
Expert Advisor de scalping Ilan 3.0 AI com aprendizado de máquina

Introdução
No mundo do trading algorítmico, algumas estratégias, como estrelas eternas em um céu financeiro em constante mudança, deixam uma marca indelével na história do trading. Entre elas estava o Ilan, um EA de grid que se tornou lendário, conquistando a mente e as contas de traders da década de 2010 com sua simplicidade enganosa e sua eficácia potencial em períodos de baixa volatilidade.
No entanto, o tempo não para. Na era da computação quântica, das redes neurais e do aprendizado de máquina, as estratégias de ontem exigem uma reinterpretação profunda. E se combinássemos a clássica mecânica de média em grade do Ilan com algoritmos avançados de inteligência artificial? E se, em vez de regras rigidamente codificadas, permitíssemos que o sistema se adaptasse e melhorasse continuamente por conta própria?
Neste artigo, desafiamos as concepções tradicionais sobre sistemas de trading e fazemos uma tentativa ambiciosa de reviver o clássico Ilan, equipando-o com mecanismos de aprendizado profundo por reforço (DQN) e uma tabela Q dinâmica. Não estamos apenas atualizando o código existente, mas criando um sistema inteligente de nova geração, que aprende com a própria experiência, adapta-se às mudanças do mercado e otimiza as decisões de trading em tempo real.
Nossa jornada o levará pelos labirintos do trading algorítmico, onde o rigor matemático encontra a elegância computacional, e as clássicas técnicas de martingale ganham nova vida graças às abordagens inovadoras do aprendizado de máquina. Seja você um trader algorítmico experiente, um desenvolvedor de sistemas de trading ou apenas um entusiasta de tecnologia financeira, este artigo oferece uma visão única sobre o futuro do trading automatizado.
Aperte os cintos, embarcamos em uma jornada fascinante para criar o Ilan 3.0 AI, onde a tradição encontra a inovação e o passado evolui para o futuro.
Analisando o Ilan clássico por dentro
Antes de mergulhar no mundo da inteligência artificial, é essencial entender o que tornava o Ilan um EA tão popular nos anos 2010. A ideia central de seu funcionamento estava baseada no conceito de média de posições. Quando o preço se movia contra a posição aberta, o EA não encerrava a operação com prejuízo, mas adicionava novas ordens, melhorando o preço médio de entrada.
Aqui está um trecho simplificado de código que ilustra essa lógica:
// Упрощенная логика усреднения в оригинальном Ilan if(positionCount == 0) { // Открытие первой позиции по сигналу if(OpenSignal()) { OpenPosition(ORDER_TYPE_BUY, StartLot); } } else { // Вычисление уровня для усреднения double averagePrice = CalculateAveragePrice(); double gridLevel = averagePrice - GridSize * Point(); // Если цена достигла уровня сетки, добавляем позицию if(Bid <= gridLevel) { double newLot = StartLot * MathPow(LotMultiplier, positionCount); OpenPosition(ORDER_TYPE_BUY, newLot); } // Проверка на закрытие всех позиций по TP if(Bid >= averagePrice + TakeProfit * Point()) { CloseAllPositions(); } }
A magia do Martingale: por que os traders se apaixonavam pelo Ilan
A popularidade do Ilan pode ser explicada por diversos fatores. Antes de tudo, seu funcionamento era intuitivamente compreensível até mesmo para traders iniciantes. Em mercados laterais, o sistema apresentava resultados quase mágicos, pois cada oscilação de preço se transformava em uma fonte de lucro. A média das posições permitia "salvar" operações que inicialmente estavam em prejuízo, criando no trader a sensação de invencibilidade do sistema.
Outro fator atraente era a possibilidade de configurar a estratégia com um conjunto mínimo de parâmetros:
// Ключевые параметры советника Ilan input double StartLot = 0.01; // Начальный размер лота input double LotMultiplier = 1.5; // Множитель лота для каждой новой позиции input int GridSize = 30; // Шаг сетки в пунктах input int TakeProfit = 40; // Прибыль для закрытия всех позиций input int MaxPositions = 10; // Максимальное количество открываемых позиций
Essa simplicidade de configuração criava uma ilusão de controle, pois o trader podia experimentar diferentes combinações de parâmetros, obtendo resultados impressionantes em dados históricos.
Tentativas de evolução: o que mudou no Ilan 2.0
No Ilan 2.0, os desenvolvedores tentaram resolver algumas dessas limitações. Foram adicionados o cálculo dinâmico do passo da grade com base na volatilidade do mercado, o suporte a múltiplos pares de moedas e a análise de suas correlações, além de filtros adicionais para abertura de posições e mecanismos de proteção contra perdas excessivas.
// Динамический расчет шага сетки в Ilan 2.0 double CalculateGridStep(string symbol) { double atr = iATR(symbol, PERIOD_CURRENT, ATR_Period, 0); return atr * ATR_Multiplier; } // Защитный механизм для ограничения убытков bool EquityProtection() { double currentEquity = AccountInfoDouble(ACCOUNT_EQUITY); double maxAllowedDrawdown = AccountInfoDouble(ACCOUNT_BALANCE) * MaxDrawdownPercent / 100.0; if(AccountInfoDouble(ACCOUNT_BALANCE) - currentEquity > maxAllowedDrawdown) { CloseAllPositions(); return true; } return false; }
Essas melhorias realmente tornaram o sistema mais estável, mas não resolveram o problema fundamental da falta de adaptabilidade. O Ilan 2.0 ainda se baseava em regras estáticas e não era capaz de aprender com sua própria experiência nem de se ajustar às mudanças nas condições de mercado.
Por que os traders continuavam usando o Ilan
Apesar das falhas evidentes, muitos traders continuavam utilizando o Ilan e suas modificações. Isso se explicava por uma série de fatores psicológicos. Aqueles que perderam tudo geralmente permaneciam em silêncio, enquanto as histórias de sucesso eram amplamente divulgadas. Os traders viam apenas os períodos lucrativos e ignoravam os sinais de alerta. Parecia que um ajuste fino nos parâmetros poderia resolver todos os problemas. Além disso, a estratégia Martingale ativava os mesmos gatilhos psicológicos que os jogos de azar.
Para ser justo, vale ressaltar que, em determinadas condições de mercado (especialmente em períodos de baixa volatilidade e movimentos laterais), o EA realmente podia apresentar resultados impressionantes por um longo tempo. O problema era que as condições do mercado inevitavelmente mudavam, e o EA não se adaptava a essas mudanças.
Por que o Ilan inevitavelmente quebrava e perdia o depósito
O verdadeiro problema do Ilan se revelava no longo prazo. A estratégia, que funcionava brilhantemente em mercados laterais, tornava-se catastrófica diante de movimentos de tendência prolongados. Vejamos um cenário típico de colapso.
Primeiro, é aberta uma posição de compra. Em seguida, o mercado começa um movimento descendente consistente. O EA adiciona novas posições, aumentando os lotes em progressão geométrica. Após alguns níveis de média, o tamanho total da posição se torna tão grande que até mesmo um pequeno movimento adicional do preço leva a um margin call.
Matematicamente, esse problema pode ser expresso da seguinte forma: em uma estratégia Martingale com coeficiente de multiplicação de lote 1.5 e lote inicial de 0.01, a décima posição consecutiva terá tamanho aproximado de 0.57 lote, ou seja, 57 vezes maior que o lote inicial. O tamanho total de todas as posições abertas será de cerca de 1.1 lote, o que, para uma conta de $1000 com alavancagem de 1:100, significa praticamente o uso de toda a margem disponível.
// Расчет общего размера позиций при мартингейле double totalVolume = 0; double currentLot = StartLot; for(int i = 0; i < MaxPositions; i++) { totalVolume += currentLot; currentLot *= LotMultiplier; } // При StartLot = 0.01 и LotMultiplier = 1.5 после 10 позиций // totalVolume будет около 1.1 лота!
O problema central estava na ausência de um mecanismo para determinar quando o processo de média deveria ser interrompido. O Ilan era como um jogador compulsivo que não sabe quando parar e continua apostando cada vez mais, na esperança de recuperar as perdas.
Por que o Ilan precisa de inteligência artificial
Ao analisar os pontos fortes e fracos do Ilan, torna-se evidente que o problema principal está em sua incapacidade de aprender e se adaptar. O EA segue as mesmas regras, independentemente de suas ações anteriores terem sido bem-sucedidas ou desastrosas.
É exatamente aqui que entra a inteligência artificial. E se mantivermos o mecanismo básico de funcionamento do Ilan, mas adicionarmos a ele a capacidade de analisar os resultados de suas próprias ações e ajustar a estratégia? E se, em vez de regras rigidamente codificadas, permitirmos que o sistema encontre de forma autônoma os parâmetros e pontos de entrada ideais com base na experiência acumulada?
É justamente essa a ideia que fundamenta nosso projeto de criação do Ilan 3.0 AI, no qual integramos a comprovada estratégia de média com métodos modernos de aprendizado de máquina. Na próxima parte, veremos como a tecnologia de aprendizado Q torna essa concepção possível.
Como o aprendizado Q aprimora o EA Ilan
A transição do modelo clássico do Ilan para um sistema inteligente capaz de aprender exige uma mudança fundamental na arquitetura do EA. O coração do Ilan 3.0 AI é o algoritmo de aprendizado Q, uma das tecnologias mais importantes dentro do aprendizado por reforço.
Fundamentos do aprendizado Q com base em suas ações
O aprendizado Q recebe esse nome devido à "função de qualidade" (Quality function), que define o valor de uma ação em um determinado estado. Em nossa implementação, utilizamos uma tabela Q, que é uma estrutura de dados que armazena as avaliações para cada par "estado–ação":
// Структура для Q-таблицы struct QEntry { string state; // Дискретизированное состояние рынка int action; // Действие (0-ничего, 1-покупка, 2-продажа) double value; // Q-значение }; // Глобальный массив для Q-таблицы QEntry QTable[]; int QTableSize = 0;A principal característica do aprendizado Q é a capacidade do sistema de aprender com a própria experiência. Após cada ação, o algoritmo recebe uma recompensa (lucro) ou uma penalidade (prejuízo) e ajusta sua estimativa do valor dessa ação em uma situação de mercado específica:
// Обновление Q-значения по формуле Беллмана void UpdateQValue(string stateStr, int action, double reward, string nextStateStr, bool done) { double currentQ = GetQValue(stateStr, action); double nextMaxQ = 0; if(!done) { // Находим максимальное Q для следующего состояния nextMaxQ = GetMaxQValue(nextStateStr); } // Обновление Q-значения double newQ = currentQ + LearningRate * (reward + DiscountFactor * nextMaxQ - currentQ); // Сохранение обновленного значения SetQValue(stateStr, action, newQ); }
Essa fórmula, conhecida como equação de Bellman, é a pedra angular do nosso sistema. O parâmetro LearningRate define a velocidade de aprendizado, enquanto o DiscountFactor determina a importância das recompensas futuras em relação às recompensas atuais.
Equilíbrio entre busca de novas soluções e uso da experiência
Um dos maiores desafios no aprendizado por reforço é a necessidade de equilibrar a exploração de novas estratégias e a intensificação (exploitation) das soluções já conhecidas como ótimas. Para resolver esse problema, utilizamos a estratégia ε-greedy:
// Выбор действия с балансом между исследованием и использованием int SelectAction(string stateStr) { // С вероятностью epsilon выбираем случайное действие (исследование) if(MathRand() / (double)32767 < currentEpsilon) { return MathRand() % ActionCount; } // Иначе выбираем действие с максимальным Q-значением (использование) int bestAction = 0; double maxQ = GetQValue(stateStr, 0); for(int a = 1; a < ActionCount; a++) { double q = GetQValue(stateStr, a); if(q > maxQ) { maxQ = q; bestAction = a; } } return bestAction; }O parâmetro currentEpsilon define a probabilidade de uma ação ser escolhida aleatoriamente. Com o tempo, esse valor diminui, permitindo que o sistema passe gradualmente da exploração ativa para o uso preferencial do conhecimento acumulado:
// Уменьшение epsilon для постепенного перехода от исследования к использованию if(currentEpsilon > MinExplorationRate) currentEpsilon *= ExplorationDecay;
O órgão sensorial digital: como o algoritmo percebe o mercado
Para que o aprendizado seja eficaz, o algoritmo precisa "enxergar" o mercado, ou seja, ter uma representação formalizada da situação atual. No Ilan 3.0 AI, utilizamos um vetor de estado complexo, que inclui indicadores técnicos, métricas das posições abertas e outros dados de mercado:
// Получение текущего состояния рынка для Q-обучения void GetCurrentState(string symbol, double &state[]) { ArrayResize(state, StateDimension); // Технические индикаторы double rsi = iRSI(symbol, PERIOD_CURRENT, RSI_Period, PRICE_CLOSE, 0); double cci = iCCI(symbol, PERIOD_CURRENT, CCI_Period, PRICE_TYPICAL, 0); double macd = iMACD(symbol, PERIOD_CURRENT, 12, 26, 9, PRICE_CLOSE, MODE_MAIN, 0); // Нормализация индикаторов double normalized_rsi = rsi / 100.0; double normalized_cci = (cci + 500) / 1000.0; // Метрики позиций int positions = (symbol == "EURUSD") ? euroUsdPositions : audUsdPositions; double normalized_positions = (double)positions / MaxTrades; // Расчет разницы цен double point = SymbolInfoDouble(symbol, SYMBOL_POINT); double currentBid = SymbolInfoDouble(symbol, SYMBOL_BID); double avgPrice = CalculateAveragePrice(symbol); double price_diff = (currentBid - avgPrice) / (100 * point); // Заполнение вектора состояния state[0] = normalized_rsi; state[1] = normalized_cci; state[2] = normalized_positions; state[3] = price_diff; state[4] = macd / (100 * point); state[5] = AccountInfoDouble(ACCOUNT_EQUITY) / AccountInfoDouble(ACCOUNT_BALANCE); }Para trabalhar com a tabela Q, os valores contínuos do estado precisam ser discretizados, ou seja, convertidos em uma representação textual com um número finito de variações:
// Преобразование состояния в строку для Q-таблицы string StateToString(double &state[]) { string stateStr = ""; for(int i = 0; i < ArraySize(state); i++) { // Округление до 2 десятичных знаков для дискретизации double discretized = MathRound(state[i] * 100) / 100.0; stateStr += DoubleToString(discretized, 2); if(i < ArraySize(state) - 1) stateStr += ","; } return stateStr; }
Esse processo de discretização permite que o sistema generalize a experiência adquirida, aplicando-a a situações de mercado semelhantes, mas não idênticas.
O sistema de estímulos: a cenoura e o chicote no mundo da IAA definição correta do sistema de recompensas é, sem dúvida, o aspecto mais crítico na construção de um sistema eficiente de aprendizado por reforço. No Ilan 3.0 AI, desenvolvemos um sistema de estímulos em múltiplos níveis, que orienta o desenvolvimento do algoritmo na direção desejada.
A economia das recompensas: como motivar o algoritmo
Ao encerrar posições lucrativas, o sistema recebe uma recompensa positiva proporcional ao tamanho do lucro:
// Награда при закрытии прибыльных позиций if(shouldClose) { if(ClosePositions(symbol, magic)) { if(isTraining) { double reward = profit; // Награда равна прибыли UpdateQValue(stateStr, action, reward, stateStr, true); // Статистика обучения episodeCount++; totalReward += reward; Print("Эпизод ", episodeCount, " завершен с наградой: ", reward, ". Средняя награда: ", totalReward / episodeCount); } } }Ao fazer a média de posições perdedoras, o sistema recebe uma pequena penalidade, o que o incentiva a buscar pontos de entrada mais eficientes e a evitar situações que exijam média:
// Штраф при усреднении позиций if(OpenPosition(symbol, ORDER_TYPE_BUY, CalculateLot(positionsCount, symbol), StopLoss, TakeProfit, magic)) { if(isTraining) { double reward = -1; // Небольшой штраф за усреднение UpdateQValue(stateStr, action, reward, stateStr, false); } }
A ausência de recompensa imediata na abertura da primeira posição força o sistema a focar em resultados de longo prazo, em vez de ações de curto prazo.
A delicada calibragem do sistema
A eficiência do sistema de aprendizado Q depende fortemente da configuração correta de seus parâmetros principais. No Ilan 3.0 AI, oferecemos a possibilidade de ajuste fino de todos os aspectos do aprendizado:
// Параметры обучения с подкреплением input double LearningRate = 0.01; // Скорость обучения input double DiscountFactor = 0.95; // Коэффициент дисконтирования input double ExplorationRate = 0.3; // Начальная вероятность исследования input double ExplorationDecay = 0.995; // Коэффициент уменьшения исследования input double MinExplorationRate = 0.01;// Минимальная вероятность исследования
LearningRate define a velocidade de atualização dos valores Q. Valores altos resultam em aprendizado rápido, mas podem causar instabilidade. Valores baixos proporcionam um aprendizado mais estável, porém mais lento.
DiscountFactor determina a importância das recompensas futuras. Valores próximos de 1 fazem com que o sistema busque a maximização de lucros no longo prazo, às vezes sacrificando ganhos imediatos.
Os parâmetros de exploração controlam o equilíbrio entre a busca por novas estratégias e a intensificação (exploitation) das soluções já conhecidas como ideais. Com o tempo, a probabilidade de exploração diminui, permitindo que o sistema dependa cada vez mais da experiência acumulada.
Da teoria à prática: implementação
A implementação do Ilan 3.0 AI exige a integração dos mecanismos de aprendizado Q com a lógica tradicional de um EA de trading. O componente central é a função de controle de operações, que utiliza o aprendizado Q para a tomada de decisões:// Функция управления торговлей с использованием Q-обучения void ManagePairWithDQN(string symbol, int &positionsCount, CArrayDouble &trades, int magic, datetime &firstTradeTime) { // Получение текущих рыночных данных double currentBid = SymbolInfoDouble(symbol, SYMBOL_BID); double currentAsk = SymbolInfoDouble(symbol, SYMBOL_ASK); double point = SymbolInfoDouble(symbol, SYMBOL_POINT); // Формирование текущего состояния double state[]; GetCurrentState(symbol, state); string stateStr = StateToString(state); // Выбор действия с помощью Q-таблицы int action = SelectAction(stateStr); // Преобразование действия в торговую операцию bool shouldTrade = (action > 0); ENUM_ORDER_TYPE orderType = (action == 1) ? ORDER_TYPE_BUY : ORDER_TYPE_SELL; // Логика открытия и управления позициями if(shouldTrade) { // Логика открытия первой позиции или усреднения // ... } // Проверка необходимости закрытия позиций double profit = CalculatePositionsPnL(symbol, magic); if(profit > 0 && positionsCount > 0) { // Логика закрытия прибыльных позиций // ... } }
Armazenamento da experiência do sistema
Para preservar a experiência acumulada entre as sessões, implementamos um mecanismo de salvamento e carregamento da tabela Q:
// Сохранение Q-таблицы в файл bool SaveQTable(string filename) { int handle = FileOpen(filename, FILE_WRITE|FILE_BIN); if(handle == INVALID_HANDLE) { Print("Ошибка при открытии файла для записи Q-таблицы: ", GetLastError()); return false; } // Запись размера таблицы FileWriteInteger(handle, QTableSize); // Запись значений for(int i = 0; i < QTableSize; i++) { FileWriteString(handle, QTable[i].state); FileWriteInteger(handle, QTable[i].action); FileWriteDouble(handle, QTable[i].value); } FileClose(handle); return true; } // Загрузка Q-таблицы из файла bool LoadQTable(string filename) { if(!FileIsExist(filename)) { Print("Файл Q-таблицы не существует: ", filename); return false; } int handle = FileOpen(filename, FILE_READ|FILE_BIN); if(handle == INVALID_HANDLE) { Print("Ошибка при открытии файла для чтения Q-таблицы: ", GetLastError()); return false; } // Чтение размера таблицы int size = FileReadInteger(handle); // Выделение памяти для таблицы if(size > ArraySize(QTable)) { ArrayResize(QTable, size); } // Чтение значений for(int i = 0; i < size; i++) { QTable[i].state = FileReadString(handle); QTable[i].action = FileReadInteger(handle); QTable[i].value = FileReadDouble(handle); QTableSize++; } FileClose(handle); return true; }
Vejamos o teste deste EA. O teste foi realizado com modelagem OHLC em gráficos de 15 minutos, nos pares AUDUSD e EURUSD, cobrindo o período de 2020 a 2025 (o símbolo principal é EURUSD, mas o EA também carrega AUDUSD).
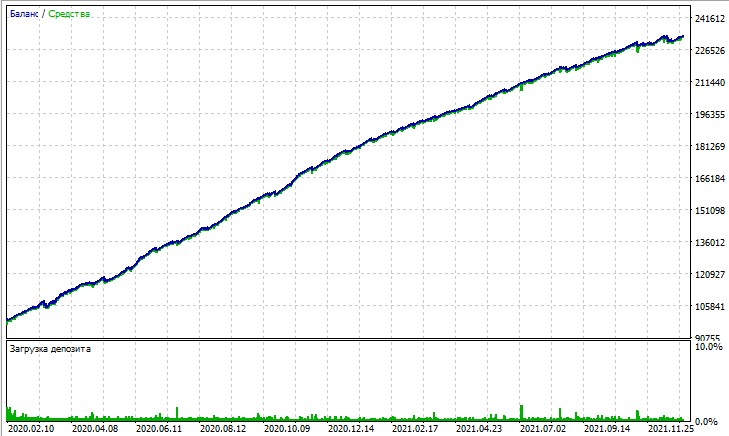
Já o teste em “Todos os ticks” expõe de forma implacável as grandes retrações resultantes do Martingale. Apesar das penalidades, às vezes o modelo entra em uma sequência de operações de média. É possível que, em versões futuras, eliminemos essas retrações utilizando gestão de risco baseada em DQN:
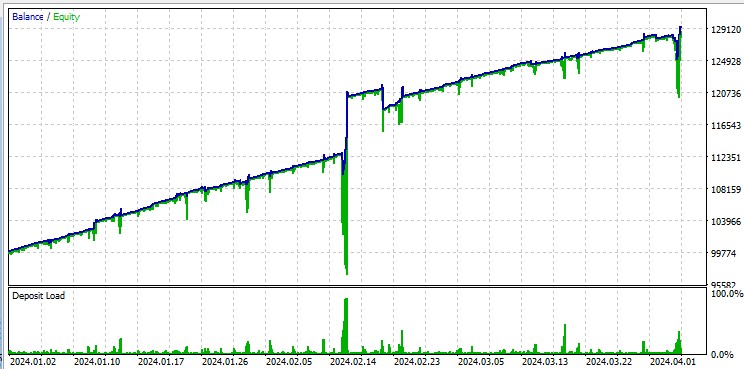
Vale ressaltar que o robô negocia volumes muito altos, o que é útil para gerar rebates de volume pagos pela corretora.
Caminhos para aprimorar o algoritmo
Apesar das melhorias significativas, o Ilan 3.0 AI representa apenas o primeiro passo na evolução dos sistemas de trading inteligentes. As direções promissoras para o desenvolvimento futuro incluem:
- Substituir a tabela Q por uma rede neural completa, capaz de generalizar melhor a experiência
- Implementar algoritmos de aprendizado profundo por reforço (DQN, DDPG, PPO)
- Aplicar técnicas de meta-aprendizado para adaptação rápida a novas condições de mercado
- Integrar o sistema a módulos de análise de notícias e dados fundamentais
Considerações finais
A criação do Ilan 3.0 AI demonstra uma mudança fundamental na abordagem do trading algorítmico. Estamos passando de sistemas estáticos, baseados em regras fixas, para algoritmos adaptativos, capazes de aprender e evoluir continuamente.
A integração da estratégia clássica do Ilan com métodos modernos de aprendizado de máquina abre novos horizontes no desenvolvimento de sistemas de trading. Em vez de uma otimização interminável de parâmetros, estamos criando sistemas capazes de encontrar autonomamente estratégias ideais e se adaptar às condições mutáveis do mercado.
O futuro do trading algorítmico está em abordagens híbridas que combinam estratégias consagradas com métodos inovadores de inteligência artificial. O Ilan 3.0 AI não é apenas uma versão aprimorada do EA clássico, mas uma nova geração de sistemas de trading inteligentes, capazes de aprender, se adaptar e evoluir junto com o mercado.
Estamos à beira de uma nova era no trading algorítmico, uma era de sistemas que não apenas executam regras predefinidas, mas evoluem continuamente, descobrindo estratégias ideais em um mundo financeiro em constante transformação.
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/17455
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Eu o li brevemente - à primeira vista, o artigo é excelente!
é necessário observar e testar diferentes símbolos - quais são os melhores e quais são os piores para serem treinados pelo ilano!
Martin deve muito.
Será interessante obter um produto avançado com uma perspectiva de desenvolvimento.
Olá , Yevgeniy,
Onde está o código de CalculateAveragePrice(symbol)?
E também, como faço para pré-calcular o SL e o TP de um preço médio entre 2 ou mais posições?
Obrigado, Sabino.