
Нейросети в трейдинге: Контекстно-зависимое обучение, дополненное памятью (Окончание)

Введение
В предыдущей статье мы познакомились с фреймворком MacroHFT, который был разработан для высокочастотной торговли (HFT) криптовалютами. Этот фреймворк представляет собой современный подход, сочетающий методы контекстно зависимого обучения с подкреплением и использование памяти, что позволяет эффективно адаптироваться к динамичным рыночным условиям и минимизировать риски.
Принцип работы MacroHFT основан на двух этапах обучения отдельных его компонентов. На первом этапе происходит классификация рыночных состояний по направленности тренда и уровню волатильности. Этот процесс позволяет выделить основные состояния рынка, которые затем используются для обучения специализированных субагентов. Каждый субагент оптимизирован для работы в определённых сценариях. На втором этапе осуществляется обучение гиперагента, оснащённого модулем памяти, который координирует работу субагентов. Этот модуль учитывает исторические данные и позволяет принимать более точные решения, основываясь на предыдущем опыте.
Архитектура MacroHFT включает несколько ключевых компонентов. Первый из них — модуль предварительной обработки данных выполняет фильтрацию и нормализацию входящей рыночной информации. Это позволяет устранить шумы и улучшить качество данных, что критически важно для последующего анализа.
Субагенты представляют собой модели глубокого обучения, обученные на конкретных рыночных сценариях. Они используют методы обучения с подкреплением, чтобы адаптироваться к сложным и быстро меняющимся условиям. Завершающим элементом является гиперагент с памятью. Он интегрирует результаты работы субагентов, анализируя историю событий и текущее состояние рынка. Благодаря этому, достигается высокая точность прогнозирования и устойчивость к рыночным всплескам.
Интеграция всех этих компонентов позволяет MacroHFT не только эффективно функционировать в условиях высокой нестабильности рынков, но и обеспечивать значительное улучшение показателей прибыльности.
Авторская визуализация фреймворка MacroHFT представлена ниже.
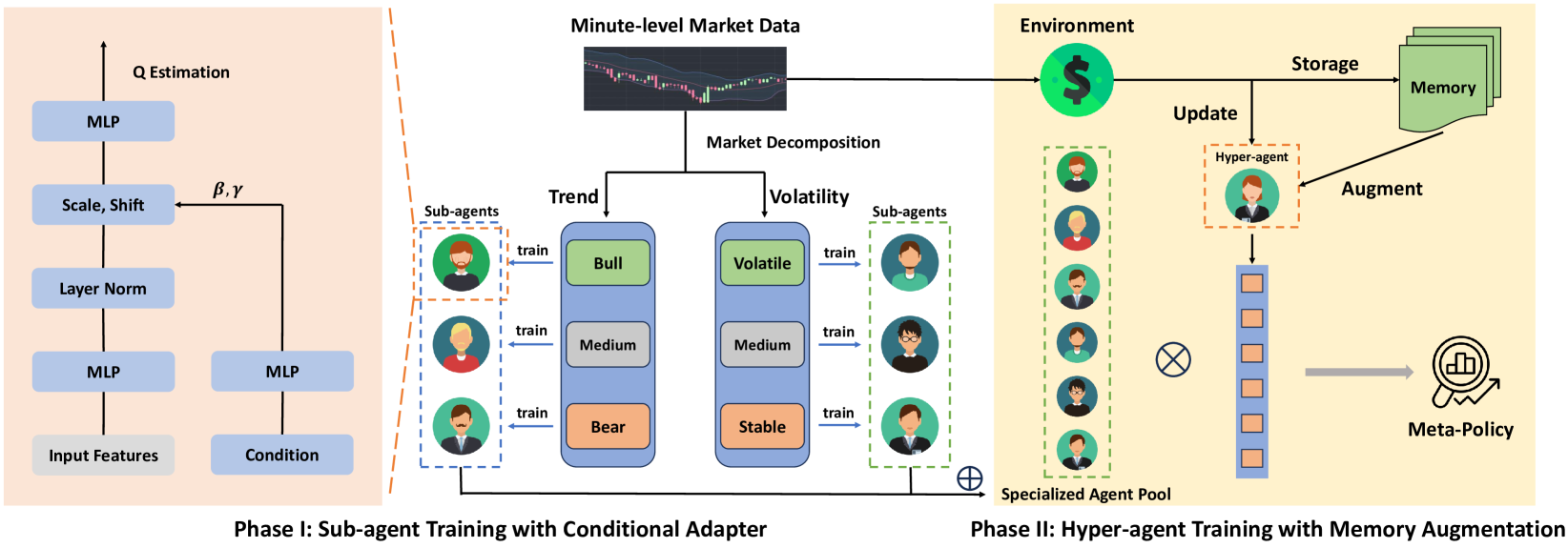
В практической части предыдущей статьи мы создали объект гиперагента и реализовали алгоритм его взаимодействия с субагентами. Сегодня мы продолжим начатую работу, сосредоточив внимание на новых аспектах архитектуры MacroHFT.
Модуль риск-менеджмента
В предыдущей статье мы организовали работу гиперагента в виде объекта CNeuronMacroHFTHyperAgent и разработали алгоритмы его взаимодействия с субагентами. Кроме того, в качестве субагентов мы решили использовать ранее созданных агентов-аналитиков с более сложной архитектурой. На первый взгляд, этого достаточно для реализации фреймворка MacroHFT, однако, текущая реализация имеет определённые ограничения: субагенты и гиперагент анализируют исключительно состояние окружающей среды. Это позволяет прогнозировать будущие ценовые движения, определять направление торговых операций и устанавливать уровни стоп-лоссов и тейк-профитов. Однако, такой подход не охватывает аспект определения объёма торговых операций, что является важным элементом общей стратегии.
Простое использование фиксированного размера сделки, или расчёт объёма на основе фиксированного уровня риска с учётом прогнозного стоп-лосса и доступных средств на счёте, конечно, возможно. Однако, необходимо учитывать, что каждый прогноз имеет индивидуальный уровень уверенности в его реализации. Логично предположить, что этот уровень уверенности должен играть ключевую роль при определении размера сделки. Высокий уровень уверенности в прогнозе позволяет открывать сделки с большим объёмом, что способствует максимизации общей прибыльности торговли, тогда как низкий уровень уверенности предполагает использование более консервативного подхода.
С учётом этих факторов, было принято решение дополнить реализацию модулем риск-менеджмента. Этот модуль будет интегрирован в существующую архитектуру, чтобы обеспечить гибкий и адаптивный подход к управлению объёмом сделок. Внедрение риск-менеджмента позволит улучшить устойчивость модели к нестабильным рыночным условиям, что особенно важно в условиях высокочастотной торговли.
Следует отметить, что в данном случае мы реализуем алгоритм риск-менеджмента, который будет частично "оторван" от анализа непосредственного состояния окружающей среды. Вместо этого, основной акцент будет сделан на оценке влияния действий агента на финансовый результат. Идея заключается в том, чтобы сопоставить каждую торговую операцию с изменением баланса счёта и выявить закономерности, характеризующие эффективность политики. Предполагается, что рост числа прибыльных операций, в сочетании с устойчивым увеличением баланса, будут являться индикаторами успешности текущей политики, что, в свою очередь, позволит обоснованно повышать уровень риска на одну сделку. В то же время, увеличение доли убыточных сделок станет сигналом к применению более консервативных стратегий, направленных на снижение рисков. Такой подход позволит не только лучше адаптироваться к изменяющимся рыночным условиям, но и повысить общую эффективность управления капиталом. Кроме того, для повышения качества анализа мы подготовим несколько проекций состояния счёта, каждая из которых будет представлять различные аспекты его текущего и исторического состояния. Это позволит более точно оценивать эффективность стратегии и оперативно адаптировать её к изменяющимся условиям рынка.
Алгоритм риск-менеджмента мы реализуем в рамках объекта CNeuronMacroHFTvsRiskManager, структура которого представлена ниже.
class CNeuronMacroHFTvsRiskManager : public CResidualConv { protected: CNeuronBaseOCL caAccountProjection[2]; CNeuronMemoryDistil cMemoryAccount; CNeuronMemoryDistil cMemoryAction; CNeuronRelativeCrossAttention cCrossAttention; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronMacroHFTvsRiskManager(void) {}; ~CNeuronMacroHFTvsRiskManager(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint nactions, uint account_decr, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronMacroHFTvsRiskManager; } //--- virtual bool Save(const int file_handle) override; virtual bool Load(const int file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
В представленной структуре можно заметить стандартный набор переопределяемых методов и несколько внутренних объектов, которые играют ключевую роль в реализации описанного выше механизма риск-менеджмента. Более подробно функционал объявленных объектов будет рассмотрен при описании алгоритмов методов класса, что позволит глубже понять логику их использования.
Все внутренние объекты в нашем классе риск-менеджмента объявлены как статические, что позволяет значительно упростить структуру объекта. В частности, это дает возможность оставить пустыми конструктор и деструктор, поскольку они не требуют дополнительных операций для инициализации или очистки памяти, связанной с этими объектами. Инициализация всех унаследованных и объявленных объектов выполняется в методе Init, который отвечает за настройку архитектуры класса при его создании.
В параметрах данного класса мы получаем ряд констант, которые позволяют однозначно интерпретировать архитектуру создаваемого объекта.
bool CNeuronMacroHFTvsRiskManager::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint nactions, uint account_decr, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CResidualConv::Init(numOutputs, myIndex, open_cl, 3, 3, (nactions + 2) / 3, optimization_type, batch)) return false;
В теле метода мы сразу вызываем одноименный метод родительского класса. В данном случае, это объект сверточного блока с обратной связью. Важно отметить, что на выходе этого модуля мы ожидаем получить тензор, представляющий собой матрицу торговых решений. Каждая строка этой матрицы описывает отдельную сделку и содержит вектор с параметрами сделки: объем, стоп-лосс и тейк-профит. Для правильной организации анализа сделок, мы рассматриваем сделки на покупку и продажу как отдельные строки, что позволяет нам независимо анализировать каждую торговую операцию.
При организации работы сверточных операций, размер окна свертки и его шаг установлены равными 3, что соответствует числу параметров в описании торговой операции.
Далее рассмотрим процесс инициализации внутренних объектов. Здесь важно отметить, что модуль управления рисками опирается на два ключевых источника данных: действия агента и вектор описания анализируемого состояние счета. Основной поток информации, представленный действиями агента, поступает в виде объекта нейронного слоя. Вторичный поток, содержащий описание состояния счета, передается через буфер данных.
Для обеспечения корректной работы всех внутренних компонентов необходимо, чтобы оба потока данных были представлены объектами нейронных слоев. Поэтому первым шагом является инициализация полносвязного нейронного слоя, в который мы будем переносить данные второго информационного потока.
int index = 0; if(!caAccountProjection[0].Init(0, index, OpenCL, account_decr, optimization, iBatch)) return false;
Следующим этапом добавляется полносвязный слой, предназначенный для формирования проекций полученного описания состояния счета. Этот обучающийся слой создает тензор, содержащий несколько проекций анализируемого состояния счета в подпространствах заданной размерности. Количество проекций и размерность подпространств передаются в параметрах метода от вызывающей программы, что обеспечивает гибкую настройку работы слоя для различных задач.
index++; if(!caAccountProjection[1].Init(0, index, OpenCL, window * units_count, optimization, iBatch)) return false;
Исходные данные, которые получает модуль управления рисками, предоставляют лишь статическое описание анализируемого состояния. Однако, для точного анализа эффективности используемой политики агента необходимо учитывать динамические изменения. Для этого применяются модули памяти по обоим информационным магистралям, которые фиксируют временную последовательность данных. Ключевым является определение оптимального подхода к работе с модулем памяти информационного потока состояния счета: сохранять исходный вектор, или его проекции. Предполагается, что исходный вектор имеет меньший размер, что делает его более подходящим для экономного использования ресурсов. Более того, проекции, созданные после использования модуля памяти, дают больше информации, так как обогащают статичные исходные данные сведениями о динамике баланса счета.
index++; if(!cMemoryAccount.Init(caAccountProjection[1].Neurons(), index, OpenCL, account_decr, window_key, 1, heads, stack_size, optimization, iBatch)) return false;
Модуль памяти, предлагаемых агентом торговых операций, функционирует в разрезе каждой отдельной сделки.
index++; if(!cMemoryAction.Init(0, index, OpenCL, 3, window_key, (nactions + 2) / 3, heads, stack_size, optimization, iBatch)) return false;
Для осуществления более эффективного анализа применяемой политики, используется модуль кросс-внимания. Этот модуль позволяет сопоставить последние действия агента с динамикой изменений состояния торгового счета, выявляя зависимость между принятыми решениями и финансовыми результатами, полученными в процессе торговли.
index++; if(!cCrossAttention.Init(0, index, OpenCL, 3, window_key, (nactions + 2) / 3, heads, window, units_count, optimization, iBatch)) return false; //--- return true; }
На этом процесс инициализации внутренних объектов завершается, что также означает завершение работы метода. Остается только вернуть логический результат выполнения операций вызывающей программе.
После завершения этапа инициализации объекта риск-менеджмента, мы приступаем к построению алгоритма прямого прохода в рамках метода feedForward.
bool CNeuronMacroHFTvsRiskManager::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(caAccountProjection[0].getOutput() != SecondInput) { if(!caAccountProjection[0].SetOutput(SecondInput, true)) return false; }
В параметрах метода мы получаем указатели на два объекта исходных данных. Один из этих объектов представлен в виде буфера данных, информацию из которого необходимо перенести в специально созданный внутренний объект нейронного слоя. Однако, вместо того чтобы полностью копировать данные из буфера в нейронный слой, мы воспользуемся более эффективным подходом: заменим указатель на буфер результатов внутреннего объекта на указатель, ссылающийся на полученный буфер исходных данных. Это позволит значительно ускорить процесс обработки.
Далее мы обогащаем исходные данные обоих информационных потоков дополнительными сведениями о накопленной динамике. Для этого, данные пропускаются через специализированные модули памяти, которые аккумулируют информацию о прошлых состояниях и изменениях. Это позволяет учитывать временные зависимости и сохранять контекст, что способствует более точной обработке информации.
if(!cMemoryAccount.FeedForward(caAccountProjection[0].AsObject())) return false; if(!cMemoryAction.FeedForward(NeuronOCL)) return false;
На основе данных, обогащенных информацией о прошлых состояниях, формируются проекции вектора, описывающего анализируемое состояние счета. Эти проекции служат основой для всестороннего анализа, позволяя глубже понять динамику изменения счета и оценить влияние предыдущих действий на его текущее состояние.
if(!caAccountProjection[1].FeedForward(cMemoryAccount.AsObject())) return false;
После завершения этапа предварительной обработки исходных данных, мы переходим к анализу воздействия политики поведения агента на финансовый результат с помощью блока кросс-внимания. Сопоставление действий агента с изменениями в финансовых показателях, позволяет выявить взаимосвязь между принятыми решениями и достигнутыми результатами.
if(!cCrossAttention.FeedForward(cMemoryAction.AsObject(), caAccountProjection[1].getOutput())) return false;
Последний "штрих" в формирование итогового торгового решения вносится с помощью механизмов родительского класса, который выполняет окончательную обработку информации.
return CResidualConv::feedForward(cCrossAttention.AsObject());
}
Логический результат выполнения операций возвращаем вызывающей программе и завершаем работу метода.
Методы обратного прохода имеют линейные алгоритмы и, думаю, не вызовут дополнительных вопросов в процессе самостоятельного изучения. Поэтому мы завершаем рассмотрение объекта риск-менеджмента. С полным кодом представленного класса и всех его методов Вы можете самостоятельно ознакомиться во вложении.
Архитектура модели
Мы продолжаем нашу работу по имплементации подходов фреймворка MacroHFT средствами MQL5. И следующим этапом будет построение архитектуры обучаемой модели. В данном случае будем обучать только одну модель Актера, архитектура которой формируется в методе CreateDescriptions.
bool CreateDescriptions(CArrayObj *&actor) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; }
В параметрах метода мы получаем указатель на объект динамического массива для записи архитектуры создаваемой модели. И в теле метода мы сразу проверяем актуальность полученного указателя. При необходимости, создаем новый экземпляр объекта динамического массива.
Далее мы создаем описание полносвязного слоя, который в данном случае используется для приема исходных данных и должен иметь достаточный размер для приема тензора описания анализируемого состояния окружающей среды.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Я хочу напомнить, что в качестве исходных данных мы получаем "сырые" значения напрямую от терминала. И блок их предварительной обработки организован в виде слоя пакетной нормализации.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
После нормализации, описание состояния окружающей среды передается в созданный нами слой фреймворка MacroHFT.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMacroHFT; //--- Windows { int temp[] = {BarDescr, 120, NActions}; //Window, Stack Size, N Actions if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = HistoryBars; descr.window_out = 32; descr.step = 4; // Heads descr.layers =3; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Обратите внимание, что фреймворк MacroHFT разработан для работы на минутном таймфрейме. В связи с этим, стек памяти состояний окружающей среды был увеличен до 120 элементов, что соответствует 2 часовой последовательности. Это позволяет более полно учитывать динамику изменений на рынке, обеспечивая более точное прогнозирование и принятие решений в рамках торговой стратегии.
Как уже было упомянуто ранее, данный модуль фокусируется исключительно на анализе состояния окружающей среды, но не предоставляет возможности для оценки рисков. Поэтому, следующим мы добавим модуль риск-менеджмента.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMacroHFTvsRiskManager; //--- Windows { int temp[] = {3, 15, NActions,AccountDescr}; //Window, Stack Size, N Actions, Account Description if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = 10; descr.window_out = 16; descr.step = 4; // Heads descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
В данном случае мы уменьшаем стек памяти до 15 элементов, что позволяет сократить объем обрабатываемых данных и сосредоточиться на более краткосрочной динамике. Это обеспечивает более быструю реакцию на изменения.
На выходе модуля риск-менеджмента мы получаем нормализованные значения. И с целью приведения их в необходимое пространство действий Агента, мы используем сверточный слой с соответствующей функцией активации.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvSAMOCL; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = 3; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability = Rho; if(!actor.Add(descr)) { delete descr; return false; } //--- return true; }
В завершении работы метода, мы возвращаем логический результат выполнения операций вызывающей программе.
Обратите внимание, что в данном случае мы не используем стохастическую "голову" агента. На мой взгляд, в условиях высокочастотной торговли её использование только добавило бы лишний шум. В высокочастотных стратегиях важно максимально уменьшить количество случайных факторов, чтобы обеспечить быстрые и обоснованные реакции на рыночные изменения.
Обучение модели
На данном этапе мы завершили работу по имплементации нашего видения подходов, предложенных авторами фреймворка MacroHFT, средствами MQL5. Создали описание архитектуры обучаемой модели. И пришло время перейти к обучению модели. Но прежде, нам необходимо собрать обучающую выборку. Ведь раньше мы обучали модели на данных часового таймфрейма. В данном же случае нам потребуется информация с минутного таймфрейма.
И здесь следует обратить внимание, что уменьшение таймфрейма ведет к увеличению объема информации. Очевидно, что на одном и том же историческом интервале мы получаем в 60 раз больше баров. Это ведет к аналогичному увеличению обучающей выборки при сохранении всех прочих параметров. И мы просто вынуждены принять меры к её уменьшению. И здесь есть 2 пути: уменьшение периода обучения и снижение количества проходов, сохраненных в обучающей выборке.
Было принято решение оставить период обучения в размере года, что, на мой взгляд, является минимальным временным интервалом, позволяющим получить хоть какое-то представление о сезонности. Однако, длина одного прохода была ограничена рамками месяца. Для каждого месяца мы сохранили по два прохода случайных политик, что в сумме дает всего 24 прохода. Этого, конечно, недостаточно для полноценного обучения, но в таком формате я уже получил файл обучающей выборки объемом более 3 Гб.
Эти ограничения для сбора обучающей выборки оказались довольно жесткими. И думаю, никто не имеет иллюзий относительно получения прибыльных результатов при использовании случайных политик поведения агента. Очевидно, что на всех проходах мы получили быстрый "слив" депозита. И во избежание прекращения тестирования по стоп-ауту, мы ограничили минимальный уровень баланса, при котором советником генерируются торговые решения. Это позволило нам сохранить в обучающей выборке все состояния окружающей среды за анализируемый период, хотя и без вознаграждений за торговые операции.
Здесь также стоит уточнить, что авторы фреймворка MacroHFT использовали собственный список технических индикаторов при обучении своей модели торговли криптовалютами. Этот список можно найти в приложении к авторской статье.
Мы же решили оставить прежний список анализируемых индикаторов, что позволит провести сравнение эффективности реализованного решения с ранее построенными и обученными моделями. Такой подход обеспечит объективную оценку, поскольку использование тех же индикаторов, что и в предыдущих моделях, позволяет непосредственно сопоставить результаты и выявить сильные и слабые стороны новой модели.
Сбор данных обучающей выборки осуществляется советником "...\MacroHFT\Research.mq5". В рамках данной работы предлагаю ознакомиться лишь с методом обработки тиков OnTick, в рамках которого реализован основной алгоритм получения данных от терминала и осуществления торговых операций.
void OnTick() { //--- if(!IsNewBar()) return;
В теле метода мы сначала проверяем наступление события открытия нового бара, и только в этом случае выполняются дальнейшие операции. Вначале мы обновим данные анализируемых технических индикаторов и загрузим исторические данные ценового движения.
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Далее организовываем цикл, в котором формируем буфер описания состояния окружающей среды на основании полученных от терминала данных.
float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Следует отметить, что показатели осцилляторов имеют сопоставимый вид и сохраняют распределение данных со временем. Для достижения такого эффекта, при анализе показателей ценового движения, мы используем исключительно отклонения между ними, что позволяет сохранить стабильность распределения и избежать излишних колебаний, которые могут искажать результаты анализа.
Следующим этапом создаем вектор описания состояния счета, с учетом открытых позиций и достигнутых финансовых результатов. Для этого мы сначала соберем информацию об открытых позициях.
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time;
Сгенерируем гармоники временной метки.
bTime.Clear(); double time = (double)Rates[0].time; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bTime.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bTime.GetIndex() >= 0) bTime.BufferWrite();
И лишь после завершения подготовительной работы, соберем всю информацию о финансовых результатах в единый буфер данных.
bAccount.Clear(); bAccount.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bAccount.Add((float)(sState.account[1] / PrevBalance)); bAccount.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bAccount.Add(sState.account[2]); bAccount.Add(sState.account[3]); bAccount.Add((float)(sState.account[4] / PrevBalance)); bAccount.Add((float)(sState.account[5] / PrevBalance)); bAccount.Add((float)(sState.account[6] / PrevBalance)); bAccount.AddArray(GetPointer(bTime)); //--- if(bAccount.GetIndex() >= 0) if(!bAccount.BufferWrite()) return;
Теперь, когда подготовлены все необходимые исходные данные, мы проверяем размер баланса и, если его размер позволяет совершать торговые операции, осуществляем прямой проход модели.
double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); //--- vector<float> temp; if(sState.account[0] > 50) { if(!Actor.feedForward((CBufferFloat*)GetPointer(bState), 1, false, GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; } Actor.getResults(temp); if(temp.Size() < NActions) temp = vector<float>::Zeros(NActions); //--- for(int i = 0; i < NActions; i++) { float random = float(rand() / 32767.0 * 5 * min_lot - min_lot); temp[i] += random; } } else temp = vector<float>::Zeros(NActions);
Для достижения эффекта большего изучения окружающей среды, добавим к сгенерированному торговому решению немного шума. Это может показаться излишним при использовании случайных политик на первом этапе, но будет полезно при обновлении обучающей выборки с использованием предварительно обученной политики.
В случае же достижения нижней границы баланса, вектор торговых решений заполняется нулевыми значениями, что подразумевает отсутствие торговых операций.
Далее мы работаем уже с полученным вектором торговых решений. Вначале мы исключаем объемы встречных операций.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; }
Затем, проверяем параметры длинной позиции. Если таковая не предусмотрена торговым решением, то проверяем и закрываем все ранее открытые длинные позиции.
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); }
В случае необходимости открытия или удержания длинной позиции, мы сначала приводим в необходимый вид параметры сделки и корректируем торговые уровни уже открытых позиций.
else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()); double buy_sl = NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp);
А затем корректируем объем открытых позиций путем доливки или частичного закрытия.
if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
Аналогичным образом обрабатываются параметры короткой позиции.
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()); double sell_sl = NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
После осуществления торговых операций, формируется вектор вознаграждений.
sState.rewards[0] = bAccount[0]; sState.rewards[1] = 1.0f - bAccount[1]; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0;
А затем, все накопленные данные передаются в буфер сохранения данных для обучающей выборки, и мы переходим к ожиданию события открытия нового бара.
for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; if(!Base.Add(sState)) ExpertRemove(); }
Обратите внимание, что при невозможности добавления новых данных в буфер обучающей выборки, мы инициализируем закрытие программы. Это может произойти, как при возникновении какой-либо ошибки, так и при полном заполнении буфера.
С полным кодом данного советника вы можете ознакомиться во вложении.
Непосредственно сбор обучающей выборки осуществляется в тестере стратегий MetaTrader 5 путем запуска медленной оптимизации.

Очевидно, что собранная обучающая выборка с ограниченным числом проходов требует особого подхода к обучению модели. Особенно если учесть, что значительная часть данных состоит исключительно из информации о состоянии окружающей среды, что в свою очередь ограничивает возможности для обучения. В таких условиях, мне кажется, наиболее оптимальным будет подход, при котором обучение модели происходит на основе "почти идеальных" торговых решений. Этот метод, который мы использовали при обучении нескольких последних моделей, позволяет максимально эффективно использовать имеющиеся данные, несмотря на их ограниченность.
Кроме того, стоит отметить, что программа обучения модели работает исключительно с обучающей выборкой и не зависит от таймфрейма или финансового инструмента, используемых для сбора данных. Это дает нам значительное преимущество, поскольку мы можем использовать ранее разработанную программу обучения, без необходимости вносить изменения в её алгоритм. Таким образом, мы получаем возможность эффективно использовать существующие ресурсы и методы, сэкономив время и усилия, при этом не снижая качества обучения модели.
Тестирование
Мы проделали большую работу по реализации собственного видения подходов, предложенных авторами фреймворка MacroHFT, средствами MQL5. Теперь наступил момент для оценки эффективности реализованных методов на реальных исторических данных.
Стоит отметить, что представленная в данной работе реализация существенно отличается от оригинальной, в том числе в части используемых технических индикаторов. Это, безусловно, повлияет на полученные результаты, и поэтому мы можем говорить только о предварительной оценке эффективности реализованных подходов в контексте этих изменений.
Для обучения модели мы использовали данные валютной пары EURUSD за 2024 год на минутном таймфрейме (M1). Параметры анализируемых индикаторов были оставлены без изменений, что позволило сосредоточиться на оценке работы самих алгоритмов и подходов, исключая влияние изменений в настройках индикаторов. Процедура сбора обучающей выборки и обучения модели представлена выше.
Тестирование обученной модели осуществлялось на доступных исторических данных Января 2025 года. Результаты тестирования представлены ниже.


И тут надо сказать, что более чем за 2 недели периода тестирования модель совершила всего 8 сделок, что несомненно мало для советника высокочастотной торговли. С другой стороны, довольно интересна эффективность совершенных операций — только одна из них убыточная. Это позволило зафиксировать уровень профит фактора на отметке 2.47.

При детальном рассмотрении истории совершенных операций, можно отметить "доливку" на восходящем тренде.
Заключение
Мы познакомились с фреймворк MacroHFT, который является инновационным и перспективным инструментом для высокочастотной торговли на криптовалютных рынках. Одной из ключевых особенностей данного фреймворка является способность учитывать как макроэкономические контексты, так и особенности локальной рыночной динамики. Такое сочетание позволяет эффективно адаптироваться к быстро меняющимся условиям на финансовых рынках и принимать более обоснованные торговые решения.
В практической части нашей работы мы реализовали собственное видение предложенных подходов средствами MQL5, при этом провели некоторую адаптацию работы фреймворка. Мы обучили модель на реальных исторических данных и провели её тестирование за пределами обучающей выборки. Конечно, нас разочаровало количество совершенных торговых операций, которое совсем не соответствует высокочастотной торговле. Возможно, это можно отнести к неоптимальности используемых технических индикаторов или скудности обучающей выборки, но проверка этих допущений требует дополнительной проработки. Однако, результаты теста показали способность модели к поиску действительно устойчивых паттернов, что позволило получить большую долю прибыльных сделок на тестовой выборке.
Ссылки
- MacroHFT: Memory Augmented Context-aware Reinforcement Learning On High Frequency Trading
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.


- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования