
Нейросети в трейдинге: Иерархия навыков для адаптивного поведения агентов (Окончание)

Введение
В предыдущей статье мы познакомились с теоретическими аспектами фреймворка HiSSD (Hierarchical and Separate Skill Discovery), который представляет собой современный подход к офлайн-обучению мультиагентных систем, способных работать в условиях сложной и динамично изменяющейся среды. Этот фреймворк позволяет обучать агентов эффективно взаимодействовать друг с другом и адаптироваться к меняющимся условиям. Первоначально HiSSD был протестирован в симуляторных средах, однако, предложенные подходы и архитектура делают его особенно актуальным для применения на финансовых рынках, где ситуация может резко меняться в течение нескольких секунд, а от интеллектуальных торговых агентов требуется оперативная и скоординированная реакция.
Одним из ключевых преимуществ HiSSD является его высокая адаптивность. В условиях трейдинга, когда экономические индикаторы, поведение участников рынка или новости могут внезапно изменить рыночный ландшафт, агенты, обученные в рамках HiSSD, способны мгновенно подстраиваться без необходимости полного переобучения. Это стало возможным, благодаря архитектуре, основанной на двухуровневом разделении навыков: общие и специфические. Общие навыки — это паттерны поведения, актуальные во множестве ситуаций, например, распознавании рыночных трендов или оценке риска. Специфические навыки отвечают за поведение в уникальных или узкоспециализированных условиях. Такая двухуровневая структура позволяет агентам HiSSD действовать стабильно и эффективно, независимо от изменения рыночных условий.
Ещё одним сильным качеством HiSSD является его масштабируемость. Финансовые рынки представляют собой многоагентную систему. Каждый участник, будь то человек, торговый робот или крупный маркет-мейкер, влияет на рыночную динамику. В таких условиях важно иметь возможность масштабировать систему, не разрушая её согласованность. HiSSD предлагает иерархическую архитектуру, где каждый агент может координировать свое поведение с другими через общие управляющие модули. Это особенно полезно при построении комплексных стратегий. На практике это позволяет строить более надёжные и устойчивые торговые системы.
Авторская визуализация архитектуры фреймворка HiSSD представлена ниже.
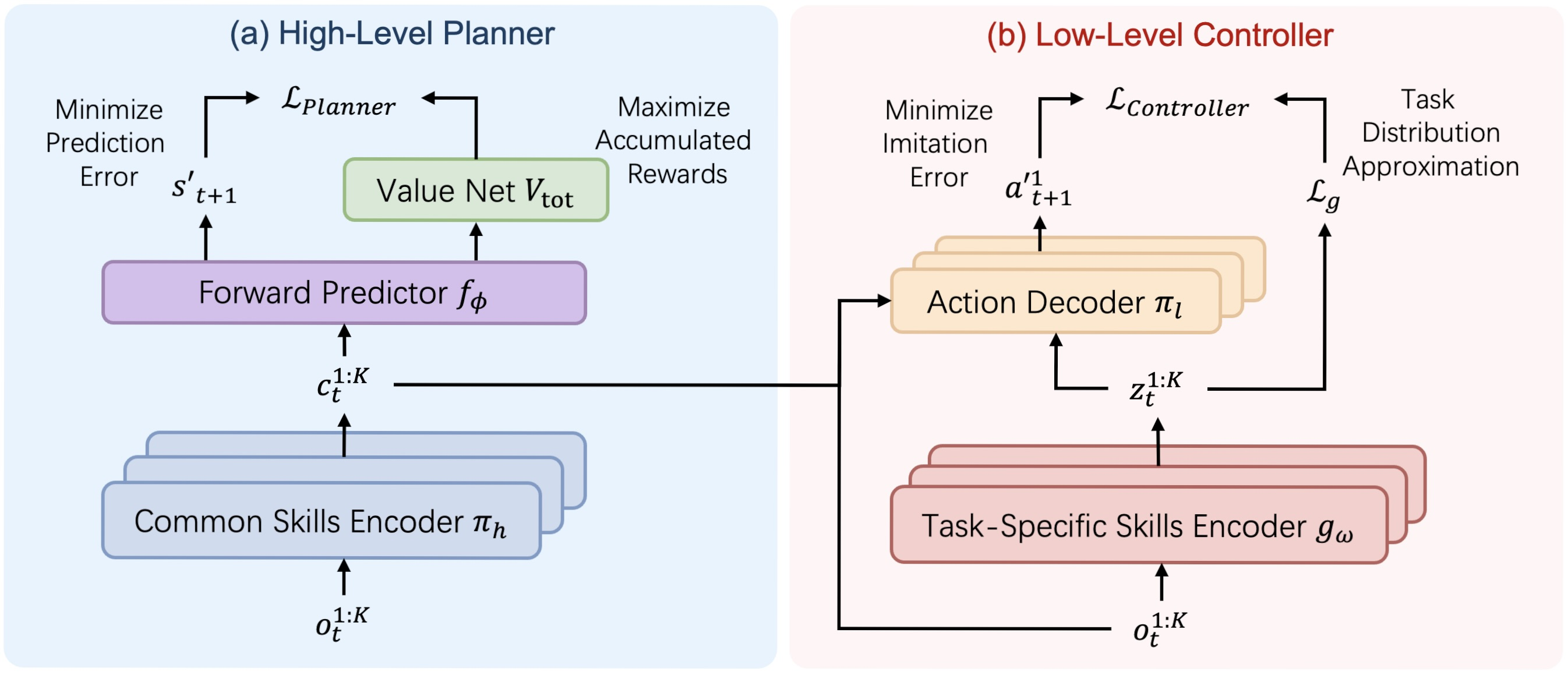
В практической части предыдущей статьи была начата работа по реализации средствами MQL5 собственного видения подходов, предложенных авторами фреймворка. В частности, был представлен вариант реализации универсального энкодера навыков, который был построен в рамках объекта CNeuronSkillsEncoder. Сегодня мы продолжим начатую работу и доведем её до логического завершения с тестированием эффективности реализованных подходов на реальных исторических данных.
Но прежде, чем продолжить работу по реализации собственного видения предложенных авторами фреймворка подходов, предлагаю ещё раз посмотреть на структуру фреймворка HiSSD. Мы видим здесь 2 крупных блока: Планировщик и Контроллер.
Первый обладает линейным потоком информации. Исходные данные проходят через энкодер общих навыков, которые передаются в предсказательный модуль для прогнозирования последующего состояния и ожидаемой стоимости. Такую архитектуру мы можем построить существующими средствами в виде линейной модели.
Немного сложнее обстоят дела в плане организации работы Контроллера. В его структуре можно выделить декодер действий агентов, который получает исходные данные из 3 источников. Среди них локальные наблюдения агентов, общие и специфические навыки, генерируемые разными энкодерами навыков. Это обстоятельство побуждает нас к построению Контролера в виде отдельного объекта.
Объект контролера
Следующим этапом нашей работы будет построение объекта Контроллера, функционал которого организуем в рамках объекта CNeuronHiSSDLowLevelControler.
class CNeuronHiSSDLowLevelControler: public CNeuronConvOCL { protected: uint iTaskSkills; uint iCommonSkills; //--- CNeuronSkillsEncoder cTaskSpecificSkillsEncoder; CNeuronTransposeOCL cTranspose; CNeuronBaseOCL cObservAndSkillsConcat; CNeuronBatchNormOCL cNormalizarion; CNeuronConvOCL cActionDecoder[2]; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *second) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None ) override; public: CNeuronHiSSDLowLevelControler(void) {}; ~CNeuronHiSSDLowLevelControler(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint time_step, uint variables, uint task_skills, uint common_skills, uint n_actions, uint window, uint step, uint window_key, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronHiSSDLowLevelControler; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
Здесь стоит обратить внимание, что декодер действий агента в Контроллере фреймворка HiSSD предполагает параллельную работу нескольких независимых агентов. Данный функционал можно реализовать с помощью последовательных сверточных слоев. А так как декодер располагается на выходе модуля, то мы можем функционал последнего слоя декодера выполнять средствами родительского класса. Именно по этой причине мы выбрали объект сверточного слоя в качестве родительского при создании модуля Контроллера.
В представленной структуре нового объекта мы видим несколько внутренних объектов, с функционалом которых детально познакомимся в процессе построения алгоритмов прямого и обратного проходов. Здесь же стоит отметить их статическое объявление, что позволяет нам оставить пустыми конструктор и деструктор класса. Инициализация всех внутренних объектов, в том числе и унаследованных, осуществляется в методе Init.
Как обычно, в параметрах метода инициализации получаем ряд констант, позволяющих однозначно интерпретировать архитектуру необходимого объекта.
bool CNeuronHiSSDLowLevelControler::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint time_step, uint variables, uint task_skills, uint common_skills, uint n_actions, uint window, uint step, uint window_key, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronConvOCL::Init(numOutputs, myIndex, open_cl, window_key, window_key, n_actions, 1, variables, optimization_type, batch)) return false; SetActivationFunction(SIGMOID);
В теле метода, по уже сложившейся традиции, сразу вызываем одноименный метод родительского класса. И здесь нужно обратить внимание на несколько ключевых моментов.
Прежде всего, мы предполагаем использовать функционал родительского класса в качестве последнего слоя декодера действий агентов. Соответственно, на вход методов родительского класса будем передавать результаты предварительной обработки внутренних объектов декодера. Внутри декодера ожидается организация параллельных потоков информации в процессе формирования "сознания" отдельных агентов. Поэтому окно анализируемых данных и его шаг создаваемого сверточного слоя равны размерности вектора внутреннего потока информации отдельного агента.
На выходе слоя мы ожидаем получить тензор действий агентов. Следовательно, количество фильтров сверточного слоя равно размеру вектора действий одного агента.
И ещё один момент. С целью организации полностью независимого обучения отдельных агентов, мы должны предоставить им уникальные весовые параметры. Для этого указываем единичную размерность анализируемой последовательности, а количество обучаемых агентов переносим в параметр числа унитарных последовательностей. Такой простой прием позволяет нам организовать параллельную работу нужного числа полностью независимых агентов.
Далее мы переходим к инициализации объектов, объявленных в структуре нового класса. Напомню, инициализация унаследованных объектов осуществляется в одноименном методе родительского класса, который был вызван выше.
Первый инициализируем энкодер специфических навыков, роль которого выполняет универсальный энкодер навыков, созданный нами в предыдущей статье.
int index = 0; if(!cTaskSpecificSkillsEncoder.Init(0, index, OpenCL, time_step, variables, task_skills, window, step, window_key, heads, optimization, iBatch)) return false; cTaskSpecificSkillsEncoder.SetActivationFunction(None);
А затем, сохраняем необходимые нам константы описания архитектуры объекта.
iTaskSkills = task_skills; iCommonSkills = MathMax(common_skills, 1);
Обратите внимание, размерность специфических навыков сохраняем как есть, а для общих навыков вводим минимально допустимое значение. Здесь все довольно прозрачно. Дело в том, что размерность специфических навыков мы ранее передали в параметрах метода инициализации энкодера. И успешное выполнение данного метода подтверждает допустимость полученного значения. А вот тензор общих навыков мы будем получать от Планировщика, который, в данной реализации, является другим объектом и даже другой моделью. Поэтому мы можем указать лишь минимально допустимое значение.
Следующим этапом, переходим к организации работы декодера действий агентов. Авторы фреймворка HiSSD предлагают на вход декодера подать информацию от 3 источников данных:
- локальные наблюдения агента;
- общие навыки;
- специфические навыки.
Как уже было сказано выше, тензор общих навыков мы планируем получать от другой модели по второму информационному потоку. Специфические навыки формируются инициализированным выше энкодером на основании локальных наблюдений агента, получаемых по основному информационному потоку. Следовательно, на данном этапе у нас уже есть все необходимые данные. Нужно лишь собрать их в единый объект.
Однако здесь следует обратить внимание, что каждый агент должен получить свой уникальный набор информации. Следовательно, необходимо организовать правильную конкатенацию данных. Тензоры навыков представлены в виде "воображаемой" матрицы, строки которой представлены векторами навыков отдельных агентов. Построчная конкатенация позволит нам получить желаемую матрицу исходных данных, пригодную для организации параллельных независимых потоков информации функционалом сверточных слоев.
Немного иначе обстоят дела с тензором локальных наблюдений. Мы уже говорили, что в качестве исходных данных, как и ранее, планируется использование мультимодального временного ряда. При этом, каждый агент для анализа получает свою унитарную последовательность. И прежде, чем добавить их к навыкам, нам необходимо транспонировать матрицу в представление, удобное для анализа унитарных последовательностей.
index++; if(!cTranspose.Init(0, index, OpenCL, time_step, variables, optimization, iBatch)) return false;
Далее определим размерность вектора исходных данных одного агента и инициализируем объект для сохранения конкатенированного тензора.
uint window_size = (time_step + iTaskSkills + iCommonSkills); index++; if(!cObservAndSkillsConcat.Init(0, index, OpenCL, window_size * iVariables, optimization, iBatch)) return false; cObservAndSkillsConcat.SetActivationFunction(None);
Хочется ещё раз обратить внимание на использование данных из 3 источников. С целью приведения их в сопоставимый вид, воспользуемся слоем пакетной нормализации данных.
index++; if(!cNormalizarion.Init(0, index, OpenCL, cObservAndSkillsConcat.Neurons(), iBatch, optimization)) return false; cNormalizarion.SetActivationFunction(None);
После завершения работы с объектами подготовки данных, мы переходим непосредственно к созданию нейронных слоев декодера действий. Для этого мы организуем небольшой цикл, в теле которого инициализируем сверточные слои декодера. Принципы инициализации были подробно изложены при вызове метода инициализации родительского класса.
for(uint i = 0; i < cActionDecoder.Size(); i++) { index++; if(!cActionDecoder[i].Init(0, index, OpenCL, window_size, window_size, window_key, 1, iVariables, optimization, iBatch)) return false; cActionDecoder[i].SetActivationFunction(SoftPlus); window_size = window_key; } //--- return true; }
После чего, завершаем работу метода, вернув логический результат выполнения операций вызывающей программе.
Следующим этапом переходим к построению алгоритма прямого прохода в рамках метода feedForward. Как уже было сказано выше, здесь мы работаем с 2 источниками данных. По основному информационному потоку получаем мультимодальный временной ряд описания состояния окружающей среды, а по вспомогательному информационному потоку — тензор общих навыков.
bool CNeuronHiSSDLowLevelControler::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!SecondInput) return false;
В теле метода мы сначала проверяем актуальность полученного указателя на объект тензора общих навыков. При этом не проверяем актуальность указателя на объект основного информационного потока. Вместо этого, просто передаем его в одноименный метод энкодера специфических навыков, в теле которого уже организована соответствующая точка контроля.
if(!cTaskSpecificSkillsEncoder.FeedForward(NeuronOCL)) return false;
После генерации тензора специфических навыков, мы транспонируем тензор описания состояния окружающей среды и построчно его конкатенируем с двумя матрицами навыков (общих и специфических).
if(!cTranspose.FeedForward(NeuronOCL)) return false; if(!Concat(cTranspose.getOutput(), cTaskSpecificSkillsEncoder.getOutput(), SecondInput, cObservAndSkillsConcat.getOutput(), cTranspose.GetCount(), iTaskSkills, iCommonSkills, iVariables)) return false;
Собранные данные нормализуем и проводим через 3 слоя декодера действий агентов, на выходе которого получаем ожидаемый результат в виде конкатенированного тензора действий всех агентов.
if(!cNormalizarion.FeedForward(cObservAndSkillsConcat.AsObject())) return false; CNeuronBaseOCL *neuron = cNormalizarion.AsObject(); for(uint i = 0; i < cActionDecoder.Size(); i++) { if(!cActionDecoder[i].FeedForward(neuron)) return false; neuron = cActionDecoder[i].AsObject(); } //--- return CNeuronConvOCL::feedforward(neuron); }
После чего, завершаем работу метода, вернув логический результат вызывающей программе.
Далее переходим к организации процессов обратного прохода. Как вы уже знаете, данный процесс мы разбиваем на 2 этапа:
- распределение градиента ошибки между всеми участниками процесса, в соответствии с их влиянием на итоговый результат модели;
- оптимизация параметров модели в сторону снижения ошибки.
Первый этап организован в методе calcInputGradients. В параметрах данного метода получаем указатели на объекты двух информационных потоков исходных данных и соответствующих градиентов ошибки. Актуальность полученных указателей сразу проверяем.
bool CNeuronHiSSDLowLevelControler::calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = -1) { if(!NeuronOCL || !SecondGradient) return false;
Процесс распределения градиентов ошибки организован с полным соблюдением информационных потоков прямого прохода, только информация передается в обратном направлении. Прямой проход был завершен работой декодера действий. Следовательно, распределение градиентов ошибки начинаем с декодера, перебирая его сверточные слои, опять же, в обратном направлении.
uint total = cActionDecoder.Size(); if(total <= 0) return false; CObject *neuron = cActionDecoder[total - 1].AsObject(); //--- if(!CNeuronConvOCL::calcInputGradients(neuron)) return false; for(int i = int(total - 2); i >= 0; i--) { if(!cActionDecoder[i].calcHiddenGradients(neuron)) return false; neuron = cActionDecoder[i].AsObject(); }
Полученные значения проводим через слой нормализации данных до уровня конкатенированного тензора трех сущностей.
if(!cNormalizarion.calcHiddenGradients(neuron)) return false; if(!cObservAndSkillsConcat.calcHiddenGradients(cNormalizarion.AsObject())) return false;
А затем распределяем градиенты ошибки по трем информационным потокам, путем деконкатенации данных.
if(!DeConcat(cTranspose.getGradient(), cTaskSpecificSkillsEncoder.getGradient(), SecondGradient, cObservAndSkillsConcat.getGradient(), cTranspose.GetCount(), iTaskSkills, iCommonSkills, iVariables)) return false;
Здесь следует обратить внимание, что каждый из информационных потоков может обладать своей функцией активации. Поэтому проверяем наличие функций активации по всем информационным потокам и, при необходимости, корректируем полученные значения на соответствующие производные функций.
if(SecondActivation != None) { if(!DeActivation(SecondInput, SecondGradient, SecondGradient, SecondActivation)) return false; } if(NeuronOCL.Activation() != None) { if(!DeActivation(cTranspose.getOutput(), cTranspose.getGradient(), cTranspose.getGradient(), NeuronOCL.Activation())) return false; } if(cTaskSpecificSkillsEncoder.Activation() != None) { if(!DeActivation(cTaskSpecificSkillsEncoder.getOutput(), cTaskSpecificSkillsEncoder.getGradient(), cTaskSpecificSkillsEncoder.getGradient(), cTaskSpecificSkillsEncoder.Activation())) return false; }
На данном этапе мы передали градиент ошибки в магистраль вспомогательного потока исходных данных и можем про него забыть. Остается суммировать погрешность на уровне основной магистрали исходных данных от двух информационных потоков. Вначале проведем данные через энкодер специфических навыков.
if(!NeuronOCL.calcHiddenGradients(cTaskSpecificSkillsEncoder.AsObject())) return false;
А затем, осуществим подмену указателя на буфер градиентов ошибки объекта исходных данных и проведем градиент ошибки по второму информационному потоку от объекта транспонирования.
CBufferFloat *temp = NeuronOCL.getGradient(); if(!NeuronOCL.SetGradient(cTranspose.getPrevOutput(), false) || !NeuronOCL.calcHiddenGradients(cTranspose.AsObject()) || !SumAndNormilize(temp, NeuronOCL.getGradient(), temp, iVariables, false, 0, 0, 0, 1) || !NeuronOCL.SetGradient(temp, false)) return false; //--- return true; }
Данные двух информационных потоков суммируем и возвращаем указатели на буфера данных в исходное состояние.
И теперь можно смело завершить работу метода, но предварительно вернем логический результат выполнения операций вызывающей программе.
На этом завершаем рассмотрение алгоритмов нашего видения работы Контроллера. С полным кодом нового объекта и всех его методов вы можете самостоятельно ознакомиться во вложении.
Архитектура моделей
После завершения работы по построению отдельных объектов фреймворка HiSSD, переходим к описанию архитектуры обучаемых моделей. И здесь надо сказать, что мы планируем обучать сразу целых 4 модели.
Одна из них — Энкодер состояния окружающей среды, который в данном случае выполняет роль Планировщика в фреймворке HiSSD. Его мы планируем обучать в стиле обучения с учителем. Из анализируемого состояния окружающей среды генерируются общие навыки агентов. А из полученных навыков планируется описание будущих состояний окружающей среды на заданный горизонт планирования.
Здесь, конечно, можно заметить некоторое отклонение от авторского представления фреймворка HiSSD. Ведь в нем предусмотрено планирование лишь одного последующего состояния. Однако, мы хотим обучить политику, способную открывать позицию и удерживать её некоторое время, что требует более глубокого анализа и длительного планирования.
Вторая модель — Контроллер, который анализирует текущее состояние окружающей среды и генерирует тензор действий нескольких агентов.
Третья модель — Менеджер (Актер). В нашей реализации данная модель анализирует состояния счета, оценивает варианты действий, предложенные агентами Контроллера и, на основании проведенного анализа, принимает решение о совершении торговой операции.
Ну и четвертая прогнозная модель, которая определяет вероятность направления предстоящего ценового движения.
Архитектура всех обучаемых моделей представлена в методе CreateDescriptions.
bool CreateDescriptions(CArrayObj *&encoder, CArrayObj *&task, CArrayObj *&actor, CArrayObj *&probability) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!task) { task = new CArrayObj(); if(!task) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; }
В параметрах метода получаем указатели на 4 динамических массива для записи описания архитектуры соответствующих моделей. Актуальность всех полученных указателей проверяется и, при необходимости, создаются новые экземпляры объектов.
Вначале описываем архитектуру Энкодера состояния окружающей среды. Как обычно, на входе модели используем базовый полносвязный нейронный слой достаточного размера для записи исходных данных.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
На вход модели подаются необработанные исходные данные, которые приводим в сопоставимый вид средствами слоя пакетной нормализации.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Далее идет объект универсального энкодера навыков, который, в данном случае, должен сгенерировать тензор общих навыков.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSkillsEncoder; descr.count = HistoryBars; { int temp[] = {BarDescr, NSkills, 4}; // Variables, Common Skills, Heads if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.window = 8; descr.step = 1; descr.window_out = 32; prev_count = descr.windows[0]; int prev_out = descr.windows[1]; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
За ним располагаем 2 сверточных слоя, которые на основании тензора общих навыков, планируют предстоящее движение отдельных унитарных последовательностей анализируемого мультимодального временного ряда.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = prev_out; descr.step = prev_out; prev_out=descr.window_out = 4*NForecast; descr.layers = prev_count; descr.activation = SoftPlus; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = prev_out; descr.step = prev_out; prev_out=descr.window_out = NForecast; descr.layers = prev_count; descr.activation = TANH; if(!encoder.Add(descr)) { delete descr; return false; }
Здесь стоит обратить внимание, что на основании вектора общих навыков одного агента строится прогнозное поведение одной унитарной последовательности на заданный горизонт планирования. Таким образом, на выходе нашего блока планирования последовательность данных будет отличаться от привычного мультимодального временного ряда. Для приведения данных в нужное представление нам необходимо их транспонировать.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_out; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
А затем, вернем их в распределение исходных данных путем обратной нормализации.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = prev_count*prev_out; descr.layers = 1; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
На этом завершается описание архитектуры Энкодера состояния окружающей среды. Но прежде, чем перейти к описанию следующей модели, сохраним объект описания скрытого состояния с тензором общих навыков на выходе.
//--- Latent CLayerDescription *latent = encoder.At(LatentLayer); if(!latent) return false;
Второй моделью, как уже было сказано выше, является Контроллер. В нем генерируются специфические навыки агентов на основании анализа того же описания состояния окружающей среды. Поэтому мы просто копируем описание первых двух слоев из предыдущей модели.
//--- Task task.Clear(); //--- Input layer if(!task.Add(encoder.At(0))) { return false; } //--- layer 1 if(!task.Add(encoder.At(1))) { return false; }
И завершает данную модель построенный выше объект Контроллера.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronHiSSDLowLevelControler; descr.count = HistoryBars; { int temp[] = {latent.windows[0], // Variables NSkills, // Task Skills latent.windows[1], // Common Skills NActions, // Action Space 4}; // Heads if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.window = 8; descr.step = 1; descr.window_out = 32; prev_count = descr.windows[0]; prev_out = descr.windows[3]; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = SIGMOID; if(!task.Add(descr)) { delete descr; return false; }
Третья модель — Менеджер верхнего уровня получает на вход вектора описания состояния счета. Для его записи мы так же используем базовый нейронный слой.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Полученные значения нормализуем.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = AccountDescr; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
А затем, используем модуль кросс-внимания для сопоставления текущего состояния счета и предлагаемых вариантов торговых операций.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossDMHAttention; { int temp[] = {AccountDescr, // Inputs window prev_out // Cross window }; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } { int temp[] = {1, // Inputs units prev_count // Cross units }; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.step = 4; // Heads descr.window_out = 32; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
И добавляем 3 полносвязных слоя, которые образуют так называемую голову принятия решения. Эта структура позволяет трансформировать извлечённые признаки в вектор действий Актера.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.batch = 1e4; descr.activation = TANH; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SoftPlus; descr.batch = 1e4; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions; descr.activation = SIGMOID; descr.batch = 1e4; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Прогнозная модель определения вероятности направления предстоящего движения анализирует общие навыки из латентного состояния Планировщика. Поэтому в слой исходных данных переносим параметры соответствующего объекта.
//--- Probability probability.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = latent.windows[0] * latent.windows[1]; descr.activation = latent.activation; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; }
Непосредственно анализ данных осуществляется перцептроном с 2 скрытыми полносвязными слоями. С целью создания нелинейности между нейронными слоями, используются различные функции активации. Результаты последнего слоя активируются сигмовидной функцией, что позволяет получить вероятность движения цены в каждом направлении.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * LatentCount; descr.activation = SoftPlus; descr.batch = 1e4; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = TANH; descr.batch = 1e4; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions / 3; descr.activation = SIGMOID; descr.batch = 1e4; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- return true; }
После завершения работы по описанию архитектуры обучаемых моделей, завершаем работу метода, вернув логический результат выполнения операций вызывающей программе.
Обучение моделей
На данный момент мы уже провели довольно большую работу по построению алгоритмов собственного видения реализации подходов, предложенных авторами фреймворка HiSSD и подошли к этапу обучения системы из 4 моделей. Как и было предложено авторами фреймворка, обучение всех моделей будет осуществляться одновременно офлайн. Для этого воспользуемся обучающей выборкой, собранной в рамках предыдущих работ.
