
Floresta de Decisão Aleatória na Aprendizagem por Reforço
A descrição abstrata do algoritmo Floresta Aleatória
Floresta Aleatória (RF) com o uso de bagging é um dos mais poderosos métodos de aprendizado de máquina, que é um pouco inferior ao gradient boosting.
A Floresta Aleatória consiste em um bagging de Árvores de Decisão (também conhecidas como árvores de classificação ou árvores de regressão "CART" para resolver tarefas com o mesmo nome). Eles são usados em estatística, mineração de dados e aprendizado de máquina. Cada árvore individual é um modelo bastante simples que possui ramificações, nós e folhas. Os nós contêm os atributos dos quais a função objetivo é dependente. Então os valores da função objetivo vão para as folhas através dos ramos. No processo de classificação de um novo caso, é necessário descer a árvore através de seus ramos até uma folha, passando por todos os valores dos atributos de acordo com o princípio lógico "IF-THEN". Dependendo dessas condições, a variável objetiva receberá um valor específico ou uma classe (a variável objetiva cairá em uma folha específica). O propósito de construir uma árvore de decisão é criar um modelo que prevê o valor da variável objetiva, dependendo de diversas variáveis de entrada.
Uma floresta aleatória é construída por um simples voto de árvores de decisão usando o algoritmo Bagging. Bagging é uma palavra artificial formada a partir da combinação de palavras, também conhecido como bootstrap aggregating. Este termo foi introduzido por Leo Breiman em 1994.
Em estatística, o bootstrap é um método de geração de amostras em que o número de objetos escolhidos é o mesmo que o número inicial de objetos. Mas esses objetos são escolhidos com substituições. Em outras palavras, o objeto escolhido aleatoriamente é retornado e pode ser escolhido novamente. Nesse caso, o número de objetos escolhidos compreenderá aproximadamente 63% da amostra de origem e o restante dos objetos (aproximadamente 37%) nunca será incluído na amostra de treinamento. Esta amostra gerada é usada para treinar os algoritmos básicos (neste caso, as árvores de decisão). Isso também acontecer aleatoriamente: subconjuntos aleatórios (amostras) de um determinado tamanho são treinados no subconjunto aleatório de características selecionadas (atributos). Os 37% restantes da amostra são usados para testar a capacidade de generalização do modelo construído.
Depois disso, todas as árvores treinadas são combinadas em uma composição com uma votação simples, usando o erro médio de todas as amostras. O uso de bootstrap aggregating reduz o erro quadrático médio e diminui a variância do classificador treinado. O erro não será muito diferente em diferentes amostras. Como resultado, o modelo sofrerá menos overfitting, de acordo com os autores. A eficácia do bagging reside no fato de que os algoritmos básicos (árvores de decisão) são treinados em várias amostras aleatórias e seus resultados podem variar muito, enquanto que seus erros são mutuamente compensados na votação.
Pode-se dizer que uma Floresta Aleatória é um caso especial de bagging, onde as árvores de decisão são usadas como a família base. Ao mesmo tempo, ao contrário do método convencional de construção de árvores de decisão, o método de poda (pruning) não é utilizado. O método destina-se a construir uma composição a partir de grandes amostras de dados o mais rápido possível. Cada árvore é construída de uma maneira específica. Uma característica (atributo) para a construção de um nó da árvore não é selecionada a partir do número total de características, mas de seu subconjunto aleatório. Ao construir um modelo de regressão, o número de características é n/3. No caso de classificação, ele é √n. Todas estas são recomendações empíricas e são chamadas de decorrelação: diferentes conjuntos de características caem em diferentes árvores, e as árvores são treinadas em diferentes amostras.
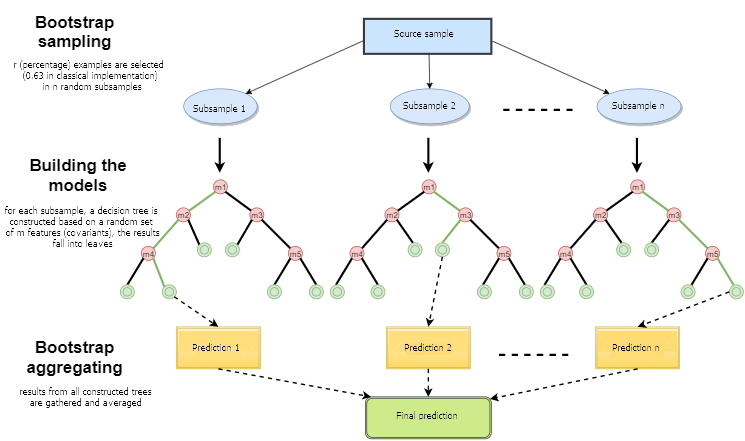
Fig. 1. Esquema operacional da Floresta Aleatória
O algoritmo da Floresta Aleatória mostrou-se extremamente eficaz, capaz de resolver problemas práticos. Ele fornece um treinamento de alta qualidade com um número aparentemente grande de aleatoriedade, introduzido no processo de construção do modelo. A vantagem sobre outros modelos de aprendizado de máquina é a estimativa fora da amostra para a parte do conjunto que não está incluída na amostra de treinamento. Portanto, o cross-validation ou o teste em uma única amostra não são necessários para as árvores de decisão. Basta nos limitarmos à estimativa fora da amostra para posteriores "ajustes" do modelo: selecionar o número de árvores de decisão e o componente de regularização.
A biblioteca ALGLIB, incluída no pacote padrão da МetaТrader 5, contém o algoritmo RDF (Random Decision Forest - Floresta de Decisão Aleatória). Ela é uma modificação do algoritmo Floresta Aleatória original proposto por Leo Breiman e Adele Cutler. Este algoritmo combina duas ideias: usando um bag de árvores de decisão que obtém o resultado pelo voto e a ideia de randomizar o processo de aprendizagem. Mais detalhes sobre as modificações do algoritmo podem ser encontradas no site da ALGLIB.
Vantagens do algoritmo
- Alta velocidade de aprendizagem
- Aprendizado não iterativo — o algoritmo é concluído em um número fixo de operações
- Escalabilidade (capacidade de lidar com grandes quantidades de dados)
- Alta qualidade dos modelos obtidos (comparável com as redes neurais e os ensembles de redes neurais)
- Sem sensibilidade aos picos nos dados devido a amostragem aleatória
- Um pequeno número de parâmetros configuráveis
- Sem sensibilidade ao dimensionamento dos valores das características (e a qualquer transformação monótona em geral) devido à seleção de subespaços aleatórios
- Não requer uma configuração cuidadosa dos parâmetros, funciona bem fora da caixa. O "ajuste" dos parâmetros permite um aumento na precisão de 0,5% a 3%, dependendo da tarefa e dos dados.
- Funciona bem com dados ausentes — mantém uma boa precisão, mesmo que uma grande parte dos dados esteja ausente.
- Avaliação interna da capacidade de generalização do modelo.
- A capacidade de trabalhar com dados brutos, sem pré-processamento.
Desvantagens do algoritmo
- O modelo construído ocupa uma grande quantidade de memória. Se um bag é construído a partir de K árvores com base em um conjunto de treinamento de tamanho N, então os requisitos de memória são O(K·N). Por exemplo, para K=100 e N=1000, o modelo construído pela ALGLIB leva cerca de 1 MB de memória. No entanto, como a quantidade de RAM nos computadores modernos é grande o suficiente, por isso não é um grande defeito.
- Um modelo treinado funciona um pouco mais lento do que outros algoritmos (se houver 100 árvores em um modelo, é necessário iterar sobre todos eles para obter o resultado). Em máquinas modernas, no entanto, isso não é tão perceptível.
- O algoritmo funciona pior do que a maioria dos métodos lineares quando um conjunto tem muitas características esparsas (textos, Bag de palavras) ou quando os objetos a serem classificados podem ser separados linearmente.
- O algoritmo é propenso a overfitting, especialmente em tarefas com muito ruído. Parte deste problema pode ser resolvido ajustando o parâmetro r. Um problema similar, mas mais pronunciado também existe no algoritmo Floresta Aleatória original. No entanto, os autores afirmaram que o algoritmo não é suscetível a overfitting. Essa falácia é compartilhada por alguns praticantes e teóricos de aprendizado de máquina.
- Para dados que incluem variáveis categóricas com um número diferente de níveis, as florestas aleatórias são inclinadas em favor de características com mais níveis. Uma árvore será mais fortemente ajustada a tais características, pois elas permitem receber um valor maior de funcionalidade otimizada (tipo de ganho de informação).
- Semelhante às árvores de decisão, o algoritmo é absolutamente incapaz de extrapolação (mas isso pode ser considerado uma vantagem, já que não haverá valores extremos no caso de um pico)
Peculiaridades do uso de aprendizado de máquina na negociação
Entre os neófitos do aprendizado de máquina, há uma crença popular de que é algum tipo de mundo de conto de fadas, onde os programas fazem de tudo para o trader, enquanto ele simplesmente desfruta do lucro recebido. Isso é apenas parcialmente verdade. O resultado final dependerá do quão bem os problemas descritos abaixo são resolvidos.
- Seleção de características
O primeiro e principal problema é a escolha do que exatamente o modelo precisa ser ensinado. O preço é afetado por muitos fatores. Existe apenas uma abordagem científica para estudar o mercado — Econometria. Existem três métodos principais: análise de regressão, análise de séries temporais e análise de painel. Uma seção interessante separada neste campo é a econometria não paramétrica, que é baseada somente nos dados disponíveis, sem uma análise das causas que os formam. Métodos de econometria não paramétrica tornaram-se recentemente populares na pesquisa aplicada: por exemplo, estes incluem métodos de kernel e redes neurais. A mesma seção inclui a análise matemática de conceitos não numéricos — por exemplo, conjuntos fuzzy. Se você pretende levar a sério o aprendizado de máquina, uma introdução aos métodos econométricos será útil. Este artigo se concentrará nos conjuntos difusos.
- Seleção do modelo
O segundo problema é a escolha do modelo de treinamento. Existem muitos modelos lineares e não lineares. Sua lista e comparação de características podem ser encontradas no Site da Microsoft, por exemplo.
Por exemplo, existe uma enorme variedade de redes neurais. Ao usá-los, você precisa experimentar a arquitetura de rede, selecionando o número de camadas e neurônios. Ao mesmo tempo, as redes neurais clássicas do tipo MLP são treinadas lentamente (especialmente com o método gradiente descendente com um passo fixo), os experimentos com elas levam muito tempo. Redes Modernas de Deep Learning de aprendizagem rápida estão atualmente indisponíveis na biblioteca padrão do terminal e incluir bibliotecas de terceiros no formato DLL não é muito conveniente. Eu ainda não estudei o suficiente esses pacotes.
Ao contrário das redes neurais, modelos lineares trabalham rápido, mas nem sempre manipulam bem uma aproximação.
A Floresta Aleatória não tem essas desvantagens. Só é necessário selecionar o número de árvores e o parâmetro r responsável pela porcentagem de objetos que se enquadram na amostra de treinamento. Experimentos no Microsoft Azure Machine Learning Studio mostraram que as florestas aleatórias apresentam o menor erro de previsão nos dados de teste na maioria dos casos.
- Modelo de teste
Em geral, há apenas uma recomendação rigorosa: quanto maior a amostra de treinamento e mais informativas as características, mais estável o sistema deve estar nos novos dados. Mas, ao resolver as tarefas de negociação, pode ocorrer um caso de capacidade insuficiente do sistema, quando as variações mútuas dos preditores são muito pequenas e não são informativas. Como resultado, o mesmo sinal dos preditores gerará sinais de compra e venda. O modelo de saída terá uma baixa capacidade de generalização e, consequentemente, uma baixa qualidade de sinais no futuro. Além disso, o treinamento em uma amostra grande será lenta, impossibilitando várias execuções durante a otimização. Com tudo isso, não haverá garantia de um resultado positivo. Acrescente a esses problemas a natureza caótica das cotações, com sua não estacionariedade, mudando constantemente os padrões de mercado ou (pior) com sua completa ausência.
Selecionando o método de treinamento do modelo
A Floresta Aleatória é usada para resolver uma ampla gama de problemas de regressão, classificação e agrupamento.
Esses métodos podem ser representados da seguinte maneira.
- Aprendizado não supervisionado. Agrupamento, detecção de anomalias. Esses métodos são aplicados para dividir as características programaticamente em grupos com diferenças distintas determinadas automaticamente.
- Aprendizado supervisionado. Classificação e regressão. Um conjunto de exemplos de treinamento conhecidos anteriormente (rótulos) é alimentado como entrada e a Floresta Aleatória tenta aprender (aproximar) todos os casos.
- Aprendizagem por reforço. Este é talvez o tipo mais incomum e promissor de aprendizado de máquina, que se destaca do resto. Aqui, o aprendizado ocorre quando o agente virtual interage com o ambiente, enquanto o agente tenta maximizar as recompensas recebidas pelas ações nesse ambiente. Vamos usar essa abordagem.
Aprendizado de reforço nas tarefas de desenvolvimento do Sistema de Negociação
Imagine criar um trader com inteligência artificial. Ele irá interagir com o ambiente e receber uma certa resposta às suas ações no ambiente. Por exemplo, os negócios lucrativos serão pontuados e os negócios não lucrativos serão multados. No final, depois de vários episódios de interação com o mercado, o trader artificial desenvolverá sua própria experiência única, que será impressa em seu "cérebro". A Floresta Aleatória agirá como o "cérebro".
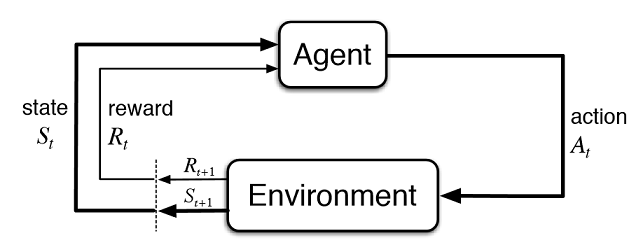
Fig. 2. Interação do trader virtual com o mercado
A figura 2 apresenta o esquema de interação do agente (trader artificial) com o ambiente (mercado). O agente pode executar ações A no tempo t, estando no estado St. Depois disso, ele entra no estado St+1, recebendo recompensa Rt para a ação anterior do ambiente, dependendo de quão bem sucedido ele foi. Essas ações podem continuar t+n vezes, até que toda a sequência estudada (ou um episódio do jogo para o agente) esteja completa. Esse processo pode ser iterativo, fazendo com que o agente aprenda várias vezes, melhorando constantemente os resultados.
A memória do agente (ou experiência) deve ser armazenada em algum lugar. A implementação clássica do aprendizado por reforço usa matrizes de estado de ação. Ao entrar em um determinado estado, o agente é forçado a endereçar a matriz para a próxima decisão. Essa implementação é adequada para tarefas com um conjunto muito limitado de estados. Caso contrário, a matriz pode se tornar muito grande. Portanto, a tabela é substituída por uma floresta aleatória:
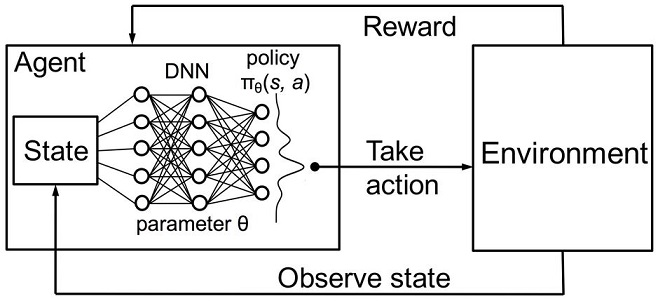
Fig. 3. Rede Neural Profunda ou Floresta Aleatória para aproximação de políticas
Uma política parametrizada estocástica Πθ de um agente é um conjunto de pares (s,a), onde θ é o vetor de parâmetros para cada estado. A política ótima é o conjunto ideal de ações para uma tarefa específica. Vamos concordar que o agente procura desenvolver uma política ótima. Esta abordagem funciona bem para tarefas contínuas com um número de estados previamente desconhecidos e é um método Ator-Crítico sem modelo no Aprendizado por Reforço. Existem muitas outras abordagens para o aprendizado por Reforço. Eles são descritos no livro "Reinforcement Learning: An Introduction" de Richard S. Sutton e Andrew G. Barto.
Implementação de software de um expert com autoaprendizagem (agente)
Eu me esforço para a continuidade em meus artigos, pois o sistema de lógica difusa atuará como um agente. No artigo anterior, a função de associação Gaussiana foi otimizada para a inferência fuzzy de Mamdani. No entanto, essa abordagem teve uma desvantagem significativa — a Gaussiana permaneceu inalterada para todos os casos, independentemente do estado atual do ambiente (valores do indicador). Agora a tarefa é selecionar automaticamente a posição da Gaussiana para o termo "neutro" da saída difusa "out". O agente será encarregado no desenvolvimento da política ótima, selecionando valores e aproximando a função do centro da Gaussiana, dependendo dos valores dos três valores e no intervalo de [0;1].
Crie um ponteiro separado para a função de associação nas variáveis globais do expert. Isso nos permite alterar livremente seus parâmetros no processo de aprendizagem:
CNormalMembershipFunction *updateNeutral=new CNormalMembershipFunction(0.5,0.2);
Crie uma Floresta Aleatória e objetos de classe matricial para preenchê-lo com os valores:
//RDF system. Aqui nós criamos todos os objetos RF. CDecisionForest RDF; //Random forest object CMatrixDouble RDFpolicyMatrix; //Matrix for RF inputs and output CDFReport RDF_report; //RF return errors in this object, then we can check it
As principais configurações da Floresta Aleatória são movidas para os parâmetros de entrada: o número de árvores e o componente de regularização. Isso permite melhorar um pouco o modelo ajustando esses parâmetros:
sinput int number_of_trees=50; sinput double regularization=0.63;
Vamos escrever uma função de serviço para verificar o estado do modelo. Se a Floresta Aleatória já tiver sido treinada para o período atual, ela será usada para os sinais de negociação e, se não, inicializa a política com valores aleatórios (negociar aleatoriamente).
void checkBeforeLearn() { if(clear_model) { int clearRDF=FileOpen("RDFNtrees"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_CSV|FILE_ANSI|FILE_COMMON); FileWrite(clearRDF,0); FileClose(clearRDF); ExpertRemove(); return; } int filehnd=FileOpen("RDFNtrees"+ _Symbol + (string)_Period +".txt",FILE_READ|FILE_WRITE|FILE_CSV|FILE_ANSI|FILE_COMMON); int ntrees = (int)FileReadNumber(filehnd); FileClose(filehnd); if(ntrees>0) { random_policy=false; int setRDF=FileOpen("RDFBufsize"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_CSV|FILE_ANSI|FILE_COMMON); RDF.m_bufsize=(int)FileReadNumber(setRDF); FileClose(setRDF); setRDF=FileOpen("RDFNclasses"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_CSV|FILE_ANSI|FILE_COMMON); RDF.m_nclasses=(int)FileReadNumber(setRDF); FileClose(setRDF); setRDF=FileOpen("RDFNtrees"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_CSV|FILE_ANSI|FILE_COMMON); RDF.m_ntrees=(int)FileReadNumber(setRDF); FileClose(setRDF); setRDF=FileOpen("RDFNvars"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_CSV|FILE_ANSI|FILE_COMMON); RDF.m_nvars=(int)FileReadNumber(setRDF); FileClose(setRDF); setRDF=FileOpen("RDFMtrees"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); FileReadArray(setRDF,RDF.m_trees); FileClose(setRDF); } else Print("Starting new learn"); checked_for_learn=true; }
Como você pode ver na listagem, o modelo treinado é carregado a partir dos arquivos contendo:
- o tamanho da amostra de treinamento,
- o número de classes (1 no caso de um modelo de regressão),
- o número de árvores,
- o número de características,
- e a matriz de árvores treinadas.
O treinamento ocorrerá no testador de estratégias, no modo de otimização. Após cada passo no testador, o modelo será treinado na matriz recém-formada e armazenado nos arquivos acima para uso posterior:
double OnTester() { if(clear_model) return 0; if(MQLInfoInteger(MQL_OPTIMIZATION)==true) { if(numberOfsamples>0) { CDForest::DFBuildRandomDecisionForest(RDFpolicyMatrix,numberOfsamples,3,1,number_of_trees,regularization,RDFinfo,RDF,RDF_report); } int filehnd=FileOpen("RDFBufsize"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_CSV|FILE_ANSI|FILE_COMMON); FileWrite(filehnd,RDF.m_bufsize); FileClose(filehnd); filehnd=FileOpen("RDFNclasses"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_CSV|FILE_ANSI|FILE_COMMON); FileWrite(filehnd,RDF.m_nclasses); FileClose(filehnd); filehnd=FileOpen("RDFNtrees"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_CSV|FILE_ANSI|FILE_COMMON); FileWrite(filehnd,RDF.m_ntrees); FileClose(filehnd); filehnd=FileOpen("RDFNvars"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_CSV|FILE_ANSI|FILE_COMMON); FileWrite(filehnd,RDF.m_nvars); FileClose(filehnd); filehnd=FileOpen("RDFMtrees"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); FileWriteArray(filehnd,RDF.m_trees); FileClose(filehnd); } return 0; }
A função para processar os sinais de negociação do artigo anterior permanece praticamente inalterada, mas agora a seguinte função é chamada depois de abrir uma ordem:
void updatePolicy(double action) { if(MQLInfoInteger(MQL_OPTIMIZATION)==true) { numberOfsamples++; RDFpolicyMatrix.Resize(numberOfsamples,4); RDFpolicyMatrix[numberOfsamples-1].Set(0,arr1[0]); RDFpolicyMatrix[numberOfsamples-1].Set(1,arr2[0]); RDFpolicyMatrix[numberOfsamples-1].Set(2,arr3[0]); RDFpolicyMatrix[numberOfsamples-1].Set(3,action); } }
Ela adiciona um vetor de estado com os valores de três indicadores à matriz, e o valor de saída é preenchido com o sinal atual obtido da inferência fuzzy de Mamdani.
Outra função:
void updateReward() { if(MQLInfoInteger(MQL_OPTIMIZATION)==true) { int unierr; if(getLAstProfit()<0) RDFpolicyMatrix[numberOfsamples-1].Set(3,MathRandomUniform(0,1,unierr)); } }
ela é chamada toda vez que uma ordem é fechada. Se uma negociação se mostrar não rentável, então a recompensa pelo agente é selecionada de uma distribuição uniforme aleatória, caso contrário, a recompensa permanece inalterada.
Fig. 4. Distribuição uniforme para selecionar um valor aleatório de recompensa
Assim, na implementação atual, os negócios lucrativos feitos pelo agente são pontuados, e no caso dos não lucrativos o agente é forçado a tomar uma ação aleatória (posição aleatória do centro da Gaussiana) em busca da solução ótima.
O código completo da função de processamento do sinal é o seguinte:
void PlaceOrders(double ts) { if(CountOrders(0)!=0 || CountOrders(1)!=0) { for(int b=OrdersTotal()-1; b>=0; b--) if(OrderSelect(b,SELECT_BY_POS)==true) if(OrderSymbol()==_Symbol && OrderMagicNumber()==OrderMagic) switch(OrderType()) { case OP_BUY: if(ts>=0.5) if(OrderClose(OrderTicket(),OrderLots(),OrderClosePrice(),0,Red)) { updateReward(); if(ts>0.6) { lots=LotsOptimized(); if(OrderSend(Symbol(),OP_SELL,lots,SymbolInfoDouble(_Symbol,SYMBOL_BID),0,0,0,NULL,OrderMagic,Red)>0) { updatePolicy(ts); }; } } break; case OP_SELL: if(ts<=0.5) if(OrderClose(OrderTicket(),OrderLots(),OrderClosePrice(),0,Red)) { updateReward(); if(ts<0.4) { lots=LotsOptimized(); if(OrderSend(Symbol(),OP_BUY,lots,SymbolInfoDouble(_Symbol,SYMBOL_ASK),0,0,0,NULL,OrderMagic,Green)>0) { updatePolicy(ts); }; } } break; } return; } lots=LotsOptimized(); if((ts<0.4) && (OrderSend(Symbol(),OP_BUY,lots,SymbolInfoDouble(_Symbol,SYMBOL_ASK),0,0,0,NULL,OrderMagic,INT_MIN) > 0)) updatePolicy(ts); else if((ts>0.6) && (OrderSend(Symbol(),OP_SELL,lots,SymbolInfoDouble(_Symbol,SYMBOL_BID),0,0,0,NULL,OrderMagic,INT_MIN) > 0)) updatePolicy(ts); return; }
A função de cálculo da inferência fuzzy de Mamdani sofreu mudanças. Agora, se a política do agente não foi selecionada aleatoriamente, ela chama o cálculo da posição da Gaussiana ao longo do eixo X usando a Floresta Aleatória treinada. A Floresta Aleatória é alimentada com o estado atual como um vetor com 3 valores do oscilador, e o resultado obtido atualiza a posição da Gaussiana. Se o EA for executado no otimizador pela primeira vez, a posição da Gaussiana será selecionada aleatoriamente para cada estado.
double CalculateMamdani() { CopyBuffer(hnd1,0,0,1,arr1); NormalizeArrays(arr1); CopyBuffer(hnd2,0,0,1,arr2); NormalizeArrays(arr2); CopyBuffer(hnd3,0,0,1,arr3); NormalizeArrays(arr3); if(!random_policy) { vector[0]=arr1[0]; vector[1]=arr2[0]; vector[2]=arr3[0]; CDForest::DFProcess(RDF,vector,RFout); updateNeutral.B(RFout[0]); } else { int unierr; updateNeutral.B(MathRandomUniform(0,1,unierr)); } //Print(updateNeutral.B()); firstTerm.SetAll(firstInput,arr1[0]); secondTerm.SetAll(secondInput,arr2[0]); thirdTerm.SetAll(thirdInput,arr3[0]); Inputs.Clear(); Inputs.Add(firstTerm); Inputs.Add(secondTerm); Inputs.Add(thirdTerm); CList *FuzzResult=OurFuzzy.Calculate(Inputs); Output=FuzzResult.GetNodeAtIndex(0); double res=Output.Value(); delete FuzzResult; return(res); }
O processo de treinamento e teste do modelo
O agente será treinado sequencialmente no otimizador. Ou seja, os resultados do treinamento anterior gravado em arquivos serão usados na próxima execução. Para fazer isso, basta desativar todos os agentes de teste e a nuvem, deixando apenas um núcleo.
Desative o algoritmo genético (use o algoritmo lento e completo). O treinamento/teste é realizado usando os preços de abertura (Open), porque o EA controla explicitamente a abertura da nova barra.
Existe apenas um parâmetro otimizável — o número de passos no otimizador. Para demonstrar a operação do algoritmo, defina 15 iterações.
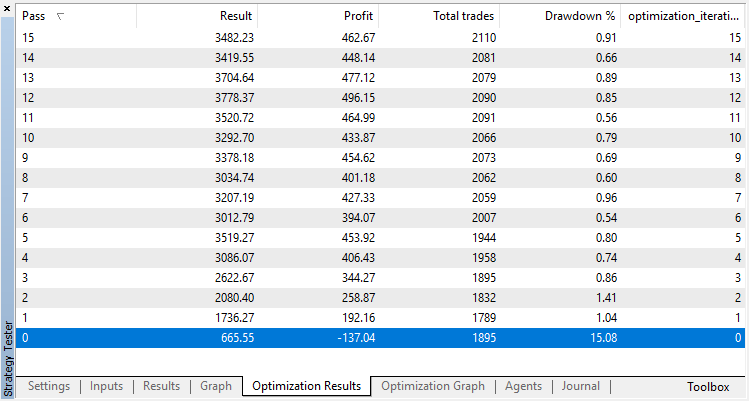
Os resultados da otimização do modelo de regressão (com uma variável de saída) são apresentados abaixo. Tenha em mente que o modelo treinado é salvo em um arquivo, portanto, somente o resultado da última execução será salvo.
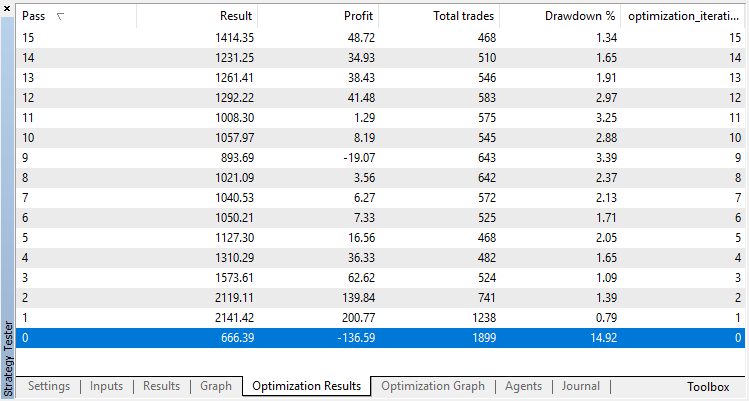
A execução zero corresponde à política aleatória do Agente (primeira execução), causando a maior perda. A primeira execução, ao contrário, acabou sendo a mais produtiva. Jogos subsequentes não deram um ganho, mas estagnaram. Como resultado, o gráfico de crescimento aparece da seguinte maneira após a 15ª execução:
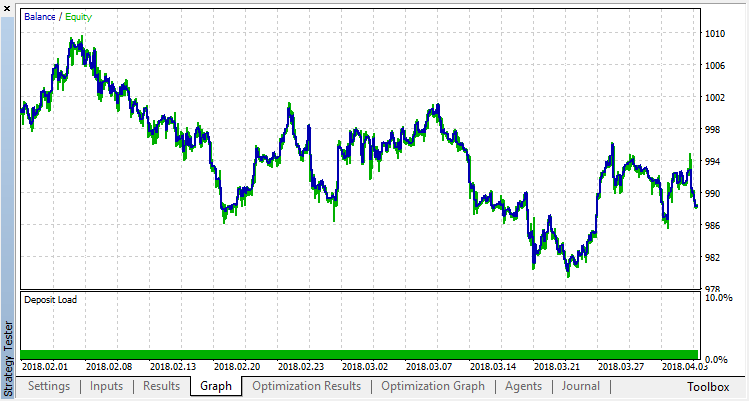
Vamos realizar o mesmo experimento para o modelo de classificação. Neste caso, as recompensas são divididas em 2 classes — positivas e negativas.
A classificação executa essa tarefa melhor. Pelo menos há um crescimento estável da execução zero, correspondente à política aleatória, até o dia 15, onde o crescimento parou e a política começou a flutuar em torno do ponto ótimo.
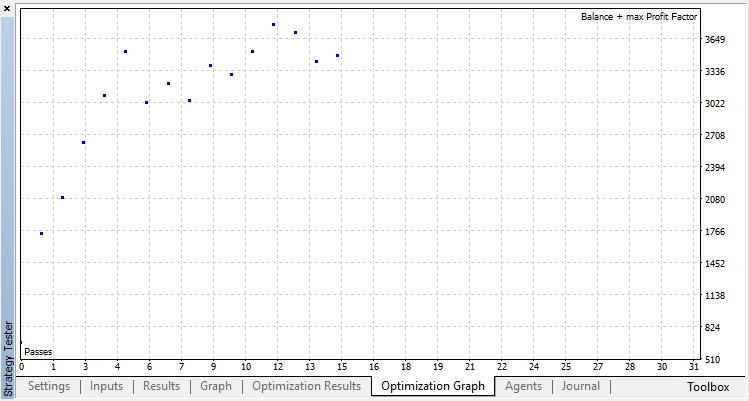
O resultado final do treinamento do agente:
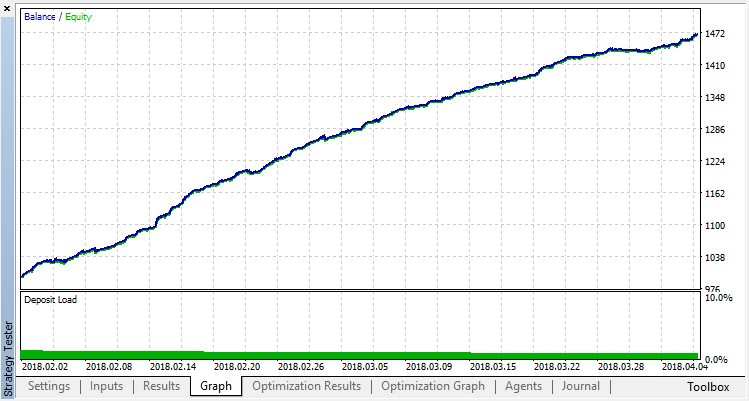
Verifica os resultados da operação do sistema em uma amostra fora do intervalo de treinamento. O modelo sofreu muito overfitting:
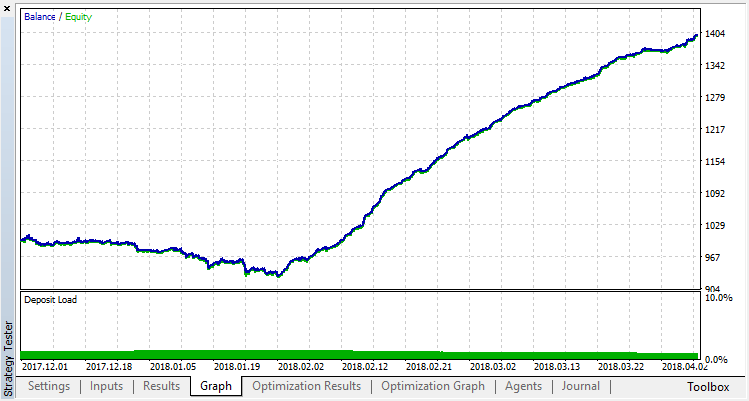
Vamos tentar nos livrar do overfitting. Configure o parâmetro r (regularização) para 0.25: apenas 25% da amostra será usada no treinamento. Use o mesmo intervalo de treinamento.
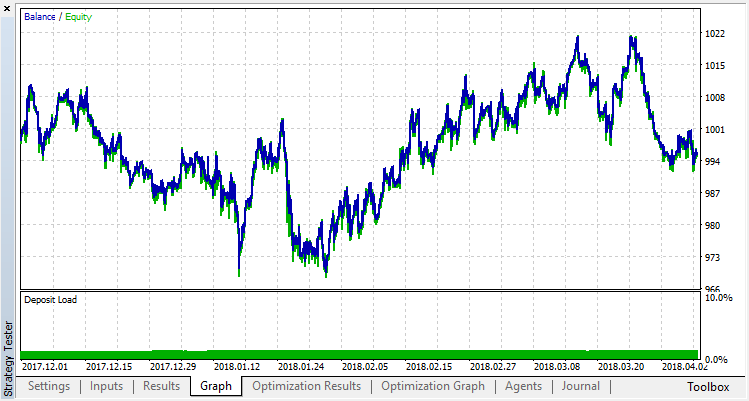
O modelo aprendeu pior (mais ruído foi adicionado), mas não foi possível livrar-se do overfitting global. Este método de regularização é obviamente adequado apenas para processos estacionários em que as regularidades não mudam com o tempo. Outro fator negativo óbvio são os 3 osciladores na entrada do modelo, que, além disso, se correlacionam entre si.
Resumindo o artigo
O objetivo era mostrar as possibilidades de usar uma Floresta Aleatória para aproximar uma função. Nesse caso, a função dos valores dos indicadores era um sinal de compra ou venda. Além disso, dois tipos de aprendizagem supervisionada foram considerados — classificação e regressão. Uma abordagem fora do padrão foi aplicada ao aprendizado com exemplos de treinamento previamente desconhecidos que foram selecionados automaticamente durante o processo de otimização. No geral, o processo é semelhante a uma otimização convencional no testador (nuvem), com o algoritmo convergindo em apenas algumas iterações e sem a necessidade de se preocupar com o número de parâmetros otimizados. Essa é uma clara vantagem da abordagem aplicada. A desvantagem do modelo é uma forte tendência a overfitting quando a estratégia é selecionada incorretamente, o que equivale à super otimização dos parâmetros.
Por tradição, eu darei possíveis maneiras de melhorar a estratégia (afinal, a implementação atual é apenas um quadro aproximado).
- Aumentar o número de parâmetros otimizados (otimização de múltiplas funções de associação).
- Adicionar vários preditores significativos.
- Aplicar diferentes métodos de recompensar o agente.
- Criar vários agentes rivais para aumentar o espaço de variantes.
Os arquivos fontes do expert de autoaprendizagem estão anexados abaixo.
Para que o EA compile e funcione corretamente, é necessário baixar a biblioteca MT4Orders e a biblioteca Fuzzy atualizada.
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/3856
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.
 Construtor de estratégia visual. Criação de robôs de negociação sem programação
Construtor de estratégia visual. Criação de robôs de negociação sem programação
 Como analisar os trades do Sinal selecionado no gráfico
Como analisar os trades do Sinal selecionado no gráfico
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Há algum problema com o algoritmo?
Estou recebendo constantemente o erro de divisão por zero em "dataanalysis.mqh"!
Criei minha própria versão com vários símbolos... mas esse erro é muito chato!
Ficaria muito grato com alguma ajuda.
a respeito.
Acho que o resultado desse EA no artigo é muito bom
mas em uma conta real com dinheiro real, qual é o problema desse EA que precisa ser corrigido?
ou outra pergunta, qual é o ponto fraco desse EA que precisa ser desenvolvido, corrigido ou atualizado para melhor?
Alguém pode me dar uma sugestão?
Obrigado
Obrigado por abrir meus olhos para a biblioteca Alglib, que eu não sabia que vinha com a versão mais recente do Metatrader 5....
Eu me vi reinventando a roda de certa forma!
Olá, esse artigo é muito fascinante. No entanto, quando tento compilar o modelo de regressão de floresta de decisão aleatória, são gerados 93 erros.
O primeiro erro é um erro de identificador não declarado. A variável que está tentando ser chamada é a propriedade m_buffsize do RDF.
A chamada é feita pelo manipulador de eventos OnTester. Incluí um trecho do código.
Qual é a melhor maneira de resolver isso?
Fig. 1: Alguns dos erros lançados durante o tempo de compilação.