
Redes neuronales en el trading: Aprendizaje contextual aumentado por memoria (Final)

Introducción
En el artículo anterior, nos familiarizamos con el framework MacroHFT, desarrollado para el trading de alta frecuencia (HFT) con criptomonedas. Este framework supone un enfoque de vanguardia que combina técnicas de aprendizaje por refuerzo dependientes del contexto con el uso de memoria para adaptarse eficazmente a las condiciones dinámicas del mercado y minimizar el riesgo.
El principio de funcionamiento del MacroHFT se basa en dos etapas de entrenamiento de sus componentes individuales. La primera es la clasificación de los estados del mercado según la dirección de la tendencia y el nivel de la volatilidad. Este proceso pone de relieve las condiciones clave del mercado, que luego se usan para formar a subagentes especializados. Cada subagente está optimizado para funcionar en escenarios concretos. La segunda etapa consiste en entrenar a un hiperagente dotado de un módulo de memoria que coordina el trabajo de los subagentes. Este módulo considera los datos históricos y permite tomar decisiones más precisas basándose en la experiencia previa.
La arquitectura de MacroHFT incluye varios componentes clave. El primero de ellos es el módulo de preprocesamiento de datos, que realiza el filtrado y la normalización de la información de mercado entrante. Esto elimina el ruido y mejora la calidad de los datos, lo que resulta fundamental para los análisis posteriores.
Los subagentes son modelos de aprendizaje profundo entrenados en escenarios de mercado específicos. Estos usan técnicas de aprendizaje por refuerzo para adaptarse a entornos complejos y rápidamente cambiantes. El último elemento es un hiperagente con memoria, que integra el rendimiento de los subagentes analizando la historia de eventos y las condiciones actuales del mercado. Gracias a esto, se alcanza una gran precisión en las previsiones y una resistencia notable a los picos del mercado.
La integración de todos estos componentes permite a MacroHFT no solo funcionar eficazmente en mercados muy volátiles, sino también lograr mejoras significativas de la rentabilidad.
A continuación le mostramos la visualización del framework MacroHFT por parte del autor.
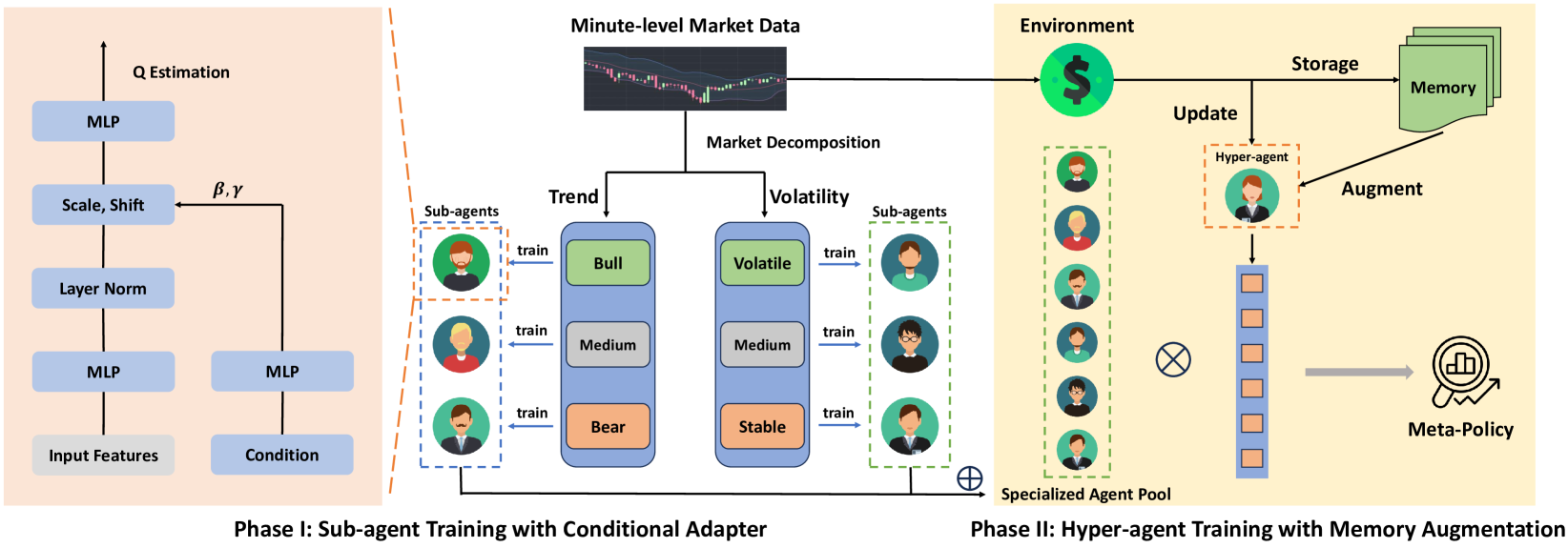
En la parte práctica del artículo anterior, creamos un objeto de hiperagente e implementamos un algoritmo para su interacción con los subagentes. Hoy proseguiremos el trabajo iniciado centrándonos en nuevos aspectos de la arquitectura de MacroHFT.
Módulo de gestión de riesgos
En el artículo anterior organizamos el hiperagente como un objeto CNeuronMacroHFTHyperAgent y desarrollamos los algoritmos para su interacción con los subagentes. Además, decidimos usar como subagentes los agentes analistas creados previamente con una arquitectura más compleja. A primera vista, esto parece suficiente para implementar el framework MacroHFT, pero la implementación actual tiene ciertas limitaciones: los subagentes y el hiperagente analizan exclusivamente el estado del entorno. Esto permite prever los movimientos futuros de los precios, determinar la dirección de las transacciones y fijar los niveles de stop loss y take profit. Sin embargo, este enfoque no abarca la determinación del volumen comercial, que es un elemento importante de la estrategia global.
Usar simplemente un tamaño de transacción fijo, o calcular el volumen según un nivel de riesgo fijo, considerando un stop loss previsto y los fondos disponibles en la cuenta, resulta ciertamente posible. No obstante, debemos considerar que cada previsión tiene un nivel de confianza individual en su realización. Lógicamente, este nivel de confianza debería desempeñar un papel clave a la hora de determinar el tamaño de la transacción. Un alto nivel de confianza en el pronóstico permite abrir transacciones con un gran volumen, lo cual ayuda a maximizar la rentabilidad global de la transacción, mientras que un bajo nivel de confianza sugiere un enfoque más conservador.
Teniendo en cuenta estos factores, hemos decidido completar la aplicación con un módulo de gestión de riesgos. Este módulo se integrará en la arquitectura existente para proporcionar un enfoque flexible y adaptable a la gestión del volumen de transacciones. La introducción de la gestión de riesgos mejorará la robustez del modelo antes las condiciones volátiles del mercado, lo cual resulta especialmente importante en un entorno comercial de alta frecuencia.
Cabe señalar que en este caso estamos aplicando un algoritmo de gestión de riesgos parcialmente "desvinculado" del análisis del entorno inmediato. En su lugar, la atención se centrará en evaluar el impacto de las acciones del agente en el resultado financiero. La idea consiste en relacionar cada operación con el cambio en el balance de la cuenta e identificar patrones que caractericen la eficacia de la política. Se espera que el aumento del número de transacciones rentables, unido a un crecimiento constante del balance, sean indicadores del éxito de la política actual, lo que a su vez permitirá un aumento razonable del nivel de riesgo por transacción. Al mismo tiempo, un aumento de la proporción de transacciones perdedoras será una señal para utilizar estrategias más conservadoras destinadas a reducir los riesgos. Este enfoque no solo nos permitirá adaptarnos mejor a las cambiantes condiciones del mercado, sino que también mejorará la eficiencia general de la gestión del capital. Además, para mejorar la calidad del análisis, prepararemos varias proyecciones del estado de la cuenta, cada una de las cuales representará distintos aspectos del estado actual e histórico de la cuenta. Esto permitirá evaluar con mayor precisión la eficacia de la estrategia y adaptarla rápidamente a la evolución de las condiciones del mercado.
Implementaremos el algoritmo de gestión de riesgos dentro del objeto CNeuronMacroHFTvsRiskManager, cuya estructura se muestra a continuación.
class CNeuronMacroHFTvsRiskManager : public CResidualConv { protected: CNeuronBaseOCL caAccountProjection[2]; CNeuronMemoryDistil cMemoryAccount; CNeuronMemoryDistil cMemoryAction; CNeuronRelativeCrossAttention cCrossAttention; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronMacroHFTvsRiskManager(void) {}; ~CNeuronMacroHFTvsRiskManager(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint nactions, uint account_decr, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronMacroHFTvsRiskManager; } //--- virtual bool Save(const int file_handle) override; virtual bool Load(const int file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
En la estructura presentada se puede observar un conjunto estándar de métodos redefinidos y varios objetos internos que desempeñan un papel clave en la aplicación del mecanismo de gestión de riesgos descrito anteriormente. La funcionalidad de los objetos declarados se analizará con más detalle al describir los algoritmos de los métodos de clase, lo que permitirá comprender más profundamente su lógica de uso.
Todos los objetos internos de nuestra clase de gestión de riesgos se declaran como estáticos, lo cual nos permitirá simplificar considerablemente la estructura de objetos. En particular, esto permitirá dejar el constructor y el destructor vacíos, ya que estos no requieren operaciones adicionales para inicializar o borrar la memoria asociada a estos objetos. La inicialización de todos los objetos heredados y declarados se implementa en el método Init, encargado de configurar la arquitectura de la clase cuando esta se crea.
En los parámetros de esta clase, obtenemos una serie de constantes que nos permitirán interpretar sin ambigüedades la arquitectura del objeto que se está creando.
bool CNeuronMacroHFTvsRiskManager::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint nactions, uint account_decr, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CResidualConv::Init(numOutputs, myIndex, open_cl, 3, 3, (nactions + 2) / 3, optimization_type, batch)) return false;
En el cuerpo del método, llamaremos inmediatamente al método homónimo de la clase padre. En este caso, se trata de un objeto de bloque convolucional con retroalimentación. Debemos señalar que en la salida de este módulo esperamos obtener un tensor que represente una matriz de decisiones comerciales. Cada fila de esta matriz describe una operación independiente y contiene un vector con los parámetros de la operación: volumen, stop loss y take profit. Para organizar adecuadamente el análisis de las transacciones, trataremos las transacciones de compra y venta como líneas separadas, lo que nos permitirá analizar cada operación de forma independiente.
Al organizar el trabajo de las transacciones convolucionales, el tamaño de la ventana convolucional y su paso se fijarán en 3, que corresponderá al número de parámetros de la descripción de la transacción comercial.
A continuación, veremos el proceso de inicialización de los objetos internos. Aquí debemos señalar que el módulo de gestión de riesgos se basa en dos fuentes de datos clave: las acciones de los agentes y el vector de descripción del estado de la cuenta analizado. El flujo principal de información representado por las acciones del agente se presentará como objeto de capa neuronal. A través del búfer de datos se transmitirá un flujo secundario con una descripción del estado de la cuenta.
Para garantizar que todos los componentes internos funcionen correctamente, ambos flujos de datos deberán estar representados por objetos de capas neuronales. Por ello, el primer paso consistirá en inicializar una capa neuronal totalmente conectada a la que transferiremos los datos del segundo flujo de información.
int index = 0; if(!caAccountProjection[0].Init(0, index, OpenCL, account_decr, optimization, iBatch)) return false;
El siguiente paso será añadir una capa completamente conectada diseñada para formar proyecciones de la descripción del estado de la cuenta resultante. Esta capa de aprendizaje genera un tensor que contendrá varias proyecciones del estado de la cuenta analizado en subespacios de una dimensionalidad determinada. El número de proyecciones y la dimensionalidad de los subespacios se transmitirán en los parámetros del método desde el programa que realiza la llamada, lo que posibilitará el ajuste flexible del funcionamiento de las capas para diferentes tareas.
index++; if(!caAccountProjection[1].Init(0, index, OpenCL, window * units_count, optimization, iBatch)) return false;
Los datos de entrada que recibe el módulo de gestión de riesgos solo ofrecen una descripción estática del estado analizado. Sin embargo, para analizar con precisión la eficacia de la política del agente, deberemos considerar los cambios dinámicos. Para ello, se usarán módulos de memoria en ambas líneas troncales de información que registrarán la secuencia temporal de los datos. La clave está en determinar el enfoque óptimo para manejar el módulo de memoria del flujo de información del estado de cuenta: almacenar el vector original, o sus proyecciones. Se supone que el vector original es de menor tamaño, lo cual lo hace más adecuado para lograr una utilización económica de los recursos. Además, las proyecciones creadas tras usar el módulo de memoria proporcionan más información porque enriquecen los datos de origen estáticos con información sobre la dinámica del balance de la cuenta.
index++; if(!cMemoryAccount.Init(caAccountProjection[1].Neurons(), index, OpenCL, account_decr, window_key, 1, heads, stack_size, optimization, iBatch)) return false;
El módulo de memoria de las transacciones propuestas por el agente funciona transacción por transacción.
index++; if(!cMemoryAction.Init(0, index, OpenCL, 3, window_key, (nactions + 2) / 3, heads, stack_size, optimization, iBatch)) return false;
Para realizar un análisis más eficaz de la política aplicada, utilizaremos un módulo de atención cruzada. Este módulo permitirá comparar las acciones recientes del agente con la dinámica de cambios en el estado de la cuenta comercial, revelando la relación entre las decisiones tomadas y los resultados financieros obtenidos en el proceso de trading.
index++; if(!cCrossAttention.Init(0, index, OpenCL, 3, window_key, (nactions + 2) / 3, heads, window, units_count, optimization, iBatch)) return false; //--- return true; }
Esto completará el proceso de inicialización de los objetos internos, lo que también significará que el método ha finalizado. Solo queda devolver el resultado lógico de las operaciones al programa que realiza la llamada.
Una vez completada la fase de inicialización del objeto de gestión de riesgos, construiremos el algoritmo de pasada directa dentro del método feedForward.
bool CNeuronMacroHFTvsRiskManager::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(caAccountProjection[0].getOutput() != SecondInput) { if(!caAccountProjection[0].SetOutput(SecondInput, true)) return false; }
En los parámetros del método, obtendremos los punteros a los dos objetos de datos de origen. Uno de estos objetos se representa como un búfer de datos, cuya información deberá transferirse a un objeto interno especialmente creado para la capa neuronal. Sin embargo, en lugar de copiar completamente los datos del búfer a la capa neuronal, adoptaremos un enfoque más eficiente: sustituiremos el puntero al búfer de resultados del objeto interno por un puntero que hará referencia al búfer de datos de origen resultante. Esto acelerará enormemente el tiempo de procesamiento.
Asimismo, enriqueceremos los datos de origen de ambos flujos de información con información adicional sobre la dinámica acumulada. Para ello, los datos pasarán por módulos de memoria especializados que acumularán información sobre los estados y cambios transmitidos. Esto permitirá considerar las dependencias temporales y preservará el contexto, lo cual facilitará un procesamiento más preciso de la información.
if(!cMemoryAccount.FeedForward(caAccountProjection[0].AsObject())) return false; if(!cMemoryAction.FeedForward(NeuronOCL)) return false;
A partir de los datos enriquecidos con información sobre los estados anteriores, se generarán proyecciones del vector que describirán el estado de la cuenta analizado. Estas proyecciones constituirán la base de un análisis exhaustivo que permitirá comprender mejor la dinámica de la cuenta y evaluar el impacto de las acciones anteriores en su estado actual.
if(!caAccountProjection[1].FeedForward(cMemoryAccount.AsObject())) return false;
Una vez completada la etapa de preprocesamiento de los datos de entrada, analizaremos el impacto de la política de comportamiento del agente sobre el resultado financiero usando el bloque de atención cruzada. La comparación de las acciones del agente con los cambios en los indicadores financieros permitirá revelar la relación entre las decisiones tomadas y los resultados obtenidos.
if(!cCrossAttention.FeedForward(cMemoryAction.AsObject(), caAccountProjection[1].getOutput())) return false;
El último "toque" en la entrenamiento de la decisión comercial final se introducirá con la ayuda de mecanismos de la clase padre, que realizará el procesamiento final de la información.
return CResidualConv::feedForward(cCrossAttention.AsObject());
}
Después retornaremos el resultado lógico de las operaciones al programa que realiza la llamada y finalizaremos el método.
Los métodos de pasada inversa tienen algoritmos lineales y no creo que planteen preguntas adicionales mientras los estudia por su cuenta. Por consiguiente, concluiremos nuestro examen del objeto de gestión de riesgos. Podrá leer el código completo de la clase presentada y todos sus métodos por sí mismo en el archivo adjunto.
Arquitectura del modelo
Vamos a continuar trabajando en la implementación de los enfoques del framework MacroHFT usando MQL5. Y el siguiente paso consistirá en construir la arquitectura del modelo entrenado. En este caso entrenaremos solo un modelo de Actor, cuya arquitectura se formará en el método CreateDescriptions.
bool CreateDescriptions(CArrayObj *&actor) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; }
En los parámetros del método, obtendremos el puntero al objeto array dinámico para registrar la arquitectura del modelo creado. En el cuerpo del método comprobaremos directamente la relevancia del puntero obtenido. Y de ser necesario, crearemos una nueva instancia del objeto de array dinámico.
A continuación, crearemos una descripción de una capa totalmente conectada, que en este caso se utilizará para aceptar los datos de origen y deberá tener un tamaño suficiente para aceptar la descripción tensorial del estado del entorno analizado.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Quisiera recordarle que los valores "brutos" los obtendremos directamente del terminal como datos de entrada. Y su bloque de preprocesamiento se organizará como una capa de normalización por lotes.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Tras la normalización, la descripción del estado del entorno se transmitirá a la capa del framework MacroHFT que hemos creado.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMacroHFT; //--- Windows { int temp[] = {BarDescr, 120, NActions}; //Window, Stack Size, N Actions if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = HistoryBars; descr.window_out = 32; descr.step = 4; // Heads descr.layers =3; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Tenga en cuenta que el framework MacroHFT está diseñado para trabajar en un marco temporal de minutos. Como consecuencia, la pila de memoria del estado del entorno ha aumentado a 120 elementos, correspondientes a una secuencia de 2 horas. Esto le permitirá considerar al completo la dinámica de los cambios en el mercado, ofreciendo una previsión más precisa y una toma de decisiones dentro de la estrategia comercial.
Como ya hemos mencionado, este módulo se centrará únicamente en los análisis del entorno, pero no ofrecerá funciones de evaluación de riesgos. A continuación añadiremos un módulo de gestión de riesgos.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMacroHFTvsRiskManager; //--- Windows { int temp[] = {3, 15, NActions,AccountDescr}; //Window, Stack Size, N Actions, Account Description if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = 10; descr.window_out = 16; descr.step = 4; // Heads descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
En este caso, reduciremos la pila de memoria a 15 elementos, lo cual nos permitirá reducir la cantidad de datos a procesar y centrarnos en dinámicas a más corto plazo. Esto garantizará una respuesta más rápida a los cambios.
A la salida del módulo de gestión de riesgos obtendremos valores normalizados. Y para llevarlos al espacio de acción requerido del Agente, utilizaremos una capa convolucional con la función de activación correspondiente.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvSAMOCL; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = 3; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability = Rho; if(!actor.Add(descr)) { delete descr; return false; } //--- return true; }
Cuando el método finalice, retornaremos el resultado lógico de las operaciones al programa que realiza la llamada.
Nótese que en este caso no utilizaremos la "cabeza" estocástica del agente. En mi opinión, en un entorno comercial de alta frecuencia, su uso solo añadiría ruido innecesario. En las estrategias de alta frecuencia, resulta importante minimizar al máximo los factores aleatorios para garantizar reacciones rápidas e informadas a los cambios del mercado.
Entrenamiento de modelos
En esta fase, hemos completado la implementación de nuestra visión de los enfoques propuestos por los autores del framework MacroHFT usando MQL5. Asimismo, hemos creado una descripción de la arquitectura del modelo entrenado. Y hora es el momento de pasar al entrenamiento de los modelos. Pero primero deberemos recoger una muestra de entrenamiento. Al fin y al cabo, solíamos entrenar los modelos con los datos del marco temporal de horas. En este caso, necesitaremos la información del marco temporal de minutos.
Y aquí deberemos prestar atención a que una disminución del marco temporal conllevará un aumento de la cantidad de información. Obviamente, obtendremos 60 veces más barras en el mismo intervalo histórico. Esto provocará un aumento similar de la muestra de entrenamiento, manteniendo todos los demás parámetros iguales. Y solo tendremos que tomar medidas para reducirlo. Aquí hay 2 maneras: reducir el periodo de entrenamiento y reducir el número de pasadas almacenadas en la muestra de entrenamiento.
Decidimos mantener el periodo de estudio en un año, que creo que es el plazo mínimo para hacerse una idea de la estacionalidad. Sin embargo, la duración de una sola pasada se limitaba a un mes. Para cada mes, guardaremos dos pasadas de políticas aleatorias, lo que nos dará un total de 24 pasadas. Sin duda no será suficiente para un entrenamiento completo, pero en este formato ya hemos obtenido un archivo de muestra de entrenamiento de más de 3 GB.
Estas limitaciones en la recogida de la muestra de entrenamiento resultaron bastante severas. Y creo que nadie se hace ilusiones sobre la obtención de resultados rentables utilizando políticas aleatorias de comportamiento de los agentes. Obviamente, en todas las pasadas conseguimos un rápido "drenaje" del depósito. Y para evitar que las pruebas se interrumpan por stop out, limitamos el nivel mínimo de balance al que el asesor experto genera decisiones comerciales. Esto nos permitió conservar todos los estados del entorno de la muestra de entrenamiento durante el periodo analizado, aunque sin recompensas por las transacciones comerciales.
También debemos aclarar aquí que los autores del framework MacroHFT utilizaron su propia lista de indicadores técnicos al entrenar su modelo de comercio de criptodivisas. Esta lista puede consultarse en los anexos al artículo del autor.
Decidimos mantener la misma lista de indicadores analizados, lo cual nos permitirá comparar la eficacia de la solución implementada con modelos previamente construidos y entrenados. Este enfoque garantizará una evaluación objetiva, ya que el uso de los mismos indicadores de los modelos anteriores permitirá comparar directamente los resultados y determinar los puntos fuertes y débiles del nuevo modelo.
Los datos de la muestra de entrenamiento serán recogidos por el asesor experto "...\MacroHFT\Research.mq5". En el marco de este artículo le propongo familiarizarse únicamente con el método de procesamiento de ticks OnTick, que implementa el algoritmo principal de recepción de datos del terminal y realización de transacciones comerciales.
void OnTick() { //--- if(!IsNewBar()) return;
En el cuerpo del método primero comprobaremos la ocurrencia del evento de apertura de una nueva barra, y solo entonces se realizarán otras operaciones. En primer lugar, actualizaremos los datos de los indicadores técnicos analizados y descargaremos los datos históricos del movimiento de los precios.
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
A continuación, organizaremos un ciclo en el que formamos un búfer para describir el estado del entorno a partir de los datos obtenidos del terminal.
float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Cabe señalar que los índices de oscilación tendrán un aspecto comparable y conservarán la distribución de los datos a lo largo del tiempo. Para conseguir este efecto, al analizar los indicadores del movimiento de los precios, utilizaremos únicamente las desviaciones entre ellos, lo que nos permitirá mantener estable la distribución y evitar fluctuaciones excesivas que pueden distorsionar los resultados del análisis.
El siguiente paso consistirá en crear un vector de descripción del estado de la cuenta considerando las posiciones abiertas y los resultados financieros obtenidos. Para ello, primero recopilaremos información sobre las posiciones abiertas.
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time;
Generaremos los armónicos de la marca temporal.
bTime.Clear(); double time = (double)Rates[0].time; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bTime.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bTime.GetIndex() >= 0) bTime.BufferWrite();
Y solo después de completar el trabajo preparatorio, recopilaremos toda la información sobre los resultados financieros en un único búfer de datos.
bAccount.Clear(); bAccount.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bAccount.Add((float)(sState.account[1] / PrevBalance)); bAccount.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bAccount.Add(sState.account[2]); bAccount.Add(sState.account[3]); bAccount.Add((float)(sState.account[4] / PrevBalance)); bAccount.Add((float)(sState.account[5] / PrevBalance)); bAccount.Add((float)(sState.account[6] / PrevBalance)); bAccount.AddArray(GetPointer(bTime)); //--- if(bAccount.GetIndex() >= 0) if(!bAccount.BufferWrite()) return;
Ahora, una vez preparados todos los datos iniciales necesarios, comprobaremos el tamaño del balance y, si su tamaño permite transacciones comerciales, haremos una pasada directa del modelo.
double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); //--- vector<float> temp; if(sState.account[0] > 50) { if(!Actor.feedForward((CBufferFloat*)GetPointer(bState), 1, false, GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; } Actor.getResults(temp); if(temp.Size() < NActions) temp = vector<float>::Zeros(NActions); //--- for(int i = 0; i < NActions; i++) { float random = float(rand() / 32767.0 * 5 * min_lot - min_lot); temp[i] += random; } } else temp = vector<float>::Zeros(NActions);
Para lograr aprender más sobre el entorno, añadiremos algo de ruido a la solución comercial generada. Esto podría parecer innecesario al utilizar políticas aleatorias en el primer paso, pero resultará útil al actualizar la muestra de entrenamiento utilizando una política preentrenada.
Si se alcanza el límite inferior del balance, el vector de decisiones comerciales se rellenará con valores cero, lo cual implicará la ausencia de transacciones comerciales.
A continuación, trabajaremos con el vector de decisiones comerciales obtenido. En primer lugar, excluiremos los volúmenes de las transacciones opuestas.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; }
A continuación, comprobaremos los parámetros de la posición larga. Si esta no ha sido contemplada por la solución comercial, comprobaremos y cerraremos todas las posiciones largas abiertas anteriormente.
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); }
Si es necesario abrir o mantener una posición larga, primero llevaremos los parámetros de la operación a la forma requerida y ajustaremos los niveles comerciales de las posiciones ya abiertas.
else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()); double buy_sl = NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp);
Y luego ajustaremos el volumen de las posiciones abiertas incrementándolas o cerrándolas parcialmente.
if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
Los parámetros de las posiciones cortas se tratarán de la misma manera.
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()); double sell_sl = NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Una vez realizadas las transacciones comerciales, se generará un vector de recompensas.
sState.rewards[0] = bAccount[0]; sState.rewards[1] = 1.0f - bAccount[1]; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0;
A continuación, todos los datos acumulados se transferirán al búfer de almacenamiento de datos para la muestra de entrenamiento, y procederemos a esperar un nuevo evento de apertura de barra.
for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; if(!Base.Add(sState)) ExpertRemove(); }
Tenga en cuenta que si no podemos añadir nuevos datos al búfer de muestras de entrenamiento, inicializaremos el cierre del programa. Esto puede ocurrir cuando se produce un error o cuando el búfer está lleno.
Encontrará el código completo de este asesor experto en el archivo adjunto.
La muestra de entrenamiento se recogerá directamente en el simulador de estrategias de MetaTrader 5 al ejecutar la optimización lenta.

Obviamente, una muestra de entrenamiento recogida con un número limitado de ejecuciones requerirá un enfoque especial para el entrenamiento del modelo. Sobre todo si consideramos que gran parte de los datos consisten únicamente en información del entorno, lo que a su vez limitará las oportunidades de aprendizaje. En tales circunstancias, me parece que lo mejor sería entrenar el modelo usando como base decisiones comerciales "casi perfectas". Este método, que hemos usado en el entrenamiento de varios modelos recientes, aprovecha al máximo los datos disponibles, a pesar de sus limitaciones.
Además, cabe señalar que el programa de entrenamiento del modelo trabaja exclusivamente con la muestra de entrenamiento y es independiente del marco temporal o del instrumento financiero utilizado para recopilar los datos. Esto nos ofrece una ventaja significativa, ya que podemos utilizar un programa de entrenamiento desarrollado previamente sin tener que hacer cambios en su algoritmo. De este modo, podremos aprovechar los recursos y métodos existentes, ahorrando tiempo y esfuerzo sin comprometer la calidad del entrenamiento del modelo.
Simulación
Hemos trabajado mucho para implementar nuestra propia visión de los enfoques propuestos por los autores del framework MacroHFT utilizando las herramientas MQL5. Ahora es el momento de evaluar la eficacia de los métodos aplicados usando datos históricos reales.
Cabe señalar que la aplicación presentada en este artículo difiere significativamente de la original, incluso en lo que respecta a los indicadores técnicos utilizados. Esto afectará sin duda a los resultados obtenidos, por lo que solo podremos hablar de una evaluación preliminar de la eficacia de los planteamientos aplicados en el contexto de estos cambios.
Para entrenar el modelo, utilizaremos los datos de EURUSD para 2024 en el marco temporal de un minuto (M1). Los parámetros de los indicadores analizados no se han modificado, lo que nos ha permitido centrarnos en la evaluación del rendimiento de los propios algoritmos y enfoques, excluyendo la influencia de los cambios en la configuración de los indicadores. El procedimiento para recoger la muestra de entrenamiento y entrenar el modelo se ha presentado más arriba.
Las pruebas del modelo entrenado se han realizado con los datos históricos disponibles de enero de 2025. Ahora le presentamos los resultados de las pruebas.


Y aquí debemos decir que durante las más de 2 semanas del periodo de prueba el modelo ha realizado solo 8 transacciones, lo que sin duda no es suficiente para un asesor experto comercial de alta frecuencia. Por otra parte, resulta bastante interesante ver la eficacia de las transacciones realizadas: solo una de ellas no ha sido rentable. Esto nos ha permitido fijar el nivel del factor de beneficio en 2,47.

Tras examinar detalladamente la historia de las transacciones realizadas, observamos que el "refuerzo" en un movimiento de tendencia alcista.
Conclusión
Hoy nos hemos familiarizado con el framework MacroHFT, una herramienta innovadora y prometedora para el trading de alta frecuencia en los mercados de criptomonedas. Una de las principales características de este framework es su capacidad para tener en cuenta tanto los contextos macroeconómicos como la dinámica del mercado local. Esta combinación le permite adaptarse eficazmente a las condiciones cambiantes de los mercados financieros y tomar decisiones comerciales más informadas.
En la parte práctica de nuestro trabajo, hemos implementado nuestra propia visión de los enfoques propuestos usando MQL5, con alguna adaptación del framework. Asimismo, hemos entrenado el modelo con datos históricos reales y lo hemos probado fuera de la muestra de entrenamiento. Obviamente, nos ha decepcionado el número de transacciones realizadas, que no se corresponde en absoluto con el trading de alta frecuencia. Probablemente esto pueda atribuirse a la suboptimidad de los indicadores técnicos utilizados o a la escasez de la muestra de entrenamiento, pero la verificación de estas hipótesis requiere un mayor análisis. Sin embargo, los resultados de las pruebas han demostrado que el modelo puede encontrar patrones realmente estables, lo que ha permitido obtener una gran proporción de transacciones rentables en la muestra de prueba.
Enlaces
- MacroHFT: Memory Augmented Context-aware Reinforcement Learning On High Frequency Trading
- Otros artículos de la serie
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor de recopilación de ejemplos con el método Real-ORL |
| 3 | Study.mq5 | Asesor | Asesor de entrenamiento de modelos |
| 4 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 5 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema y la arquitectura del modelo |
| 6 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código del programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/16993
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.


- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso