
Redes neuronales en el trading: Jerarquía de habilidades para el comportamiento adaptativo de agentes (Final)

Introducción
En el artículo anterior nos familiarizamos con los aspectos teóricos del framework HiSSD (Hierarchical and Separate Skill Discovery), que supone un enfoque moderno para el aprendizaje offline de sistemas multiagente capaces de trabajar en entornos complejos y dinámicamente cambiantes. Este framework permite entrenar a los agentes para que interactúen entre sí con eficacia y se adapten a las condiciones cambiantes. El HiSSD se probó inicialmente en entornos de simulación; sin embargo, los planteamientos y la arquitectura propuestos lo hacen especialmente relevante para la aplicación en los mercados financieros, donde las situaciones pueden mudar drásticamente en segundos y se requieren agentes comerciales inteligentes que reaccionen con rapidez y de forma coordinada.
Una de las principales ventajas del HiSSD es su gran adaptabilidad. En entornos comerciales en los que los indicadores económicos, el comportamiento de los participantes en el mercado o las noticias pueden cambiar repentinamente el panorama del mercado, los agentes entrenados con HiSSD son capaces de ajustarse instantáneamente sin necesidad de un reentrenamiento completo. Esto es posible gracias a una arquitectura basada en una división de habilidades en dos niveles: generales y específicas. Las habilidades generales son pautas de comportamiento que resultan relevantes en multitud de situaciones, como el reconocimiento de tendencias de mercado o la evaluación de riesgos. Las habilidades específicas son responsables del comportamiento en entornos únicos o muy especializados. Esta estructura de dos niveles permite a los agentes de HiSSD negociar de forma estable y eficiente, independientemente de las condiciones inestables del mercado.
Otro punto fuerte del HiSSD es su escalabilidad. Los mercados financieros son un sistema multiagente. Cada participante, ya sea humano, robot comercial o gran creador de mercado, influye en la dinámica del mercado. En un entorno así, resulta esencial escalar el sistema sin destruir su coherencia. El HiSSD ofrece una arquitectura jerárquica en la que cada agente puede coordinar su comportamiento con los demás a través de módulos de control comunes. Esto resulta especialmente útil a la hora de elaborar estrategias globales. En la práctica, esto permite construir sistemas comerciales más fiables y sostenibles.
A continuación le mostramos la visualización de la arquitectura del framework HiSSD por parte del autor.
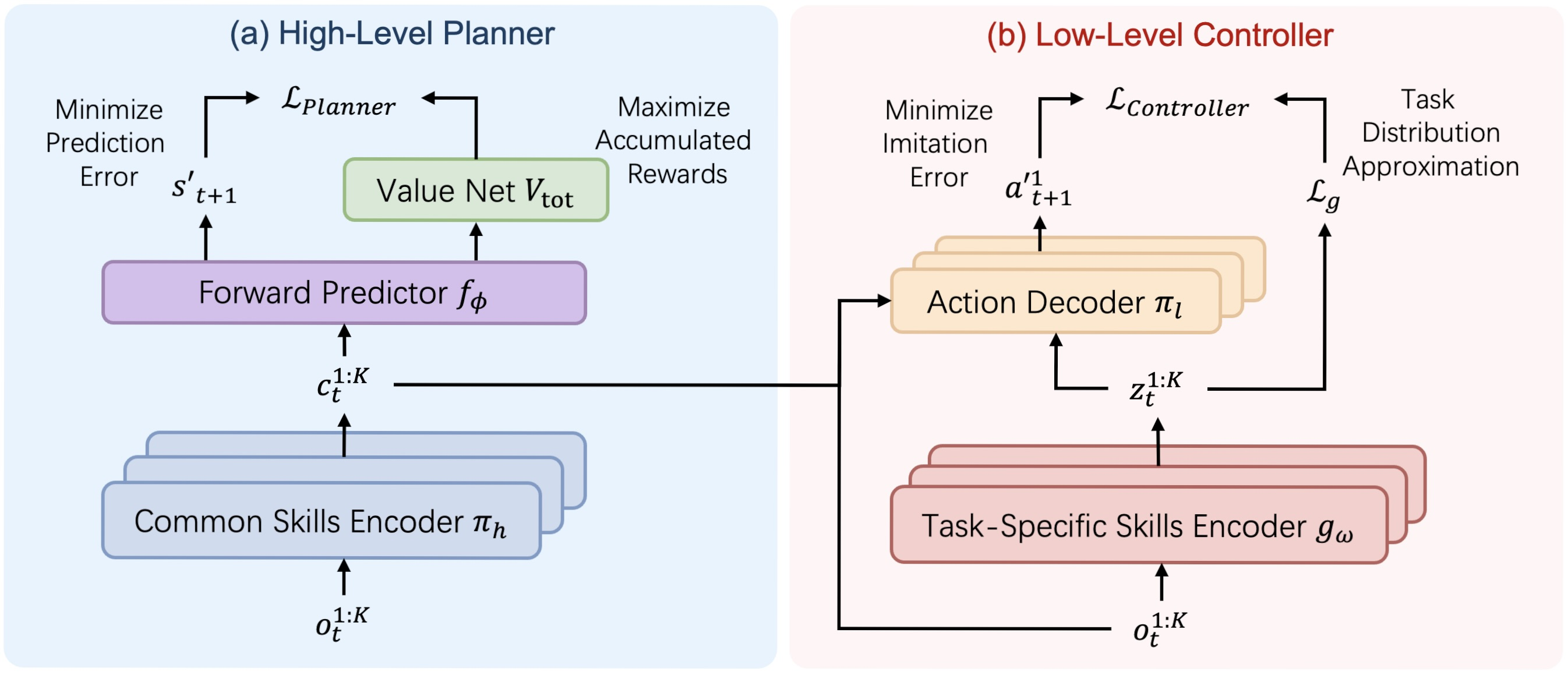
En la parte práctica del artículo anterior, comenzamos a implementar usando MQL5 nuestra propia visión de los enfoques propuestos por los autores del framework. En particular, presentamos una implementación de un codificador universal de habilidades que se construyó dentro del objeto CNeuronSkillsEncoder. Hoy continuaremos el trabajo iniciado y lo llevaremos a su conclusión lógica probando la eficacia de los planteamientos aplicados con datos históricos reales.
Pero antes de continuar nuestro trabajo sobre la realización de nuestra propia visión de los enfoques propuestos por los autores del framework, le sugiero echar otro vistazo a la estructura del framework HiSSD. Aquí vemos dos grandes bloques: El Planeador y Controlador.
El primero tiene un flujo lineal de información. Los datos de origen pasan por un codificador genérico de habilidades, que se transmite al módulo de predicción para pronosticar el estado posterior y el valor esperado. Podemos construir una arquitectura de este tipo con las herramientas existentes en forma de modelo lineal.
Las cosas resultan un poco más complicadas en cuanto a la organización del trabajo del Controlador. En su estructura podemos distinguir el descodificador de las acciones de los agentes, que recibe datos de entrada de 3 fuentes. Entre ellas se incluyen las observaciones locales de los agentes y las habilidades generales y específicas generadas por diferentes codificadores de habilidades. Esta circunstancia nos lleva a construir el Controlador como un objeto independiente.
Objeto de controlador
La siguiente etapa de nuestro trabajo consistirá en construir el objeto de Controlador, cuya funcionalidad organizaremos dentro del objeto CNeuronHiSSDLowLevelController.
class CNeuronHiSSDLowLevelControler: public CNeuronConvOCL { protected: uint iTaskSkills; uint iCommonSkills; //--- CNeuronSkillsEncoder cTaskSpecificSkillsEncoder; CNeuronTransposeOCL cTranspose; CNeuronBaseOCL cObservAndSkillsConcat; CNeuronBatchNormOCL cNormalizarion; CNeuronConvOCL cActionDecoder[2]; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *second) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None ) override; public: CNeuronHiSSDLowLevelControler(void) {}; ~CNeuronHiSSDLowLevelControler(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint time_step, uint variables, uint task_skills, uint common_skills, uint n_actions, uint window, uint step, uint window_key, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronHiSSDLowLevelControler; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
Aquí cabe señalar que el descodificador de las acciones del agente en el Controlador del framework HiSSD supone el trabajo en paralelo de varios agentes independientes. Esta funcionalidad puede implementarse usando capas convolucionales sucesivas. Y como el decodificador se encuentra a la salida del módulo, podemos implementar la funcionalidad de la última capa del decodificador usando la clase padre. Precisamente por ello hemos elegido el objeto de capa convolucional como objeto padre al crear el módulo del Controlador.
En la estructura presentada del nuevo objeto vemos varios objetos internos, cuya funcionalidad descubriremos con detalle durante la construcción de los algoritmos de pasada directa y inversa. Aquí también cabe destacar su declaración estática, que nos permitirá dejar vacíos el constructor y el destructor de la clase. La inicialización de todos los objetos internos, incluidos los heredados, se realiza en el método Init.
Como viene siendo habitual, en los parámetros del método de inicialización obtendremos una serie de constantes que nos permitirán interpretar sin ambigüedades la arquitectura del objeto requerido.
bool CNeuronHiSSDLowLevelControler::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint time_step, uint variables, uint task_skills, uint common_skills, uint n_actions, uint window, uint step, uint window_key, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronConvOCL::Init(numOutputs, myIndex, open_cl, window_key, window_key, n_actions, 1, variables, optimization_type, batch)) return false; SetActivationFunction(SIGMOID);
En el cuerpo del método, llamaremos directamente al método homónimo de la clase padre. Y aquí hay algunos puntos clave a los que debemos prestar atención.
En primer lugar, prevemos usar la funcionalidad de la clase padre como última capa del descodificador de acciones del agente. Como consecuencia, transmitiremos los resultados del procesamiento preliminar de los objetos internos del descodificador a la entrada de los métodos de la clase padre. Dentro del descodificador, se espera que se organicen flujos paralelos de información durante el entrenamiento de la "conciencia" de los agentes individuales. Por consiguiente, la ventana de los datos analizados y su paso de la capa convolucional creada serán iguales a la dimensionalidad del vector de flujo de información interna de un agente individual.
A la salida de la capa, esperamos obtener un tensor de acciones de los agentes. Por ello, el número de filtros de la capa convolucional será igual al tamaño del vector de acción de un agente.
Una cosa más: para organizar un entrenamiento totalmente independiente de los agentes individuales, deberemos proporcionarles parámetros de ponderación únicos. Para ello, especificaremos la dimensión unitaria de la secuencia analizada, mientras que el número de agentes entrenados se transmitirá al parámetro del número de secuencias unitarias. Esta sencilla técnica nos permitirá organizar el trabajo en paralelo del número necesario de agentes totalmente independientes.
A continuación, inicializaremos los objetos declarados en la nueva estructura de clases. Recordemos que la inicialización de los objetos heredados se realizará en el método homónimo de la clase padre llamado anteriormente.
Primero inicializaremos el codificador de habilidades específicas, cuyo papel desempeñará el codificador de habilidades universales que creamos en el artículo anterior.
int index = 0; if(!cTaskSpecificSkillsEncoder.Init(0, index, OpenCL, time_step, variables, task_skills, window, step, window_key, heads, optimization, iBatch)) return false; cTaskSpecificSkillsEncoder.SetActivationFunction(None);
Y luego, guardaremos las constantes que necesitamos para describir la arquitectura del objeto.
iTaskSkills = task_skills; iCommonSkills = MathMax(common_skills, 1);
Obsérvese que mantendremos la dimensionalidad de las habilidades específicas tal cual, y para las habilidades generales introduciremos el valor mínimo admisible. Aquí todo es bastante transparente. La cuestión es que antes transmitíamos la dimensionalidad de las habilidades específicas en los parámetros del método de inicialización del codificador. Y la ejecución satisfactoria de este método confirma la aceptabilidad del valor obtenido, mientras que el tensor de habilidades generales lo obtendremos del Planeador, que, en esta implementación, será un objeto diferente e incluso un modelo diferente. Por lo tanto, solo podremos especificar el valor mínimo aceptable.
El siguiente paso consistirá en organizar el descodificador de las acciones de los agentes. Los autores del framework HiSSD proponen suministrar a la entrada del descodificador información procedente de 3 fuentes de datos:
- las observaciones locales del agente;
- las habilidades generales;
- las habilidades específicas.
Como ya hemos mencionado, tenemos previsto obtener el tensor de habilidades generales a partir de otro modelo usando el segundo flujo de información. Las habilidades específicas son generadas por el codificador anteriormente inicializado basándose en las observaciones locales del agente recibidas a través del flujo de información principal. Por consiguiente, en esta fase ya tenemos todos los datos que necesitamos. Solo tenemos que ensamblarlos en un único objeto.
Sin embargo, debemos considerar que cada agente debe recibir su propio conjunto de información. De ahí que sea necesario organizar la concatenación de los datos correctamente. Los tensores de habilidades se representan como una matriz "imaginaria" cuyas filas están representadas por vectores de habilidades individuales de los agentes. La concatenación línea por línea nos permitirá obtener la matriz de datos de origen deseada, adecuada para organizar flujos de información paralelos e independientes usando la funcionalidad de las capas convolucionales.
El caso del tensor de observaciones locales es ligeramente distinto. Ya hemos mencionado que tenemos previsto utilizar una serie temporal multimodal como datos de entrada, al igual que antes. En este caso, cada agente recibirá su propia secuencia unitaria para analizar. Y antes de poder añadirlas a las habilidades, deberemos transponer la matriz a una representación adecuada para analizar secuencias unitarias.
index++; if(!cTranspose.Init(0, index, OpenCL, time_step, variables, optimization, iBatch)) return false;
A continuación, determinaremos la dimensionalidad del vector de datos iniciales del agente e inicializaremos el objeto para almacenar el tensor concatenado.
uint window_size = (time_step + iTaskSkills + iCommonSkills); index++; if(!cObservAndSkillsConcat.Init(0, index, OpenCL, window_size * iVariables, optimization, iBatch)) return false; cObservAndSkillsConcat.SetActivationFunction(None);
Nos gustaría llamar nuevamente la atención sobre el uso de los datos procedentes de 3 fuentes. Para que resulten comparables, utilizaremos la capa de normalización de datos por lotes.
index++; if(!cNormalizarion.Init(0, index, OpenCL, cObservAndSkillsConcat.Neurons(), iBatch, optimization)) return false; cNormalizarion.SetActivationFunction(None);
Una vez completados los objetos de preparación de datos, procederemos directamente a crear las capas neuronales del descodificador de acciones. Para ello organizaremos un pequeño ciclo, en cuyo cuerpo inicializaremos las capas convolucionales del descodificador. Los principios de inicialización se han detallado en la llamada al método de inicialización de la clase padre.
for(uint i = 0; i < cActionDecoder.Size(); i++) { index++; if(!cActionDecoder[i].Init(0, index, OpenCL, window_size, window_size, window_key, 1, iVariables, optimization, iBatch)) return false; cActionDecoder[i].SetActivationFunction(SoftPlus); window_size = window_key; } //--- return true; }
A continuación, finalizaremos el método retornando el resultado lógico de las operaciones al programa que realiza la llamada.
El siguiente paso consistirá en construir el algoritmo de pasada directa dentro del método feedForward. Como ya hemos dicho, trabajaremos con dos fuentes de datos. Sobre el flujo de información principal obtendremos una descripción multimodal de series temporales del estado del entorno, mientras que sobre el flujo de información auxiliar obtendremos un tensor de habilidades generales.
bool CNeuronHiSSDLowLevelControler::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!SecondInput) return false;
En el cuerpo del método, primero comprobaremos la pertinencia del puntero obtenido al objeto de tensor de habilidades generales. En este caso, además, no comprobaremos la relevancia del puntero al objeto de flujo de información principal. En su lugar, simplemente lo transmitiremos al método homónimo del codificador de habilidades específicas, en cuyo cuerpo ya está organizado el punto de control correspondiente.
if(!cTaskSpecificSkillsEncoder.FeedForward(NeuronOCL)) return false;
Tras generar el tensor de habilidades específicas, transpondremos el tensor de descripción del estado del entorno y lo concatenaremos por líneas con las dos matrices de habilidades (generales y específicas).
if(!cTranspose.FeedForward(NeuronOCL)) return false; if(!Concat(cTranspose.getOutput(), cTaskSpecificSkillsEncoder.getOutput(), SecondInput, cObservAndSkillsConcat.getOutput(), cTranspose.GetCount(), iTaskSkills, iCommonSkills, iVariables)) return false;
Luego normalizaremos los datos recopilados y los pasaremos por las 3 capas del descodificador de acciones de los agentes, a cuya salida obtendremos el resultado esperado en forma de tensor concatenado de todas las acciones de los agentes.
if(!cNormalizarion.FeedForward(cObservAndSkillsConcat.AsObject())) return false; CNeuronBaseOCL *neuron = cNormalizarion.AsObject(); for(uint i = 0; i < cActionDecoder.Size(); i++) { if(!cActionDecoder[i].FeedForward(neuron)) return false; neuron = cActionDecoder[i].AsObject(); } //--- return CNeuronConvOCL::feedforward(neuron); }
A continuación, finalizaremos el método devolviendo el resultado lógico al programa que realiza la llamada.
Después organizaremos los procesos de pasada inversa. Como ya sabe, dividiremos este proceso en 2 pasos:
- la distribución del gradiente de error entre todos los participantes en el proceso según su influencia en el resultado final del modelo;
- la optimización de los parámetros del modelo para reducir los errores.
El primer paso se organizará en el método calcInputGradients. En los parámetros de este método, obtendremos los punteros a los objetos de los dos flujos de información de los datos de origen y los gradientes de error correspondientes. Luego comprobaremos directamente la pertinencia de los punteros recibidos.
bool CNeuronHiSSDLowLevelControler::calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = -1) { if(!NeuronOCL || !SecondGradient) return false;
El proceso de distribución del gradiente de error se organizará respetando al completo los flujos de información de la pasada directa, solo que la información se transmitirá en sentido inverso. La pasada directa ha sido finalizada por el decodificador de acciones. En consecuencia, comenzaremos la distribución de los gradientes de error desde el descodificador atravesando sus capas convolucionales, nuevamente, en sentido contrario.
uint total = cActionDecoder.Size(); if(total <= 0) return false; CObject *neuron = cActionDecoder[total - 1].AsObject(); //--- if(!CNeuronConvOCL::calcInputGradients(neuron)) return false; for(int i = int(total - 2); i >= 0; i--) { if(!cActionDecoder[i].calcHiddenGradients(neuron)) return false; neuron = cActionDecoder[i].AsObject(); }
Los valores obtenidos los pasaremos por la capa de normalización de datos al tensor concatenado de las tres entidades.
if(!cNormalizarion.calcHiddenGradients(neuron)) return false; if(!cObservAndSkillsConcat.calcHiddenGradients(cNormalizarion.AsObject())) return false;
Y después distribuiremos los gradientes de error en los tres flujos de información desconcatenando los datos.
if(!DeConcat(cTranspose.getGradient(), cTaskSpecificSkillsEncoder.getGradient(), SecondGradient, cObservAndSkillsConcat.getGradient(), cTranspose.GetCount(), iTaskSkills, iCommonSkills, iVariables)) return false;
Aquí cabe señalar que cada uno de los flujos de información puede tener su propia función de activación. Por lo tanto, comprobaremos la presencia de funciones de activación para todos los flujos de información y, si es necesario, corregiremos los valores obtenidos mediante las correspondientes derivadas de las funciones.
if(SecondActivation != None) { if(!DeActivation(SecondInput, SecondGradient, SecondGradient, SecondActivation)) return false; } if(NeuronOCL.Activation() != None) { if(!DeActivation(cTranspose.getOutput(), cTranspose.getGradient(), cTranspose.getGradient(), NeuronOCL.Activation())) return false; } if(cTaskSpecificSkillsEncoder.Activation() != None) { if(!DeActivation(cTaskSpecificSkillsEncoder.getOutput(), cTaskSpecificSkillsEncoder.getGradient(), cTaskSpecificSkillsEncoder.getGradient(), cTaskSpecificSkillsEncoder.Activation())) return false; }
En este punto, ya hemos pasado el gradiente de error a la línea troncal del flujo auxiliar de datos de origen y podemos olvidarnos de él. Solo queda por sumar el error al nivel de la línea troncal de los datos de origen de los dos flujos de información. En primer lugar, pasaremos los datos por el codificador de habilidades específicas.
if(!NeuronOCL.calcHiddenGradients(cTaskSpecificSkillsEncoder.AsObject())) return false;
Y luego sustituiremos el puntero al búfer de gradientes de error del objeto de datos de origen y pasaremos el gradiente de error a lo largo del segundo flujo de información desde el objeto de transposición.
CBufferFloat *temp = NeuronOCL.getGradient(); if(!NeuronOCL.SetGradient(cTranspose.getPrevOutput(), false) || !NeuronOCL.calcHiddenGradients(cTranspose.AsObject()) || !SumAndNormilize(temp, NeuronOCL.getGradient(), temp, iVariables, false, 0, 0, 0, 1) || !NeuronOCL.SetGradient(temp, false)) return false; //--- return true; }
Después sumaremos los datos de los dos flujos de información y devolveremos a su estado inicial los punteros a los búferes de datos.
Ahora ya podemos finalizar el método de forma segura, pero antes retornaremos el resultado lógico de las operaciones al programa que realiza la llamada.
Con esto concluirán los algoritmos de nuestro análisis del funcionamiento del Controlador. Podrá leer el código completo del nuevo objeto y todos sus métodos por sí mismo en el archivo adjunto.
Arquitectura de los modelos
Tras completar el trabajo de construcción de los objetos individuales del framework HiSSD, pasaremos a describir la arquitectura de los modelos entrenados. Y aquí debemos decir que tenemos previsto entrenar hasta 4 modelos a la vez.
Uno de ellos es el Codificador de estado del entorno, que en este caso cumple la función de Planeador en el framework HiSSD. Planeamos entrenarlo al estilo del aprendizaje supervisado. Las habilidades comunes de los agentes se generan a partir del estado analizado del entorno. Partiendo de las habilidades adquiridas, se planifica una descripción de los futuros estados del entorno para un horizonte de planificación determinado.
Aquí, obviamente, podemos ver alguna desviación respecto a la representación del autor del framework HiSSD. Al fin y al cabo, solo se prevé la planificación de un estado posterior. Sin embargo, queremos formar una política que pueda abrir una posición y mantenerla durante un tiempo, lo cual requiere un análisis más profundo y una planificación a largo plazo.
El segundo modelo será el Controlador, que analizará el estado actual del entorno y generará un tensor de acciones de varios agentes.
El tercer modelo será el Gestor (Actor). En nuestra aplicación, este modelo analizará los estados de cuenta, evaluará las opciones ofrecidas por los agentes del Controlador y, basándose en este análisis, tomará la decisión de ejecutar una operación comercial.
Y el cuarto modelo será el predictivo, que determinará la probabilidad de la dirección del próximo movimiento del precio.
La arquitectura de todos los modelos entrenados se representa en el método CreateDescriptions.
bool CreateDescriptions(CArrayObj *&encoder, CArrayObj *&task, CArrayObj *&actor, CArrayObj *&probability) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!task) { task = new CArrayObj(); if(!task) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; }
En los parámetros del método obtendremos los punteros a 4 arrays dinámicos para registrar la descripción de la arquitectura de los modelos correspondientes. Luego se comprobará la pertinencia de todos los punteros recibidos y, si es necesario, se crearán nuevas instancias de objetos.
En primer lugar, describiremos la arquitectura del codificador de estados del entorno. Como es habitual, en la entrada del modelo utilizaremos una capa neuronal básica totalmente conectada de tamaño suficiente para registrar los datos de origen.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
La entrada del modelo serán los datos de origen, que convertiremos en comparables mediante una capa de normalización por lotes.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
A continuación vendrá el objeto de codificador universal de habilidades, que, en este caso, deberá generar un tensor de habilidades generales.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSkillsEncoder; descr.count = HistoryBars; { int temp[] = {BarDescr, NSkills, 4}; // Variables, Common Skills, Heads if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.window = 8; descr.step = 1; descr.window_out = 32; prev_count = descr.windows[0]; int prev_out = descr.windows[1]; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Luego tenemos 2 capas convolucionales que, basándose en el tensor de habilidades generales, planificarán el próximo movimiento de secuencias unitarias separadas de las series temporales multimodales analizadas.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = prev_out; descr.step = prev_out; prev_out=descr.window_out = 4*NForecast; descr.layers = prev_count; descr.activation = SoftPlus; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = prev_out; descr.step = prev_out; prev_out=descr.window_out = NForecast; descr.layers = prev_count; descr.activation = TANH; if(!encoder.Add(descr)) { delete descr; return false; }
Aquí cabe señalar que el comportamiento predictivo de una secuencia unitaria para un horizonte de planificación dado se construirá a partir de un vector de habilidades comunes de un agente. Así, en la salida de nuestro bloque de planificación la secuencia de datos se distinguirá de las series temporales multimodales habituales. Para llevar los datos a la representación deseada, deberemos transponerlos.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_out; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Y después, los devolveremos a la distribución original de los datos usando una normalización inversa.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = prev_count*prev_out; descr.layers = 1; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Con esto concluirá la descripción de la arquitectura del codificador de entorno. Pero antes de describir el siguiente modelo, guardaremos el objeto de descripción del estado oculto con el tensor de habilidades genéricas en la salida.
//--- Latent CLayerDescription *latent = encoder.At(LatentLayer); if(!latent) return false;
El segundo modelo, como ya hemos mencionado, será el Controlador. Este generará habilidades específicas de los agentes basándose en el análisis de la misma descripción del estado del entorno. Por lo tanto, simplemente copiaremos la descripción de las dos primeras capas del modelo anterior.
//--- Task task.Clear(); //--- Input layer if(!task.Add(encoder.At(0))) { return false; } //--- layer 1 if(!task.Add(encoder.At(1))) { return false; }
Y este modelo se completará con el objeto de Controlador construido anteriormente.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronHiSSDLowLevelControler; descr.count = HistoryBars; { int temp[] = {latent.windows[0], // Variables NSkills, // Task Skills latent.windows[1], // Common Skills NActions, // Action Space 4}; // Heads if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.window = 8; descr.step = 1; descr.window_out = 32; prev_count = descr.windows[0]; prev_out = descr.windows[3]; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = SIGMOID; if(!task.Add(descr)) { delete descr; return false; }
El tercer modelo, el Gestor de nivel superior, recibirá como entrada los vectores de descripción del estado de la cuenta. También utilizaremos una capa neuronal básica para registrarlo.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Luego normalizaremos los valores obtenidos.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = AccountDescr; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Y, a continuación, utilizaremos el módulo de atención cruzada para comparar el estado actual de la cuenta y las opciones comerciales propuestas.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossDMHAttention; { int temp[] = {AccountDescr, // Inputs window prev_out // Cross window }; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } { int temp[] = {1, // Inputs units prev_count // Cross units }; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.step = 4; // Heads descr.window_out = 32; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Y añadiremos 3 capas totalmente conectadas que formarán la llamada cabeza de decisión. Esta estructura permitirá transformar las características extraídas en el vector de acciones del Actor.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.batch = 1e4; descr.activation = TANH; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SoftPlus; descr.batch = 1e4; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions; descr.activation = SIGMOID; descr.batch = 1e4; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
El modelo predictivo para determinar la probabilidad de la dirección del próximo movimiento analizará las habilidades generales a partir del estado latente del Planificador. Por lo tanto, transferiremos los parámetros del objeto correspondiente a la capa de datos de origen.
//--- Probability probability.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = latent.windows[0] * latent.windows[1]; descr.activation = latent.activation; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; }
Los datos serán directamente analizados por un perceptrón con 2 capas ocultas completamente conectadas. Para crear no linealidad entre las capas neuronales, se utilizarán diferentes funciones de activación. Los resultados de la última capa se activarán mediante una función sigmoidea que permitirá obtener la probabilidad de movimiento del precio en cada dirección.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * LatentCount; descr.activation = SoftPlus; descr.batch = 1e4; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = TANH; descr.batch = 1e4; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions / 3; descr.activation = SIGMOID; descr.batch = 1e4; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- return true; }
Una vez completada la descripción de la arquitectura de los modelos entrenados, finalizaremos el método devolviendo el resultado lógico de las operaciones al programa que realiza la llamada.
Entrenamiento de modelos
En este punto, ya hemos trabajado bastante en la construcción de los algoritmos según nuestra propia visión de la aplicación de los enfoques propuestos por los autores del framework HiSSD y nos hemos acercado a la fase de entrenamiento de este sistema de 4 modelos. Como sugieren los autores del framework, todos los modelos se entrenarán simultáneamente offline. Para ello, usaremos la muestra de entrenamiento recogida en trabajos anteriores.
Permítame recordarle que, al recopilar la muestra de entrenamiento, se han utilizado datos históricos reales del par de divisas EURUSD para todo el año 2024 en el marco temporal M1. Los parámetros de todos los indicadores se han utilizado por defecto.
Pero volveremos a esa cuestión más adelante. Ahora nos centraremos en el programa de entrenamiento de modelos. El entrenamiento simultáneo de los 4 modelos y la implementación de sus algoritmos de interacción han requerido modernizar el experto correspondiente. En el marco de este artículo no analizaremos al completo el código del programa, solo nos centraremos en el método de entrenamiento directo de modelos, el método Train.
void Train(void) { //--- vector<float> probability = vector<float>::Full(Buffer.Size(), 1.0f / Buffer.Size()); //--- vector<float> result, target, state; matrix<float> fstate = matrix<float>::Zeros(1, NForecast * BarDescr); bool Stop = false; //--- uint ticks = GetTickCount();
En este caso, primero realizaremos un pequeño trabajo preparatorio que generará un vector de probabilidades para seleccionar las trayectorias del búfer de reproducción de experiencias. De inicio, se supone una distribución de probabilidad uniforme: cada trayectoria tiene la misma probabilidad de ser seleccionada para el entrenamiento.
Sin embargo, a medida que se termina de procesar cada paquete de entrenamiento, la distribución se ajusta: la probabilidad de seleccionar la trayectoria usada disminuye, aumentando así la prioridad de las demás no utilizadas anteriormente. Esta estrategia anima al modelo a abarca de manera uniforme el conjunto de datos de entrenamiento al completo, lo que posibilita una generalización más eficaz y robusta.
Aquí declararemos el número de variables locales que planeamos utilizar para el almacenamiento temporal de datos.
A continuación, organizaremos el proceso de aprendizaje. Para ello, crearemos un sistema de ciclos anidados.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter += Batch) { int tr = SampleTrajectory(probability); int start = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast - Batch)); if(start <= 0) { iter -= Batch; continue; } if( !Encoder.Clear() || !Task.Clear() || !Actor.Clear() ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } result = vector<float>::Zeros(NActions);
El ciclo exterior iterará los paquetes de entrenamiento. En ella, primero muestrearemos una trayectoria del búfer de reproducción de experiencias y seleccionaremos aleatoriamente un estado del entorno en ella a partir del cual comenzará el paquete de entrenamiento. Y a continuación organizaremos un ciclo anidado de enumeración secuencial de estados del entorno en el lugar seleccionado.
for(int i = start; i < MathMin(Buffer[tr].Total, start + Batch); i++) { if(!state.Assign(Buffer[tr].States[i].state) || MathAbs(state).Sum() == 0 || !bState.AssignArray(state)) { iter -= Batch + start - i; break; }
El cuerpo del ciclo anidado es donde organizaremos el proceso de entrenamiento del modelo. En primer lugar, transferiremos a un búfer de datos la descripción seleccionada del estado del entorno de la muestra de entrenamiento, preparándola para transferirla a nuestros modelos.
A continuación, generaremos un vector temporal del estado del entorno analizado.
bTime.Clear(); double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bTime.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bTime.GetIndex() >= 0) bTime.BufferWrite();
Luego prepararemos la descripción de los datos del estado de la cuenta y las posiciones abiertas.
//--- Account float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; float profit = float(bState[0] / _Point * (result[0] - result[3])); bAccount.Clear(); bAccount.Add(1); bAccount.Add((PrevEquity + profit) / PrevEquity); bAccount.Add(profit / PrevEquity); bAccount.Add(MathMax(result[0] - result[3], 0)); bAccount.Add(MathMax(result[3] - result[0], 0)); bAccount.Add((bAccount[3] > 0 ? profit / PrevEquity : 0)); bAccount.Add((bAccount[4] > 0 ? profit / PrevEquity : 0)); bAccount.Add(0); bAccount.AddArray(GetPointer(bTime)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
Con esto completaremos el proceso inicial de preparación de datos, y aplicaremos una pasada directa de nuestros modelos. Primero llamaremos al método de pasada directa del codificador de estado del entorno pasándole el búfer correspondiente de datos previamente preparados.
//--- Feed Forward if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Le seguirá el Controlador, que analizará las habilidades generales a partir del estado latente del Codificador, además del búfer de descripción del estado del entorno.
if(!Task.feedForward((CBufferFloat*)GetPointer(bState), 1, false, GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
A la entrada del Gestor, suministraremos el vector de descripción del estado de la cuenta y los resultados del trabajo del Controlador, que habrá formado un tensor de las diversas variantes de operaciones comerciales.
if(!Actor.feedForward((CBufferFloat*)GetPointer(bAccount), 1, false, GetPointer(Task), -1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Y el modelo de predicción para determinar la dirección más probable del próximo movimiento de los precios solo analizará las habilidades generales del estado latente del Codificador.
if(!Probability.feedForward(GetPointer(Encoder), LatentLayer, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
En esta fase, cada modelo habrá analizado los datos de origen y producido algunos de sus propios resultados. Ahora tendremos que compararlos con los valores objetivo, pero ¿de dónde podemos sacarlos?
A la salida del codificador, esperamos obtener una descripción predictiva de los estados del entorno posteriores. Para formar el tensor de valores objetivo, extraeremos los datos reales de los estados posteriores de la muestra de entrenamiento y los reordenamos en el orden deseado.
//--- Look for target target = vector<float>::Zeros(NActions); bActions.AssignArray(target); if(!state.Assign(Buffer[tr].States[i + NForecast].state) || !state.Resize(NForecast * BarDescr) || MathAbs(state).Sum() == 0) { iter -= Batch + start - i; break; } if(!fstate.Resize(1, NForecast * BarDescr) || !fstate.Row(state, 0) || !fstate.Reshape(NForecast, BarDescr)) { iter -= Batch + start - i; break; } for(int j = 0; j < NForecast / 2; j++) { if(!fstate.SwapRows(j, NForecast - j - 1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
Ahora podremos pasarlos como valores objetivo del codificador del entorno y ajustar los parámetros del modelo para minimizar el error de predicción.
//--- State Encoder Result.AssignArray(fstate); if(!Encoder.backProp(Result, (CBufferFloat*)NULL, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
También utilizaremos los mismos datos para construir valores objetivo para otros modelos, pero de una forma más sofisticada. Para generar una operación comercial óptima, además del próximo movimiento de precios, que ya hemos descargado de la muestra de entrenamiento, necesitaremos analizar la presencia de posiciones abiertas. Al fin y al cabo, cuando están disponibles, buscamos puntos de salida. Y estos son diferentes para las posiciones largas y cortas.
target = fstate.Col(0).CumSum(); if(result[0] > result[3]) { float tp = 0; float sl = 0; float cur_sl = float(-(result[2] > 0 ? result[2] : 1) * MaxSL * Point()); int pos = 0; for(int j = 0; j < NForecast; j++) { tp = MathMax(tp, target[j] + fstate[j, 1] - fstate[j, 0]); pos = j; if(cur_sl >= target[j] + fstate[j, 2] - fstate[j, 0]) break; sl = MathMin(sl, target[j] + fstate[j, 2] - fstate[j, 0]); } if(tp > 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = float(MathMin(tp / (MaxTP * Point()), 1)); result[0] = MathMax(result[0] - result[3], 0.011f); result[5] = result[1] = tp; result[4] = result[2] = sl; result[3] = 0; bActions.AssignArray(result); } }
else { if(result[0] < result[3]) { float tp = 0; float sl = 0; float cur_sl = float((result[5] > 0 ? result[5] : 1) * MaxSL * Point()); int pos = 0; for(int j = 0; j < NForecast; j++) { tp = MathMin(tp, target[j] + fstate[j, 2] - fstate[j, 0]); pos = j; if(cur_sl <= target[j] + fstate[j, 1] - fstate[j, 0]) break; sl = MathMax(sl, target[j] + fstate[j, 1] - fstate[j, 0]); } if(tp < 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = float(MathMin(-tp / (MaxTP * Point()), 1)); result[3] = MathMax(result[3] - result[0], 0.011f); result[2] = result[4] = tp; result[1] = result[5] = sl; result[0] = 0; bActions.AssignArray(result); } }
Y en caso de que no haya posiciones abiertas, buscaremos un punto de entrada. Aquí determinaremos primero la próxima dirección del movimiento del precio y su intensidad.
else { ulong argmin = target.ArgMin(); ulong argmax = target.ArgMax(); float max_sl = float(MaxSL * Point()); while(argmax > 0 && argmin > 0) { if(argmax < argmin && target[argmax] / 2 > MathAbs(target[argmin]) && MathAbs(target[argmin]) < max_sl) break; if(argmax > argmin && target[argmax] < MathAbs(target[argmin] / 2) && target[argmax] < max_sl) break; target.Resize(MathMin(argmax, argmin)); argmin = target.ArgMin(); argmax = target.ArgMax(); }
Y solo entonces definiremos los parámetros de la operación comercial.
if(argmin == 0 || (argmax < argmin && argmax > 0)) { float tp = 0; float sl = 0; float cur_sl = - float(MaxSL * Point()); ulong pos = 0; for(ulong j = 0; j < argmax; j++) { tp = MathMax(tp, target[j] + fstate[j, 1] - fstate[j, 0]); pos = j; if(cur_sl >= target[j] + fstate[j, 2] - fstate[j, 0]) break; sl = MathMin(sl, target[j] + fstate[j, 2] - fstate[j, 0]); } if(tp > 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = (float)MathMin(tp / (MaxTP * Point()), 1); result[0] = float(MathMax(Buffer[tr].States[i].account[0] / 100 * 0.01, 0.011)); result[5] = result[1] = tp; result[4] = result[2] = sl; result[3] = 0; bActions.AssignArray(result); } }
else { if(argmax == 0 || argmax > argmin) { float tp = 0; float sl = 0; float cur_sl = float(MaxSL * Point()); ulong pos = 0; for(ulong j = 0; j < argmin; j++) { tp = MathMin(tp, target[j] + fstate[j, 2] - fstate[j, 0]); pos = j; if(cur_sl <= target[j] + fstate[j, 1] - fstate[j, 0]) break; sl = MathMax(sl, target[j] + fstate[j, 1] - fstate[j, 0]); } if(tp < 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = (float)MathMin(-tp / (MaxTP * Point()), 1); result[3] = float(MathMax(Buffer[tr].States[i].account[0] / 100 * 0.01, 0.011)); result[2] = result[4] = tp; result[1] = result[5] = sl; result[0] = 0; bActions.AssignArray(result); } } } } }
El "funcionamiento óptimo de las operaciones" solo se utilizará para la entrenamiento del Gestor.
//--- Actor Policy if(!Actor.backProp(GetPointer(bActions), (CNet*)GetPointer(Task), -1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
A continuación, generaremos el tensor de valores objetivo del Controlador. Aquí también será bastante lógico utilizar los parámetros de la "operación comercial óptima". Pero en ella se especificará un volumen comercial que no podrá determinarse únicamente sobre la base de los análisis del entorno de que dispone el Controlador. También necesitará datos sobre el estado actual de la cuenta, que solo recibirá el Gestor. Por ello, sustituiremos el valor absoluto del volumen comercial por la probabilidad de beneficio. Para una operación comercial óptima, la probabilidad de alcanzar los valores objetivo será de 1.
//--- Agents target=result; if(target[0] > 0) target[0] = 1; if(target[3] > 0) target[3] = 1;
Luego repetiremos la "operación comercial óptima" ajustada para un número determinado de agentes y la pasaremos al Controlador como valor objetivo.
Result.Clear(); for(int i = 0; i < BarDescr; i++) { if(!Result.AddArray(target)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } } if(!Task.backProp(Result, (CNet*)GetPointer(Encoder), LatentLayer) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Tenga en cuenta que todos los agentes recibirán los mismos valores objetivo. Sin embargo, no esperamos que funcionen de forma sincrónica, ya que todos ellos analizan únicamente los datos de observación local de sus series temporales unitarias. Por consiguiente, una interpretación unidireccional del estado del entorno analizado por parte de múltiples agentes ofrecerá potencialmente una señal más fuerte al Gestor.
Solo nos quedará por determinar los valores objetivo del modelo de previsión del movimiento de precios más probable. También en este caso volveremos a los datos de los estados del entorno posteriores. Tomaremos la suma acumulada de la dinámica de precios y determinamos el movimiento máximo en un horizonte de planificación determinado. La dirección de la desviación máxima será la tendencia prioritaria que usaremos para entrenar el modelo predictivo.
//--- Probability target = vector<float>::Zeros(NActions / 3); vector<float> trend=fstate.Col(0).CumSum(); ulong argmax=MathAbs(trend).ArgMax(); if(trend[argmax] > 0) target[0] = 1; else if(trend[argmax] < 0) target[1] = 1; if(!Result.AssignArray(target) || !Probability.backProp(Result, (CNet*)GetPointer(Encoder),LatentLayer) || !Encoder.backPropGradient((CBufferFloat*)NULL, (CBufferFloat*)NULL, LatentLayer) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Tenga en cuenta que en este caso, pasaremos el gradiente de error al nivel de habilidades generales y ajustaremos los parámetros del Codificador. Nuestro objetivo es que las habilidades genéricas informen sobre la tendencia prioritaria.
Ahora solo nos quedará informar al usuario del progreso del entrenamiento del modelo y pasar a la siguiente iteración del sistema de ciclos.
if(GetTickCount() - ticks > 500) { double percent = double(iter + i - start) * 100.0 / (Iterations); string str = StringFormat("%-12s %6.2f%% -> Error %15.8f\n", "Encoder", percent, Encoder.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Task", percent, Task.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-13s %6.2f%% -> Error %15.8f\n", "Probability", percent, Probability.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Después de ejecutar con éxito todas las iteraciones del sistema de ciclos creado, mostraremos los resultados del entrenamiento del modelo en el registro e inicializaremos el proceso de finalización del EA.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Encoder", Encoder.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Task", Task.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Probability", Probability.getRecentAverageError()); ExpertRemove(); //--- }
El código completo de este programa figura en los anexos. También presentamos los programas de recopilación de las muestras de entrenamiento y prueba de los modelos entrenados. Le sugiero que lea por sí mismo las ediciones puntuales introducidas en los programas anteriores.
Simulación
Y ahora hemos llegado, quizá, a la fase más crítica de nuestro trabajo: la evaluación de la eficacia de las soluciones aplicadas sobre datos históricos reales. Como ya hemos señalado, los modelos se han entrenado utilizando datos reales del mercado para todo el año 2024.
Para verificar objetivamente la calidad de la política entrenada, probaremos los modelos entrenados en el simulador de estrategias de MetaTrader 5, utilizando los datos históricos para el periodo de enero a marzo de 2025. Todos los demás parámetros, incluidas las condiciones del mercado, los marcos temporales y la configuración de la simulación, se han mantenido sin cambios para garantizar que los resultados sean correctos y comparables.
Ahora le presentamos los resultados de las pruebas.


Durante los 3 meses del periodo de prueba, el modelo ha realizado 860 transacciones comerciales y 340 de ellas se han cerrado con beneficios. Esto supone el 39,53% de las transacciones rentables. Sin embargo, la transacción rentable media ha sido un 70% superior al mismo indicador de las transacciones con pérdidas, lo que ha ayudado a compensar el bajo nivel de transacciones rentables y a obtener beneficios en los resultados de las pruebas.
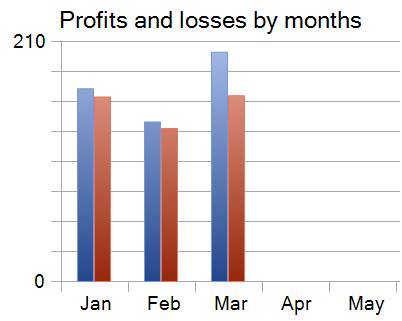
Cabe señalar que cada uno de los 3 meses del periodo de prueba se ha cerrado con beneficios.
Conclusión
En este artículo, hemos aprendido aspectos del framework HiSSD que hemos adaptado para tareas de trading algorítmico. La idea básica (la división de las habilidades en genéricas y específicas) ha demostrado su eficacia en un mercado que cambia dinámicamente. Esta estructura permite a los agentes adaptarse más rápidamente a los cambios sin necesidad de volver a entrenarse.
La aplicación ha tenido en cuenta las peculiaridades de los datos financieros: el entrenamiento se ha realizado con cotizaciones históricas reales de 2024, mientras que la simulación se ha realizado con datos nuevos de principios de 2025. Esto ha permitido evaluar objetivamente el rendimiento de los modelos en condiciones próximas a las del comercio real.
Sin embargo, una vez más, me gustaría recordarle que antes de su aplicación al trading real, el modelo deberá entrenarse con una muestra más representativa, seguida de pruebas exhaustivas.
Enlaces
- Learning Generalizable Skills from Offline Multi-Task Data for Multi-Agent Cooperation
- Otros artículos de la serie
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor experto para recopilar ejemplos con el método Real-ORL |
| 3 | Study.mq5 | Asesor | Asesor de entrenamiento de modelos |
| 4 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 5 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema y la arquitectura del modelo |
| 6 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código del programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/17739
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso