
Redes neurais em trading: Agente com memória multinível (Conclusão)

Introdução
No artigo anterior, examinamos os fundamentos teóricos do framework FinMem — um agente inovador baseado em grandes modelos de linguagem (LLM). Esse framework emprega um sistema exclusivo de memória multinível, que permite processar de forma eficaz dados de diferentes naturezas e relevâncias temporais.
O módulo de memória FinMem está dividido em duas partes principais:
- Memória de trabalho — destinada ao processamento de dados de curto prazo, como notícias diárias e oscilações de mercado.
- Memória de longo prazo — armazena informações de valor duradouro, incluindo relatórios analíticos e pesquisas.
A estrutura principal da memória permite que o agente priorize dados, focando nos mais relevantes para as condições atuais do mercado. Por exemplo, eventos de curto prazo são analisados instantaneamente, enquanto informações com impacto mais profundo são preservadas para uso futuro.
O módulo de criação de perfil FinMem adapta o funcionamento do agente a contextos profissionais específicos e condições de mercado. Considerando as preferências individuais e o perfil de risco do usuário, o agente consegue otimizar sua estratégia, garantindo máxima eficiência nas operações de trading.
O módulo de tomada de decisão integra os dados atuais com as memórias armazenadas, gerando estratégias que levam em conta tanto as tendências de curto prazo quanto os padrões de longo prazo. Essa abordagem inspirada na cognição permite que o agente memorize eventos-chave do mercado e se adapte a novos sinais, o que melhora significativamente a precisão e a efetividade das decisões de investimento.
Os resultados dos experimentos conduzidos pelos autores do framework mostram que FinMem supera outros modelos de trading autônomo. Mesmo com dados de entrada limitados, o agente demonstra eficiência excepcional no processamento de informações e na formulação de estratégias. Sua capacidade de gerenciar a carga cognitiva permite analisar dezenas de sinais de mercado simultaneamente e identificar os mais importantes. O agente estrutura os sinais por relevância e toma decisões fundamentadas mesmo sob restrições de tempo.
Além disso, FinMem possui uma capacidade única de aprendizado em tempo real, o que o torna flexível diante das condições de mercado em constante mudança. Isso permite que o agente não apenas lide com eficácia com as tarefas atuais, mas também aprimore continuamente suas abordagens, adaptando-se a novos dados. FinMem une princípios cognitivos e tecnologias de ponta, oferecendo uma solução moderna para atuar em mercados financeiros complexos e dinâmicos.
A visualização autoral do fluxo de informações do framework FinMem é apresentada abaixo.
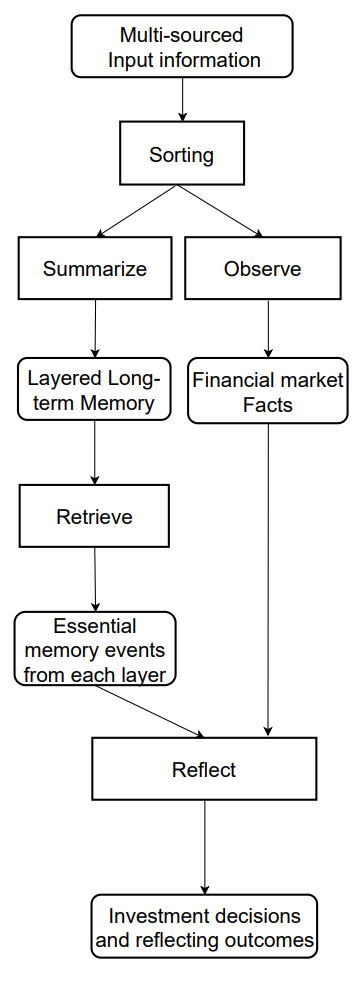
Na parte anterior, iniciamos a implementação das abordagens propostas pelos autores do framework utilizando MQL5. E propusemos nossa própria visão do módulo de memória multinível CNeuronMemory, que difere significativamente da versão original. Afinal, na nossa implementação do FinMem, excluímos o grande modelo de linguagem, que é um componente-chave da concepção original. Isso influenciou todos os componentes do modelo.
Apesar disso, nos esforçamos ao máximo para reproduzir os principais fluxos de informação do framework. Em particular, o objeto CNeuronFinMem foi desenvolvido de forma a preservar a abordagem estratificada no processamento dos dados. Esse objeto integra com sucesso os métodos de tratamento de informações de curto prazo e estratégias de longo prazo, garantindo um funcionamento estável em dinâmicos mercados.
Construção do framework FinMem
Relembrando, paramos na construção do algoritmo complexo do framework proposto, FinMem, dentro do objeto CNeuronFinMem, cuja estrutura é apresentada abaixo.
class CNeuronFinMem : public CNeuronRelativeCrossAttention { protected: CNeuronTransposeOCL cTransposeState; CNeuronMemory cMemory[2]; CNeuronRelativeCrossAttention cCrossMemory; CNeuronRelativeCrossAttention cMemoryToAccount; CNeuronRelativeCrossAttention cActionToAccount; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronFinMem(void) {}; ~CNeuronFinMem(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint accoiunt_descr, uint nactions, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronFinMem; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
Anteriormente, vimos como é realizada a inicialização do objeto, e agora passaremos à construção do método de propagação para frente feedForward, que recebe dois parâmetros principais.
O primeiro é um tensor, que representa um arranjo multidimensional de dados caracterizando o estado do ambiente. Ele contém diversos dados de mercado, como cotações atuais e indicadores técnicos analisados. Essa abordagem permite levar em consideração uma ampla gama de variáveis, dando ao algoritmo a capacidade de tomar decisões com base em uma análise abrangente.
O segundo parâmetro é um vetor que contém informações sobre o estado da conta de trading. Ele inclui o saldo atual, dados de lucros e perdas, além do registro temporal. Esse componente garante a disponibilidade de informações atualizadas e mantém a precisão dos cálculos em tempo real.
bool CNeuronFinMem::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!cTransposeState.FeedForward(NeuronOCL)) return false;
A execução da análise abrangente do estado do ambiente começa com o processamento dos dados brutos, apresentados na forma de um tensor multidimensional. O procedimento de transposição permite transformar o array recebido, facilitando o trabalho com diferentes projeções para destacar com mais detalhe as características-chave.
Em seguida, duas projeções dos dados brutos são encaminhadas para módulos de memória especializados, voltados para uma análise aprofundada. O primeiro módulo é destinado ao estudo da dinâmica temporal dos parâmetros de mercado, organizados em forma de barras, o que permite registrar e interpretar o comportamento complexo do instrumento financeiro analisado. O segundo módulo concentra-se na análise de sequências unitárias de séries temporais multimodais, permitindo identificar dependências ocultas entre diferentes indicadores e registrar suas relações de correlação. Isso gera uma representação integrada do estado atual do mercado.
Essa estrutura de análise garante um alto nível de precisão e favorece a adaptação flexível do modelo às mudanças na dinâmica do mercado, o que é essencial para alcançar decisões confiáveis e oportunas no ambiente financeiro.
if(!cMemory[0].FeedForward(NeuronOCL) || !cMemory[1].FeedForward(cTransposeState.AsObject())) return false;
A unificação dos resultados da análise dos dois módulos de memória é realizada por meio do bloco de atenção cruzada, que permite enriquecer as séries temporais multimodais com os resultados da análise das sequências unitárias. Isso contribui para o aumento da precisão e da completude das informações obtidas, tornando-as mais adequadas à tomada de decisões fundamentadas.
if(!cCrossMemory.FeedForward(cMemory[0].AsObject(), cMemory[1].getOutput())) return false;
Em seguida, investiga-se a influência das mudanças do mercado sobre o estado do saldo. Para isso, os resultados da análise multinível da situação de mercado são comparados com o vetor de estado atual da conta utilizando o módulo de atenção cruzada. Essa abordagem metodológica permite avaliar com mais precisão o impacto dos eventos de mercado sobre os indicadores financeiros. A análise possibilita considerar as dependências complexas entre os eventos do mercado e os resultados financeiros. Isso é especialmente importante para a previsão e a gestão de riscos.
if(!cMemoryToAccount.FeedForward(cCrossMemory.AsObject(), SecondInput)) return false;
O passo seguinte é o trabalho com o bloco de tomada de decisão operacional. Esse trabalho começa com a comparação das últimas ações do Agente com os lucros e perdas atuais, permitindo determinar suas interdependências. Nesta etapa, avaliamos a eficácia da política utilizada e a necessidade de sua correção. Isso ajuda a evitar ações padronizadas e aumenta a flexibilidade da estratégia de trading, o que é especialmente valioso em condições de alta volatilidade.
Além disso, neste ponto, o modelo pode avaliar o risco aceitável para a próxima operação de trading.
É importante destacar que o tensor das últimas ações do Agente constitui a terceira fonte de dados. Ao mesmo tempo, devemos lembrar da limitação do método, que permite o processamento de apenas dois fluxos de dados brutos. No entanto, podemos aproveitar o fato de que o tensor das ações do Agente é formado na saída deste objeto e armazenado no buffer de resultados até a conclusão das operações do próximo método de propagação para frente. Isso viabiliza a chamada da propagação para frente do bloco interno de atenção cruzada utilizando o ponteiro para o objeto atual, de maneira semelhante aos módulos recorrentes.
if(!cActionToAccount.FeedForward(this.AsObject(), SecondInput)) return false;
Neste ponto, é necessário garantir a preservação do tensor das últimas ações do Agente até que ele seja atualizado com novos dados, para assegurar a execução correta das operações de propagação reversa. Para isso, são substituídos os ponteiros para os buffers de dados correspondentes, minimizando o risco de perda de informação.
if(!SwapBuffers(Output, PrevOutput)) return false;
Em seguida, é chamado o método da classe pai, cuja função é gerar um novo tensor de ações do Agente. Esse processo baseia-se nos resultados das operações analíticas realizadas anteriormente no método atual. Assim, cria-se uma cadeia contínua de interação entre os diferentes módulos, permitindo manter um alto nível de consistência e atualidade dos dados.
if(!CNeuronRelativeCrossAttention::feedForward(cActionToAccount.AsObject(), cMemoryToAccount.getOutput())) return false; //--- return true; }
Concluímos o funcionamento do método retornando o resultado lógico da execução das operações ao programa que o chamou.
O algoritmo de propagação para frente que construímos apresenta natureza não linear, o que influencia significativamente o processamento dos dados nos métodos de propagação reversa. Isso é especialmente perceptível no algoritmo de distribuição dos gradientes de erro, implementado no método calcInputGradients. Para executar corretamente esse processo, as informações devem ser processadas estritamente de acordo com a lógica da propagação para frente, mas em ordem inversa. Isso exige a consideração de todas as características únicas da arquitetura do modelo para garantir a precisão e a consistência dos cálculos.
Nos parâmetros do método calcInputGradients recebemos os ponteiros para os objetos dos dois fluxos de dados brutos, nos quais devemos transferir os gradientes de erro conforme a influência desses dados sobre o resultado final do funcionamento do modelo.
bool CNeuronFinMem::calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = -1) { if(!NeuronOCL || !SecondInput || !SecondGradient) return false;
E no corpo do método, verificamos imediatamente a validade dos ponteiros recebidos. Afinal, do contrário, todas as operações subsequentes perdem o sentido, devido à impossibilidade de repassar seus resultados adiante.
Lembro que as operações de propagação para frente se encerraram com a chamada ao método da classe pai, que é responsável pelo processamento final. Consequentemente, a distribuição do gradiente de erro inicia-se a partir do método de mesmo nome da classe pai. Sua tarefa é direcionar o gradiente de erro aos dois blocos internos de atenção cruzada das trilhas paralelas de processamento de dados.
if(!CNeuronRelativeCrossAttention::calcInputGradients(cActionToAccount.AsObject(), cMemoryToAccount.getOutput(), cMemoryToAccount.getGradient(), (ENUM_ACTIVATION)cMemoryToAccount.Activation())) return false;
Aqui é importante observar que, por uma das trilhas de informação, utilizamos de forma recorrente os resultados da propagação para frente anterior do nosso objeto como dados brutos. Isso leva à criação de um laço contínuo no processo de propagação reversa, o qual precisaremos interromper.
Para que as operações de distribuição do gradiente de erro sejam executadas corretamente, é necessário primeiro restaurar no buffer os valores do penúltimo feedforward, que usamos como dados brutos no módulo de atenção cruzada para comparação com o resultado financeiro obtido. Isso é feito através da substituição dos ponteiros para os buffers de dados, permitindo o retorno das informações sem perda e com custo mínimo.
if(!SwapBuffers(Output, PrevOutput)) return false;
Além disso, precisamos substituir o ponteiro para o buffer de gradientes de erro do nosso objeto, a fim de preservar os dados recebidos anteriormente da camada subsequente. Para isso, utilizaremos qualquer buffer disponível no momento, desde que tenha tamanho suficiente. É evidente que o tensor que descreve o estado do ambiente é muito maior do que o vetor das ações do Agente. Isso nos permite utilizar um dos buffers dessa trilha.
CBufferFloat *temp = Gradient; if(!SetGradient(cMemoryToAccount.getPrevOutput(), false)) return false;
Agora que protegemos todos os dados necessários, chamamos o método de distribuição dos gradientes de erro por meio do bloco de atenção cruzada, que analisa a influência das ações anteriores do Agente sobre o resultado financeiro obtido.
if(!calcHiddenGradients(cActionToAccount.AsObject(), SecondInput, SecondGradient, SecondActivation)) return false;
Em seguida, restauramos os ponteiros dos buffers de dados ao seu estado original.
if(!SwapBuffers(Output, PrevOutput)) return false; Gradient = temp;
Neste ponto, distribuímos o gradiente de erro pela trilha de avaliação das últimas ações do Agente. Assim, transmitimos os respectivos gradientes de erro para a trilha de memória e para o buffer do vetor que descreve a conta. No entanto, é importante destacar que os dados do buffer de descrição do estado da conta participam de dois fluxos de informação: o da memória e o das ações do Agente. Para o último, já enviamos o gradiente de erro. Agora, vamos determinar a influência dos dados sobre o estado da conta no resultado final do modelo ao longo da trilha da memória e somar os valores provenientes dos dois fluxos de informação.
if(!cCrossMemory.calcHiddenGradients(cMemoryToAccount.AsObject(), SecondInput, cMemoryToAccount.getPrevOutput(), SecondActivation)) return false; if(!SumAndNormilize(SecondGradient, cMemoryToAccount.getPrevOutput(), SecondGradient, 1, false, 0, 0, 0, 1)) return false;
A seguir, precisamos distribuir o gradiente de erro pela trilha da memória até o nível dos dados brutos da trilha principal, conforme sua influência no resultado final do modelo. E novamente temos dois fluxos de análise dos dados brutos em diferentes projeções. Primeiro, distribuímos o gradiente de erro por esses fluxos de informação.
if(!cMemory[0].calcHiddenGradients(cCrossMemory.AsObject(), cMemory[1].getOutput(), cMemory[1].getGradient(), (ENUM_ACTIVATION)cMemory[1].Activation())) return false;
E o levamos até o nível do objeto de transposição dos dados brutos.
if(!cTransposeState.calcHiddenGradients(cMemory[1].AsObject())) return false;
Neste estágio, só precisamos transferir o gradiente de erro para o objeto de dados brutos a partir das duas trilhas paralelas da memória. Primeiro, conduzimos os erros ao longo de uma das trilhas.
if(!NeuronOCL.calcHiddenGradients(cMemory[0].AsObject())) return false;
Em seguida, realizamos a substituição dos buffers de dados e conduzimos o gradiente de erro pela segunda trilha.
temp = NeuronOCL.getGradient(); if(!NeuronOCL.SetGradient(cTransposeState.getPrevOutput(), false) || !NeuronOCL.calcHiddenGradients(cTransposeState.AsObject()) || !NeuronOCL.SetGradient(temp, false) || !SumAndNormilize(temp, cTransposeState.getPrevOutput(), temp, iWindow, false, 0, 0, 0, 1)) return false; //--- return true; }
Resta somar os dados dos dois fluxos de informação e restaurar os ponteiros dos buffers de dados ao estado original. Depois disso, retornamos o resultado lógico ao programa que chamou o método e encerramos sua execução.
Com isso, concluímos a análise dos algoritmos de construção dos métodos do objeto CNeuronFinMem. O código completo dessa classe e de todos os seus métodos pode ser consultado por você mesmo no anexo.
Arquitetura do modelo
Finalizamos a implementação das abordagens do framework FinMem com recursos do MQL5 no contexto do objeto CNeuronFinMem. Essa implementação fornece a funcionalidade básica e uma base sólida para prosseguir com os algoritmos de aprendizado. O próximo passo será a integração do objeto criado em um modelo treinável do Agente, que atua como núcleo do processo de tomada de decisões em sistemas financeiros. A arquitetura do modelo treinável é apresentada no método CreateDescriptions.
Vale observar que o framework FinMem não se limita apenas a soluções arquitetônicas. Ele também incorpora algoritmos de aprendizado exclusivos que permitem ao modelo adaptar-se a mudanças e processar dados de forma eficiente em ambientes financeiros complexos. No entanto, voltaremos ao processo de aprendizado mais adiante. Por agora, o que importa é que treinaremos apenas um modelo: o do Agente.
Nos parâmetros do método CreateDescriptions, recebemos um ponteiro para o array dinâmico no qual será registrada a arquitetura do modelo em construção.
bool CreateDescriptions(CArrayObj *&actor) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; }
No corpo do método, verificamos imediatamente a validade do ponteiro recebido e, se necessário, criamos uma nova instância do array dinâmico.
Em seguida, como de costume, criamos o bloco de pré-processamento dos dados brutos. Esse bloco inclui uma camada totalmente conectada, que recebe os dados brutos, e uma camada de normalização em lote, que reduz a sensibilidade do modelo a mudanças de escala nos dados e melhora a estabilidade do treinamento. Essa abordagem garante o funcionamento eficaz dos componentes seguintes do modelo.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Depois, inserimos o bloco do framework FinMem que desenvolvemos, o qual serve de base para a implementação dos principais aspectos do processamento de dados e da formulação de decisões.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFinMem; //--- Windows { int temp[] = {BarDescr, AccountDescr, 2*NActions}; //Window, Account description, N Actions if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = HistoryBars; descr.window_out = 32; descr.step = 4; // Heads descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
No array windows, indicamos as 3 principais dimensões dos tensores de dados brutos: descrição de uma barra, estado da conta e ações do Agente. A última também representa a dimensão do vetor de resultados gerado pelo bloco.
Observe que, neste caso, indicamos a dimensão do tensor das ações do Agente como sendo 2 vezes maior do que a constante correspondente. Essa abordagem nos permite incorporar os métodos da cabeça estocástica do Agente. Como de costume em situações assim, a primeira parte indica os valores médios das distribuições, enquanto a segunda se refere às respectivas variâncias. E, nesse contexto, vale lembrar que ao inicializar os objetos de atenção cruzada que trabalham com o tensor das ações do Agente, dividimos o fluxo principal de dados brutos em 2 vetores iguais. Isso nos permitirá obter, na saída do bloco, valores consistentes para as médias e as respectivas variâncias.
A geração de valores dentro das distribuições definidas é realizada por meio da camada de estado latente do autocodificador variacional.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
E a arquitetura do modelo é finalizada com uma camada convolucional, que projeta os valores obtidos no intervalo necessário das ações do Agente.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvSAMOCL; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = 3; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability = Rho; if(!actor.Add(descr)) { delete descr; return false; } //--- return true; }
Depois disso, resta apenas retornar o resultado lógico da execução das operações ao programa chamador e encerrar a execução do método.
Programa de aprendizado
Realizamos um trabalho significativo na implementação das abordagens propostas pelos autores do framework FinMem. E, neste estágio, já temos uma arquitetura de modelo formada, capaz de processar dados financeiros de forma eficaz e adaptar-se a condições de mercado complexas. Um diferencial do modelo criado é o uso de memória multinível, que imita os processos cognitivos humanos.
Mas, como mencionado anteriormente, os autores deste framework propuseram, além de soluções arquitetônicas, um algoritmo de aprendizado para o modelo, baseado em uma abordagem multinível no processamento dos dados. Isso permite considerar não apenas dependências lineares, mas também inter-relações não lineares complexas entre os parâmetros. Na fase de aprendizado, o modelo acessa uma ampla variedade de informações provenientes de múltiplas fontes, o que contribui para a construção de uma representação abrangente do ambiente financeiro. Isso garante a adaptação às mudanças do mercado e melhora a precisão das previsões.
Durante o treinamento, ao receber uma solicitação com os dados analisados, o modelo ativa dois processos-chave: observação e generalização. O sistema observa os rótulos de mercado, que incluem as variações diárias de preços do instrumento financeiro analisado. Esses rótulos funcionam como indicadores das ações “Comprar” ou “Vender”. Essas informações permitem que o modelo identifique e priorize as memórias mais relevantes, classificando-as com base nas avaliações extraídas de cada camada da memória de longo prazo.
Por sua vez, a memória de longo prazo do FinMem permite armazenar eventos e lembranças com dados criticamente importantes para uso futuro. Eles são processados em níveis mais profundos da memória, o que garante seu armazenamento prolongado. Operações de trading repetidas e reações do mercado reforçam a relevância das informações salvas, contribuindo para a melhoria contínua da qualidade das decisões tomadas.
A decisão que tomamos anteriormente de não utilizar um grande modelo de linguagem também impacta o processo de aprendizado. Ainda assim, nos esforçaremos para manter as abordagens de treinamento de modelo propostas. Em particular, durante o aprendizado, permitiremos que o modelo “vislumbre o futuro”, como fizemos no treinamento de diferentes modelos de previsão de movimento de preços. Mas há um detalhe importante. Neste caso, não podemos simplesmente fornecer ao modelo informações sobre o movimento de preços futuro. Na saída do nosso modelo são gerados os parâmetros da operação de trading. E, durante o processo de aprendizado, precisamos transmitir como feedback (rótulos de treinamento) dados equivalentes. Portanto, no treinamento dos modelos, com base nas informações disponíveis sobre o movimento de preços futuro, tentaremos gerar uma decisão de trading quase ideal.
Proponho analisar a implementação dessa abordagem no código. Dentro do escopo deste artigo, trataremos apenas do método de treinamento direto do modelo, Train. O código completo do programa de treinamento “...\Experts\FinMem\Study.mq5” pode ser consultado no anexo.
O início do método de treinamento dos modelos é bastante tradicional: geramos um vetor de probabilidades para seleção de trajetórias a partir do buffer de reprodução de experiência, com base na rentabilidade dos episódios salvos, e declaramos as variáveis locais necessárias.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target, state; matrix<float> fstate = matrix<float>::Zeros(1, NForecast * BarDescr); bool Stop = false;
Em seguida, estruturamos o ciclo de treinamento dos modelos. Porém, neste caso, utilizamos modelos recorrentes, que são sensíveis à ordem de entrada dos dados brutos. Isso nos leva à necessidade de utilizar um sistema de laços aninhados. No laço externo, amostramos uma trajetória do buffer de reprodução de experiência e o estado inicial nela. Já no laço interno, percorremos sequencialmente os estados dessa trajetória escolhida. A quantidade de iterações de aprendizado e o tamanho de cada lote são definidos nos parâmetros externos do programa de treinamento.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter += Batch) { int tr = SampleTrajectory(probability); int start = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast - Batch)); if(start <= 0) { iter -= Batch; continue; } if(!Actor.Clear()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } for(int i = start; i < MathMin(Buffer[tr].Total, start + Batch); i++) { if(!state.Assign(Buffer[tr].States[i].state) || MathAbs(state).Sum() == 0 || !bState.AssignArray(state)) { iter -= Batch + start - i; break; }
Vale destacar que, antes de iniciar o aprendizado em cada nova trajetória, é necessário limpar a memória do modelo. Afinal, os dados armazenados devem estar relacionados ao estado do ambiente em análise.
No corpo do laço interno, começamos extraindo do buffer de reprodução de experiência a descrição do estado analisado do ambiente e formamos o vetor que descreve o estado da conta.
Aqui é importante observar que estamos de fato formando o vetor de descrição do estado da conta. Anteriormente, apenas transferíamos para esse vetor as informações do buffer de reprodução de experiência, ajustando levemente o formato dos dados. Agora, contudo, devemos considerar o fato de que o modelo está aprendendo a analisar a influência das últimas ações do Agente sobre o resultado financeiro obtido. Isso significa que o vetor do estado da conta deve depender dessas ações, algo que não pode ser alcançado com a simples transferência de dados do buffer.
Primeiro, formamos as harmônicas da marcação temporal do estado do ambiente em análise.
bTime.Clear(); double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bTime.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bTime.GetIndex() >= 0) bTime.BufferWrite();
Em seguida, obtemos o vetor das últimas ações do Agente, armazenado no buffer do modelo.
//--- Previous Action
Actor.getResults(result);
Logo após, calculamos o retorno dessa ação com base na variação de preço dentro do último candle do estado analisado do ambiente. Cabe reconhecer que, para simplificação do algoritmo, é utilizado um modelo de análise básico. Não levamos em consideração fatores como a ativação de níveis de stop-loss, take-profit, ou possíveis comissões por execução de operações de trading. Além disso, é assumido que antes da execução da última operação do Agente, todas as posições abertas anteriormente foram encerradas. Essa abordagem é válida para uma avaliação superficial da eficácia do modelo, mas antes de utilizá-lo em trading real, será necessário levar em conta, com detalhe, todas as particularidades do mercado.
Para calcular o retorno da última operação, simplesmente multiplicamos a variação de preço pela diferença entre os volumes de compra e venda do vetor das últimas ações do Agente.
float profit = float(bState[0] / (_Point * 10) * (result[0] - result[3]));
Lembro que, como variação de preço, consideramos a diferença entre os preços de fechamento e abertura, portanto, obtemos um valor positivo para uma vela de alta e negativo em caso contrário. A diferença nos volumes das operações também nos fornece um número positivo para compras e negativo para vendas, Sendo assim, o produto desses dois valores resulta no sinal correto da operação de trading.
Depois, extraímos do buffer de reprodução de experiência os dados de saldo e patrimônio líquido (equity) do estado anterior, no qual se pressupunha a execução da operação de trading sugerida pelo Agente na etapa anterior.
//--- Account float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1];
Como foi dito anteriormente, assumimos o encerramento de todas as posições abertas antes da execução da nova operação. Isso implica que o saldo passa a equivaler ao equity.
bAccount.Clear(); bAccount.Add((PrevEquity - PrevBalance) / PrevBalance);
A variação do equity no último candle de trading é igual ao resultado financeiro da última operação calculado anteriormente.
bAccount.Add((PrevEquity + profit) / PrevEquity); bAccount.Add(profit / PrevEquity);
A operação de trading é realizada apenas com base na diferença dos volumes, o que se reflete nos indicadores de posições abertas.
bAccount.Add(MathMax(result[0] - result[3], 0)); bAccount.Add(MathMax(result[3] - result[0], 0));
Consequentemente, o resultado financeiro é informado apenas para a posição aberta.
bAccount.Add((bAccount[3]>0 ? profit / PrevBalance : 0)); bAccount.Add((bAccount[4]>0 ? profit / PrevBalance : 0)); bAccount.Add(0); bAccount.AddArray(GetPointer(bTime)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
E, após a preparação dos dados brutos, realizamos a propagação para frente do nosso modelo, durante a qual será formado um novo vetor de ações do Agente.
//--- Feed Forward if(!Actor.feedForward((CBufferFloat*)GetPointer(bState), 1, false, GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Agora, para executar as operações de propagação reversa, precisamos preparar os valores-alvo de uma operação de trading “ideal” com base nos dados sobre o movimento de preços futuro. Para isso, extraímos do buffer de reprodução de experiência os dados no horizonte de planejamento especificado.
//--- Look for target target = vector<float>::Zeros(NActions); bActions.AssignArray(target); if(!state.Assign(Buffer[tr].States[i + NForecast].state) || !state.Resize(NForecast * BarDescr) || MathAbs(state).Sum() == 0) { iter -= Batch + start - i; break;
Reformatamos esses dados em uma matriz.
if(!fstate.Resize(1, NForecast * BarDescr) || !fstate.Row(state, 0) || !fstate.Reshape(NForecast, BarDescr)) { iter -= Batch + start - i; break; }
E, em seguida, alteramos a ordem das linhas da matriz de modo que os dados estejam dispostos em sequência cronológica.
for(int i = 0; i < NForecast / 2; i++) { if(!fstate.SwapRows(i, NForecast - i - 1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
Na primeira coluna da nossa matriz de previsão, estão os dados sobre a variação de preços de cada barra. Vamos utilizar a soma acumulada desses valores, o que nos permitirá obter a variação total de preço em cada etapa do período de previsão.
target = fstate.Col(0).CumSum();
Aqui é importante observar que essa abordagem não considera possíveis gaps. Dada a baixa probabilidade relativa desses eventos, aceitamos ignorá-los durante os experimentos. No entanto, essa abordagem não é adequada para a formulação de decisões de trading reais.
A formação do vetor de ações-alvo do Agente dependerá da operação anterior. Se na etapa anterior foi aberta uma posição, procuramos o ponto de saída. Vamos analisar o algoritmo no exemplo de uma operação de compra. Primeiro, definimos o nível do stop-loss configurado e declaramos as variáveis locais necessárias.
if(result[0] > result[3]) { float tp = 0; float sl = 0; float cur_sl = float(-(result[2] > 0 ? result[2] : 1) * MaxSL * Point()); int pos = 0;
Em seguida, estruturamos um laço para percorrer os valores previstos de variação de preço, buscando a posição em que o stop-loss atual seria acionado. Durante essa varredura, registramos os valores máximo e mínimo com o objetivo de estabelecer novos níveis de stop-loss e take-profit.
for(int i = 0; i < NForecast; i++) { tp = MathMax(tp, target[i] + fstate[i, 1] - fstate[i, 0]); pos = i; if(cur_sl >= target[i] + fstate[i, 2] - fstate[i, 0]) break; sl = MathMin(sl, target[i] + fstate[i, 2] - fstate[i, 0]); }
Em caso de movimento descendente, é esperado que o valor do take-profit permaneça igual a “0”, o que resultará na formação de um vetor de ações nulo do Agente. Como consequência, todas as posições abertas são encerradas e o modelo passa a aguardar a abertura de uma nova barra.
Se for esperado um movimento de alta no preço, então um novo vetor de ações do Agente será formado, com os valores de níveis de trading ajustados.
if(tp > 0) { sl = float(MathMin(MathAbs(sl) / (MaxSL * Point()), 1)); tp = float(MathMin(tp / (MaxTP * Point()), 1)); result[0] = MathMax(result[0] - result[3], 0.01f); result[1] = tp; result[2] = sl; for(int i = 3; i < NActions; i++) result[i] = 0; bActions.AssignArray(result); } }
De forma semelhante é formado o vetor de ações ao procurar o ponto de saída de uma posição vendida.
else { if(result[0] < result[3]) { float tp = 0; float sl = 0; float cur_sl = float((result[5] > 0 ? result[5] : 1) * MaxSL * Point()); int pos = 0; for(int i = 0; i < NForecast; i++) { tp = MathMin(tp, target[i] + fstate[i, 2] - fstate[i, 0]); pos = i; if(cur_sl <= target[i] + fstate[i, 1] - fstate[i, 0]) break; sl = MathMax(sl, target[i] + fstate[i, 1] - fstate[i, 0]); } if(tp < 0) { sl = float(MathMin(MathAbs(sl) / (MaxSL * Point()), 1)); tp = float(MathMin(-tp / (MaxTP * Point()), 1)); result[3] = MathMax(result[3] - result[0], 0.01f); result[4] = tp; result[5] = sl; for(int i = 0; i < 3; i++) result[i] = 0; bActions.AssignArray(result); } }
A abordagem é um pouco diferente no caso de não haver uma posição aberta. Nessa situação, identificamos primeiro a tendência dominante mais próxima.
ulong argmin = target.ArgMin(); ulong argmax = target.ArgMax(); while(argmax > 0 && argmin > 0) { if(argmax < argmin && target[argmax] > MathAbs(target[argmin])) break; if(argmax > argmin && target[argmax] < MathAbs(target[argmin])) break; target.Resize(MathMin(argmax, argmin)); argmin = target.ArgMin(); argmax = target.ArgMax(); }
E o vetor de ações é formado de acordo com essa tendência. O volume da operação é indicado com base na proporção de um lote mínimo para cada 100 USD do saldo atual.
if(argmin == 0 || argmax < argmin) { float tp = 0; float sl = 0; float cur_sl = - float(MaxSL * Point()); ulong pos = 0; for(ulong i = 0; i < argmax; i++) { tp = MathMax(tp, target[i] + fstate[i, 1] - fstate[i, 0]); pos = i; if(cur_sl >= target[i] + fstate[i, 2] - fstate[i, 0]) break; sl = MathMin(sl, target[i] + fstate[i, 2] - fstate[i, 0]); } if(tp > 0) { sl = (float)MathMin(MathAbs(sl) / (MaxSL * Point()), 1); tp = (float)MathMin(tp / (MaxTP * Point()), 1); result[0] = float(Buffer[tr].States[i].account[0] / 100 * 0.01); result[1] = tp; result[2] = sl; for(int i = 3; i < NActions; i++) result[i] = 0; bActions.AssignArray(result); } } else { if(argmax == 0 || argmax > argmin) { float tp = 0; float sl = 0; float cur_sl = float(MaxSL * Point()); ulong pos = 0; for(ulong i = 0; i < argmin; i++) { tp = MathMin(tp, target[i] + fstate[i, 2] - fstate[i, 0]); pos = i; if(cur_sl <= target[i] + fstate[i, 1] - fstate[i, 0]) break; sl = MathMax(sl, target[i] + fstate[i, 1] - fstate[i, 0]); } if(tp < 0) { sl = (float)MathMin(MathAbs(sl) / (MaxSL * Point()), 1); tp = (float)MathMin(-tp / (MaxTP * Point()), 1); result[3] = float(Buffer[tr].States[i].account[0] / 100 * 0.01); result[4] = tp; result[5] = sl; for(int i = 0; i < 3; i++) result[i] = 0; bActions.AssignArray(result); } } } } }
Após formar o vetor de ações “quase ideais”, realizamos a propagação reversa do nosso modelo, minimizando a divergência entre as ações previstas pelo Agente e os nossos valores-alvo.
//--- Actor Policy if(!Actor.backProp(GetPointer(bActions), (CBufferFloat*)GetPointer(bAccount), GetPointer(bGradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Agora, resta apenas informar o usuário sobre o andamento do processo de treinamento e seguir para a próxima iteração do nosso sistema de laços.
if(GetTickCount() - ticks > 500) { double percent = double(iter + i - start) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Após a execução bem-sucedida de todas as iterações do sistema de laços de treinamento do modelo, limpamos o campo de comentários no gráfico do instrumento financeiro, que foi utilizado para manter o usuário informado. Em seguida, registramos no log os resultados do treinamento e iniciamos o processo de finalização do programa.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); ExpertRemove(); //--- }
Com isso, encerramos a análise dos algoritmos de construção do framework FinMem utilizando os recursos do MQL5. O código completo de todos os objetos apresentados, seus métodos e os programas utilizados na elaboração deste artigo estão disponíveis no anexo para consulta.
Testes
As duas últimas partes deste artigo foram dedicadas ao framework FinMem. Nelas, implementamos nossa visão das abordagens propostas pelos autores do framework utilizando MQL5. E agora chegamos à etapa mais empolgante, a verificação da eficácia das soluções implementadas em dados históricos reais.
Vale destacar que, durante a implementação, realizamos modificações significativas nos algoritmos do framework FinMem. Portanto, estamos avaliando exclusivamente a solução implementada, e não o framework original.
O treinamento do modelo foi realizado com dados históricos do par de moedas EURUSD referentes ao ano de 2023, utilizando o timeframe H1. As configurações dos indicadores analisados pelo modelo foram mantidas em seus valores padrão.
Para a etapa inicial de treinamento, foi utilizada uma amostra de dados formada em estudos anteriores. O algoritmo de treinamento implementado, com a formação de ações-alvo “quase ideais” para o Agente, permite o treinamento do modelo sem a necessidade de atualizar a amostra de treinamento. No entanto, para cobrir um espectro mais amplo de estados da conta, eu recomendaria, se possível, adicionar uma atualização regular da amostra de treinamento.
Após alguns ciclos de treinamento, conseguimos obter um modelo que demonstrou rentabilidade consistente tanto nos dados de treinamento quanto nos dados de teste. O teste final foi realizado com dados históricos referentes a janeiro de 2024, mantendo todos os demais parâmetros inalterados. Os resultados do teste são apresentados abaixo.
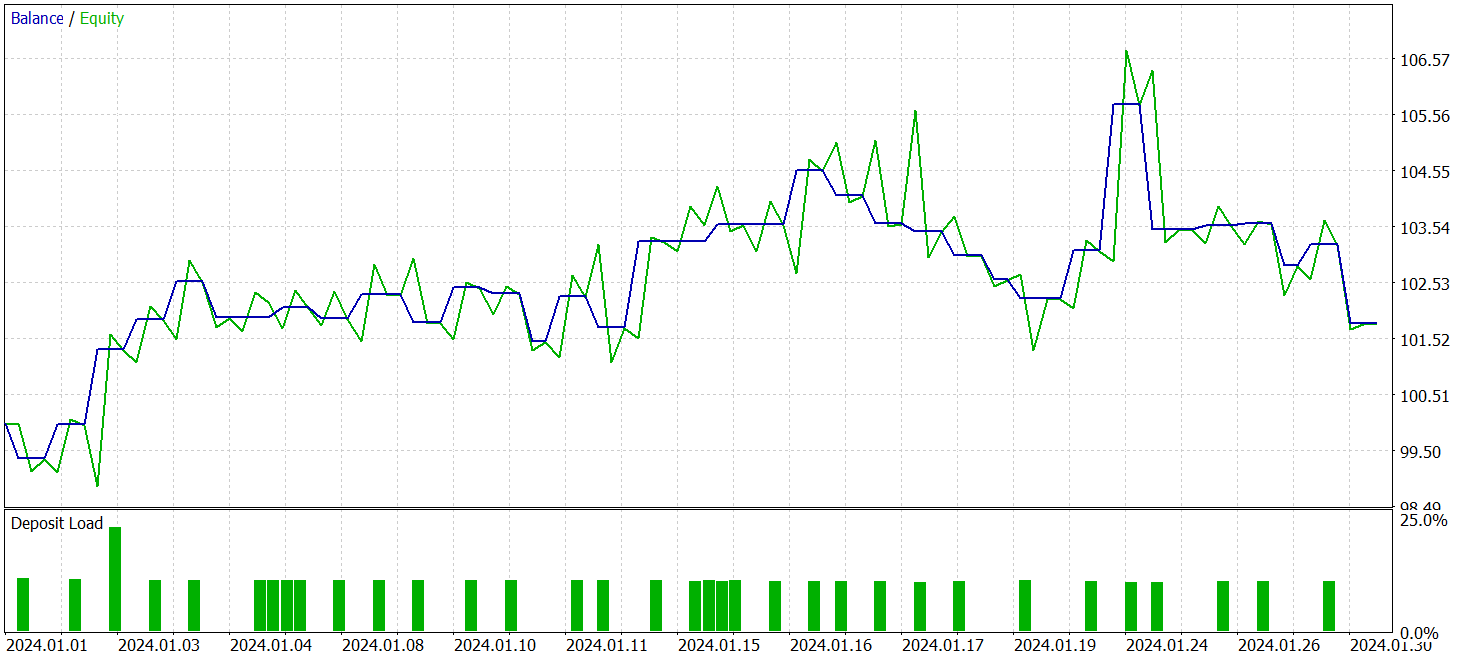
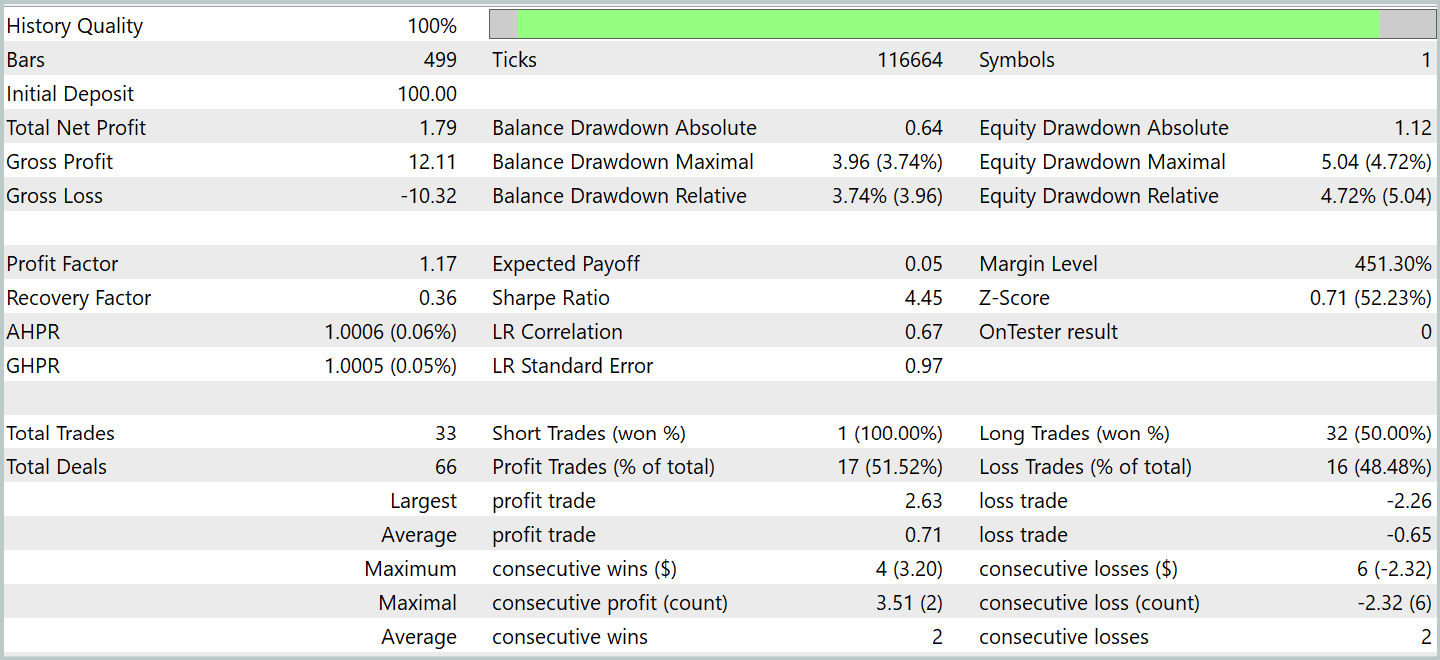
Durante o período de teste, o modelo executou 33 operações de trading, e um pouco mais da metade delas foi encerrada com lucro. Além disso, o fato de a média e o valor máximo das posições lucrativas terem superado os das operações com prejuízo permitiu ao modelo demonstrar uma tendência de crescimento do saldo. Isso indica o potencial das abordagens propostas e sua viabilidade para aplicação em trading real.
Considerações finais
Exploramos o framework FinMem, que representa uma nova etapa na evolução dos sistemas de trading autônomos. Esse framework combina princípios cognitivos com algoritmos modernos baseados em grandes modelos de linguagem. A memória multinível e a capacidade de adaptação em tempo real permitem que o agente tome decisões de investimento fundamentadas e precisas, mesmo em cenários de instabilidade nos mercados.
Na parte prática do trabalho, implementamos nossa própria interpretação das abordagens propostas, utilizando a linguagem de programação MQL5, mas excluindo o grande modelo de linguagem. Os resultados dos experimentos realizados confirmam a eficácia das abordagens propostas e sua aplicabilidade ao trading real. No entanto, para o uso pleno desse modelo em mercados financeiros reais, é necessário realizar ajustes adicionais e treinar o modelo com uma amostra de treinamento mais representativa, além de submetê-lo a uma testagem minuciosa e abrangente.
Referências
- FinMem: A Performance-Enhanced LLM Trading Agent with Layered Memory and Character Design
- Outros artigos da série
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA de coleta de exemplos |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA de coleta de exemplos com o método Real-ORL |
| 3 | Study.mq5 | Expert Advisor | EA de treinamento dos modelos |
| 4 | Test.mq5 | Expert Advisor | EA para teste do modelo |
| 5 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema e da arquitetura dos modelos |
| 6 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de rede neural |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código para o programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/16816
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso