
Redes neurais em trading: Hierarquia de habilidades para comportamento adaptativo de agentes (HiSSD)

Introdução
O aprendizado por reforço multiagente cooperativo (Multi-Agent Reinforcement Learning — MARL) tornou-se especialmente relevante nos últimos anos. Esse conceito encontra aplicação em diversas áreas, isto é, desde jogos e transporte autônomo até logística, dinâmica social e, o que é particularmente importante, mercados financeiros. Em todos os contextos onde é necessário um comportamento coordenado entre várias estratégias ou agentes, os métodos tradicionais frequentemente se mostram insuficientes. O MARL, em contrapartida, apresenta resultados impressionantes nesses tipos de tarefas.
No entanto, há uma série de desafios. O desenvolvimento de simuladores precisos ou a implementação de uma interação online contínua exige custos consideráveis. Em um ambiente real, os agentes enfrentam condições em constante mudança: o número de participantes varia, assim como os objetivos e os parâmetros do ambiente. Por isso, cresce o interesse em treinar sistemas capazes de se adaptar e transferir conhecimento de uma tarefa para outra, de forma eficiente e sem custos adicionais.
A abordagem clássica consiste em treinar os agentes em uma tarefa e depois realizar um novo treinamento em outra. Mas esse método tem suas limitações. Em primeiro lugar, é necessário um novo e caro processo de interação com o novo ambiente. Em segundo, um modelo treinado para um número fixo de agentes não consegue lidar bem com o escalonamento. Ele se desestabiliza quando a composição dos participantes ou os parâmetros-alvo mudam.
Para enfrentar esses problemas, pesquisadores começaram a utilizar uma arquitetura baseada em Transformer. Ela oferece flexibilidade, até porque o modelo não depende do número de agentes e pode se adaptar a novas condições. Isso se tornou a base para o desenvolvimento de padrões cooperativos de comportamento universais, como habilidades que podem ser transferidas entre tarefas e reutilizadas.
Diversos métodos para a implementação dessas habilidades já foram propostos. Alguns se baseiam em um aprendizado em duas etapas, em que primeiro são extraídos padrões comportamentais gerais e, em seguida, é formada a política. Outros combinam aprendizado offline e online, acelerando a adaptação a novas condições.
Essas abordagens trouxeram resultados notáveis, especialmente na redução dos custos de transferência de modelos para resolver tarefas relacionadas. No entanto, também apresentam pontos fracos. As habilidades universais são úteis, mas ignoram características específicas necessárias para alcançar determinados objetivos. E é justamente nos detalhes que muitas vezes se encontra a chave do sucesso. Além disso, em muitos casos, a estrutura temporal das interações acaba sendo negligenciada. No entanto, a cooperação, como se sabe, não se desenvolve instantaneamente, e sim ao longo do tempo. A sequência de ações, a coerência nos movimentos, tudo isso tem importância.
Para resolver esses problemas, no trabalho "Learning Generalizable Skills from Offline Multi-Task Data for Multi-Agent Cooperation" foi proposto o framework HiSSD — Hierarchical and Separate Skill Discovery. Trata-se de uma nova arquitetura que permite o aprendizado simultâneo de habilidades gerais e específicas. Sem separações artificiais. Sem restrições rígidas. Na estrutura hierárquica, ambas as categorias de conhecimento se desenvolvem em paralelo.
As habilidades gerais descrevem padrões universais de cooperação. Elas permitem que os agentes atuem de forma coordenada mesmo em ambientes desconhecidos. Essas habilidades formam a base, nomeadamente um conjunto de reações comportamentais úteis na maioria das situações. As habilidades específicas, por outro lado, são ajustadas para tarefas concretas. Elas permitem calibrar o comportamento de acordo com os objetivos e condições de cada situação.
O HiSSD é construído sobre o conceito de aprendizado hierárquico simultâneo. Isso proporciona uma compreensão mais profunda dos aspectos temporais das interações e do contexto das tarefas específicas. Como resultado, obtém-se não apenas um comportamento mais qualificado dos agentes, mas também uma transferência de estratégias mais consistente para novas condições.
Os experimentos realizados pelos autores do framework em simuladores populares, como SMAC e MuJoCo, confirmaram a eficácia da abordagem. Mesmo em tarefas novas e previamente desconhecidas, os agentes treinados com o HiSSD demonstraram um comportamento cooperativo estável. Sua estratégia mostrou-se flexível, precisa e confiável.
O algoritmo HiSSD
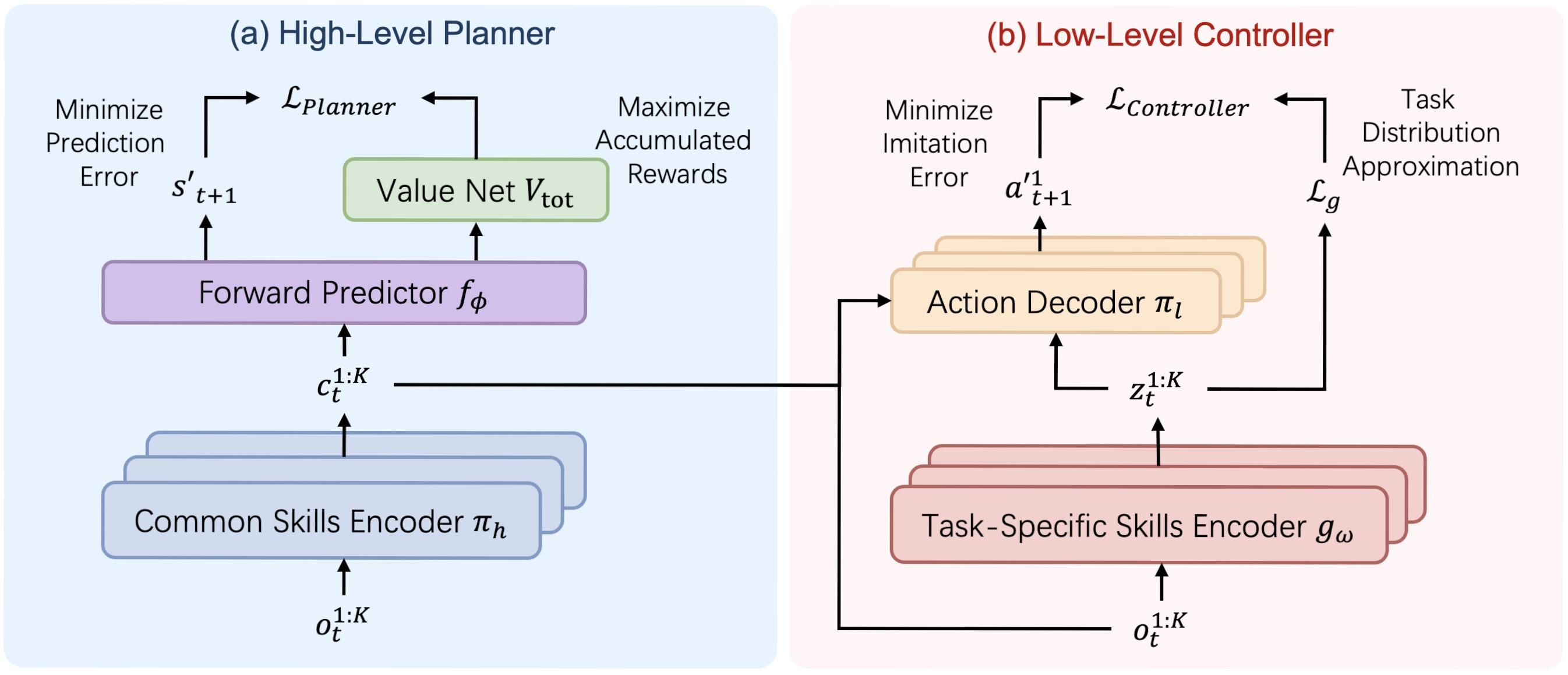
O algoritmo HiSSD (Hierarchical and Separable Skill Discovery) é uma abordagem inovadora para o treinamento de agentes em ambientes multiagente, desenvolvida com o objetivo de garantir a transferibilidade de habilidades entre diferentes tarefas e a estabilidade do comportamento dos agentes na ausência de controle centralizado. A principal ideia do algoritmo está na decomposição hierárquica do comportamento de cada agente em dois componentes-chave: as habilidades comuns (common), aplicáveis a todos os agentes e tarefas, e as habilidades individuais específicas de cada tarefa (task-specific), que permitem adaptar o comportamento conforme o papel ou a missão atribuída.
Uma das diferenças fundamentais do HiSSD em relação a outras abordagens é a possibilidade de treinar simultaneamente todos os módulos do modelo. Isso é essencial: em vez de um treinamento por etapas ou alternado, como é comum em sistemas hierárquicos, aqui todos os componentes (planejador, controlador, codificadores e modelo de avaliação de valor) são treinados em conjunto. Essa sincronia evita problemas de desalinhamento entre os níveis e garante um comportamento dos agentes mais coerente e eficiente.
Durante o treinamento, utiliza-se um dataset offline DT = {Di}, onde cada Di corresponde a uma tarefa específica. A cada passo de tempo, o agente k recebe uma observação ot,k, com base na qual o planejador forma a habilidade geral ct,k:
![]()
Essa habilidade reflete a intenção de alto nível e o plano estratégico geral de comportamento. Em seguida, o codificador de habilidades específicasgω gera a habilidade zt,k a partir das mesmas observações:
![]()
Essas duas habilidades (a geral e a específica) são alimentadas no controlador, que, considerando a observação atual, toma a decisão final sobre a ação do agente:
![]()
O treinamento do modelo de previsão de valor do estado do ambiente baseia-se em uma versão modificada do algoritmo Implicit Q-Learning (IQL), adaptada para o ambiente multiagente. O valor do estado é estimado levando em conta a recompensa total recebida por todos os agentes:
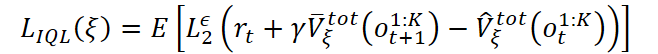
onde é utilizada o erro quadrático truncado:
![]()
Com base na avaliação de valor feita pelo modelo, o planejador é treinado. Seu principal objetivo é selecionar as habilidades gerais que conduzam a estados futuros mais vantajosos. Isso é obtido minimizando uma função de perda que considera tanto o valor do próximo estado quanto a verossimilhança do estado previsto:
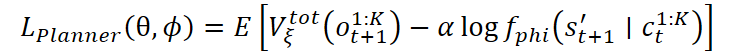
Também é possível usar uma versão exponencial da função de perda:
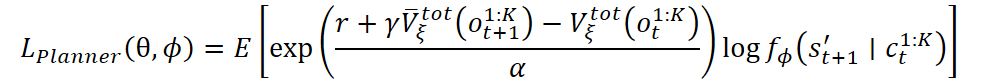
O controlador e o codificador de habilidades específicas são treinados utilizando um autocodificador variacional de codificação comportamental. A ideia é ensinar o controlador a reproduzir as ações a partir das demonstrações, levando em conta a estrutura oculta das tarefas. As perdas incluem o logaritmo da verossimilhança da ação e um termo de regularização na forma de divergência KL:
![]()
Para que as habilidades do agente realmente se diferenciem entre as tarefas, utiliza-se adicionalmente o aprendizado contrastivo. O codificador é treinado de modo que, para cada tarefa, a representação gω(q) fique mais próxima dos exemplos positivos k+ da mesma tarefa do que dos exemplos negativos k- de outras tarefas:
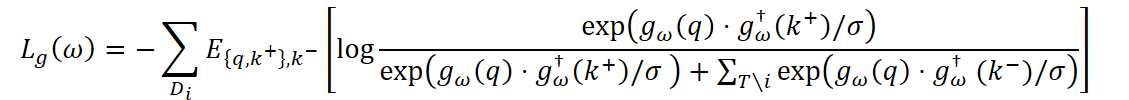
onde σ é o coeficiente de temperatura e gω† é a versão do codificador com média exponencial, utilizada para estabilizar o processo de aprendizado
A função de perda final do controlador soma os componentes comportamentais e contrastivos.
Como resultado, o HiSSD representa um sistema poderoso, no qual todos os níveis de comportamento — desde o planejamento estratégico até a tática individual — são treinados de forma coordenada e operam eficientemente mesmo na ausência de controle centralizado.
A visualização elaborada pelos autores do framework HiSSD é apresentada a seguir.
Implementação com MQL5
Após analisarmos os aspectos teóricos do funcionamento do framework HiSSD, passamos à parte prática deste artigo, na qual implementaremos, com os recursos do MQL5, nossa própria visão das abordagens propostas pelos autores do framework.
Princípios fundamentais da construção do modelo
Antes de avançar para a aplicação prática dos métodos propostos, é importante destacar alguns princípios-chave que servirão de base para nossa solução.
Em primeiro lugar, vale ressaltar que o framework HiSSD é voltado para o treinamento de um modelo multiagente. Isso difere da nossa tarefa, que consiste em treinar uma política de trading para um único instrumento financeiro. No entanto, essa abordagem possui enorme potencial no contexto de multitarefas, algo característico dos mercados financeiros reais. Podemos, portanto, tornar a estrutura hierárquica proposta um pouco mais complexa, treinando vários agentes independentes, sendo que cada um deles analisará e preverá uma parte específica das informações de mercado. E, para tornar a decisão final mais coerente e eficaz, adicionaremos um modelo-gerente de nível superior, responsável por integrar as propostas dos diferentes agentes e selecionar a melhor estratégia. Tais sistemas multitarefas não são novos no campo da inteligência artificial, e sua aplicação no contexto dos mercados financeiros permite levar em consideração, de forma eficiente, a diversidade de fatores e riscos existentes.
O segundo ponto importante é que, no contexto do framework HiSSD, cada agente gera ações com base em observações locais. No entanto, nos mercados financeiros, onde informações como preços, volumes de negociação e outros indicadores estão fortemente interligados, essa abordagem requer ajustes adicionais. Podemos fornecer a cada agente, para análise, uma sequência unitária extraída de uma série temporal multimodal de dados brutos. Mas é essencial lembrar que, nos mercados reais, os indicadores frequentemente apresentam correlação entre si. Por exemplo, as variações no preço de um ativo podem influenciar o preço de outros ativos, o que torna necessário considerar essas interdependências. Para isso, implementaremos um mecanismo de enriquecimento de dados, que permitirá a cada agente adquirir um conhecimento global sobre o estado do mercado e utilizar essas informações para tomar decisões mais equilibradas.
Por fim, é importante destacar a relevância da modularidade, que constitui a base do framework HiSSD. Essa abordagem é ideal para sistemas complexos e multitarefas. É possível dividir o sistema em vários componentes, sendo que cada um deles resolve uma tarefa específica. A modularidade não apenas permite otimizar de forma eficiente os componentes individuais, como também ajuda a adaptar o sistema de maneira flexível às mudanças nas condições do mercado. No nosso caso, essa característica tem um valor especial, pois os mercados financeiros estão em constante transformação, e a capacidade de modificar ou aprimorar rapidamente partes isoladas do modelo pode ser a chave para um trading bem-sucedido.
Codificador de habilidades
O primeiro módulo com o qual iniciaremos a construção do modelo é o codificador de habilidades. Aqui, chamamos a atenção para uma característica arquitetônica importante do framework HiSSD: as habilidades gerais e as específicas da tarefa são formadas a partir da mesma fonte de informação. Trata-se das observações locais do agente. No nosso caso, são sequências unitárias obtidas a partir de uma série temporal multimodal que descreve o estado do ambiente.
Considerando essa característica, foi tomada a decisão de utilizar uma única solução arquitetônica para as duas subtarefas. Esse método oferece diversas vantagens. Em primeiro lugar, simplifica o design e a posterior depuração do modelo. Em segundo, permite aplicar uma metodologia unificada para analisar a qualidade das características extraídas. Por fim, o reuso das soluções arquitetônicas economiza recursos de desenvolvimento e possibilita escalar o modelo mais rapidamente ao migrar para novas tarefas ou novos instrumentos financeiros.
A operação do codificador de habilidades será organizada dentro do objeto CNeuronSkillsEncoder, cuja estrutura é apresentada a seguir.
class CNeuronSkillsEncoder : public CNeuronSoftMaxOCL { protected: CNeuronCATCH cCrossObservAttention; CNeuronTransposeOCL cTranspose; CNeuronConvOCL cSkillsProjection[2]; CNeuronBaseOCL cPrevSkillsConcat; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; public: CNeuronSkillsEncoder(void) {}; ~CNeuronSkillsEncoder(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint time_step, uint variables, uint skills, uint window, uint step, uint window_key, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronSkillsEncoder; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
Na estrutura apresentada, observamos uma série de objetos internos, cada um desempenhando um papel importante. Detalharemos suas funcionalidades no processo de desenvolvimento dos métodos da nova classe. Por ora, o que importa é que todos os objetos foram declarados como estáticos. Isso nos permite deixar o construtor e o destrutor da classe vazios. A inicialização de todos os objetos internos é realizada no método Init.
bool CNeuronSkillsEncoder::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint time_step, uint variables, uint skills, uint window, uint step, uint window_key, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronSoftMaxOCL::Init(numOutputs, myIndex, open_cl, variables * skills, optimization_type, batch)) return false; SetHeads(variables);
Nos parâmetros desse método, são recebidas várias constantes que permitem identificar de forma inequívoca a arquitetura do objeto que está sendo criado. A nomenclatura de praticamente todos os parâmetros já nos é familiar de trabalhos anteriores, portanto, não iremos detalhar cada um deles neste momento.
No corpo do método, como de costume, chamamos imediatamente o método homônimo da classe pai, no qual já estão implementados os pontos mínimos de controle, bem como os processos de inicialização dos objetos e interfaces herdadas.
Como classe pai, utilizamos a camada da função SoftMax. Isso nos permite normalizar os resultados do trabalho dos codificadores de habilidades de cada agente, tornando-os comparáveis entre si. A quantidade de habilidades atribuída a cada agente é determinada pelo parâmetro skills. Esse é exatamente o comprimento do vetor de resultados gerado na saída do módulo para cada agente. O valor de cada elemento do vetor indica o grau de importância de uma habilidade específica.
Não é difícil perceber que, neste caso, o número de agentes será igual ao número de sequências unitárias presentes na série temporal multimodal analisada. Esse número será usado como o total de cabeças de normalização na função SoftMax.
Após a execução bem-sucedida das operações do método da classe pai, passamos à inicialização dos novos objetos internos criados. O primeiro a ser inicializado é o objeto responsável pela troca de informações entre as sequências unitárias. Neste experimento, essa função será desempenhada pelo objeto do framework CATCH, desenvolvido por nós em um trabalho anterior.
int index = 0; if(!cCrossObservAttention.Init(0, index, OpenCL, time_step, variables, window, step, window_key, heads, optimization, iBatch)) return false;
Vale lembrar que esse objeto permite alinhar as sequências unitárias no domínio da frequência. O espectro é decomposto em segmentos, e a análise é realizada dentro de cada um deles separadamente. Essa abordagem possibilita levar em conta, de forma mais flexível, as particularidades do comportamento dos diferentes sinais de mercado. Em vez de analisar toda a estrutura de frequências da série temporal como um todo, concentramos a atenção em faixas de frequência específicas. Isso é especialmente importante no contexto dos mercados financeiros, onde oscilações de alta e baixa frequência podem carregar informações de natureza fundamentalmente distinta: as oscilações de alta frequência geralmente refletem volatilidade de curto prazo e ruído, enquanto as componentes de baixa frequência permitem identificar tendências e padrões de longo prazo.
Esse processo torna possível identificar regularidades comuns — sincronias, defasagens de fase, correlações — e utilizá-las como uma fonte adicional de informação na formação das habilidades.
É importante ressaltar que a troca de informações não ocorre de forma direta, mas por meio de um mecanismo de atenção mascarada. Esse mecanismo protege os agentes de uma influência excessiva entre si, preservando o princípio da descentralização. Assim, cada agente continua trabalhando com sua própria sequência unitária, mas passa a considerar as regularidades significativas que caracterizam todo o cenário de mercado.
Na saída do módulo CATCH, obtemos a mesma série temporal multimodal de dados brutos, mas agora enriquecida com informações sobre as conexões entre canais.
Em seguida, cada agente deve receber sua própria sequência unitária. E, com o objetivo de transformar os dados analisados em uma forma mais conveniente de representação, utilizaremos uma camada de transposição.
index++; if(!cTranspose.Init(0, index, OpenCL, time_step, variables, optimization, iBatch)) return false;
Em seguida, são utilizadas cabeças independentes para a geração do vetor de habilidades de cada agente. Aqui empregamos duas camadas convolucionais sequenciais.
No entanto, é importante observar que o comprimento da sequência analisada pode variar dentro de uma faixa bastante ampla, e processar toda a sequência de uma só vez com um único bloco pode ser computacionalmente dispendioso. Por essa razão, na primeira etapa, dividimos a sequência em vários segmentos e ajustamos sua dimensionalidade por meio de uma camada convolucional.
uint count = (time_step - window + step - 1) / step; if(count <= 1) { window = time_step; count = 1; } //--- index++; if(!cSkillsProjection[0].Init(0, index, OpenCL, window, step, window_key, count, variables, optimization, iBatch)) return false; cSkillsProjection[0].SetActivationFunction(SoftPlus);
A segunda camada convolucional, por sua vez, reúne todos os segmentos relacionados a uma mesma sequência unitária e forma um único vetor de habilidades para cada agente individualmente. Isso é indicado pela especificação do valor “1” como tamanho da sequência.
index++; if(!cSkillsProjection[1].Init(0, index, OpenCL, window_key * count, window_key * count, skills, 1, variables, optimization, iBatch)) return false; cSkillsProjection[1].SetActivationFunction(None);
Vale ressaltar que, nos parâmetros das camadas convolucionais, definimos explicitamente o número de sequências unitárias independentes que o modelo processará. Isso permite que cada agente utilize sua própria cópia da arquitetura convolucional, com um conjunto único de pesos. Além disso, cada agente analisa sua área local de dados, isto é, uma parte específica da série temporal multimodal completa.
Em outras palavras, o agente não apenas observa dados exclusivos, mas também concentra sua atenção em um subconjunto limitado de informações. Essa característica aproxima a modelagem da realidade dos mercados financeiros, onde cada trader (no nosso caso, agente) trabalha com diferentes fontes de informação e toma decisões com base nelas.
Como resultado, obtemos não apenas executores paralelos de uma mesma tarefa, mas uma verdadeira equipe de agentes especializados, cada um treinando em seu próprio ambiente, construindo sua própria representação do mercado e desenvolvendo sua própria estratégia de comportamento. Essa organização aumenta a resiliência de todo o sistema, reforça a diversificação comportamental e permite combinar estratégias locais para atingir um objetivo global, o de realizar uma negociação eficiente e adaptativa em condições de incerteza.
Em seguida, inicializamos um objeto auxiliar, cujo tamanho é duas vezes maior que o tensor de resultados. Falaremos sobre sua funcionalidade durante a construção do método de distribuição do gradiente de erro.
index++; if(!cPrevSkillsConcat.Init(0, index, OpenCL, 2 * Neurons(), optimization, iBatch)) return false; cPrevSkillsConcat.SetActivationFunction((ENUM_ACTIVATION)cSkillsProjection[1].Activation()); //--- return true; }
Após a bem-sucedida inicialização de todos os objetos internos, concluímos a execução do método, retornando previamente à função chamadora o resultado lógico das operações realizadas.
A próxima etapa do nosso trabalho é a construção dos algoritmos de propagação para frente dentro do método feedForward. Aqui, como esperado, tudo ocorre de maneira bastante simples e linear.
bool CNeuronSkillsEncoder::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cCrossObservAttention.FeedForward(NeuronOCL)) return false;
Nos parâmetros do método, recebemos um ponteiro para o objeto de dados brutos multimodais, que imediatamente passamos para o módulo interno de análise das dependências entre canais.
if(!cTranspose.FeedForward(cCrossObservAttention.AsObject())) return false;
Transpomos os resultados obtidos e os passamos para o bloco de geração do tensor de habilidades.
if(!cSkillsProjection[0].FeedForward(cTranspose.AsObject())) return false;
No entanto, vale chamar a atenção para um ponto. Antes de chamar o método de propagação para frente da segunda camada convolucional, fazemos a permutação dos ponteiros para os buffers de resultados. Essa simples iteração permite preservar os resultados das operações anteriores. O valor dessa ação será explicado ao construirmos o método de distribuição do gradiente do erro.
if(!cSkillsProjection[1].SwapOutputs() || !cSkillsProjection[1].FeedForward(cSkillsProjection[0].AsObject())) return false; //--- return CNeuronSoftMaxOCL::feedForward(cSkillsProjection[1].AsObject()); }
O tensor de habilidades dos agentes formado é convertido em um subespaço de probabilidades pelos recursos da classe pai, e concluímos o trabalho do método, retornando à função chamadora o resultado lógico das operações.
Em seguida, passamos à construção dos algoritmos de propagação reversa. Como você sabe, esse trabalho está dividido em 2 etapas:
- distribuição dos gradientes do erro entre todos os participantes do processo, método calcInputGradients;
- otimização dos parâmetros do modelo na direção da minimização do erro, método updateInputWeights.
Vamos começar pelo método calcInputGradients, que é responsável por propagar o gradiente do erro entre os objetos internos, em conformidade com sua influência no resultado final do trabalho do modelo. Já vínhamos preparando o leitor para sua implementação, mencionando esse método duas vezes anteriormente e deixando uma leve intriga. Agora chegou o momento de analisar em detalhes como ele é estruturado e por que desempenha um papel importante no treinamento do modelo.
Nos parâmetros do método, recebemos um ponteiro para o objeto de dados brutos, o mesmo que foi utilizado durante as operações de propagação para frente. Porém, desta vez, teremos de passar para ele o gradiente do erro de acordo com a influência que os dados brutos exercem sobre o resultado final do trabalho do modelo.
bool CNeuronSkillsEncoder::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!prevLayer) return false;
Naturalmente, só podemos passar dados para um objeto válido. Por isso, no corpo do método, verificamos imediatamente a validade do ponteiro recebido. Se o ponteiro estiver vazio ou inválido, a execução do método é interrompida instantaneamente, pois cálculos adicionais deixam de fazer sentido. Essa verificação é uma medida básica de segurança, que garante a correção da execução do algoritmo e protege contra falhas imprevisíveis durante o treinamento.
No caso de uma passagem bem-sucedida por esse ponto de controle, avançamos para a etapa seguinte, a distribuição do gradiente do erro. Aqui começa a transferência sequencial de informações entre todos os objetos envolvidos no processo. Cada um desses objetos é responsável por sua parte da lógica do modelo, e nossa tarefa é, com cuidado e passo a passo, encaminhar o gradiente do erro para os componentes corretos.
Esse mecanismo é de importância crítica: ele garante a retroalimentação dentro do modelo, permitindo que cada bloco ajuste seus parâmetros de acordo com o erro final. É precisamente graças a esse mecanismo que o modelo aprende, encontrando parâmetros ótimos ao minimizar as perdas.
Na primeira etapa, utilizando os mecanismos fornecidos pela classe pai, transmitimos o gradiente do erro, recebido das camadas subsequentes da arquitetura da rede neural, para as interfaces externas do objeto, até o nível da última camada responsável pela geração do tensor de habilidades dos agentes.
if(!CNeuronSoftMaxOCL::calcInputGradients(cSkillsProjection[1].AsObject())) return false;
Esse processo desempenha um papel central no aprendizado do modelo, pois é ele que garante a capacidade de gerar habilidades realmente relevantes para a tarefa proposta. Por meio da propagação sequencial do gradiente do erro, o modelo recebe um retorno direto sobre o quão corretas foram suas ações e decisões anteriores.
No entanto, o nosso objetivo não é apenas treinar os agentes para gerar habilidades úteis, mas também organizar o trabalho deles em equipe de modo que possam interagir de forma eficiente, direcionando seus esforços em diferentes direções para alcançar o máximo resultado coletivo. Não se trata simplesmente de treinar cada agente individualmente, mas de criar uma sinergia entre eles.
Para implementar essa abordagem, utilizamos algoritmos de aprendizado contrastivo, que nos permitem introduzir diversidade nos tensores de habilidades dos agentes. É importante notar que essa diversificação ocorre não apenas entre diferentes agentes em um mesmo instante temporal, mas também entre habilidades geradas em diferentes passos de tempo. Isso cria uma diferenciação mais profunda na forma como os estados são percebidos.
Assim, cada agente é levado não apenas a reconhecer a singularidade de sua própria habilidade, mas também a considerar o contexto formado por ações anteriores. Isso os impulsiona a desenvolver estratégias comportamentais mais complexas e consistentes, capazes de se adaptar às mudanças nas condições e na dinâmica do mercado.
No contexto dos mercados financeiros, onde a situação muda com extrema rapidez, essa capacidade dos agentes de levar em conta ações passadas e diferenças entre estados se torna crucial. A diversificação das habilidades, aliada ao uso de dados históricos, permite construir estratégias mais robustas e adaptativas, capazes de operar de forma eficiente em ambientes de alta instabilidade e incerteza.
O algoritmo de aprendizado contrastivo desempenhará um papel fundamental na criação dessas diferenças, pois é ele que aprimora a capacidade dos agentes de distinguir e analisar diversas situações, possibilitando a tomada de decisões mais fundamentadas a cada passo.
Durante o processo de propagação para frente, antes da geração de um novo tensor de habilidades, salvamos os resultados da propagação anterior. Agora, reunimos os resultados do processamento de dois estados do ambiente em um único tensor.
if(!Concat(cSkillsProjection[1].getOutput(), cSkillsProjection[1].getPrevOutput(), cPrevSkillsConcat.getOutput(), cSkillsProjection[1].GetFilters(), cSkillsProjection[1].GetFilters(), iHeads)) return false;
Em seguida, chamamos o método de diversificação, cuja função é maximizar a separação entre os vetores individuais no subespaço de habilidades.
if(!DiversityLoss(cPrevSkillsConcat.AsObject(), 2 * iHeads, cSkillsProjection[1].GetFilters(), false)) return false;
Os gradientes de erro obtidos são então divididos entre as sequências correspondentes.
if(!DeConcat(cPrevSkillsConcat.getOutput(), cPrevSkillsConcat.getPrevOutput(), cPrevSkillsConcat.getGradient(), cSkillsProjection[1].GetFilters(), cSkillsProjection[1].GetFilters(), iHeads)) return false;
Adicionamos esses gradientes aos anteriormente calculados para as habilidades do passo temporal atual.
if(!SumAndNormilize(cSkillsProjection[1].getGradient(), cPrevSkillsConcat.getOutput(), cSkillsProjection[1].getGradient(), cSkillsProjection[1].GetFilters(), false, 0, 0, 0, 1)) return false;
O restante do algoritmo do método é linear. Propagamos o gradiente do erro pelo bloco de geração de habilidades.
if(!cSkillsProjection[0].calcHiddenGradients(cSkillsProjection[1].AsObject())) return false;
Os valores resultantes são transpostos e passados para o módulo de análise das dependências entre canais.
if(!cTranspose.calcHiddenGradients(cSkillsProjection[0].AsObject())) return false; if(!cCrossObservAttention.calcHiddenGradients(cTranspose.AsObject())) return false;
Em seguida, o gradiente do erro é transferido para o objeto de dados brutos, de acordo com sua influência sobre o resultado final.
return prevLayer.calcHiddenGradients(cCrossObservAttention.AsObject());
}
Depois disso, o método é concluído, retornando à função chamadora o resultado lógico das operações realizadas.
O método de atualização dos parâmetros do modelo, updateInputWeights, é extremamente simples: apenas chamamos os métodos homônimos dos objetos internos. Vale observar que nem todos os objetos internos possuem parâmetros treináveis, portanto apenas parte deles participa efetivamente desse processo.
bool CNeuronSkillsEncoder::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cCrossObservAttention.UpdateInputWeights(NeuronOCL)) return false; if(!cSkillsProjection[0].UpdateInputWeights(cTranspose.AsObject())) return false; if(!cSkillsProjection[1].UpdateInputWeights(cSkillsProjection[0].AsObject())) return false; //--- return true; }
É necessário ainda fazer algumas observações sobre os métodos de salvamento do modelo treinado e de restauração de sua funcionalidade. Como você deve ter percebido, o objeto responsável pela concatenação dos resultados de duas propagações para frente consecutivas não contém parâmetros treináveis. Ele cumpre apenas uma função auxiliar, unindo os dados de saída de dois fluxos diferentes. Apesar disso, o objeto de concatenação possui buffers de dados cujo tamanho é duas vezes maior que o tensor de resultados do objeto atual. No entanto, esses dados não têm influência crítica sobre o funcionamento do modelo, pois servem apenas como armazenamento temporário de informações utilizadas em cálculos intermediários. Considerando isso, ao salvar o modelo treinado podemos economizar espaço em disco, excluindo a necessidade de armazenar esses buffers de dados.
bool CNeuronSkillsEncoder::Save(const int file_handle) { if(!CNeuronSoftMaxOCL::Save(file_handle)) return false; if(!cCrossObservAttention.Save(file_handle)) return false; if(!cTranspose.Save(file_handle)) return false; for(uint i = 0; i < cSkillsProjection.Size(); i++) if(!cSkillsProjection[i].Save(file_handle)) return false; //--- return true; }
Durante a restauração do modelo, podemos facilmente reinicializar o objeto de concatenação com base nas informações sobre o tamanho do tensor de resultados do nosso codificador de habilidades.
bool CNeuronSkillsEncoder::Load(const int file_handle) { if(!CNeuronSoftMaxOCL::Load(file_handle)) return false; if(!LoadInsideLayer(file_handle, cCrossObservAttention.AsObject())) return false; if(!LoadInsideLayer(file_handle, cTranspose.AsObject())) return false; for(uint i = 0; i < cSkillsProjection.Size(); i++) if(!LoadInsideLayer(file_handle, cSkillsProjection[i].AsObject())) return false; //--- if(!cPrevSkillsConcat.Init(0, 4, OpenCL, 2 * Neurons(), optimization, iBatch)) return false; cPrevSkillsConcat.SetActivationFunction((ENUM_ACTIVATION)cSkillsProjection[1].Activation()); //--- return true; }
Com isso, encerramos a análise dos algoritmos de construção dos métodos do codificador de habilidades. O código completo do objeto apresentado e de todos os seus métodos pode ser consultado no anexo.
Hoje trabalhamos intensamente, mas, infelizmente, o espaço do artigo está praticamente esgotado. Por isso, faremos uma breve pausa e continuaremos o trabalho no próximo artigo.
Considerações finais
Conhecemos os aspectos teóricos do framework HiSSD, que representa um sistema poderoso e flexível para o treinamento de agentes em um ambiente multiagente. Cada agente aprende uma política de comportamento individual em estreita interação com os demais participantes do processo. Essa combinação de aprendizado de habilidades gerais e específicas permite criar estratégias mais adaptativas e resilientes, capazes de operar de forma eficaz em condições de incerteza e variabilidade.
A modularidade da abordagem HiSSD, juntamente com a combinação do uso de diferentes métodos para o treinamento e ajuste do modelo — como o aprendizado contrastivo e o codificador variacional de comportamento — torna esse framework uma ferramenta extremamente versátil e promissora para a solução de tarefas no campo dos sistemas multiagente.
Na parte prática do artigo, iniciamos a implementação, com os recursos do MQL5, da nossa própria interpretação das abordagens propostas pelos autores do framework. Em particular, foi apresentada a implementação de um codificador de habilidades universal. No próximo artigo, daremos continuidade a esse trabalho, testando a eficiência dos métodos implementados em dados históricos reais.
Referências
- Learning Generalizable Skills from Offline Multi-Task Data for Multi-Agent Cooperation
- Outros artigos da série
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA de coleta de exemplos |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA de coleta de exemplos pelo método Real-ORL |
| 3 | Study.mq5 | Expert Advisor | EA de treinamento de modelos |
| 4 | Test.mq5 | Expert Advisor | EA para teste do modelo |
| 5 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema e da arquitetura dos modelos |
| 6 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de rede neural |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/17729
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso