
Redes neuronales en el trading: Jerarquía de habilidades para el comportamiento adaptativo de agentes (HiSSD)

Introducción
El aprendizaje multiagente cooperativo por refuerzo (Multi-Agent Reinforcement Learning — MARL) ha cobrado especial relevancia en los últimos años. Este concepto tiene aplicaciones que van desde los juegos y el transporte autónomo hasta la logística, las dinámicas sociales y, sobre todo, los mercados financieros. Cuando se requiere el comportamiento coherente de múltiples estrategias o agentes, los métodos tradicionales suelen mostrar resultados inferiores. El MARL muestra unos resultados impresionantes en este tipo de tareas.
No obstante, surgen muchas complejidades. El desarrollo simulaciones precisas o la organización de una interacción continua en línea requiere costes importantes. En un entorno real, los agentes se enfrentan a condiciones que cambian constantemente: varían el número de participantes, los objetivos y los parámetros del entorno. Por ello, cada vez existe más interés por los sistemas de aprendizaje capaces de adaptarse y transferir conocimientos de una tarea a otra. Además, de la forma más eficaz y rentable posible.
El enfoque clásico consiste en entrenar a los agentes en una tarea y después volver a entrenarlos en otra. Pero este enfoque no está exento de defectos. En primer lugar, es necesaria una nueva y costosa interacción con el nuevo entorno. En segundo lugar, un modelo entrenado para un número fijo de agentes no gestiona el escalado. Este se pierde al modificarse la composición de los participantes o los parámetros objetivo.
Para hacer frente a estos problemas, los investigadores empezaron a usar una arquitectura basada en el Transformer. Dicha arquitectura aporta flexibilidad: el modelo no depende del número de agentes y puede adaptarse a nuevas condiciones. Esto se convirtió en la base para el desarrollo de patrones universales de comportamiento cooperativo, es decir, habilidades que pueden transferirse entre tareas y usarse nuevamente.
Se han propuesto muchos métodos para hacer realidad estas habilidades. Algunos se basan en el aprendizaje en dos etapas; en la primera de ellas se extraen las pautas generales de comportamiento y luego se forman las políticas. Otros combinan el aprendizaje online y offline, lo que acelera la adaptación a nuevos entornos.
Estos planteamientos han tenido un efecto sustancial, sobre todo en la reducción del coste de la transferencia de modelos para resolver problemas relacionados. Sin embargo, también muestran algunos puntos débiles. Las habilidades universales son útiles, pero ignoran las particularidades necesarias para alcanzar objetivos concretos. Y en los detalles reside a menudo la clave del éxito. Además, en muchos casos, la estructura temporal de las interacciones queda fuera de foco. No obstante, la cooperación, como sabemos, no se desarrolla instantáneamente, sino con el tiempo. La secuencia de los pasos, la coherencia de las acciones... todo importa.
Para resolver estos problemas, en el artículo "Learning Generalizable Skills from Offline Multi-Task Data for Multi-Agent Cooperation" se propuso el framework HiSSD — Hierarchical and Separate Skill Discovery. Se trata de una nueva arquitectura que permite aprender al mismo tiempo habilidades generales y específicas. Sin separación artificial. Sin límites estrictos. En una estructura jerárquica, ambas categorías de conocimientos se desarrollan en paralelo.
Las habilidades genéricas describen patrones universales de cooperación. Dichas habilidades permiten a los agentes actuar con coherencia incluso en entornos desconocidos, constituyendo una base, un conjunto de respuestas conductuales adecuadas en la mayoría de las situaciones. En cambio, las habilidades específicas se perfeccionan para tareas concretas, permitiendo ajustar el comportamiento según los objetivos y las condiciones.
El HiSSD se basa en la idea del aprendizaje jerárquico concurrente. Esto permite comprender en profundidad los aspectos temporales de las interacciones y el contexto de tareas específicas. De este modo, no solo se logra un comportamiento de calidad de los agentes, sino también una transferencia segura de las estrategias a nuevas condiciones.
Los experimentos realizados por los autores del framework en los populares simuladores SMAC y MuJoCo confirmaron la eficacia del planteamiento. Incluso en tareas nuevas y desconocidas, los agentes entrenados con HiSSD demuestran un comportamiento cooperativo seguro. Su estrategia demuestra ser flexible, precisa y fiable.
El algoritmo HiSSD
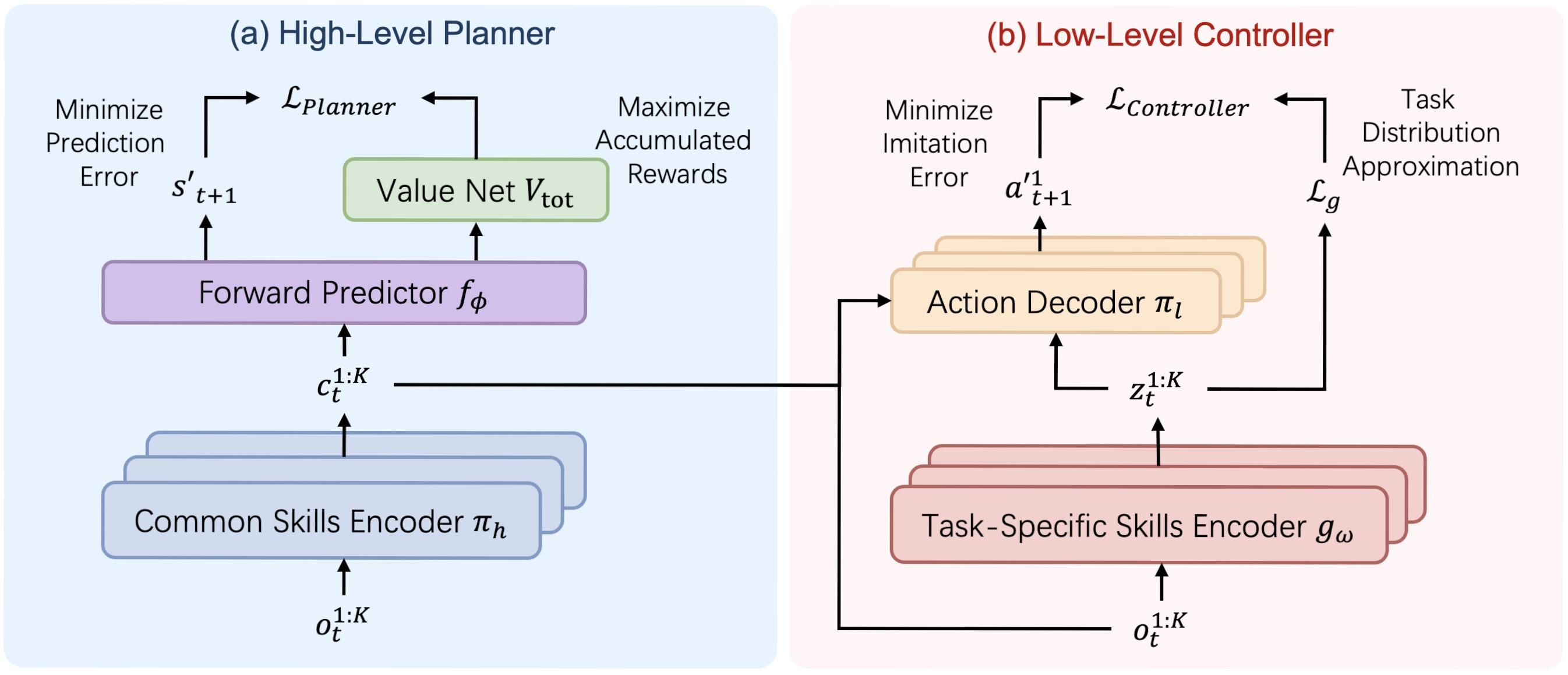
El algoritmo HiSSD (Hierarchical and Separable Skill Discovery) es un enfoque innovador para el aprendizaje de agentes en un entorno multiagente, diseñado para garantizar la transferibilidad de habilidades entre distintas tareas y la solidez del comportamiento de los agentes en ausencia de un control centralizado. La idea básica del algoritmo consiste en descomponer jerárquicamente el comportamiento de cada agente en dos componentes clave: habilidades generales (common), que se aplican a todos los agentes y tareas, y habilidades individuales específicas de la tarea (task-specific), que permiten adaptar el comportamiento a un papel o tarea concretos.
Una de las diferencias fundamentales entre el HiSSD y otros enfoques es la capacidad de entrenar todos los módulos del modelo simultáneamente. Esto es importante: en lugar de un entrenamiento incremental o por turnos, como suele practicarse en los sistemas jerárquicos, aquí todos los componentes -programador, controlador, codificadores y modelo de estimación de costes- se entrenan juntos. Esta simultaneidad evita los problemas de desajuste entre niveles y garantiza un comportamiento más coherente y eficaz por parte de los agentes.
El proceso de entrenamiento usa un conjunto de datos offline DT = {Di}, donde cada Di se corresponde con una tarea diferente. En cada paso temporal, el agente k recibe una observación ot,k, en base a la cual el planificador forma una habilidad genérica ct,k:
![]()
Esta habilidad refleja una intención de alto nivel y un plan estratégico global de comportamiento. Además, el codificador de habilidades específicas gω genera la habilidad zt,k a partir de las mismas observaciones:
![]()
Estas dos habilidades (general y específica) son transmitidas al controlador, que, dada la observación actual, toma la decisión final sobre la acción del agente:
![]()
El entrenamiento del modelo de predicción de costes del estado del entorno se basa en un algoritmo modificado Implicit Q-Learning (IQL) adaptado a un entorno multiagente. El valor del estado se evalúa considerando la recompensa total obtenida por todos los agentes:
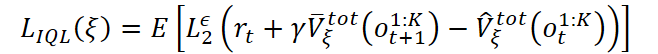
donde se usa el error cuadrático truncado:
![]()
A partir de la estimación de costes del modelo, se entrenará el planeador. Su principal objetivo es seleccionar aquellas habilidades generales que lleven a los estados más útiles en el futuro. Esto se logra minimizando una función de pérdida que tenga en cuenta tanto el valor del siguiente estado como la probabilidad del estado predicho:
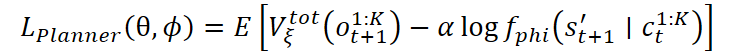
También es posible usar una versión exponencial de la función de pérdida:
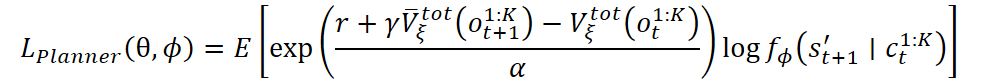
El controlador y el codificador específico de la habilidad se entrenan usando un autocodificador de variación de la codificación del comportamiento. La idea es enseñar al controlador a reproducir las acciones de las demostraciones, considerando al mismo tiempo la estructura oculta de las tareas. Las pérdidas incluyen el logaritmo de probabilidad de la acción y un elemento de regularización en forma de divergencia KL:
![]()
Para garantizar que las habilidades del agente varíen entre tareas, se usa además el aprendizaje contrastivo. El codificador se entrena de forma que, para cada tarea, la representación de gω(q) esté más cerca de los ejemplos k+ positivos de la misma tarea que de los ejemplos k- negativos de otras tareas:
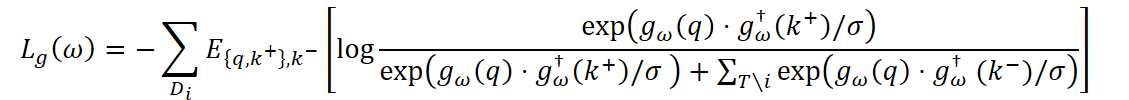
donde σ es el coeficiente de temperatura y gω† es la versión exponencialmente promediada del codificador usada para estabilizar el proceso de aprendizaje.
La función de pérdida final para el controlador suma los componentes conductuales y contrastivos.
Como resultado, el HiSSD supone un potente sistema en el que todos los niveles de comportamiento -desde la planificación estratégica hasta las tácticas individuales- se entrenan de forma coherente y funcionan eficazmente en ausencia de un control centralizado.
A continuación le mostramos la visualización del framework HiSSD realizada por el autor.
Implementación con MQL5
Tras repasar los aspectos teóricos del framework HiSSD, pasaremos a la parte práctica de este artículo, donde implementaremos nuestra visión de los enfoques propuestos por los autores del framework usando MQL5.
Principios básicos de la construcción de modelos
Antes de pasar a la aplicación práctica de los métodos propuestos, debemos esbozar algunos principios clave que constituirán la base de nuestra solución.
En primer lugar, debemos señalar que el framework HiSSD se centra en el entrenamiento de un modelo multiagente. Esto difiere de nuestro objetivo de enseñar la política comercial de un único instrumento financiero. Sin embargo, este enfoque tiene un enorme potencial en el contexto multitarea que caracteriza a los mercados financieros reales. Así, podemos complicar ligeramente la estructura jerárquica propuesta formando varios agentes independientes, cada uno de los cuales analizará y pronosticará una parte determinada de la información del mercado. Y para que la decisión final resulte más coherente y eficiente, añadiremos un gestor de modelos de alto nivel que combinará las propuestas de los distintos agentes y seleccionará la mejor estrategia. Estos sistemas multitarea no son nuevos en la inteligencia artificial, y su uso en los mercados financieros permite abordar con eficacia una diversidad de factores y riesgos.
El segundo punto importante es que, en el framework HiSSD, cada agente genera acciones basadas en observaciones locales. Sin embargo, en el contexto de los mercados financieros, donde la información sobre los precios, los volúmenes comerciales y otros indicadores está estrechamente interconectada, este planteamiento requiere de ciertas mejoras. Podemos proporcionar a cada agente una secuencia unitaria separada de una serie temporal multimodal de datos de origen para su análisis. Pero es importante recordar que, en los mercados reales, los indicadores suelen estar correlacionados entre sí. Por ejemplo, los cambios en el precio de un activo pueden influir en el precio de otros activos, lo que hace necesario considerar estas interrelaciones. Para ello, pondremos en marcha un mecanismo de enriquecimiento de datos que permitirá a cada agente adquirir conocimientos generales sobre el estado del mercado y usar dicha información para tomar una decisión más informada.
Por último, cabe destacar la importancia de la modularidad, que constituye el núcleo del framework HiSSD. Este enfoque resulta ideal para sistemas complejos y multitarea. Podemos dividir el sistema en varios componentes, cada uno de los cuales resuelve una tarea diferente. La modularidad no solo permite optimizar los componentes individuales de forma eficaz, sino que también ayuda a adaptar con flexibilidad el sistema a las cambiantes condiciones del mercado. En nuestro caso, este enfoque es especialmente valioso porque los mercados financieros están sujetos a cambios, y la capacidad de modificar o mejorar rápidamente partes del modelo puede resultar clave para negociar con éxito.
Codificador de habilidades
El primer módulo con el que empezaremos a construir el modelo es el codificador de habilidades. Aquí destacaremos de inmediato una importante característica arquitectónica del framework HiSSD: las habilidades genéricas y específicas de la tarea se generan a partir de la misma fuente de información. Estas son las observaciones localizadas del agente; en nuestro caso, las secuencias unitarias derivadas de una serie temporal multimodal que describe el estado del entorno.
Dada esta característica, se decidió usar una única solución arquitectónica para las dos subtareas. Así, este planteamiento ofrece varias ventajas. En primer lugar, simplifica el diseño y la posterior depuración del modelo. En segundo lugar, permite aplicar una metodología unificada para analizar la calidad de las características extraídas. Por último, el uso repetido de la arquitectura ahorra recursos de desarrollo y permite que el modelo se amplíe más rápidamente al pasar a nuevas tareas o nuevos instrumentos financieros.
El funcionamiento del codificador de habilidades se organiza dentro del objeto CNeuronSkillsEncoder, cuya estructura le mostramos a continuación.
class CNeuronSkillsEncoder : public CNeuronSoftMaxOCL { protected: CNeuronCATCH cCrossObservAttention; CNeuronTransposeOCL cTranspose; CNeuronConvOCL cSkillsProjection[2]; CNeuronBaseOCL cPrevSkillsConcat; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; public: CNeuronSkillsEncoder(void) {}; ~CNeuronSkillsEncoder(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint time_step, uint variables, uint skills, uint window, uint step, uint window_key, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronSkillsEncoder; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
En la estructura presentada, vemos una serie de objetos internos, cada uno de los cuales cumplirá una función importante. Aprenderemos más sobre su funcionalidad durante la construcción de los métodos de la nueva clase. Ahora es importante para nosotros que todos los objetos se declaren de forma estática, lo cual nos permitirá dejar el constructor y el destructor de la clase vacíos. La inicialización de todos los objetos internos se realizará en el método Init.
bool CNeuronSkillsEncoder::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint time_step, uint variables, uint skills, uint window, uint step, uint window_key, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronSoftMaxOCL::Init(numOutputs, myIndex, open_cl, variables * skills, optimization_type, batch)) return false; SetHeads(variables);
En los parámetros de este método obtendremos una serie de constantes que nos permitirán identificar unívocamente la arquitectura del objeto creado. Los nombres de casi todos los parámetros ya nos resultan familiares de artículos anteriores, así que no describiremos ahora cada uno de ellos.
En el cuerpo del método, como es habitual, llamaremos inmediatamente al método homónimo de la clase padre en la que ya están organizados los puntos de control mínimos necesarios, y se han construido los procesos de inicialización de objetos e interfaces heredados.
Como clase principal, usaremos la capa de características SoftMax. Esto nos permitirá normalizar los resultados de cada uno de los codificadores de habilidades de los agentes y hacerlos comparables. El número de habilidades de cada agente viene determinado por el parámetro skills. Es la longitud del vector de resultados generado a la salida del módulo para cada agente, mientras que el valor del elemento vectorial indicará la importancia de usar una habilidad concreta.
No es difícil adivinar que en nuestro caso el número de agentes será igual al número de secuencias unitarias en las series temporales multimodales analizadas. Lo especificaremos como el número de cabezas de normalización por la función SoftMax.
Una vez ejecutadas con éxito las operaciones de los métodos de la clase padre, procederemos a la inicialización de los objetos internos recién creados. Y primero inicializaremos el objeto de intercambio de información entre secuencias unitarias. En nuestro experimento, este trabajo lo realizará el objeto de framework CATCH que construimos en el artículo anterior.
int index = 0; if(!cCrossObservAttention.Init(0, index, OpenCL, time_step, variables, window, step, window_key, heads, optimization, iBatch)) return false;
Recordemos que este objeto permite emparejar secuencias unitarias en el dominio de la frecuencia. En este caso, la descomposición espectral se dividirá en segmentos y los análisis se realizarán dentro de los segmentos individuales. Este enfoque permitirá una mayor flexibilidad a la hora de considerar el comportamiento de las distintas señales del mercado. En lugar de analizar toda la estructura de frecuencias de una serie temporal, nos centraremos en rangos de frecuencia individuales. Esto resultará especialmente importante en el contexto de los mercados financieros, donde las fluctuaciones de alta y baja frecuencia pueden contener información fundamentalmente distinta: las fluctuaciones de alta frecuencia suelen reflejar volatilidad y ruido a corto plazo, mientras que los componentes de baja frecuencia revelan tendencias y pautas a largo plazo.
Esto permitirá encontrar patrones generales -sincronicidad, desfases, correlaciones- y usarlos como fuente adicional de información en el entrenamiento de habilidades.
Debemos destacar que el intercambio de información no se produce directamente, sino a través del mecanismo de atención enmascarada. De este modo se protegerá a los agentes de influencias indebidas entre sí, al tiempo que se preserva el principio de descentralización. Como resultado, cada agente sigue trabajando con su propia secuencia unitaria, pero es capaz de considerar patrones importantes que son característicos de toda la escena del mercado.
A la salida del módulo CATCH obtendremos las mismas series temporales multimodales de datos de origen, pero enriquecidas con la información de los enlaces entre canales.
A continuación, cada agente deberá obtener su propia secuencia unitaria. Y para transformar los datos analizados en una representación más conveniente, usaremos la capa de transposición.
index++; if(!cTranspose.Init(0, index, OpenCL, time_step, variables, optimization, iBatch)) return false;
Luego se usarán cabezas independientes de generación del vector de habilidades de cada agente. Aquí usaremos 2 capas convolucionales consecutivas.
Sin embargo, debemos considerar que la longitud de la secuencia analizada puede variar en un rango bastante amplio, y procesar directamente la secuencia analizada completa con un solo bloque podría resultar demasiado laborioso. Por lo tanto, en el primer paso, la dividiremos en varios segmentos y cambiaremos la dimensionalidad mediante una capa convolucional.
uint count = (time_step - window + step - 1) / step; if(count <= 1) { window = time_step; count = 1; } //--- index++; if(!cSkillsProjection[0].Init(0, index, OpenCL, window, step, window_key, count, variables, optimization, iBatch)) return false; cSkillsProjection[0].SetActivationFunction(SoftPlus);
Y la segunda capa convolucional recogerá todos los segmentos que pertenezcan a la misma secuencia unitaria y formará un único vector de habilidades de un agente individual. Así lo demuestra la indicación de "1" como tamaño de la secuencia.
index++; if(!cSkillsProjection[1].Init(0, index, OpenCL, window_key * count, window_key * count, skills, 1, variables, optimization, iBatch)) return false; cSkillsProjection[1].SetActivationFunction(None);
Asimismo, debemos destacar que en los parámetros de la capa convolucional especificaremos explícitamente el número de secuencias unitarias independientes que procesará el modelo. Esto permitirá a cada agente usar su propia copia de la arquitectura convolucional con un conjunto único de pesos. Pero más allá de eso, cada agente analizará su dominio de datos local, es decir, una parte separada de la serie temporal multimodal global.
En otras palabras, el agente no solo verá datos únicos, sino que se centrará en un subconjunto limitado de información. Esto acercará el modelo a la realidad de los mercados financieros, donde cada tráder (en nuestro caso, un agente) trabajará con distintas fuentes de información y tomará decisiones según estas.
Como resultado, no obtendremos solo ejecutores paralelos de una tarea, sino un equipo completo de agentes especializados, cada uno de los cuales aprenderá en su propio entorno, construirá su propia comprensión del mercado y desarrollará su propia estrategia de comportamiento. Esta organización aumentará la resistencia de todo el sistema, potenciará la diversificación de los comportamientos y permitirá combinar estrategias locales para alcanzar el objetivo global de un comercio eficaz y adaptable en condiciones de incertidumbre.
A continuación, inicializaremos un objeto auxiliar cuyo tamaño será 2 veces el tensor de resultados. Hablaremos de su funcionalidad durante la construcción del método de distribución del gradiente de error.
index++; if(!cPrevSkillsConcat.Init(0, index, OpenCL, 2 * Neurons(), optimization, iBatch)) return false; cPrevSkillsConcat.SetActivationFunction((ENUM_ACTIVATION)cSkillsProjection[1].Activation()); //--- return true; }
Tras inicializar correctamente todos los objetos internos, finalizaremos el método retornando primero el resultado lógico de las operaciones al programa que realiza la llamada.
La siguiente etapa de nuestro trabajo consistirá en construir los algoritmos de pasada directa dentro del método feedForward. Aquí, como era de esperar, todo será bastante sencillo y lineal.
bool CNeuronSkillsEncoder::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cCrossObservAttention.FeedForward(NeuronOCL)) return false;
En los parámetros del método obtendremos el puntero al objeto de datos de origen multimodales, que pasaremos inmediatamente al módulo interno de análisis de dependencias entre canales.
if(!cTranspose.FeedForward(cCrossObservAttention.AsObject())) return false;
Luego transpondremos los resultados obtenidos y los pasaremos al bloque de generación del tensor de habilidades.
if(!cSkillsProjection[0].FeedForward(cTranspose.AsObject())) return false;
Sin embargo, hay un punto que debemos destacar. Antes de llamar al método de pasada directa de la segunda capa convolucional, reordenaremos los punteros a las búferes de resultados. Esta sencilla iteración nos permitirá conservar los resultados de las operaciones anteriores. Explicaremos el valor de esta acción en la construcción del método de distribución del gradiente de error.
if(!cSkillsProjection[1].SwapOutputs() || !cSkillsProjection[1].FeedForward(cSkillsProjection[0].AsObject())) return false; //--- return CNeuronSoftMaxOCL::feedForward(cSkillsProjection[1].AsObject()); }
El tensor formado de las habilidades de los agentes lo trasladaremos al subespacio de probabilidades usando la clase padre y finalizaremos el método retornando el resultado lógico de las operaciones al programa que realiza la llamada.
A continuación, pasaremos a la construcción de algoritmos de pasada inversa. Como ya sabrá, este trabajo se divide en 2 etapas:
- la distribución de los gradientes de error entre todos los participantes del proceso con ayuda del método calcInputGradients;
- la optimización de los parámetros del modelo para minimizar el error, mediante el método updateInputWeights.
Empezaremos por el método calcInputGradients, que se encargará de propagar el gradiente de error entre los objetos internos según su influencia en el resultado final del modelo. Ya hemos conducido al lector en su implementación: lo hemos mencionado dos veces antes, dejando una ligera intriga. Ahora es el momento de analizar en detalle cómo está estructurado y por qué desempeña un papel importante en el entrenamiento de modelos.
En los parámetros del método obtendremos el puntero al objeto de datos de origen, el mismo que se ha usado en las operaciones de pasada directa. Sin embargo, esta vez, tendremos que transmitirle el gradiente de error según la influencia de los datos de entrada en la salida final del modelo.
bool CNeuronSkillsEncoder::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!prevLayer) return false;
Obviamente, solo podremos transferir datos a un objeto válido. Por lo tanto, en el cuerpo del método comprobaremos inmediatamente la relevancia del puntero recibido. Si el puntero resulta estar vacío o ser inválido, la ejecución del método se interrumpirá inmediatamente, y los cálculos posteriores carecerán de sentido. Esta verificación supone una medida de seguridad básica que garantizará que el algoritmo se ejecute correctamente y servirá de protección contra fallos de entrenamiento impredecibles.
Si el punto de control se supera con éxito, procederemos al siguiente paso: la distribución del gradiente de error. Aquí comenzará la transferencia secuencial de información entre todos los objetos que intervienen en el proceso. Cada uno de estos objetos es responsable de una parte diferente de la lógica del modelo, y nuestra tarea consiste en transferir cuidadosamente, paso a paso, el gradiente de error a los componentes correspondientes.
Este mecanismo resulta fundamental: proporciona retroalimentación dentro del modelo, lo que permite a cada bloque ajustar sus parámetros según el error resultante. Mediante este mecanismo, el modelo aprenderá a encontrar los parámetros óptimos y minimizar las pérdidas.
En el primer paso, usando los mecanismos proporcionados por la clase padre, pasaremos el gradiente de error procedente de las capas posteriores de la arquitectura de la red neuronal a las interfaces externas del objeto, hasta el nivel de la última capa de generación del tensor de habilidades del agente.
if(!CNeuronSoftMaxOCL::calcInputGradients(cSkillsProjection[1].AsObject())) return false;
Este proceso desempeña un papel clave en el entrenamiento de modelos, ya que garantizará la capacidad de generar habilidades que sean realmente relevantes para la tarea en cuestión. Al propagar constantemente el gradiente de error, el modelo obtendrá información directa sobre el grado de acierto de sus acciones y decisiones anteriores.
Sin embargo, no solo es importante que entrenemos a los agentes para que generen habilidades útiles, sino también que organicemos su trabajo en equipo de manera que puedan interactuar eficazmente, canalizando sus esfuerzos en distintas direcciones para maximizar el resultado global. No se trata solo de formar a cada agente individualmente, sino de crear sinergias entre ellos.
Para aplicar este enfoque, usaremos algoritmos de aprendizaje contrastivo que nos permitirán introducir diversidad en los tensores de habilidades de los agentes. Debemos señalar que la diversificación no solo se producirá entre distintos agentes en el mismo paso temporal, sino también entre habilidades generadas en distintos pasos. Esto creará una diferencia más profunda en la percepción de los estados.
Así, cada agente no solo se verá obligado a reconocer la singularidad de su habilidad, sino también a considerar el contexto formado por acciones anteriores. Esto impulsará a los agentes a crear estrategias de comportamiento más complejas y coherentes, capaces de adaptarse a las condiciones y dinámicas cambiantes del mercado.
En el contexto de los mercados financieros, donde la situación suele cambiar muy rápidamente, esta capacidad de los agentes para considerar las acciones previas y las diferencias de estado se vuelve crucial. La diversificación de habilidades, complementada con el uso de datos históricos, posibilita estrategias más resistentes y adaptables que pueden funcionar eficazmente en entornos muy volátiles e inciertos.
El algoritmo de aprendizaje contrastivo desempeñará un papel clave en la creación de estas diferencias, es decir, mejorará la capacidad de los agentes para distinguir y analizar distintas situaciones, tomando decisiones más informadas en cada paso.
Durante la pasada directa, antes de generar un nuevo tensor de habilidades, guardaremos los resultados de la pasada directa anterior. Y ahora reuniremos los resultados del procesamiento de los dos estados del entorno en un único tensor.
if(!Concat(cSkillsProjection[1].getOutput(), cSkillsProjection[1].getPrevOutput(), cPrevSkillsConcat.getOutput(), cSkillsProjection[1].GetFilters(), cSkillsProjection[1].GetFilters(), iHeads)) return false;
Después, llamaremos el método de diversificación, diseñado para maximizar la separación de vectores individuales en el subespacio de habilidades.
if(!DiversityLoss(cPrevSkillsConcat.AsObject(), 2 * iHeads, cSkillsProjection[1].GetFilters(), false)) return false;
Los gradientes de error resultantes los dividiremos en sus respectivas secuencias.
if(!DeConcat(cPrevSkillsConcat.getOutput(), cPrevSkillsConcat.getPrevOutput(), cPrevSkillsConcat.getGradient(), cSkillsProjection[1].GetFilters(), cSkillsProjection[1].GetFilters(), iHeads)) return false;
Y añadiremos a los gradientes de error obtenidos previamente las habilidades del paso de tiempo actual.
if(!SumAndNormilize(cSkillsProjection[1].getGradient(), cPrevSkillsConcat.getOutput(), cSkillsProjection[1].getGradient(), cSkillsProjection[1].GetFilters(), false, 0, 0, 0, 1)) return false;
El algoritmo posterior del método será lineal. Luego haremos descender el gradiente de error en el bloque de generación de habilidades.
if(!cSkillsProjection[0].calcHiddenGradients(cSkillsProjection[1].AsObject())) return false;
Los valores obtenidos se transpondrán con la transferencia de datos al módulo de análisis de la dependencia entre canales.
if(!cTranspose.calcHiddenGradients(cSkillsProjection[0].AsObject())) return false; if(!cCrossObservAttention.calcHiddenGradients(cTranspose.AsObject())) return false;
Y pasaremos el gradiente de error al objeto de datos de origen según su influencia en el resultado final.
return prevLayer.calcHiddenGradients(cCrossObservAttention.AsObject());
}
Después, finalizaremos el método devolviendo el resultado lógico de las operaciones al programa que realiza la llamada.
El método updateInputWeights para actualizar los parámetros del modelo es sencillo al máximo: nos limitaremos a llamar a los métodos de los objetos homónimos internos. Aquí cabe señalar que no todos los objetos internos contendrán parámetros entrenables, por lo que solo una parte de ellos intervendrá en el método.
bool CNeuronSkillsEncoder::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cCrossObservAttention.UpdateInputWeights(NeuronOCL)) return false; if(!cSkillsProjection[0].UpdateInputWeights(cTranspose.AsObject())) return false; if(!cSkillsProjection[1].UpdateInputWeights(cSkillsProjection[0].AsObject())) return false; //--- return true; }
Asimismo, debemos decir unas palabras sobre los métodos para guardar el modelo entrenado y restablecer su rendimiento. Como habrá observado, el objeto de concatenación de los resultados de dos pasadas directas consecutivas no contiene parámetros entrenables. Solo realizará una función auxiliar, conectar la salida de dos flujos diferentes. A pesar de esto, el objeto de concatenación tiene búferes de datos que suponen el doble del tamaño del tensor de resultados del objeto actual. Sin embargo, estos datos no afectarán de forma crítica al rendimiento del modelo, ya que solo son un depósito temporal de información que se usa para cálculos intermedios. Considerando esto, al guardar el modelo entrenado, podemos ahorrar espacio en el disco eliminando la necesidad de almacenar dichos búferes de datos.
bool CNeuronSkillsEncoder::Save(const int file_handle) { if(!CNeuronSoftMaxOCL::Save(file_handle)) return false; if(!cCrossObservAttention.Save(file_handle)) return false; if(!cTranspose.Save(file_handle)) return false; for(uint i = 0; i < cSkillsProjection.Size(); i++) if(!cSkillsProjection[i].Save(file_handle)) return false; //--- return true; }
Cuando recuperemos el modelo, podremos reinicializar fácilmente el objeto de concatenación basándonos en nuestros datos sobre el tamaño del tensor de resultados del codificador de habilidades.
bool CNeuronSkillsEncoder::Load(const int file_handle) { if(!CNeuronSoftMaxOCL::Load(file_handle)) return false; if(!LoadInsideLayer(file_handle, cCrossObservAttention.AsObject())) return false; if(!LoadInsideLayer(file_handle, cTranspose.AsObject())) return false; for(uint i = 0; i < cSkillsProjection.Size(); i++) if(!LoadInsideLayer(file_handle, cSkillsProjection[i].AsObject())) return false; //--- if(!cPrevSkillsConcat.Init(0, 4, OpenCL, 2 * Neurons(), optimization, iBatch)) return false; cPrevSkillsConcat.SetActivationFunction((ENUM_ACTIVATION)cSkillsProjection[1].Activation()); //--- return true; }
Con esto concluirá nuestro repaso a los algoritmos para construir los métodos de codificación de habilidades. El código completo del objeto presentado y todos sus métodos se encuentran en el archivo adjunto.
Hoy hemos hecho un buen trabajo, pero por desgracia el artículo ha llegado casi al final. Así que haremos una breve pausa y continuaremos en el próximo artículo.
Conclusión
Hoy hemos aprendido los aspectos teóricos del framework HiSSD, que es un sistema potente y flexible para el aprendizaje de agentes en entornos multiagente. Cada agente aprende políticas de comportamiento individuales en estrecha interacción con otros agentes del proceso. Esta combinación de entrenamiento en habilidades genéricas y específicas crea estrategias más adaptables y resistentes que pueden funcionar eficazmente frente a la incertidumbre y la variabilidad.
La modularidad del enfoque HiSSD y la combinación del uso de distintos métodos para el entrenamiento y el ajuste de modelos, como el aprendizaje contrastivo y la codificación variacional del comportamiento, lo convierten en una herramienta muy flexible y prometedora para resolver problemas en sistemas multiagente.
En la parte práctica del artículo, hemos empezado a aplicar nuestra propia visión de los enfoques propuestos por los autores del framework usando herramientas MQL5 . En concreto, hemos presentado la implementación de un codificador universal de habilidades. En el próximo artículo continuaremos el trabajo iniciado con más pruebas para analizar la eficacia de los enfoques implementados con datos históricos reales.
Enlaces
- Learning Generalizable Skills from Offline Multi-Task Data for Multi-Agent Cooperation
- Otros artículos de la serie
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor experto para recopilar ejemplos con el método Real-ORL |
| 3 | Study.mq5 | Asesor | Asesor de entrenamiento de modelos |
| 4 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 5 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema y la arquitectura del modelo |
| 6 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código del programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/17729
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Se ha publicado un nuevo artículo titulado «Aplicación de las redes neuronales en el trading: descubrimiento jerárquico de habilidades (HiSSD) para el comportamiento adaptativo de los agentes »:
Autor: Dmitriy Gizlyk