Напомню, что при сборе данных обучающей выборки использовались реальные исторические данные валютной пары EURUSD за весь 2024 год на таймфрейме M1. Параметры всех индикаторов использовались по умолчанию.
Но к этому вопросу вернемся позже. А сейчас обратим внимание на программу обучения моделей. Обучение сразу 4 моделей и реализация алгоритмов их взаимодействия привели к необходимости модернизации соответствующего эксперта. В рамках данной статьи мы не будем полностью рассматривать код программы, остановимся лишь на методе непосредственного обучения моделей Train.
void Train(void) { //--- vector<float> probability = vector<float>::Full(Buffer.Size(), 1.0f / Buffer.Size()); //--- vector<float> result, target, state; matrix<float> fstate = matrix<float>::Zeros(1, NForecast * BarDescr); bool Stop = false; //--- uint ticks = GetTickCount();
Здесь мы сначала проводим небольшую подготовительную работу, в ходе которой формируется вектор вероятностей выбора траекторий из буфера воспроизведения опыта. На начальном этапе предполагается равномерное распределение вероятностей: каждая траектория имеет одинаковый шанс быть выбранной для обучения.
Однако, по завершении обработки каждого обучающего пакета, происходит корректировка распределения: вероятность выбора использованной траектории понижается, тем самым повышается приоритет остальных, ранее неиспользованных. Такая стратегия стимулирует модель равномерно охватывать всё множество обучающих данных, обеспечивая более эффективное и устойчивое обобщение.
Тут же объявим ряд локальных переменных, которые планируем использовать для временного хранения данных.
Далее переходим к организации процесса обучения. Для этого создаем систему вложенных циклов.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter += Batch) { int tr = SampleTrajectory(probability); int start = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast - Batch)); if(start <= 0) { iter -= Batch; continue; } if( !Encoder.Clear() || !Task.Clear() || !Actor.Clear() ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } result = vector<float>::Zeros(NActions);
Внешний цикл перебирает пакеты обучения. В нем сначала семплируем траекторию из буфера воспроизведения опыта и случайным образом выбираем на ней состояние окружающей среды, с которого начнется пакет обучения. А затем организовываем вложенный цикл последовательного перебора состояний окружающей среды на выбранном участке.
for(int i = start; i < MathMin(Buffer[tr].Total, start + Batch); i++) { if(!state.Assign(Buffer[tr].States[i].state) || MathAbs(state).Sum() == 0 || !bState.AssignArray(state)) { iter -= Batch + start - i; break; }
В теле вложенного цикла мы и организуем процесс обучения моделей. Сначала перенесем описание выбранного состояния окружающей среды из обучающей выборки в буфер данных, подготовив его для передачи в наши модели.
Затем, сформируем вектор временной метки анализируемого состояния окружающей среды.
bTime.Clear(); double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bTime.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bTime.GetIndex() >= 0) bTime.BufferWrite();
После чего, подготовим данные описания состояния счета и открытых позиций.
//--- Account float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; float profit = float(bState[0] / _Point * (result[0] - result[3])); bAccount.Clear(); bAccount.Add(1); bAccount.Add((PrevEquity + profit) / PrevEquity); bAccount.Add(profit / PrevEquity); bAccount.Add(MathMax(result[0] - result[3], 0)); bAccount.Add(MathMax(result[3] - result[0], 0)); bAccount.Add((bAccount[3] > 0 ? profit / PrevEquity : 0)); bAccount.Add((bAccount[4] > 0 ? profit / PrevEquity : 0)); bAccount.Add(0); bAccount.AddArray(GetPointer(bTime)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
На этом завершается процесс подготовки исходных данных, и мы переходим к осуществлению прямого прохода наших моделей. Сначала вызываем метод прямого прохода Энкодера состояния окружающей среды, передав ему соответствующий буфер ранее подготовленных данных.
//--- Feed Forward if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
За ним идет Контроллер, который, помимо буфера описания состояния окружающей среды, анализирует общие навыки из латентного состояния Энкодера.
if(!Task.feedForward((CBufferFloat*)GetPointer(bState), 1, false, GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
На вход Менеджера подаем вектор описания состояния счета и результаты работы Контролера, который сформировал тензор из нескольких вариантов торговых операций.
if(!Actor.feedForward((CBufferFloat*)GetPointer(bAccount), 1, false, GetPointer(Task), -1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
А прогнозная модель определения наиболее вероятного направления предстоящего движения цены анализирует только общие навыки из латентного состояния Энкодера.
if(!Probability.feedForward(GetPointer(Encoder), LatentLayer, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
На данном этапе каждая модель провела анализ исходных данных и дала некоторые свои результаты. Теперь нам необходимо сравнить их с целевыми значениями, но где их взять?
На выходе Энкодера мы ожидаем получить прогнозное описание последующих состояний окружающей среды. С целью формирования тензора целевых значений, мы извлекаем из обучающей выборки реальные данные последующих состояний и переставляем из в нужном порядке.
//--- Look for target target = vector<float>::Zeros(NActions); bActions.AssignArray(target); if(!state.Assign(Buffer[tr].States[i + NForecast].state) || !state.Resize(NForecast * BarDescr) || MathAbs(state).Sum() == 0) { iter -= Batch + start - i; break; } if(!fstate.Resize(1, NForecast * BarDescr) || !fstate.Row(state, 0) || !fstate.Reshape(NForecast, BarDescr)) { iter -= Batch + start - i; break; } for(int j = 0; j < NForecast / 2; j++) { if(!fstate.SwapRows(j, NForecast - j - 1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
Теперь можно передать их в качестве целевых значений Энкодера состояния окружающей среды и скорректировать параметры модели в сторону минимизации ошибки прогнозирования.
//--- State Encoder Result.AssignArray(fstate); if(!Encoder.backProp(Result, (CBufferFloat*)NULL, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Эти же данные мы используем и для построения целевых значений для других моделей, но более изощренным способом. Для генерации оптимальной торговой операции помимо предстоящего ценового движения, которое мы уже загрузили из обучающей выборки, нам необходимо проанализировать и наличие открытых позиций. Ведь при их наличии мы ищем точки выхода. А они отличаются для длинных и коротких позиций.
target = fstate.Col(0).CumSum(); if(result[0] > result[3]) { float tp = 0; float sl = 0; float cur_sl = float(-(result[2] > 0 ? result[2] : 1) * MaxSL * Point()); int pos = 0; for(int j = 0; j < NForecast; j++) { tp = MathMax(tp, target[j] + fstate[j, 1] - fstate[j, 0]); pos = j; if(cur_sl >= target[j] + fstate[j, 2] - fstate[j, 0]) break; sl = MathMin(sl, target[j] + fstate[j, 2] - fstate[j, 0]); } if(tp > 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = float(MathMin(tp / (MaxTP * Point()), 1)); result[0] = MathMax(result[0] - result[3], 0.011f); result[5] = result[1] = tp; result[4] = result[2] = sl; result[3] = 0; bActions.AssignArray(result); } }
else { if(result[0] < result[3]) { float tp = 0; float sl = 0; float cur_sl = float((result[5] > 0 ? result[5] : 1) * MaxSL * Point()); int pos = 0; for(int j = 0; j < NForecast; j++) { tp = MathMin(tp, target[j] + fstate[j, 2] - fstate[j, 0]); pos = j; if(cur_sl <= target[j] + fstate[j, 1] - fstate[j, 0]) break; sl = MathMax(sl, target[j] + fstate[j, 1] - fstate[j, 0]); } if(tp < 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = float(MathMin(-tp / (MaxTP * Point()), 1)); result[3] = MathMax(result[3] - result[0], 0.011f); result[2] = result[4] = tp; result[1] = result[5] = sl; result[0] = 0; bActions.AssignArray(result); } }
А в случае отсутствия открытых позиций, мы ищем точку входа. Здесь мы сначала определяем предстоящее направление движения цены и его силу.
else { ulong argmin = target.ArgMin(); ulong argmax = target.ArgMax(); float max_sl = float(MaxSL * Point()); while(argmax > 0 && argmin > 0) { if(argmax < argmin && target[argmax] / 2 > MathAbs(target[argmin]) && MathAbs(target[argmin]) < max_sl) break; if(argmax > argmin && target[argmax] < MathAbs(target[argmin] / 2) && target[argmax] < max_sl) break; target.Resize(MathMin(argmax, argmin)); argmin = target.ArgMin(); argmax = target.ArgMax(); }
И только затем определяем параметры торговой операции.
if(argmin == 0 || (argmax < argmin && argmax > 0)) { float tp = 0; float sl = 0; float cur_sl = - float(MaxSL * Point()); ulong pos = 0; for(ulong j = 0; j < argmax; j++) { tp = MathMax(tp, target[j] + fstate[j, 1] - fstate[j, 0]); pos = j; if(cur_sl >= target[j] + fstate[j, 2] - fstate[j, 0]) break; sl = MathMin(sl, target[j] + fstate[j, 2] - fstate[j, 0]); } if(tp > 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = (float)MathMin(tp / (MaxTP * Point()), 1); result[0] = float(MathMax(Buffer[tr].States[i].account[0] / 100 * 0.01, 0.011)); result[5] = result[1] = tp; result[4] = result[2] = sl; result[3] = 0; bActions.AssignArray(result); } }
else { if(argmax == 0 || argmax > argmin) { float tp = 0; float sl = 0; float cur_sl = float(MaxSL * Point()); ulong pos = 0; for(ulong j = 0; j < argmin; j++) { tp = MathMin(tp, target[j] + fstate[j, 2] - fstate[j, 0]); pos = j; if(cur_sl <= target[j] + fstate[j, 1] - fstate[j, 0]) break; sl = MathMax(sl, target[j] + fstate[j, 1] - fstate[j, 0]); } if(tp < 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = (float)MathMin(-tp / (MaxTP * Point()), 1); result[3] = float(MathMax(Buffer[tr].States[i].account[0] / 100 * 0.01, 0.011)); result[2] = result[4] = tp; result[1] = result[5] = sl; result[0] = 0; bActions.AssignArray(result); } } } } }
"Оптимальную торговую операцию" используем только для обучения Менеджера.
//--- Actor Policy if(!Actor.backProp(GetPointer(bActions), (CNet*)GetPointer(Task), -1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Далее переходим к генерации тензора целевых значений Контролера. Вполне логично здесь так же воспользоваться параметрами "оптимальной торговой операции". Но в ней указан объем сделки, который невозможно определить только на основании анализа состояния окружающей среды, доступном Контролеру. Необходимы ещё данные о текущем состоянии счета, которые получает только Менеджер. Поэтому абсолютное значение объема торговой операции мы заменим вероятностью получения прибыли. Для оптимальной торговой операции вероятность достижения целевых значений равна 1.
//--- Agents target=result; if(target[0] > 0) target[0] = 1; if(target[3] > 0) target[3] = 1;
Скорректированную "оптимальную торговую операцию" мы повторим для заданного количества агентов и передадим Контроллеру в качестве целевых значений.
Result.Clear(); for(int i = 0; i < BarDescr; i++) { if(!Result.AddArray(target)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } } if(!Task.backProp(Result, (CNet*)GetPointer(Encoder), LatentLayer) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Обратите внимание, что все агенты получают одинаковые целевые значения. Однако, мы не ожидаем их синхронной работы, ведь все они анализируют только данные локальных наблюдений своего унитарного временного ряда. Поэтому, однонаправленная трактовка анализируемого состояния окружающей среды несколькими агентами потенциально даст более сильный сигнал для Менеджера.
Нам остается определить целевые значения прогнозной модели наиболее вероятного ценового движения. Здесь мы опять возвращаемся к данным последующих состояний окружающей среды. Мы берем накопительную сумму динамики цены и определяем максимальное движение на заданном горизонте планирования. Направление максимального отклонения и будет приоритетной тенденцией, используемой нами для обучения прогнозной модели.
//--- Probability target = vector<float>::Zeros(NActions / 3); vector<float> trend=fstate.Col(0).CumSum(); ulong argmax=MathAbs(trend).ArgMax(); if(trend[argmax] > 0) target[0] = 1; else if(trend[argmax] < 0) target[1] = 1; if(!Result.AssignArray(target) || !Probability.backProp(Result, (CNet*)GetPointer(Encoder),LatentLayer) || !Encoder.backPropGradient((CBufferFloat*)NULL, (CBufferFloat*)NULL, LatentLayer) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Обратите внимание, что в данном случае, мы передаем градиент ошибки на уровень общих навыков и корректируем параметры Энкодера. Наша цель, чтобы общие навыки содержали информацию о приоритетной тенденции.
Теперь нам остается проинформировать пользователя о ходе обучения моделей и перейти к следующей итерации системы циклов.
if(GetTickCount() - ticks > 500) { double percent = double(iter + i - start) * 100.0 / (Iterations); string str = StringFormat("%-12s %6.2f%% -> Error %15.8f\n", "Encoder", percent, Encoder.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Task", percent, Task.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-13s %6.2f%% -> Error %15.8f\n", "Probability", percent, Probability.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
После успешного выполнения всех итераций созданной системы циклов, для обучения моделей выводим в журнал результаты обучения моделей и инициализируем процесс завершения работы советника.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Encoder", Encoder.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Task", Task.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Probability", Probability.getRecentAverageError()); ExpertRemove(); //--- }
С полным кодом данной программы можно ознакомиться во вложении. Там же представлены программы сбора обучающей выборки и тестирования обученных моделей. С точечными правками, внесенными в указанные программы предлагаю ознакомиться самостоятельно.
Тестирование
И вот мы подошли, пожалуй, к наиболее ответственному этапу нашей работы — оценке эффективности реализованных решений на реальных исторических данных. Как уже отмечалось ранее, обучение моделей проводилось на основе реальных рыночных данных за весь 2024 год.
Для объективной проверки качества сформированной политики, было проведено тестирование обученных моделей в тестере стратегий MetaTrader 5, с использованием исторических данных за период с Января по Март 2025 года. Все прочие параметры, включая рыночные условия, таймфреймы и настройки симуляции, были сохранены без изменений, что обеспечило корректность и сопоставимость результатов.
Результаты тестирования представлены ниже.


За 3 месяца периода тестирования модель совершила 860 торговых операций и 340 из них было закрыто с прибылью. Это составило 39.53% прибыльных операций. Однако, средняя прибыльная сделка на 70% превысила аналогичный показатель убыточных операций, что позволило компенсировать низкий уровень прибыльных операций и получить прибыль по результатам тестирования.
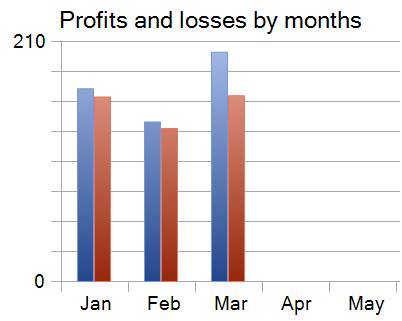
Стоит отметить, что каждый из 3 месяцев периода тестирования был закрыт с прибылью.
Заключение
В данной работе мы познакомились с аспектами фреймворка HiSSD, который был адаптирован под задачи алгоритмического трейдинга. Основная идея — разделение навыков на общие и специфические — показала свою эффективность в условиях динамично меняющегося рынка. Такая структура позволила агентам быстрее адаптироваться к изменениям без необходимости переобучения.
В рамках реализации были учтены особенности финансовых данных: обучение велось на реальных исторических котировках за 2024 год, а тестирование проводилось на новых данных начала 2025 года. Это дало возможность объективно оценить работоспособность моделей в условиях, близких к реальной торговле.
Однако, еще раз хочу напомнить, что перед применением для торговли в реальных условиях, модель должна быть обучена на более репрезентативной выборке с последующим проведением всестороннего тестирования.
Ссылки
- Learning Generalizable Skills from Offline Multi-Task Data for Multi-Agent Cooperation
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования