
Нейросети в трейдинге: Иерархия навыков для адаптивного поведения агентов (HiSSD)

Введение
Кооперативное мультиагентное обучение с подкреплением (Multi-Agent Reinforcement Learning — MARL) в последние годы стало особенно актуальным. Эта концепция находит применение в самых разных сферах — от игр и автономного транспорта до логистики, социальной динамики и, что особенно важно, финансовых рынков. Везде, где требуется слаженное поведение нескольких стратегий или агентов, традиционные методы часто уступают. MARL в таких задачах показывает впечатляющие результаты.
Тем не менее, возникает немало сложностей. Разработка точных симуляторов или организация непрерывного онлайн-взаимодействия требует серьёзных затрат. В реальной среде агенты сталкиваются с постоянно меняющимися условиями: варьируется число участников, цели, параметры среды. Поэтому возрастает интерес к обучению систем, способных адаптироваться и переносить знания из одних задач в другие. При этом — максимально эффективно и без дополнительных затрат.
Классический подход — обучить агентов на одной задаче, а затем дообучить на другой. Но он не лишён недостатков. Во-первых, требуется дорогостоящее повторное взаимодействие с новой средой. Во-вторых, модель, обученная под фиксированное число агентов, не справляется с масштабированием. Она теряется при изменении состава участников или целевых параметров.
Чтобы справиться с этими проблемами, исследователи начали использовать архитектуру на базе Transformer. Она даёт гибкость — модель не зависит от количества агентов и может адаптироваться к новым условиям. Это стало основой для разработки универсальных кооперативных паттернов поведения — навыков, которые можно переносить между задачами и использовать повторно.
Методов реализации таких навыков предложено множество. Одни основываются на двухэтапном обучении, где сначала извлекаются общие поведенческие шаблоны, а потом уже формируется политика. Другие совмещают офлайн- и онлайн-обучение, ускоряя адаптацию к новым условиям.
Такие подходы дали заметный эффект, особенно в снижении затрат на перенос моделей для решения смежных задач. Однако есть и слабые стороны. Универсальные навыки полезны, но игнорируют особенности, необходимые для достижения конкретных целей. А ведь именно в деталях часто кроется ключ к успеху. Более того, во многих случаях из внимания выпадает временная структура взаимодействий. Однако кооперация, как известно, развивается не мгновенно, а во времени. Последовательность шагов, согласованность действий — всё это имеет значение.
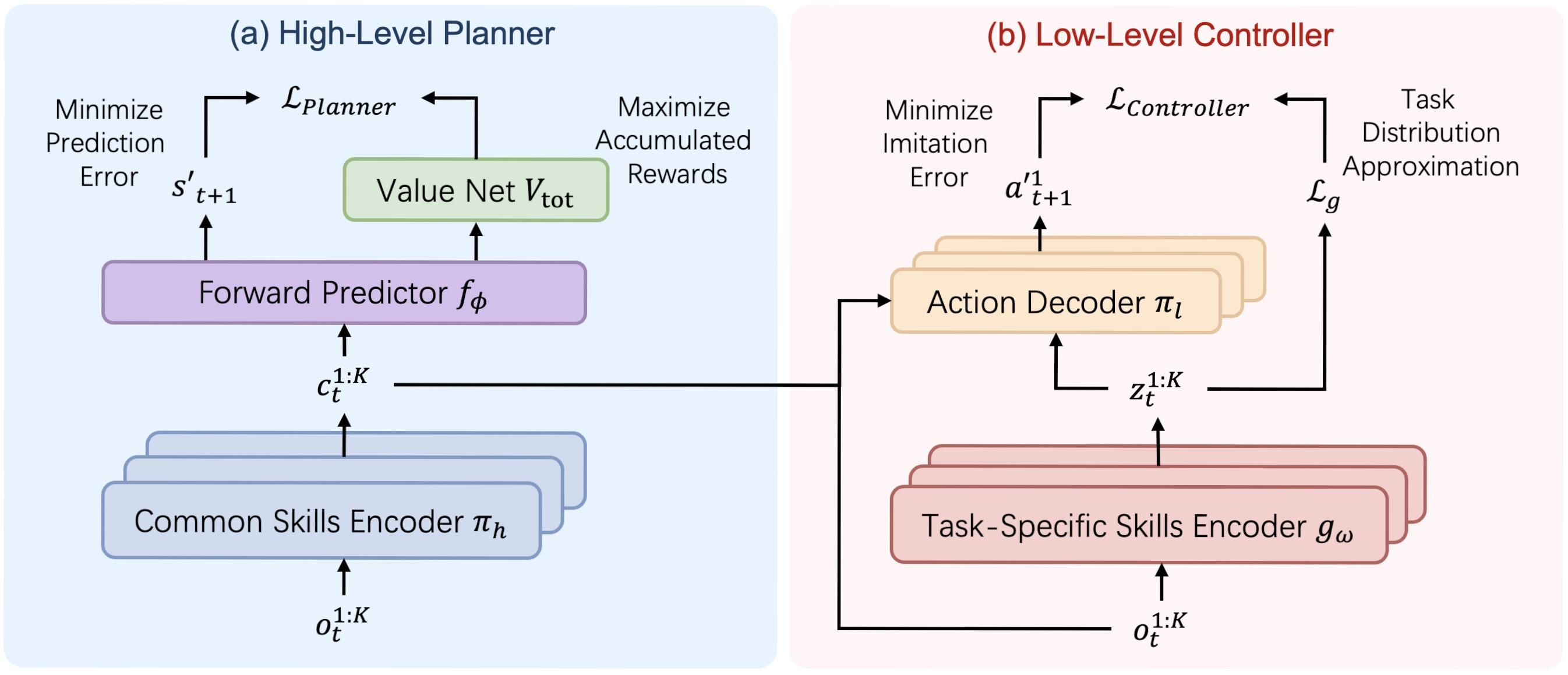
Для решения этих проблем в работе "Learning Generalizable Skills from Offline Multi-Task Data for Multi-Agent Cooperation" был предложен фреймворк HiSSD — Hierarchical and Separate Skill Discovery. Это новая архитектура, которая позволяет одновременно изучать как общие, так и специфические навыки. Без искусственного разделения. Без жёстких ограничений. В иерархической структуре обе категории знаний развиваются параллельно.
Общие навыки описывают универсальные паттерны кооперации. Они позволяют агентам действовать согласованно даже в незнакомой среде. Такие навыки формируют фундамент — набор поведенческих реакций, пригодных в большинстве ситуаций. Специфические навыки, напротив, заточены под конкретные задачи. Они позволяют точно настраивать поведение, в зависимости от целей и условий.
HiSSD строится на идее одновременного иерархического обучения. Это обеспечивает глубокое понимание временных аспектов взаимодействий и контекста конкретных задач. За счёт этого достигается не только качественное поведение агентов, но и уверенный перенос стратегий на новые условия.
Эксперименты, проведенные авторами фреймворка на популярных симуляторах SMAC и MuJoCo, подтвердили эффективность подхода. Даже в новых, ранее неизвестных задачах, агенты, обученные с HiSSD, демонстрируют уверенное кооперативное поведение. Их стратегия оказывается гибкой, точной и надёжной.
Алгоритм HiSSD
Алгоритм HiSSD (Hierarchical and Separable Skill Discovery) — это инновационный подход к обучению агентов в многоагентной среде, разработанный с целью обеспечить переносимость навыков между различными задачами и устойчивость поведения агентов при отсутствии централизованного управления. Основная идея алгоритма заключается в иерархическом разложении поведения каждого агента на два ключевых компонента: общие (common) навыки, которые применимы ко всем агентам и задачам, и индивидуальные, специфичные для отдельных задач (task-specific) навыки, позволяющие адаптировать поведение под конкретную роль или задачу.
Одним из принципиальных отличий HiSSD от других подходов является возможность одновременного обучения всех модулей модели. Это важно: вместо поэтапного или поочерёдного обучения, как это часто практикуется в иерархических системах, здесь все компоненты — планировщик, контроллер, энкодеры и модель оценки стоимости — тренируются совместно. Такая синхронность позволяет избежать проблем рассогласования между уровнями и обеспечивает более согласованное и эффективное поведение агентов.
В процессе обучения используется офлайн-датасет DT = {Di}, где каждая Di соответствует отдельной задаче. На каждом шаге времени агент k получает наблюдение ot,k, на основе которого планировщик формирует общий навык ct,k:
![]()
Этот навык отражает высокоуровневое намерение и общий стратегический план поведения. Далее, энкодер специфических навыков gω генерирует навык zt,k из тех же наблюдений:
![]()
Эти два навыка (общий и специфический) подаются в контроллер, который, учитывая текущее наблюдение, принимает окончательное решение о действии агента:
![]()
Обучение модели прогнозирования стоимости состояния окружающей среды опирается на модифицированный алгоритм Implicit Q-Learning (IQL), адаптированный для многоагентной среды. Ценность состояния оценивается с учётом общего вознаграждения, полученного всеми агентами:
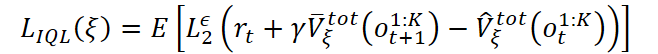
где используется усечённая квадратичная ошибка:
![]()
На основе оценки моделью стоимости, обучается планировщик. Его основная цель — выбрать такие общие навыки, которые ведут к наиболее полезным состояниям в будущем. Это достигается путём минимизации функции потерь, учитывающей как ценность следующего состояния, так и правдоподобие прогнозного состояния:
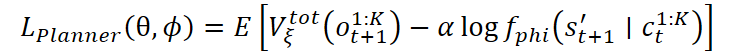
Также возможно использование экспоненциальной версии функции потерь:
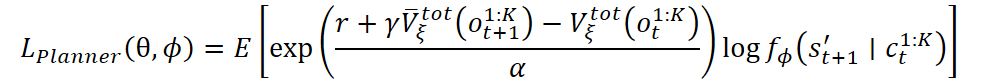
Контроллер и энкодер специфических навыков обучаются с использованием вариационного автоэнкодера поведенческого кодирования. Идея в том, чтобы научить контроллер воспроизводить действия из демонстраций, при этом учитывая скрытую структуру задач. Потери включают в себя логарифм правдоподобия действия и регуляризационный элемент в виде KL-дивергенции:
![]()
Чтобы навыки агента действительно различались между задачами, дополнительно используется контрастивное обучение. Энкодер учится таким образом, чтобы для каждой задачи представление gω(q) было ближе к положительным примерам k+ из той же задачи, чем к отрицательным k- из других задач:
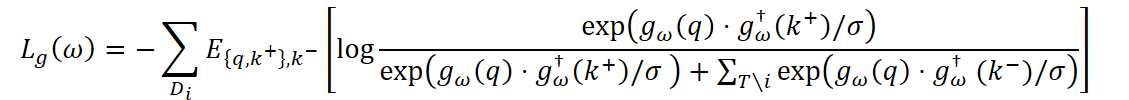
где σ — температурный коэффициент, а gω† — экспоненциально усреднённая версия энкодера, используемая для стабилизации процесса обучения.
Итоговая функция потерь для контроллера суммирует поведенческие и контрастивные компоненты.
В результате, HiSSD представляет собой мощную систему, в которой все уровни поведения — от стратегического планирования до индивидуальной тактики — согласованно обучаются и эффективно работают в условиях отсутствия централизованного управления.
Авторская визуализация фреймворка HiSSD представлена ниже.
Реализация средствами MQL5
После рассмотрения теоретических аспектов работы фреймворка HiSSD, мы переходим к практической части данной статьи, в которой реализуем средствами MQL5 свое видение подходов, предложенных авторами фреймворка.
Основные принципы построения модели
Перед тем, как перейти к практическому внедрению предложенных методов, важно обозначить несколько ключевых принципов, которые будут составлять основу нашего решения.
Прежде всего, стоит отметить, что фреймворк HiSSD ориентирован на обучение мультиагентной модели. Это отличается от нашей задачи обучения политики торговли на одном финансовом инструменте. Однако, такой подход имеет огромный потенциал в контексте многозадачности, характерной для реальных финансовых рынков. Мы можем несколько усложнить предложенную иерархическую структуру, обучив несколько независимых агентов, каждый из которых будет анализировать и прогнозировать определенную часть рыночной информации. А чтобы сделать итоговое решение более согласованным и эффективным, добавим модель-менеджер верхнего уровня, которая будет объединять предложения от разных агентов и выбирать наилучшую стратегию. Такие многозадачные системы не новы в области искусственного интеллекта, и их использование в контексте финансовых рынков позволяет эффективно учитывать разнообразие факторов и рисков.
Второй важный момент — в рамках фреймворка HiSSD каждый агент генерирует действия на основе локальных наблюдений.Однако в контексте финансовых рынков, где информация о ценах, объемах торгов и других показателях тесно взаимосвязаны между собой, такой подход требует доработки. Мы можем предоставить каждому агенту для анализа отдельную унитарную последовательность из мультимодального временного ряда исходных данных. Но важно помнить, что на реальных рынках показатели часто коррелируют между собой. Например, изменения цен на один актив могут оказывать влияние на цену других активов, что приводит к необходимости учитывать эти взаимосвязи. С этой целью, мы внедрим механизм обогащения данных, который позволит каждому агенту получать общие знания о состоянии рынка и использовать эту информацию для более взвешенного принятия решения.
Наконец, стоит подчеркнуть важность модульности, которая является основой фреймворка HiSSD. Такой подход идеально подходит для сложных и многозадачных систем. Можно разделить систему на несколько компонентов, каждый из которых решает отдельную задачу. Модульность не только позволяет эффективно оптимизировать отдельные компоненты, но и помогает гибко адаптировать систему под изменяющиеся условия на рынке. В нашем случае, такой подход имеет особую ценность, так как финансовые рынки подвержены изменениям, и способность оперативно менять или улучшать отдельные части модели может стать ключом к успешной торговле.
Энкодер навыков
Первый модуль, с которого мы начнём построение модели, — это энкодер навыков. Здесь мы сразу обращаем внимание на важную архитектурную особенность фреймворка HiSSD: общие и специфические для задачи навыки формируются на основе одного и того же источника информации. Это локальные наблюдения агента. В нашем случае — унитарные последовательности, полученные из мультимодального временного ряда, описывающего состояние окружающей среды.
С учетом данной особенности, было принято решение использовать одно архитектурное решение для двух подзадач. Такой подход обеспечивает несколько преимуществ. Во-первых, это упрощает проектирование и последующую отладку модели. Во-вторых, он позволяет использовать единую методологию анализа качества извлекаемых признаков. Наконец, повторное использование архитектурных решений экономит ресурсы разработки и позволяет быстрее масштабировать модель при переходе к новым задачам, или новым финансовым инструментам.
Работу энкодера навыков организуем в рамках объекта CNeuronSkillsEncoder, структура которого представлена ниже.
class CNeuronSkillsEncoder : public CNeuronSoftMaxOCL { protected: CNeuronCATCH cCrossObservAttention; CNeuronTransposeOCL cTranspose; CNeuronConvOCL cSkillsProjection[2]; CNeuronBaseOCL cPrevSkillsConcat; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; public: CNeuronSkillsEncoder(void) {}; ~CNeuronSkillsEncoder(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint time_step, uint variables, uint skills, uint window, uint step, uint window_key, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronSkillsEncoder; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
В представленной структуре мы видим ряд внутренних объектов, каждый из которых будет выполнять свою важную роль. Подробнее с их функционалом познакомимся в процессе построения методов нового класса. А сейчас для нас важно, что все объекты объявлены статично. Это позволяет нам оставить пустыми конструктор и деструктор класса. Инициализация всех внутренних объектов осуществляется в методе Init.
bool CNeuronSkillsEncoder::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint time_step, uint variables, uint skills, uint window, uint step, uint window_key, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronSoftMaxOCL::Init(numOutputs, myIndex, open_cl, variables * skills, optimization_type, batch)) return false; SetHeads(variables);
В параметрах данного метода получаем ряд констант, позволяющих однозначно идентифицировать архитектуру создаваемого объекта. Наименование практически всех параметров нам уже знакомо по предыдущим работам и мы не будем сейчас расписывать каждый из них.
В теле метода, как обычно, сразу вызываем одноименный метод родительского класса в котором уже организованы минимально необходимые точки контроля, а также построены процессы инициализации унаследованных объектов и интерфейсов.
В качестве родительского класса мы использовали слой функции SoftMax. Это позволит нам нормализовать результаты работы энкодеров навыков отдельных агентов, приведя их в сопоставимый вид. Количество навыков для каждого агента определяется параметром skills. Именно такой длины генерируется вектор результатов на выходе модуля для каждого агента. А значение элемента вектора укажет на важность использования того или иного навыка.
Не сложно догадаться, что в нашем случае число агентов будет равно количеству унитарных последовательностей в анализируемом мультимодальном временном ряде. Его мы и укажем в качестве числа голов нормализации функцией SoftMax.
После успешного выполнения операций метода родительского класса, переходим к инициализации вновь созданных внутренних объектов. И первым инициализируем объект обмена информацией между унитарными последовательностями. В рамках данного эксперимента эту работу будет выполнять объект фреймворка CATCH, построенный нами в рамках предыдущей работы.
int index = 0; if(!cCrossObservAttention.Init(0, index, OpenCL, time_step, variables, window, step, window_key, heads, optimization, iBatch)) return false;
Напомню, что данный объект позволяет согласовать унитарные последовательности в частотной области. При этом, спектральное разложение делится на сегменты, и анализ осуществляется в рамках отдельных сегментов. Такой подход позволяет более гибко учитывать особенности поведения различных рыночных сигналов. Вместо того, чтобы анализировать всю частотную структуру временного ряда целиком, мы концентрируем внимание на отдельных диапазонах частот. Это особенно важно в контексте финансовых рынков, где колебания высокой и низкой частоты могут нести принципиально разную информацию: высокочастотные колебания часто отражают краткосрочную волатильность и шум, тогда как низкочастотные компоненты позволяют выявить тренды и долгосрочные закономерности.
Это позволяет найти общие закономерности — синхронность, фазовые сдвиги, корреляции — и использовать их как дополнительный источник информации при формировании навыков.
Важно, что обмен информацией происходит не напрямую, а через механизм маскированного внимания. Это защищает агентов от чрезмерного влияния друг на друга, сохраняя принцип децентрализации. В результате, каждый агент продолжает работать с собственной унитарной последовательностью, но получает возможность учитывать важные закономерности, характерные для всей рыночной сцены.
На выходе модуля CATCH получаем тот же мультимодальный временной ряд исходных данных, но уже обогащенный информацией межканальных связей.
Далее, каждый агент должен получить свою унитарную последовательность. И с целью трансформации анализируемых данных в более удобное представление, воспользуемся слоем транспонирования.
index++; if(!cTranspose.Init(0, index, OpenCL, time_step, variables, optimization, iBatch)) return false;
Далее используются независимые головы генерации вектора навыков каждого агента. Здесь мы используем 2 последовательных сверточных слоя.
Однако, следует обратить внимание, что длина анализируемой последовательности может варьироваться в довольно широком диапазоне, и напрямую обрабатывать всю анализируемую последовательность одним блоком может быть достаточно накладно. Поэтому, на первом этапе, мы разбиваем её на несколько сегментов и изменяем размерность средствами сверточного слоя.
uint count = (time_step - window + step - 1) / step; if(count <= 1) { window = time_step; count = 1; } //--- index++; if(!cSkillsProjection[0].Init(0, index, OpenCL, window, step, window_key, count, variables, optimization, iBatch)) return false; cSkillsProjection[0].SetActivationFunction(SoftPlus);
А второй сверточный слой собирает все сегменты, относящиеся к одной унитарной последовательности, и формирует единый вектор навыков отдельно взятого агента. Об этом свидетельствует указание "1" в качестве размера последовательности.
index++; if(!cSkillsProjection[1].Init(0, index, OpenCL, window_key * count, window_key * count, skills, 1, variables, optimization, iBatch)) return false; cSkillsProjection[1].SetActivationFunction(None);
Важно подчеркнуть, в параметрах сверточных слоёв мы явно задаём количество независимых унитарных последовательностей, обрабатываемых моделью. Это позволяет каждому агенту использовать собственную копию сверточной архитектуры с уникальным набором весов. Но помимо этого, каждый агент анализирует свою локальную область данных, то есть, отдельную часть общего мультимодального временного ряда.
Другими словами, агент не просто видит уникальные данные — он фокусируется на ограниченном подмножестве информации. Это приближает модель к реальности финансовых рынков, где каждый трейдер (в нашем случае — агент) работает с разными источниками информации и принимает решения на их основе.
В результате, мы получаем не просто параллельных исполнителей одной задачи, а целую команду специализированных агентов, каждый из которых обучается в своей среде, строит своё представление о рынке и вырабатывает собственную стратегию поведения. Такая организация повышает устойчивость всей системы, усиливает диверсификацию поведения и даёт возможность комбинировать локальные стратегии для достижения глобальной цели — эффективной и адаптивной торговли в условиях неопределённости.
Далее мы инициализируем вспомогательный объект, размер которого в 2 раза превышает тензор результатов. О его функционале мы поговорим в процессе построения метода распределения градиента ошибки.
index++; if(!cPrevSkillsConcat.Init(0, index, OpenCL, 2 * Neurons(), optimization, iBatch)) return false; cPrevSkillsConcat.SetActivationFunction((ENUM_ACTIVATION)cSkillsProjection[1].Activation()); //--- return true; }
После успешной инициализации всех внутренних объектов, мы завершаем работу метода, предварительно вернув логический результат выполнения операций вызывающей программе.
Следующим этапом нашей работы является построение алгоритмов прямого прохода в рамках метода feedForward. Здесь, ожидаемо, все довольно просто и линейно.
bool CNeuronSkillsEncoder::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cCrossObservAttention.FeedForward(NeuronOCL)) return false;
В параметрах метода получаем указатель на объект мультимодальных исходных данных, которой сразу передаем во внутренний модуль анализа межканальных зависимостей.
if(!cTranspose.FeedForward(cCrossObservAttention.AsObject())) return false;
Полученные результаты транспонируем и передаем в блок генерации тензора навыков.
if(!cSkillsProjection[0].FeedForward(cTranspose.AsObject())) return false;
Однако, стоит обратить внимание на один момент. Перед вызовом метода прямого прохода второго сверточного слоя мы осуществляем перестановку указателей на буферы результатов. Эта несложная итерация позволяет нам сохранить результаты предшествующих операций. Ценность данного действия будет объяснена при построении метода распределения градиента ошибки.
if(!cSkillsProjection[1].SwapOutputs() || !cSkillsProjection[1].FeedForward(cSkillsProjection[0].AsObject())) return false; //--- return CNeuronSoftMaxOCL::feedForward(cSkillsProjection[1].AsObject()); }
Сформированный тензор навыков агентов мы переводим в подпространство вероятностей средствами родительского класса и завершаем работу метода, вернув логический результат выполнения операций вызывающей программе.
Далее, мы переходим к построению алгоритмов обратного прохода. Как вы знаете, данная работа у нас разделена на 2 этапа:
- распределение градиентов ошибки между всеми участниками процесса — метод calcInputGradients;
- оптимизация параметров модели в сторону минимизации ошибки — метод updateInputWeights.
Начнём с метода calcInputGradients, который отвечает за распространение градиента ошибки между внутренними объектами, в соответствии с их влиянием на итоговый результат работы модели. К его реализации мы уже подводили читателя — дважды упоминали его ранее, оставляя лёгкую интригу. Теперь настало время детально разобрать, как он устроен и почему играет важную роль в обучении модели.
В параметрах метода получаем указатель на объект исходных данных, тот самый, который использовался при выполнении операций прямого прохода. Однако, на этот раз, нам предстоит передать в него градиент ошибки в соответствии с влиянием исходных данных на итоговый результат работы модели.
bool CNeuronSkillsEncoder::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!prevLayer) return false;
Разумеется, передать данные мы можем только в действительный объект. Поэтому, в теле метода сразу проверяем актуальность полученного указателя. Если указатель оказался пустым или невалидным, выполнение метода моментально прерывается — дальнейшие вычисления теряют смысл. Такая проверка — это базовая мера безопасности, гарантирующая корректность выполнения алгоритма и защиту от непредсказуемых сбоев в обучении.
В случае же успешного прохождения контрольной точки, мы переходим к следующему этапу — распределению градиента ошибки. Здесь начинается последовательная передача информации между всеми объектами, вовлечёнными в процесс. Каждый из этих объектов отвечает за свою часть логики модели, и наша задача — аккуратно, шаг за шагом, передать градиент ошибки в нужные компоненты.
Этот механизм критически важен: он обеспечивает обратную связь внутри модели, позволяя каждому блоку скорректировать свои параметры в зависимости от итоговой ошибки. Именно благодаря такому механизму, модель обучается — находит оптимальные параметры, минимизируя потери.
На первом этапе, используя механизмы, предоставленные родительским классом, мы передаём градиент ошибки, поступивший от последующих слоёв нейросетевой архитектуры во внешние интерфейсы объекта, до уровня последнего слоя генерации тензора навыков агентов.
if(!CNeuronSoftMaxOCL::calcInputGradients(cSkillsProjection[1].AsObject())) return false;
Этот процесс играет ключевую роль в обучении модели — он обеспечивает способность генерировать навыки, которые действительно релевантны поставленной задаче. Благодаря последовательному распространению градиента ошибки, модель получает прямую обратную связь о том, насколько корректными были её предыдущие действия и решения.
Однако, для нас важно не только обучить агентов генерировать полезные навыки, но и организовать их работу в команде таким образом, чтобы они могли эффективно взаимодействовать, направляя свои усилия в различных направлениях для достижения максимального общего результата. Это не просто обучение каждого агента индивидуально, а создание синергии между ними.
Для реализации этого подхода мы используем алгоритмы контрастного обучения, которые позволят нам внести разнообразие в тензоры навыков агентов. Важно отметить, что диверсификация будет происходить не только между различными агентами на одном временном шаге, но и между навыками, сгенерированными на разных шагах. Это создаст более глубокое различие в восприятии состояний.
Таким образом, каждый агент будет вынужден не только осознавать уникальность своего навыка, но и учитывать контекст, сформированный предыдущими действиями. Это подталкивает агентов к созданию более сложных и последовательных стратегий поведения, в которых они способны адаптироваться к меняющимся условиям и динамике рынка.
В контексте финансовых рынков, где ситуация часто изменяется очень быстро, такая способность агентов учитывать предшествующие действия и различия в состояниях становится крайне важной. Диверсификация навыков, дополненная использованием исторических данных, позволяет строить более устойчивые и адаптивные стратегии, которые могут эффективно работать в условиях высокой нестабильности и неопределенности.
Алгоритм контрастного обучения будет играть ключевую роль в создании этих различий, а именно он будет способствовать улучшению способности агентов различать и анализировать различные ситуации, принимая более обоснованные решения на каждом шаге.
В процессе прямого прохода, перед генерацией нового тензора навыков, мы сохранили результаты предыдущего прямого прохода. И теперь соберем результаты обработки двух состояний окружающей среды в единый тензор.
if(!Concat(cSkillsProjection[1].getOutput(), cSkillsProjection[1].getPrevOutput(), cPrevSkillsConcat.getOutput(), cSkillsProjection[1].GetFilters(), cSkillsProjection[1].GetFilters(), iHeads)) return false;
После чего, вызовем метод диверсификации, который призван максимально развести отдельные векторы в подпространстве навыков.
if(!DiversityLoss(cPrevSkillsConcat.AsObject(), 2 * iHeads, cSkillsProjection[1].GetFilters(), false)) return false;
Полученные градиенты ошибки мы разделяем на соответствующие последовательности.
if(!DeConcat(cPrevSkillsConcat.getOutput(), cPrevSkillsConcat.getPrevOutput(), cPrevSkillsConcat.getGradient(), cSkillsProjection[1].GetFilters(), cSkillsProjection[1].GetFilters(), iHeads)) return false;
И добавляем к ранее полученным градиентам ошибки навыки текущего временного шага.
if(!SumAndNormilize(cSkillsProjection[1].getGradient(), cPrevSkillsConcat.getOutput(), cSkillsProjection[1].getGradient(), cSkillsProjection[1].GetFilters(), false, 0, 0, 0, 1)) return false;
Дальнейший алгоритм метода линеен. Спускаем градиент ошибки по блоку генерации навыков.
if(!cSkillsProjection[0].calcHiddenGradients(cSkillsProjection[1].AsObject())) return false;
Полученные значения транспонируем с передачей данных в модуль анализа межканальных зависимостей.
if(!cTranspose.calcHiddenGradients(cSkillsProjection[0].AsObject())) return false; if(!cCrossObservAttention.calcHiddenGradients(cTranspose.AsObject())) return false;
И передаем градиент ошибки в объект исходных данных, в соответствии с их влиянием на итоговый результат.
return prevLayer.calcHiddenGradients(cCrossObservAttention.AsObject());
}
После чего, завершаем работу метода, вернув логический результат выполнения операций вызывающей программе.
Метод обновления параметров модели updateInputWeights максимально прост: мы лишь вызываем одноименные методы внутренних объектов. Здесь стоит обметить, что не все внутренние объекты содержат обучаемые параметры, поэтому, и в работе метода участвует лишь часть из них.
bool CNeuronSkillsEncoder::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cCrossObservAttention.UpdateInputWeights(NeuronOCL)) return false; if(!cSkillsProjection[0].UpdateInputWeights(cTranspose.AsObject())) return false; if(!cSkillsProjection[1].UpdateInputWeights(cSkillsProjection[0].AsObject())) return false; //--- return true; }
Несколько слов надо сказать о методах сохранения обученной модели и восстановления её работоспособности. Как вы могли заметить, объект конкатенирования результатов двух последовательных прямых проходов не содержит обучаемых параметров. Он выполняет лишь вспомогательную функцию, соединяя выходные данные из двух разных потоков. Несмотря на это, объект конкатенирования обладает буферами данных, размер которых в два раза больше тензора результатов текущего объекта. Однако, такие данные не оказывают критического влияния на функционирование модели, поскольку они являются лишь временным хранилищем информации, используемой для промежуточных вычислений. С учетом этого, при сохранении обученной модели мы можем сэкономить пространство на диске, исключив необходимость хранения таких буферов данных.
bool CNeuronSkillsEncoder::Save(const int file_handle) { if(!CNeuronSoftMaxOCL::Save(file_handle)) return false; if(!cCrossObservAttention.Save(file_handle)) return false; if(!cTranspose.Save(file_handle)) return false; for(uint i = 0; i < cSkillsProjection.Size(); i++) if(!cSkillsProjection[i].Save(file_handle)) return false; //--- return true; }
При восстановлении работоспособности модели, мы легко можем повторно инициализировать объект конкатенации на основании данных о размере тензора результатов нашего энкодера навыков.
bool CNeuronSkillsEncoder::Load(const int file_handle) { if(!CNeuronSoftMaxOCL::Load(file_handle)) return false; if(!LoadInsideLayer(file_handle, cCrossObservAttention.AsObject())) return false; if(!LoadInsideLayer(file_handle, cTranspose.AsObject())) return false; for(uint i = 0; i < cSkillsProjection.Size(); i++) if(!LoadInsideLayer(file_handle, cSkillsProjection[i].AsObject())) return false; //--- if(!cPrevSkillsConcat.Init(0, 4, OpenCL, 2 * Neurons(), optimization, iBatch)) return false; cPrevSkillsConcat.SetActivationFunction((ENUM_ACTIVATION)cSkillsProjection[1].Activation()); //--- return true; }
На этом мы завершаем рассмотрение алгоритмов построения методов энкодера навыков. С полным кодом представленного объекта и всех его методов можно ознакомиться во вложении.
Сегодня мы хорошо поработали, но к сожалению, объем статьи практически исчерпан. Поэтому сделаем небольшой перерыв и продолжим работу в следующей статье.
Заключение
Мы познакомились с теоретическими аспектами фреймворка HiSSD, который представляет собой мощную и гибкую систему для обучения агентов в многоагентной среде. Каждый агент учит индивидуальную политику поведения в тесном взаимодействии с другими участниками процесса. Такое сочетание обучения общих и специфических навыков позволяет создавать более адаптивные и устойчивые стратегии, которые способны эффективно работать в условиях неопределенности и изменчивости.
Модульность подхода HiSSD, а также комбинация использования различных методов для обучения и настройки модели, таких как контрастное обучение и вариационное поведенческое кодирование, делают его очень гибким и перспективным инструментом для решения задач в области мультиагентных систем.
В практической части статьи начата работа по реализации средствами MQL5 собственного видения подходов, предложенных авторами фреймворка. В частности, представлена реализация универсального энкодера навыков. В следующей статье мы продолжим начатую работу с последующим тестированием эффективности реализованных подходов на реальных исторических данных.
Ссылки
- Learning Generalizable Skills from Offline Multi-Task Data for Multi-Agent Cooperation
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Введение в Connexus (Часть 1): Как использовать функцию WebRequest?
Введение в Connexus (Часть 1): Как использовать функцию WebRequest?
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования