
Redes neurais em trading: Ator–Diretor–Crítico (Actor–Director–Critic)

Introdução
O aprendizado por reforço (Reinforcement Learning — RL) continua sendo uma das áreas mais promissoras e ativamente desenvolvidas no aprendizado de máquina moderno. Sua singularidade está na capacidade de o Agente aprender por meio da interação com o ambiente, desenvolvendo estratégias de comportamento ótimas com base na experiência acumulada. A combinação com redes neurais profundas, o chamado aprendizado por reforço profundo (Deep Reinforcement Learning — Deep-RL), mostrou-se especialmente eficaz, impulsionando o desenvolvimento de sistemas autônomos em robótica, jogos, controle de produção e também no campo dos mercados financeiros.
O ambiente financeiro é caracterizado por alta estocasticidade, mudanças contínuas e um nível elevado de risco, o que o torna um campo ideal para aplicação e teste de métodos Deep-RL. Aqui o Agente precisa se adaptar rapidamente às mudanças de preços, volumes negociados, volatilidade do mercado e tomar decisões em condições de incerteza. No entanto, na prática, a aplicação de RL em estratégias de trading, especialmente em condições de trading de alta frequência e gestão de portfólios, enfrenta uma série de dificuldades. Um dos principais problemas continua sendo a baixa eficiência no uso dos dados, ou seja, o custo extremamente alto de ações pouco informativas e de estratégias incorretas.
Nos algoritmos clássicos de Model-Free RL, onde a o modelo do ambiente não é usado de forma explícita, o Agente recebe informações exclusivamente da experiência observada. Ele age por tentativa e erro: realiza ações, recebe recompensas, atualiza suas estimativas. No entanto, grande parte dessas interações acaba sendo pouco informativa. Em condições de mercado, isso significa altos custos operacionais, perdas de capital e um longo caminho até formar uma estratégia robusta. Assim, torna-se uma tarefa atual aumentar a eficiência no uso dos dados e acelerar a convergência do treinamento.
Uma das arquiteturas mais robustas e amplamente utilizadas tornou-se o framework Actor-Critic, que combina dois modelos:
- Ator (Actor) — aprende a estratégia (Policy),
- Crítico (Critic) — avalia as ações por meio da função de valor (Value Function).
Em aplicações financeiras, a arquitetura Actor-Critic é usada para construir Agentes capazes de prever lucros de curto prazo e gerenciar riscos no longo prazo. Por exemplo, na tarefa de rebalanceamento de portfólio, o Crítico é treinado para prever a rentabilidade esperada, enquanto o Ator escolhe os pesos dos ativos que permitem aumentar o valor do portfólio. No entanto, mesmo essa arquitetura avançada possui limitações: nas fases iniciais do treinamento, a estimativa do Crítico pode ser muito grosseira, e os sinais enviados ao Ator podem ser incorretos. Nesse caso, o Agente pode voltar a explorar áreas deliberadamente desfavoráveis do espaço de ações.
Para eliminar essa limitação, no trabalho "Actor-Director-Critic: A Novel Deep Reinforcement Learning Framework" foi proposto um novo framework — Actor–Director–Critic (ADC). Além do Ator e do Crítico, a arquitetura introduz um terceiro elemento, chamado de Diretor (Director). Sua tarefa é atuar como um classificador capaz de distinguir ações de boa qualidade das de baixa qualidade antes mesmo de o Crítico aprender a fornecer avaliações corretas. Diferentemente do Crítico, o Diretor não realiza uma função de avaliação, mas sim de classificação. Ele determina se vale a pena tentar treinar a política com base em uma determinada ação ou se ela é, desde o início, de baixa qualidade e pode ser descartada das análises posteriores.
A introdução do Diretor oferece as seguintes vantagens. Primeiro, na fase inicial do treinamento, a seletividade é extremamente importante, por isso é necessário evitar a repetição de ações ineficientes. Segundo, em condições de altos custos transacionais e volatilidade, características dos mercados financeiros, cada passo malsucedido sai caro para o Agente. Nessas condições, o Diretor atua como um mecanismo inicial de “orientação” do Ator, permitindo focar em ações potencialmente eficazes. Essa abordagem reduz a entropia da diversificação e acelera a formação de estratégias produtivas.
O treinamento do Diretor é baseado na construção de dois subconjuntos empíricos de dados: em um são incluídos conjuntos de dados (estado, ação, recompensa) com alta rentabilidade, e no outro, com baixa rentabilidade. Após o treinamento, o Diretor é capaz de realizar classificação binária de novas ações: filtrar aquelas potencialmente ineficientes, fortalecendo assim os sinais enviados pelo Crítico. A influência do Diretor é regulada por um coeficiente de atenuação: inicialmente ele exerce grande influência sobre o Ator, mas à medida que a precisão do Crítico aumenta, o peso do Diretor diminui. Esse mecanismo permite manter flexibilidade e robustez durante a otimização.
Além das melhorias estruturais na arquitetura ADC, os autores do framework propõem a solução de outro problema fundamental,a superestimação das ações (Overestimation Bias). No RL, a superestimação surge devido ao uso de valores inflados como valores-alvo, isso leva a uma recompensa esperada superestimada e à desestabilização do treinamento. As causas da superestimação são:
- Viés associado à escolha de um valor inflado da função de valor (Maximization Bias);
- Erros de bootstrap, quando estimativas previstas de recompensas futuras são usadas para atualizar o estado atual.
Uma das abordagens mais conhecidas para combater a superestimação foi o algoritmo Twin Delayed Deep Deterministic Policy Gradient (TD3). Ele utiliza duas funções Q independentes e seleciona o mínimo entre elas para realizar a atualização. No entanto, a estabilidade desse método ainda é limitada: os modelos-alvo são atualizados com atraso, e suas estimativas são instáveis.
O framework ADC propõe uma modificação desse esquema: cada função Q recebe duas cópias-alvo, que são atualizadas alternadamente em diferentes intervalos. No cálculo do valor-alvo, utiliza-se a estimativa média das duas modelos-alvo. Essa abordagem reduz a variância das estimativas, minimiza a superestimação e torna o treinamento mais estável. Isso é especialmente importante em tarefas onde o erro na função Q pode levar à perda de capital, como em aplicações de trading.
A combinação da arquitetura Actor-Director-Critic com um sistema aprimorado de avaliação dupla resulta em um framework poderoso, adaptativo e robusto. Sua aplicação em tarefas de trading algorítmico, gestão de ativos e hedge automático pode aumentar significativamente a eficácia das estratégias de trading, acelerar o treinamento dos Agentes e reduzir riscos graças à seleção inteligente de ações já nas fases iniciais do treinamento.
Algoritmo ADC
Em diversas tarefas de aprendizado por reforço, a arquitetura Actor-Critic estabeleceu-se como uma ferramenta confiável e eficaz. Sua elegância, clareza e capacidade de fornecer estratégias de alta qualidade fizeram desse modelo a base para novos avanços em aprendizado por reforço. No entanto, com o aumento da complexidade dos ambientes analisados, especialmente na presença de um espaço de ações contínuo do Agente e uma retroalimentação fraca por parte do ambiente, surgiu a necessidade de soluções arquitetônicas mais poderosas e flexíveis. A resposta a esses desafios foi o framework inovador Actor-Director-Critic (ADC), que incorpora princípios de planejamento estratégico, orientação heurística e avaliação profunda da utilidade das ações.
Esta arquitetura baseia-se em três componentes interligados: o Ator (Actor), o Crítico (Critic) e o Diretor (Director). Juntos, eles formam um sistema coordenado no qual cada elemento apoia e reforça os outros, criando condições para um treinamento mais estável e rápido do Agente.
O Crítico desempenha o papel de centro analítico do sistema. Sua tarefa principal é avaliar a utilidade das ações do Agente no longo prazo, aproximando a função de valor Q(s, a), que reflete a recompensa total esperada ao utilizar a política atual. Ele é treinado minimizando o erro entre o valor previsto e o valor-alvo:
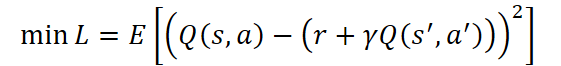
onde:
- r — recompensa recebida do ambiente pela última ação do Agente,
- γ ∈ [0,1) — coeficiente de desconto,
- s' e a' — o próximo estado e a próxima ação, respectivamente.
No entanto, depender exclusivamente das estimativas do Crítico, especialmente nas fases iniciais do treinamento, pode ser arriscado, pois suas previsões ainda são instáveis. Para compensar essa incerteza e direcionar o Agente na direção de decisões sensatas, a arquitetura incorpora o Diretor. Ele é um componente que desempenha funções de mentor. Ele atua como um classificador binário, distinguindo ações potencialmente boas das indesejáveis. O treinamento do Diretor ocorre em amostras previamente rotuladas de ações positivas a e negativas a de acordo com a seguinte função-alvo:
![]()
onde a função D(s, a) avalia a probabilidade de que a ação a no estado s seja adequada. Assim, o Diretor filtra ações e direciona o treinamento do Ator, especialmente na fase inicial, quando as estimativas do Crítico podem ser pouco confiáveis.
O Ator, por sua vez, representa a implementação da política de comportamento do Agente. Trata-se de uma função paramétrica μ(s), que retorna a ação a otimizada (dentro da política atual) após analisar o estado s. No framework ADC, o Ator é treinado não apenas com base nas previsões do Crítico, mas também recebe orientações do Diretor. Isso lhe proporciona um movimento mais seguro em direção a estratégias ótimas. A função-alvo do Ator combina duas fontes de informação:
![]()
Assim, o Ator busca escolher ações que sejam simultaneamente aprovadas pelo Diretor e que possuam alto valor esperado segundo o Crítico.
Com o objetivo de aumentar a estabilidade do treinamento e combater a superestimação, os autores do framework ADC propõem utilizar um sistema aprimorado de avaliação dupla: dois Críticos independentes recebem duas cópias-alvo com parâmetros congelados para cada um deles. No treinamento do Crítico, é usado o valor médio das estimativas do estado e ação subsequentes produzidas pelos modelos-alvo correspondentes, o que contribui para a estabilização do processo. E, no treinamento do Ator, utiliza-se o valor mínimo entre as estimativas dos dois Críticos, o que evita a superestimação da ação e favorece a formação de uma estratégia mais conservadora, porém confiável.
Os modelos-alvo dos Críticos são atualizados alternadamente, copiando os parâmetros dos modelos treináveis correspondentes após um intervalo de tempo definido. Isso permite garantir estabilidade durante o treinamento de longo prazo e evitar saltos bruscos nos valores das funções-alvo.
Vale notar também que a otimização dos parâmetros dos modelos treináveis do Crítico é realizada em todas as iterações do processo de treinamento. No entanto, a atualização da política do Ator é feita com atraso, o que confere estabilidade adicional ao processo de aprendizado. O período de atraso permite que o Crítico avalie com mais precisão a política atual e indique uma direção mais equilibrada para sua correção.
Além disso, para aumentar a diversidade e a estabilidade no comportamento do Agente, são aplicados métodos de suavização estocástica, incluindo:
- adição de ruído gaussiano às ações do Agente:
![]()
- adição de ruído limitado às ações-alvo:
![]()
A função final de otimização dos parâmetros do Ator integra ambos os sinais, do Crítico e do Diretor:
![]()
O framework Actor-Director-Critic abre novos horizontes para a criação de Agentes inteligentes capazes não apenas de extrair conhecimento da experiência, mas também de perceber orientação, semelhante ao aprendizado humano.
A visualização autoral do framework Actor-Director-Critic é apresentada abaixo.

Implementação em MQL5
Após analisar os aspectos teóricos do framework Actor-Director-Critic, passamos à parte prática do artigo, na qual examinamos nossa própria visão da implementação das abordagens propostas pelos autores do framework utilizando MQL5.
Como você deve ter notado, o framework analisado não pressupõe a criação de novos módulos na forma de objetos separados. E isso distingue significativamente este trabalho de vários anteriores. Hoje, dedicaremos mais atenção à criação da arquitetura dos modelos treináveis a partir de módulos já existentes e à construção do processo de treinamento levando em conta as abordagens propostas.
Arquitetura dos modelos treináveis
Ao iniciar o trabalho de construção da arquitetura dos modelos treináveis, vale destacar que as soluções propostas pelos autores do framework ADC são aplicáveis a um espectro bastante amplo de decisões arquiteturais. No trabalho original, foram apresentados resultados de experimentos envolvendo a expansão do framework TD3. Nós, por nossa vez, iremos mais longe e tentaremos aplicar as soluções propostas a uma estrutura arquitetural mais complexa, o HiSSD, que foi analisado no trabalho anterior. Além disso, não nos limitamos a adicionar duas novas modelos: o Crítico e o Diretor, mas também fizemos algumas alterações nas que já haviam sido criadas.
Como anteriormente, a arquitetura de todos os modelos treináveis é apresentada no método CreateDescriptions. Nos parâmetros desse método, adicionamos dois arrays dinâmicos para registrar a arquitetura dos modelos adicionais.
bool CreateDescriptions(CArrayObj *&encoder, CArrayObj *&task, CArrayObj *&actor, CArrayObj *&probability, CArrayObj *&director, CArrayObj *&critic ) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!task) { task = new CArrayObj(); if(!task) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; } if(!director) { director = new CArrayObj(); if(!director) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
No corpo do método, verificamos imediatamente os ponteiros recebidos e, se necessário, criamos novas instâncias dos objetos dos arrays dinâmicos, o que nos permite evitar erros críticos ao acessarmos esses arrays posteriormente.
Primeiro, como antes, apresentamos a arquitetura do planejador de alto nível, que em parte desempenha o papel de um codificador do estado do ambiente.
Lembro que esse modelo recebe como entrada um tensor que descreve o estado do ambiente. Ele gera uma matriz de habilidades gerais no estado latente do modelo e prevê a descrição dos estados subsequentes do ambiente para um horizonte de planejamento definido. Para construir os estados previstos, é utilizada apenas a informação das habilidades gerais. Dessa forma, estimulamos o modelo a criar um tensor de habilidades gerais o mais informativo possível.
Como primeira camada, continuamos utilizando uma camada totalmente conectada, cujo tamanho é suficiente para registrar o tensor completo de descrição do estado do ambiente.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Aqui é importante lembrar que a entrada do modelo recebe dados brutos, não processados, obtidos diretamente do terminal MetaTrader 5. Isso pode incluir tanto sequências de cotações de preços quanto dados de indicadores técnicos, isto é, desde médias móveis simples até osciladores complexos.
Os dados analisados, apesar de seu valor, possuem natureza extremamente diversa. Seus intervalos, distribuições estatísticas e características de ruído podem diferir significativamente. Sem um pré-processamento adequado, essa heterogeneidade leva a uma queda acentuada na eficiência do treinamento dos modelos. Por isso, o próximo passo é trazê-los para uma forma comparável. Normalmente, para isso utilizamos uma camada de normalização em lote, que permite eliminar o desequilíbrio na distribuição dos valores.
Mas não hoje. Com o objetivo de aumentar a estabilidade do modelo e sua capacidade de generalização, propomos aprimorar essa etapa adicionando ruído controlado aos dados normalizados. Assim, forma-se um tipo de mecanismo de regularização, que impede o sobreajuste e aumenta a adaptabilidade do modelo diante da turbulência real dos mercados.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormWithNoise; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Somente depois utilizamos o objeto universal de geração de habilidades, cuja tarefa é criar o tensor de habilidades gerais informativas para cada agente. Esse tensor representa uma forma concentrada de características essenciais, capazes de descrever o comportamento e os objetivos do agente no contexto atual do mercado. Em condições de alta volatilidade e imprevisibilidade dos instrumentos financeiros, tal abstração permite aumentar a robustez da estratégia, reduzindo a sensibilidade a ruídos de curto prazo e valores atípicos.
É importante compreender que o tensor de habilidades será posteriormente utilizado como parte dos dados brutos na formação da política de comportamento do Agente. Sua presença aumenta significativamente a capacidade seletiva do modelo, o que permite separar com mais precisão ações potencialmente rentáveis das sem perspectiva. Assim, reinterpretamos os dados analisados em termos de tarefas e competências. Já não se trata mais do clássico “state → action”, mas de uma transição interpretável: “contexto → habilidade → ação”.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSkillsEncoder; descr.count = HistoryBars; { int temp[] = {BarDescr, NSkills, 4}; // Variables, Common Skills, Heads if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.window = 8; descr.step = 1; descr.window_out = 32; prev_count = descr.windows[0]; int prev_out = descr.windows[1]; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Com o objetivo de aumentar a eficácia das ações dos agentes considerando a dinâmica de mudança do tensor de habilidades gerais, adicionamos em seguida um bloco LSTM recorrente. Esse elemento da arquitetura desempenha um papel fundamental na compreensão da estrutura temporal dos dados de mercado observados. Os mercados financeiros, como se sabe, possuem forte dependência de estados anteriores, e grande parte da lógica do mercado está escondida justamente em padrões temporais.
É exatamente aqui que o LSTM (Long Short-Term Memory) se revela uma ferramenta indispensável. Sua memória interna permite conservar e atualizar informações sobre transições de mercado importantes e padrões internos, sem perder o contexto mesmo em dependências de longo prazo. Dessa maneira, o modelo aprende não apenas a reconhecer as condições atuais do mercado, mas também a prever potenciais reversões ou continuações do movimento, baseando-se na estrutura complexa das observações passadas.
A conexão do bloco LSTM após a camada de geração de habilidades é uma decisão arquitetural consciente. Primeiro, o modelo extrai uma representação abstrata do estado atual e dos objetivos do agente na forma de um tensor de habilidades; depois, o bloco LSTM acompanha a evolução dessas habilidades ao longo do tempo. Isso permite que o agente perceba não apenas um “instantâneo estático” do mercado, mas também observe como seu perfil estratégico muda com o tempo, por exemplo, como o padrão dominante de tendência se altera, como se formam níveis de suporte e resistência, e como se comporta a volatilidade.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLSTMOCL; descr.count = prev_out; // Common Skkills descr.layers = prev_count; // Variables descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Em seguida, conectamos de forma sequencial duas camadas convolucionais, cada uma desempenhando seu papel específico no processamento dos séries temporais multidimensionais provenientes dos níveis anteriores. Essas camadas convolucionais funcionam como uma espécie de MLP com cabeças de previsão independentes, projetadas para análise autônoma e previsão da continuação de componentes unitárias de uma sequência de mercado complexa em um horizonte de planejamento definido.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = prev_out; descr.step = prev_out; prev_out=descr.window_out = 4*NForecast; descr.layers = prev_count; descr.activation = SoftPlus; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = prev_out; descr.step = prev_out; prev_out=descr.window_out = NForecast; descr.layers = prev_count; descr.activation = TANH; if(!encoder.Add(descr)) { delete descr; return false; }
Os valores previstos das sequências unitárias são transpostos para uma representação de série temporal multidimensional.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_out; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
E, o que é igualmente importante, após todo esse processamento em cascata e transformação de características, retornamos os valores previstos ao seu escala e distribuição originais por meio da normalização reversa. Essa etapa é necessária para que os resultados do modelo permaneçam dentro de limites compreensíveis e interpretáveis para o ambiente de trading.
A aplicação da normalização reversa permite preservar a conexão entre o “mundo do modelo” e o espaço real do mercado, onde cada valor possui um significado quantitativo preciso.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = prev_count*prev_out; descr.layers = 1; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Quero lembrar que a representação latente obtida na saída do bloco de formação do tensor de habilidades gerais não é o produto final do processamento. Ela constitui uma abstração intermediária valiosa, que será posteriormente utilizada diversas vezes em vários componentes do framework Actor-Director-Critic que estamos implementando. É por essa razão que mantemos a descrição do bloco LSTM recorrente em uma variável local, garantindo assim sua disponibilidade para operações subsequentes.
//--- Latent CLayerDescription *latent = encoder.At(LatentLayer); if(!latent) return false;
Na etapa seguinte, descrevemos a arquitetura do Controlador de baixo nível. Esse módulo analisa o mesmo estado do ambiente e forma um tensor de habilidades específicas. Por isso, podemos simplesmente copiar da arquitetura do modelo anterior a descrição das duas primeiras camadas: os dados brutos e sua normalização.
//--- Task task.Clear(); //--- Input layer if(!task.Add(encoder.At(0))) { return false; } //--- layer 1 if(!task.Add(encoder.At(1))) { return false; }
Em seguida, é utilizado o objeto do Controlador de baixo nível, cuja tarefa inclui formar o tensor de habilidades específicas. Ao contrário do módulo anteriormente construído para gerar habilidades generalizadas considerando o contexto estratégico, o Controlador opera no nível tático, analisando o estado atual do ambiente.
O Controlador não apenas reage à situação, mas interpreta ativamente o complexo ambiente de mercado, extraindo dele o que pode ser chamado de "intuição" de curto prazo do agente. Com base nessa análise, é formado um tensor de habilidades específicas, que reflete as preferências imediatas e as ações que o agente deve tomar em uma situação específica.
Em seguida, ocorre a fusão de três fluxos de informações:
- A representação latente das habilidades gerais (de alto nível).
- O tensor de habilidades específicas (de baixo nível).
- A descrição normalizada do estado atual do ambiente.
O tensor combinado serve como base para a geração da matriz de ações dos agentes. Essa estrutura proporciona uma poderosa adaptabilidade ao modelo: os objetivos estratégicos são alinhados com as realidades táticas. Os padrões comportamentais dos agentes se tornam mais flexíveis, mas ainda assim subordinados à lógica geral da política de trading.
É importante destacar que o Controlador não é apenas um mecanismo de previsão de ação, mas sim um elemento semântico que conecta o mundo das intenções de alto nível com o contexto específico do mercado. Ele permite que o agente se adapte às condições de mercado em constante mudança, mantendo sua orientação estratégica.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronHiSSDLowLevelControler; descr.count = HistoryBars; { int temp[] = {latent.layers, // Variables NSkills, // Task Skills latent.count, // Common Skills NActions, // Action Space 4}; // Heads if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.window = 8; descr.step = 1; descr.window_out = 32; prev_count = descr.windows[0]; prev_out = descr.windows[3]; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = SIGMOID; if(!task.Add(descr)) { delete descr; return false; }
A seguir, passamos à descrição da arquitetura do modelo do Ator de alto nível, que é responsável pela formação da decisão final de trading. Sua tarefa é interpretar a matriz de ações proposta pelo Controlador na etapa anterior. Em outras palavras, o Ator atua como a última instância, determinando qual comportamento específico será implementado no contexto atual do mercado, com base em uma variedade de cenários táticos alternativos.
A arquitetura do Ator foi totalmente emprestada de nosso trabalho anterior. Tomamos a decisão de princípio de não adicionar ruído às ações geradas com base na matriz de alternativas possíveis. Ao contrário de muitas tarefas em aprendizado por reforço, onde a adição de ruído pode favorecer a exploração e a variabilidade, no contexto dos mercados financeiros, até mesmo uma mínima distorção na ação final pode resultar em consequências catastróficas. Mudanças na fração do volume da posição, um pequeno deslocamento nos níveis de trading, ou ainda, uma dinâmica de mercado mal interpretada. Tudo isso pode levar a perdas significativas e, como consequência, à diminuição da confiança no sistema.
Na modelo de previsão de probabilidades para a direção do movimento futuro, fizemos apenas ajustes pontuais, relacionados à transferência do estado latente do Codificador da descrição do estado do ambiente do módulo de geração de habilidades gerais para o bloco recorrente. Essa pequena, mas importante alteração visa melhorar a capacidade do modelo de considerar dependências temporais e se adaptar às condições de mercado em dinâmica.
Como neste trecho do artigo buscamos manter a concisão da exposição, optamos por não incluir uma descrição completa e detalhada das arquiteturas desses modelos. No entanto, todos os leitores interessados podem consultar a descrição completa e os detalhes da implementação no anexo do artigo.
Praticamente todos os modelos descritos acima formam uma estrutura hierárquica do Ator dentro do framework Actor–Director–Critic. O próximo componente importante do framework que estamos implementando é o Diretor (Director), um modelo especializado, cuja principal tarefa é a classificação contextual das ações do Ator como lucrativas ou prejudiciais.
A função do Diretor não pode ser subestimada: ele atua como um filtro de qualidade estratégica, descartando decisões potencialmente prejudiciais antes mesmo de serem realizadas e causarem perdas financeiras. Em condições de mercados financeiros altamente voláteis, onde cada erro pode ser custoso, tal mecanismo de avaliação precoce adquire uma importância especial.
A particularidade do método proposto é que o Diretor não apenas classifica as ações, mas também gera um feedback de treinamento adicional. Isso acelera a adaptação da estratégia do Ator, pois permite que ele leve em consideração os sinais do Diretor sem precisar acumular repetidamente experiências negativas. Esse mecanismo é especialmente eficaz quando o custo de erro é alto e o tempo de treinamento é limitado.
Em implementações tradicionais, o Diretor recebe como entrada um tensor de descrição do estado do ambiente, refletindo diretamente as observações do Agente. No entanto, em nossa implementação, o Diretor recebe uma matriz de habilidades gerais, uma representação latente informativa, formada no módulo de geração de habilidades a partir da saída do bloco LSTM, previamente treinado para extrair padrões comportamentais de séries temporais multidimensionais. Essa representação já leva em conta a dinâmica das mudanças no ambiente, está filtrada de sinais irrelevantes e concentra os aspectos mais significativos do contexto atual. Graças a isso, o Diretor trabalha em um espaço de características comprimido e robusto, o que aumenta consideravelmente a precisão da classificação, melhora a estabilidade das decisões e permite uma adaptação ao mercado real em tempo real.
Pelo principal fluxo de informações, o Diretor recebe como entrada o tensor de ações do Agente, o qual normalizamos imediatamente.
//--- Director director.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = None; descr.optimization = ADAM; if(!director.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = NActions; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!director.Add(descr)) { delete descr; return false; }
A análise direta das ações propostas pelo Ator no contexto da situação atual do mercado, refletida na matriz de habilidades gerais, é realizada no módulo de atenção cruzada. É nesse ponto que ocorre a correspondência semântica entre o que o agente pretende fazer e o que, no momento atual, é realmente relevante e justificado do ponto de vista da dinâmica de mercado.
O mecanismo de atenção cruzada permite ao Diretor identificar as inter-relações entre os componentes individuais do tensor de ações e as características da matriz de habilidades gerais. Isso é especialmente importante em mercados altamente voláteis, onde as simples dependências lineares já não são eficazes. A atenção cruzada, em essência, permite que o modelo se concentre nos aspectos do comportamento do Agente que são mais críticos em uma situação específica.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossDMHAttention; { int temp[] = {3, // Inputs window latent.count // Cross window }; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } { int temp[] = {NActions/3, // Inputs units latent.layers // Cross units }; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.step = 4; // Heads descr.window_out = 32; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!director.Add(descr)) { delete descr; return false; }
Na saída do módulo de atenção cruzada, é gerada uma representação semântica rica da ação do Ator, já adaptada ao contexto atual do mercado. Essa representação reflete não apenas a intenção do Agente, mas também sua adequação à situação atual, considerando todos os padrões e inter-relações identificados entre as ações e as habilidades gerais.
Essa representação enriquecida pelo contexto torna-se a base para a etapa final de processamento, que consiste na classificação da ação com base em sua potencial lucratividade.
O procedimento de classificação é realizado por meio de uma sequência de três camadas neurais totalmente conectadas, cada uma equipada com sua própria função de ativação, permitindo incorporar a não linearidade necessária nos dados processados. Esse cascamento oferece à modelagem a flexibilidade para aproximar limites complexos de tomada de decisão, criando uma separação mais precisa entre ações lucrativas e prejudiciais.
Na última camada, utiliza-se a função de ativação sigmoide, permitindo interpretar a saída do modelo como uma estimativa probabilística de a ação pertencer a um dos dois classes. Assim, o modelo não apenas toma uma decisão binária, mas também fornece uma avaliação da confiança na correção de sua classificação.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.batch = 1e4; descr.activation = TANH; descr.optimization = ADAM; if(!director.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SoftPlus; descr.batch = 1e4; descr.optimization = ADAM; if(!director.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = 1; descr.activation = SIGMOID; descr.batch = 1e4; descr.optimization = ADAM; if(!director.Add(descr)) { delete descr; return false; }
Vale ressaltar que o modelo do Crítico, nesta implementação, segue uma arquitetura análoga. Assim como no caso do Diretor, é utilizado o módulo de atenção cruzada, que permite correlacionar as ações propostas pelo Ator com o contexto atual do ambiente, representado pela matriz de habilidades gerais. Isso garante uma avaliação mais precisa das consequências da ação escolhida, levando em consideração as complexas dependências entre o comportamento do agente e a dinâmica oculta do mercado.
No entanto, na parte final da arquitetura do Crítico, há uma diferença fundamental. Ao contrário do Diretor, onde a sigmoide é usada para a interpretação probabilística do resultado, a camada de saída do Crítico não contém uma função de ativação. Isso se deve à natureza da variável-alvo, o valor esperado da recompensa acumulada, que pode estar em uma faixa ampla e praticamente ilimitada.
Em outras palavras, a saída do Crítico é uma avaliação escalar da utilidade da ação proposta no contexto atual, expressa em unidades condicionais de lucro esperado. A aplicação de uma função de ativação limitante distorceria o significado desse valor, cortando desvios potencialmente importantes. Por isso, o valor final é enviado diretamente, permitindo que o modelo varie livremente as estimativas de acordo com as representações aprendidas sobre o ambiente.
Mas isso é apenas um ajuste pontual na arquitetura do modelo. Por isso, deixaremos de lado a análise detalhada da arquitetura do Crítico nesta parte do artigo. A descrição completa da solução arquitetônica dos modelos mencionados está no anexo e está disponível para estudo independente.
Infelizmente, com a análise detalhada das soluções arquitetônicas, já esgotamos o espaço do artigo. Faremos uma pequena pausa e, no próximo artigo, discutiremos o processo de treinamento dos modelos e avaliaremos a eficácia da solução implementada em dados históricos reais.
Considerações finais
Neste trabalho, apresentamos um novo framework, o Actor-Director-Critic, destinado à resolução de problemas utilizando métodos de aprendizado profundo e redes neurais. Um dos aspectos-chave desse framework é a introdução do modelo Diretor*, que classifica as ações do Ator no contexto do estado atual do ambiente, permitindo aumentar significativamente a eficiência e a estabilidade do processo de treinamento.
Na parte prática do artigo, detalhamos as soluções arquitetônicas dos modelos treináveis que formam a base do framework Actor-Director-Critic. Descrevemos minuciosamente os princípios de uso dos diferentes módulos e apresentamos pontos importantes que fundamentam cada componente do sistema.
No próximo artigo, discutiremos em detalhes o processo de construção de programas para o treinamento dos modelos apresentados, além de realizar uma avaliação de sua eficácia em dados históricos reais.
Referências
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA para coleta de exemplos |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA para coleta de exemplos utilizando o método Real-ORL |
| 3 | Study.mq5 | Expert Advisor | EA para treinamento offline de modelos |
| 4 | StudyOnline.mq5 | Expert Advisor | EA para treinamento online de modelos |
| 4 | Test.mq5 | Expert Advisor | EA para teste de modelo |
| 5 | Trajectory.mqh | Biblioteca de classe | Estrutura para descrição do estado do sistema e arquitetura dos modelos |
| 6 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de redes neurais |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código para programas OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/17796
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso