
Gradient Boosting (CatBoost) no desenvolvimento de sistemas de negociação. Uma abordagem ingênua
Introdução
O gradient boosting é um algoritmo de aprendizado de máquina poderoso. O método produz um conjunto de modelos fracos (por exemplo, árvores de decisão), nos quais (em contraste com o bagging) os modelos não são construídos em paralelo, mas de maneira sequêncial. Isso significa que a próxima árvore aprende com os erros da anterior, então esse processo se repete, aumentando o número de modelos fracos. Isso cria um modelo forte que pode generalizar utilizando os dados heterogêneos. Neste experimento, eu usei a biblioteca CatBoost desenvolvida por Yandex. Ela é uma das bibliotecas mais populares, junto com a XGboost e LightGBM.
O objetivo do artigo é demonstrar a criação de um modelo baseado em aprendizado de máquina. O processo de criação consiste nas seguintes etapas:
- receber e pré-processar os dados
- treinar o modelo usando os dados preparados
- teste o modelo em um testador de estratégia personalizado
- portar o modelo para a MetaTrader 5
A linguagem Python e a biblioteca MetaTrader 5 são usadas para preparar os dados e treinar o modelo.
Preparando os Dados
Importamos os módulos necessários em Python:
import MetaTrader5 as mt5 import pandas as pd import numpy as np from datetime import datetime import random import matplotlib.pyplot as plt from catboost import CatBoostClassifier from sklearn.model_selection import train_test_split mt5.initialize() # check for gpu devices is availible from catboost.utils import get_gpu_device_count print('%i GPU devices' % get_gpu_device_count())
Em seguida, inicializamos todas as variáveis globais:
LOOK_BACK = 250 MA_PERIOD = 15 SYMBOL = 'EURUSD' MARKUP = 0.0001 TIMEFRAME = mt5.TIMEFRAME_H1 START = datetime(2020, 5, 1) STOP = datetime(2021, 1, 1)
Esses parâmetros são responsáveis pelo seguinte:
- look_back — profundidade do histórico analisado
- ma_period — período da média móvel para calcular os incrementos do preço
- symbol — quais símbolos devem ser carregados da plataforma MetaTrader 5
- markup — tamanho do spread para o testador personalizado
- timeframe — dados do tempo gráfico para símbolo carregado
- start, stop — intervalo dos dados
Vamos escrever uma função que recebe os dados brutos diretamente e cria um dataframe contendo as colunas necessárias para o treinamento:
def get_prices(look_back = 15): prices = pd.DataFrame(mt5.copy_rates_range(SYMBOL, TIMEFRAME, START, STOP), columns=['time', 'close']).set_index('time') # set df index as datetime prices.index = pd.to_datetime(prices.index, unit='s') prices = prices.dropna() ratesM = prices.rolling(MA_PERIOD).mean() ratesD = prices - ratesM for i in range(look_back): prices[str(i)] = ratesD.shift(i) return prices.dropna()
A função recebe os preços de fechamento para o tempo gráfico especificado e calcula a média móvel, após o qual ele calcula os incrementos (a diferença entre os preços e a média móvel). Na etapa final, ele calcula as colunas adicionais com as linhas deslocadas para trás no histórico pela variável look_back, o que significa adicionar recursos extras (atraso) ao modelo.
Por exemplo, para look_back = 10, o dataframe conterá 10 colunas adicionais com os incrementos de preço:
>>> pr = get_prices(look_back=LOOK_BACK) >>> pr close 0 1 2 3 4 5 6 7 8 9 time 2020-05-01 16:00:00 1.09750 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 0.000566 0.000285 2020-05-01 17:00:00 1.10074 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 0.000566 2020-05-01 18:00:00 1.09976 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 2020-05-01 19:00:00 1.09874 0.001577 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 2020-05-01 20:00:00 1.09817 0.000759 0.001577 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 ... ... ... ... ... ... ... ... ... ... ... ... 2020-11-02 23:00:00 1.16404 0.000400 0.000105 -0.000581 -0.001212 -0.000999 -0.000547 -0.000344 -0.000773 -0.000326 0.000501 2020-11-03 00:00:00 1.16392 0.000217 0.000400 0.000105 -0.000581 -0.001212 -0.000999 -0.000547 -0.000344 -0.000773 -0.000326 2020-11-03 01:00:00 1.16402 0.000270 0.000217 0.000400 0.000105 -0.000581 -0.001212 -0.000999 -0.000547 -0.000344 -0.000773 2020-11-03 02:00:00 1.16423 0.000465 0.000270 0.000217 0.000400 0.000105 -0.000581 -0.001212 -0.000999 -0.000547 -0.000344 2020-11-03 03:00:00 1.16464 0.000885 0.000465 0.000270 0.000217 0.000400 0.000105 -0.000581 -0.001212 -0.000999 -0.000547 [3155 rows x 11 columns]
O destaque em amarelo indica que cada coluna tem o mesmo conjunto de dados, mas com um deslocamento. Portanto, cada linha é um exemplo de treinamento separado.
Criação dos rótulos de treinamento (Amostragem Aleatória)
Os exemplos de treinamento são as coleções de características e seus rótulos correspondentes. O modelo deve produzir certas informações, que o modelo deve aprender a prever. Vamos considerar a classificação binária, na qual o modelo irá prever a probabilidade de determinar o exemplo de treinamento como classe 0 ou 1. Zeros e uns podem ser usados para a direção da negociação: comprar ou vender. Em outras palavras, o modelo deve aprender a prever a direção de uma negociação para os parâmetros de ambiente (conjunto de características).
def add_labels(dataset, min, max): labels = [] for i in range(dataset.shape[0]-max): rand = random.randint(min, max) if dataset['close'][i] >= (dataset['close'][i + rand]): labels.append(1.0) elif dataset['close'][i] <= (dataset['close'][i + rand]): labels.append(0.0) else: labels.append(0.0) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() return dataset
A função add_labels (no intervalo mínimo e máximo) define aleatoriamente a duração de cada negociação em barras. Ao alterar a duração máxima e mínima, você altera a frequência de amostragem do negócio. Portanto, se o preço atual for maior do que o próximo 'rand' das barras à frente, esse será um rótulo de venda (1). No caso oposto, o rótulo é 0. Vamos ver como fica o conjunto de dados depois de aplicar a função acima:
>>> pr = add_labels(pr, 10, 25) >>> pr close 0 1 2 3 4 5 6 7 8 9 labels time 2020-05-01 16:00:00 1.09750 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 0.000566 0.000285 1.0 2020-05-01 17:00:00 1.10074 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 0.000566 1.0 2020-05-01 18:00:00 1.09976 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 1.0 2020-05-01 19:00:00 1.09874 0.001577 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 1.0 2020-05-01 20:00:00 1.09817 0.000759 0.001577 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 1.0 ... ... ... ... ... ... ... ... ... ... ... ... ... 2020-10-29 20:00:00 1.16700 -0.003651 -0.005429 -0.005767 -0.006750 -0.004699 -0.004328 -0.003475 -0.003769 -0.002719 -0.002075 1.0 2020-10-29 21:00:00 1.16743 -0.002699 -0.003651 -0.005429 -0.005767 -0.006750 -0.004699 -0.004328 -0.003475 -0.003769 -0.002719 0.0 2020-10-29 22:00:00 1.16731 -0.002276 -0.002699 -0.003651 -0.005429 -0.005767 -0.006750 -0.004699 -0.004328 -0.003475 -0.003769 0.0 2020-10-29 23:00:00 1.16740 -0.001648 -0.002276 -0.002699 -0.003651 -0.005429 -0.005767 -0.006750 -0.004699 -0.004328 -0.003475 0.0 2020-10-30 00:00:00 1.16695 -0.001655 -0.001648 -0.002276 -0.002699 -0.003651 -0.005429 -0.005767 -0.006750 -0.004699 -0.004328 1.0
A coluna 'labels' foi adicionada, contendo o número da classe (0 ou 1) para compra e venda, respectivamente. Agora, cada exemplo de treinamento ou conjunto de características (que são 10 aqui) tem seu próprio rótulo, que indica sob quais condições você deve comprar e sob quais condições você deve vender (ou seja, a qual classe ele pertence). O modelo deve ser capaz de lembrar e generalizar esses exemplos — essa capacidade será discutida mais tarde.
Desenvolvendo um Testador Personalizado
Já que nós estamos criando um sistema de negociação, seria bom ter um testador de estratégia para testar o modelo em tempo hábil. Abaixo está um exemplo desse testador:
def tester(dataset, markup = 0.0): last_deal = int(2) last_price = 0.0 report = [0.0] for i in range(dataset.shape[0]): pred = dataset['labels'][i] if last_deal == 2: last_price = dataset['close'][i] last_deal = 0 if pred <=0.5 else 1 continue if last_deal == 0 and pred > 0.5: last_deal = 1 report.append(report[-1] - markup + (dataset['close'][i] - last_price)) last_price = dataset['close'][i] continue if last_deal == 1 and pred <=0.5: last_deal = 0 report.append(report[-1] - markup + (last_price - dataset['close'][i])) last_price = dataset['close'][i] return report
A função do testador aceita um conjunto de dados e uma 'marcação' (opcional) e verifica todo o conjunto de dados, da mesma forma como é feito no testador da MetaTrader 5. Um sinal (rótulo) é verificado em cada nova barra e quando o rótulo muda, a negociação é revertida. Assim, um sinal de venda serve como um sinal para fechar uma posição de compra e para abrir uma posição de venda. Agora, vamos testar o conjunto de dados acima:
pr = get_prices(look_back=LOOK_BACK) pr = add_labels(pr, 10, 25) rep = tester(pr, MARKUP) plt.plot(rep) plt.show()
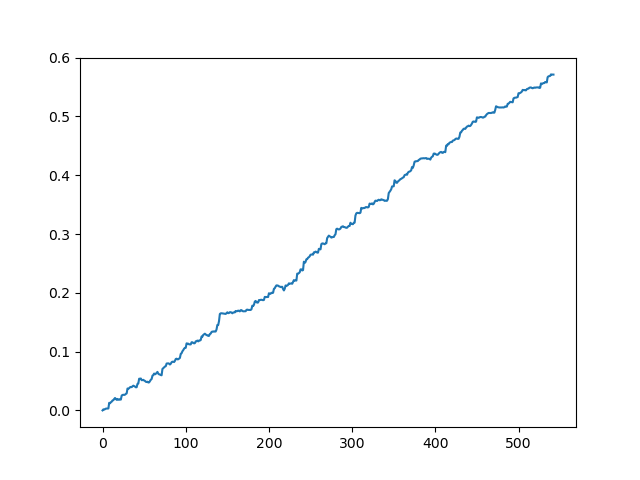
Testando o conjunto de dados original sem spread
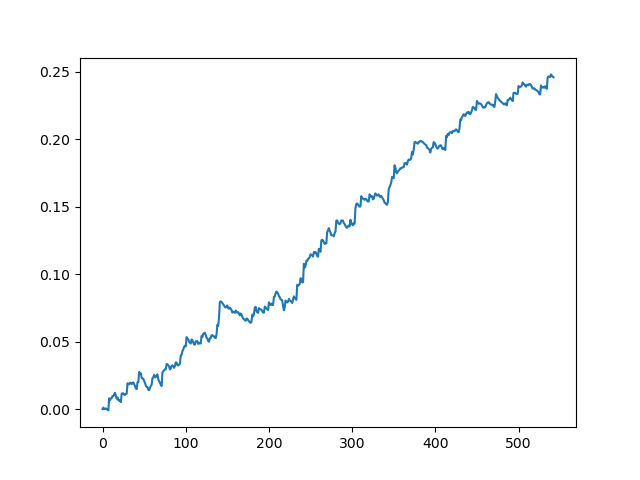
Testando o conjunto de dados original com uma propagação de 70 pontos de cinco dígitos
Esta é uma espécie de imagem idealizada (é assim que nós queremos que o modelo funcione). Como os rótulos são amostrados aleatoriamente, dependendo de uma gama de parâmetros responsáveis pela vida útil mínima e máxima das negociações, as curvas sempre serão diferentes. No entanto, todos eles mostrarão um bom aumento de pontos (ao longo do eixo Y) e um número diferente de negócios (ao longo do eixo X).
Treinamento do modelo CatBoost
Agora, vamos prosseguir diretamente para o treinamento do modelo. Primeiro, vamos dividir o conjunto de dados em dois exemplos: treinamento e validação. Isso é usado para reduzir o overfitting do modelo. Enquanto o modelo continua a treinar na subamostra de treinamento, tentando minimizar o erro de classificação, o mesmo erro também é medido na subamostra de validação. Se a diferença nesses erros for grande, o modelo é considerado excessivamente adequado. Por outro lado, os valores próximos indicam o treinamento adequado de um modelo.
#splitting on train and validation subsets X = pr[pr.columns[1:-1]] y = pr[pr.columns[-1]] train_X, test_X, train_y, test_y = train_test_split(X, y, train_size = 0.5, test_size = 0.5, shuffle=True)
Vamos dividir os dados em dois conjuntos de dados com comprimentos iguais, depois de misturar aleatoriamente os exemplos de treinamento. Em seguida, criamos e treinamos o modelo:
#learning with train and validation subsets model = CatBoostClassifier(iterations=1000, depth=6, learning_rate=0.01, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=True, use_best_model=True, task_type='CPU') model.fit(train_X, train_y, eval_set = (test_X, test_y), early_stopping_rounds=50, plot=False)
O modelo usa vários parâmetros, embora nem todos sejam mostrados neste exemplo. Você pode consultar a documentação, se desejar ajustar o modelo, o que não é obrigatório como regra. O CatBoost funciona bem fora da caixa, com ajuste mínimo.
Aqui está uma breve descrição dos parâmetros do modelo:
- iterations — o número máximo de árvores no modelo. O modelo aumenta o número de modelos fracos (árvores) após cada iteração, portanto, certifique-se de definir um valor grande o suficiente. Pela minha prática, 1000 iterações para este exemplo específico são normalmente mais do que suficientes.
- depth — a profundidade de cada árvore. Quanto menor a profundidade, mais grosseiro é o modelo - gerando menos negócios. A profundidade entre 6 e 10 parece ótima.
- learning_rate — valor do passo do gradiente; este é o mesmo princípio usado nas redes neurais. Um intervalo razoável de parâmetros é 0.01 - 0.1. Quanto menor o valor, mais tempo o modelo leva para treinar. Mas, neste caso, ele pode encontrar variantes melhores.
- custom_loss, eval_metric — a métrica usada para avaliar o modelo. A métrica clássica para a classificação é a 'precisão'
- use_best_model — em cada passo, o modelo avalia a 'precisão', que pode mudar com o tempo. Esta flag permite salvar o modelo com o mínimo de erro. Caso contrário, o modelo obtido na última iteração será salvo
- task_type — permite treinar o modelo em uma GPU (a CPU é usada por padrão). Isso só é relevante no caso de dados muito grandes; em outros casos, o treinamento é executado mais lentamente nos núcleos da GPU do que no processador.
- early_stopping_rounds — o modelo possui um detector de overfitting embutido que opera de acordo com um princípio simples. Se a métrica parar de diminuir/aumentar (para a 'precisão', ela para de aumentar) durante o número especificado de iterações, o treinamento é encerrado.
Após o início do treinamento, o estado atual do modelo em cada iteração será exibido no console:
170: learn: 1.0000000 test: 0.7712509 best: 0.7767795 (165) total: 11.2s remaining: 21.5s 171: learn: 1.0000000 test: 0.7726330 best: 0.7767795 (165) total: 11.2s remaining: 21.4s 172: learn: 1.0000000 test: 0.7733241 best: 0.7767795 (165) total: 11.3s remaining: 21.3s 173: learn: 1.0000000 test: 0.7740152 best: 0.7767795 (165) total: 11.3s remaining: 21.3s 174: learn: 1.0000000 test: 0.7712509 best: 0.7767795 (165) total: 11.4s remaining: 21.2s 175: learn: 1.0000000 test: 0.7726330 best: 0.7767795 (165) total: 11.5s remaining: 21.1s 176: learn: 1.0000000 test: 0.7712509 best: 0.7767795 (165) total: 11.5s remaining: 21s 177: learn: 1.0000000 test: 0.7740152 best: 0.7767795 (165) total: 11.6s remaining: 21s 178: learn: 1.0000000 test: 0.7719419 best: 0.7767795 (165) total: 11.7s remaining: 20.9s 179: learn: 1.0000000 test: 0.7747063 best: 0.7767795 (165) total: 11.7s remaining: 20.8s 180: learn: 1.0000000 test: 0.7705598 best: 0.7767795 (165) total: 11.8s remaining: 20.7s Stopped by overfitting detector (15 iterations wait) bestTest = 0.7767795439 bestIteration = 165
No exemplo acima, o detector de overfitting disparou e parou o treinamento na iteração 180. Além disso, o console exibe estatísticas para a subamostra de treinamento (aprendizado) e a subamostra de validação (teste), bem como o tempo total de treinamento do modelo, que foi de apenas 20 segundos. Na saída, nós obtivemos a melhor precisão na subamostra de treinamento 1.0 (que corresponde ao resultado ideal) e a precisão de 0.78 na subamostra de validação, que é pior, mas ainda está acima de 0.5 (que é considerada aleatória). A melhor iteração é 165 — este modelo é salvo. Agora, nós podemos testar em nosso Testador:
#test the learned model p = model.predict_proba(X) p2 = [x[0]<0.5 for x in p] pr2 = pr.iloc[:len(p2)].copy() pr2['labels'] = p2 rep = tester(pr2, MARKUP) plt.plot(rep) plt.show()
X - é o conjunto de dados de origem com as características, mas sem os rótulos. Para a obtenção dos rótulos, é necessário obtê-los do modelo treinado e prever as probabilidades 'p' de atribuição à classe 0 ou 1. Como o modelo gera as probabilidades para as duas classes, enquanto nós precisamos apenas de 0s ou 1s, a variável 'p2' recebe as probabilidades apenas na primeira dimensão (0). Além disso, os rótulos no conjunto de dados original são substituídos pelos rótulos previstos pelo modelo. Aqui estão os resultados do Testador:
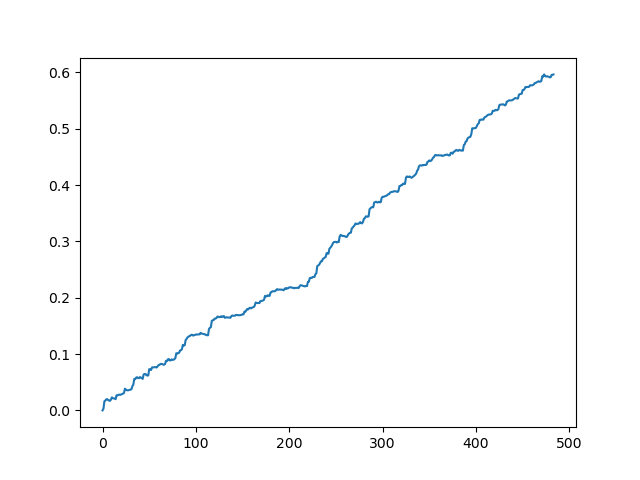
O resultado ideal após a amostragem das negociações
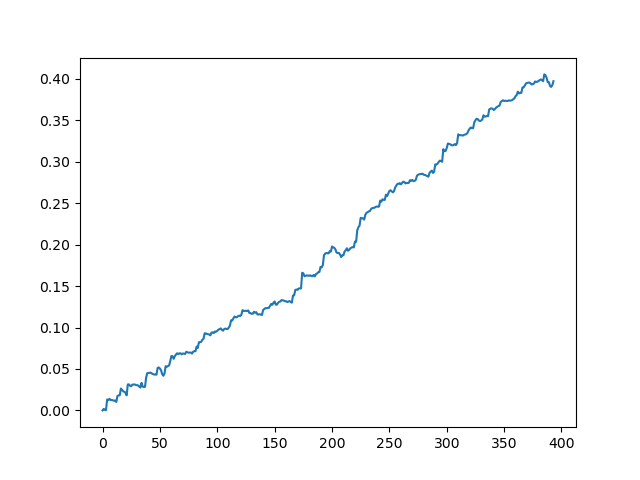
O resultado obtido na saída do modelo
Como você pode ver, o modelo aprendeu bem, o que significa que se lembrou dos exemplos de treinamento e mostrou um resultado melhor do que o aleatório no conjunto de validação. Vamos passar para o estágio final: exportar o modelo e criar um robô de negociação.
Portando o modelo para a MetaTrader 5
A API em Python da MetaTrader 5 permite a negociação diretamente de um programa em python e, portanto, não há necessidade de portar o modelo. No entanto, eu queria verificar no meu testador personalizado e compará-lo com o testador de estratégia padrão. Além disso, a disponibilidade de um bot compilado pode ser conveniente em muitas situações, incluindo o uso em um VPS (neste caso, você não terá que instalar o Python). Portanto, eu escrevi uma função auxiliar que salva um modelo pronto em um arquivo MQH. A função é a seguinte:
def export_model_to_MQL_code(model):
model.save_model('catmodel.h',
format="cpp",
export_parameters=None,
pool=None)
code = 'double catboost_model' + '(const double &features[]) { \n'
code += ' '
with open('catmodel.h', 'r') as file:
data = file.read()
code += data[data.find("unsigned int TreeDepth"):data.find("double Scale = 1;")]
code +='\n\n'
code+= 'return ' + 'ApplyCatboostModel(features, TreeDepth, TreeSplits , BorderCounts, Borders, LeafValues); } \n\n'
code += 'double ApplyCatboostModel(const double &features[],uint &TreeDepth_[],uint &TreeSplits_[],uint &BorderCounts_[],float &Borders_[],double &LeafValues_[]) {\n\
uint FloatFeatureCount=ArrayRange(BorderCounts_,0);\n\
uint BinaryFeatureCount=ArrayRange(Borders_,0);\n\
uint TreeCount=ArrayRange(TreeDepth_,0);\n\
bool binaryFeatures[];\n\
ArrayResize(binaryFeatures,BinaryFeatureCount);\n\
uint binFeatureIndex=0;\n\
for(uint i=0; i<FloatFeatureCount; i++) {\n\
for(uint j=0; j<BorderCounts_[i]; j++) {\n\
binaryFeatures[binFeatureIndex]=features[i]>Borders_[binFeatureIndex];\n\
binFeatureIndex++;\n\
}\n\
}\n\
double result=0.0;\n\
uint treeSplitsPtr=0;\n\
uint leafValuesForCurrentTreePtr=0;\n\
for(uint treeId=0; treeId<TreeCount; treeId++) {\n\
uint currentTreeDepth=TreeDepth_[treeId];\n\
uint index=0;\n\
for(uint depth=0; depth<currentTreeDepth; depth++) {\n\
index|=(binaryFeatures[TreeSplits_[treeSplitsPtr+depth]]<<depth);\n\
}\n\
result+=LeafValues_[leafValuesForCurrentTreePtr+index];\n\
treeSplitsPtr+=currentTreeDepth;\n\
leafValuesForCurrentTreePtr+=(1<<currentTreeDepth);\n\
}\n\
return 1.0/(1.0+MathPow(M_E,-result));\n\
}'
file = open('C:/Users/dmitrievsky/AppData/Roaming/MetaQuotes/Terminal/D0E8209F77C8CF37AD8BF550E51FF075/MQL5/Include/' + 'cat_model' + '.mqh', "w")
file.write(code)
file.close()
print('The file ' + 'cat_model' + '.mqh ' + 'has been written to disc')
O código da função parece estranho e desajeitado. O objeto de modelo treinado é inserido na função, que então salva o objeto no formato em C++:
model.save_model('catmodel.h',
format="cpp",
export_parameters=None,
pool=None)
Em seguida, uma string é criada e o código C++ é analisado em MQL5 usando as funções em Python padrão:
code = 'double catboost_model' + '(const double &features[]) { \n' code += ' ' with open('catmodel.h', 'r') as file: data = file.read() code += data[data.find("unsigned int TreeDepth"):data.find("double Scale = 1;")] code +='\n\n' code+= 'return ' + 'ApplyCatboostModel(features, TreeDepth, TreeSplits , BorderCounts, Borders, LeafValues); } \n\n'
A função 'ApplyCatboostModel' desta biblioteca é inserida após as manipulações acima. Ela retorna o resultado calculado no intervalo entre (0;1), com base no modelo salvo e no vetor de características passado.
Depois disso, nós precisamos especificar o caminho para a pasta \\Include da plataforma MetaTrader 5 na qual o modelo será salvo. Assim, após configurar todos os parâmetros, o modelo é treinado com um clique e salvo imediatamente como um arquivo MQH, o que é muito conveniente. Essa opção também é boa porque é uma prática comum e popular para ensinar modelos em Python.
Escrevendo um robô de negociação na MetaTrader 5
Depois de treinar e salvar um modelo CatBoost, nós precisamos escrever um robô simples para teste:
#include <MT4Orders.mqh> #include <Trade\AccountInfo.mqh> #include <cat_model.mqh> sinput int look_back = 50; sinput int MA_period = 15; sinput int OrderMagic = 666; //Orders magic sinput double MaximumRisk=0.01; //Maximum risk sinput double CustomLot=0; //Custom lot input int stoploss = 500; static datetime last_time=0; #define Ask SymbolInfoDouble(_Symbol, SYMBOL_ASK) #define Bid SymbolInfoDouble(_Symbol, SYMBOL_BID) int hnd;
Agora, incluímos a cat_model.mqh salva e a MT4Orders.mqh por fxsaber.
Os parâmetros look_back e MA_period devem ser definidos exatamente como foram especificados durante o treinamento no programa em Python, caso contrário, será gerado um erro.
Além disso, em cada barra, nós verificamos o sinal do modelo, no qual o vetor de incrementos (diferença entre o preço e a média móvel) é inserido:
if(!isNewBar()) return; double ma[]; double pr[]; double ret[]; ArrayResize(ret, look_back); CopyBuffer(hnd, 0, 1, look_back, ma); CopyClose(NULL,PERIOD_CURRENT,1,look_back,pr); for(int i=0; i<look_back; i++) ret[i] = pr[i] - ma[i]; ArraySetAsSeries(ret, true); double sig = catboost_model(ret);
A lógica de abertura de negociação é semelhante à lógica do testador personalizado, mas ela é realizada no estilo mql5 + MT4Orders:
for(int b = OrdersTotal() - 1; b >= 0; b--) if(OrderSelect(b, SELECT_BY_POS) == true) { if(OrderType() == 0 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig > 0.5) if(OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red)) { } if(OrderType() == 1 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig < 0.5) if(OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red)) { } } if(countOrders(0) == 0 && countOrders(1) == 0) { if(sig < 0.5) OrderSend(Symbol(),OP_BUY,LotsOptimized(), Ask, 0, Bid-stoploss*_Point, 0, NULL, OrderMagic); else if(sig > 0.5) OrderSend(Symbol(),OP_SELL,LotsOptimized(), Bid, 0, Ask+stoploss*_Point, 0, NULL, OrderMagic); return; }
Testando o robô utilizando aprendizado de máquina
O robô compilado pode ser testado no Testador de Estratégia padrão da MetaTrader 5. Selecionamos um tempo gráfico adequado (que deve corresponder ao utilizado no treinamento do modelo) e as entradas look_back e MA_period, que também deve corresponder aos parâmetros do programa em Python. Vamos verificar o modelo no período de treinamento (subamostras treinamento + validação):
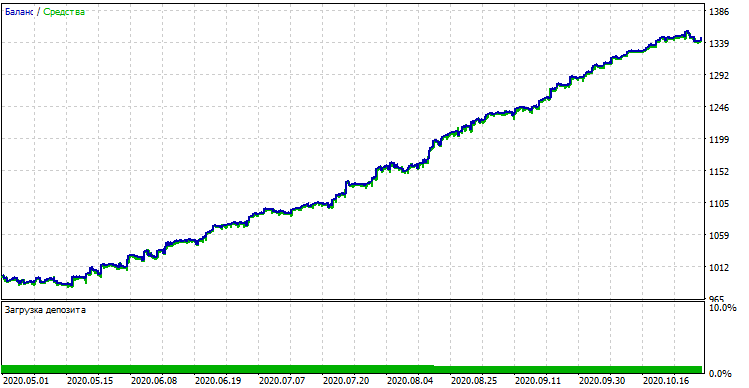
Desempenho do modelo (subamostras de treinamento + validação)
Se nós compararmos o resultado com o obtido no testador personalizado, esses resultados são iguais, exceto por alguns desvios do spread. Agora, vamos testar o modelo usando os dados absolutamente novos, desde o início do ano:
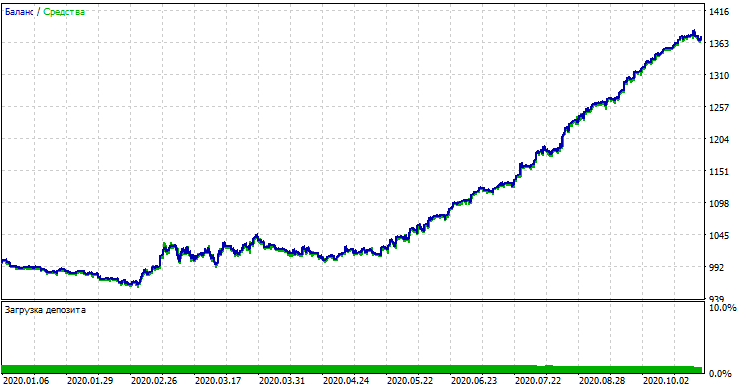
Desempenho do modelo em novos dados
O modelo teve um desempenho significativamente pior com os novos dados. Esse resultado ruim está relacionado a razões objetivas, que eu tentarei descrever mais adiante.
De modelos ingênuos a modelos significativos (pesquisa adicional)
O artigo intitulado afirma que nós estamos usando "A Abordagem Ingênua". Ela é ingênua pelos seguintes motivos:
- O modelo não inclui os dados anteriores sobre os padrões. A identificação de qualquer padrão é totalmente realizada pelo aumento do gradiente, cujas possibilidades são, no entanto, limitadas.
- O modelo usa uma amostra aleatória de negócios, portanto, os resultados em diferentes ciclos de treinamento podem ser diferentes. Isso não é apenas uma desvantagem, mas também pode ser considerado uma vantagem, pois esse recurso permite a abordagem de força bruta.
- Nenhuma característica da população em geral é conhecida no treinamento. Você nunca sabe como o modelo se comportará com os novos dados.
Possíveis maneiras de melhorar o desempenho do modelo (a serem abordadas em um artigo separado):
- Seleção de modelos por algum critério externo (por exemplo, desempenho nos novos dados)
- Novas abordagens para amostragem de dados e treinamento do modelo, empilhamento de classificadores
- Seleção de características de natureza diferente, com base nos conhecimentos e/ou suposições a priori
Conclusão
Este artigo considera o excelente modelo de aprendizado de máquina denominado CatBoost: nós discutimos os principais aspectos relacionados à configuração do modelo e ao treinamento de classificação binária em problemas de previsão de séries temporais. Nós preparamos e testamos um modelo, bem como o portamos para a linguagem MQL como um robô pronto. Os aplicativos em Python e MQL estão anexados abaixo.
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/8642
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.
 Redes Neurais de Maneira Fácil(Parte 7): Métodos de otimização adaptativos
Redes Neurais de Maneira Fácil(Parte 7): Métodos de otimização adaptativos
 Redes neurais de Maneira Fácil (Parte 6): Experimentos com a taxa de aprendizado da rede neural
Redes neurais de Maneira Fácil (Parte 6): Experimentos com a taxa de aprendizado da rede neural
 Perceptron Multicamadas e o Algoritmo Backpropagation
Perceptron Multicamadas e o Algoritmo Backpropagation
 Conjunto de ferramentas para marcação manual de gráficos e negociação (Parte II). Fazendo a marcação
Conjunto de ferramentas para marcação manual de gráficos e negociação (Parte II). Fazendo a marcação
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
prices.dropna()Isso não funcionou no final. O arquivo ainda continha valores Nan. Isso foi resolvido com a simples exclusão de linhas.
Parece que não consigo reproduzir os resultados do testador python. O testador MT5 não está reproduzindo os resultados para o mesmo período no testador python.
Por outro lado, eu transferi o modelo conforme explicado.
Coloquei cat_model.mqh e cat_trader.mql5 (compilado em .ex5).
Mas os resultados parecem diferentes.
Aqui você pode ver o código do modelo. Anote MA_Period, Look_Back, etc. Em seguida, observe a curva de lucro do testador de código python. Em seguida, observe as entradas, as configurações e os resultados do testador de estratégia do MT5.
Parece que não consigo reproduzir os resultados do testador python. O testador MT5 não está reproduzindo os resultados para o mesmo período no testador python.
Por outro lado, eu transferi o modelo conforme explicado.
Coloquei cat_model.mqh e cat_trader.mql5 (compilado em .ex5).
Mas os resultados parecem diferentes.
Olá, pode haver uma diferença entre a forma como o modelo foi analisado quando o artigo foi escrito e como isso acontece agora. O CatBoost pode ter alterado a lógica do código do modelo final nas novas versões, portanto, você terá que descobrir isso.
Parece-me que há uma grande probabilidade de que isso possa ser um problema.
Fiz algumas alterações:
Alterei o código para salvar o mqh de acordo com o tempo gráfico dos dados.
Alterei o mqh para ser diferente para cada período de tempo, para que seja possível ter todos os períodos de tempo treinados e prontos para uso no EA.
Alterei o EA para usar todos os arquivos treinados para análise e geração de sinais.
Todos os arquivos estão anexados para sua análise, se possível.
Se você puder melhorar o código eu ficaria grato.
A estratégia e também o treinamento do modelo precisam de melhorias extremas, se possível agradeço ajuda.
fiz algumas alterações:
alterei o código para salvar o mqh diacordo com o tempo gráfico dos dados.
alterei o mqh para ser diferenciado para cada tempo gráfico, com isso é possível ter todos os tempos gráficos treinados e prontos para usar no EA.
alterei o EA para usar todos os arquivos treinados para análise e geração de sinais.
estao anexos todos os arquivos para sua analise se possivel.
se tiver como melhorar o código fico agradecido.
a estratégia e também o treinamento do modelo precisa de melhorias extremas, se possível ajudar obrigado.