Discussão do artigo "Floresta de Decisão Aleatória na Aprendizagem por Reforço"
if(ts<0.4 && CheckMoneyForTrade(_Symbol,lots,ORDER_TYPE_BUY)) { if(OrderSend(Symbol(),OP_BUY,lots,SymbolInfoDouble(_Symbol,SYMBOL_ASK),0,0,0,NULL,OrderMagic,Green)) { updatePolicy(ts); }; }
Você pode substituí-la por esta
if((ts<0.4) && (OrderSend(Symbol(),OP_BUY,lots,SymbolInfoDouble(_Symbol,SYMBOL_ASK),0,0,0,NULL,OrderMagic,INT_MIN) > 0)) updatePolicy(ts);
A propósito, sua variante da verificação if(OrderSend) sempre funcionará. Porque o OrderSend não retorna zero em caso de erro.
Infelizmente, é exatamente isso que temos de fazer. Dê uma olhada neste artigo, que tem uma maneira interessante de "passar" dados para os agentes.

- 2018.02.27
- Aleksey Zinovik
- www.mql5.com
Infelizmente, é exatamente isso que temos de fazer. Dê uma olhada neste artigo, que tem uma maneira interessante de "passar" dados para os agentes.
Sim, eu o vi, é um ótimo artigo. Decidi não fazer nada extravagante, pois o desempenho está bom assim, não precisei de muitas passagens.
Você pode substituí-lo pelo seguinte
A propósito, sua variante da verificação if(OrderSend) sempre funcionará. Porque o OrderSend não retorna zero em caso de erro.
Obrigado, assim está melhor (e eu me esqueci do nulo). Vou corrigi-lo mais tarde
Respeito ao autor por um ótimo exemplo de implementação de ML usando ferramentas MQL nativas e sem nenhuma muleta!
Minha única opinião IMHO é sobre o posicionamento desse exemplo como aprendizado por reforço.
Em primeiro lugar, parece-me que o reforço deve ter um efeito dependente da dose na memória do agente, ou seja, nesse caso, no RDF, mas aqui ele apenas filtra as amostras da amostra de treinamento e praticamente não é muito diferente de preparar dados para treinamento com um professor.
Em segundo lugar, o treinamento em si não é de fluxo contínuo, mas único, porque após cada passagem do testador, durante o processo de otimização, todo o sistema é treinado novamente, sem mencionar o tempo real.
Respeito ao autor por um ótimo exemplo de implementação de ML usando ferramentas MQL nativas e sem nenhuma ajuda!
Minha única opinião é sobre o posicionamento desse exemplo como aprendizado por reforço.
Em primeiro lugar, parece-me que o reforço deve afetar de forma dependente a memória do agente, ou seja, neste caso, o RDF, mas aqui ele apenas filtra as amostras da amostra de treinamento e não é praticamente muito diferente de preparar dados para treinamento com um professor.
Em segundo lugar, o treinamento em si não é de fluxo contínuo, mas ad hoc, pois após cada passagem do testador, durante o processo de otimização, todo o sistema é treinado novamente, e não estou falando de tempo real.
É isso mesmo, este é um exemplo simples de granulação grossa, mais voltado para a familiaridade de andaimes do que para o aprendizado por reforço. Acho que vale a pena desenvolver mais o tópico e analisar outras formas de reforço.
Informativo, obrigado!
Em primeiro lugar, parece-me que o reforço deveria dosar a memória do agente, ou seja, nesse caso, o RDF, mas aqui ele está apenas filtrando as amostras de treinamento e é quase nada diferente dos dados de treinamento para o aprendizado com um professor.
Em segundo lugar, o treinamento em si não é de fluxo contínuo, mas de uma só vez, porque depois de cada passagem do testador, no processo de otimização, todo o sistema é treinado novamente, e não estou falando de tempo real.
Gostaria de acrescentar um pouco à sua resposta. Esses dois pontos estão intimamente relacionados. Essa versão é uma variação do tema de repetição de experiência. Isso não atualizaria constantemente a tabela e não treinaria novamente a floresta (o que consumiria mais recursos), e treinaria novamente apenas no final, em uma nova experiência. Ou seja, essa é uma variante completamente legítima do reforço e é usada, por exemplo, no DeepMind para jogos de atari, mas lá tudo é mais complicado e minilotes são usados para combater o excesso de ajuste.
Para tornar o aprendizado contínuo, seria bom ter um NS com aprendizado adicional; estou pensando em redes bayesianas. Se você ou alguém tiver exemplos de tais redes em vantagens, eu ficaria grato :)
Mais uma vez, se não houver possibilidade de o aproximador ser retreinado, então, para uma atualização em tempo real, eu teria que arrastar toda a matriz de estados passados, e apenas retreinar toda a amostra todas as vezes não é uma solução muito elegante e lenta (com o aumento do número de estados e recursos)
Além disso, eu gostaria de combinar Q-phrase e NN com mql, mas não entendo por que usá-lo e fazer ciclos com probabilidades de transição de estado para estado, quando posso me limitar à estimativa de diferença temporal usual, como neste artigo. Portanto, o ator-crítico é mais apropriado aqui.
Quero acrescentar um pouco mais à resposta. Esses dois pontos estão intimamente relacionados. Essa versão é uma variação do tema de repetição de experiência. Isso não atualizaria constantemente a tabela e não treinaria novamente a floresta (o que consumiria mais recursos), e treinaria novamente apenas no final, em uma nova experiência. Ou seja, essa é uma variante completamente legítima de reforço e é usada, por exemplo, no DeepMind para jogos de atari, mas lá tudo é mais complicado e minilotes são usados para combater o excesso de ajuste.
Para fazer o streaming do aprendizado, seria bom ter um NS com aprendizado adicional, e estou pensando em redes bayesianas. Se você ou outra pessoa tiver exemplos de tais redes em vantagens, ficarei grato :)
Mais uma vez, se não houver possibilidade de o aproximador ser retreinado, então, para uma atualização em tempo real, você terá que arrastar toda a matriz de estados passados, e o simples retreinamento de toda a amostra a cada vez não é uma solução muito elegante e lenta (com o aumento do número de estados e recursos).
Além disso, eu gostaria de combinar Q-phrase e NN com mql, mas não entendo por que usá-lo e fazer ciclos com probabilidades de transição de estado para estado, quando posso me limitar à estimativa de diferença temporal usual, como neste artigo. Portanto, a crítica ao ator está mais relacionada ao tópico aqui.
Não discuto, talvez a variante com reprodução de experiência, na forma de aprendizado em lote, seja uma implementação legítima da RL, mas também é uma demonstração de uma de suas principais desvantagens - atribuição de crédito de longo prazo. Já que a recompensa (reforço) ocorre com um atraso, o que pode ser ineficiente.
Ao mesmo tempo, outra desvantagem bem conhecida na forma de violação do equilíbrio - exploração vs. explotação, porque até o final da passagem, toda a experiência só pode ser acumulada e não pode ser usada de forma alguma na sessão de operação atual. Portanto, na minha opinião, é provável que, na RL, sem aprendizado contínuo, nada de bom aconteça.
Com relação a novos exemplos de redes, se estivermos falando da P-net, que mencionei aqui no fórum, ela ainda é NDA, portanto não posso compartilhar o código-fonte. Tecnicamente, há, é claro, seus prós e contras, do lado positivo - alta velocidade de aprendizado, trabalho com diferentes objetos de dados, treinamento adicional no futuro, talvez LSTM.
No momento, há uma biblioteca para Python e um gerador nativo de EA para MT4, todos em fase de teste. Para a codificação direta, há uma variante do uso do interpretador Python incorporado ao mecanismo, com o qual é possível trabalhar por meio de blocos de código passados diretamente do EA por meio de canais nomeados.
Com relação à implementação pura da RL em MQL, não sei, intuitivamente parece que ela deve estar na construção dinâmica de árvores de decisão (árvores de políticas) ou em manipulações com matrizes de pesos entre MLPs, talvez modificações com base nas classes correspondentes de Alglib....
Muito bem, Mikhail, você está a 20% do caminho do sucesso. Isso é um elogio, os outros 3% já passaram. E você está indo na direção certa.
Muitas pessoas adicionam mais 84 indicadores a um Expert Advisor com 37 indicadores e pensam "agora vai funcionar de verdade". Ingênuo.
E agora vamos ao que interessa. Você tem um diálogo apenas entre máquina e máquina. Na minha opinião, você deveria adicionar máquina - humano - máquina.
Vou explicar. Na teoria dos jogos, os jogos estratégicos têm os seguintes atributos: um grande número de fatores aleatórios, regulares e psicológicos.
Psicológicos - é como: há filmes bons, há filmes ruins e há filmes indianos. Você entendeu a ideia?
Se estiver interessado, você perguntará o que fazer em seguida e como fazer isso? Eu responderei - ainda não sei, estou tentando encontrar uma resposta eu mesmo.
Mas se você se concentrar apenas em carros, será como com 84 indicadores: adicionar ou não adicionar, você andará em círculos.
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Novo artigo Floresta de Decisão Aleatória na Aprendizagem por Reforço foi publicado:
A Floresta Aleatória (RF), com o uso de bagging, é um dos métodos mais poderosos de aprendizado de máquina, o que é ligeiramente inferior ao gradient boosting. Este artigo tenta desenvolver um sistema de negociação de autoaprendizagem que toma decisões com base na experiência adquirida com a interação com o mercado.
Pode-se dizer que uma Floresta Aleatória é um caso especial de bagging, onde as árvores de decisão são usadas como a família base. Ao mesmo tempo, ao contrário do método convencional de construção de árvores de decisão, o método de poda (pruning) não é utilizado. O método destina-se a construir uma composição a partir de grandes amostras de dados o mais rápido possível. Cada árvore é construída de uma maneira específica. Uma característica (atributo) para a construção de um nó da árvore não é selecionada a partir do número total de características, mas de seu subconjunto aleatório. Ao construir um modelo de regressão, o número de características é n/3. No caso de classificação, ele é √n. Todas estas são recomendações empíricas e são chamadas de decorrelação: diferentes conjuntos de características caem em diferentes árvores, e as árvores são treinadas em diferentes amostras.
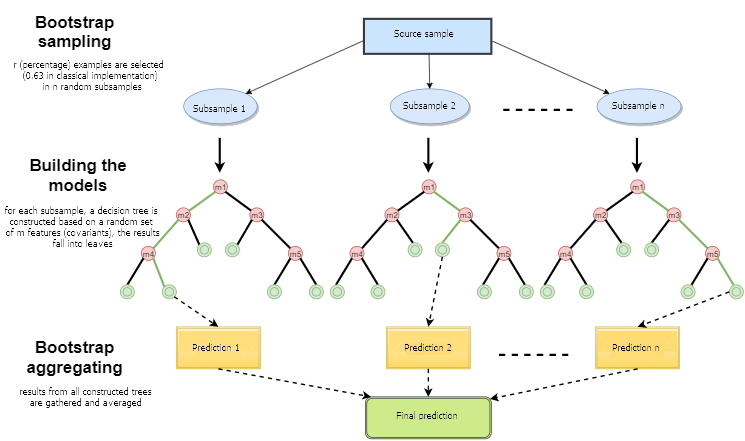
Fig. 1. Esquema operacional da Floresta AleatóriaAutor: Maxim Dmitrievsky