
Do básico ao intermediário: Filas, Listas e Árvores (VII)

Introdução
No artigo anterior Do básico ao intermediário: Filas, Listas e Árvores (VI), no artigo anterior foi demonstrado como poderíamos implementar o que seria o mecanismo básico e inicial a fim de construir uma árvore. No final aquele mesmo artigo, permitirmos que o nosso código viesse a utilizar um template, de modo a poder tornar um pouco mais genérico o mecanismo construído ali.
Apesar de muitos de vocês, dificilmente venham a fazer uso massivo e extensivo de uma árvore. Entender os mecanismos envolvidos na implementação de tal sistema de modelagem de dados, permitirá a você conseguir tirar um melhor proveito das funcionalidades do MQL5. Lembrando que aqui, o foco principal estará sendo a didática. Então todo princípio adotado aqui, deve ser pensado a fim de adaptar as coisas as suas necessidades pessoais e voltadas a cada caso específico. Mesmo que em teoria, tudo que vier a ser implementado e mostrado aqui, possa parecer ser válido a todas situações. Pode ocorrer da implementação não ser a mais adequada para seu objetivo particular. Neste caso, o correto entendimento dos conceitos adotados e explicados nos artigos, lhe ajudaram a encontrar o que pode vir a ser a melhor solução ao seu caso.
Muito bem, partindo deste princípio, precisamos entender como efetuar um outro tipo de atividade dentro de uma árvore. Mesmo que você dificilmente venha a de fato fazer uso de tal implementação. Entender como a mesma funciona, poderá lhe ajudar e solucionar outros tipos de problema. No caso, este artigo irá focar inicialmente no problema da remoção de elementos de entro de uma árvore binária.
Se você acha que fazer isto, é uma tarefa simples. Acertou. Porém, sem entender certos conceitos, esta tarefa, que ao meu ver é relativamente simples e fácil de ser implementada, pode acabar se tornando uma grande dor de cabeça para você, meu caro leitor. Ainda mais se você estiver começando a se aprofundar no ramo da programação. Então sem mais delongas, vamos ao que será o tópico principal deste artigo.
Filas, listas e árvores (VII)
Quando o assunto é remover elementos de uma cadeia de elementos, talvez muitos encontrem uma certa dificuldade em efetuar tal atividade. Porém, a despeito do que acontece quando o assunto são filas e listas, onde remover elementos presentes ali, é algo relativamente simples. A mesma coisa não se aplica quando a questão envolve o uso de árvores. Portanto saber exatamente o que acontece durante a remoção de elementos de uma árvore, pode lhe ajudar a entender diversas outras coisas, que serão vistas futuramente. Isto por que, quando vamos eliminar algo de dentro de uma árvore, acabamos em uma situação um tanto quanto engraçada. Que é justamente o fato de fazermos nascer uma segunda árvore, mesmo que de forma temporária.
Para que você consiga compreender como um elemento pode ser removido de dentro de uma árvore e o que acontecerá com a estrutura da árvore. Primeiro preciso que você consiga entender a própria estrutura da árvore, usando para isto a leitura que será impressa no terminal. Como sei que isto pode parecer bastante doido no início, e algo difícil de ser visualizado nas primeiras amostragens de árvores que você estará modelando. Vamos fazer isto com calma e juntos. Assim, a primeira coisa a ser analisada é o próprio código visto no artigo anterior, mas com um pequeno incremento. Este pode ser visto na íntegra logo abaixo.
001. //+------------------------------------------------------------------+ 002. #property copyright "Daniel Jose" 003. //+------------------------------------------------------------------+ 004. template <typename T> 005. class C_TreeNode 006. { 007. private : 008. //+----------------+ 009. T info; 010. C_TreeNode *left, 011. *right; 012. //+----------------+ 013. public : 014. //+----------------+ 015. C_TreeNode() 016. :left(NULL), 017. right(NULL) 018. {} 019. //+----------------+ 020. void SetInfo(T arg) { info = arg; } 021. //+----------------+ 022. void SetLeft(C_TreeNode *ptr) { left = ptr; } 023. //+----------------+ 024. void SetRight(C_TreeNode *ptr) { right = ptr; } 025. //+----------------+ 026. T GetInfo(void) const { return info; } 027. //+----------------+ 028. C_TreeNode *GetLeft(void) const { return left; } 029. //+----------------+ 030. C_TreeNode *GetRight(void) const { return right; } 031. //+----------------+ 032. }; 033. //+------------------------------------------------------------------+ 034. #define C_TreeNode C_TreeNode<T> 035. template <typename T> 036. class C_Tree 037. { 038. //+----------------+ 039. #define def_InfoToString(A) (A != NULL ? StringFormat("%d ", (*A).GetInfo()) : "") 040. enum E_SEQ {eInOrder, ePreOrder, ePostOrder, eDestroy}; 041. //+----------------+ 042. private : 043. C_TreeNode *root; 044. string m_szInfo; 045. //+----------------+ 046. C_TreeNode *Insert(C_TreeNode *arg, C_TreeNode *ptr, T info) 047. { 048. if (ptr == NULL) 049. { 050. ptr = new C_TreeNode; 051. 052. (*ptr).SetInfo(info); 053. if (arg == NULL) return ptr; 054. if (info < (*arg).GetInfo()) (*arg).SetLeft(ptr); 055. else (*arg).SetRight(ptr); 056. 057. return ptr; 058. } 059. if (info < (*ptr).GetInfo()) return Insert(ptr, (*ptr).GetLeft(), info); 060. else return Insert(ptr, (*ptr).GetRight(), info); 061. } 062. //+----------------+ 063. void Seq(C_TreeNode *ptr, const E_SEQ type) 064. { 065. if (ptr == NULL) return; 066. 067. switch (type) 068. { 069. case eInOrder : 070. case ePostOrder : 071. case eDestroy : 072. Seq((*ptr).GetLeft(), type); 073. if (type == eInOrder) break; 074. Seq((*ptr).GetRight(), type); 075. } 076. m_szInfo += def_InfoToString(ptr); 077. switch (type) 078. { 079. case ePreOrder : 080. Seq((*ptr).GetLeft(), type); 081. case eInOrder : 082. Seq((*ptr).GetRight(), type); 083. break; 084. case eDestroy : 085. delete ptr; 086. } 087. } 088. //+----------------+ 089. public : 090. //+----------------+ 091. C_Tree() 092. :root(NULL) 093. {} 094. //+----------------+ 095. ~C_Tree() 096. { 097. Seq(root, eDestroy); 098. } 099. //+----------------+ 100. void Store(T info) 101. { 102. if (root == NULL) root = Insert(root, root, info); 103. else Insert(root, root, info); 104. } 105. //+----------------+ 106. string In_Order(void) 107. { 108. m_szInfo = "In Order: "; 109. Seq(root, eInOrder); 110. 111. return m_szInfo; 112. } 113. //+----------------+ 114. string Pre_Order(void) 115. { 116. m_szInfo = "Pre Order: "; 117. Seq(root, ePreOrder); 118. 119. return m_szInfo; 120. } 121. //+----------------+ 122. string Post_Order(void) 123. { 124. m_szInfo = "Post Order: "; 125. Seq(root, ePostOrder); 126. 127. return m_szInfo; 128. } 129. //+----------------+ 130. #undef def_InfoToString 131. //+----------------+ 132. }; 133. #undef C_TreeNode 134. //+------------------------------------------------------------------+ 135. void OnStart(void) 136. { 137. C_Tree <int> Tree; 138. 139. Tree.Store(10); 140. Tree.Store(-6); 141. Tree.Store(47); 142. Tree.Store(35); 143. Tree.Store(85); 144. Tree.Store(40); 145. 146. Print(Tree.In_Order()); 147. Print(Tree.Pre_Order()); 148. Print(Tree.Post_Order()); 149. } 150. //+------------------------------------------------------------------+
Código 01
Apesar deste código está sendo mostrado na íntegra. O que realmente nos interessa é justamente entender o que as linhas 139 até 144 estão criando. E apesar das linhas 146 até 148 mostrarem dados de um formato linear, preciso que você, meu caro e estima leitor, se esforce um pouco, para tentar entender estes mesmos dados de uma forma um pouco diferente. Onde o resultado a ser visualizado, deverá lhe permitir criar uma representação mental da própria estrutura que está sendo gerada. Em alguns casos, pode ser que venhamos a ter algo semelhante ao o que seria uma lista encadeada. Porém, devido a ordem com que os valores foram adicionados, não iremos criar uma representação de lista, mas sim um outro tipo de coisa. E é justamente isto que quero que você tente visualizar mentalmente. Pois sem conseguir fazer isto, você não irá conseguir de maneira alguma entender como podemos remover algum elemento de uma árvore. Isto sem destruir a própria árvore.
Assim sendo, quando você executar este código 01, irá ver no terminal a saída mostrada na imagem logo abaixo.
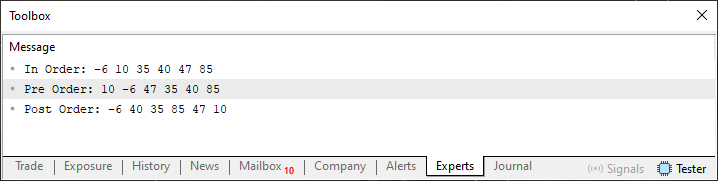
Imagem 01
Agora meu caro leitor, preciso que você foque nesta imagem 01, ao mesmo tempo que montar mentalmente como a saída da função Pre_Order e Post_Order fizeram para gerar esta mesma imagem 01. Mas por que você não está mencionando a saída In_Order? O motivo para isto é simples, meu caro leitor. A saída de In_Order, sempre nos irá mostrar algo parecido com uma lista encadeada ordenada. E como ela não nos ajuda muito, pelo menos não neste cenário. Ela pode ser ignorada.
Ok, vamos primeiro focar na saída da função Post_Order. Esta saída nos informa primeiro os elementos terminais, para somente depois nos mostrar os elementos internos da árvore. Lembre-se de uma coisa: Você NÃO SABE quantos elementos terminais existem na árvore. Você apenas sabe que cada node pode apontar para dois outros elementos. Com isto, sabemos, com toda a certeza, que os dois primeiros dos elementos listados, são de fato elementos terminais. Independentemente de qualquer outra informação. Já que a própria classe C_TreeNode, nos indica que temos duas direções possíveis.
Agora precisamos olhar para a saída da função Pre_Order. Neste caso, a função começa a sua varredura tendo como ponto de partida a raiz da árvore, daí ela vai primeiro para a esquerda até encontrar um elemento terminal. Quando retorna, tomando neste retorno o caminho da direita. Com base nisto, agora sabemos e podemos afirmar uma coisa. O valor 10 é a raiz da árvore, já o valor -6 é um valor terminal. No caso ele está à esquerda do valor presente no node raiz. Isto nos permite gerar, a seguinte imagem vista logo abaixo.
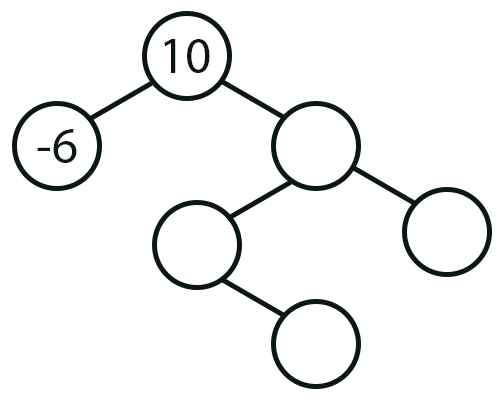
Imagem 02
Ok, já temos algo visível em nossa mente. Agora preciso que você continue este pequeno esforço mental. Isto por que se você observar com calma esta imagem 02, irá notar o seguinte fato. Estes dois valores conhecidos e visíveis na imagem, faz parte de um ramo inteiro da árvore. O que nos falta, pode e deve ser pensado como sendo uma nova árvore. Se você conseguir entender isto, irá conseguir perceber que com base na saída de Pre_Order, o próximo valor será o node raiz desta nova árvore que estaremos visualizando. Sei que parece um tanto quanto estranho dizer isto. Mas você precisa tentar visualizar as coisas de uma maneira não linear.
Muito bem, então se a imagem 02 representa o que foi criado como sendo o ramo a esquerda, e como o valor 10 é a raiz, e a linha 54 nos diz como os nodes serão distribuídos. Podemos afirmar, que a próxima imagem representa o próximo passo, na criação mental da árvore criada pelo código 01.
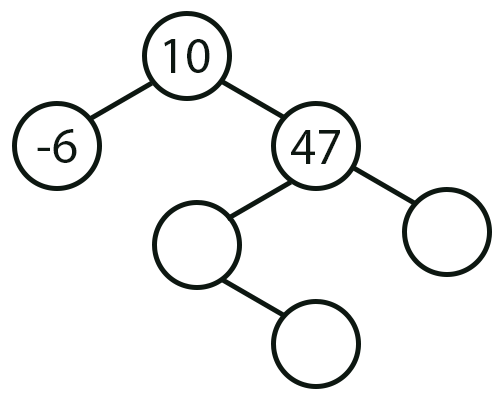
Imagem 03
Ok, isto parece fazer sentido. Mas ainda nos falta completar os demais nodes na imagem 03. Para fazer isto, precisamos recorrer novamente ao resultado impresso pela função Post_Order. Preste atenção. O primeiro valor impresso é -6. Já o segundo valor é 40. Porque? O motivo é que este valor 40 é um valor terminal. Mas espere um pouco, se ele é um valor terminal, pode estar em qualquer um destes nodes vazios da imagem 03, correto? Sim meu caro leitor. Porém, você deve olhar o código da função Post_Order. Ao fazer isto, você irá compreender que Post_Order, irá o mais fundo possível antes de começar a retornar. Sempre indo primeiro para a esquerda e depois para a direita. E é muito importante que você entenda muito bem isto. Pois se esta ordem for invertida o resultado será diferente, quando a função imprimir seu resultado. Assim sendo, tendo como base este conhecimento, podemos afirmar com toda a convicção de que a próxima imagem representa o local onde o elemento cujo valor é 40, deverá estar.
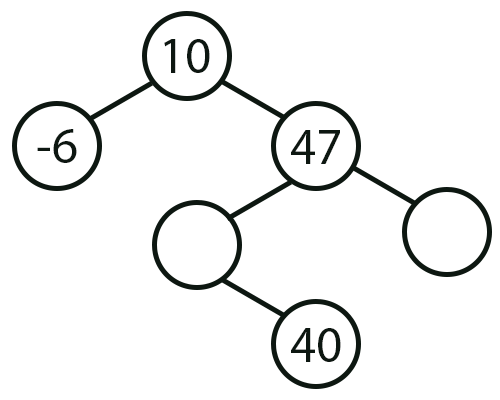
Imagem 04
Bem, agora nos resta dois valores a serem colocados no local correto. E para saber onde eles deverão ser colocados, podemos tanto usar um pouco de lógica, como também a própria imagem 01. Em ambos os casos, teremos no final o que é mostrado logo abaixo. Completando assim o que seria a representação da nossa árvore.
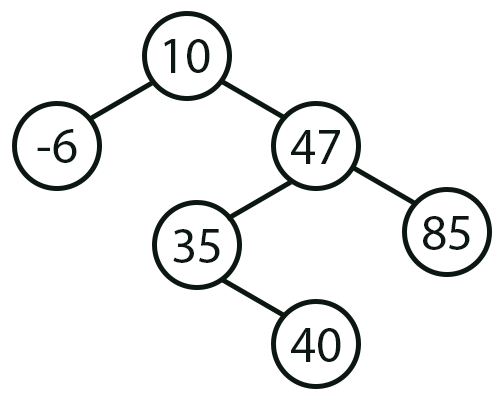
Imagem 05
Legal, se você conseguiu entender como esta imagem 05 foi conseguida, então é sinal que podemos continuar. Porém, toda via e, entretanto, antes de fazermos isto, quero lhe mostrar um pequeno detalhe, suponhamos que a ordem de varredura dentro da árvore venha a ser implementada de maneira diferente. Como pode ser visto no fragmento logo abaixo.
. . . 062. //+----------------+ 063. void Seq(C_TreeNode *ptr, const E_SEQ type) 064. { 065. if (ptr == NULL) return; 066. 067. switch (type) 068. { 069. case ePostOrder : 070. case eDestroy : 071. Seq((*ptr).GetRight(), type); 072. case eInOrder : 073. Seq((*ptr).GetLeft(), type); 074. } 075. m_szInfo += def_InfoToString(ptr); 076. switch (type) 077. { 078. case eInOrder : 079. case ePreOrder : 080. Seq((*ptr).GetRight(), type); 081. if (type == eInOrder) break; 082. Seq((*ptr).GetLeft(), type); 083. break; 084. case eDestroy : 085. delete ptr; 086. } 087. } 088. //+----------------+ . . .
Fragmento 01
Neste caso, o resultado impresso pelo código seria este que você pode visualizar na imagem vista na sequência.
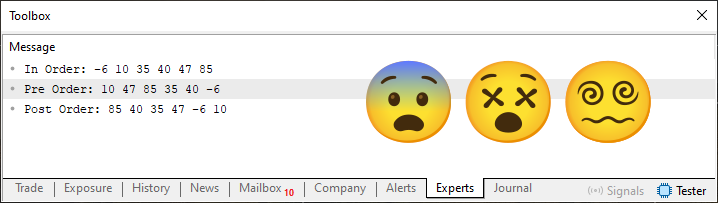
Imagem 06
Observe que neste caso o simples fato de termos modificado o código 01, conforme proposto no fragmento 01. Fez com que o resultado final da varredura fosse a imagem 06. E observe que a diferença no fragmento 01, com o código 01 é muito sutil. Algo que passaria batido se não fosse visto aqui no artigo. Mas agora você já sabe, meu caro leitor, sempre que for analisar algo, procure observar o código fonte junto. Para de fato conseguir ter uma visão mais completa da própria situação analisada.
Maravilha, agora já temos como entender a própria exclusão de algum elemento da árvore. Isto por que, com toda a certeza, você, meu caro leitor, conseguirá interpretar de maneira correta e adequada o que será impresso no terminal. Contudo e apenas para demonstrar de maneira bastante simplista a exclusão de algum node da árvore, vamos remover primeiramente o elemento cujo valor é 47. Ao fazermos isto, teremos dentro do nosso sistema, algo parecido com a imagem logo abaixo.
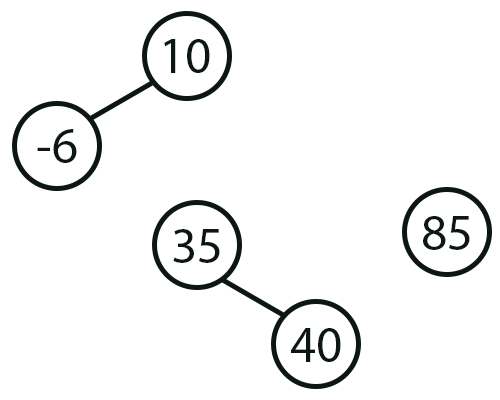
Imagem 07
Caramba, isto si é algo bem sinistro. Pois temos um node raiz cujo valor é 10, assim com teremos uma árvore "solta", cujo node raiz é 35, e um node solto no mundo, com o valor 85. De fato, as coisas irão ficar desta forma, meu caro leitor. Isto se a remoção, do elemento cujo valor é 47, vier a ser feita de qualquer maneira, sem nenhum cuidado ou critério.
Certo, mas como vamos fazer para encontrar este node de valor 47 dentro da árvore? Você ainda não explicou como isto é feito. Hum, é verdade. Ainda não expliquei como encontramos algo dentro da árvore. Falha minha. Me perdoe por isto, meu caro leitor. Então, antes de iniciar a remoção, vamos ver como encontrar algum node especifico dentro da árvore. Isto é algo muito simples e fácil de fazer, tudo que precisamos fazer é adicionar uma pouco de código dentro do procedimento Seq, que está sendo implementado na linha 63. Para tal coisa, iremos utilizar o código visto logo abaixo na íntegra.
001. //+------------------------------------------------------------------+ 002. #property copyright "Daniel Jose" 003. //+------------------------------------------------------------------+ 004. template <typename T> 005. class C_TreeNode 006. { 007. private : 008. //+----------------+ 009. T info; 010. C_TreeNode *left, 011. *right; 012. //+----------------+ 013. public : 014. //+----------------+ 015. C_TreeNode() 016. :left(NULL), 017. right(NULL) 018. {} 019. //+----------------+ 020. void SetInfo(T arg) { info = arg; } 021. //+----------------+ 022. void SetLeft(C_TreeNode *ptr) { left = ptr; } 023. //+----------------+ 024. void SetRight(C_TreeNode *ptr) { right = ptr; } 025. //+----------------+ 026. T GetInfo(void) const { return info; } 027. //+----------------+ 028. C_TreeNode *GetLeft(void) const { return left; } 029. //+----------------+ 030. C_TreeNode *GetRight(void) const { return right; } 031. //+----------------+ 032. }; 033. //+------------------------------------------------------------------+ 034. #define C_TreeNode C_TreeNode<T> 035. template <typename T> 036. class C_Tree 037. { 038. //+----------------+ 039. #define def_InfoToString(A) (A != NULL ? StringFormat("%d ", (*A).GetInfo()) : "") 040. enum E_SEQ {eInOrder, ePreOrder, ePostOrder, eDestroy, eSearch}; 041. //+----------------+ 042. private : 043. C_TreeNode *root; 044. string m_szInfo; 045. //+----------------+ 046. C_TreeNode *Insert(C_TreeNode *arg, C_TreeNode *ptr, T info) 047. { 048. if (ptr == NULL) 049. { 050. ptr = new C_TreeNode; 051. 052. (*ptr).SetInfo(info); 053. if (arg == NULL) return ptr; 054. if (info < (*arg).GetInfo()) (*arg).SetLeft(ptr); 055. else (*arg).SetRight(ptr); 056. 057. return ptr; 058. } 059. if (info < (*ptr).GetInfo()) return Insert(ptr, (*ptr).GetLeft(), info); 060. else return Insert(ptr, (*ptr).GetRight(), info); 061. } 062. //+----------------+ 063. C_TreeNode *Seq(C_TreeNode *ptr, const E_SEQ type, const T info = 0) 064. { 065. if (ptr == NULL) return NULL; 066. 067. switch (type) 068. { 069. case eSearch : 070. while ((ptr != NULL) && ((*ptr).GetInfo() != info)) 071. ptr = (info < (*ptr).GetInfo() ? (*ptr).GetLeft() : (*ptr).GetRight()); 072. return ptr; 073. case eInOrder : 074. case ePostOrder : 075. case eDestroy : 076. Seq((*ptr).GetLeft(), type); 077. if (type == eInOrder) break; 078. Seq((*ptr).GetRight(), type); 079. } 080. m_szInfo += def_InfoToString(ptr); 081. switch (type) 082. { 083. case ePreOrder : 084. Seq((*ptr).GetLeft(), type); 085. case eInOrder : 086. Seq((*ptr).GetRight(), type); 087. break; 088. case eDestroy : 089. delete ptr; 090. } 091. 092. return NULL; 093. } 094. //+----------------+ 095. public : 096. //+----------------+ 097. C_Tree() 098. :root(NULL) 099. {} 100. //+----------------+ 101. ~C_Tree() 102. { 103. Seq(root, eDestroy); 104. } 105. //+----------------+ 106. void Store(T info) 107. { 108. if (root == NULL) root = Insert(root, root, info); 109. else Insert(root, root, info); 110. } 111. //+----------------+ 112. string In_Order(void) 113. { 114. m_szInfo = "In Order: "; 115. Seq(root, eInOrder); 116. 117. return m_szInfo; 118. } 119. //+----------------+ 120. string Pre_Order(void) 121. { 122. m_szInfo = "Pre Order: "; 123. Seq(root, ePreOrder); 124. 125. return m_szInfo; 126. } 127. //+----------------+ 128. string Post_Order(void) 129. { 130. m_szInfo = "Post Order: "; 131. Seq(root, ePostOrder); 132. 133. return m_szInfo; 134. } 135. //+----------------+ 136. void Address(const T info) 137. { 138. Print(info, " information address is: ", Seq(root, eSearch, info)); 139. } 140. //+----------------+ 141. #undef def_InfoToString 142. //+----------------+ 143. }; 144. #undef C_TreeNode 145. //+------------------------------------------------------------------+ 146. void OnStart(void) 147. { 148. C_Tree <int> Tree; 149. 150. Tree.Store(10); 151. Tree.Store(-6); 152. Tree.Store(47); 153. Tree.Store(35); 154. Tree.Store(85); 155. Tree.Store(40); 156. 157. Print(Tree.In_Order()); 158. Print(Tree.Pre_Order()); 159. Print(Tree.Post_Order()); 160. Tree.Address(47); 161. } 162. //+------------------------------------------------------------------+
Código 02
Note que mudamos muito pouco o código 02, frente ao que era o código 01. Sendo que basicamente ocorreu uma mudança na linha 40, onde adicionamos uma nova enumeração e depois a mudança no antigo procedimento da linha 63, que agora passou a ser uma função.
Existe uma coisa aqui nesta função, que acho ser interessante você aprender, meu amigo leitor. Esta coisa está sendo feita na linha 70. Muita gente, principalmente iniciantes não tem muita noção de como um compilador funciona. Talvez futuramente eu venha a explicar isto em detalhes. Ainda estou pensando a este respeito. Talvez seja algo que muitos irão gostar de aprender. Mas ainda estou pensando se compensa falar a este respeito. Se você tem este interesse, deixe nos comentários deste artigo o fato de você se interessar em aprender como um compilador funciona. Se houver um certo número de interessados, irei mostrar isto com o máximo de detalhes possíveis. E de uma forma que será bem interessante, usando MQL5 puro.
Um outro detalhe, que vale também mencionar, é o fato de que na linha 71, estamos simulando a mesma forma de inserir dados na árvore. Repare o fato de que estamos fazendo o mesmo tipo de teste que é feito na linha 59, cujo propósito é adicionar elementos na árvore. Entender isto é importante, pois precisamos seguir um caminho padrão para não ficarmos perdidos dentro da árvore.
Mas vamos continuar, pois quero explicar uma coisa a respeito desta linha 70. Note que aqui temos um laço while sendo executado. O laço em si não nos interessa, o que nos interessa é o teste que está sendo feito.
Preste muita atenção, pois isto que irei mostrar, dá uma verdadeira surra de toalha molhada em todo programador. Em uns mais do que em outros. Perceba o seguinte: Quando a linha 160 for executada, o código irá chamar a linha 136. Esta por sua vez irá carregar a linha 63, com objetivo de encontrar o endereço do valor pedido na linha 160. Até neste ponto, tudo ok. Tanto que ao executar este código você irá ver o resultado mostrado logo abaixo.
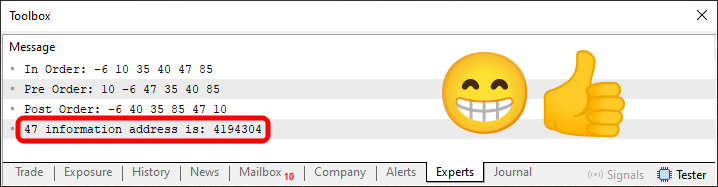
Imagem 08
Agora vem o detalhe. Abra o editor, e dentro deste código 02, que estará no anexo. Mude o valor procurado para algum não presente na árvore. Por exemplo, coloque o valor 50, para ser procurado. O resultado é o que podemos ver logo abaixo.
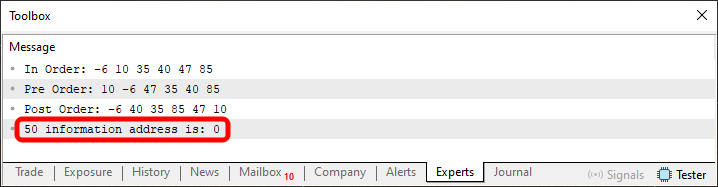
Imagem 09
Até aí tudo certo. Nenhum problema. Mas agora mude a linha 70 para esta mostrada logo abaixo.
while (((*ptr).GetInfo() != info) && (ptr != NULL))
Agora compile novamente o código 02, tendo feito apenas e tão somente esta mudança na linha 70. Ao tentar executar o código, você irá ver o que é mostrado na imagem logo abaixo.
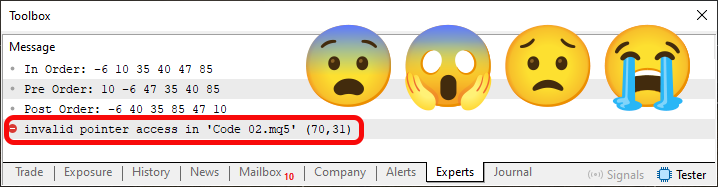
Imagem 10
Mais que foi isto? Cara este tipo de coisa não faz o menor sentido. Você só pode estar é de sacanagem, pois nunca vi este tipo de coisa acontecer comigo. A linha 70 praticamente não mudou e mesmo assim o código falhou? Que coisa mais maluca. Bem meu caro leitor, apesar de você achar que a linha 70 não mudou, ela mudou sim. Isto devido a algumas questões envolvidas durante o procedimento de compilação. Este tipo de coisa é um tanto quanto complicado de explicar na teoria. Mas na prática, vendo como o compilador trabalha, este tipo de coisa passa a fazer total sentido. Então se deseja entender isto em mais detalhes, não se esqueça de comentar neste artigo: "Eu quero entender como um compilador funciona." Assim, saberei se vale ou não a pena criar alguns artigos explicando isto em detalhes.
Mas agora voltando a nossa questão. Já temos com base neste procedimento Address, que foi implementado na linha 136, um mecanismo para encontrar um node específico dentro da árvore. Agora chegou a hora de implementar o código capaz de eliminar um node da árvore.
Para fazer isto, precisaremos implementar algo, que a priori é um tanto quanto confuso. Porém se você entendeu o início deste artigo, irá conseguir compreender perfeitamente bem o que será feito. Certo, e como não quero complicar as coisas, assim de imediato. Já que excluir coisas em uma árvore é diferente de fazer a mesma coisa em uma lista. Vamos começar pelo que seria o caso mais simples, antes de podermos ver um caso um pouco mais elaborado e por consequência mais abrangente. O caso mais simples de todos, envolve remover justamente uma folha da árvore. Mas que história é esta de folha? Você explicou o que seria um node, um ramo e também uma raiz.
No entanto, não falou nada desta coisa de folha. Bem, esta questão referente a folha, para mim acho que seria algo bem natural de entender. Mas de qualquer forma, vamos esclarecer o que seria a tal folha. Uma folha seria um node terminal. Ou seja, um node sem que nenhum ramo saindo dele. Basicamente, seria um ponto no qual aquele ramo em que estamos navegando morreria. Para ficar ainda mais claro, na imagem 05, temos três folhas. Estas são os elementos cujo valores são -6, 40 e 85. Assim acredito que você consiga compreender o que de fato seria uma folha.
Ok, este é o caso mais simples de todos. Então em tese tudo que precisamos fazer será remover este node do sistema. Mas, na prática as coisas não são bem assim. Apenas remover o node folha, acabaria fazendo com que futuras pesquisas ou navegações dentro da árvore viessem a fazer o código quebrar. Isto por que, estaríamos apontando para uma posição invalida na memória.
Como assim? Não entendi esta sua colocação. Calma meu caro leitor, logo você irá entender isto. Mas primeiro vamos implementar um código para conseguir remover as folhas de uma árvore. O código de exemplo pode ser visto na íntegra logo abaixo.
001. //+------------------------------------------------------------------+ 002. #property copyright "Daniel Jose" 003. //+------------------------------------------------------------------+ 004. template <typename T> 005. class C_TreeNode 006. { 007. private : 008. //+----------------+ 009. T info; 010. C_TreeNode *left, 011. *right; 012. //+----------------+ 013. public : 014. //+----------------+ 015. C_TreeNode() 016. :left(NULL), 017. right(NULL) 018. {} 019. //+----------------+ 020. void SetInfo(T arg) { info = arg; } 021. //+----------------+ 022. void SetLeft(C_TreeNode *ptr) { left = ptr; } 023. //+----------------+ 024. void SetRight(C_TreeNode *ptr) { right = ptr; } 025. //+----------------+ 026. T GetInfo(void) const { return info; } 027. //+----------------+ 028. C_TreeNode *GetLeft(void) const { return left; } 029. //+----------------+ 030. C_TreeNode *GetRight(void) const { return right; } 031. //+----------------+ 032. }; 033. //+------------------------------------------------------------------+ 034. #define C_TreeNode C_TreeNode<T> 035. template <typename T> 036. class C_Tree 037. { 038. //+----------------+ 039. #define def_InfoToString(A) (A != NULL ? StringFormat("%d ", (*A).GetInfo()) : "") 040. enum E_SEQ {eInOrder, ePreOrder, ePostOrder, eDestroy, eSearch}; 041. //+----------------+ 042. private : 043. C_TreeNode *root; 044. string m_szInfo; 045. //+----------------+ 046. C_TreeNode *Insert(C_TreeNode *arg, C_TreeNode *ptr, T info) 047. { 048. if (ptr == NULL) 049. { 050. ptr = new C_TreeNode; 051. 052. (*ptr).SetInfo(info); 053. if (arg == NULL) return ptr; 054. if (info < (*arg).GetInfo()) (*arg).SetLeft(ptr); 055. else (*arg).SetRight(ptr); 056. 057. return ptr; 058. } 059. if (info < (*ptr).GetInfo()) return Insert(ptr, (*ptr).GetLeft(), info); 060. else return Insert(ptr, (*ptr).GetRight(), info); 061. } 062. //+----------------+ 063. C_TreeNode *Seq(C_TreeNode *ptr, const E_SEQ type, const T info = 0) 064. { 065. if (ptr == NULL) return NULL; 066. 067. switch (type) 068. { 069. case eSearch : 070. while ((ptr != NULL) && ((*ptr).GetInfo() != info)) 071. ptr = (info < (*ptr).GetInfo() ? (*ptr).GetLeft() : (*ptr).GetRight()); 072. return ptr; 073. case eInOrder : 074. case ePostOrder : 075. case eDestroy : 076. Seq((*ptr).GetLeft(), type); 077. if (type == eInOrder) break; 078. Seq((*ptr).GetRight(), type); 079. } 080. m_szInfo += def_InfoToString(ptr); 081. switch (type) 082. { 083. case ePreOrder : 084. Seq((*ptr).GetLeft(), type); 085. case eInOrder : 086. Seq((*ptr).GetRight(), type); 087. break; 088. case eDestroy : 089. delete ptr; 090. } 091. 092. return NULL; 093. } 094. //+----------------+ 095. public : 096. //+----------------+ 097. C_Tree() 098. :root(NULL) 099. {} 100. //+----------------+ 101. ~C_Tree() 102. { 103. Seq(root, eDestroy); 104. } 105. //+----------------+ 106. void Store(T info) 107. { 108. if (root == NULL) root = Insert(root, root, info); 109. else Insert(root, root, info); 110. } 111. //+----------------+ 112. string In_Order(void) 113. { 114. m_szInfo = "In Order: "; 115. Seq(root, eInOrder); 116. 117. return m_szInfo; 118. } 119. //+----------------+ 120. string Pre_Order(void) 121. { 122. m_szInfo = "Pre Order: "; 123. Seq(root, ePreOrder); 124. 125. return m_szInfo; 126. } 127. //+----------------+ 128. string Post_Order(void) 129. { 130. m_szInfo = "Post Order: "; 131. Seq(root, ePostOrder); 132. 133. return m_szInfo; 134. } 135. //+----------------+ 136. void DeleteNode(const T info) 137. { 138. C_TreeNode *tmp, *ptr = root; 139. 140. for (tmp = NULL; (ptr != NULL) && ((*ptr).GetInfo() != info); tmp = ptr, ptr = (info < (*ptr).GetInfo() ? (*ptr).GetLeft() : (*ptr).GetRight())); 141. 142. if (ptr != NULL) 143. { 144. if ((*ptr).GetLeft() == (*ptr).GetRight()) 145. { 146. if (info < (*tmp).GetInfo()) (*tmp).SetLeft(NULL); 147. else (*tmp).SetRight(NULL); 148. delete ptr; 149. } 150. } 151. } 152. //+----------------+ 153. #undef def_InfoToString 154. //+----------------+ 155. }; 156. #undef C_TreeNode 157. //+------------------------------------------------------------------+ 158. void OnStart(void) 159. { 160. C_Tree <int> Tree; 161. 162. Tree.Store(10); 163. Tree.Store(-6); 164. Tree.Store(47); 165. Tree.Store(35); 166. Tree.Store(85); 167. Tree.Store(40); 168. 169. Print(Tree.In_Order()); 170. Print(Tree.Pre_Order()); 171. Print(Tree.Post_Order()); 172. 173. Tree.DeleteNode(85); 174. Print("----------------"); 175. 176. Print(Tree.In_Order()); 177. Print(Tree.Pre_Order()); 178. Print(Tree.Post_Order()); 179. } 180. //+------------------------------------------------------------------+
Código 03
A remoção de nodes, pode ser feita de diversas maneiras, tanto usando a recursividade, quanto também modelos interativos. Aqui no caso, iremos utilizar um modelo interativo. E o motivo é que utilizar o modelo interativo é um pouco mais rápido, ainda mais por conta que excluir nodes de uma árvore, faz com que ela fique desbalanceada de maneira muito rápida. Prejudicando por meios de degradação da árvore, uma tentativa de usar modelos recursivos de eliminar nodes. Mas vamos entender o que estamos fazendo aqui no código 03.
Quando a linha 173 for executada ela irá chamar a linha 136. Dentro deste procedimento, a primeira coisa que iremos fazer é procurar o valor mencionado dentro da árvore. Mas por que não estamos usando a pesquisa feita pela função Seq? O motivo é que aquela pesquisa não nos informa o node anterior. E precisamos dele para corrigir a árvore.
Perceba o seguinte meu caro leitor. O laço na linha 140, irá efetuar a pesquisa em busca do elemento a ser eliminado. A cada nova posição pesquisada, a anterior é armazenada na variável tmp. Quando a pesquisa finalizar, iremos utilizar a linha 144 para analisar se estamos eliminando uma folha. Caso isto esteja sendo feito, iremos na linha 146 ajustar no node anterior a fim de não mais apontar para o node que estaremos eliminando. Para finalmente na linha 148, eliminarmos o tal node encontrado.
Assim, quando este código 03 for executado, iremos ter como resposta o que é visto logo abaixo.
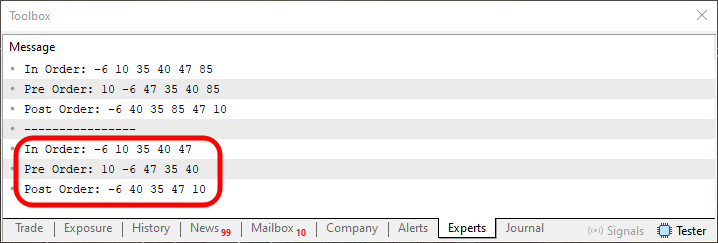
Imagem 11
Agora preste atenção a uma coisa nesta imagem 11, justamente na parte em que estou destacando. Se você observar com atenção irá notar que o elemento indicado na linha 173, não está sendo mostrado nesta região demarcada. Indicando assim que ele foi excluído da árvore. É importante você notar isto, justamente pelo fato de que, usando esta mesma técnica vista no código 03, conseguiremos remover quase todos os nodes da árvore. Isto removendo folha a folha. E digo quase, por que temos um problema, justamente no momento de eliminar o node raiz. Se você tentar eliminar o node raiz usando este código 03, mesmo que ele seja, o único node da árvore, irá fatalmente quebrar o código. Isto devido a tentativa de acesso que está sendo feito na linha 146. Para sanar isto, precisaremos adicionar um teste a fim de evitar uma tentativa de acessar memória inválida.
Ok, agora que você que você entende como o código de exclusão funciona. E de que precisamos ficar observando o node anterior. Podemos organizar o código de uma forma que ele seja bem mais interessante. Tanto pelo ponto de vista prático. Quanto também pelo pronto de vista didático. Então não precisa ficar apavorado que o que será visto logo abaixo, meu caro leitor. Apenas não quero ficar criando bloco a bloco o código. Pois isto acaba deixando as coisas bem chatas.
Assim, fazendo todas as mudanças necessárias no código, temos o que é visto logo abaixo, como sendo o nosso novo código de construção de árvores.
001. //+------------------------------------------------------------------+ 002. #property copyright "Daniel Jose" 003. //+------------------------------------------------------------------+ 004. template <typename T> 005. class C_TreeNode 006. { 007. private : 008. //+----------------+ 009. T info; 010. C_TreeNode *left, 011. *right; 012. //+----------------+ 013. public : 014. //+----------------+ 015. C_TreeNode() 016. :left(NULL), 017. right(NULL) 018. {} 019. //+----------------+ 020. void SetInfo(T arg) { info = arg; } 021. //+----------------+ 022. void SetLeft(C_TreeNode *ptr) { left = ptr; } 023. //+----------------+ 024. void SetRight(C_TreeNode *ptr) { right = ptr; } 025. //+----------------+ 026. T GetInfo(void) const { return info; } 027. //+----------------+ 028. C_TreeNode *GetLeft(void) const { return left; } 029. //+----------------+ 030. C_TreeNode *GetRight(void) const { return right; } 031. //+----------------+ 032. }; 033. //+------------------------------------------------------------------+ 034. #define C_TreeNode C_TreeNode<T> 035. template <typename T> 036. class C_Tree 037. { 038. //+----------------+ 039. #define def_InfoToString(A) (A != NULL ? StringFormat("%d ", (*A).GetInfo()) : "") 040. enum E_SEQ {eInOrder, ePreOrder, ePostOrder, eDestroy}; 041. //+----------------+ 042. private : 043. C_TreeNode *root; 044. string m_szInfo; 045. //+----------------+ 046. C_TreeNode *Insert(C_TreeNode *arg, C_TreeNode *ptr, T info) 047. { 048. if (ptr == NULL) 049. { 050. ptr = new C_TreeNode; 051. 052. (*ptr).SetInfo(info); 053. if (arg == NULL) return ptr; 054. if (info < (*arg).GetInfo()) (*arg).SetLeft(ptr); 055. else (*arg).SetRight(ptr); 056. 057. return ptr; 058. } 059. if (info < (*ptr).GetInfo()) return Insert(ptr, (*ptr).GetLeft(), info); 060. else return Insert(ptr, (*ptr).GetRight(), info); 061. } 062. //+----------------+ 063. C_TreeNode *EraseAndMerge(C_TreeNode *ptr) 064. { 065. C_TreeNode *tmp = ptr; 066. 067. if ((*tmp).GetRight() == NULL) ptr = (*ptr).GetLeft(); 068. else if ((*tmp).GetLeft() == NULL) ptr = (*ptr).GetRight(); 069. else 070. { 071. tmp = (*ptr).GetLeft(); 072. while ((*tmp).GetRight() != NULL) tmp = (*tmp).GetRight(); 073. (*tmp).SetRight((*ptr).GetRight()); 074. tmp = ptr; 075. ptr = (*ptr).GetLeft(); 076. } 077. delete tmp; 078. 079. return ptr; 080. } 081. //+----------------+ 082. void Seq(C_TreeNode *ptr, const E_SEQ type) 083. { 084. if (ptr == NULL) return; 085. 086. switch (type) 087. { 088. case eInOrder : 089. case ePostOrder : 090. case eDestroy : 091. Seq((*ptr).GetLeft(), type); 092. if (type == eInOrder) break; 093. Seq((*ptr).GetRight(), type); 094. } 095. m_szInfo += def_InfoToString(ptr); 096. switch (type) 097. { 098. case ePreOrder : 099. Seq((*ptr).GetLeft(), type); 100. case eInOrder : 101. Seq((*ptr).GetRight(), type); 102. break; 103. case eDestroy : 104. delete ptr; 105. } 106. } 107. //+----------------+ 108. public : 109. //+----------------+ 110. C_Tree() 111. :root(NULL) 112. {} 113. //+----------------+ 114. ~C_Tree() 115. { 116. Seq(root, eDestroy); 117. } 118. //+----------------+ 119. void Store(T info) 120. { 121. if (root == NULL) root = Insert(root, root, info); 122. else Insert(root, root, info); 123. } 124. //+----------------+ 125. string In_Order(void) 126. { 127. m_szInfo = "In Order: "; 128. Seq(root, eInOrder); 129. 130. return m_szInfo; 131. } 132. //+----------------+ 133. string Pre_Order(void) 134. { 135. m_szInfo = "Pre Order: "; 136. Seq(root, ePreOrder); 137. 138. return m_szInfo; 139. } 140. //+----------------+ 141. string Post_Order(void) 142. { 143. m_szInfo = "Post Order: "; 144. Seq(root, ePostOrder); 145. 146. return m_szInfo; 147. } 148. //+----------------+ 149. void DeleteNode(const T info) 150. { 151. C_TreeNode *tmp, *ptr = root; 152. 153. for (tmp = NULL; (ptr != NULL) && ((*ptr).GetInfo() != info); tmp = ptr, ptr = (info < (*ptr).GetInfo() ? (*ptr).GetLeft() : (*ptr).GetRight())); 154. 155. if (ptr != NULL) 156. { 157. if (ptr == root) root = EraseAndMerge(ptr); else 158. { 159. if ((*tmp).GetLeft() == ptr) (*tmp).SetLeft(EraseAndMerge(ptr)); 160. else (*tmp).SetRight(EraseAndMerge(ptr)); 161. } 162. } 163. } 164. //+----------------+ 165. #undef def_InfoToString 166. //+----------------+ 167. }; 168. #undef C_TreeNode 169. //+------------------------------------------------------------------+ 170. void OnStart(void) 171. { 172. C_Tree <int> Tree; 173. 174. Tree.Store(10); 175. Tree.Store(-6); 176. Tree.Store(47); 177. Tree.Store(35); 178. Tree.Store(85); 179. Tree.Store(40); 180. 181. Print(Tree.In_Order()); 182. Print(Tree.Pre_Order()); 183. Print(Tree.Post_Order()); 184. 185. Tree.DeleteNode(10); 186. Print("----------------"); 187. 188. Print(Tree.In_Order()); 189. Print(Tree.Pre_Order()); 190. Print(Tree.Post_Order()); 191. } 192. //+------------------------------------------------------------------+
Código 04
Note que aqui neste código 04, que estará presente no anexo. Fiz a remoção da parte referente a pesquisa dentro da árvore. Isto por que, em um outro momento iremos trabalhar melhor nesta questão da pesquisa. Porém você pode notar que adicionei uma nova função a classe C_Tree. Esta se encontra implementada na linha 63. Agora preste atenção meu caro leitor. Esta função da linha 63, irá ser a responsável por remover qualquer node de dentro da árvore. Ela funciona quase da mesma forma que aquelas poucas linhas vistas no código anterior, onde removíamos a folha. No entanto, aqui já estou postando todos os passos de uma só vez. Já que fazer isto aos poucos, tornaria a explicação muito chata e cansativa.
Observe que o objetivo aqui, é o de recortar o node que será removido, e logo depois unir os ramos de modo a reconstruir a árvore. Não interessa qual node estaremos removendo. A forma de trabalhar será sempre a mesma. Se faz o isolamento do node a ser removido. Logo depois recortamos a árvore de forma que o node a ser removido não seja mais visto. Reconstruímos a árvore e destruímos o node.
Ok, mas, e é justamente este o ponto principal. Esta função não trabalha de forma isolada. Ela na verdade é apenas um sistema de apoio ao procedimento que de fato marca o node a ser removido. Então vamos pular para a linha 149, onde realmente iremos marcar o node a ser removido. Observe que este procedimento continua basicamente da mesma maneira. Apenas mudamos alguns detalhes no mesmo. Veja que agora na linha 157, estaremos verificando se o node a ser removido é a raiz da árvore. Caso seja, iremos usar a função de remodelagem da árvore a fim de remover a raiz atual e criar uma nova.
Caso o node a ser removido, venha a ser qualquer outro, iremos verificar se ele está à esquerda ou à direita do node anterior. Dependendo de que lado o node a ser removido venha a se encontrar, iremos ajustar o node anterior da maneira adequada. Isto de certa forma, se parece bastante com o que foi feito, quando implementamos a remoção de elementos das listas encadeadas. Note que é muito simples e bastante prático. Da mesma maneira que eu disse no início do artigo. Quando falei que o código de exclusão em si, é bem simples. Porém entender como ele funciona não é algo assim tão direto. Por conta disto, precisamos fazer todos estes passos para finalmente chegar neste código 04.
Certo, mas e quanto ao resultado da execução deste código 04? Bem, meu caro leitor, o resultado pode ser visto logo abaixo.
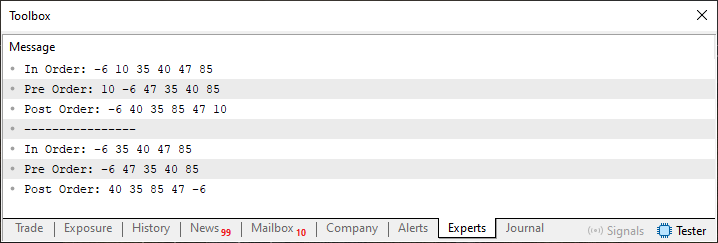
Imagem 12
Agora preste muita atenção, e se ficar na dúvida, volte ao início do artigo a fim de entender o que irei mencionar. Está árvore que você pode observar na imagem 12, é uma árvore que não tem nenhum ramo a esquerda. Isto porque agora ela está completamente desbalanceada. O que torna o processo de pesquisa na árvore uma tarefa um tanto quanto lenta. Mas você pode claramente notar que o node que era a raiz original foi substituído por um outro node, que antes estava à esquerda da raiz original. E como ele era o único node do ramo a esquerda, agora não temos mais nenhum ramo a esquerda.
Considerações finais
Neste artigo, foi possível demonstrar e explicar de uma maneira bastante lucida, como ocorre a remoção de um node de uma árvore. Algo que na maior parte das vezes, mais gera dúvidas e confusão na mente de iniciantes do que necessariamente os ajuda a entender como todo o processo acontece. E por que ele precisa ser feito desta ou daquela maneira.
Como aqui o objetivo, é pura e simplesmente didático. A implementação do código de remoção de node, foi feito utilizando um dentre tantos outros algoritmos focados neste tipo de tarefa. Fica a cargo de leitor procurar estudar outros tipos de mecanismos, que também podem vir a ser utilizados para promover o mesmo tipo de objetivo. Já que dependendo da quantidade de ramos presentes em cada node, este mecanismo mostrando neste artigo, não irá ser o mais adequado. Para isto, existem outros mecanismos muito mais simples e com melhores resultados. Pelo menos no que diz respeito a questão de velocidade de execução.
Lembre-se do seguinte meu caro leitor. Tarefas como excluir e incluir node em uma árvore, podem a tornar desbalanceada. Existem situações em que isto é desejável. Porém em muitas outras, ter uma árvore desbalanceada acaba por nos prejudicar no processo de pesquisar dentro de uma árvore. Por conta disto, removi a parte responsável por pesquisar na árvore. No próximo artigo iremos falar mais a este respeito. Daí você poderá decidir qual o melhor tipo de solução a ser adotada em cada caso.
| Arquivo MQ5 | Descrição |
|---|---|
| Code 01 | Árvore simples |
| Code 02 | Árvore simples |
| Code 03 | Árvore simples |
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso