
Random Decision Forest en el aprendizaje reforzado
Descripción del algoritmo Random Forest
Random Forest (RF) (en castellano, Bosques Aleatorios) con aplicación del bagging (Empaquetado) es uno de los métodos del aprendizaje automático más fuerte, que cede un poco ante el boosting del gradiente (Potenciación del gradiente).
El Bosque Aleatorio se compone de un conjunto de árboles de decisión (que también se llaman los árboles de clasificación o árboles de regresión "CART" y solucionan las tareas homónimas). Se utilizan en la estadística, análisis de los datos y en el aprendizaje automático. Cada uno de los árboles es un modelo bastante simple que tiene sus ramas, nodos y hojas. En los nodos se escriben los atributos de cuyos valores depende la función finalista. Luego, los valores de la función finalista llegan en las hojas por las ramas. En el proceso de la clasificación de un nuevo caso, hay que bajar por el árbol a través de las ramas hasta la hoja, pasando por todos los valores del atributo aplicando el principio lógico «si..., entonces». Dependiendo de estas condiciones, a la variable finalista se le adjudicará un valor o clase (la variable finalista entra en una hoja determinada). El objetivo de la construcción del árbol de decisiones es la creación de un modelo que predice el valor de la variable finalista dependiendo de varias variables en la entrada.
El bosque aleatorio se construye mediante una votación simple de los árboles de decisión según el algoritmo de Bagging (Empaquetado). El Bagging es una palabra artificial formada de la combinación inglesa bootstrap aggregating. Este término fue introducido por Leo Breiman en 1994.
Bootstrap en la estadística es un modo de formar la muestra, cuando se selecciona la misma cantidad de objetos que había desde el principio. Pero estos objetos se seleccionan con repeticiones. En otras palabras, un objetos aleatorio seleccionado se devuelve y puede seleccionarse otra vez. El número de los objetos que serán seleccionados será aproximadamante 63% de la muestra original, mientras que el resto de los objetos (aproximadamante 37%) no entrará nunca en la muestra de aprendizaje. Esta muestra empilada se usa para enseñar los algoritmos básicos (en nuestro caso, los árboles de decisión). Eso también se hace de manera aleatoria: se toman los subconjuntos (samples) de una determinada longitud y se entrenan en un subconjunto aleatorio de características (atributos). Los 37% restantes de la muestra se usan para para comprobar la capacidad conjunta del modelo construido.
Luego todos los árboles entrenados se combinan en una composición a través de una simple votación, con el uso del error promediado para todos los samples. En resultado de aplicación de bootstrap aggregating, se reduce el cuadrado medio del error, se disminuye la dispersión del clasificador entrenado. El error no va diferenciarse mucho en muestras diferentes. Como resultado, el modelo, según afirman los autores, va a reentrenarse menos. La eficacia del bagging consiste en que los algoritmos básicos (árboles de decisión) se entrenan a base de diferentes muestras aleatorias y sus resultados pueden ser muy diferentes, pero sus errores se compensan mutuamente durante la votación.
Se puede decir que Random forest es un caso especial del bagging, cuando se usan los árboles de decisión como una familia básica. Además, a diferencia del modo habitual de la construcción de árboles de decisión, no se usa la reducción del árbol (pruning). El método está orientado a la posibilidad de construir cuanto antes una composición usando las muestras grandes de los datos. Cada árbol se construye de una manera específica. La característica (atributo) para construir un nodo del árbol no se selecciona del número total de características, sino de su subconjunto aleatorio. Si estamos construyendo un modelo regresivo, el número de las características será igual a n/3. En caso de la clasificación, es √n. Todo eso representa las recomendaciones empíricas y se llama decorrelación: diferentes árboles reciben diferentes conjuntos de características, y los árboles se entrenan en diferentes muestras.
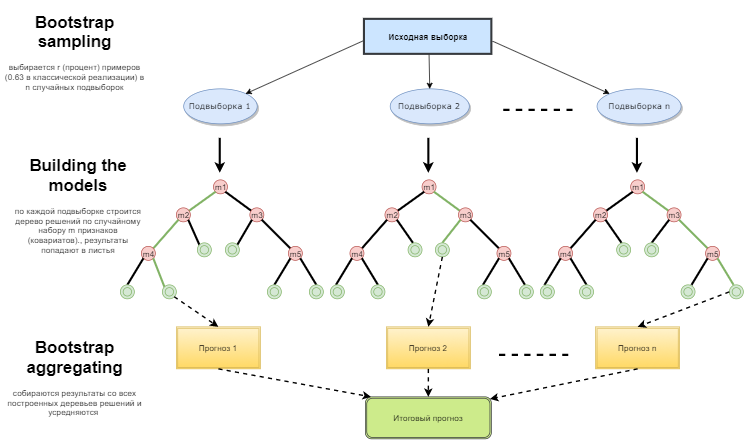
Fig. 1. Esquema de funcionamiento del árbol aleatorio
El algoritmo del bosque aleatorio ha resultado muy eficaz, permitiendo resolver problemas prácticas. Ofrece una alta precisión del entrenamiento, con una cantidad supuestamente alta de las contingencias que figuran en el proceso de la construcción del modelo. La ventaja ante otros modelos del aprendizaje automático es la evaluación out of bag para la primera parte del subconjunto que no forma parte de la muestra de entrenamiento. Por eso, no es obligatorio hacer la validación cruzada o la simulación en una muestra separada para los árboles de decisión. Será suficiente hacer la estimación out of bag para la siguiente mejora del modelo: selección del número de los árboles de decisión y el componente de regularización.
En la biblioteca ALGLIB, que entra en la entrega estándar del terminal МetaТrader 5, hay algoritmo Random Decision Forest (RDF). Es la modificación del algoritmo original Random Forest propuesto por Leo Breiman y Adel Katler. Este algoritmo combina dos ideas: el uso del círculo de los árboles de decisión que recibe el resultado mediante la votación, y la idea de aleatorizar el proceso del entrenamiento. Puede encontrar la información detallada sobre las modificaciones del algoritmo en la web ALGLIB.
Ventajas del algoritmo
- Alta velocidad del entrenamiento
- Entrenamiento no iterado — el algoritmo se termina en una cantidad fija de operaciones
- Escalamiento (capacidad de procesar grandes volúmenes de datos)
- Alta calidad de modelos resultantes (comparada con redes neuronales y conjuntos de redes neuronales)
- Falta de la sensibilidad a la emisión de datos debido al sampling aleatorio
- Pocos parámetros para ajustar
- Falta de la sensibilidad al escalamiento (y a cualquier transformación en general) de los valores de características gracias a la selección de subentornos aleatorios
- No requiere configuración minuciosa de parámetros, trabaja bien «desde el paquete» A través del «tuning» de los parámetros se puede conseguir el incremento de 0,5 a 3% de precisión, dependiendo de la tarea y datos
- Trabaja bien con datos omitidos — mantiene buena precisión incluso si la mayor parte de datos ha sido omitida
- Estimación interna de la capacidad del modelo para la generalización
- Capacidad del trabajo con datos crudos, sin el preprocesamiento
Desventajas del algoritmo
- El modelo construido ocupa mucha memoria. Si construimos un círculo de K árboles a base del conjunto de entrenamiento con el tamaño N, el requerimiento para la memoria será O(K·N). Por ejemplo, para K=100 y N=1000 el modelo construido por ALGLIB ocupará 1 Mb de la memoria. Pero el volumen de la memoria operativa de los ordenadores modernos es bastante elevado, así que no es una desventaja tan importante.
- Un modelo entrenado trabaja un poco más lento que otros algoritmos (si el modelo tiene 100 árboles, tenemos que recorrer todos para obtener el resultado). Pero eso tampoco se nota tanto en los ordenadores modernos rápidos.
- El algoritmo trabaja peor que la mayoría de los métodos lineales cuando la muestra contiene muchos características enrarecidas (textos, Bag of words), o cuando los objetos clasificados pueden ser divididos de forma lineal notoriamente.
- El algoritmo es propenso al reentrenamiento, sobre todo en las tareas con mucho ruido. Parcialmente, se puede resolver este problema ajustando el parámetro r. El algoritmo Random Forest tiene el mismo problema pero aún más grave. Sin embargo, los autores del algoritmo declaraban que la tendencia al reentrenamiento no existe. Algunos prácticos y teóricos del aprendizaje automático comparten este error.
- Para los datos que incluyen las variables conceptuales con la cantidad diferente de niveles, los bosques aleatorios tienden a favor de las características con la cantidad grande de niveles. El árbol va a ajustarse más precisamente a estas características puesto que ahí se puede conseguir un valor más alto de la funcionalidad optimizada (tipo del incremento de la información).
- Igual como los árboles de decisión, el algoritmo es absolutamente incapaz para la extrapolación (pero eso puede considerarse como una ventaja porque no habrá valores extremos en caso de la emisión).
Particularidades de la aplicación del aprendizaje automático en el trading
Entre los neófitos del aprendizaje automático predomina la opinión que se trata de un mundo maravilloso, donde los programas hacen todo por el trader, mientras que éste se felicita de recibir los beneficios. Es así, pero en parte. Desde luego, el resultado va a depender de hasta qué punto serán resueltos los problemas descritos a continuación.
- Feature selection (selección de características)
El primer problema y el más importante es seleccionar qué es lo que debe aprender el modelo. Hay muchos factores que influyen en el precio. Existe sólo un enfoque científico de analizar el mercado (econometría). Incluye tres métodos principales: análisis de la regresión, análisis de series temporales y análisis del panel. Una rama interesante de esta ciencia es la econometría no paramétrica, que se basa exclusivamente en los datos existentes, sin analizar las causas que los forman. Últimamente, los métodos de la econometría no paramétrica son populares en las investigaciones aplicadas: por ejemplo, son los métodos nucleares y redes neuronales. A la misma rama le pertenece el análisis de los conceptos no numéricos: por ejemplo, los conjuntos difusos Si pretende dedicarse al aprendizaje automático en serio, le será útil estudiar los métodos de la econometría. En este artículo, nos centraremos en los conjuntos difusos.
- Model selection (selección del modelo)
El segundo problema consiste en seleccionar el modelo del aprendizaje. Hay muchos modelos lineales y no lineales. Puede encontrar su lista y características comparativas, por ejemplo, en la web de Microsoft.
Por ejemplo, hay una enorme cantidad de variedades de las redes neuronales. Al usarlas, es necesario experimentar con la arquitectura de la red seleccionando la cantidad de las capas y neuronas. En su lugar, las redes neuronales clásicas tipo MLP se entrenan muy lento (sobre todo en el descenso del gradiente con un paso fijo), los experimentos con ellas requieren un montón de tiempo. Actualmente, las redes modernas rápidamente entrenadas Deep Learning no están presentadas en la biblioteca estándar del terminal, y usar las bibliotecas ajenas en forma de dll no es muy conveniente. Todavía no he estudiado suficientemente estos paquetes.
A diferencia de las redes neuronales, los modelos lineales trabajan rápido, pero no siempre pueden bien con la aproximación.
Random Forest no tiene estos defectos. Lo único que necesitamos es seleccionar el número de los árboles y el parámetro r, que responde del porcentaje de objetos que entran en la muestra de aprendizaje. Mis experimentos en Microsoft Azure Machine Learning Studio han demostrado que en mayoría de los casos los bosques aleatorios dan el menor error de predicción con los datos de prueba.
- Model testing (simulación del modelo obtenido con datos nuevos)
Generalmente, hay sólo una recomendación: cuanto más grande sea la muestra de aprendizaje y las características sean más informativas, más estable debe ser el sistema en los datos nuevos. Pero al solucionar las tareas del trading, puede surgir la situación de la capacidad insuficiente del sistema, cuando las variaciones de los predictores son muy pocas y no son informativas. Como resultado, las mismas señales de los predictores van a enviar las señales de compra y de venta. En la salida, obtenemos una capacidad generalizada baja y por consiguiente, una mala calidad de señales en el futuro. Además, el aprendizaje en una muestra grande será lento, entonces, no habrá posibilidad de los repasos múltiples durante la optimización. Además, no habrá ninguna garantía de un resultado positivo. Añadimos a estos problemas la naturaleza caótica de las cotizaciones, con las regularidades del mercado que se cambian constantemente, o (lo que es peor), con su falta en absoluto.
Selección del modo de selección del modelo
El bosque aleatorio se utiliza para resolver un amplio abanico de tareas de la regresión, clasificación y análisis de grupos.
Condicionalmente, se puede presentar estos métodos de la siguiente manera.
- Aprendizaje no supervisado (unsupervised). El análisis de grupos, detección de anomalías. Estos métodos se aplican para dividir las características (usando los métodos del programa) en diferentes grupos con distinciones características que se determinan automáticamente.
- Aprendizaje supervisado (supervised). Clasificación y regresión. A la salida se envía un conjunto de ejemplos de entrenamiento (marcas) conocidos de antemano, y el bosque aleatorio trata de aprender (aproximar) todos los casos.
- Aprendizaje reforzado (reinforcement). Probablemente, es el tipo más insólito y perspectivo del aprendizaje automático que se destaca de los demás. Aquí, el aprendizaje se realiza durante la interacción del agente virtual con el entorno. En este caso, el agente intenta maximizar las remuneraciones obtenidas de las acciones dentro de este entorno. Vamos a aplicar este enfoque.
Aprendizaje reforzado en las tareas del desarrollo de un sistema comercial
Presentamos la creación del trader con inteligencia artificial. Va a interactuar con el entorno y obtener alguna respuesta a sus acciones. Por ejemplo, las transacciones rentables van a estimularse y las transacciones no rentables van a suponer una multa. En conclusión, después de una cierta cantidad de episodios de interacción con el mercado, el trader artificial elaborará su propia experiencia única que se grabará en su «cerebro». El papel del «cerebro» va a desempeñarse por el bosque artificial.
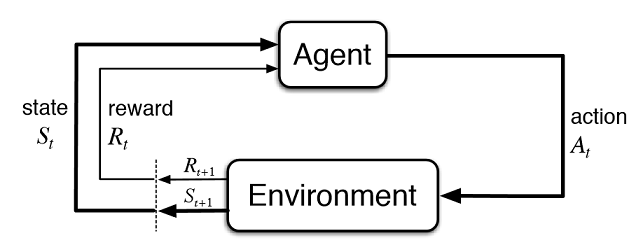
Fig. 2. Interacción del trader virtual con el mercado
En la imagen 2 se muestra el esquema de interacción del agente (trader artificial) con el entorno (mercado). El agente puede realizar las acciones A en el momento del tiempo t, encontrándose además en el estado St. Después de eso pasa en el estado St+1, obteniendo las remuneraciones Rt de parte del entorno por la acción anterior dependiendo de su éxito. Estas acciones pueden durar t+n veces hasta que se termine la secuencia entera que se analiza (o el episodio de juego para el agente). Se puede hacer que este proceso sea interactivo, obligando al agente entrenarse varias veces, mejorando constantemente los resultados.
La memoria del agente (o su experiencia) debe almacenarse en algún lugar. En la implementación clásica del aprendizaje reforzado, se usan las matrices estado-acciones. Entrando en un determinado estado, el agente tiene que acceder a la matriz a por la siguiente decisión. Esta implementación conviene para las tareas con un reducido conjunto de estados. En este caso, la matriz puede llegar a ser muy grande. Por eso, vamos a sustituir la tabla por el bosque aleatorio:
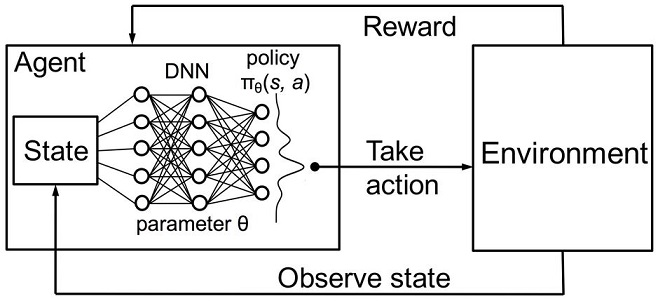
Fig. 3. Red neuronal profunda o bosque aleatorio para aproximación de la política
La política estocástica parametrizada Πθ (policy) del agente se llama el conjunto de pares (s,a), donde θ es el vector de parámetro para cada estado. La política óptima es el conjunto óptimo de acciones para cada tarea determinada. Vamos a acordar que el agente pretenderá desarrollar una política óptima. Este enfoque funciona bien para las tareas ininterrumpido con el número de estados desconocido previamente, siendo el método model-free actor-critic en el aprendizaje reforzado. Existen muchos otros enfoques en el aprendizaje reforzado. Se describen en el libro de Richard S. Sutton y Andrew G. Barto "Reinforcement Learning: An Introduction"
Implementación del Asesor Experto Autoenseñable
Yo pretendo mantener la continuidad en mis artículos, por eso como agente usaremos el sistema de lógica difusa. Recordaré que en el artículo anterior, he optimizado la función gaussiana de pertenencia para la inferencia difusa tipo Mamdani. Pero aquel enfoque tenía una importante desventaja: es que la gaussiana se quedaba invariable para todos los casos, independientemente del estado actual del entorno (valores de indicadores). Ahora nuestra tarea es la selección automática de la posición de la gaussiana de la terma "neutral" de la lógica difusa "out". La tarea del agente será el desarrollo de una política óptima a través de la selección de valores y la aproximación de la función de la posición del centro de gaussiana, dependiendo de los valores de tres indicadores, en el rango [0;1].
Crearemos un puntero separado a la función de pertenencia en las variables globales del EA. Eso permitirá cambiar sus parámetros de forma aleatoria en el proceso del aprendizaje:
CNormalMembershipFunction *updateNeutral=new CNormalMembershipFunction(0.5,0.2);
Crearemos los objetos de las clases del bosque aleatorio y matriz, para llenarla con valores:
//RDF system. Here we create all RF objects. CDecisionForest RDF; //Random forest object CMatrixDouble RDFpolicyMatrix; //Matrix for RF inputs and output CDFReport RDF_report; //RF return errors in this object, then we can check it
En los inputs, colocaremos los ajustes principales del bosque aleatorio: número de árboles y el componente de regularización. Eso permitirá mejorar un poco el modelo mediante el tuning de estos parámetros:
sinput int number_of_trees=50; sinput double regularization=0.63;
Escribiremos la función de servicio para verificar el estado del modelo. Si el bosque aleatorio ya está entrenado para el timeframe actual, vamos a usarlo para las señales comerciales, de lo contrario, inicializamos la política usando valores aleatorios (vamos a tradear de forma aleatoria):
void checkBeforeLearn() { if(clear_model) { int clearRDF=FileOpen("RDFNtrees"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_CSV|FILE_ANSI|FILE_COMMON); FileWrite(clearRDF,0); FileClose(clearRDF); ExpertRemove(); return; } int filehnd=FileOpen("RDFNtrees"+ _Symbol + (string)_Period +".txt",FILE_READ|FILE_WRITE|FILE_CSV|FILE_ANSI|FILE_COMMON); int ntrees = (int)FileReadNumber(filehnd); FileClose(filehnd); if(ntrees>0) { random_policy=false; int setRDF=FileOpen("RDFBufsize"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_CSV|FILE_ANSI|FILE_COMMON); RDF.m_bufsize=(int)FileReadNumber(setRDF); FileClose(setRDF); setRDF=FileOpen("RDFNclasses"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_CSV|FILE_ANSI|FILE_COMMON); RDF.m_nclasses=(int)FileReadNumber(setRDF); FileClose(setRDF); setRDF=FileOpen("RDFNtrees"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_CSV|FILE_ANSI|FILE_COMMON); RDF.m_ntrees=(int)FileReadNumber(setRDF); FileClose(setRDF); setRDF=FileOpen("RDFNvars"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_CSV|FILE_ANSI|FILE_COMMON); RDF.m_nvars=(int)FileReadNumber(setRDF); FileClose(setRDF); setRDF=FileOpen("RDFMtrees"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); FileReadArray(setRDF,RDF.m_trees); FileClose(setRDF); } else Print("Starting new learn"); checked_for_learn=true; }
Como se puede ver de este código, el modelo entrenado se descarga desde los archivos que contienen lo siguiente:
- tamaño de la muestra de aprendizaje,
- número de clases (1 en caso del modelo de regresión),
- número de árboles,
- número de características
- y array de árboles entrenados.
El aprendizaje va a realizarse en el Probador de Estrategias del terminal, en el modo de optimización. Después de cada repaso del Probador de Estrategias, el modelo va a entrenarse en la matriz formada de nuevo y guardarse en los archivos arriba especificados, para el uso posterior:
tester:
{
if(clear_model) return 0;
if(MQLInfoInteger(MQL_OPTIMIZATION)==true)
{
if(numberOfsamples>0)
{
CDForest::DFBuildRandomDecisionForest(RDFpolicyMatrix,numberOfsamples,3,1,number_of_trees,regularization,RDFinfo,RDF,RDF_report);
}
int filehnd=FileOpen("RDFBufsize"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_CSV|FILE_ANSI|FILE_COMMON);
FileWrite(filehnd,RDF.m_bufsize);
FileClose(filehnd);
filehnd=FileOpen("RDFNclasses"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_CSV|FILE_ANSI|FILE_COMMON);
FileWrite(filehnd,RDF.m_nclasses);
FileClose(filehnd);
filehnd=FileOpen("RDFNtrees"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_CSV|FILE_ANSI|FILE_COMMON);
FileWrite(filehnd,RDF.m_ntrees);
FileClose(filehnd);
filehnd=FileOpen("RDFNvars"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_CSV|FILE_ANSI|FILE_COMMON);
FileWrite(filehnd,RDF.m_nvars);
FileClose(filehnd);
filehnd=FileOpen("RDFMtrees"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON);
FileWriteArray(filehnd,RDF.m_trees);
FileClose(filehnd);
}
return 0;
}
La función del procesamiento de señales comerciales del artículo anterior ha quedado prácticamente invariable, pero ahora, después de la apertura de la nueva orden, se invoca la función:
void updatePolicy(double action) { if(MQLInfoInteger(MQL_OPTIMIZATION)==true) { numberOfsamples++; RDFpolicyMatrix.Resize(numberOfsamples,4); RDFpolicyMatrix[numberOfsamples-1].Set(0,arr1[0]); RDFpolicyMatrix[numberOfsamples-1].Set(1,arr2[0]); RDFpolicyMatrix[numberOfsamples-1].Set(2,arr3[0]); RDFpolicyMatrix[numberOfsamples-1].Set(3,action); } }
Ella añade a la matriz, un nuevo vector del estado de los valores de tres indicadores, mientras que el valor de salida se rellena con la señal actual obtenida desde la lógica difusa de Mamdani.
Otra función:
void updateReward() { if(MQLInfoInteger(MQL_OPTIMIZATION)==true) { int unierr; if(getLAstProfit()<0) RDFpolicyMatrix[numberOfsamples-1].Set(3,MathRandomUniform(0,1,unierr)); } }
se invoca cada vez después del cierre de la orden. Si la transacción ha resultado negativa, la remuneración del agente se selecciona desde una distribución uniforme aleatoria, en caso contrario, la remuneración queda sin cambios.
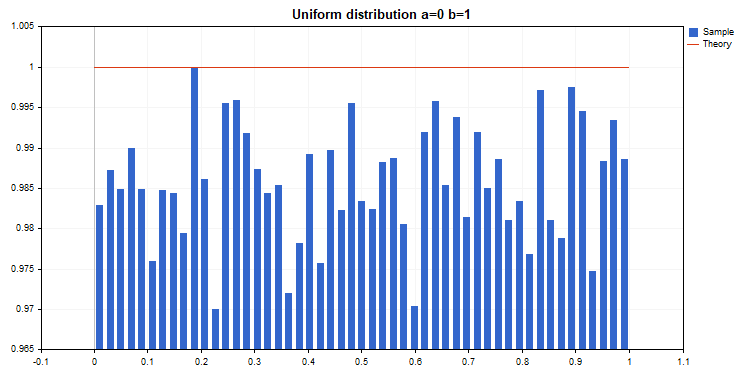
Fig. 4. Distribución uniforme para la selección del valor aleatorio de la remuneración
De esta manera, en la implementación actual, las transacciones rentables del agente se recompensan, y en caso de las no rentables, le haremos realizar una acción aleatoria (posición aleatoria del centro de la gaussiana) en búsqueda de una solución apropiada.
El código completo de la función del procesamiento de las señales es el siguiente:
void PlaceOrders(double ts) { if(CountOrders(0)!=0 || CountOrders(1)!=0) { for(int b=OrdersTotal()-1; b>=0; b--) if(OrderSelect(b,SELECT_BY_POS)==true) if(OrderSymbol()==_Symbol && OrderMagicNumber()==OrderMagic) switch(OrderType()) { case OP_BUY: if(ts>=0.5) if(OrderClose(OrderTicket(),OrderLots(),OrderClosePrice(),0,Red)) { updateReward(); if(ts>0.6) { lots=LotsOptimized(); if(OrderSend(Symbol(),OP_SELL,lots,SymbolInfoDouble(_Symbol,SYMBOL_BID),0,0,0,NULL,OrderMagic,Red)>0) { updatePolicy(ts); }; } } break; case OP_SELL: if(ts<=0.5) if(OrderClose(OrderTicket(),OrderLots(),OrderClosePrice(),0,Red)) { updateReward(); if(ts<0.4) { lots=LotsOptimized(); if(OrderSend(Symbol(),OP_BUY,lots,SymbolInfoDouble(_Symbol,SYMBOL_ASK),0,0,0,NULL,OrderMagic,Green)>0) { updatePolicy(ts); }; } } break; } return; } lots=LotsOptimized(); if((ts<0.4) && (OrderSend(Symbol(),OP_BUY,lots,SymbolInfoDouble(_Symbol,SYMBOL_ASK),0,0,0,NULL,OrderMagic,INT_MIN) > 0)) updatePolicy(ts); else if((ts>0.6) && (OrderSend(Symbol(),OP_SELL,lots,SymbolInfoDouble(_Symbol,SYMBOL_BID),0,0,0,NULL,OrderMagic,INT_MIN) > 0)) updatePolicy(ts); return; }
Función del cálculo de Inferencia difusa tipo Mamdani ha sufrido modificaciones. Ahora, si la política del agente no está seleccionada aleatoriamente, se llama al cálculo del valor de la posición de la gaussiana por el eje x usando el bosque aleatorio ya entrenado. El estado actual en forma de un vector de 3 valores de osciladores se pasa a la entrada del bosque, y el resultado obtenido actualiza la posición de la gaussiana. Si el EA se inicia en el optimizador por primera vez, la posición de la gaussiana se selecciona de forma aleatoria para cada estado.
double CalculateMamdani() { CopyBuffer(hnd1,0,0,1,arr1); NormalizeArrays(arr1); CopyBuffer(hnd2,0,0,1,arr2); NormalizeArrays(arr2); CopyBuffer(hnd3,0,0,1,arr3); NormalizeArrays(arr3); if(!random_policy) { vector[0]=arr1[0]; vector[1]=arr2[0]; vector[2]=arr3[0]; CDForest::DFProcess(RDF,vector,RFout); updateNeutral.B(RFout[0]); } else { int unierr; updateNeutral.B(MathRandomUniform(0,1,unierr)); } //Print(updateNeutral.B()); firstTerm.SetAll(firstInput,arr1[0]); secondTerm.SetAll(secondInput,arr2[0]); thirdTerm.SetAll(thirdInput,arr3[0]); Inputs.Clear(); Inputs.Add(firstTerm); Inputs.Add(secondTerm); Inputs.Add(thirdTerm); CList *FuzzResult=OurFuzzy.Calculate(Inputs); Output=FuzzResult.GetNodeAtIndex(0); double res=Output.Value(); delete FuzzResult; return(res); }
Proceso del aprendizaje t simulación del modelo
El agente va a entrenarse en el optimizador de forma consecutiva. Es decir, los resultados del aprendizaje anterior que almacenan en los archivos van a usarse para el siguiente repaso. Para eso, simplemente desactivamos los agentes de la simulación y la nube, dejando sólo el núcleo.
Desactivamos el algoritmo genético (usamos el repaso completo). El aprendizaje/simulación se realiza por los precios de apertura, porque en el EA habrá un control explícito de la apertura de la nueva barra.
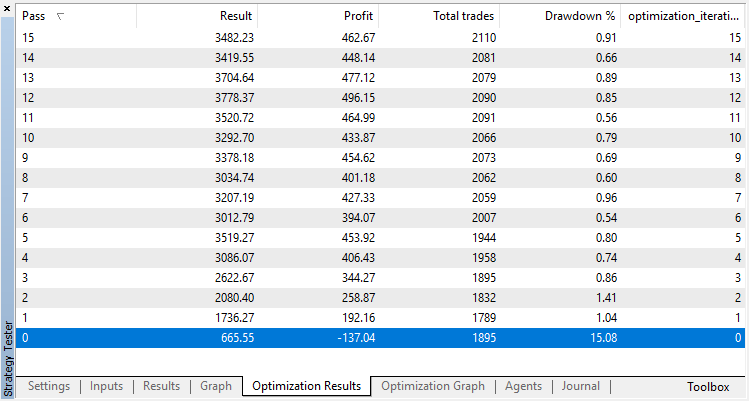
Hay sólo un parámetro de optimización: el número de repasos en el optimizador. Para demostrar el trabajo del algoritmo, establecemos 15 iteraciones.
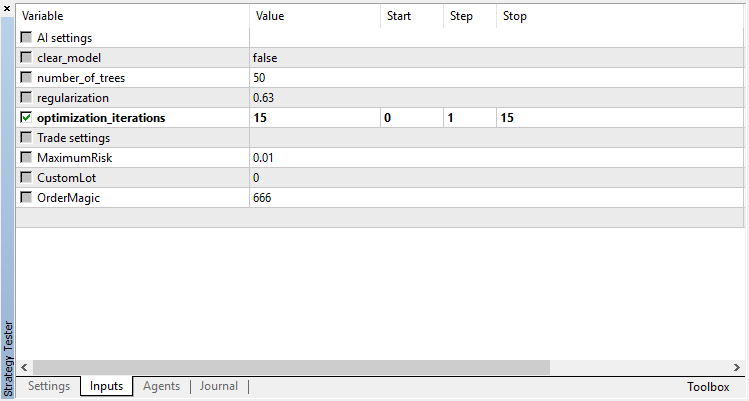
Los resultados de la optimización del modelo de regresión (con un parámetro de salida) se muestran a continuación: No olvide que el modelo entrenado se guarda en el archivo, por eso se guardará el resultado sólo del último repaso.
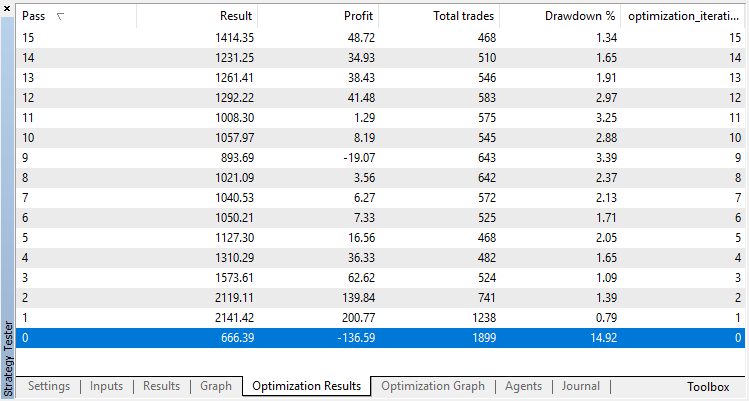
El repaso nulo corresponde a la política aleatoria del Agente (el primer inicio), por eso ha traído la pérdida más grande. El prime repaso, al contrario, ha salido con el mayor resultado. Los siguientes juegos no han dado ningún incremento, sino se han estancado. Al final, tras el repaso 15, el gráfico del incremento es el siguiente:
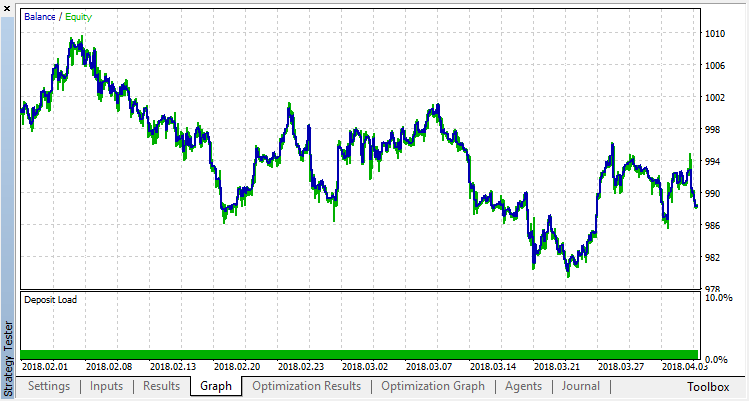
Hagamos el mismo experimento para el modelo de clasificación. En este caso, las recompensas se dividen en 2 clases: positivas y negativas.
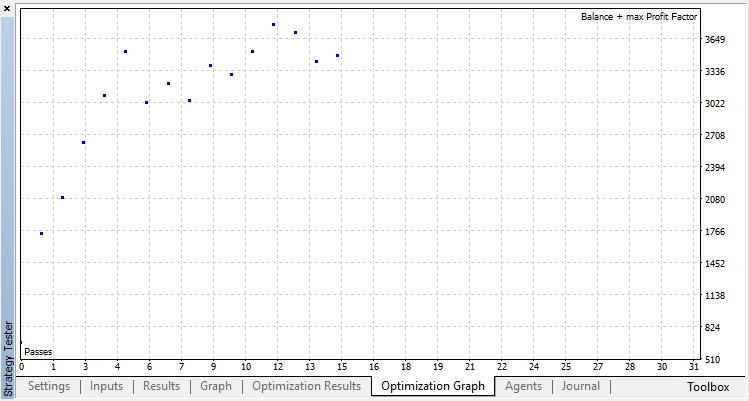
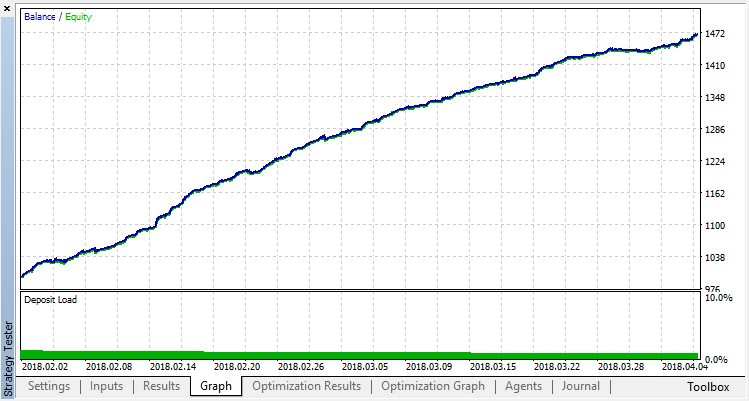
La clasificación funciona bastante mejor para nuestra tarea. Por lo menos, se observa un crecimiento estable a partir del repaso cero correspondiente a la política aleatoria hasta el repaso 15, en el que el crecimiento se ha detenido y la política ha empezado a fluctuar alrededor del óptimo.
Resultado final del entrenamiento del Agente:
Comprobamos los resultados del trabajo del sistema usando la muestra fuera del intervalo del aprendizaje. El modelo se ha reentrenado muchísimo:
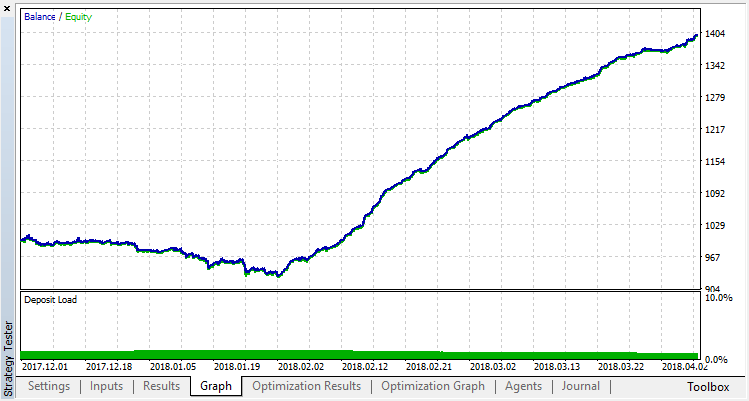
Intentaremos librarse del reentrenamiento. Establecemos el parámetro r (regularization), igual a 0,25: sólo 25% de la muestra pueden participar en el aprendizaje. Vamos a entrenar en el mismo intervalo de tiempo.
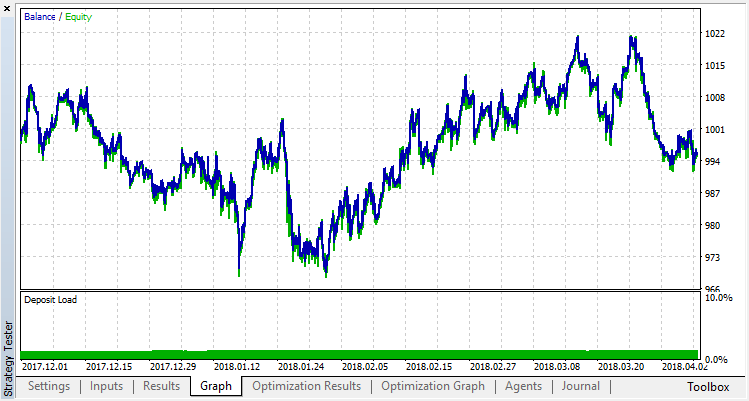
El modelo se ha entrenado peor (se ha añadido más ruido), pero no hemos podido librarse del reentrenamiento global. Es evidente que este modo de regularización conviene sólo para los parámetros estacionarios en los que las regularidades no se cambian con el tiempo. Vemos otro factor muy negativo, es que hay 3 osciladores en la entrada del modelo, y además se correlacionan entre sí.
Sacando conclusiones del artículos
Mi propósito era demostrar las posibilidades de la aplicación del bosque aleatorio para la aproximación de alguna función. En nuestro caso, la función de las indicaciones de los indicadores era la señal de compra o de venta. Además, hemos considerado 2 tipos del aprendizaje supervisado: clasificación y regresión; y ha sido aplicado un enfoque no estándar en el aprendizaje con los ejemplos de entrenamiento desconocidos previamente, que se seleccionan automáticamente, en el proceso de la optimización. En general, el proceso parece a una optimización común en el Probador de Estrategias (nube), y para el algoritmo serán suficientes algunas iteraciones, sin que tengamos preocuparse del número de parámetros a optimizar. Es un plus indudable de la aplicación del enfoque. La desventaja del modelo es su reentrenamiento al seleccionar una estrategia incorrecta, equivale a la sobreoptimización de parámetros.
Por tradición, nombraré posibles caminos para mejorar la estrategia (es que la implementación actual es sólo una estructura cruda).
- Aumentar el número de parámetros a optimizar (optimización de varias funciones de pertenencia).
- Añadir diferentes predictores de importancia.
- Aplicar otros modos de recompensa del agente.
- Crear varios agentes que compiten entre sí para aumentar el espacio de opciones.
A continuación, se adjuntan los códigos fuente del EA autoenseñable.
Para el trabajo y compilación del EA, es necesario cargar la biblioteca MT4Orders y la librería actualizada Fuzzy.
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/3856
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
 Visualización de los resultados de la optimización según el criterio seleccionado
Visualización de los resultados de la optimización según el criterio seleccionado
 Trabajando con los resultados de la optimización mediante la interfaz gráfica
Trabajando con los resultados de la optimización mediante la interfaz gráfica
 Aplicando el método de Monte Carlo para optimizar estrategias comerciales
Aplicando el método de Monte Carlo para optimizar estrategias comerciales
 Sincronización de varios gráficos del mismo símbolo en timeframes diferentes
Sincronización de varios gráficos del mismo símbolo en timeframes diferentes
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Is there any problem with the algorithm?
I am constantly getting the error zero divide on on "dataanalysis.mqh"!
I' have made my own multi-symbol version... but this error is a pain in the ass!
Some help would be grateful.
reguards.
Creo que este EA en el artículo es muy buen resultado
pero en cuenta real con dinero real ¿Cuál es el problema de esta EA necesita ser fijo
u otra pregunta ¿cuál es el punto débil de esta necesidad EA para desarrollar o fijar o actualizar a mejor
¿Puede alguien ayudar a sugerencia?
Gracias
Gracias por abrirme los ojos a la biblioteca Alglib que no me di cuenta viene con la última versión de Metatrader 5....
¡Me encontré reinventando la rueda un poco!
Hola, este artículo es fascinante. Sin embargo, cuando intento compilar el modelo de regresión de bosque de decisión aleatoria, se producen 93 errores.
El primer error es un error de identificador no declarado. La variable que intenta ser llamada es la propiedad m_buffsize del RDF.
La llamada es desde el manejador de eventos OnTester. He incluido un extracto del código.
¿Cuál es la mejor manera de resolverlo?
Fig 1: Algunos de los errores arrojados durante la compilación.