
Redes neurais em trading: Hierarquia de habilidades para comportamento adaptativo de agentes (Conclusão)

Introdução
No artigo anterior, conhecemos os aspectos teóricos do framework HiSSD (Hierarchical and Separate Skill Discovery), que representa uma abordagem moderna para o aprendizado offline em sistemas multiagente capazes de operar em ambientes complexos e altamente dinâmicos. Esse framework permite treinar agentes para interagir de forma eficiente entre si e se adaptar a condições em constante mudança. Inicialmente, o HiSSD foi testado em ambientes simulados; no entanto, as abordagens e a arquitetura propostas o tornam especialmente relevante para aplicação nos mercados financeiros, onde a situação pode se alterar drasticamente em questão de segundos, exigindo dos agentes de negociação inteligentes uma resposta rápida e coordenada.
Uma das principais vantagens do HiSSD é sua alta adaptabilidade. No contexto do trading, quando indicadores econômicos, o comportamento dos participantes do mercado ou as notícias podem modificar repentinamente o cenário, os agentes treinados com o HiSSD são capazes de se ajustar instantaneamente sem a necessidade de um novo treinamento completo. Isso é possível graças à arquitetura baseada em uma divisão de habilidades em dois níveis: gerais e específicas. As habilidades gerais correspondem a padrões de comportamento aplicáveis em diversas situações, como o reconhecimento de tendências de mercado ou a avaliação de risco. As habilidades específicas são responsáveis por ações em condições únicas ou altamente especializadas. Essa estrutura em dois níveis permite que os agentes HiSSD atuem de maneira estável e eficiente, independentemente das mudanças nas condições do mercado.
Outra característica marcante do HiSSD é sua escalabilidade. Os mercados financeiros são, por natureza, sistemas multiagente. Cada participante — seja uma pessoa, um robô de negociação ou um grande market maker — influencia a dinâmica do mercado. Nessas circunstâncias, é essencial ter a capacidade de escalar o sistema sem comprometer sua coerência. O HiSSD propõe uma arquitetura hierárquica, na qual cada agente pode coordenar seu comportamento com os demais por meio de módulos de controle compartilhados. Isso se mostra particularmente útil na construção de estratégias complexas. Na prática, essa abordagem permite desenvolver sistemas de negociação mais confiáveis e resilientes.
A visualização autoral da arquitetura do framework HiSSD é apresentada abaixo.
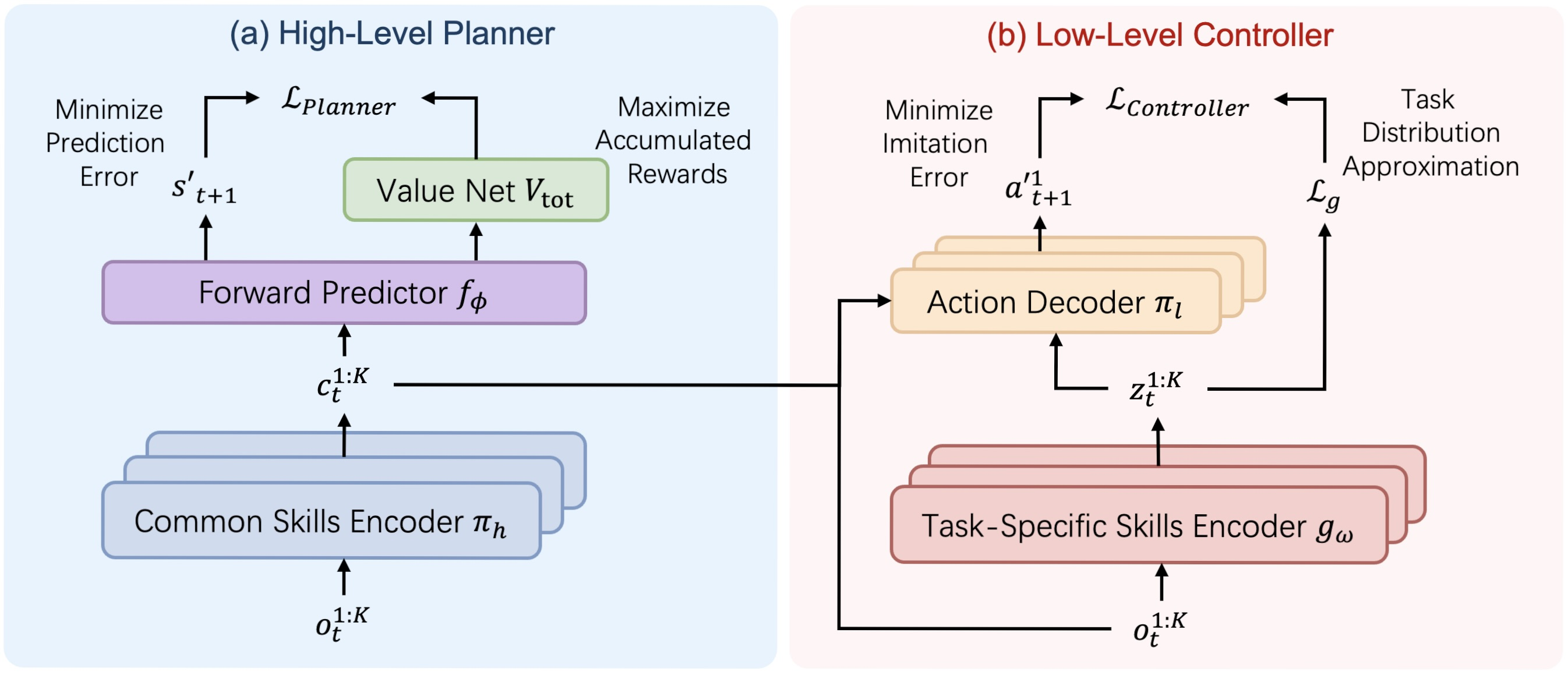
Na parte prática do artigo anterior, iniciamos o trabalho de implementação, utilizando os recursos do MQL5, de uma versão própria das abordagens propostas pelos autores do framework. Em particular, foi apresentada uma variante de implementação de um codificador universal de habilidades, construída dentro do objeto CNeuronSkillsEncoder. Hoje daremos continuidade a esse trabalho e o levaremos à sua conclusão lógica, testando a eficácia das abordagens implementadas em dados históricos reais.
Antes, porém, de prosseguir com a implementação da nossa própria visão das abordagens propostas pelos autores do framework, proponho revisarmos novamente a estrutura do HiSSD. Observamos aqui dois grandes blocos: Planejador e Controlador.
O primeiro possui um fluxo linear de informações. Os dados brutos passam por um codificador de habilidades gerais, que os transfere para o módulo preditivo, responsável por prever o estado subsequente e o valor esperado. Essa arquitetura pode ser construída com os recursos já existentes, sob a forma de um modelo linear.
A situação é um pouco mais complexa no que diz respeito à organização do trabalho do Controlador. Em sua estrutura, podemos destacar o decodificador de ações dos agentes, que recebe dados brutos provenientes de três fontes. Entre elas, as observações locais dos agentes, as habilidades gerais e as habilidades específicas, geradas por diferentes codificadores de habilidades. Essa característica nos leva à necessidade de construir o Controlador como um objeto separado.
Objeto do Controlador
O próximo passo do nosso trabalho será a construção do objeto Controlador, cujo funcional será implementado dentro do objeto CNeuronHiSSDLowLevelControler.
class CNeuronHiSSDLowLevelControler: public CNeuronConvOCL { protected: uint iTaskSkills; uint iCommonSkills; //--- CNeuronSkillsEncoder cTaskSpecificSkillsEncoder; CNeuronTransposeOCL cTranspose; CNeuronBaseOCL cObservAndSkillsConcat; CNeuronBatchNormOCL cNormalizarion; CNeuronConvOCL cActionDecoder[2]; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *second) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None ) override; public: CNeuronHiSSDLowLevelControler(void) {}; ~CNeuronHiSSDLowLevelControler(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint time_step, uint variables, uint task_skills, uint common_skills, uint n_actions, uint window, uint step, uint window_key, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronHiSSDLowLevelControler; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
Aqui, vale destacar que o decodificador de ações do agente no Controlador do framework HiSSD pressupõe o funcionamento paralelo de vários agentes independentes. Esse funcional pode ser implementado por meio de camadas convolucionais sequenciais. E como o decodificador está localizado na saída do módulo, podemos executar o funcional da última camada do decodificador utilizando os recursos da classe pai. É exatamente por esse motivo que escolhemos o objeto de camada convolucional como classe pai na criação do módulo do Controlador.
Na estrutura apresentada do novo objeto, vemos diversos objetos internos, cujo funcional será detalhadamente explorado durante a construção dos algoritmos de propagação para frente e propagação reversa. Aqui também vale ressaltar que eles são declarados de forma estática, o que nos permite deixar o construtor e o destrutor da classe vazios. A inicialização de todos os objetos internos, incluindo os herdados, é realizada no método Init.
Como de costume, os parâmetros do método de inicialização recebem um conjunto de constantes que permitem interpretar de forma inequívoca a arquitetura do objeto necessário.
bool CNeuronHiSSDLowLevelControler::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint time_step, uint variables, uint task_skills, uint common_skills, uint n_actions, uint window, uint step, uint window_key, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronConvOCL::Init(numOutputs, myIndex, open_cl, window_key, window_key, n_actions, 1, variables, optimization_type, batch)) return false; SetActivationFunction(SIGMOID);
No corpo do método, como já é de costume, chamamos imediatamente o método homônimo da classe pai. E aqui é importante destacar alguns pontos-chave.
Antes de tudo, supomos utilizar o funcional da classe pai como a camada final do decodificador de ações dos agentes. Consequentemente, os métodos da classe pai receberão como entrada os resultados do pré-processamento dos objetos internos do decodificador. Dentro do decodificador, espera-se a organização de fluxos paralelos de informação durante o processo de formação da "consciência" de cada agente individual. Por essa razão, a janela dos dados analisados e o passo da camada convolucional criada devem corresponder à dimensionalidade do vetor do fluxo interno de informação de um agente específico.
Na saída da camada, esperamos obter um tensor de ações dos agentes. Portanto, o número de filtros da camada convolucional é igual ao tamanho do vetor de ações de um único agente.
E há mais um ponto importante. Com o objetivo de organizar o aprendizado completamente independente dos agentes, devemos fornecer a cada um parâmetros de peso exclusivos. Para isso, definimos uma dimensionalidade unitária para a sequência analisada e transferimos o número de agentes em treinamento para o parâmetro que indica a quantidade de sequências unitárias. Esse procedimento simples nos permite implementar o trabalho paralelo do número necessário de agentes totalmente independentes.
Em seguida, passamos para a inicialização dos objetos declarados na estrutura da nova classe. Lembro que a inicialização dos objetos herdados é realizada no método homônimo da classe pai, que já foi chamado anteriormente.
Primeiro, inicializamos o codificador de habilidades específicas, cuja função é desempenhada pelo codificador universal de habilidades que criamos no artigo anterior.
int index = 0; if(!cTaskSpecificSkillsEncoder.Init(0, index, OpenCL, time_step, variables, task_skills, window, step, window_key, heads, optimization, iBatch)) return false; cTaskSpecificSkillsEncoder.SetActivationFunction(None);
Depois disso, armazenamos as constantes necessárias para descrever a arquitetura do objeto.
iTaskSkills = task_skills; iCommonSkills = MathMax(common_skills, 1);
Observe que mantemos a dimensionalidade das habilidades específicas conforme está, enquanto para as habilidades gerais definimos o valor mínimo permitido. Aqui, tudo é bastante direto. O motivo é que a dimensionalidade das habilidades específicas já foi passada anteriormente nos parâmetros do método de inicialização do codificador, e a execução bem-sucedida desse método confirma a validade do valor obtido. Já o tensor das habilidades gerais será recebido do Planejador, que nesta implementação é outro objeto, e até mesmo outro modelo. Por isso, podemos apenas especificar o valor mínimo permitido.
No próximo estágio, passamos à implementação do funcionamento do decodificador de ações dos agentes. Os autores do framework HiSSD propõem que o decodificador receba informações de três fontes de dados:
- observações locais do agente;
- habilidades gerais;
- habilidades específicas.
Como já mencionado anteriormente, o tensor das habilidades gerais será obtido de outro modelo, por meio do segundo fluxo de informação. As habilidades específicas são formadas pelo codificador inicializado acima, com base nas observações locais do agente, recebidas através do fluxo principal de informação. Portanto, neste estágio, já dispomos de todos os dados necessários. Resta apenas reuni-los em um único objeto.
No entanto, é importante observar que cada agente deve receber seu próprio conjunto exclusivo de informações. Isso significa que precisamos organizar a concatenação correta dos dados. Os tensores de habilidades são apresentados sob a forma de uma “matriz imaginária”, cujas linhas correspondem aos vetores de habilidades de agentes individuais. A concatenação linha a linha nos permitirá obter a matriz desejada de dados brutos, adequada para a implementação de fluxos de informação paralelos e independentes utilizando o funcional das camadas convolucionais.
A situação é um pouco diferente no caso do tensor das observações locais. Já comentamos que, assim como antes, os dados de entrada planejados consistem em uma série temporal multimodal. Nesse caso, cada agente recebe sua própria sequência unitária para análise. E, antes de adicioná-las às habilidades, precisamos transpor a matriz para uma representação mais conveniente para a análise dessas sequências unitárias.
index++; if(!cTranspose.Init(0, index, OpenCL, time_step, variables, optimization, iBatch)) return false;
Em seguida, definimos a dimensionalidade do vetor de dados brutos de um agente e inicializamos o objeto responsável pelo armazenamento do tensor concatenado.
uint window_size = (time_step + iTaskSkills + iCommonSkills); index++; if(!cObservAndSkillsConcat.Init(0, index, OpenCL, window_size * iVariables, optimization, iBatch)) return false; cObservAndSkillsConcat.SetActivationFunction(None);
Vale reforçar novamente o uso de dados provenientes de três fontes. Para trazê-los a uma forma comparável, utilizamos uma camada de normalização em lote (batch normalization).
index++; if(!cNormalizarion.Init(0, index, OpenCL, cObservAndSkillsConcat.Neurons(), iBatch, optimization)) return false; cNormalizarion.SetActivationFunction(None);
Após concluir o trabalho com os objetos de preparação dos dados, passamos diretamente à criação das camadas neurais do decodificador de ações. Para isso, organizamos um pequeno laço, dentro do qual inicializamos as camadas convolucionais do decodificador. Os princípios de inicialização foram detalhados anteriormente, durante a chamada do método de inicialização da classe pai.
for(uint i = 0; i < cActionDecoder.Size(); i++) { index++; if(!cActionDecoder[i].Init(0, index, OpenCL, window_size, window_size, window_key, 1, iVariables, optimization, iBatch)) return false; cActionDecoder[i].SetActivationFunction(SoftPlus); window_size = window_key; } //--- return true; }
Depois disso, encerramos o método retornando o resultado lógico da execução das operações ao programa que o chamou.
No próximo estágio, avançamos para a construção do algoritmo de propagação para frente dentro do método feedForward. Como já mencionado, aqui trabalhamos com duas fontes de dados. Pelo fluxo principal de informação, recebemos a série temporal multimodal que descreve o estado do ambiente, e pelo fluxo auxiliar de informação, recebemos o tensor das habilidades gerais.
bool CNeuronHiSSDLowLevelControler::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!SecondInput) return false;
No corpo do método, primeiramente verificamos a validade do ponteiro recebido para o objeto do tensor de habilidades gerais. Nesse momento, não verificamos a validade do ponteiro para o objeto do fluxo principal de informação. Em vez disso, simplesmente o passamos para o método homônimo do codificador de habilidades específicas, dentro do qual já está organizada a verificação correspondente.
if(!cTaskSpecificSkillsEncoder.FeedForward(NeuronOCL)) return false;
Após a geração do tensor de habilidades específicas, transpondo o tensor que descreve o estado do ambiente, fazemos a concatenação linha a linha com as duas matrizes de habilidades (gerais e específicas).
if(!cTranspose.FeedForward(NeuronOCL)) return false; if(!Concat(cTranspose.getOutput(), cTaskSpecificSkillsEncoder.getOutput(), SecondInput, cObservAndSkillsConcat.getOutput(), cTranspose.GetCount(), iTaskSkills, iCommonSkills, iVariables)) return false;
Os dados reunidos são então normalizados e processados por três camadas do decodificador de ações dos agentes, ao final das quais obtemos o resultado esperado, um tensor concatenado representando as ações de todos os agentes.
if(!cNormalizarion.FeedForward(cObservAndSkillsConcat.AsObject())) return false; CNeuronBaseOCL *neuron = cNormalizarion.AsObject(); for(uint i = 0; i < cActionDecoder.Size(); i++) { if(!cActionDecoder[i].FeedForward(neuron)) return false; neuron = cActionDecoder[i].AsObject(); } //--- return CNeuronConvOCL::feedforward(neuron); }
Concluímos o método retornando o resultado lógico de execução ao programa que o chamou.
Em seguida, passamos à organização dos processos de propagação reversa. Como já sabemos, esse processo é dividido em duas etapas:
- distribuição do gradiente do erro entre todos os componentes do processo, de acordo com sua influência sobre o resultado final do modelo;
- otimização dos parâmetros do modelo, visando reduzir o erro.
A primeira etapa é organizada no método calcInputGradients. Nos parâmetros desse método, recebemos os ponteiros para os objetos dos dois fluxos de dados de entrada e seus respectivos gradientes de erro. A validade dos ponteiros recebidos é verificada imediatamente.
bool CNeuronHiSSDLowLevelControler::calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = -1) { if(!NeuronOCL || !SecondGradient) return false;
O processo de distribuição dos gradientes de erro é estruturado em total conformidade com os fluxos de informação da propagação para frente, apenas com a diferença de que, agora, a informação é transmitida na direção inversa. A propagação para frente foi concluída com a execução do decodificador de ações. Assim, iniciamos a distribuição dos gradientes de erro a partir do decodificador, percorrendo suas camadas convolucionais novamente, porém em ordem inversa.
uint total = cActionDecoder.Size(); if(total <= 0) return false; CObject *neuron = cActionDecoder[total - 1].AsObject(); //--- if(!CNeuronConvOCL::calcInputGradients(neuron)) return false; for(int i = int(total - 2); i >= 0; i--) { if(!cActionDecoder[i].calcHiddenGradients(neuron)) return false; neuron = cActionDecoder[i].AsObject(); }
Os valores obtidos passam pela camada de normalização de dados até o nível do tensor concatenado das três entidades.
if(!cNormalizarion.calcHiddenGradients(neuron)) return false; if(!cObservAndSkillsConcat.calcHiddenGradients(cNormalizarion.AsObject())) return false;
Em seguida, distribuímos os gradientes de erro entre os três fluxos de informação por meio da desconcatenação dos dados.
if(!DeConcat(cTranspose.getGradient(), cTaskSpecificSkillsEncoder.getGradient(), SecondGradient, cObservAndSkillsConcat.getGradient(), cTranspose.GetCount(), iTaskSkills, iCommonSkills, iVariables)) return false;
É importante observar que cada fluxo de informação pode possuir sua própria função de ativação. Portanto, verificamos a existência dessas funções em todos os fluxos e, se necessário, ajustamos os valores obtidos de acordo com as derivadas correspondentes das funções de ativação.
if(SecondActivation != None) { if(!DeActivation(SecondInput, SecondGradient, SecondGradient, SecondActivation)) return false; } if(NeuronOCL.Activation() != None) { if(!DeActivation(cTranspose.getOutput(), cTranspose.getGradient(), cTranspose.getGradient(), NeuronOCL.Activation())) return false; } if(cTaskSpecificSkillsEncoder.Activation() != None) { if(!DeActivation(cTaskSpecificSkillsEncoder.getOutput(), cTaskSpecificSkillsEncoder.getGradient(), cTaskSpecificSkillsEncoder.getGradient(), cTaskSpecificSkillsEncoder.Activation())) return false; }
Neste ponto, já transmitimos o gradiente de erro para o canal auxiliar do fluxo de dados de entrada, e podemos deixá-lo de lado. Resta agora somar o erro na via principal dos dados de entrada, considerando ambos os fluxos de informação. Primeiro, processamos os dados através do codificador de habilidades específicas.
if(!NeuronOCL.calcHiddenGradients(cTaskSpecificSkillsEncoder.AsObject())) return false;
Depois disso, substituímos o ponteiro do buffer de gradientes de erro do objeto dos dados de entrada e conduzimos o gradiente de erro pelo segundo fluxo de informação, partindo do objeto de transposição.
CBufferFloat *temp = NeuronOCL.getGradient(); if(!NeuronOCL.SetGradient(cTranspose.getPrevOutput(), false) || !NeuronOCL.calcHiddenGradients(cTranspose.AsObject()) || !SumAndNormilize(temp, NeuronOCL.getGradient(), temp, iVariables, false, 0, 0, 0, 1) || !NeuronOCL.SetGradient(temp, false)) return false; //--- return true; }
Os dados provenientes dos dois fluxos de informação são somados, e os ponteiros dos buffers de dados são retornados ao seu estado original.
Agora podemos encerrar o método com segurança, mas antes retornamos o resultado lógico da execução das operações ao programa que o chamou.
Com isso, concluímos a análise dos algoritmos que representam nossa visão sobre o funcionamento do Controlador. O código completo do novo objeto e de todos os seus métodos pode ser consultado no anexo.
Arquitetura das modelos
Após finalizar a construção dos objetos individuais do framework HiSSD, passamos à descrição da arquitetura das modelos que serão treinadas. E aqui é importante observar que planejamos treinar quatro modelos ao mesmo tempo.
A primeira delas é o Codificador do estado do ambiente, que neste caso desempenha o papel de Planejador dentro do framework HiSSD. Pretendemos treiná-lo no estilo de aprendizado supervisionado. A partir do estado do ambiente analisado, são geradas as habilidades gerais dos agentes. Com base nas habilidades obtidas, será gerada a previsão dos estados futuros do ambiente dentro de um horizonte de planejamento definido.
Aqui, pode-se notar um leve desvio em relação à visão original dos autores do framework HiSSD. Pois, segundo o conceito proposto, o planejamento envolve apenas o próximo estado. No entanto, nosso objetivo é treinar uma política capaz de abrir uma posição e mantê-la por um determinado tempo, o que exige uma análise mais profunda e um planejamento mais prolongado.
A segunda modelo é o Controlador, responsável por analisar o estado atual do ambiente e gerar o tensor de ações de múltiplos agentes.
A terceira modelo é o Gerente (Ator). Em nossa implementação, essa modelo analisa o estado da conta, avalia as opções de ação propostas pelos agentes do Controlador e, com base nessa análise, toma a decisão de realizar ou não uma operação de trading.
Por fim, a quarta é a modelo preditiva, responsável por determinar a probabilidade da direção do próximo movimento de preço.
A arquitetura de todas as modelos treináveis é apresentada no método CreateDescriptions.
bool CreateDescriptions(CArrayObj *&encoder, CArrayObj *&task, CArrayObj *&actor, CArrayObj *&probability) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!task) { task = new CArrayObj(); if(!task) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; }
Nos parâmetros desse método, recebemos ponteiros para quatro arrays dinâmicos destinados ao registro da descrição da arquitetura de cada modelo correspondente. A validade de todos os ponteiros recebidos é verificada, e, se necessário, novos objetos são criados.
Começamos descrevendo a arquitetura do Codificador do estado do ambiente. Como de costume, na entrada do modelo utilizamos uma camada neural totalmente conectada, de tamanho adequado para registrar os dados brutos.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Os dados brutos são alimentados no modelo e, em seguida, convertidos para uma forma comparável utilizando uma camada de normalização em lote.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Em seguida, vem o objeto do codificador universal de habilidades, que, neste caso, deve gerar o tensor de habilidades gerais.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSkillsEncoder; descr.count = HistoryBars; { int temp[] = {BarDescr, NSkills, 4}; // Variables, Common Skills, Heads if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.window = 8; descr.step = 1; descr.window_out = 32; prev_count = descr.windows[0]; int prev_out = descr.windows[1]; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Logo após, posicionamos duas camadas convolucionais que, com base no tensor de habilidades gerais, planejam o movimento futuro das sequências unitárias individuais da série temporal multimodal analisada.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = prev_out; descr.step = prev_out; prev_out=descr.window_out = 4*NForecast; descr.layers = prev_count; descr.activation = SoftPlus; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = prev_out; descr.step = prev_out; prev_out=descr.window_out = NForecast; descr.layers = prev_count; descr.activation = TANH; if(!encoder.Add(descr)) { delete descr; return false; }
Aqui é importante observar que, a partir do vetor de habilidades gerais de um agente, é construído o comportamento preditivo de uma sequência unitária ao longo de um horizonte de planejamento definido. Assim, na saída do nosso bloco de planejamento, a sequência de dados obtida diferirá da série temporal multimodal original. Para converter os dados na forma necessária, devemos transpor essa sequência.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_out; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Em seguida, aplicamos a normalização reversa para retornar os dados à distribuição original.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = prev_count*prev_out; descr.layers = 1; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Com isso, concluímos a descrição da arquitetura do Codificador do estado do ambiente. No entanto, antes de prosseguir com a próxima modelo, armazenamos o objeto que descreve o estado latente com o tensor de habilidades gerais obtido na saída.
//--- Latent CLayerDescription *latent = encoder.At(LatentLayer); if(!latent) return false;
A segunda modelo, como já mencionado, é o Controlador. Nela são geradas as habilidades específicas dos agentes com base na análise do mesmo estado do ambiente. Por essa razão, copiamos a descrição das duas primeiras camadas da modelo anterior.
//--- Task task.Clear(); //--- Input layer if(!task.Add(encoder.At(0))) { return false; } //--- layer 1 if(!task.Add(encoder.At(1))) { return false; }
Essa modelo é finalizada com o objeto do Controlador construído anteriormente.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronHiSSDLowLevelControler; descr.count = HistoryBars; { int temp[] = {latent.windows[0], // Variables NSkills, // Task Skills latent.windows[1], // Common Skills NActions, // Action Space 4}; // Heads if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.window = 8; descr.step = 1; descr.window_out = 32; prev_count = descr.windows[0]; prev_out = descr.windows[3]; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = SIGMOID; if(!task.Add(descr)) { delete descr; return false; }
A terceira modelo — o Gerente de nível superior — recebe na entrada os vetores que descrevem o estado da conta. Para registrá-los, utilizamos também uma camada neural básica totalmente conectada.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Os valores recebidos são então normalizados.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = AccountDescr; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Em seguida, empregamos um módulo de cross-attention (atenção cruzada) para correlacionar o estado atual da conta com as opções de operações de trading propostas.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossDMHAttention; { int temp[] = {AccountDescr, // Inputs window prev_out // Cross window }; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } { int temp[] = {1, // Inputs units prev_count // Cross units }; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.step = 4; // Heads descr.window_out = 32; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Adicionamos ainda três camadas totalmente conectadas, que formam a chamada “cabeça de tomada de decisão”. Essa estrutura permite transformar as características extraídas em um vetor de ações do Ator.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.batch = 1e4; descr.activation = TANH; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SoftPlus; descr.batch = 1e4; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions; descr.activation = SIGMOID; descr.batch = 1e4; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
A modelo preditiva, responsável por determinar a probabilidade da direção do próximo movimento, analisa as habilidades gerais a partir do estado latente do Planejador. Assim, os parâmetros do objeto correspondente são transferidos para a camada de entrada dos dados.
//--- Probability probability.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = latent.windows[0] * latent.windows[1]; descr.activation = latent.activation; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; }
A análise em si é realizada por um perceptron com duas camadas ocultas totalmente conectadas. Para introduzir não linearidade entre as camadas neurais, utilizam-se diferentes funções de ativação. Os resultados da última camada são ativados por uma função sigmoide, o que nos permite obter a probabilidade do movimento do preço em cada direção.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * LatentCount; descr.activation = SoftPlus; descr.batch = 1e4; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = TANH; descr.batch = 1e4; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions / 3; descr.activation = SIGMOID; descr.batch = 1e4; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- return true; }
Após finalizar a descrição da arquitetura das modelos treináveis, concluímos o método retornando o resultado lógico da execução das operações ao programa que o chamou.
Treinamento das modelos
Neste ponto, já realizamos um trabalho bastante extenso na construção dos algoritmos que representam nossa própria visão da implementação das abordagens propostas pelos autores do framework HiSSD, e agora chegamos à etapa de treinamento do sistema composto por quatro modelos. Assim como foi proposto pelos autores do framework, o treinamento de todas as modelos será realizado simultaneamente em modo offline. Para isso, utilizaremos o conjunto de dados de treinamento coletado nos trabalhos anteriores.
Vale lembrar que, durante a coleta dos dados da amostra de treinamento, foram utilizados dados históricos reais do par de moedas EURUSD referentes a todo o ano de 2024, no timeframe M1. Os parâmetros de todos os indicadores foram mantidos em seus valores padrão.
Voltaremos a esse ponto mais adiante. Por enquanto, concentremo-nos no programa de treinamento das modelos. O treinamento simultâneo das quatro modelos e a implementação dos algoritmos de interação entre elas tornaram necessária a modernização do EA correspondente. Dentro do escopo deste artigo, não analisaremos o código completo do programa, mas focaremos no método de treinamento direto das modelos — Train.
void Train(void) { //--- vector<float> probability = vector<float>::Full(Buffer.Size(), 1.0f / Buffer.Size()); //--- vector<float> result, target, state; matrix<float> fstate = matrix<float>::Zeros(1, NForecast * BarDescr); bool Stop = false; //--- uint ticks = GetTickCount();
Neste método, inicialmente realizamos uma pequena etapa preparatória, na qual é formado o vetor de probabilidades de seleção das trajetórias armazenadas no buffer de replay de experiência. No estágio inicial, considera-se uma distribuição uniforme de probabilidades: cada trajetória possui a mesma chance de ser escolhida para o treinamento.
No entanto, ao final do processamento de cada lote de treinamento, ocorre um ajuste nessa distribuição: a probabilidade de seleção da trajetória já utilizada é reduzida, o que, por sua vez, aumenta o peso das trajetórias ainda não exploradas. Essa estratégia incentiva o modelo a abranger de forma equilibrada todo o conjunto de dados de treinamento, garantindo um aprendizado mais eficiente e uma generalização mais estável.
Neste ponto, também declaramos um conjunto de variáveis locais que serão utilizadas para o armazenamento temporário de dados durante o processo.
Em seguida, passamos à organização do processo de treinamento propriamente dito. Para isso, criamos um sistema de laços aninhados.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter += Batch) { int tr = SampleTrajectory(probability); int start = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast - Batch)); if(start <= 0) { iter -= Batch; continue; } if( !Encoder.Clear() || !Task.Clear() || !Actor.Clear() ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } result = vector<float>::Zeros(NActions);
O laço externo percorre os lotes de treinamento. Nele, primeiro realizamos o *sampling* de uma trajetória a partir do buffer de replay de experiência e selecionamos aleatoriamente, dentro dessa trajetória, o estado do ambiente a partir do qual o lote de treinamento terá início. Depois, organizamos um laço interno responsável pela iteração sequencial dos estados do ambiente dentro do segmento escolhido.
for(int i = start; i < MathMin(Buffer[tr].Total, start + Batch); i++) { if(!state.Assign(Buffer[tr].States[i].state) || MathAbs(state).Sum() == 0 || !bState.AssignArray(state)) { iter -= Batch + start - i; break; }
No corpo do laço interno é onde de fato organizamos o processo de treinamento das modelos. Primeiramente, transferimos a descrição do estado do ambiente selecionado da amostra de treinamento para o buffer de dados, preparando-o para ser alimentado em nossas modelos.
Em seguida, formamos o vetor de marcação temporal (timestamp) correspondente ao estado do ambiente em análise.
bTime.Clear(); double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bTime.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bTime.GetIndex() >= 0) bTime.BufferWrite();
Depois disso, preparamos os dados que descrevem o estado da conta e as posições abertas.
//--- Account float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; float profit = float(bState[0] / _Point * (result[0] - result[3])); bAccount.Clear(); bAccount.Add(1); bAccount.Add((PrevEquity + profit) / PrevEquity); bAccount.Add(profit / PrevEquity); bAccount.Add(MathMax(result[0] - result[3], 0)); bAccount.Add(MathMax(result[3] - result[0], 0)); bAccount.Add((bAccount[3] > 0 ? profit / PrevEquity : 0)); bAccount.Add((bAccount[4] > 0 ? profit / PrevEquity : 0)); bAccount.Add(0); bAccount.AddArray(GetPointer(bTime)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
Com isso, concluímos o processo de preparação dos dados brutos e passamos à execução da propagação para frente das nossas modelos. Primeiro, chamamos o método de propagação para frente do Codificador do estado do ambiente, passando para ele o buffer correspondente com os dados previamente preparados.
//--- Feed Forward if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Em seguida, vem o Controlador, que, além do buffer que descreve o estado do ambiente, analisa também as habilidades gerais provenientes do estado latente do Codificador.
if(!Task.feedForward((CBufferFloat*)GetPointer(bState), 1, false, GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Na entrada do Gerente, enviamos o vetor que descreve o estado da conta, juntamente com os resultados gerados pelo Controlador, que formou o tensor contendo diversas opções de operações de trading.
if(!Actor.feedForward((CBufferFloat*)GetPointer(bAccount), 1, false, GetPointer(Task), -1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
A modelo preditiva, responsável por determinar a direção mais provável do próximo movimento de preço, analisa exclusivamente as habilidades gerais extraídas do estado latente do Codificador.
if(!Probability.feedForward(GetPointer(Encoder), LatentLayer, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Neste estágio, cada modelo realizou a análise dos dados de entrada e produziu seus respectivos resultados. Agora precisamos compará-los com os valores-alvo — mas onde obtê-los?
Na saída do Codificador, esperamos receber uma descrição preditiva dos estados futuros do ambiente. Para formar o tensor dos valores-alvo, extraímos da amostra de treinamento os dados reais dos estados subsequentes e os reorganizamos na ordem necessária.
//--- Look for target target = vector<float>::Zeros(NActions); bActions.AssignArray(target); if(!state.Assign(Buffer[tr].States[i + NForecast].state) || !state.Resize(NForecast * BarDescr) || MathAbs(state).Sum() == 0) { iter -= Batch + start - i; break; } if(!fstate.Resize(1, NForecast * BarDescr) || !fstate.Row(state, 0) || !fstate.Reshape(NForecast, BarDescr)) { iter -= Batch + start - i; break; } for(int j = 0; j < NForecast / 2; j++) { if(!fstate.SwapRows(j, NForecast - j - 1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
Esses dados podem então ser utilizados como valores-alvo para o Codificador do estado do ambiente, permitindo ajustar os parâmetros do modelo na direção da minimização do erro de previsão.
//--- State Encoder Result.AssignArray(fstate); if(!Encoder.backProp(Result, (CBufferFloat*)NULL, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Usamos esses mesmos dados também para construir os valores-alvo das outras modelos, mas de forma mais elaborada. Para gerar a operação de trading ideal, além do movimento de preço futuro — que já foi carregado da amostra de treinamento —, é necessário analisar também a presença de posições abertas. Isso porque, quando há posições abertas, buscamos pontos de saída. Que diferem dependendo de se tratar de uma posição longa ou curta.
target = fstate.Col(0).CumSum(); if(result[0] > result[3]) { float tp = 0; float sl = 0; float cur_sl = float(-(result[2] > 0 ? result[2] : 1) * MaxSL * Point()); int pos = 0; for(int j = 0; j < NForecast; j++) { tp = MathMax(tp, target[j] + fstate[j, 1] - fstate[j, 0]); pos = j; if(cur_sl >= target[j] + fstate[j, 2] - fstate[j, 0]) break; sl = MathMin(sl, target[j] + fstate[j, 2] - fstate[j, 0]); } if(tp > 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = float(MathMin(tp / (MaxTP * Point()), 1)); result[0] = MathMax(result[0] - result[3], 0.011f); result[5] = result[1] = tp; result[4] = result[2] = sl; result[3] = 0; bActions.AssignArray(result); } }
else { if(result[0] < result[3]) { float tp = 0; float sl = 0; float cur_sl = float((result[5] > 0 ? result[5] : 1) * MaxSL * Point()); int pos = 0; for(int j = 0; j < NForecast; j++) { tp = MathMin(tp, target[j] + fstate[j, 2] - fstate[j, 0]); pos = j; if(cur_sl <= target[j] + fstate[j, 1] - fstate[j, 0]) break; sl = MathMax(sl, target[j] + fstate[j, 1] - fstate[j, 0]); } if(tp < 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = float(MathMin(-tp / (MaxTP * Point()), 1)); result[3] = MathMax(result[3] - result[0], 0.011f); result[2] = result[4] = tp; result[1] = result[5] = sl; result[0] = 0; bActions.AssignArray(result); } }
No caso de não haver posições abertas, buscamos pontos de entrada. Nesse processo, primeiro determinamos a direção esperada do movimento do preço e sua intensidade.
else { ulong argmin = target.ArgMin(); ulong argmax = target.ArgMax(); float max_sl = float(MaxSL * Point()); while(argmax > 0 && argmin > 0) { if(argmax < argmin && target[argmax] / 2 > MathAbs(target[argmin]) && MathAbs(target[argmin]) < max_sl) break; if(argmax > argmin && target[argmax] < MathAbs(target[argmin] / 2) && target[argmax] < max_sl) break; target.Resize(MathMin(argmax, argmin)); argmin = target.ArgMin(); argmax = target.ArgMax(); }
Somente depois definimos os parâmetros da operação de trading.
if(argmin == 0 || (argmax < argmin && argmax > 0)) { float tp = 0; float sl = 0; float cur_sl = - float(MaxSL * Point()); ulong pos = 0; for(ulong j = 0; j < argmax; j++) { tp = MathMax(tp, target[j] + fstate[j, 1] - fstate[j, 0]); pos = j; if(cur_sl >= target[j] + fstate[j, 2] - fstate[j, 0]) break; sl = MathMin(sl, target[j] + fstate[j, 2] - fstate[j, 0]); } if(tp > 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = (float)MathMin(tp / (MaxTP * Point()), 1); result[0] = float(MathMax(Buffer[tr].States[i].account[0] / 100 * 0.01, 0.011)); result[5] = result[1] = tp; result[4] = result[2] = sl; result[3] = 0; bActions.AssignArray(result); } }
else { if(argmax == 0 || argmax > argmin) { float tp = 0; float sl = 0; float cur_sl = float(MaxSL * Point()); ulong pos = 0; for(ulong j = 0; j < argmin; j++) { tp = MathMin(tp, target[j] + fstate[j, 2] - fstate[j, 0]); pos = j; if(cur_sl <= target[j] + fstate[j, 1] - fstate[j, 0]) break; sl = MathMax(sl, target[j] + fstate[j, 1] - fstate[j, 0]); } if(tp < 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = (float)MathMin(-tp / (MaxTP * Point()), 1); result[3] = float(MathMax(Buffer[tr].States[i].account[0] / 100 * 0.01, 0.011)); result[2] = result[4] = tp; result[1] = result[5] = sl; result[0] = 0; bActions.AssignArray(result); } } } } }
A “operação de trading ideal” é utilizada exclusivamente para o treinamento do Gerente.
//--- Actor Policy if(!Actor.backProp(GetPointer(bActions), (CNet*)GetPointer(Task), -1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Em seguida, passamos à geração do tensor de valores-alvo do Controlador. É bastante lógico que também façamos uso dos parâmetros da “operação de trading ideal”. No entanto, nela está especificado o volume da operação, o qual não pode ser determinado apenas com base na análise do estado do ambiente — informação disponível apenas ao Controlador. São necessários também os dados sobre o estado atual da conta, que apenas o Gerente possui. Por essa razão, substituímos o valor absoluto do volume da operação pela probabilidade de obtenção de lucro. Para a operação de trading ideal, essa probabilidade de atingir os valores-alvo é igual a 1.
//--- Agents target=result; if(target[0] > 0) target[0] = 1; if(target[3] > 0) target[3] = 1;
A “operação de trading ideal” ajustada é então replicada para o número definido de agentes e transmitida ao Controlador como valores-alvo.
Result.Clear(); for(int i = 0; i < BarDescr; i++) { if(!Result.AddArray(target)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } } if(!Task.backProp(Result, (CNet*)GetPointer(Encoder), LatentLayer) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Vale observar que todos os agentes recebem os mesmos valores-alvo. No entanto, não esperamos que atuem de maneira sincronizada, pois cada um deles analisa apenas os dados das observações locais de sua sequência temporal unitária. Assim, a interpretação unidirecional de um mesmo estado do ambiente por vários agentes potencialmente gera um sinal mais forte para o Gerente.
Resta agora definir os valores-alvo para a modelo preditiva responsável pela determinação do movimento de preço mais provável. Aqui voltamos novamente aos dados dos estados subsequentes do ambiente. Calculamos a soma acumulada da dinâmica do preço e determinamos o maior deslocamento dentro do horizonte de planejamento especificado. A direção desse desvio máximo é então considerada a tendência prioritária, que utilizamos para o treinamento da modelo preditiva.
//--- Probability target = vector<float>::Zeros(NActions / 3); vector<float> trend=fstate.Col(0).CumSum(); ulong argmax=MathAbs(trend).ArgMax(); if(trend[argmax] > 0) target[0] = 1; else if(trend[argmax] < 0) target[1] = 1; if(!Result.AssignArray(target) || !Probability.backProp(Result, (CNet*)GetPointer(Encoder),LatentLayer) || !Encoder.backPropGradient((CBufferFloat*)NULL, (CBufferFloat*)NULL, LatentLayer) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
É importante destacar que, nesse caso, o gradiente de erro é transmitido ao nível das habilidades gerais, ajustando os parâmetros do Codificador. O objetivo é que as habilidades gerais passem a conter informações sobre a tendência prioritária.
Em seguida, informamos o usuário sobre o andamento do processo de treinamento das modelos e passamos para a próxima iteração do sistema de laços.
if(GetTickCount() - ticks > 500) { double percent = double(iter + i - start) * 100.0 / (Iterations); string str = StringFormat("%-12s %6.2f%% -> Error %15.8f\n", "Encoder", percent, Encoder.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Task", percent, Task.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-13s %6.2f%% -> Error %15.8f\n", "Probability", percent, Probability.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Após a execução bem-sucedida de todas as iterações do sistema de laços criado para o treinamento das modelos, registramos no log os resultados do treinamento e iniciamos o processo de finalização do EA.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Encoder", Encoder.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Task", Task.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Probability", Probability.getRecentAverageError()); ExpertRemove(); //--- }
O código completo deste programa está disponível no anexo. Nele também se encontram os programas de coleta da amostra de treinamento e de teste das modelos treinadas. Recomendo examinar de forma independente as pequenas correções realizadas nesses programas.
Testes
Chegamos, então, talvez à etapa mais importante do nosso trabalho — a avaliação da eficiência das soluções implementadas em dados históricos reais. Como já foi mencionado, o treinamento das modelos foi realizado com base em dados reais de mercado referentes a todo o ano de 2024.
Para uma verificação objetiva da qualidade da política desenvolvida, os testes das modelos treinadas foram realizados no testador de estratégias do MetaTrader 5, utilizando dados históricos do período de janeiro a março de 2025. Todos os demais parâmetros — incluindo as condições de mercado, timeframes e configurações de simulação — foram mantidos inalterados, garantindo a correção e a comparabilidade dos resultados.
Os resultados dos testes são apresentados a seguir.


Durante os três meses do período de testes, o modelo realizou 860 operações de trading, das quais 340 foram encerradas com lucro. Isso corresponde a 39,53% de operações lucrativas. No entanto, o lucro médio das operações vencedoras superou em 70% o valor médio das operações perdedoras, o que compensou a baixa taxa de acertos e resultou em lucro ao final do teste.
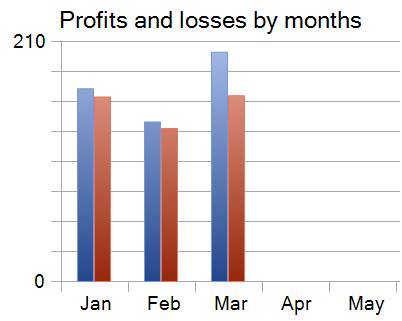
Vale destacar que cada um dos três meses do período de teste foi encerrado com resultado positivo.
Considerações finais
Neste trabalho, exploramos os aspectos do framework HiSSD, adaptado para tarefas de trading algorítmico. A ideia central — a divisão das habilidades em gerais e específicas — demonstrou sua eficácia em um mercado dinâmico e em constante mudança. Essa estrutura possibilitou que os agentes se adaptassem rapidamente às alterações do ambiente sem a necessidade de um novo treinamento completo.
Na implementação, foram levadas em consideração as particularidades dos dados financeiros: o treinamento foi conduzido com cotações históricas reais de 2024, enquanto o teste foi realizado com dados recentes do início de 2025. Isso permitiu avaliar de forma objetiva a eficiência e a estabilidade das modelos em condições próximas à negociação real.
Ainda assim, é importante ressaltar que, antes de aplicar a abordagem em negociações reais, o modelo deve ser treinado em uma amostra mais ampla e representativa, seguida de uma bateria completa de testes e validações.
Referências
- Learning Generalizable Skills from Offline Multi-Task Data for Multi-Agent Cooperation
- Outros artigos da série
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA para coleta de exemplos |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA para coleta de exemplos pelo método Real-ORL |
| 3 | Study.mq5 | Expert Advisor | EA para treinamento das modelos |
| 4 | Test.mq5 | Expert Advisor | EA para teste das modelos |
| 5 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema e da arquitetura das modelos |
| 6 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de redes neurais |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código para programas OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/17739
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso