
Redes neurais em trading: Sistema multiagente com confirmação conceitual (Conclusão)

Introdução
No artigo anterior, exploramos os aspectos teóricos do framework FinCon, desenvolvido como uma ferramenta para análise e automação no setor financeiro. Seu objetivo é auxiliar na tomada de decisões nos mercados financeiros, utilizando métodos de processamento de big data, análise de texto (NLP) e gerenciamento de portfólio. A ideia central do sistema é usar uma arquitetura multiagente, em que cada módulo executa tarefas específicas e interage com os demais para alcançar objetivos comuns.
O elemento-chave da arquitetura é o Agente-Gerente, que coordena o trabalho dos Agentes-Analistas. Gerente reúne os resultados do trabalho dos analistas, realiza o controle de riscos e ajusta a estratégia de investimento. No FinCon, são utilizados Analistas especializados, entre os quais são distribuídas as funções de processamento e análise de dados, previsão da dinâmica do mercado e avaliação de riscos. A divisão das tarefas entre os agentes permite reduzir a redundância de informações e acelera o processo de análise.
O framework implementa uma arquitetura de gerenciamento de riscos em dois níveis:
- O primeiro nível atua em tempo real, minimizando perdas de curto prazo.
- O segundo nível analisa as ações do sistema com base em episódios finalizados, ajudando a identificar erros e aprimorar estratégias.
Uma das funções centrais do FinCon é o uso de reforço verbal conceitual (CVRF). Esse mecanismo avalia os resultados do trabalho dos Analistas e as decisões de trading tomadas pelo Gerente. Isso permite que o sistema aprenda com a própria experiência e aperfeiçoe sua política de atuação, concentrando-se nos fatores de mercado mais relevantes.
O framework também inclui um sistema de memória com três níveis:
- A memória de trabalho é responsável pelo armazenamento temporário dos dados usados nas operações em andamento.
- A memória procedural guarda métodos e algoritmos testados, que podem ser reutilizados.
- A memória episódica registra eventos-chave e seus resultados, permitindo analisar experiências anteriores e aplicá-las no futuro.
A visualização original do framework FinCon é apresentada a seguir.

No artigo anterior, iniciamos a implementação da nossa própria visão das abordagens propostas pelos autores do framework. Dentro do objeto CNeuronMemoryDistil, foram construídos os algoritmos de funcionamento do sistema de memória de três níveis. E hoje vamos continuar esse trabalho.
Objeto do Agente-Analista
Hoje vamos começar a construção do módulo do Agente-Analista. Os autores do framework FinCon desenvolveram um módulo universal de agente, que pode atuar em diversas áreas, independentemente da natureza das tarefas executadas. Isso se tornou possível graças ao uso de uma arquitetura baseada em uma grande linguagem modelo pré-treinada (LLM), que opera no formato "pergunta-resposta" (QA). A natureza do trabalho do agente depende da pergunta ou tarefa atribuída a ele.
Embora nossas modelos não utilizem LLM, isso não nos impede de criar um objeto universal que futuramente poderá ser adaptado para executar funções de agentes-analistas com especializações diversas. Essa abordagem garante flexibilidade e modularidade ao sistema.
Segundo a descrição apresentada no trabalho original, os agentes do framework FinCon incluem diversos módulos-chave que se integram para dar suporte à sua funcionalidade.
O módulo de configuração geral e perfilamento exerce um papel importante na definição dos tipos de tarefas a serem resolvidas. Ele não apenas estabelece os objetivos de trading, incluindo detalhes sobre setores da economia e indicadores de ótimo desempenho, mas também distribui funções e responsabilidades entre os agentes. Esse módulo forma uma base textual fundamental, utilizada para gerar as consultas relacionadas à funcionalidade do agente no banco de dados de memória.
Além disso, o módulo de configuração geral e perfilamento ajuda os agentes a se adaptarem a diferentes setores econômicos, determinando as métricas mais importantes para a tarefa em questão. As informações geradas por esse módulo se tornam a base para uma interação correta entre todos os demais componentes do sistema.
O módulo de percepção é responsável por realizar a interação do agente com o ambiente. Ele regula a captação de informações de mercado, filtrando os dados e identificando padrões relevantes. Com isso, o agente consegue se adaptar às condições mutáveis, mantendo-se eficiente e preciso em suas previsões.
O módulo de memória é um componente de importância crítica, pois assegura o armazenamento e o processamento de dados necessários para a tomada de decisão. Ele consiste em três elementos principais: memória de trabalho, memória procedural e memória episódica. A memória de trabalho permite ao agente realizar as tarefas em andamento, monitorando as mudanças no mercado e ajustando suas ações. A memória procedural registra todos os passos tomados pelo agente durante sua atuação, incluindo resultados e conclusões. A memória episódica, por sua vez, armazena dados sobre as tarefas finalizadas e contribui para a formulação de estratégias de longo prazo.
No trabalho anterior, já desenvolvemos o módulo de memória e agora podemos utilizar essa solução pronta. Vale destacar que os autores do framework deram acesso à memória episódica apenas ao Gerente. Em nossa implementação, vamos usar a organização de memória em três níveis para todos os agentes. Porém, cada agente terá seu próprio módulo de memória, o que naturalmente limitará o acesso apenas aos dados relevantes para a tarefa atribuída. Essa abordagem permitirá que o agente leve em consideração não apenas as mudanças recentes, mas também seu contexto dentro de uma perspectiva temporal mais ampla.
A funcionalidade do módulo de configuração geral e perfilamento pressupõe a existência de um objeto especial, que fica fora do agente e gera tarefas levando em conta a especificidade de cada agente e os dados brutos disponíveis. Em nossa implementação, assumimos o uso de dados brutos do mesmo tipo. Isso significa que, com uma função fixa para o agente, em cada etapa de sua atuação serão geradas as mesmas consultas. No entanto, durante o treinamento do modelo, essas consultas podem ser ajustadas para que o agente receba tarefas mais precisas, alinhadas com sua função atual e suas habilidades.
Essas reflexões nos levam à ideia de criar um tensor de consultas treinável dentro do próprio módulo do agente. Essa abordagem elimina a necessidade de um fluxo adicional de informações externas ao agente. Os valores iniciais desse tensor são definidos aleatoriamente durante a inicialização do objeto. Esses parâmetros formam as "capacidades cognitivas inatas" do agente, criando uma base única para seu aprendizado futuro.
Durante o treinamento, o agente gradualmente assume a função que melhor se ajusta às suas habilidades individuais, formadas na fase de inicialização. Isso permite que o agente se adapte de forma orgânica às tarefas atribuídas, utilizando de maneira eficaz suas características "inatas", criando uma base sólida para seu desenvolvimento contínuo. O tensor de consultas treinável torna-se uma ferramenta essencial para identificar e fortalecer a direção de desenvolvimento mais apropriada para o agente. Essa abordagem garante uma coerência entre o estado inicial aleatório e a função-alvo do agente, o que, por sua vez, contribui para a redução dos custos de treinamento do modelo, aumentando sua eficácia geral.
O objetivo principal do módulo de percepção é definir abordagens que ajudem a identificar, dentro do fluxo geral de informações, os padrões mais úteis para a execução das tarefas do agente. Para implementar essa função, podemos utilizar mecanismos de atenção cruzada. Eles permitirão "destacar" os dados mais relevantes, garantindo uma filtragem e um processamento eficazes da informação.
Após analisarmos as questões relacionadas à construção dos módulos internos do agente, é importante focar na análise dos resultados de sua atuação. Um dos pontos centrais aqui é a especificidade dos resultados obtidos. Por um lado, essa especificidade é determinada pelas tarefas atribuídas ao agente, o que vai um pouco contra a ideia de um agente universal. Por outro lado, a diversidade dos resultados dificulta seu processamento, tornando a padronização uma questão extremamente relevante.
Nesta implementação, na saída de cada agente geramos um tensor com a decisão de trading futura. Naturalmente, lembramos que os autores do framework concederam exclusivamente ao Gerente o direito de gerar a decisão de trading. No entanto, nada nos impede de permitir que cada agente apresente suas próprias sugestões. Isso nos permite criar uma estrutura de dados unificada que pode ser usada para descrever os resultados do agente, independentemente de sua função específica. Essa padronização facilita o processamento dos resultados e contribui para o aumento da eficiência geral do sistema.
Todas as abordagens descritas acima serão implementadas dentro do objeto CNeuronFinConAgent, cuja estrutura está apresentada a seguir.
class CNeuronFinConAgent : public CNeuronRelativeCrossAttention { protected: CNeuronMemoryDistil cStatesMemory; CNeuronMemoryDistil cActionsMemory; CNeuronBaseOCL caRole[2]; CNeuronRelativeCrossAttention cStateToRole; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override { return feedForward(NeuronOCL); } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override { return calcInputGradients(NeuronOCL); } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override { return updateInputWeights(NeuronOCL); } public: CNeuronFinConAgent(void) {}; ~CNeuronFinConAgent(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronFinConAgent; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
Na estrutura apresentada, podemos ver o já conhecido conjunto de métodos sobrescrevíveis e alguns objetos que utilizaremos para elaborar as abordagens descritas anteriormente. Conheceremos com mais detalhes a finalidade de cada um desses elementos no processo de implementação dos algoritmos dos métodos desse objeto.
Também vale destacar o uso do objeto de atenção cruzada como classe-pai. Os métodos e objetos herdados dessa forma também serão utilizados para organizar o funcionamento do módulo que estamos criando.
Todos os objetos internos são declarados de forma estática, o que simplifica a estrutura da classe, permitindo manter o construtor e o destrutor vazios. A inicialização de todos os objetos internos e herdados é realizada no método Init. Esse método recebe um conjunto de constantes que permite definir de forma clara e precisa a arquitetura do objeto que está sendo criado.
bool CNeuronFinConAgent::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronRelativeCrossAttention::Init(numOutputs, myIndex, open_cl, 3, window_key, action_space / 3, heads, window, units_count, optimization_type, batch)) return false;
No corpo do método, como sempre, chamamos primeiro o método com o mesmo nome da classe-pai, no qual já está implementado o processo de inicialização dos objetos herdados e das interfaces de troca de dados com objetos externos.
Como mencionado anteriormente, o objeto de atenção cruzada foi escolhido como classe-pai. Tais objetos são projetados para trabalhar com dois fluxos de dados, o que pode levantar dúvidas no contexto do funcionamento dos agentes FinCon. Afinal, eles originalmente operam com um fluxo unitário de informação, necessário para resolver uma tarefa específica. No entanto, é preciso considerar que os agentes também recebem informações do módulo de memória. Isso introduz um segundo fluxo de dados. Além disso, um aspecto importante da atuação do agente é sua sequência de ações e sua capacidade de analisar o próprio comportamento, ajustando-se conforme as condições de mercado mudam. Esse processo reflexivo constitui um terceiro fluxo de informação.
Em nossa implementação, a funcionalidade de reflexão será elaborada usando os mecanismos herdados da classe-pai. Espera-se que as abordagens de atenção cruzada sejam eficazes para ajustar o tensor de resultados anteriores, levando em conta as mudanças nas condições do mercado. Assim, o fluxo de dados principal do objeto pai será representado pelos parâmetros do tensor de resultados, enquanto o segundo fluxo corresponderá às informações sobre o estado atual do ambiente.
Vale lembrar que, na saída do agente, esperamos obter um tensor com as operações de trading recomendadas.
Em seguida, inicializamos dois módulos de atenção. Em cada um deles armazenamos separadamente a dinâmica da situação de mercado e a sequência de decisões de trading sugeridas por esse agente. Isso permitirá uma avaliação mais precisa da eficácia da política de comportamento adotada, dentro da dinâmica atual do mercado.
int index = 0; if(!cStatesMemory.Init(0, index, OpenCL, window, iWindowKey, iUnitsKV, iHeads, stack_size, optimization, iBatch)) return false; index++; if(!cActionsMemory.Init(0, index, OpenCL, iWindow, iWindowKey, iUnits, iHeads, stack_size, optimization, iBatch)) return false;
O módulo de perfilamento será construído a partir de duas camadas densamente conectadas em sequência. A primeira camada contém um único elemento com valor fixo "1", e a segunda camada gera um tensor com tamanho definido. Em nossa implementação, o comprimento do vetor gerado é 10 vezes maior que o comprimento da descrição de um elemento da sequência de entrada. Isso pode ser comparado à descrição do papel do agente por meio de uma sequência com 10 elementos.
index++; if(!caRole[0].Init(10 * iWindow, index, OpenCL, 1, optimization, iBatch)) return false; CBufferFloat *out = caRole[0].getOutput(); if(!out || !out.Fill(1)) return false; index++; if(!caRole[1].Init(0, index, OpenCL, 10 * iWindow, optimization, iBatch)) return false;
O papel do módulo de percepção, como discutido anteriormente, é desempenhado por um objeto interno de atenção cruzada. Ele deve realizar a análise dos dados de entrada recebidos dentro da especificidade do agente.
index++; if(!cStateToRole.Init(0, index, OpenCL, window, iWindowKey, iUnitsKV, iHeads, iWindow, 10, optimization, iBatch)) return false; //--- return true; }
Após a inicialização bem-sucedida de todos os objetos internos e herdados, retornamos um resultado lógico da execução das operações ao programa chamador e encerramos a execução do método.
O próximo passo do nosso trabalho é construir o algoritmo de propagação para frente no método feedForward. Nesse ponto, precisaremos implementar os fluxos de informação entre os objetos que foram inicializados anteriormente.
bool CNeuronFinConAgent::feedForward(CNeuronBaseOCL *NeuronOCL) { if(bTrain && !caRole[1].FeedForward(caRole[0].AsObject())) return false;
Nos parâmetros do método, recebemos um ponteiro para o objeto de dados brutos, que contém as descrições do estado do ambiente. E aqui devemos lembrar que cada agente analisa a informação recebida considerando sua própria especificidade. Por isso, primeiro geramos o tensor que descreve a tarefa atribuída.
Vale observar que o tensor de função do agente é gerado apenas durante o processo de treinamento. Afinal, no modo de teste e na utilização prática do modelo, a especialização do agente permanece fixa, e não há necessidade de gerar novamente esse tensor a cada iteração.
Em seguida, utilizamos o objeto interno de atenção cruzada para destacar os padrões relevantes para a tarefa atribuída ao agente.
if(!cStateToRole.FeedForward(NeuronOCL, caRole[1].getOutput())) return false; if(!cStatesMemory.FeedForward(cStateToRole.AsObject())) return false;
Os valores obtidos são passados ao módulo de memória de estados do ambiente, com o objetivo de enriquecer o estado atual com informações sobre a dinâmica anterior. Essa abordagem proporciona uma compreensão mais profunda do contexto.
Da mesma forma, adicionamos os resultados da propagação para frente anterior ao módulo de memória das ações do agente.
if(!cActionsMemory.FeedForward(this.AsObject())) return false;
Assim, na saída dos dois módulos de memória, são formados os tensores que descrevem as ações mais recentes do agente e as respectivas mudanças no estado do ambiente. Esses dados são transmitidos ao método homônimo da classe-pai, que ajusta o tensor das operações de trading recomendadas, levando em conta a dinâmica atual do mercado.
Antes disso, no entanto, é necessário reorganizar os ponteiros dos buffers de dados, o que permite preservar o tensor de resultados anterior, garantindo a execução correta das operações de propagação reversa durante o treinamento do modelo.
if(!SwapBuffers(Output, PrevOutput)) return false; //--- return CNeuronRelativeCrossAttention::feedForward(cActionsMemory.AsObject(), cStatesMemory.getOutput()); }
O resultado lógico da execução das operações é retornado ao programa chamador e o método é finalizado.
Após a conclusão da implementação do algoritmo de propagação para frente, passamos à realização dos fluxos de informação para a propagação reversa. Como é sabido, o fluxo de dados durante a propagação do gradiente do erro repete a estrutura dos fluxos informacionais da propagação para frente, mas no sentido inverso. Graças à identidade dos caminhos da propagação para frente e reversa, o modelo consegue considerar com eficiência o impacto de cada parâmetro no resultado final.
O método calcInputGradients é responsável pelas operações de distribuição do gradiente de erro. Nos parâmetros do método, recebemos um ponteiro para o objeto de dados brutos, mas agora devemos passar para ele os valores dos gradientes de erro, que representam a influência dos dados brutos sobre o resultado final da execução do modelo.
bool CNeuronFinConAgent::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
No corpo do método, verificamos imediatamente a validade do ponteiro recebido, pois, caso contrário, todas as operações subsequentes perderiam o sentido.
As operações de distribuição do gradiente de erro começam diretamente com a chamada do método de mesmo nome da classe-pai. Esse método repassará os erros para os módulos de atenção.
if(!CNeuronRelativeCrossAttention::calcInputGradients(cActionsMemory.AsObject(), cStatesMemory.getOutput(), cStatesMemory.getGradient(), (ENUM_ACTIVATION)cStatesMemory.Activation())) return false;
Devemos transferir o gradiente de erro para o nosso objeto atual pelo canal do módulo de memória das propostas de operações de trading. Afinal, os resultados da propagação para frente anterior foram utilizados como dados de entrada para esse módulo de memória. Porém, no buffer de resultados já se encontram outros valores, obtidos durante a execução da última propagação para frente. Além disso, queremos preservar os valores atuais do buffer de gradientes de erro. Por isso, primeiro restauramos no buffer de resultados os dados previamente salvos da propagação para frente anterior, substituindo os ponteiros para o objeto do buffer. E, no lugar do ponteiro para o buffer de gradientes de erro, usamos um buffer de dados livre. Somente após a conclusão bem-sucedida dessas etapas preparatórias, procedemos com a distribuição dos gradientes de erro.
CBufferFloat *temp = Gradient; if(!SwapBuffers(Output, PrevOutput) || !SetGradient(cActionsMemory.getPrevOutput(), false)) return false; if(!calcHiddenGradients(cActionsMemory.AsObject())) return false; if(!SwapBuffers(Output, PrevOutput)) return false; Gradient = temp;
Vale destacar que não propagamos o gradiente de erro de forma recorrente para as passagens anteriores. Nesse caso, o gradiente de erro obtido após a execução dessas operações não é utilizado por nós. No entanto, a realização dessas operações é necessária para a distribuição correta dos gradientes de erro entre os objetos internos do módulo de memória. E, após concluir essas ações com sucesso, restauramos os ponteiros para os buffers de dados ao estado original.
Em seguida, devemos distribuir o gradiente de erro pelo canal do módulo de memória dos estados do ambiente. Aqui, primeiramente o encaminhamos até o nível do módulo de percepção, cuja função é desempenhada pelo bloco de atenção cruzada.
if(!cStateToRole.calcHiddenGradients(cStatesMemory.AsObject())) return false;
Depois, distribuímos os erros obtidos entre os dados brutos e o MLP responsável pela geração do tensor de descrição da função do agente, de acordo com a influência de cada um sobre o resultado final do modelo.
if(!NeuronOCL.calcHiddenGradients(cStateToRole.AsObject(), caRole[1].getOutput(), caRole[1].getGradient(), (ENUM_ACTIVATION)caRole[1].Activation())) return false; //--- return true; }
Não distribuímos o gradiente de erro pelo MLP que gera o tensor de descrição da função do agente, pois sua primeira camada contém um valor fixo.
Portanto, após a execução de todas as operações necessárias, o método retorna ao programa chamador o resultado lógico da sua conclusão com sucesso e encerra sua execução.
Com isso, encerramos a análise dos algoritmos de construção dos métodos do objeto universal do Agente-Analista. O código completo da classe apresentada e de todos os seus métodos pode ser consultado por você mesmo no anexo.
Objeto Gerente
A próxima etapa do nosso trabalho é a construção do objeto Agente-Gerente. E aqui surge um pequeno dilema. Por um lado, falamos sobre a criação de um agente universal, que também poderia ser utilizado como gerente. Por outro lado, o gerente reúne os resultados e coordena o trabalho de todos os agentes. Isso significa que ele recebe informações de várias fontes.
A atividade que será descrita a seguir pode ser interpretada de diferentes maneiras. Inclusive, como uma adaptação do agente universal criado anteriormente para a realização das tarefas de gerente. Afinal, foi exatamente a classe do agente universal que usamos como classe-pai ao construir o novo objeto, cuja estrutura está apresentada a seguir.
class CNeuronFinConManager : public CNeuronFinConAgent { protected: CNeuronTransposeOCL cTransposeState; CNeuronFinConAgent caAgents[3]; CNeuronFinConAgent caTrAgents[3]; CNeuronFinConAgent cRiskAgent; CNeuronBaseOCL cConcatenatedAgents; CNeuronBaseOCL cAccount; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override {return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override {return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronFinConManager(void) {}; ~CNeuronFinConManager(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint account_descr, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronFinConManager; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; virtual void TrainMode(bool flag); };
Com o objetivo de minimizar os fluxos de informação externa, incorporamos todos os agentes dentro do nosso gerente. Dessa forma, ele pode ser entendido como a implementação de todo o framework FinCon. Contudo, isso é mais uma questão de percepção subjetiva; aqui, vamos focar no desenvolvimento das funcionalidades do novo objeto.
Na estrutura do novo objeto apresentada acima, podemos ver o já conhecido conjunto de métodos sobrescrevíveis e alguns objetos internos, cuja funcionalidade será explorada durante a criação dos algoritmos dos métodos desta nova classe.
Todos os objetos internos são declarados estaticamente, o que nos permite manter vazios o construtor e o destrutor da classe. A inicialização de todos os objetos declarados e herdados é feita no método Init. Nos parâmetros desse método, recebemos um conjunto de constantes que nos permite identificar de forma inequívoca a arquitetura do objeto que está sendo criado.
bool CNeuronFinConManager::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint account_descr, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronFinConAgent::Init(numOutputs, myIndex, open_cl, action_space, window_key, caAgents.Size() + caTrAgents.Size() + 1, heads, stack_size, action_space, optimization_type, batch)) return false;
No corpo do método, como de costume, chamamos imediatamente o método de mesmo nome da classe-pai. Mas, neste caso, há uma particularidade. Os dados brutos para o gerente são os resultados do trabalho dos agentes. Por isso, como janela de dados brutos, indicamos a dimensionalidade do vetor de resultados de um único agente, e o tamanho da sequência corresponde à quantidade de agentes internos, incluindo o agente de avaliação de riscos.
É importante destacar que nosso gerente vai trabalhar com dois tipos de agentes-analistas. Eles analisarão o estado atual do ambiente em duas projeções diferentes. E, para obter a segunda projeção dos dados brutos, utilizamos um objeto de transposição de matriz.
int index = 0; if(!cTransposeState.Init(0, index, OpenCL, units_count, window, optimization, iBatch)) return false;
Em seguida, fazemos dois ciclos sequenciais de inicialização dos agentes-analistas.
for(uint i = 0; i < caAgents.Size(); i++) { index++; if(!caAgents[i].Init(0, index, OpenCL, window, iWindowKey, units_count, iHeads, stack_size, action_space, optimization, iBatch)) return false; }
for(uint i = 0; i < caTrAgents.Size(); i++) { index++; if(!caTrAgents[i].Init(0, index, OpenCL, units_count, iWindowKey, window, iHeads, stack_size, action_space, optimization, iBatch)) return false; }
E adicionamos o agente de controle de riscos. Para ele, os dados brutos serão representados pelo vetor que descreve o estado atual da conta, o que é refletido nos parâmetros ao chamar o método de inicialização do objeto.
index++; if(!cRiskAgent.Init(0, index, OpenCL, account_descr, iWindowKey, 1, iHeads, stack_size, action_space, optimization, iBatch)) return false;
Além disso, precisaremos de um objeto para concatenar os resultados do trabalho de todos os agentes internos. É com esse objeto que nosso Agente-Gerente irá trabalhar, cuja funcionalidade herdamos da classe-pai.
index++; if(!cConcatenatedAgents.Init(0, index, OpenCL, caAgents.Size()*caAgents[0].Neurons() + caTrAgents.Size()*caTrAgents[0].Neurons() + cRiskAgent.Neurons(), optimization, iBatch)) return false;
Aqui vale destacar que a informação sobre o estado da conta está planejada para ser recebida por meio de um fluxo informacional auxiliar, representado por um buffer de dados. No entanto, para que o agente de controle de riscos inicializado funcione corretamente, é necessário um objeto de camada neural que contenha os dados brutos. Por isso, criamos um objeto interno para o qual transferiremos as informações recebidas pelo segundo fluxo de dados.
index++; if(!cAccount.Init(0, index, OpenCL, account_descr, optimization, iBatch)) return false; //--- return true; }
Após a conclusão de todas as operações descritas acima, o método retorna um resultado lógico que indica o sucesso da execução e encerra sua atividade.
Em seguida, passamos à construção do algoritmo de propagação para frente no método feedForward. Neste caso, estamos lidando com dois fluxos informacionais de dados brutos. Pela via principal, está previsto o recebimento do tensor que descreve o estado analisado do ambiente, e pelo segundo, o resultado financeiro do modelo, na forma de um vetor que representa o estado da conta.
bool CNeuronFinConManager::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(cAccount.getOutput() != SecondInput) { if(!cAccount.SetOutput(SecondInput, true)) return false; }
No corpo do método, primeiramente realizamos uma preparação simples, durante a qual o ponteiro para o buffer de resultados do objeto interno de dados brutos do segundo fluxo (estado da conta) é substituído pelo buffer recebido do respectivo fluxo informacional. Além disso, realizamos a transposição do tensor de dados brutos do fluxo principal de informação.
if(!cTransposeState.FeedForward(NeuronOCL)) return false;
Depois de concluídas as etapas de preparação, transmitimos os dados recebidos aos agentes-analistas para análise e geração de propostas.
//--- Agents for(uint i = 0; i < caAgents.Size(); i++) if(!caAgents[i].FeedForward(NeuronOCL)) return false; for(uint i = 0; i < caTrAgents.Size(); i++) if(!caTrAgents[i].FeedForward(cTransposeState.AsObject())) return false; if(!cRiskAgent.FeedForward(cAccount.AsObject())) return false;
Os resultados do trabalho desses agentes são concatenados em um único objeto.
//--- Concatenate if(!Concat(caAgents[0].getOutput(), caAgents[1].getOutput(), caAgents[2].getOutput(), cRiskAgent.getOutput(), cConcatenatedAgents.getPrevOutput(), Neurons(), Neurons(), Neurons(), Neurons(), 1) || !Concat(caTrAgents[0].getOutput(), caTrAgents[1].getOutput(), caTrAgents[2].getOutput(), cConcatenatedAgents.getPrevOutput(), cConcatenatedAgents.getOutput(), Neurons(), Neurons(), Neurons(), 4 * Neurons(), 1)) return false;
E então, os resultados combinados de todos os agentes são passados ao gerente, que tomará a decisão final sobre as operações de trading a serem realizadas.
//--- Manager return CNeuronFinConAgent::feedForward(cConcatenatedAgents.AsObject()); }
O resultado lógico da execução das operações é retornado ao programa chamador e o método é encerrado.
Com isso, concluímos a análise dos algoritmos de construção dos métodos do nosso Gerente. As operações de propagação reversa, eu sugiro deixar para estudo individual. O código completo da classe apresentada e de todos os seus métodos está disponível no anexo.
Arquitetura do modelo
Algumas palavras sobre a arquitetura do modelo treinável. Durante a preparação deste artigo, foi treinado apenas um modelo do Agente de tomada de decisão de trading. Por favor, não confundir com os agentes do framework FinCon.
A arquitetura do modelo treinável foi transferida praticamente sem alterações a partir dos trabalhos anteriores dedicados ao método FinAgent. Apenas uma camada neural foi substituída, o que permitiu integrar as abordagens implementadas no framework FinCon.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFinConManager; //--- Windows { int temp[] = {BarDescr, 24, AccountDescr, 2 * NActions}; //Window, Stack Size, Account description, N Actions if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = HistoryBars; descr.window_out = 32; descr.step = 4; // Heads descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
O código completo da arquitetura do modelo treinável pode ser encontrado no anexo do artigo. No mesmo local estão os programas utilizados durante o processo de treinamento e teste do modelo. Todos eles foram transferidos sem alterações dos trabalhos anteriores, portanto, não nos deteremos em analisá-los agora.
Testes
As duas últimas partes foram dedicadas ao framework FinCon. Nelas, examinamos detalhadamente os princípios fundamentais do seu funcionamento. Nossa interpretação das abordagens propostas pelos autores do framework foi implementada com recursos do MQL5, e agora chegou o momento de avaliar a eficácia dessas abordagens com dados históricos reais.
É importante observar que a implementação apresentada neste trabalho difere significativamente da original, o que, sem dúvida, afetará os resultados obtidos. Por isso, podemos falar apenas sobre a avaliação da eficácia das abordagens aqui realizadas.
Para o treinamento do modelo, utilizamos dados da paridade EURUSD referentes ao ano de 2024, no timeframe H1. Os parâmetros dos indicadores analisados foram mantidos inalterados, o que nos permitiu focar na análise da eficácia dos algoritmos propriamente ditos.
A base de treinamento foi formada a partir de passagens de várias modelos com parâmetros inicializados aleatoriamente. Além disso, adicionamos passagens bem-sucedidas geradas com base em dados disponíveis de sinais de mercado, utilizando o método Real-ORL. Isso permitiu ampliar a cobertura de possíveis situações de mercado e enriquecer o conjunto de treinamento com exemplos positivos.
Durante o treinamento, aplicamos um algoritmo que permite gerar ações-alvo "quase perfeitas" para treinar o Agente. Essa abordagem possibilita o treinamento do modelo sem a necessidade de atualizações constantes da base de treinamento. No entanto, recomendamos atualizar regularmente os dados, o que pode melhorar ainda mais os resultados do aprendizado, ampliando a variedade de estados cobertos.
O teste final foi realizado com os dados disponíveis de janeiro de 2025, mantendo todos os demais parâmetros inalterados. Os resultados do teste estão apresentados abaixo.
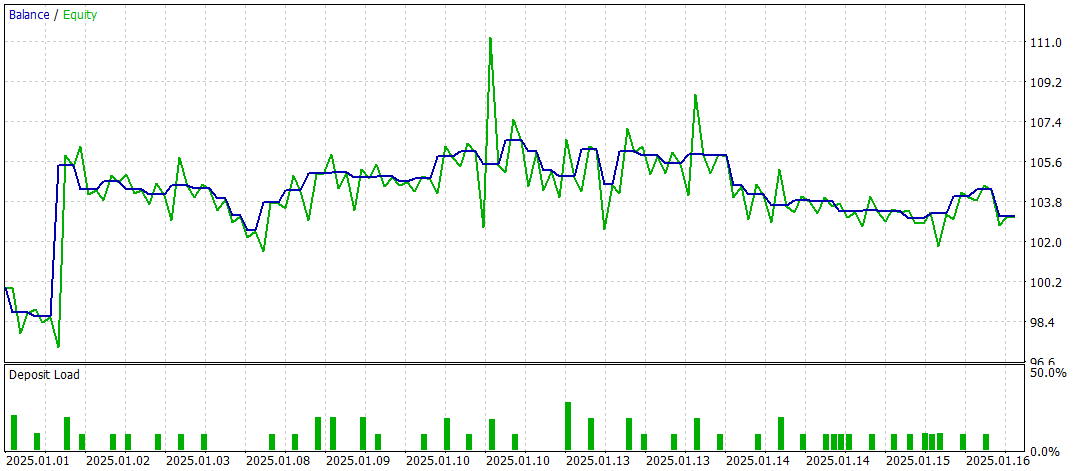
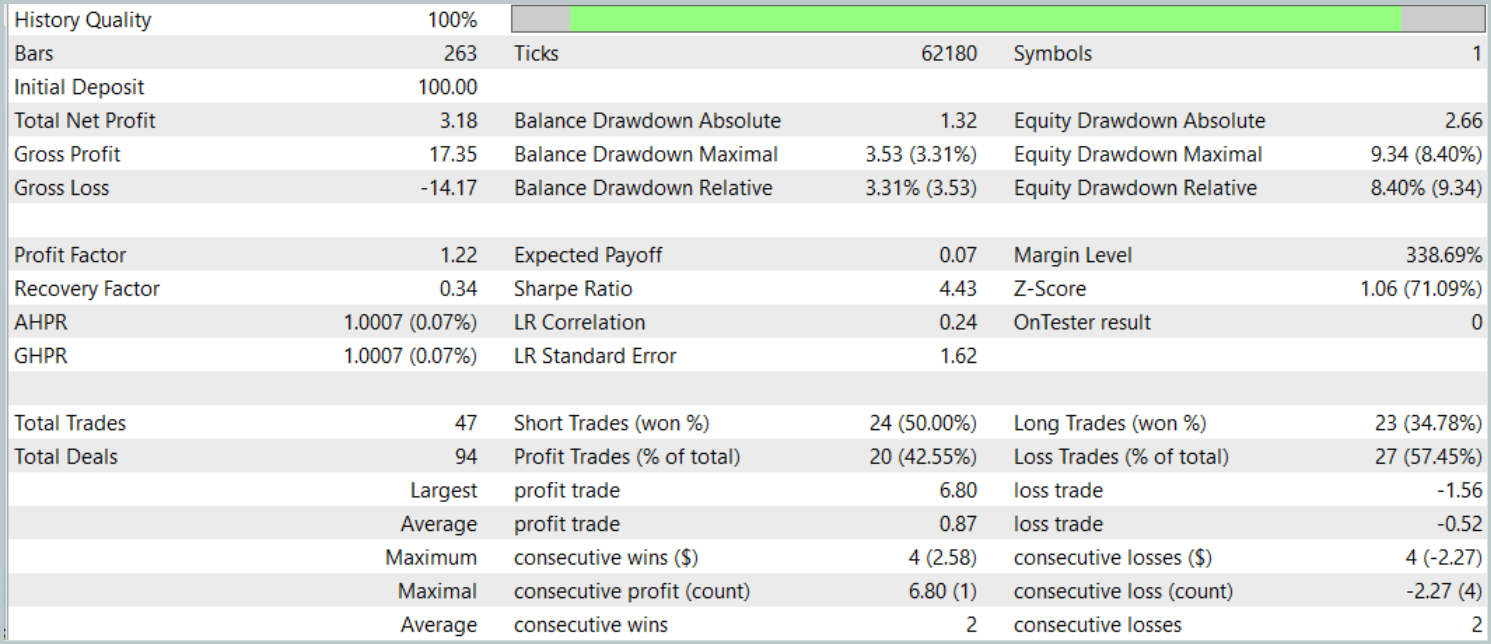
Os resultados dos testes oferecem uma visão ambígua sobre a eficácia do modelo. Durante o período testado, foi possível obter lucro com 47 operações de trading realizadas, mas apenas 42% delas foram bem-sucedidas. Além disso, o crescimento significativo do saldo ocorreu graças a apenas uma operação bem-sucedida, enquanto no restante do tempo a curva de saldo permaneceu dentro de uma faixa estreita. Isso indica a necessidade de otimizar ainda mais o modelo.
Considerações finais
Neste artigo, examinamos os principais componentes e as funcionalidades do framework FinCon, bem como suas vantagens na automatização e otimização da tomada de decisões de trading. Na parte prática, implementamos as abordagens propostas utilizando MQL5. Construímos e treinamos o modelo com dados históricos reais. No entanto, os resultados dos testes mostram que o modelo ainda exige otimização adicional para alcançar resultados mais estáveis e elevados.
Links
- FinCon: A Synthesized LLM Multi-Agent System with Conceptual Verbal Reinforcement for Enhanced Financial Decision Making
- Outros artigos da série
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA de coleta de exemplos |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA de coleta de exemplos com o método Real-ORL |
| 3 | Study.mq5 | Expert Advisor | EA de treinamento de modelos |
| 4 | Test.mq5 | Expert Advisor | EA para testes do modelo |
| 5 | Trajectory.mqh | Biblioteca de classe | Estrutura para descrever o estado do sistema e arquitetura dos modelos |
| 6 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de rede neural |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca com código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/16937
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso