastecido com novos exemplos de negócios malsucedidos que foram abertos pelos modelos anteriores após o treinamento. A verificação ocorre através do testador.
O último bloco alocado pode ser configurado de forma flexível, dependendo de qual parte dos exemplos com falha devem ser marcados como 0 no próximo treinamento. Por padrão, é calculada a média de todas as duplicatas - para cada data - presentes no livro.
marked_idx = to_mark[to_mark > mean*bad_samples_fraction].index Isso é feito para que nem todas as datas ruins possam ser removidas, mas apenas aquelas nos momentos em que o modelo cometeu mais erros durante todas as iterações de treinamento. Quanto maior o valor do parâmetro bad_samples_fraction, menos datas inválidas serão removidas e vice-versa.
A cor azul indica que, para o modelo base, é usada uma parte reduzida do conjunto de dados, que começa a partir da hora START_DATE. Dados anteriores não participam de seu treinamento, mas participam do aprendizado do metamodelo. Essa cor também destaca que exatamente dois modelos diferentes estão sendo treinados - Base e Meta.
A parte onde são extraídas as previsões de ambos os modelos está marcada em rosa. Com estas previsões, é gerado um novo conjunto de dados, que é empurrado mais abaixo no código. Ele também adiciona rótulos de metamodelo ruins ao livro de exemplos ruins.
Depois disso, ambos os modelos são avaliados em um testador personalizado, que adicionalmente recoloca (corrige) os rótulos do metamodelo para a próxima iteração de treinamento. No conjunto de dados corrigido, o modelo básico é então rerrotulado.
Na etapa final, o conjunto de dados é ainda corrigido com o livro de etiquetas ruins e devolvido pela função para a próxima iteração de aprendizagem.
Apesar da abundância de código Python, ele funciona rapidamente devido à eliminação de loops aninhados e otimização. A maior parte do tempo é gasto no treinamento de classificadores CatBoost. O tempo de treinamento aumenta com o aumento do número de características e o comprimento do conjunto de dados.
Processo de retreinamento iterativo de modelos
Acabei de descrever os principais detalhes da nova abordagem, agora você pode ir diretamente para o ciclo de treinamento do modelo. Proponho analisar tudo o que acontece em cada etapa.
# make dataset
pr = get_prices()
pr = labelling_relabeling(pr, relabeling=False)
a, b = tester(pr, MARKUP, use_meta=False, plot=False)
pr['meta_labels'] = b
pr = pr.dropna()
pr = labelling_relabeling(pr, relabeling=True)
# iterative learning
res = []
BAD_SAMPLES_BOOK = pd.DatetimeIndex([])
for i in range(25):
res.append(brute_force(pr[pr.columns[1:]], bad_samples_fraction=0.7))
print('Iteration: {}, R^2: {}'.format(i, res[-1][0]))
pr = res[-1][3]
As duas primeiras linhas simplesmente criam o conjunto de dados de treinamento, como aconteceu nos exemplos dos artigos anteriores.
>>> pr = get_prices(START_DATE, STOP_DATE) >>> pr = labelling_relabeling(pr, relabeling=False) >>> pr close 0 1 2 3 4 5 6 labels time 2020-05-06 20:00:00 1.08086 0.000258 -0.000572 -0.001667 -0.002396 -0.004554 -0.007759 -0.009549 1.0 2020-05-06 21:00:00 1.08032 -0.000106 -0.000903 -0.002042 -0.002664 -0.004900 -0.008039 -0.009938 1.0 2020-05-06 22:00:00 1.07934 -0.001020 -0.001568 -0.002788 -0.003494 -0.005663 -0.008761 -0.010778 1.0 2020-05-06 23:00:00 1.07929 -0.000814 -0.001319 -0.002624 -0.003380 -0.005485 -0.008559 -0.010684 1.0 2020-05-07 00:00:00 1.07968 -0.000218 -0.000689 -0.002065 -0.002873 -0.004894 -0.007929 -0.010144 1.0 ... ... ... ... ... ... ... ... ... ... 2021-04-13 23:00:00 1.19474 0.000154 0.002590 0.003375 0.003498 0.004095 0.004273 0.004888 0.0 2021-04-14 00:00:00 1.19492 0.000108 0.002337 0.003398 0.003565 0.004183 0.004410 0.005001 0.0 2021-04-14 01:00:00 1.19491 -0.000038 0.002023 0.003238 0.003433 0.004076 0.004353 0.004908 0.0 2021-04-14 02:00:00 1.19537 0.000278 0.002129 0.003534 0.003780 0.004422 0.004758 0.005286 0.0 2021-04-14 03:00:00 1.19543 0.000356 0.001783 0.003423 0.003700 0.004370 0.004765 0.005259 0.0 [5670 rows x 9 columns]
Agora precisamos adicionar rótulos para o metamodelo. Lembre-se de que a função tester() retorna uma pontuação R^2 e um quadro com negócios rotulados. Por isso, executamos o testador e adicionamos o quadro resultante aos dados de entrada.
>>> a, b = tester(pr, MARKUP, use_meta=False, plot=False) >>> pr['meta_labels'] = b >>> pr = pr.dropna() >>> pr close 0 1 2 ... 5 6 labels meta_labels time ... 2020-05-06 20:00:00 1.08086 0.000258 -0.000572 -0.001667 ... -0.007759 -0.009549 1.0 1.0 2020-05-06 21:00:00 1.08032 -0.000106 -0.000903 -0.002042 ... -0.008039 -0.009938 1.0 1.0 2020-05-06 22:00:00 1.07934 -0.001020 -0.001568 -0.002788 ... -0.008761 -0.010778 1.0 1.0 2020-05-06 23:00:00 1.07929 -0.000814 -0.001319 -0.002624 ... -0.008559 -0.010684 1.0 1.0 2020-05-07 00:00:00 1.07968 -0.000218 -0.000689 -0.002065 ... -0.007929 -0.010144 1.0 1.0 ... ... ... ... ... ... ... ... ... ... 2021-04-13 18:00:00 1.19385 0.001442 0.003437 0.003198 ... 0.003637 0.004279 0.0 1.0 2021-04-13 19:00:00 1.19379 0.000546 0.003121 0.003015 ... 0.003522 0.004166 0.0 1.0 2021-04-13 20:00:00 1.19423 0.000622 0.003269 0.003349 ... 0.003904 0.004555 0.0 1.0 2021-04-13 21:00:00 1.19465 0.000820 0.003315 0.003640 ... 0.004267 0.004929 0.0 1.0 2021-04-13 22:00:00 1.19552 0.001112 0.003733 0.004311 ... 0.005092 0.005733 1.0 1.0 [5665 rows x 10 columns]
Os dados estão agora preparados para o treinamento. Você pode fazer uma nova rotulagem adicional dos rótulos principais ('labels') de acordo com os segundos rótulos ('meta_labels'), ou seja, remover do conjunto de dados todos os negócios que se mostraram não lucrativos.
pr = labelling_relabeling(pr, relabeling=True) Os dados estão prontos, agora vamos ver o trabalho do ciclo de treinamento de ambos os modelos.
# iterative learning
res = []
BAD_SAMPLES_BOOK = pd.DatetimeIndex([])
for i in range(25):
res.append(brute_force(pr[pr.columns[1:]], bad_samples_fraction=0.7))
print('Iteration: {}, R^2: {}'.format(i, res[-1][0]))
pr = res[-1][3]
Primeiro é preciso zerar o livro de maus negócios, se sobrar nele alguma coisa do treinamento anterior. Em seguida, o número necessário de iterações é definido no loop. A cada iteração, listas aninhadas com modelos salvos e tudo o resto que a função brute_force() retorna são gravados na lista res[]. Por exemplo, é possível imprimir adicionalmente as informações básicas do modelo a cada iteração.
Na variável pr é registrado o conjunto de dados convertido e retornado, que será usado para treinamento na próxima iteração.
É possível aumentar o período de treinamento do modelo básico, conforme sugerido na parte teórica. Para fazer isso, a data de início do treinamento é alterada consoante o número de dias especificado. Mas seu tamanho não deve exceder o tamanho do intervalo de validação TSTART_DATE, no qual o metamodelo é treinado.
Depois de iniciar o treinamento, você pode ver algo como a imagem a seguir:
Iteration: 0, R^2: 0.30121038659012245 Iteration: 1, R^2: 0.7400055934041012 Iteration: 2, R^2: 0.6221261327516192 Iteration: 3, R^2: 0.8892813889403367 Iteration: 4, R^2: 0.787251984980149 Iteration: 5, R^2: 0.794241109825588 Iteration: 6, R^2: 0.9167876214355855 Iteration: 7, R^2: 0.903399695678254 Iteration: 8, R^2: 0.8273236332747745 Iteration: 9, R^2: 0.8646088124681762 Iteration: 10, R^2: 0.8614746864767437 Iteration: 11, R^2: 0.7900599001415054 Iteration: 12, R^2: 0.8837049280116869 Iteration: 13, R^2: 0.784793801426211 Iteration: 14, R^2: 0.941340102099874 Iteration: 15, R^2: 0.8715065229034792 Iteration: 16, R^2: 0.8104990158946458 Iteration: 17, R^2: 0.8542444489379808 Iteration: 18, R^2: 0.8307365677342298 Iteration: 19, R^2: 0.9092509787525882
A primeira corrida geralmente não é muito boa. Depois o modelo tenta se aprimorar a cada nova passagem. Os modelos são então classificados em ordem crescente R^2 e podem ser testados com novos dados. É possível optar por não utilizar a classificação, e, sim, por olhar primeiro para a evolução dos modelos. Um sinal característico dessa evolução é a redução do número de negócios quando os modelos são testados.
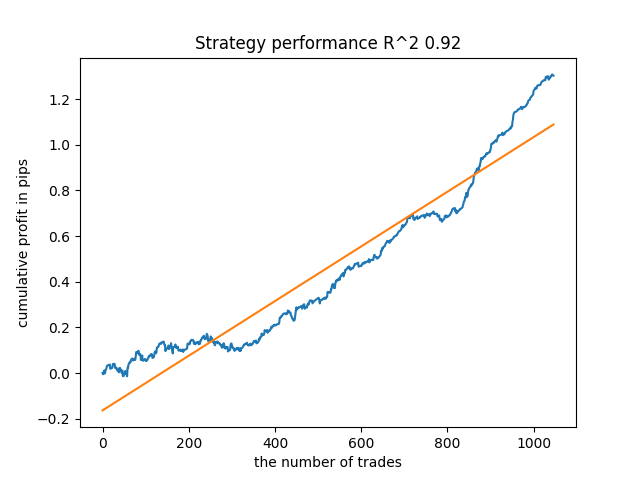
Por exemplo, testei o último modelo treinado e obtive o seguinte resultado (todos os resultados são baseados em novos dados):
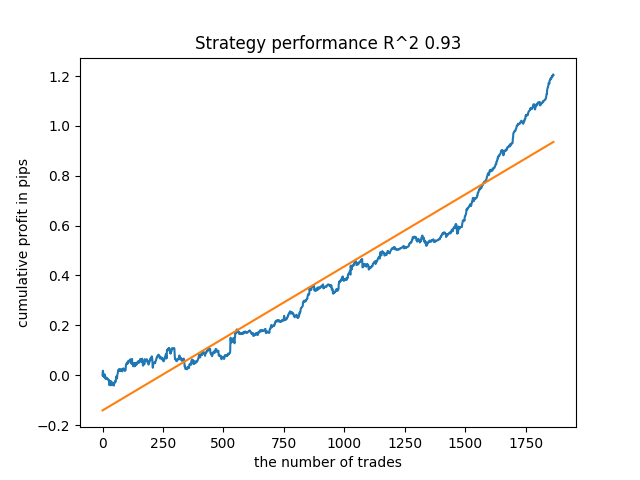
O quinto modelo a partir do final terá mais negócios, e assim por diante:
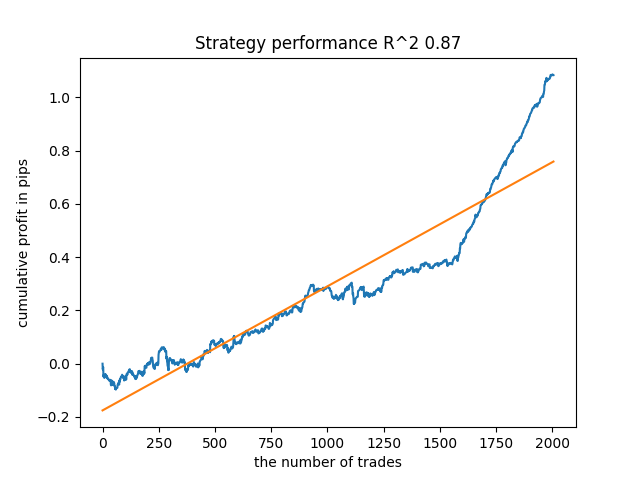
Dependendo do número de iterações e do parâmetro bad_samples_fraction, bem como dos tamanhos dos conjuntos de treinamento e teste, é possível obter modelos estáveis em novos dados. Em geral, a ideia acabou por funcionar, embora bastante difícil de entender e implementar. Aproximadamente a mesma situação aconteceu com o parâmetro use_GMM_resampling habilitado. O número de negócios depende diretamente do número de iterações, mas há exceções. Eu removi a resamostragem da biblioteca, pois demorou muito tempo de treinamento e não melhorou muito os resultados alcançados com esta abordagem.
Por exemplo, gostei do quinto resultado do final:
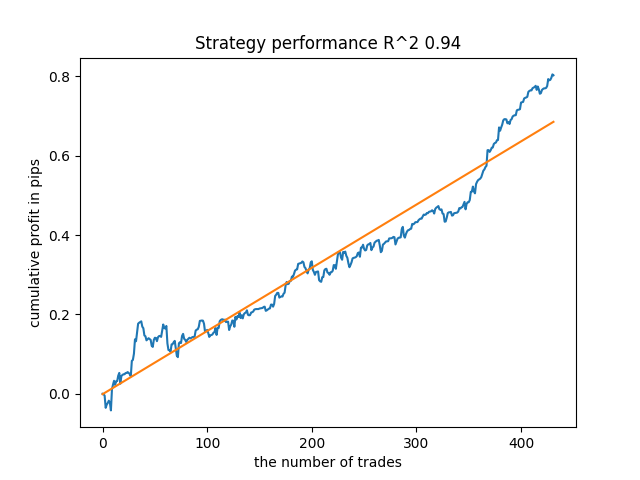
Mas o sétimo resultado foi preferível se considerarmos o número de negócios, que acabou sendo duas vezes maior. O lucro total em pontos também aumentou:
Como exportar modelos em formato MQL5 e compilar um Expert Advisor
Agora os modelos base e metamodelo serão salvos. O modelo base, como antes, controla os sinais de compra e de venda, enquanto o metamodelo proíbe ou permite a negociação em determinados momentos.
# add CatBosst base model code += 'double catboost_model' + '(const double &features[]) { \n' code += ' ' with open('catmodel.h', 'r') as file: data = file.read() code += data[data.find("unsigned int TreeDepth") :data.find("double Scale = 1;")] code += '\n\n' code += 'return ' + \ 'ApplyCatboostModel(features, TreeDepth, TreeSplits , BorderCounts, Borders, LeafValues); } \n\n' # add CatBosst meta model code += 'double catboost_meta_model' + '(const double &features[]) { \n' code += ' ' with open('meta_catmodel.h', 'r') as file: data = file.read() code += data[data.find("unsigned int TreeDepth") :data.find("double Scale = 1;")] code += '\n\n' code += 'return ' + \ 'ApplyCatboostModel(features, TreeDepth, TreeSplits , BorderCounts, Borders, LeafValues); } \n\n'
O código do EA foi ligeiramente alterado. A função catboost_meta_model(), que gera um sinal, é chamada. Se for maior que 0,5, a negociação é permitida.
void OnTick() { //--- if(!isNewBar()) return; TimeToStruct(TimeCurrent(), hours); double features[]; fill_arays(features); if(ArraySize(features) !=ArraySize(MAs)) { Print("No history availible, will try again on next signal!"); return; } double sig = catboost_model(features); double meta_sig = catboost_meta_model(features); // close positions by an opposite signal if(meta_sig > 0.5) if(count_market_orders(0) || count_market_orders(1)) for(int b = OrdersTotal() - 1; b >= 0; b--) if(OrderSelect(b, SELECT_BY_POS) == true) { if(OrderType() == 0 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig > 0.5) if(OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red)) { } if(OrderType() == 1 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig < 0.5) if(OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red)) { } } // open positions and pending orders by signals if(meta_sig > 0.5) if(countOrders() == 0 && CheckMoneyForTrade(_Symbol,LotsOptimized(),ORDER_TYPE_BUY)) { double l = LotsOptimized(); if(sig < 0.5) { OrderSend(Symbol(),OP_BUY,l, Ask, 0, Bid-stoploss*_Point, Ask+takeprofit*_Point, NULL, OrderMagic); } else { OrderSend(Symbol(),OP_SELL,l, Bid, 0, Ask+stoploss*_Point, Bid-takeprofit*_Point, NULL, OrderMagic); } } }
Complementos
Para usuários MAC e Linux, o terminal api para carregamento de cotações não está disponível. Sugiro usar outra função que aceite cotações carregadas desde o terminal MetaTrader 5 para um arquivo. O arquivo deve ser salvo no diretório de trabalho.
def get_prices() -> pd.DataFrame:
p = pd.read_csv('EURUSDMT5.csv', delim_whitespace=True)
pFixed = pd.DataFrame(columns=['time', 'close'])
pFixed['time'] = p['<DATE>'] + ' ' + p['<TIME>']
pFixed['time'] = pd.to_datetime(pFixed['time'], infer_datetime_format=True)
pFixed['close'] = p['<CLOSE>']
pFixed.set_index('time', inplace=True)
pFixed.index = pd.to_datetime(pFixed.index, unit='s')
pFixed = pFixed.dropna()
pFixedC = pFixed.copy()
count = 0
for i in MA_PERIODS:
pFixed[str(count)] = pFixedC - pFixedC.rolling(i).mean()
count += 1
return pFixed.dropna()
Três datas estão agora em uso. Graças a isso, é possível classificar modelos tanto por teste backward quanto por teste forward. O início do forward é definido pela variável global STOP_DATE, os dados após esta data não serão utilizados no processo de treinamento, mas serão utilizados no processo de teste. Por analogia, tudo antes de TSTART_DATE é um teste backward.
START_DATE = datetime(2021, 1, 1) TSTART_DATE = datetime(2017, 1, 1) STOP_DATE = datetime(2022, 1, 1)
Não esqueça que o modelo base é treinado com dados para o período START_DATE - STOP_DATE, e o metamodelo é treinado com dados TSTART_DATE - STOP_DATE. Todos os dados restantes no arquivo participam apenas dos testes backward e forward.
Mais alguns testes
Decidi testar o método de aprendizado proposto utilizando algum par de moedas, por exemplo, GBPJPY H1. As cotações de 2010 foram carregadas a partir do terminal. O número de recursos e períodos para treinamento foram escolhidos da seguinte forma:
MA_PERIODS = [i for i in range(15, 500, 15)] MARKUP = 0.00002 START_DATE = datetime(2021, 1, 1) TSTART_DATE = datetime(2018, 1, 1) STOP_DATE = datetime(2022, 1, 1)
O modelo base é treinado de 2021 até o início de 2022, enquanto o metamodelo é treinado de 2018 a 2022. Todos os outros dados são usados para testar novos dados, ou seja, de 2010 a 2022.06.15.
Amostras de negócios com uma duração aleatória selecionada entre 15-35.
def labelling_relabeling(dataset, min=15, max=35, relabeling=False):
25 iterações de treinamento e um multiplicador de 0,5 para a lista de maus exemplos foram escolhidos:
# iterative learning res = [] BAD_SAMPLES_BOOK = pd.DatetimeIndex([]) for i in range(25): res.append(brute_force(pr[pr.columns[1:]], bad_samples_fraction=0.5)) print('Iteration: {}, R^2: {}'.format(i, res[-1][0])) pr = res[-1][3] # test best model res.sort() p = test_model(res[-1])
Durante o processo de treinamento, foram obtidos os seguintes valores de estimativas R^2 para todo o conjunto de dados desde 2010:
Iteration: 0, R^2: 0.8364212812476872 Iteration: 1, R^2: 0.8265960950867208 Iteration: 2, R^2: 0.8710535097094494 Iteration: 3, R^2: 0.820894300254345 Iteration: 4, R^2: 0.7271704621597865 Iteration: 5, R^2: 0.8746302835797399 Iteration: 6, R^2: 0.7746283871087961 Iteration: 7, R^2: 0.870806543378866 Iteration: 8, R^2: 0.8651222653557956 Iteration: 9, R^2: 0.9452164577256995 Iteration: 10, R^2: 0.867541289963404 Iteration: 11, R^2: 0.9759544230548619 Iteration: 12, R^2: 0.9063804006221455 Iteration: 13, R^2: 0.9609701853129079 Iteration: 14, R^2: 0.9666262255426672 Iteration: 15, R^2: 0.7046628448822643 Iteration: 16, R^2: 0.7750941894554821 Iteration: 17, R^2: 0.9436968900331276 Iteration: 18, R^2: 0.8961403809578388 Iteration: 19, R^2: 0.9627553719743711 Iteration: 20, R^2: 0.9559809326980575 Iteration: 21, R^2: 0.9578579606050637 Iteration: 22, R^2: 0.8095556721129047 Iteration: 23, R^2: 0.654147043077418 Iteration: 24, R^2: 0.7538928969905255
Em seguida, os modelos foram ordenados pelo maior R^2, aqui estão os melhores deles, em ordem decrescente de pontuação.
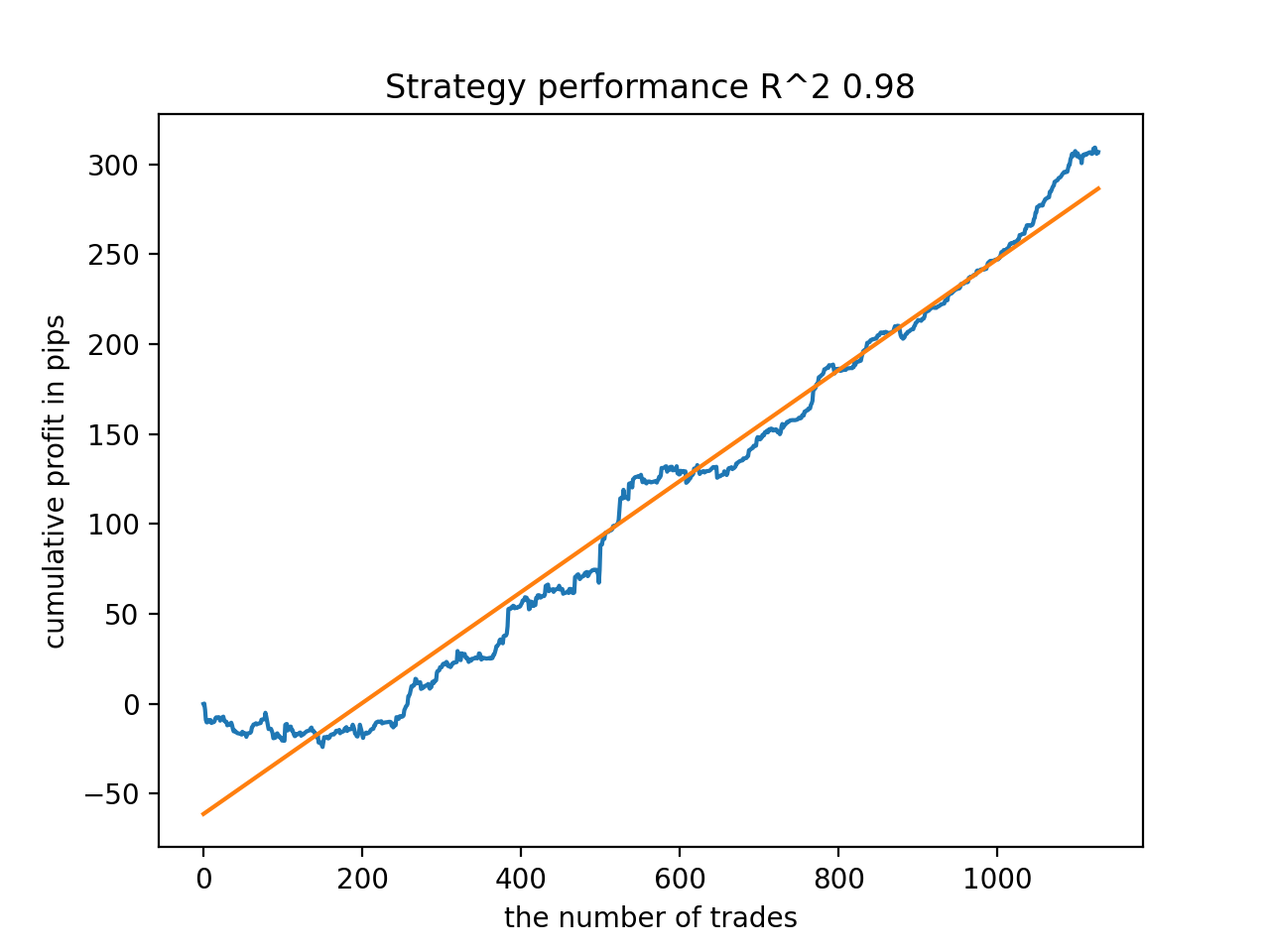
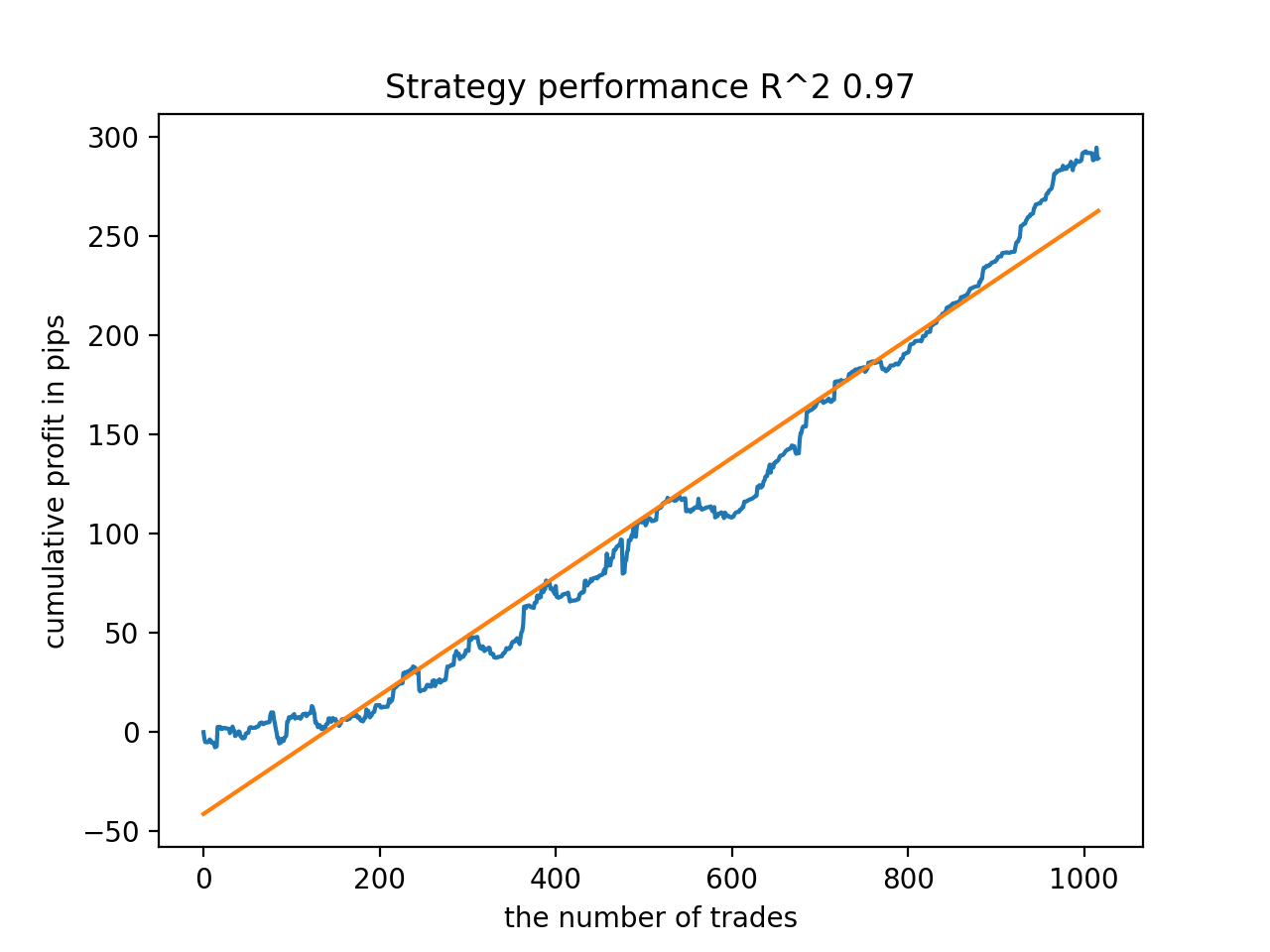
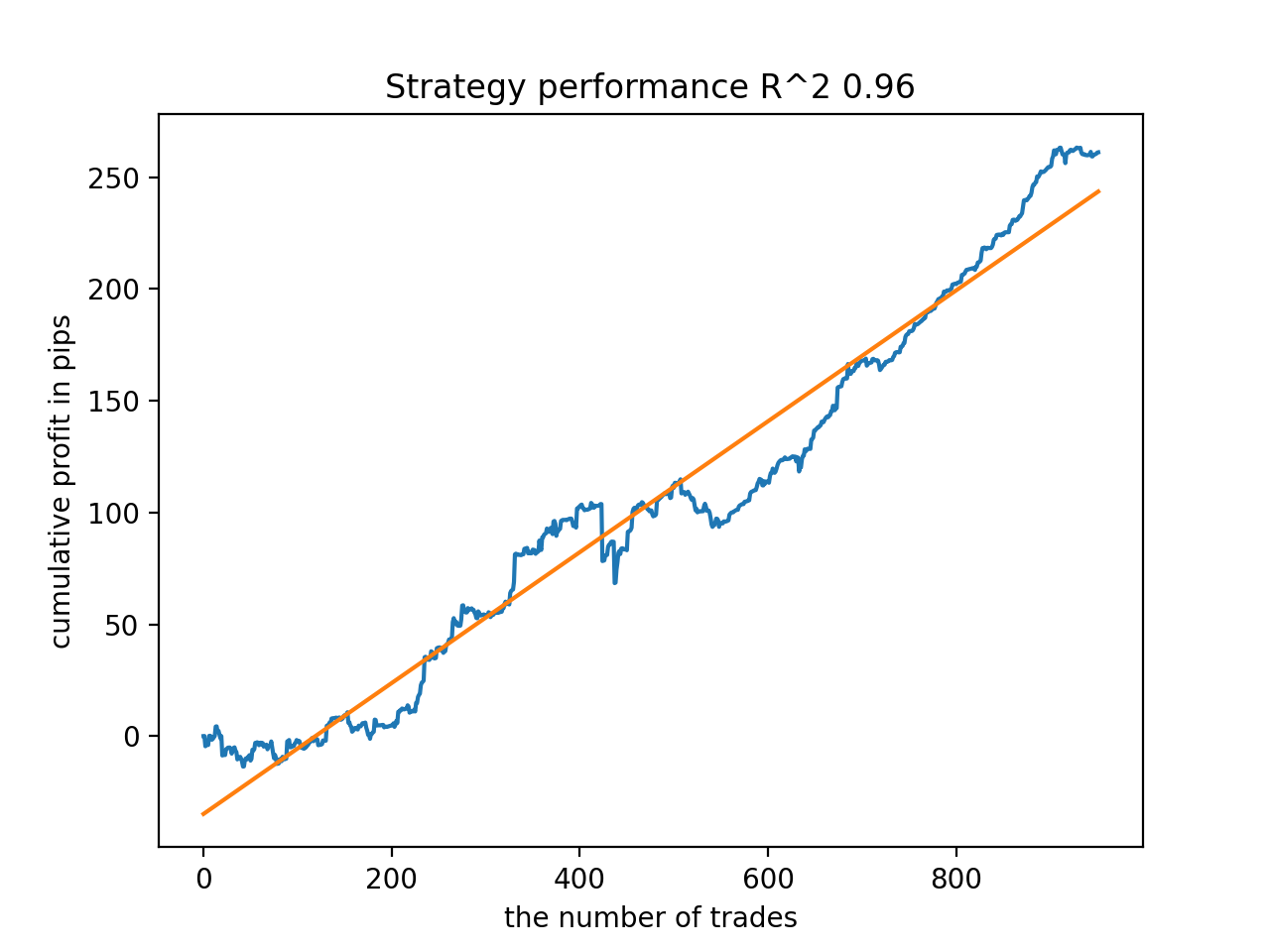
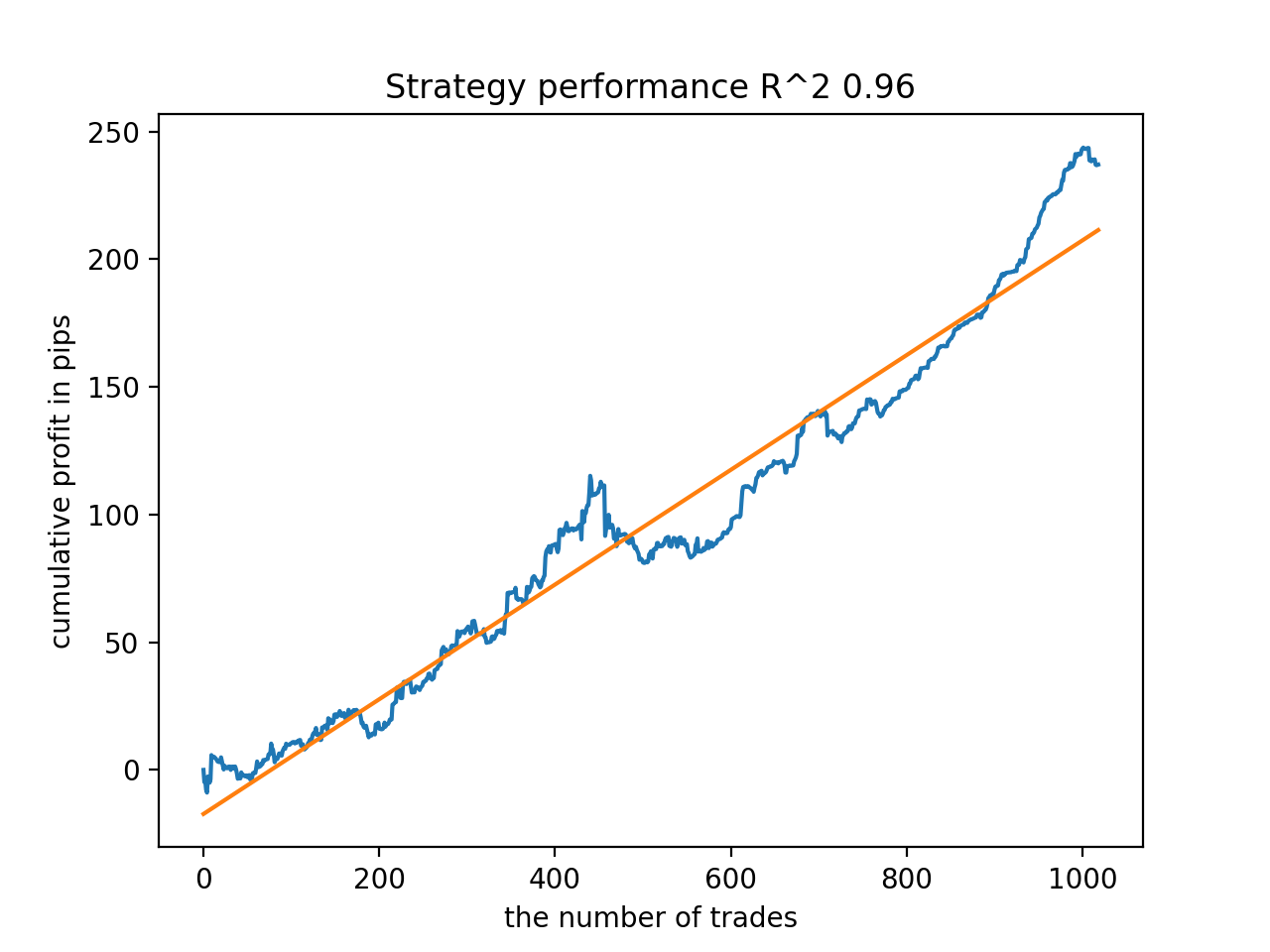
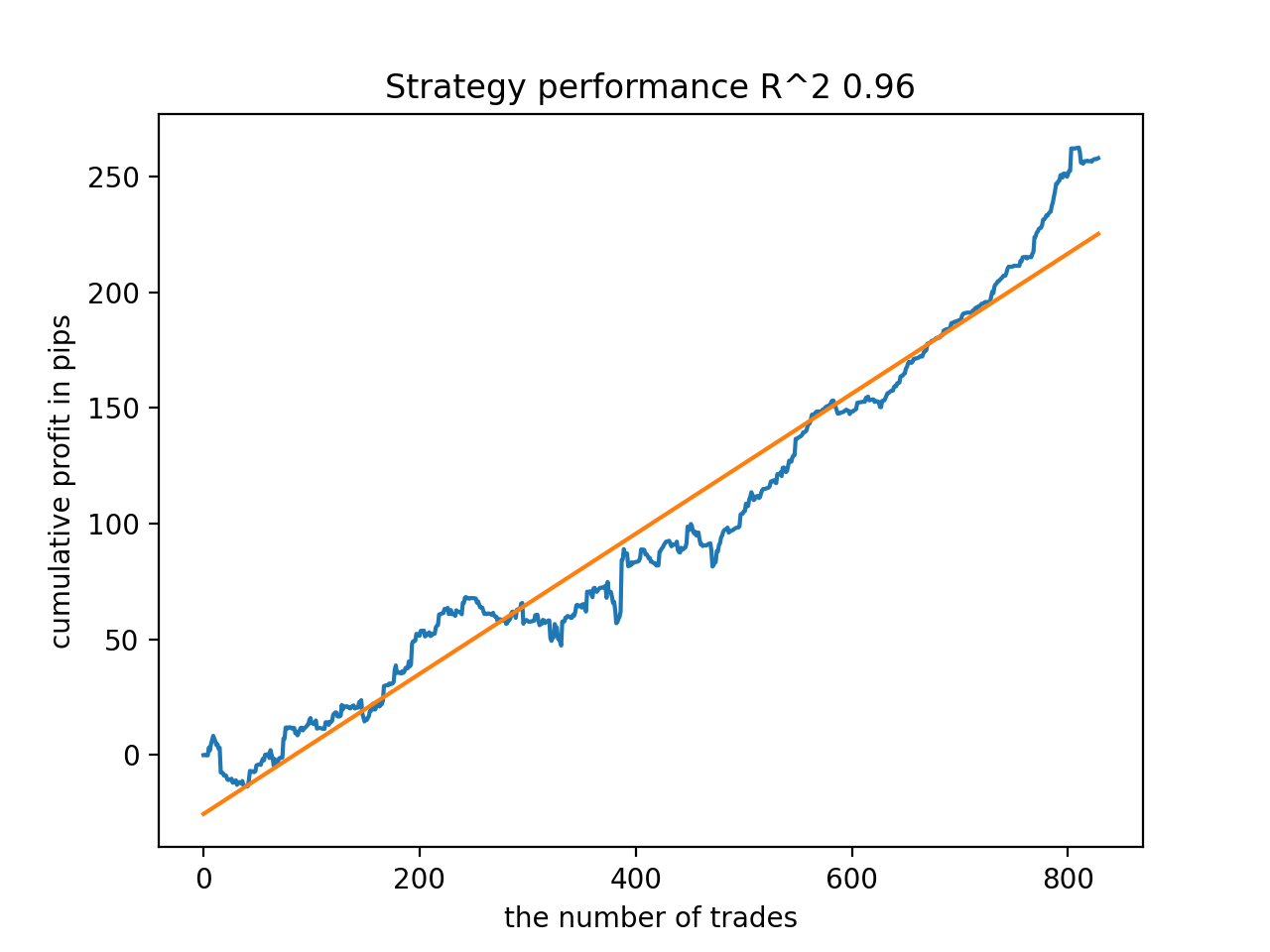
Embora os gráficos não apresentem curvas perfeitas, todos os modelos são, em geral, bastante estáveis ao longo do período desde 2010.
Como passo final, exportamos os modelos de interesse para o MetaTrader 5 com o objetivo de realizar testes adicionais ou para usar no trading. A função de exportação recebe um modelo como entrada (neste caso, o melhor do final) e um número de modelo para alterar o nome do arquivo para que vários modelos possam ser registrados ao mesmo tempo.
export_model_to_MQL_code(res[-1], str(1))
Compilamos o bot e o verificamos no testador de estratégia do MetaTrader 5.
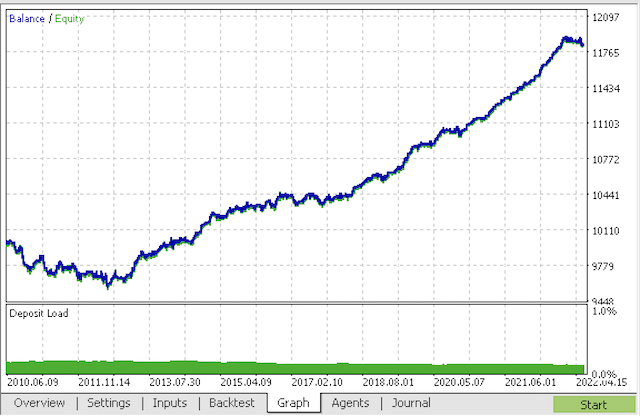
Na etapa final, você pode trabalhar com os modelos no já conhecido terminal MetaTrader 5.
Considerações finais
É provável que neste artigo tenha sido criado e apresentado o modelo de classificação de séries temporais mais complexo e sofisticado que eu já tive que implementar. Um ponto interessante disso é a capacidade de descartar automaticamente partes de histórico difíceis de classificar através de um metamodelo. Esses modelos às vezes até superam os modelos sazonais que são treinados para negociar em um horário específico do dia ou dia da semana em que há ciclos sazonais pronunciados. Aqui, a filtragem por tempo ocorre automaticamente, sem intervenção humana.
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/9138
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.
 Desenvolvendo um EA de negociação do zero (Parte 29): Plataforma falante
Desenvolvendo um EA de negociação do zero (Parte 29): Plataforma falante
 Como desenvolver um sistema de negociação baseado no indicador Acumulação/Distribuição (AD)
Como desenvolver um sistema de negociação baseado no indicador Acumulação/Distribuição (AD)
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Meu código funciona um pouco mais rápido do que o código original :) Portanto, o treinamento é ainda mais rápido. Mas eu uso GPU.
Por favor, esclareça se isso é um bug no código
A expressão correta parece ser
Caso contrário, a primeira linha simplesmente não faz sentido, porque na segunda linha a condição de cópia de dados é executada novamente, o que leva à cópia sem filtragem pelo destino "1" do metamodelo.
Estou apenas aprendendo e posso estar errado com esse python, por isso estou perguntando.....
Sim, você percebeu corretamente, seu código está correto
Também tenho uma versão mais rápida e um pouco diferente, mas queria carregá-la como um artigo em MB.Sim, você percebeu corretamente, seu código está correto.
Também tenho uma versão mais rápida e um pouco diferente, mas queria carregá-la como um artigo em MB.Escreva, será interessante.
O melhor que consegui com o treinamento.
E isso está em uma amostra separada
Adicionei o processo de inicialização por meio do treinamento.
Escreva, será interessante.
A melhor coisa sobre o treinamento que consegui obter
E isso está em uma amostra separada
Acrescentei o processo de inicialização por meio do treinamento.
Pronto, você já conhece o python
.
Eu não diria que sou um especialista - todos com um "dicionário".
Eu estava interessado em descobrir algum efeito dessa abordagem. Até agora, não percebi se há algum. Em geral, o CatBoost é treinado na amostra, sem nenhuma "mágica" - o equilíbrio está abaixo na imagem. Portanto, eu esperava um resultado mais expressivo.
Eu não diria que sou versado - tudo com um "dicionário".
Eu estava interessado em encontrar algum efeito dessa abordagem. Até agora, não percebi se há algum. Portanto, o CatBoost é treinado na amostra, em geral, sem nenhuma "mágica" - o equilíbrio está abaixo na imagem. É por isso que eu esperava um resultado mais expressivo.