Ciência de dados e Aprendizado de Máquina (parte 10): Regressão de Ridge

Introdução
A regressão de Ridge é o método de estimar os coeficientes de modelos de regressão múltipla em cenários onde as variáveis independentes são altamente
correlacionadas; O método fornece eficiência aprimorada em problemas de estimativa de parâmetros em troca de uma quantidade tolerável de viés, enquanto o Lasso (Least absolute shrinkage and selection operator) é um método de análise de regressão que executa a seleção e regularização de variáveis para melhorar a precisão da previsão e a interpretabilidade do resultado estatístico do modelo; Lasso foi originalmente formulado para os modelos de regressão linear. Este caso simples revela uma quantidade substancial sobre o estimador. Isso inclui sua relação com a regressão de ridge e a melhor seleção de subconjunto e as conexões entre as estimativas do coeficiente lasso e o chamado limite suave. Ele também revela que (como a regressão linear padrão) as estimativas de coeficiente não precisam ser únicas se as covariáveis forem colineares.
Agora, para entender por que nós precisamos de tais modelos em primeiro lugar, vamos entender o termo viés e variância.
Viés
é a incapacidade do aprendizado de máquina de capturar a verdadeira relação entre a variável independente e a variável de respostaO que isso significa para o modelo?
- Viés baixo: o modelo com viés baixo faz menos suposições sobre a forma da função de destino
- Viés alto: o modelo com viés alto faz mais suposições e pode capturar relacionamentos dentro do conjunto de dados de treinamento
Variância
A variância diz o quanto uma variável aleatória é diferente de seu valor esperado.Maneiras de reduzir o viés alto.
- Aumentar os recursos de entrada conforme o modelo está subajustado
- Diminuir o termo de regularização
- Usar recursos mais complexos, como incluir alguns recursos polinomiais
Maneiras de reduzir a alta variância.
- Reduzir os recursos de entrada; O número de parâmetros conforme o modelo é subajustado
- Não usar o modelo muito complexo
- Aumentar os dados de treinamento
- Aumentar o termo de regularização
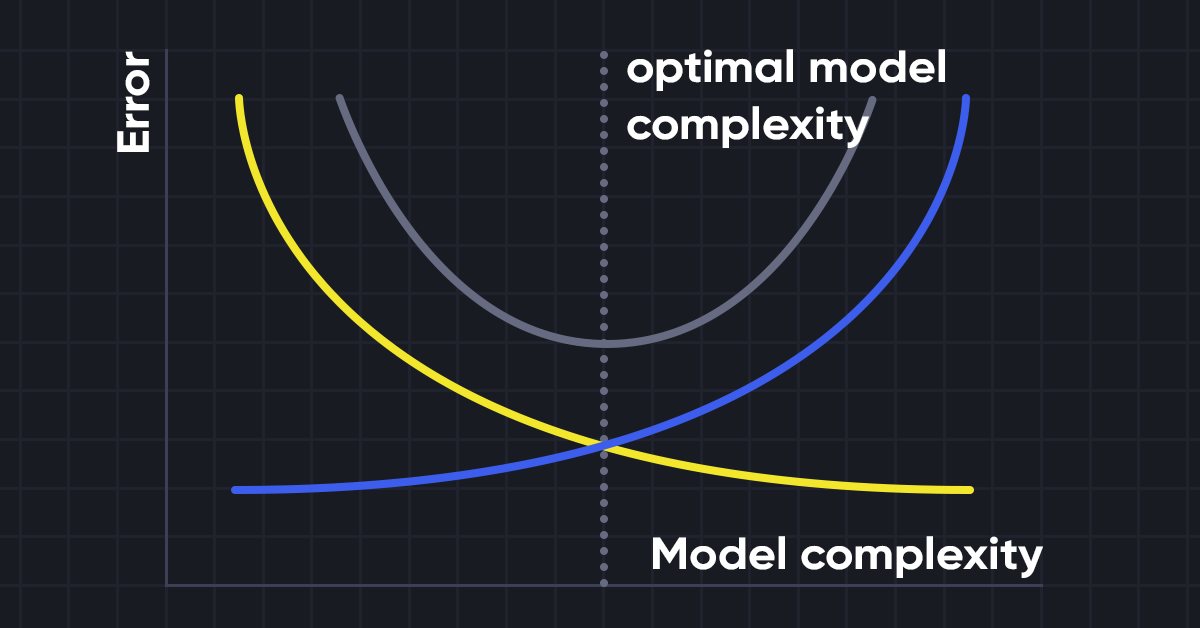
Trade-off Viés-Variância
Ao construir o modelo de aprendizado de máquina, é realmente importante cuidar do viés e da variância para evitar o ajuste excessivo do modelo. Se o modelo for muito simples e com menos parâmetros, ele tende a ter mais viés, mas pequena variância, enquanto os modelos complexos muitas vezes acabam tendo um baixo viés, mas um alto valor de variância. portanto, é necessário fazer um equilíbrio entre os erros de viés e variância. Encontrar o equilíbrio entre esses dois termos é conhecido como o tradeoff de viés-variância.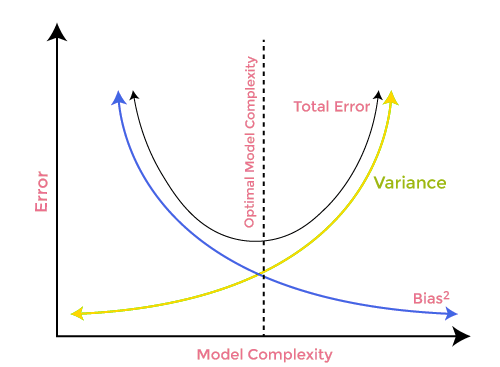
Para previsões precisas do modelo, os algoritmos também precisam de um viés e variância menores, mas isso é praticamente impossível porque o viés e a variância estão negativamente relacionados entre si.
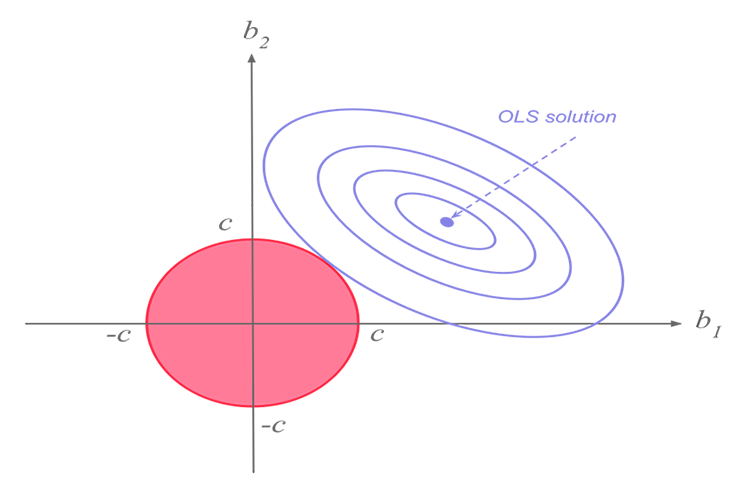
Regressão de Ridge
Regressão de Ridge e lasso estão na mesma missão, mas têm uma grande diferença, que nós veremos mais tarde, ao mergulhar na matemática e tentar descobrir o que faz cada algoritmo funcionar.A ideia por trás da regressão de ridge.
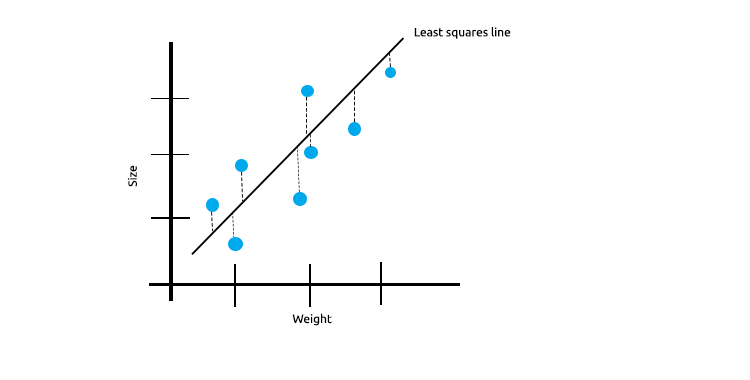
Quando temos muitas medições linearmente correlacionadas, podemos ter certeza de que os mínimos quadrados farão um bom trabalho de refletir a relação entre a variável independente e a variável objetivo.
Dê uma olhada no exemplo abaixo sobre o tamanho dos camundongos plotados em relação ao seu peso.
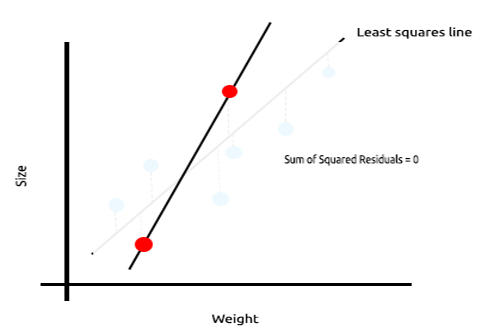
Agora vamos testar esse modelo em um novo conjunto de dados;
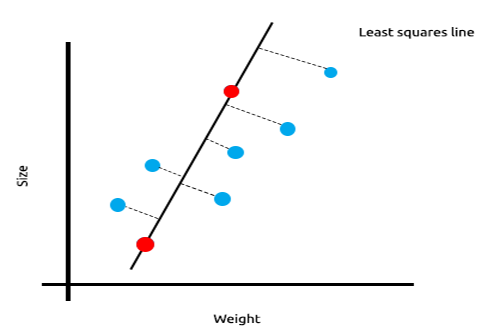
A soma dos erros quadrados para os dados de treinamento é zero, mas a soma dos resíduos quadrados para os dados de teste é grande, isso significa que o nosso modelo tem alta variância. No jargão de aprendizado de máquina, dizemos que este modelo é superajustado aos dados de treinamento.
A ideia principal por trás da regressão de ridge e lasso é encontrar o modelo que também não se ajusta aos dados de treinamento.
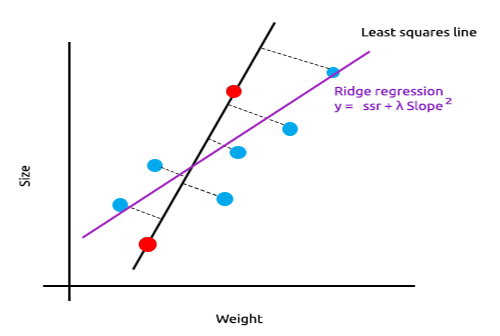
Na regressão de ridge, uma pequena quantidade de viés é introduzida na nova linha introduzindo uma pequena quantidade de viés, obtemos uma queda significativa na variância. Como a regressão de ridge introduziu uma pequena quantidade de viés, o modelo agora não se ajusta bem aos dados de treinamento e aos dados de teste nos fornecem um modelo confiável a longo prazo.
Quando usar esses modelos regularizados.
Alguém pode se perguntar se o método dos mínimos quadrados/o modelo de regressão linear pode funcionar muito bem, por que usar esses modelos L1norm e L2Norm?
Para entender isso, vamos ver como uma regressão linear multivariável funciona no conjunto de dados treinado
Para ilustrar bem o ponto que estou tentando enfatizar, eu preparei o conjunto de dados cheio de osciladores e o indicador de volume para o EURUSD;
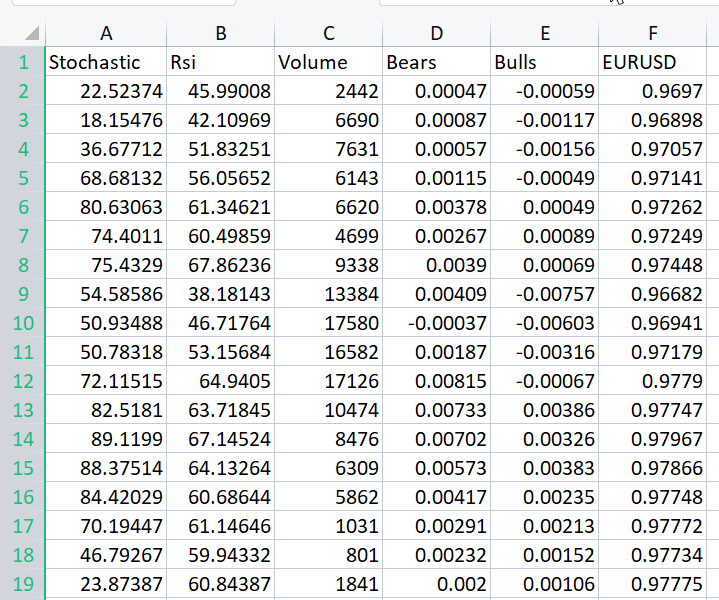
Mesmo sem olhar para a matriz de correlação, todos que estão familiarizados com esses indicadores sabem com certeza que esses indicadores não são adequados para problemas de regressão. Abaixo está a Matriz de correlação
ArrayPrint(matrix_utils.csv_header); Print(Matrix.CorrCoef(false));
Resultado:
CS 0 06:29:41.493 TestEA (EURUSD,H1) "Stochastic" "Rsi" "Volume" "Bears" "Bulls" "EURUSD" CS 0 06:29:41.493 TestEA (EURUSD,H1) [[1,0.680705511991766,0.02399740959375265,0.6910892641498844,0.7291018045506749,0.1490856367010467] CS 0 06:29:41.493 TestEA (EURUSD,H1) [0.680705511991766,1,0.07620207894739518,0.8184961346648213,0.8258569040865805,0.1567269000583347] CS 0 06:29:41.493 TestEA (EURUSD,H1) [0.02399740959375265,0.07620207894739518,1,0.3752014290536041,-0.1289026185114097,-0.1024017077869821] CS 0 06:29:41.493 TestEA (EURUSD,H1) [0.6910892641498844,0.8184961346648213,0.3752014290536041,1,0.7826404088603456,0.07283638913665436] CS 0 06:29:41.493 TestEA (EURUSD,H1) [0.7291018045506749,0.8258569040865805,-0.1289026185114097,0.7826404088603456,1,0.08392530400705019] CS 0 06:29:41.493 TestEA (EURUSD,H1) [0.1490856367010467,0.1567269000583347,-0.1024017077869821,0.07283638913665436,0.08392530400705019,1]]Como você pode ver, as correlações são inferiores a 20% para a coluna EURUSD em relação a todos os indicadores. O indicador estocástico e o RSI parecem estar melhor correlacionados do que os outros, mas apenas para cerca de 14 e 15 porcento, respectivamente. Vamos criar um modelo de regressão linear começando com o indicador estocástico e só depois vamos adicionando as variáveis independentes/outras leituras dos indicadores.
Tabela de Resultados:
| Variáveis independentes | R2 Score(Precisão) |
|---|---|
| Estocástico | 1.2 % |
| Estocástico e RSI | 1.8 % |
| Estocástico, RSI e Volume | 2.8 % |
| Estocástico, RSI, Volume, Bears Power e Bulls Power (Todas as variáveis independentes) | 4.9% |
Então, que conclusão você pode tirar desta tabela; À medida que você aumenta o número de variáveis independentes, a precisão do modelo linear treinado sempre aumenta, independentemente de quais sejam essas variáveis. uma nova variável independente é adicionada, mas pode não ser o caso quando as variáveis são correlacionadas por cerca de 30% para 40% cada um, você pode testemunhar seu modelo chegar a uma precisão de 90% na fase de treinamento, quando você fornece muitas dessas variáveis independentes.
O aumento das variáveis independentes aumenta a variância, não há dúvida de que este modelo terá um desempenho pior no novo conjunto de dados, pois está superajustado. obter uma queda significativa na variância.
Teoria da Regressão de Ridge
A própria regressão de Ridge é um método de estimar os coeficientes de um modelo de regressão linear quando as variáveis independentes são altamente correlacionadas.
A regressão de Ridge foi desenvolvida como uma possível solução para a imprecisão dos estimadores de mínimos quadrados quando os modelos de regressão linear têm alguns multicolineares (altamente correlacionados) -- criando um estimador de regressão de ridge (RR). Isso fornece os parâmetros de um cume mais preciso, pois sua variância e viés geralmente são menores do que os estimadores dos mínimos quadrados.
Estimador de cume
Análogo ao estimador de mínimos quadrados ordinário, o estimador de ridge simples é dado por
onde y é a matriz de variáveis independentes,x é a matriz do modleo, I é a matriz identidade e o parâmetro de ridge λ é o valor maior ou igual a zero.
Vamos escrever o código para isso:
CRidgeregression::CRidgeregression(matrix &_matrix) { n = _matrix.Rows(); k = _matrix.Cols(); pre_processing.Standardization(_matrix); m_dataset.Copy(_matrix); matrix_utils.XandYSplitMatrices(_matrix,XMatrix,yVector); YMatrix = matrix_utils.VectorToMatrix(yVector); //--- Id_matrix.Resize(k,k); Id_matrix.Identity(); }
No construtor da função, três coisas importantes são feitas. Primeiro, é padronizar os dados. Assim como a gradiente descendente multivariável e muitas outras técnicas de aprendizado de máquina, a regressão de ridge funciona no conjunto de dados padronizado. Em segundo lugar, os dados são divididos em matrizes x e y e, por último, a matriz de identidade é criada.
Dentro da função L2Norm:
vector CRidgeregression::L2Norm(double lambda) { matrix design = matrix_utils.DesignMatrix(XMatrix); matrix XT = design.Transpose(); matrix XTX = XT.MatMul(design); matrix lamdaxI = lambda * Id_matrix; //Print("LambdaxI \n",lamdaxI); //Print("XTX\n",XTX); matrix sum_matrix = XTX + lamdaxI; matrix Inverse_sum = sum_matrix.Inv(); matrix XTy = XT.MatMul(YMatrix); Betas = Inverse_sum.MatMul(XTy); #ifdef DEBUG_MODE Print("Betas\n",Betas); #endif return(matrix_utils.MatrixToVector(Betas)); }
Esta função faz tudo conforme instruído pela fórmula acima que acabamos de ver para encontrar os coeficientes usando a regressão de Ridge.
Para ver como isso funciona, vamos usar outro conjunto de dados, a NASDAQ_DATA.csv que o leitor desta série de artigos já conhece.
int OnInit() { //--- matrix Matrix = matrix_utils.ReadCsv("NASDAQ_DATA.csv",","); pre_processing.Standardization(Matrix); Linear_reg = new CLinearRegression(Matrix); ridge_reg = new CRidgeregression(Matrix); ridge_reg.L2Norm(0.3); }
Eu defini o valor de penalidade aleatória para 0.3 para a regressão do cume apenas para que nós possamos ver o que sai disso. Agora é hora de executar a função e ver quais coeficientes saem disso;
CS 0 10:27:41.338 TestEA (EURUSD,H1) [[5.015577002384403e-16]
CS 0 10:27:41.338 TestEA (EURUSD,H1) [0.6013523727380532]
CS 0 10:27:41.338 TestEA (EURUSD,H1) [0.3381524618200134]
CS 0 10:27:41.338 TestEA (EURUSD,H1) [0.2119467984461254]]
Vamos também executar o modelo de regressão linear para o mesmo conjunto de dados e observar seus coeficientes também. Como o método dos mínimos quadrados não padroniza o conjunto de dados, vamos padronizá-lo também antes de fornecer os dados ao modelo.
matrix Matrix = matrix_utils.ReadCsv("NASDAQ_DATA.csv",","); pre_processing.Standardization(Matrix); Linear_reg = new CLinearRegression(Matrix);
Saída:
CS 0 10:27:41.338 TestEA (EURUSD,H1) Betas
CS 0 10:27:41.338 TestEA (EURUSD,H1) [[-4.143037461930866e-14]
CS 0 10:27:41.338 TestEA (EURUSD,H1) [0.6034777119810752]
CS 0 10:27:41.338 TestEA (EURUSD,H1) [0.3363532376334173]
CS 0 10:27:41.338 TestEA (EURUSD,H1) [0.21126507562567]]
Os coeficientes parecem um pouco diferentes, então acho que a nossa função funciona. Vamos treinar e testar cada um dos modelos e, finalmente, plotar os seus respectivos gráficos para entender mais.
Como a própria regressão de ridge não é um modelo, é um estimador para os coeficientes que precisam ser usados com o modelo de regressão linear, fiz algumas alterações na classe de regressão linear que discutimos na parte 3.
No construtor de classe da regressão linear é onde o modelo é treinado. Ele é uma área onde os coeficientes são armazenados para serem usados pelo restante das funções, eu adicionei um novo construtor que permite passar os coeficientes para o modelo, isso nos ajudará a fazer o esforço mínimo na próxima vez que usarmos outros estimadores para obter os coeficientes que queremos que o nosso modelo de regressão use.
class CLinearRegression { public: CLinearRegression(matrix &Matrix_); //Least squares estimator CLinearRegression(matrix<double> &Matrix_, double Lr, uint iters = 1000); //Lr by Gradient descent CLinearRegression(matrix &Matrix_, vector &coeff_vector); ~CLinearRegression(void);
Ridge vs Regressão Linear
Print("----> Ridge regression"); ridge_reg = new CRidgeregression(Matrix); vector coeff = ridge_reg.L2Norm(0.3); Linear_reg = new CLinearRegression(Matrix,coeff); //passing the coefficients made by ridge regression // to the Linear regression model double acc =0; vector ridge_predictions = Linear_reg.LRModelPred(Matrix,acc); //making the predictions and storing them to a vector delete(Linear_reg); //deleting that instance Print("----> Linear Regression"); pre_processing.Standardization(Matrix); Linear_reg = new CLinearRegression(Matrix); //new Linear reg instance that gets coefficients by least squares vector linear_pred = Linear_reg.LRModelPred(Matrix,acc);
Saídas:
CS 0 11:35:52.153 TestEA (EURUSD,H1) ----> Ridge regression
CS 0 11:35:52.153 TestEA (EURUSD,H1) Betas
CS 0 11:35:52.153 TestEA (EURUSD,H1) [[-4.142058558619502e-14]
CS 0 11:35:52.153 TestEA (EURUSD,H1) [0.601352372738047]
CS 0 11:35:52.153 TestEA (EURUSD,H1) [0.3381524618200102]
CS 0 11:35:52.153 TestEA (EURUSD,H1) [0.2119467984461223]]
CS 0 11:35:52.154 TestEA (EURUSD,H1) R squared 0.982949 Adjusted R 0.982926
CS 0 11:35:52.154 TestEA (EURUSD,H1) ----> Linear Regression
CS 0 11:35:52.154 TestEA (EURUSD,H1) Betas
CS 0 11:35:52.154 TestEA (EURUSD,H1) [[5.014846059117108e-16]
CS 0 11:35:52.154 TestEA (EURUSD,H1) [0.6034777119810601]
CS 0 11:35:52.154 TestEA (EURUSD,H1) [0.3363532376334217]
CS 0 11:35:52.154 TestEA (EURUSD,H1) [0.2112650756256718]]
CS 0 11:35:52.154 TestEA (EURUSD,H1) R squared 0.982933 Adjusted R 0.982910
Os modelos têm um desempenho ligeiramente diferente quando você usa todos os dados como dados de treinamento.
Quando as saídas foram armazenadas e plotadas no mesmo eixo, este é o gráfico delas;

Eu quase não consigo ver nenhuma diferença entre o modelo Linear e o preditor marcado em azul, só consigo ver a diferença entre os dois modelos e a regressão de crista não se ajusta bem ao conjunto de dados, isso é uma boa notícia. Vamos treinar e testar ambos os modelos um por um.
matrix_utils.TrainTestSplitMatrices(Matrix,TrainMatrix,TestMatrix); Print("----> Ridge regression | Train "); ridge_reg = new CRidgeregression(TrainMatrix); vector coeff = ridge_reg.L2Norm(0.3); Linear_reg = new CLinearRegression(TrainMatrix,coeff); //passing the coefficients made by ridge regression // to the Linear regression model Linear_reg.LRModelPred(TrainMatrix,acc); printf("Accuracy %.5f ",acc); Print("----> Ridge regression | Test"); vector ridge_predictions = Linear_reg.LRModelPred(TestMatrix,acc); //making the predictions and storing them to a vector printf("Accuracy %.5f ",acc); delete(Linear_reg); //deleting that instance Print("\n----> Linear Regression | Train "); Linear_reg = new CLinearRegression(TrainMatrix); //new Linear reg instance that gets coefficients by least squares Linear_reg.LRModelPred(TrainMatrix,acc); printf("Accuracy %.5f ",acc); Print("----> Linear Regression | Test "); vector linear_pred = Linear_reg.LRModelPred(TestMatrix,acc); printf("Accuracy %.5f ",acc);
Saída:
CS 0 13:27:40.744 TestEA (EURUSD,H1) ----> Ridge regression | Train
CS 0 13:27:40.744 TestEA (EURUSD,H1) Accuracy 0.97580
CS 0 13:27:40.744 TestEA (EURUSD,H1) ----> Ridge regression | Test
CS 0 13:27:40.744 TestEA (EURUSD,H1) Accuracy 0.78620
CS 0 13:27:40.744 TestEA (EURUSD,H1)
CS 0 13:27:40.744 TestEA (EURUSD,H1) ----> Linear Regression | Train
CS 0 13:27:40.744 TestEA (EURUSD,H1) Accuracy 0.97580
CS 0 13:27:40.744 TestEA (EURUSD,H1) ----> Linear Regression | Test
CS 0 13:27:40.744 TestEA (EURUSD,H1) Accuracy 0.78540
Parece que ambos os modelos tiveram aproximadamente a mesma precisão no treinamento, mas uma pequena diferença no conjunto de dados de teste, nada mal, considerando a penalidade que a regressão de ridge usa para punir as variáveis independentes, 0.3 é pequeno e ainda estamos para descobrir como escolher uma penalidade certa.
Quando eu defino o valor de lambda para 10, a precisão do treinamento de regressão de ridge caiu para 0.95760 de 0.97580 enquanto a precisão do teste aumentou de 0.78540 para 0.80050, um pequeno aumento, é claro.
Escolhendo o valor da penalidade correta (lambda)
Para encontrar os valores corretos do lambda, precisamos usar a técnica LEAVE ONE OUT CROSS VALIDATION (LOOCV), para quem não está familiarizado, esta é a técnica para encontrar os parâmetros ótimos de alguns dos modelos em ML de maneira que isso é alcançado passando por todo o conjunto de dados deixando uma amostra fora do conjunto de dados. Então treinamos o modelo com o restante do conjunto de dados que é n-1, depois usa a única amostra que foi deixada de fora como amostra de teste, ele percorre todo o conjunto de dados até a enésima amostra, finalmente ele mede a perda para todos os valores em cada iteração e finalmente encontra onde estava a função de perda mínima em valores específicos de lambda, aquele que produz menos erro, ele é o melhor parâmetro, para mais informações leia.
Vamos importar a classe de validação cruzada para nos ajudar a encontrar o valor ideal do lambda.
#include <MALE5\cross_validation.mqh>
CCrossValidation *cross_validation; Abaixo está o código para LOOCV para a regressão de Ridge;
double CCrossValidation::LeaveOneOut(double init, double step, double finale) { matrix XMatrix; vector yVector; matrix_utils.XandYSplitMatrices(Matrix,XMatrix,yVector); matrix train = Matrix; vector test = {}; int size = int(finale/step); vector validation_output(ulong(size)); vector lambda_vector(ulong(size)); vector forecast(n); vector actual = yVector; double lambda = init; for (int i=0; i<size; i++) { lambda += step; for (ulong j=0; j<n; j++) { train.Copy(Matrix); ZeroMemory(test); test = XMatrix.Row(j); matrix_utils.MatrixRemoveRow(train,j); vector coeff = {}; double acc =0; switch(selected_model) { case RIDGE_REGRESSION: ridge_regression = new CRidgeregression(train); coeff = ridge_regression.L2Norm(lambda); //ridge regression Linear_reg = new CLinearRegression(train,coeff); forecast[j] = Linear_reg.LRModelPred(test); //--- delete (Linear_reg); delete (ridge_regression); break; } } validation_output[i] = forecast.Loss(actual,LOSS_MSE)/double(n); lambda_vector[i] = lambda; #ifdef DEBUG_MODE printf("%.5f LOOCV mse %.5f",lambda_vector[i],validation_output[i]); #endif } //--- #ifdef DEBUG_MODE matrix store_matrix(size,2); store_matrix.Col(validation_output,0); store_matrix.Col(lambda_vector,1); string name = EnumToString(selected_model)+"\\LOOCV.csv"; string header[2] = {"Validation output","lambda"}; matrix_utils.WriteCsv(name,store_matrix,header); #endif return(lambda_vector[validation_output.ArgMin()]); }
Vamos colocar isso em ação;
int OnInit() { matrix Matrix = matrix_utils.ReadCsv("NASDAQ_DATA.csv",","); ridge_reg = new CRidgeregression(Matrix); cross_validation = new CCrossValidation(Matrix,RIDGE_REGRESSION); double best_lambda = cross_validation.LeaveOneOut(0,1,10); Print("Best lambda ",best_lambda);
Saída:
CS 0 10:12:51.346 ridge_test (EURUSD,H1) 1.00000 LOOCV mse 0.00020 CS 0 10:12:51.465 ridge_test (EURUSD,H1) 2.00000 LOOCV mse 0.00020 CS 0 10:12:51.576 ridge_test (EURUSD,H1) 3.00000 LOOCV mse 0.00020 CS 0 10:12:51.684 ridge_test (EURUSD,H1) 4.00000 LOOCV mse 0.00020 CS 0 10:12:51.788 ridge_test (EURUSD,H1) 5.00000 LOOCV mse 0.00020 CS 0 10:12:51.888 ridge_test (EURUSD,H1) 6.00000 LOOCV mse 0.00020 CS 0 10:12:51.987 ridge_test (EURUSD,H1) 7.00000 LOOCV mse 0.00021 CS 0 10:12:52.090 ridge_test (EURUSD,H1) 8.00000 LOOCV mse 0.00021 CS 0 10:12:52.201 ridge_test (EURUSD,H1) 9.00000 LOOCV mse 0.00021 CS 0 10:12:52.317 ridge_test (EURUSD,H1) 10.00000 LOOCV mse 0.00021 CS 0 10:12:52.319 ridge_test (EURUSD,H1) Best lambda 1.0
Supondo que não haja bugs no código, o melhor valor de lambda é aquele quando a busca for de 1 a 10. Isso nos diz que o valor de lambda para este modelo é um pouco menor, então eu decidi executar o loop de 0 a 10, o tamanho do passo foi definido como 0.01 (total de 1000 iterações), demorou cerca de 5 minutos para ser concluído, mas eu estava capaz de obter o valor de 0.09 como o melhor valor de lambda, abaixo está o gráfico;

Legal, agora está tudo bem na parte de regressão de ridge.
Vantagens da Regressão de Ridge
- vamos ver alguns benefícios de usar um estimador de regressão de ridge
- Ele protege o modelo de overfitting
- A complexidade do modelo é reduzida
- ele funciona bem quanto a regressão linear no conjunto de dados multivariável
- não precisa de estimadores imparciais
Desvantagens da regressão de ridge
- inclui todos os preditores no modelo final
- Não é capaz de realizar a seleção de recursos
- Reduz os coeficientes para zero
- ele troca a variância por viés
Pensamentos finais
A regressão de ridge pode ajudar a evitar o overfitting (superajuste) do modelo de regressão nos casos em que existem multivariáveis, mas ainda é crucial evitar/remover variáveis indesejadas manualmente do modelo, no NASDAQ_DATA poderíamos ter removido a coluna RSI porque todos nós provavelmente sabemos que ele não está correlacionado com a nossa variável de objetivo. É isso, neste artigo, há tantas coisas acontecendo que eu não posso abordar por enquanto.
Continue acompanhando o desenvolvimento da regressão de ridge no meu repositório do GitHub >https://github.com/MegaJoctan/MALE5
| Nome do arquivo | Descrição |
|---|---|
| cross_validation.mqh | Assim como a validação cruzada do sklearn, Este arquivo contém técnicas de validação, como LOOCV |
| Linear regression.mqh | Este arquivo contém o método dos mínimos quadrados/ O modelo da Regressão linear |
| matrix_utils.mqh | Esta função de classe utilitária contém as funções extras de operações de matriz |
| Preprocessing.mqh | Assim como o sklearn.preprocessing, Esta classe contém funções que podem ser usadas para manipular e redimensionar os conjuntos de dados |
| Ridge Regression.mqh | Este arquivo contém o modelo de regressão ridge e suas funções relevantes |
| ridge_test.mq5 | Este é um script usado para testar tudo o que discutimos neste artigo |
| prepare_dataset.mq5 | Este script cria um conjunto de dados para os indicadores dos osciladores que discutimos anteriormente. Esses dados serão armazenados em um arquivo Oscillators.csv |
| NASDAQ_DATA.csv | Este arquivo em csv contém o conjunto de dados que usamos neste artigo |
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/11735
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Como desenvolver um sistema de negociação baseado no indicador Gator Oscillator
Como desenvolver um sistema de negociação baseado no indicador Gator Oscillator
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso