
Aprendizaje automático en la negociación de tendencias unidireccionales tomando el oro como ejemplo
Introducción
Últimamente, hemos analizado la creación de sistemas comerciales simétricos a través de la lente de la clasificación binaria. Partimos del supuesto de que las operaciones de compra y venta pueden separarse bien en el espacio de características, es decir, que existe algún límite de separación (hiperplano) que permite al algoritmo de aprendizaje automático predecir por igual las posiciones largas y cortas.
En la práctica, no siempre es así, especialmente en el caso de los instrumentos comerciales que siguen tendencias, como algunos metales e índices, así como las criptomonedas. En situaciones en las que un activo tiene una clara tendencia unidireccional, los sistemas comerciales que implican compraventa pueden ser demasiado arriesgados y la distribución global de estas transacciones puede resultar muy asimétrica, lo que provoca una clasificación incorrecta con un gran número de errores.
En este caso, un sistema comercial multidireccional puede no ser eficaz, por lo que sería mejor concentrarse en la negociación unidireccional. Este artículo pretende arrojar luz sobre el poder del aprendizaje automático para crear dichas estrategias unidireccionales.
Le propongo replantear los enfoques de inferencia causal y adaptarlos a la tarea del comercio unidireccional.
Tomaremos como base el material de artículos anteriores:
- Validación cruzada y fundamentos de la inferencia causal
- Inferencia causal en problemas de clasificación de series temporales
- Simulador rápido de estrategias comerciales en Python
Le recomiendo encarecidamente leer estos artículos para comprender mejor la idea de inferencia y comprobación causal.
Creamos un muestreador de operaciones en una dirección determinada
Como antes solíamos colocar operaciones de compra y venta al mismo tiempo, deberemos modificar el marcador de operaciones para que coloque operaciones solo para la dirección seleccionada. A continuación le mostramos un ejemplo del tipo de muestreador utilizado en este artículo:
@njit def calculate_labels_one_direction(close_data, markup, min, max, direction): labels = [] for i in range(len(close_data) - max): rand = random.randint(min, max) curr_pr = close_data[i] future_pr = close_data[i + rand] if direction == "sell": if (future_pr + markup) < curr_pr: labels.append(1.0) else: labels.append(0.0) if direction == "buy": if (future_pr - markup) > curr_pr: labels.append(1.0) else: labels.append(0.0) return labels def get_labels_one_direction(dataset, markup, min = 1, max = 15, direction = 'buy') -> pd.DataFrame: close_data = dataset['close'].values labels = calculate_labels_one_direction(close_data, markup, min, max, direction) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() return dataset
Ahora tenemos un nuevo parámetro 'direction', con el que podremos establecer la dirección necesaria para marcar las operaciones de compra o venta. Ahora la clase etiquetada como "1" indicará que hay una operación para la dirección seleccionada, mientras que la clase etiquetada como "0" indicará que es mejor no abrir una operación en este momento. También en los parámetros podremos establecer la duración aleatoria de la operación en el rango {min, max}, que se medirá en el número de barras pasadas desde el momento de la apertura de la operación. Se trata de un sencillo muestreador que ha demostrado ser bastante eficaz para este tipo de estrategia.
Modificación del simulador de estrategias personalizado
Ahora necesitaremos una lógica de comprobación diferente para las estrategias unidireccionales, por lo que deberemos modificar el propio simulador de estrategias para adaptarlo. En el módulo 'tester_lib.py', añadiremos las funciones para realizar las pruebas unidireccionales. Vamos a verlas con detalle.
La función process_data_one_direction() procesa los datos para negociar en una dirección:
@jit(nopython=True) def process_data_one_direction(close, labels, metalabels, stop, take, markup, forward, backward, direction): last_deal = 2 last_price = 0.0 report = [0.0] chart = [0.0] line_f = 0 line_b = 0 for i in range(len(close)): line_f = len(report) if i <= forward else line_f line_b = len(report) if i <= backward else line_b pred = labels[i] pr = close[i] pred_meta = metalabels[i] # 1 = allow trades if last_deal == 2 and pred_meta == 1: last_price = pr last_deal = 2 if pred < 0.5 else 1 continue if last_deal == 1 and direction == 'buy': if (-markup + (pr - last_price) >= take) or (-markup + (last_price - pr) >= stop): last_deal = 2 profit = -markup + (pr - last_price) report.append(report[-1] + profit) chart.append(chart[-1] + profit) continue if last_deal == 1 and direction == 'sell': if (-markup + (pr - last_price) >= stop) or (-markup + (last_price - pr) >= take): last_deal = 2 profit = -markup + (last_price - pr) report.append(report[-1] + profit) chart.append(chart[-1] + (pr - last_price)) continue # close deals by signals if last_deal == 1 and pred < 0.5 and direction == 'buy': last_deal = 2 profit = -markup + (pr - last_price) report.append(report[-1] + profit) chart.append(chart[-1] + profit) continue if last_deal == 1 and pred < 0.5 and direction == 'sell': last_deal = 2 profit = -markup + (last_price - pr) report.append(report[-1] + profit) chart.append(chart[-1] + (pr - last_price)) continue return np.array(report), np.array(chart), line_f, line_b
La principal diferencia con respecto a la función básica es que ahora las banderas se usarán con una indicación explícita sobre qué tipo de operaciones se utilizarán en el simulador: de compra o de venta. La función será muy rápida gracias a la aceleración con el uso de Numba, y realizará una pasada por la historia de cotizaciones, calculando el beneficio de cada operación. Observe que el simulador es capaz de cerrar operaciones tanto por las señales del modelo como por Stop Loss y Take Profit, dependiendo de qué condición se haya activado antes. Esto permitirá seleccionar modelos ya en la fase de aprendizaje, según su tolerancia al riesgo.
La función tester_one_direction() procesará el conjunto de datos marcado que contiene precios y etiquetas y pasará estos datos a la función process_data_one_direction(), tomando luego el resultado para su posterior dibujado en el gráfico.
def tester_one_direction(*args): ''' This is a fast strategy tester based on numba List of parameters: dataset: must contain first column as 'close' and last columns with "labels" and "meta_labels" stop: stop loss value take: take profit value forward: forward time interval backward: backward time interval markup: markup value direction: buy/sell plot: false/true ''' dataset, stop, take, forward, backward, markup, direction, plot = args forw = dataset.index.get_indexer([forward], method='nearest')[0] backw = dataset.index.get_indexer([backward], method='nearest')[0] close = dataset['close'].to_numpy() labels = dataset['labels'].to_numpy() metalabels = dataset['meta_labels'].to_numpy() report, chart, line_f, line_b = process_data_one_direction(close, labels, metalabels, stop, take, markup, forw, backw, direction) y = report.reshape(-1, 1) X = np.arange(len(report)).reshape(-1, 1) lr = LinearRegression() lr.fit(X, y) l = 1 if lr.coef_[0][0] >= 0 else -1 if plot: plt.plot(report) plt.axvline(x=line_f, color='purple', ls=':', lw=1, label='OOS') plt.axvline(x=line_b, color='red', ls=':', lw=1, label='OOS2') plt.plot(lr.predict(X)) plt.title("Strategy performance R^2 " + str(format(lr.score(X, y) * l, ".2f"))) plt.xlabel("the number of trades") plt.ylabel("cumulative profit in pips") plt.show() return lr.score(X, y) * l
La función test_model_one_direction() recuperará las predicciones del modelo sobre los datos seleccionados. Estas predicciones se pasarán a la función tester_one_direction() para obtener el resultado de la prueba de este modelo.
def test_model_one_direction(dataset: pd.DataFrame, result: list, stop: float, take: float, forward: float, backward: float, markup: float, direction: str, plt = False): ext_dataset = dataset.copy() X = ext_dataset[ext_dataset.columns[1:]] ext_dataset['labels'] = result[0].predict_proba(X)[:,1] ext_dataset['meta_labels'] = result[1].predict_proba(X)[:,1] ext_dataset['labels'] = ext_dataset['labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) ext_dataset['meta_labels'] = ext_dataset['meta_labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) return tester_one_direction(ext_dataset, stop, take, forward, backward, markup, direction, plt)
Meta-learner como corazón del sistema comercial
Ahora veremos el primer meta-learner del artículo de validación cruzada e intentaremos dar una explicación lógica de por qué funciona mejor en el caso de estrategias unidireccionales que en el caso de estrategias multidireccionales.
def meta_learner(folds_number: int, iter: int, depth: int, l_rate: float) -> pd.DataFrame: dataset = get_labels_one_direction(get_features(get_prices()), markup=hyper_params['markup'], min=1, max=15, direction=hyper_params['direction']) data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() X = data[data.columns[1:-2]] y = data['labels'] B_S_B = pd.DatetimeIndex([]) # learn meta model with CV method meta_model = CatBoostClassifier(iterations = iter, max_depth = depth, learning_rate=l_rate, verbose = False) cv = StratifiedKFold(n_splits=folds_number, shuffle=False) predicted = cross_val_predict(meta_model, X, y, method='predict_proba', cv=cv) coreset = X.copy() coreset['labels'] = y coreset['labels_pred'] = [x[0] < 0.5 for x in predicted] coreset['labels_pred'] = coreset['labels_pred'].apply(lambda x: 0 if x < 0.5 else 1) # select bad samples (bad labels indices) diff_negatives = coreset['labels'] != coreset['labels_pred'] B_S_B = B_S_B.append(diff_negatives[diff_negatives == True].index) to_mark = B_S_B.value_counts() marked_idx = to_mark.index data['meta_labels'] = 1.0 data.loc[data.index.isin(marked_idx), 'meta_labels'] = 0.0 data.loc[data.index.isin(marked_idx), 'labels'] = 0.0 return data[data.columns[:]]
Para mayor claridad, a continuación le mostramos un esquema de la función meta-learner en forma de bloques clave responsables de diferentes funcionalidades.
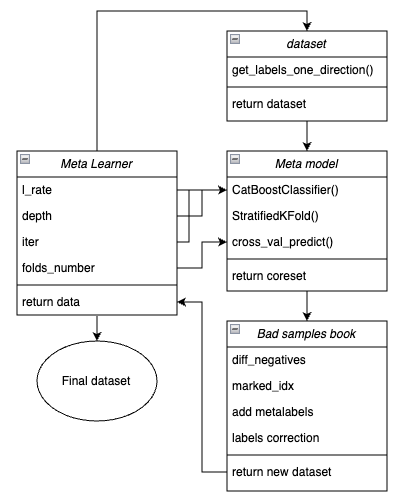
Fig. 1. Representación esquemática de la función meta_learner()
Conviene recordar que el meta-learner es el engranaje intermedio entre los datos de entrada y el modelo final. Se encarga de realizar un preprocesamiento eficaz mediante la creación de metaetiquetas ("meta labels") a través del metamodelado. La singularidad de la función que hemos desarrollado es que crea conjuntos de datos limpios y bien entrenados que producen modelos y sistemas comerciales robustos.
Parámetros de entrada de la función:
- l_rate (learning rate) — paso de gradiente para el metamodelo o clasificador CatBoost. Se ajusta en el rango de {0.01, 0.5}. El algoritmo es sensible a este parámetro.
- depth es responsable de la profundidad de los árboles de decisión construidos en cada iteración del entrenamiento del clasificador CatBoost. El rango de valores recomendado es {1, 6}
- iter — número de iteraciones de entrenamiento, se recomienda el rango {5, 25}
- folds_number — número de pliegues para la validación cruzada. Normalmente basta con {5, 15} pliegues.
Mecanismo de la función:
- Se crea un conjunto de datos con características y etiquetas. La función get_labels_one_direction() descrita anteriormente se usa como muestreador.
- Sobre estos datos, se entrena el meta-learner con los parámetros especificados en el modo de validación cruzada mediante la función StratifiedKFold(). La función divide los datos de entrenamiento en varios pliegues considerando el equilibrio de clases. En cada pliegue, se entrena el metamodelo y luego se almacenan todas las predicciones. Esto es necesario para obtener una estimación no-desplazada de los errores del modelo en los datos de entrenamiento. Estas predicciones se usarán para compararlas con las etiquetas originales.
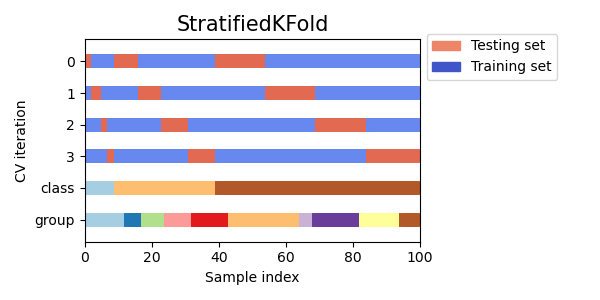
Fig. 2. Esquema de la división de datos en pliegues mediante la función StratifiedKFold()
- Se crea un conjunto de datos central independiente, en el que se registran tanto las etiquetas originales como las predichas mediante validación cruzada.
- Se crea una variable separada diff_negatives que almacena las banderas binarias de las coincidencias entre las etiquetas originales y las pronosticadas.
- Se crea un libro de muestras erróneas B_S_B (Bad Samples Book), en el que se registran los índices temporales de las filas del conjunto de datos cuyas predicciones no coinciden con las etiquetas iniciales.
- Se determinan los índices únicos de ejemplos predichos incorrectamente en todos los pliegues.
- Se crea una columna "meta_labels" adicional en el conjunto de datos de origen y se asigna "1" a todas las observaciones (se puede negociar).
- A todos los ejemplos que se han predicho incorrectamente mediante el proceso de validación cruzada se les asigna un "0" en la columna "meta_labels" (no negociar).
- Para todos los ejemplos pronosticados incorrectamente, la columna "labels", que contiene etiquetas para el modelo básico, también está etiquetada con "0" (no negociar).
- La función retorna el conjunto de datos modificado.
Una inferencia causal más sólida
En la sección anterior, hemos hablado del meta-learner básico, usando un ejemplo con el que es más fácil explicar el concepto básico. En esta sección, complicaremos un poco el enfoque y analizaremos directamente el proceso de inferencia causal en sí. Para el caso del comercio unidireccional, hemos adaptado la función de inferencia causal del artículo enlazado. Es más avanzada y tiene una funcionalidad más flexible.
def meta_learners(models_number: int, iterations: int, depth: int, bad_samples_fraction: float): dataset = get_labels_one_direction(get_features(get_prices()), markup=hyper_params['markup'], min=1, max=15, direction=hyper_params['direction']) data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() X = data[data.columns[1:-2]] y = data['labels'] BAD_WAIT = pd.DatetimeIndex([]) BAD_TRADE = pd.DatetimeIndex([]) for i in range(models_number): X_train, X_val, y_train, y_val = train_test_split( X, y, train_size = 0.5, test_size = 0.5, shuffle = True) # learn debias model with train and validation subsets meta_m = CatBoostClassifier(iterations = iterations, depth = depth, custom_loss = ['Accuracy'], eval_metric = 'Accuracy', verbose = False, use_best_model = True) meta_m.fit(X_train, y_train, eval_set = (X_val, y_val), plot = False) coreset = X.copy() coreset['labels'] = y coreset['labels_pred'] = meta_m.predict_proba(X)[:, 1] coreset['labels_pred'] = coreset['labels_pred'].apply(lambda x: 0 if x < 0.5 else 1) # add bad samples of this iteration (bad labels indices) coreset_w = coreset[coreset['labels']==0] coreset_t = coreset[coreset['labels']==1] diff_negatives_w = coreset_w['labels'] != coreset_w['labels_pred'] diff_negatives_t = coreset_t['labels'] != coreset_t['labels_pred'] BAD_WAIT = BAD_WAIT.append(diff_negatives_w[diff_negatives_w == True].index) BAD_TRADE = BAD_TRADE.append(diff_negatives_t[diff_negatives_t == True].index) to_mark_w = BAD_WAIT.value_counts() to_mark_t = BAD_TRADE.value_counts() marked_idx_w = to_mark_w[to_mark_w > to_mark_w.mean() * bad_samples_fraction].index marked_idx_t = to_mark_t[to_mark_t > to_mark_t.mean() * bad_samples_fraction].index data['meta_labels'] = 1.0 data.loc[data.index.isin(marked_idx_w), 'meta_labels'] = 0.0 data.loc[data.index.isin(marked_idx_t), 'meta_labels'] = 0.0 data.loc[data.index.isin(marked_idx_t), 'labels'] = 0.0 return data[data.columns[:]]
A continuación le mostramos un esquema de la función meta-learner en forma de bloques clave responsables de diferentes funcionalidades.
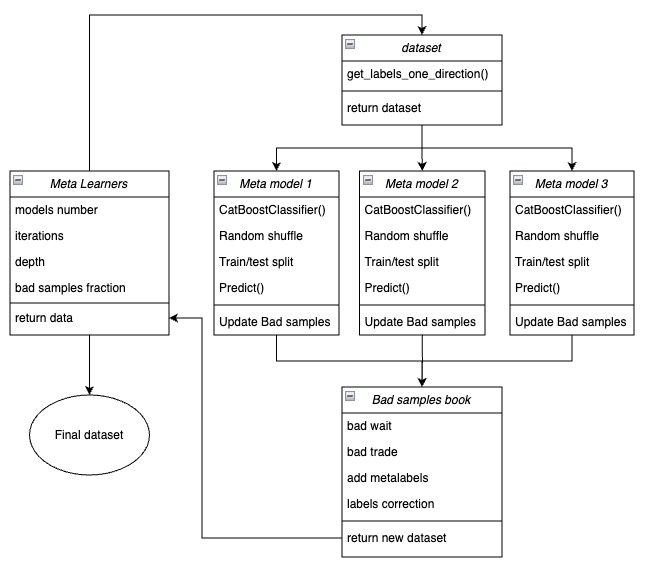
Fig. 3. Representación esquemática de la función meta_learners()
La característica distintiva de esta función es que tiene múltiples "cabezas" de metamodelos que se entrenan con submuestras aleatorias del conjunto de datos original, y que se seleccionan mediante un método bootstrap con retorno. Este método permite generar múltiples submuestras a partir del conjunto de datos original. Las características estadísticas y probabilísticas pueden estimarse a partir de este conjunto de pseudomuestras.
Por ejemplo, nos interesa la media de lo bien que se predice un ejemplo concreto tomado de la población general si entrenáramos modelos en distintas submuestras de esa población. Esto nos dará una visión menos sesgada de cada uno de los ejemplos de la población que podrán etiquetarse como malos o buenos ejemplos con un mayor grado de confianza.
Parámetros de entrada de la función:
- models number — número de metamodelos que se utilizan en el algoritmo. El rango de valores recomendado es {5, 100}
- iterations — número de iteraciones de entrenamiento para cada modelo. Rango de valores recomendado {15, 35}
- depth — profundidad de los árboles de decisión que se construyen en cada iteración del entrenamiento del clasificador CatBoost. El rango de valores recomendado es {1, 6}
- bad samples fraction — número de muestras que se marcarán como "malas". Rango de valores recomendado {0,4, 0,9}
Mecanismo de la función:
- Se crea un conjunto de datos con los atributos y etiquetas de una dirección comercial determinada.
- El ciclo entrena cada uno de los metamodelos con datos de entrenamiento y validación seleccionados aleatoriamente mediante el método bootstrap.
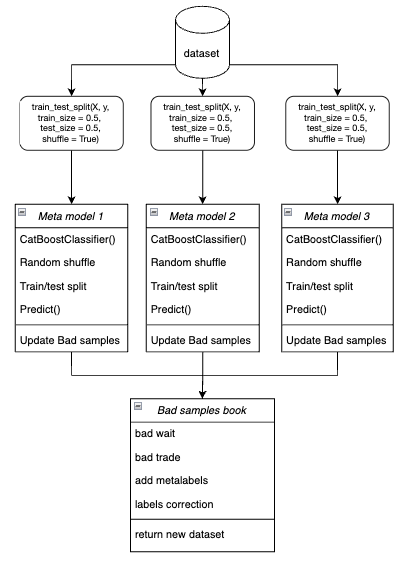
Figura 4. Representación esquemática del muestreo bootstrap
- Para cada modelo, sus predicciones se compararán con las etiquetas verdaderas. Los índices de casos mal clasificados se almacenarán en el libro de ejemplos negativos.
- Se determina el número medio de índices predichos incorrectamente en todas las pasadas.
- Los índices que poseen el mayor número de etiquetas predichas incorrectamente, y que superan la media multiplicada por el umbral, se añadirán a la columna "meta_labels" como ceros (comercio prohibido).
- Las etiquetas 'labels' quedan anuladas por el mismo principio.
Filosofía en la que se basa el uso del meta-learner para la negociación unidireccional:
- El código meta-learner resuelve el problema de filtrado de las señales "malas" en un conjunto de datos marcados.
- Simplificación de la tarea de clasificación. Las características están optimizadas para un solo tipo de patrón (por ejemplo, continuación de tendencia).
- La asimetría se mantiene en la tendencia incluso cuando las clases están equilibradas (50% compras/ 50% ventas). La compra en tendencia presenta pautas más estables, mientras que la venta contra tendencia suele vincularse a acontecimientos ruidosos (correcciones, falsos retrocesos) difíciles de predecir.
- Para vender en una tendencia alcista, la mayoría de las señales resultan inicialmente falsas (falsos positivos), lo cual provoca errores de clasificación. Por consiguiente, en el caso de la negociación multidireccional, las operaciones de compra y venta son de naturaleza distinta y no pueden compararse.
- En un sistema unidireccional, los errores están relacionados únicamente con las entradas falsas en una operación en una tendencia (por ejemplo, la entrada antes de una corrección). El meta-learner encuentra eficazmente estos casos porque tienen señales claras (por ejemplo, sobrecompra). En un sistema multidireccional, los errores incluyen falsas compras y ventas que pueden tener patrones similares. El meta-learner no puede separar de forma fiable el "ruido" de las señales reales porque las señales de compra/venta están mezcladas.
- En un sistema unidireccional, el modelo se centra en un tipo de no estacionariedad (por ejemplo, la intensificación de la tendencia) y los signos se adaptan a la actual fase del mercado.
- En un sistema multidireccional, hay dos no estacionariedades (tendencia + correcciones), lo cual requiere el doble de datos y resulta más difícil de generalizar.
Conclusión:
- La tarea de clasificación se simplifica: basta con predecir correctamente una clase en lugar de dos.
- Se reduce el ruido: el metamodelo final filtra solo un tipo de error.
- La validación cruzada mejora: la estratificación funciona correctamente.
- Se considera la no estacionariedad de la tendencia: el modelo se adapta a una sola fase del mercado.
Una característica importante de los meta-learners:
Los meta-learners no deben confundirse con el metamodelo final, que se entrena con etiquetas entrenadas por los meta-learners. Los meta-learners no son modelos finales y solo se utilizarán en la fase de preprocesamiento. Cualquier algoritmo de clasificación binaria puede usarse como learner básico, incluyendo la regresión logística, las redes de neuronas, los modelos de "árbol" y otros modelos exóticos. Además, es posible usar modelos de regresión con pequeñas modificaciones del código, lo que queda fuera del alcance de este artículo y puede discutirse en otros posteriores. Para mayor comodidad, utilizaremos el clasificador binario CatBoost, ya que el trabajo con él resulta más familiar para nosotros.
Peculiaridades relacionadas con las características para el entrenamiento
Ya hemos dicho que operar en una dirección simplifica la tarea de clasificación. Las características están optimizadas para un solo tipo de patrón (por ejemplo, de compra), por lo que no será necesario que estas sean simétricas. Podemos llamar signos simétricos tanto a la serie temporal inicial con diferentes desfases temporales, cuyos valores corresponden a operaciones de compra y venta, como a diversos derivados (incrementos de precio) y otros osciladores. La volatilidad en diferentes ventanas temporales puede considerarse una característica asimétrica, ya que solo refleja la tasa de variación de los precios, pero no su dirección. Este proyecto usará la volatilidad con diferentes ventanas establecidas en la variable "periods".
Aquí está el código completo que implementa la creación de características:
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC.rolling(i).std() count += 1 return pFixed.dropna()
Y los periodos de ventana deslizante para calcular dichas características se establecen en el diccionario. Podrá cambiarlos arbitrariamente y observar el rendimiento de los modelos.
hyper_params = {
'periods': [i for i in range(5, 300, 30)],
}
En este ejemplo, crearemos 10 características, la primera de las cuales tendrá un periodo de 5, y cada periodo posterior aumentará en 30, y así sucesivamente hasta 300:
>>> [i for i in range(5, 300, 30)] [5, 35, 65, 95, 125, 155, 185, 215, 245, 275]
Entrenamiento y prueba de modelos unidireccionales
hyper_params = {
'symbol': 'XAUUSD_H1',
'export_path': '/drive_c/Program Files/MetaTrader 5/MQL5/Include/Mean reversion/',
'model_number': 0,
'markup': 0.25,
'stop_loss': 10.0000,
'take_profit': 5.0000,
'direction': 'buy',
'periods': [i for i in range(5, 300, 30)],
'backward': datetime(2020, 1, 1),
'forward': datetime(2024, 1, 1),
'full forward': datetime(2026, 1, 1),
}
models = []
for i in range(10):
print('Learn ' + str(i) + ' model')
models.append(fit_final_models(meta_learner(5, 15, 3, 0.1)))
# models.append(fit_final_models(meta_learners(25, 15, 3, 0.8)))Vamos a probar primero el primer meta-learner, y el segundo ya lo comentaremos. Como dirección preferida, elegiremos la dirección de compra, porque el oro se encuentra actualmente en una tendencia alcista. El entrenamiento tendrá lugar desde principios de 2020 hasta 2024, mientras que el periodo de prueba elegido abarcará desde principios de 2024 hasta el 1 de abril de 2025.
El meta-learner tiene los siguientes ajustes:
- 5 pliegues para la validación cruzada
- 15 iteraciones de entrenamiento para el algoritmo CatBoost
- una profundidad del árbol para cada iteración igual a 3
- una tasa de aprendizaje de 0,1
Así es como se ve el mejor modelo en el simulador de estrategias para la dirección 'buy':
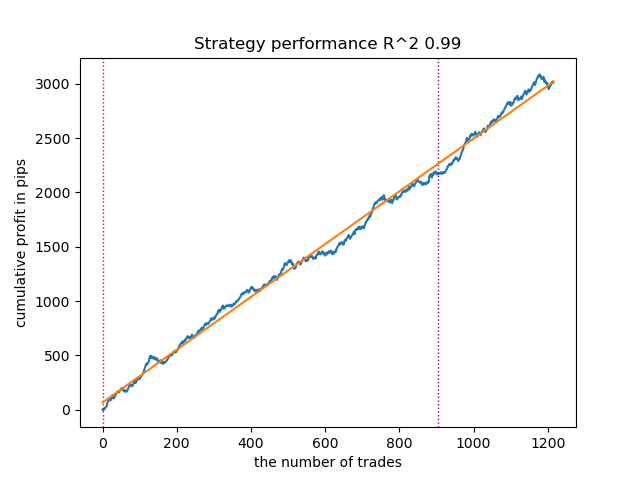
Fig. 5. Resultados de la prueba de las capacidades de la función meta_learner() en la dirección de compra
A modo de comparación, este es el mejor modelo para la dirección "venta":
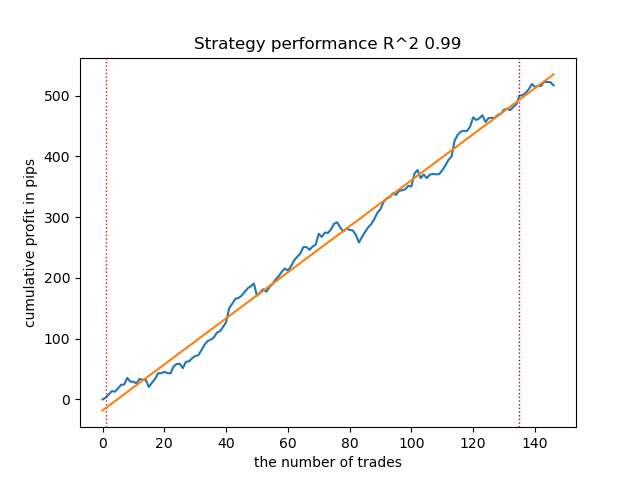
Fig. 6. Resultados de la prueba de las capacidades de la función meta_learner() en la dirección de venta
El algoritmo ha aprendido a predecir operaciones tanto de compra como de venta. Pero en el caso de las ventas, la cantidad de transacciones ha resultado mucho menor, lo que resulta natural en un mercado de tendencia en expansión. El metamodelo ha funcionado con bastante eficacia incluso sin ajustar sus hiperparámetros, lo cual se refleja tanto en la sección de entrenamiento como en la de pruebas forward.
Ahora echemos un vistazo a un meta-learner más avanzado. Haremos manipulaciones similares para la función meta_learners(). La descomentaremos y comentaremos la anterior:
models = [] for i in range(10): print('Learn ' + str(i) + ' model') # models.append(fit_final_models(meta_learner(5, 15, 3, 0.1))) models.append(fit_final_models(meta_learners(25, 15, 3, 0.8)))
El meta-learner tiene los siguientes ajustes:
- 25 "cabezas" o metamodelos
- 15 iteraciones de entrenamiento del algoritmo CatBoost para cada uno de los modelos
- una profundidad del árbol para cada iteración igual a 3
- 0,8 para el parámetro "bad_samples_fraction", que determina el porcentaje de ejemplos malos que permanecen en el conjunto de datos de entrenamiento. 0,1 correspondería a un filtrado muy fuerte, y 0,9 filtraría pocos malos ejemplos.
Así es como se ve el mejor modelo en el simulador de estrategias para la dirección 'buy':
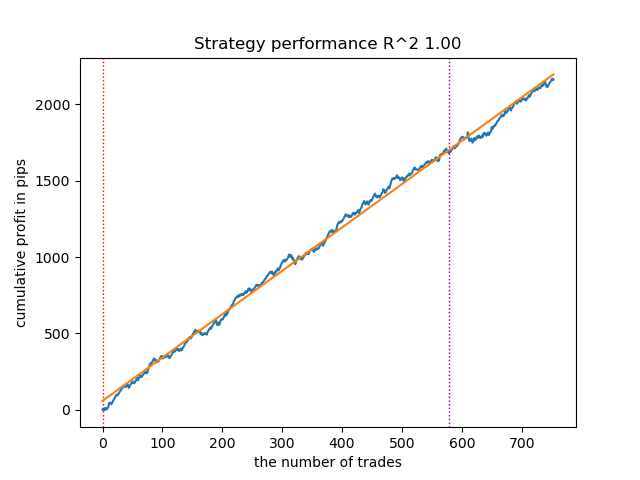
Fig. 7. Resultados de la prueba de las capacidades de meta_learners() en la dirección de compra
A modo de comparación, este es el mejor modelo para la dirección "venta":
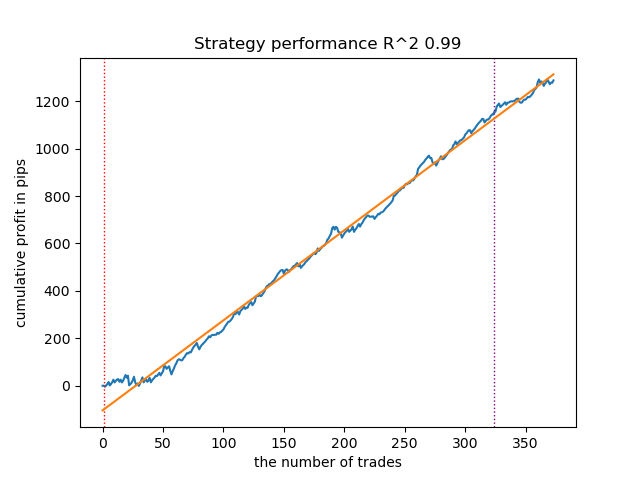
Fig. 8. Resultados de la prueba de las capacidades de la función meta_learners() en la dirección de venta
La función meta-learner, más avanzada, mostraba curvas más bonitas. El balance de las operaciones de compra y venta se ha mantenido. Obviamente, la mejor estrategia es la de compra. Una vez entrenados los modelos y seleccionado el mejor, podemos exportarlos al terminal Meta Trader 5. Se pueden usar ambas estrategias, pero como la estrategia con posiciones cortas es menos eficaz, elegiremos solo la estrategia para posiciones largas.
A continuación le presentamos la tabla de dependencias de los resultados del aprendizaje con respecto a los parámetros del metanálisis avanzado:
| Nombre del parámetro: | Influencia en la calidad de la filtrado: |
|---|---|
| models_number: int | Cuantas más "cabezas" o metamodelos, menos sesgada será la evaluación de los malos ejemplos. El tamaño del conjunto de datos de entrenamiento afectará a la elección del número de modelos. Cuanto más larga sea la historia, más modelos necesitará. Debemos experimentar variando este parámetro entre 5 y 100. |
| iterations: int | Afecta en gran medida a la tasa de filtrado. Cuantas más iteraciones de entrenamiento tenga cada meta-learner, más lento será. Los valores pequeños pueden provocar un subentrenamiento, lo que podría dar lugar a un filtrado más fuerte y a un número reducido de transacciones en la salida. Le recomendamos ajustar entre 5 y 50. |
| depth: int | La profundidad del árbol se establece entre 1 y 6. En cada iteración, el algoritmo completará un árbol de una profundidad determinada. Yo utilizo una profundidad de 3, pero usted puede experimentar con este parámetro. |
| bad_samples_fraction: float | Influye en la selección final de malos ejemplos y el número de transacciones. 0,9 se corresponde con un filtrado "suave" y un gran número de transacciones a la salida. 0,5 se corresponde con un filtrado "duro" y, en consecuencia, con un número reducido de transacciones en la salida. |
Últimos retoques: exportación de modelos y creación de un EA comercial
La exportación de modelos se realiza exactamente de la misma forma que en los demás artículos. Para ello, seleccionaremos nuestro modelo favorito en la lista ordenada de modelos y llamaremos a la función de exportación.
models.sort(key=lambda x: x[0]) data = get_features(get_prices()) test_model_one_direction(data, models[-1][1:], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], hyper_params['direction'], plt=True) export_model_to_ONNX(models[-1], 0)
La lógica del robot comercial se ha cambiado para que solo negocie en una dirección, dependiendo del modelo que hayamos exportado.
input bool direction = true; //True = Buy, False = Sell
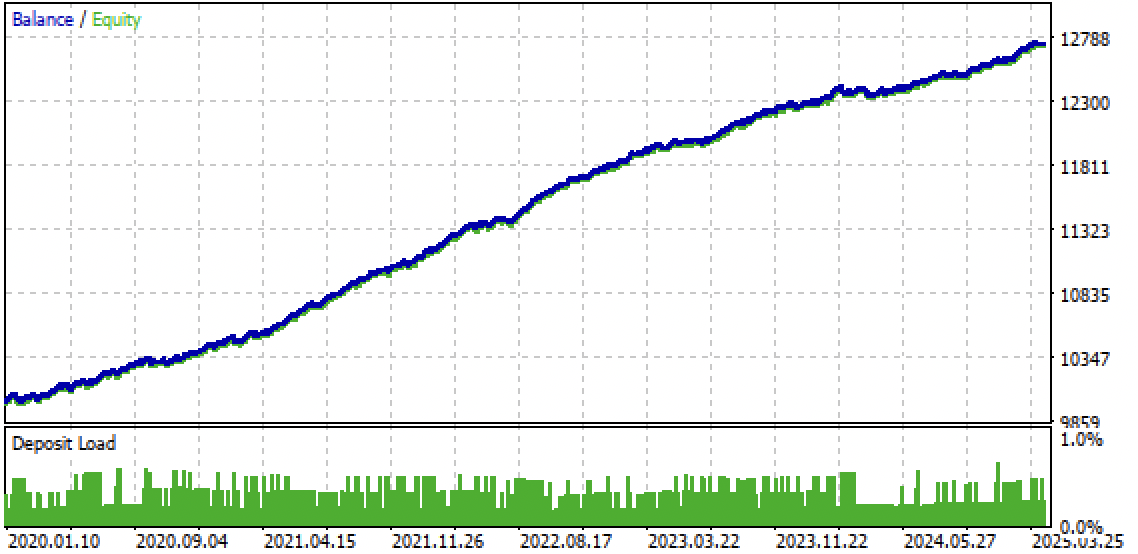
Fig. 9. Probando el bot en el terminal Meta Trader 5
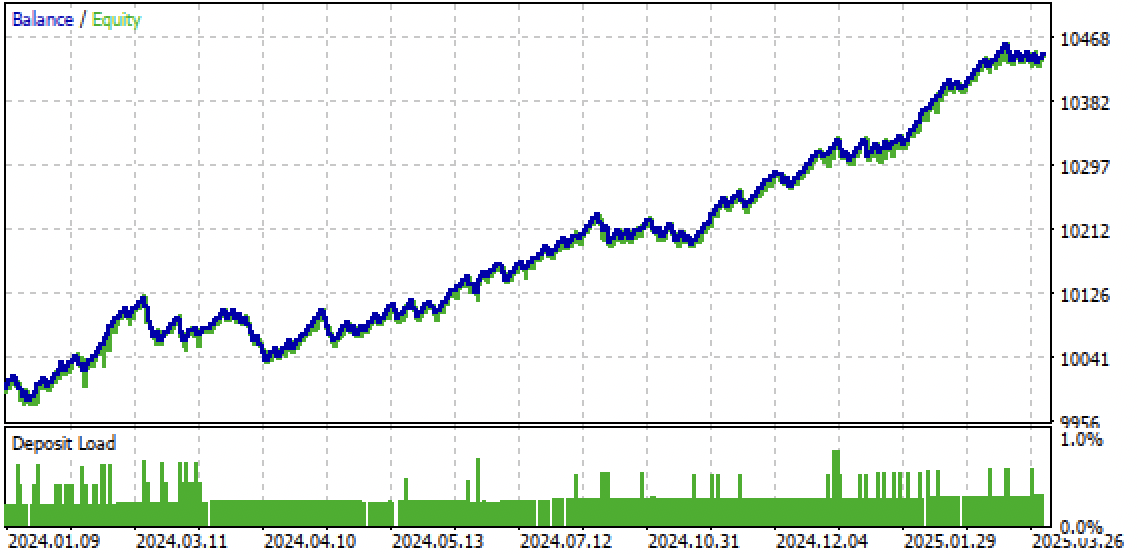
Fig. 10. Pruebas solo en el periodo forward desde principios de 2024
Conclusión
La idea de implementar estrategias unidireccionales con el uso de aprendizaje automático siempre me ha parecido interesante, por eso comencé a realizar una serie de experimentos al respecto, incluido el enfoque propuesto en este artículo. No es la única opción, pero cumple bastante bien con las tareas designadas. Estas estrategias dependientes de la tendencia pueden ofrecer buenos resultados si la tendencia se mantiene. Por ello, es importante observar los cambios de tendencia globales y ajustar dichos sistemas a la situación actual del mercado.
El archivo Python files.zip contiene los siguientes archivos para desarrollar en el entorno Python:
| Nombre del archivo | Descripción |
|---|---|
| causal one direction.py | Script básico para el entrenamiento de modelos |
| labeling_lib.py | Módulo actualizado con marcadores de transacciones |
| tester_lib.py | Simulador personalizado actualizado para estrategias basadas en aprendizaje automático |
| XAUUSD_H1.csv | Archivo con las cotizaciones exportadas desde el terminal MetaTrader 5 |
El archivo MQL5 files.zip contiene archivos para el terminal MetaTrader 5:
| Nombre del archivo | Descripción |
|---|---|
| one direction.ex5 | Bot recopilado de este artículo |
| one direction.mq5 | Bot fuente del artículo |
| la carpeta Include//Trend following | Asimismo, encontrará los modelos ONNX y el archivo de encabezado para conectarse al bot |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/17654
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso