
Ekonomik tahminler: Python’ın potansiyelini keşfetme

Giriş
Ekonomik tahmin oldukça karmaşık ve yoğun emek gerektiren bir iştir. Geçmiş verileri kullanarak gelecekteki olası hareketleri analiz etmemizi sağlar. Geçmiş verileri ve mevcut ekonomik göstergeleri analiz ederek, ekonominin nereye doğru gidebileceği konusunda spekülasyon yapabiliriz. Bu oldukça kullanışlı bir beceridir. Onun yardımıyla iş dünyasında, yatırımlarda ve ekonomi politikalarında daha bilinçli kararlar verebiliriz.
Python ve ekonomik verileri kullanarak, bilgi toplamadan tahmin modelleri oluşturmaya kadar, bu aracı geliştireceğiz. Bu araç, analizler yapmalı ve aynı zamanda geleceğe yönelik tahminlerde bulunmalıdır.
Finansal piyasalar ekonominin iyi bir barometresidir. En ufak değişikliklere tepki verirler. Sonuç öngörülebilir ya da beklenmedik olabilir. Şimdi gösterge değerlerinin bu barometrenin dalgalanmasına neden olduğu örneklere bakalım.
GSYİH büyüdüğünde piyasalar genellikle olumlu tepki verir. Enflasyon yükseldiğinde genellikle huzursuzluk beklenir. İşsizlik düştüğünde, bu genellikle iyi bir haber olarak görülür. Ancak, istisnalar da olabilir. Ticaret dengesi, faiz oranları - her gösterge piyasa duyarlılığını etkiler.
Pratikte görüldüğü üzere, piyasalar genellikle gerçek sonuca değil, oyuncuların çoğunluğunun beklentilerine göre tepki vermektedir. "Söylentileri satın al, gerçekleri sat" - bu eski borsa bilgeliği, olup bitenlerin özünü en doğru şekilde yansıtıyor. Ayrıca, önemli değişikliklerin olmaması piyasada beklenmedik haberlerden daha fazla volatiliteye neden olabilir.
Ekonomi karmaşık bir sistemdir. Burada her şey birbiriyle bağlantılıdır ve bir faktör diğerini etkiler. Bir parametredeki değişiklik zincirleme bir reaksiyon başlatabilir. Bizim görevimiz bu bağlantıları anlamak ve analiz etmeyi öğrenmektir. Python aracını kullanarak çözümler arayacağız.
Ortamın ayarlanması: Gerekli kütüphanelerin içe aktarılması
Peki, neye ihtiyacımız var? İlk önce Python. Henüz yüklemediyseniz, python.org adresine gidin. Ayrıca, yükleme işlemi sırasında "Add Python to PATH" kutusunu işaretlemeyi unutmayın.
Bir sonraki adım kütüphanelerdir. Kütüphaneler, aracımızın temel yeteneklerini önemli ölçüde genişletir. Şunlara ihtiyacımız olacak:
- pandas - verileri işlemek için.
- wbdata - Dünya Bankası ile etkileşim için. Bu kütüphane sayesinde en güncel ekonomik verilere ulaşabileceğiz.
- MetaTrader 5 - piyasanın kendisiyle doğrudan etkileşim kurmak için buna ihtiyacımız olacak.
- catboost’tan CatBoostRegressor - küçük bir el yapımı yapay zeka.
- sklearn’den train_test_split ve mean_squared_error - bu kütüphaneler modelimizin ne kadar etkili olduğunu değerlendirmemize yardımcı olacaktır.
İhtiyacınız olan her şeyi yüklemek için bir komut istemi açın ve şunu girin:
pip install pandas wbdata MetaTrader5 catboost scikit-learn
Her şey hazır mı? Mükemmel! Şimdi ilk kod satırlarımızı yazalım:
import pandas as pd import wbdata import MetaTrader5 as mt5 from catboost import CatBoostRegressor from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error import warnings warnings.filterwarnings("ignore", category=UserWarning, module="wbdata")
Gerekli tüm araçları hazırladık. Devam edelim.
Dünya Bankası API'si ile çalışma: Ekonomik göstergeleri yükleme
Şimdi Dünya Bankasından ekonomik verileri nasıl alacağımızı bulalım.
İlk olarak gösterge kodlarını içeren bir sözlük oluşturuyoruz:
indicators = {
'NY.GDP.MKTP.KD.ZG': 'GDP growth', # GDP growth
'FP.CPI.TOTL.ZG': 'Inflation', # Inflation
'FR.INR.RINR': 'Real interest rate', # Real interest rate
# ... and a bunch of other smart parameters
}
Bu kodların her biri belirli bir veri türüne erişim sağlar.
Devam edelim. Tüm kodun üzerinden geçecek bir döngü başlatıyoruz:
data_frames = [] for indicator in indicators.keys(): try: data_frame = wbdata.get_dataframe({indicator: indicators[indicator]}, country='all') data_frames.append(data_frame) except Exception as e: print(f"Error fetching data for indicator '{indicator}': {e}")
Burada her gösterge için veri elde etmeye çalışıyoruz. Eğer başarılı olursak, onu listeye ekliyoruz. Başarısız olursak, bir hata yazdırıyoruz ve devam ediyoruz.
Sonrasında, tüm verilerimizi büyük bir DataFrame'de topluyoruz:
data = pd.concat(data_frames, axis=1) Bu aşamada tüm ekonomik verileri elde etmemiz gerekiyor.
Bir sonraki adım, elde ettiğimiz her şeyi bir dosyaya kaydetmektir, böylece daha sonra ihtiyaç duyduğumuz amaçlar için kullanabiliriz:
data.to_csv('economic_data.csv', index=True) Az önce Dünya Bankasından bir grup veri indirdik. Bu kadar kolay.
Analiz için temel ekonomik göstergelere genel bakış
Eğer acemiyseniz, çok fazla veri ve sayıyı anlamak biraz zor olabilir. Süreci kolaylaştırmak için ana göstergelere bakalım:
- GSYİH büyümesi - bir ülke için bir tür gelirdir. Artan değerler olumlu, düşen değerler ise ülke üzerinde olumsuz bir etkiye sahiptir.
- Enflasyon - mal ve hizmet fiyatlarındaki artıştır.
- Reel faiz oranı - yükselirse, kredileri daha pahalı hale getirir.
- İhracat ve ithalat - bir ülkenin ne sattığını ve ne aldığını gösterir. Satışların artması olumlu bir gelişme olarak görülür.
- Cari hesap dengesi - diğer ülkelerin belirli bir ülkeye ne kadar borcu olduğu. Daha yüksek değerler ülkenin mali durumunun iyi olduğunu gösterir.
- Hükümet borcu - bir ülkenin borçlarını temsil eder. Değer ne kadar düşük olursa o kadar iyidir.
- İşsizlik - kaç kişinin işsiz olduğu. Ne kadar düşükse, o kadar iyidir.
- Kişi başına düşen GSYİH büyümesi - ortalama bir insanın zenginleşip zenginleşmediğini gösterir.
Bu, kodda aşağıdaki gibi görünür:
# Loading data from the World Bank
indicators = {
'NY.GDP.MKTP.KD.ZG': 'GDP growth', # GDP growth
'FP.CPI.TOTL.ZG': 'Inflation', # Inflation
'FR.INR.RINR': 'Real interest rate', # Real interest rate
'NE.EXP.GNFS.ZS': 'Exports', # Exports of goods and services (% of GDP)
'NE.IMP.GNFS.ZS': 'Imports', # Imports of goods and services (% of GDP)
'BN.CAB.XOKA.GD.ZS': 'Current account balance', # Current account balance (% of GDP)
'GC.DOD.TOTL.GD.ZS': 'Government debt', # Government debt (% of GDP)
'SL.UEM.TOTL.ZS': 'Unemployment rate', # Unemployment rate (% of total labor force)
'NY.GNP.PCAP.CD': 'GNI per capita', # GNI per capita (current US$)
'NY.GDP.PCAP.KD.ZG': 'GDP per capita growth', # GDP per capita growth (constant 2010 US$)
'NE.RSB.GNFS.ZS': 'Reserves in months of imports', # Reserves in months of imports
'NY.GDP.DEFL.KD.ZG': 'GDP deflator', # GDP deflator (constant 2010 US$)
'NY.GDP.PCAP.KD': 'GDP per capita (constant 2015 US$)', # GDP per capita (constant 2015 US$)
'NY.GDP.PCAP.PP.CD': 'GDP per capita, PPP (current international $)', # GDP per capita, PPP (current international $)
'NY.GDP.PCAP.PP.KD': 'GDP per capita, PPP (constant 2017 international $)', # GDP per capita, PPP (constant 2017 international $)
'NY.GDP.PCAP.CN': 'GDP per capita (current LCU)', # GDP per capita (current LCU)
'NY.GDP.PCAP.KN': 'GDP per capita (constant LCU)', # GDP per capita (constant LCU)
'NY.GDP.PCAP.CD': 'GDP per capita (current US$)', # GDP per capita (current US$)
'NY.GDP.PCAP.KD': 'GDP per capita (constant 2010 US$)', # GDP per capita (constant 2010 US$)
'NY.GDP.PCAP.KD.ZG': 'GDP per capita growth (annual %)', # GDP per capita growth (annual %)
'NY.GDP.PCAP.KN.ZG': 'GDP per capita growth (constant LCU)', # GDP per capita growth (constant LCU)
}
Her göstergenin kendi önem düzeyi vardır. Tek başlarına çok az şey söylerler, ancak birlikte daha eksiksiz bir resim sunarlar. Göstergelerin birbirlerini etkiledikleri de unutulmamalıdır. Örneğin, düşük işsizlik genellikle iyi bir haberdir, ancak daha yüksek enflasyona yol açabilir. Ya da yüksek GSYİH büyümesi, büyük borçlar pahasına elde ediliyorsa o kadar da olumlu olmayabilir.
Tüm bu karmaşık ilişkileri dikkate almamıza yardımcı olduğu için makine öğrenimini kullanmamızın nedeni budur. Bilgi işleme sürecini önemli ölçüde hızlandırır ve verileri sıralar. Ancak, süreci anlamak için biraz çaba sarf etmeniz de gerekecektir.
Dünya Bankası verilerinin işlenmesi ve yapılandırılması
Elbette ilk bakışta, Dünya Bankasının çok sayıdaki verisini anlamak göz korkutucu bir görev gibi görünebilir. Çalışmayı ve analizi kolaylaştırmak için verileri bir tabloda toplayacağız.
data_frames = [] for indicator in indicators.keys(): try: data_frame = wbdata.get_dataframe({indicator: indicators[indicator]}, country='all') data_frames.append(data_frame) except Exception as e: print(f"Error fetching data for indicator '{indicator}': {e}") data = pd.concat(data_frames, axis=1)
Ardından, her bir göstergeyi ele alıp onunla ilgili verileri elde etmeye çalışıyoruz. Bazı göstergelerle ilgili sorunlar olabilir, bunları not edip devam ediyoruz. Daha sonra verileri büyük bir DataFrame içinde topluyoruz.
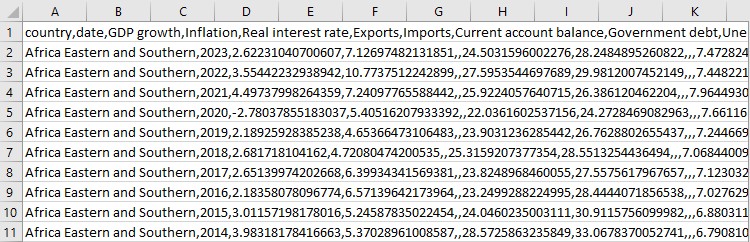
Ancak burada durmuyoruz. Şimdi en ilginç kısım başlıyor.
print("Available indicators and their data:")
print(data.columns)
print(data.head())
data.to_csv('economic_data.csv', index=True)
print("Economic Data Statistics:")
print(data.describe())
Neler başardığımıza bakıyoruz. Hangi göstergeler var? İlk veri satırları neye benziyor? Tamamlanmış bir yapboza ilk bakış gibidir: her şey yerli yerinde mi? Ve sonra tüm bunları bir CSV dosyasına kaydediyoruz.
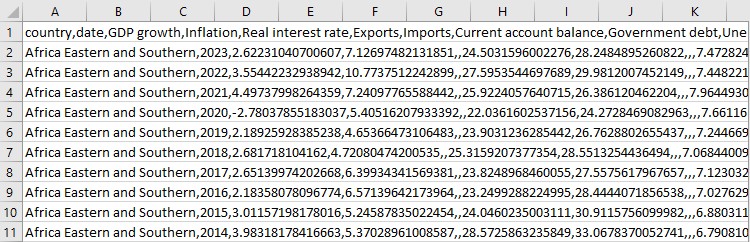
Ve son olarak, bazı istatistikler. Ortalama değerler, yüksekler, düşükler. Hızlı bir kontrol gibidir - verilerimizde her şey yolunda mı? Bir grup farklı sayıyı tutarlı bir veri sistemine bu şekilde dönüştürüyoruz. Artık ciddi bir ekonomik analiz için tüm araçlara sahibiz.
MetaTrader 5'e giriş: Bağlantı kurma ve verileri alma
Şimdi MetaTrader 5 hakkında konuşalım. Önce bir bağlantı kurmamız gerekiyor. Şu şekilde yapacağız:
if not mt5.initialize(): print("initialize() failed") mt5.shutdown()
Bir sonraki önemli adım verileri elde etmektir. İlk olarak, hangi döviz paritelerinin mevcut olduğunu kontrol etmemiz gerekiyor:
symbols = mt5.symbols_get()
symbol_names = [symbol.name for symbol in symbols]
Yukarıdaki kod yürütüldüğünde, mevcut tüm döviz paritelerinin bir listesini alacağız. Ardından, mevcut her parite için geçmiş fiyat verilerini indirmemiz gerekiyor:
historical_data = {}
for symbol in symbol_names:
rates = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_D1, 0, 1000)
df = pd.DataFrame(rates)
df['time'] = pd.to_datetime(df['time'], unit='s')
df.set_index('time', inplace=True)
historical_data[symbol] = df
Bu kodda neler oluyor? MetaTrader'a her bir alım-satım enstrümanı için son 1000 güne ait verileri indirmesi talimatını verdik. Sonrasında veriler tabloya yükleniyor.
İndirilen veriler, son üç yılda döviz piyasasında meydana gelen her şeyi ayrıntılı olarak içermektedir. Artık alınan fiyatlar analiz edilebilir ve kalıplar bulunabilir. Buradaki olasılıklar neredeyse sınırsızdır.
Verileri hazırlama: Ekonomik göstergeler ve piyasa verilerinin birleştirilmesi
Bu aşamada, doğrudan veri işleme ile ilgileneceğiz. İki ayrı sektörümüz var: ekonomik göstergeler dünyası ve döviz kurları dünyası. Bizim görevimiz bu sektörleri bir araya getirmek.
Veri hazırlama fonksiyonumuzla başlayalım. Bu kod genel görevimizde aşağıdaki gibi olacaktır:
def prepare_data(symbol_data, economic_data): data = symbol_data.copy() data['close_diff'] = data['close'].diff() data['close_corr'] = data['close'].rolling(window=30).corr(data['close'].shift(1)) for indicator in indicators.keys(): if indicator in economic_data.columns: data[indicator] = economic_data[indicator] else: print(f"Warning: Data for indicator '{indicator}' is not available.") data.dropna(inplace=True) return data
Şimdi bunu adım adım inceleyelim. İlk olarak, döviz paritesi verilerinin bir kopyasını oluşturuyoruz. Neden? Verilerin orijinali yerine bir kopyasıyla çalışmak her zaman daha iyidir. Bir hata durumunda, orijinal dosyayı tekrar oluşturmak zorunda kalmayacağız.
Şimdi en ilginç kısım geliyor. İki yeni sütun ekliyoruz: 'close_diff' ve 'close_corr'. İlki, kapanış fiyatının bir önceki güne göre ne kadar değiştiğini gösterir. Bu şekilde fiyatta pozitif ya da negatif bir değişim olup olmadığını bileceğiz. İkincisi, kapanış fiyatının kendisiyle olan korelasyonudur, ancak bir günlük bir kayma ile. Bu ne için? Aslında, bugünün fiyatının dünün fiyatına ne kadar benzediğini anlamanın en uygun yoludur.
Şimdi işin zor kısmı geliyor: döviz verilerimize ekonomik göstergeler eklemeye çalışıyoruz. Bu şekilde verilerimizi tek bir yapıya entegre etmeye başlıyoruz. Tüm ekonomik göstergelerimizin üzerinden geçiyor ve bunları Dünya Bankası verilerinde bulmaya çalışıyoruz. Eğer bulursak, harika, onu döviz verilerimize ekliyoruz. Eğer bulamazsak, bir uyarı yazıp devam ediyoruz.
Tüm bunlardan sonra, elimizde eksik veri satırları kalabilir. Onları siliyoruz.
Şimdi bu fonksiyonu nasıl uygulayacağımızı görelim:
prepared_data = {}
for symbol, df in historical_data.items():
prepared_data[symbol] = prepare_data(df, data)
Her bir döviz paritesini alıyoruz ve yazdığımız fonksiyonumuzu ona uyguluyoruz. Çıktıda, her parite için hazır bir veri seti elde ediyoruz. Her parite için ayrı bir set olacaktır, ancak hepsi aynı prensibe göre bir araya getirilir.
Bu süreçteki en önemli şeyin ne olduğunu biliyor musunuz? Yeni bir şey oluşturuyoruz. Farklı ekonomik verileri ve canlı döviz kuru verilerini alıyor ve bunlardan tutarlı bir şey oluşturuyoruz. Tek tek kaotik görünebilirler, ancak bir araya getirildiklerinde kalıpları tanımlayabiliriz.
Ve şimdi elimizde analiz için hazır bir veri seti var. İçinde sekanslar arayabilir, tahminlerde bulunabilir ve sonuçlar çıkarabiliriz. Ancak, gerçekten dikkate değer olan işaretleri belirlememiz gerekecektir. Veri dünyasında önemsiz ayrıntı yoktur. Veri hazırlamadaki her adım nihai sonuç için kritik olabilir.
Modelimizde makine öğrenimi
Makine öğrenimi oldukça karmaşık ve yoğun emek gerektiren bir süreçtir. CatBoostRegressor - bu fonksiyon daha sonra önemli bir rol oynayacaktır. İşte nasıl kullandığımız:
from catboost import CatBoostRegressor model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100) model.fit(X_train, y_train, verbose=False)
Burada her parametre önemlidir. Yineleme 1000 - modelin veriler üzerinde kaç kez çalışacağıdır. Öğrenme hızı 0.1 - hemen yüksek bir hız ayarlamaya gerek yok, yavaş yavaş öğrenmeliyiz. Derinlik 8 - karmaşık bağlantılar aramak için. RMSE - hataları bu şekilde değerlendiriyoruz. Bir modeli eğitmek belirli bir zaman alır. Örnekler gösteriyor ve doğru cevapları değerlendiriyoruz. CatBoost özellikle farklı veri türleriyle iyi çalışır. Dar bir fonksiyon yelpazesiyle sınırlı değildir.
Dövizleri tahmin etmek için aşağıdakileri yaparız:
def forecast(symbol_data):
X = symbol_data.drop(columns=['close'])
y = symbol_data['close']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, shuffle=False)
model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100)
model.fit(X_train, y_train, verbose=False)
predictions = model.predict(X_test)
mse = mean_squared_error(y_test, predictions)
print(f"Mean Squared Error for {symbol}: {mse}")
Verilerin bir kısmı eğitim için, diğer kısmı ise test içindir. Okula gitmek gibi: önce çalışırsınız, sonra sınava girersiniz
Verileri iki bölüme ayırıyoruz. Neden? Bir kısmı eğitim için, diğer kısmı test için. Çünkü modeli henüz çalışmadığı veriler üzerinde test etmemiz gerekecek.
Eğitimden sonra model tahmin yapmaya çalışır. Karesel ortalama hatanın karekökü (Root Mean Square Error, RMSE), modelin ne kadar iyi çalıştığını gösterir. Hata ne kadar küçükse, tahmin o kadar iyidir. CatBoost, sürekli iyileşiyor olmasıyla dikkat çekicidir. Hatalardan ders çıkarır.
Elbette CatBoost otomatik bir program değildir. İyi verilere ihtiyacı var. Aksi takdirde, girdide etkisiz veri, çıktıda etkisiz veri anlamına gelir. Ancak doğru verilerle sonuç olumludur. Şimdi verileri bölme hakkında konuşalım. Doğrulama için fiyatlara ihtiyacımız olduğundan bahsetmiştim. Bu, kodda aşağıdaki gibi görünür:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, shuffle=False) Verilerin %50'si teste gidiyor. Bunları karıştırmayın - finansal veriler için zaman sırasını korumak önemlidir.
Modelin oluşturulması ve eğitilmesi en ilginç kısımdır. CatBoost burada yeteneklerini sonuna kadar sergiliyor:
model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100) model.fit(X_train, y_train, verbose=False)
Model açgözlülükle verileri özümleyerek kalıplar arar. Her yineleme, piyasayı daha iyi anlamaya yönelik bir adımdır.
Ve şimdi en önemli an. Doğruluk değerlendirmesi:
predictions = model.predict(X_test) mse = mean_squared_error(y_test, predictions)
Karesel ortalama hatanın karekökü de çalışmamızda önemli bir noktadır. Modelin ne kadar yanlış olduğunu gösterir. Ne kadar düşükse, o kadar iyidir. Bu sayede programın kalitesini değerlendirebiliyoruz. Unutmayın, alım-satımda nihai garantiler yoktur. Ancak CatBoost ile süreç daha verimlidir. Bizim gözden kaçırabileceğimiz şeyleri görür. Ve her tahminde sonuç daha da iyiye gider.
Döviz paritelerinin gelecekteki değerlerinin tahmin edilmesi
Döviz paritelerini tahmin etmek olasılıklarla çalışmaktır. Bazen pozitif sonuçlar alırız, bazen de kayıplar yaşarız. Önemli olan nihai sonucun beklentilerimizi karşılamasıdır.
Kodumuzda, 'forecast' fonksiyonu olasılıklarla çalışır. Hesaplamaları şu şekilde gerçekleştirir:
def forecast(symbol_data): X = symbol_data.drop(columns=['close']) y = symbol_data['close'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False) model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100) model.fit(X_train, y_train, verbose=False) predictions = model.predict(X_test) mse = mean_squared_error(y_test, predictions) print(f"Mean Squared Error for {symbol}: {mse}") future_data = symbol_data.tail(30).copy() if len(predictions) >= 30: future_data['close'] = predictions[-30:] else: future_data['close'] = predictions future_predictions = model.predict(future_data.drop(columns=['close'])) return future_predictions
İlk olarak, halihazırda mevcut olan verileri tahmin edilen verilerden ayırıyoruz. Daha sonra verileri iki parçaya ayırıyoruz: eğitim ve test için. Model bir veri kümesinden öğreniyor ve sonra onu başka bir veri kümesi üzerinde test ediyoruz. Eğitimden sonra model tahminlerde bulunuyor. Karesel ortalama hatanın karekökü ölçütünü kullanarak ne kadar yanlış olduğuna bakıyoruz. Sayı ne kadar düşükse, tahmin o kadar iyidir.
Ancak en ilginç şey, gelecekteki olası fiyat hareketleri için fiyatların analizidir. Son 30 günlük verileri alıyoruz ve modelden bundan sonra ne olacağını tahmin etmesini istiyoruz. Bu, deneyimli analistlerin tahminlerine başvurduğumuz duruma benzer. Görselleştirmeye gelince. Ne yazık ki, kod henüz sonuçların açık bir şekilde görselleştirilmesini sağlamamaktadır. Ama ekleyelim ve neye benzeyebileceğini görelim:
import matplotlib.pyplot as plt for symbol, forecast in forecasts.items(): plt.figure(figsize=(12, 6)) plt.plot(range(len(forecast)), forecast, label='Forecast') plt.title(f'Forecast for {symbol}') plt.xlabel('Days') plt.ylabel('Price') plt.legend() plt.savefig(f'{symbol}_forecast.png') plt.close()
Bu kod her döviz paritesi için bir grafik oluşturacaktır. Görsel olarak doğrusal bir şekilde oluşturulur. Her nokta belirli bir gün için tahmin edilen fiyattır. Bu grafikler olası trendleri göstermek için tasarlanmıştır, ortalama bir insan için genellikle çok karmaşık olan devasa bir veri yığını üzerinde çalışılmıştır. Eğer çizgi yukarı yönlü ise, döviz kuru değer kazanacaktır. Çizgi aşağıya doğru mu? O zaman döviz kurunda bir düşüşe hazır olun.
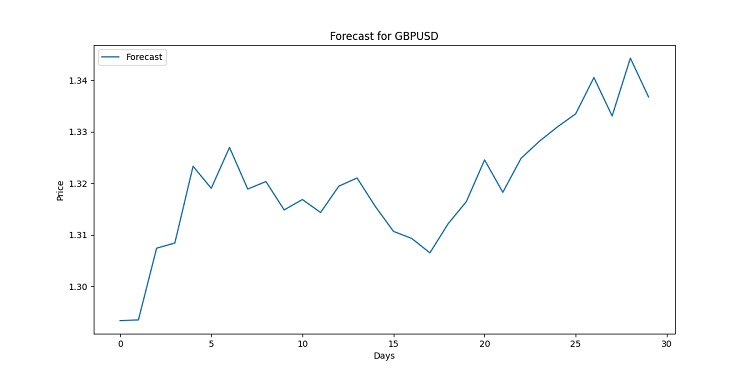
Unutmayın, tahminler garanti değildir. Piyasa kendi değişikliklerini yapabilir. Ancak iyi bir görselleştirme ile en azından ne bekleyeceğinizi bilirsiniz. Sonuçta, bu durumda elimizin altında yüksek kaliteli bir analiz var.
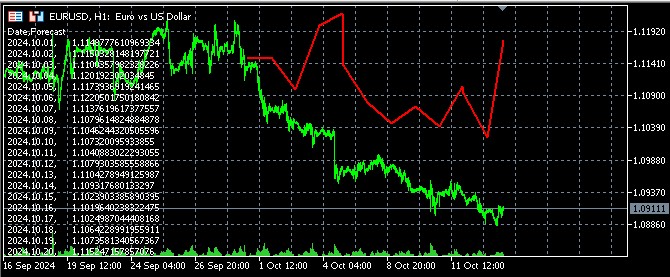
Ayrıca bir dosya açarak ve tahminleri Comment fonksiyonuyla çıktı olarak vererek tahmin sonuçlarını MQL5'te görselleştirmek için bir kod yazdım:
//+------------------------------------------------------------------+ //| Economic Forecast| //| Copyright 2024, Evgeniy Koshtenko | //| https://www.mql5.com/en/users/koshtenko | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Evgeniy Koshtenko" #property link "https://www.mql5.com/en/users/koshtenko" #property version "4.00" #property strict #property indicator_chart_window #property indicator_buffers 1 #property indicator_plots 1 #property indicator_label1 "Forecast" #property indicator_type1 DRAW_SECTION #property indicator_color1 clrRed #property indicator_style1 STYLE_SOLID #property indicator_width1 2 double ForecastBuffer[]; input string FileName = "EURUSD_forecast.csv"; // Forecast file name //+------------------------------------------------------------------+ //| Custom indicator initialization function | //+------------------------------------------------------------------+ int OnInit() { SetIndexBuffer(0, ForecastBuffer, INDICATOR_DATA); PlotIndexSetDouble(0, PLOT_EMPTY_VALUE, EMPTY_VALUE); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Draw forecast | //+------------------------------------------------------------------+ int OnCalculate(const int rates_total, const int prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int &spread[]) { static bool first=true; string comment = ""; if(first) { ArrayInitialize(ForecastBuffer, EMPTY_VALUE); ArraySetAsSeries(ForecastBuffer, true); int file_handle = FileOpen(FileName, FILE_READ|FILE_CSV|FILE_ANSI); if(file_handle != INVALID_HANDLE) { // Skip the header string header = FileReadString(file_handle); comment += header + "\n"; // Read data from file while(!FileIsEnding(file_handle)) { string line = FileReadString(file_handle); string str_array[]; StringSplit(line, ',', str_array); datetime time=StringToTime(str_array[0]); double price=StringToDouble(str_array[1]); PrintFormat("%s %G", TimeToString(time), price); comment += str_array[0] + ", " + str_array[1] + "\n"; // Find the corresponding bar on the chart and set the forecast value int bar_index = iBarShift(_Symbol, PERIOD_CURRENT, time); if(bar_index >= 0 && bar_index < rates_total) { ForecastBuffer[bar_index] = price; PrintFormat("%d %s %G", bar_index, TimeToString(time), price); } } FileClose(file_handle); first=false; } else { comment = "Failed to open file: " + FileName; } Comment(comment); } return(rates_total); } //+------------------------------------------------------------------+ //| Indicator deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { Comment(""); } //+------------------------------------------------------------------+ //| Create the arrow | //+------------------------------------------------------------------+ bool ArrowCreate(const long chart_ID=0, // chart ID const string name="Arrow", // arrow name const int sub_window=0, // subwindow number datetime time=0, // anchor point time double price=0, // anchor point price const uchar arrow_code=252, // arrow code const ENUM_ARROW_ANCHOR anchor=ANCHOR_BOTTOM, // anchor point position const color clr=clrRed, // arrow color const ENUM_LINE_STYLE style=STYLE_SOLID, // border line style const int width=3, // arrow size const bool back=false, // in the background const bool selection=true, // allocate for moving const bool hidden=true, // hidden in the list of objects const long z_order=0) // mouse click priority { //--- set anchor point coordinates if absent ChangeArrowEmptyPoint(time, price); //--- reset the error value ResetLastError(); //--- create an arrow if(!ObjectCreate(chart_ID, name, OBJ_ARROW, sub_window, time, price)) { Print(__FUNCTION__, ": failed to create an arrow! Error code = ", GetLastError()); return(false); } //--- set the arrow code ObjectSetInteger(chart_ID, name, OBJPROP_ARROWCODE, arrow_code); //--- set anchor type ObjectSetInteger(chart_ID, name, OBJPROP_ANCHOR, anchor); //--- set the arrow color ObjectSetInteger(chart_ID, name, OBJPROP_COLOR, clr); //--- set the border line style ObjectSetInteger(chart_ID, name, OBJPROP_STYLE, style); //--- set the arrow size ObjectSetInteger(chart_ID, name, OBJPROP_WIDTH, width); //--- display in the foreground (false) or background (true) ObjectSetInteger(chart_ID, name, OBJPROP_BACK, back); //--- enable (true) or disable (false) the mode of moving the arrow by mouse //--- when creating a graphical object using ObjectCreate function, the object cannot be //--- highlighted and moved by default. Selection parameter inside this method //--- is true by default making it possible to highlight and move the object ObjectSetInteger(chart_ID, name, OBJPROP_SELECTABLE, selection); ObjectSetInteger(chart_ID, name, OBJPROP_SELECTED, selection); //--- hide (true) or display (false) graphical object name in the object list ObjectSetInteger(chart_ID, name, OBJPROP_HIDDEN, hidden); //--- set the priority for receiving the event of a mouse click on the chart ObjectSetInteger(chart_ID, name, OBJPROP_ZORDER, z_order); //--- successful execution return(true); } //+------------------------------------------------------------------+ //| Check anchor point values and set default values | //| for empty ones | //+------------------------------------------------------------------+ void ChangeArrowEmptyPoint(datetime &time, double &price) { //--- if the point time is not set, it will be on the current bar if(!time) time=TimeCurrent(); //--- if the point price is not set, it will have Bid value if(!price) price=SymbolInfoDouble(Symbol(), SYMBOL_BID); } //+------------------------------------------------------------------+
İşte terminalde tahminlerin nasıl göründüğü:
Sonuçların yorumlanması: Ekonomik faktörlerin döviz kurları üzerindeki etkisinin analizi
Şimdi koda göre sonuçları yorumlamaya daha yakından bakalım. Binlerce farklı olguyu, analiz edilmesi gereken organize veriler halinde topladık.
GSYİH büyümesinden işsizliğe kadar pek çok ekonomik göstergeye sahibiz. Her bir faktörün piyasa üzerinde kendi etkisi vardır, ancak bu veriler birlikte nihai döviz kurlarını etkiler.
Örneğin GSYİH'yı ele alalım. Kodda, birkaç gösterge ile temsil edilir:
'NY.GDP.MKTP.KD.ZG': 'GDP growth', 'NY.GDP.PCAP.KD.ZG': 'GDP per capita growth',
GSYİH büyümesi genellikle para birimini güçlendirir. Neden? Çünkü olumlu haberler, daha fazla kazanç elde etmek için sermaye yatırımı yapma fırsatı arayan oyuncuları cezbeder. Yatırımcılar büyüyen ekonomilere yönelir ve bu ülkelerin para birimlerine olan talep artar.
Aksine, enflasyon (‘FP.CPI.TOTL.ZG’: ‘Inflation’) yatırımcılar için endişe verici bir sinyaldir. Enflasyon ne kadar yüksek olursa, paranın değeri o kadar hızlı düşer. Yüksek enflasyon genellikle para birimini zayıflatır, çünkü söz konusu ülkede hizmetler ve mallar çok daha pahalı hale gelmeye başlar.
Ticaret dengesine bakmak ilginçtir:
'NE.EXP.GNFS.ZS': 'Exports', 'NE.IMP.GNFS.ZS': 'Imports', 'BN.CAB.XOKA.GD.ZS': 'Current account balance',
Bu göstergeler terazi gibidir. İhracatın ithalattan fazla olması halinde ülke daha fazla döviz elde eder ve bu da genellikle ülkenin para birimini güçlendirir.
Şimdi bunu kodda nasıl analiz ettiğimizi görelim. CatBoostRegressor ana aracımızdır. Deneyimli bir orkestra şefi gibi, tüm enstrümanları aynı anda duyar ve birbirlerini nasıl etkilediklerini anlar.
İşte faktörlerin etkisini daha iyi anlamak için forecast fonksiyonuna ekleyebilecekleriniz:
def forecast(symbol_data):
# ......
feature_importance = model.feature_importances_
feature_names = X.columns
importance_df = pd.DataFrame({'feature': feature_names, 'importance': feature_importance})
importance_df = importance_df.sort_values('importance', ascending=False)
print(f"Feature Importance for {symbol}:")
print(importance_df.head(10)) # Top 10 important factors
return future_predictions
Bu bize her bir döviz paritesinin tahmini için hangi faktörlerin en önemli olduğunu gösterecektir. EUR için kilit faktörün ECB faiz oranı, JPY için ise Japonya'nın ticaret dengesi olduğu ortaya çıkabilir. Veri çıktısı örneği:
Interpretation for EURUSD:
1. Price Trend: The forecast shows a upward trend for the next 30 days.
2. Volatility: The predicted price movement shows low volatility.
3. Key Influencing Factor: The most important feature for this forecast is 'low'.
4. Economic Implications:
- If GDP growth is a top factor, it suggests strong economic performance is influencing the currency.
- High importance of inflation rate might indicate monetary policy changes are affecting the currency.
- If trade balance factors are crucial, international trade dynamics are likely driving currency movements.
5. Trading Implications:
- Upward trend suggests potential for long positions.
- Lower volatility might allow for wider stop-losses.
6. Risk Assessment:
- Always consider the model's limitations and potential for unexpected market events.
- Past performance doesn't guarantee future results.
Ancak unutmayın ki ekonomide kolay cevaplar yoktur. Bazen bir para birimi her şeye rağmen güçlenir, bazen de görünürde hiçbir neden yokken düşer. Piyasa genellikle mevcut gerçeklikten ziyade beklentilere göre yaşar.
Bir diğer önemli nokta da zaman gecikmesidir. Ekonomideki değişiklikler döviz kuruna hemen yansımaz. Bu büyük bir gemiyi idare etmeye benzer - dümeni çevirirsiniz ama gemi anında rotasını değiştirmez. Kodda günlük verileri kullanıyoruz, ancak bazı ekonomik göstergeler daha seyrek güncelleniyor. Bu durum tahminlerde bir miktar hataya yol açabilir. Nihayetinde, sonuçları yorumlamak bir bilim olduğu kadar bir sanattır da. Model güçlü bir araçtır, ancak kararlar her zaman bir insan tarafından verilir. Bu verileri akıllıca kullanın ve tahminlerinizin doğru olmasını sağlayın!
Ekonomik verilerde bariz olmayan kalıpların araştırılması
Forex piyasası çok büyük bir alım-satım platformudur. Öngörülebilir fiyat hareketleri ile karakterize değildir, ancak buna ek olarak, volatiliteyi ve likiditeyi artıran özel olaylar vardır. Bunlar küresel olaylardır.
Kodumuzda ekonomik göstergelere dayanarak değerlendirme yapıyoruz:
indicators = {
'NY.GDP.MKTP.KD.ZG': 'GDP growth',
'FP.CPI.TOTL.ZG': 'Inflation',
# ...
}
Ama beklenmedik bir şey olduğunda ne yapmalıyız? Örneğin, bir pandemi veya siyasi bir kriz?
Burada bir tür "sürpriz endeksi" faydalı olacaktır. Kodumuza şöyle bir şey eklediğimizi düşünelim:
def add_global_event_impact(data, event_date, event_magnitude): data['global_event'] = 0 data.loc[event_date:, 'global_event'] = event_magnitude data['global_event_decay'] = data['global_event'].ewm(halflife=30).mean() return data # --- def prepare_data(symbol_data, economic_data): # ... ... data = add_global_event_impact(data, '2020-03-11', 0.5) # return data
Bu, ani küresel olayları ve bunların kademeli olarak zayıflamasını dikkate almamızı sağlayacaktır.
Ancak buradaki en ilginç konu, bunun tahminleri nasıl etkilediğidir. Bazen küresel olaylar beklentilerimizi tamamen alt üst edebilir. Örneğin, bir kriz sırasında USD veya CHF gibi "güvenli" para birimleri ekonomik mantık karşısında güçlenebilir.
Böyle anlarda modelimizin üretkenliği düşer. Ve burada paniğe kapılmamak, uyum sağlamak önemlidir. Belki de tahmin ufkunu geçici olarak azaltmaya veya son verilere daha fazla ağırlık vermeye değer?
recent_weight = 2 if data['global_event'].iloc[-1] > 0 else 1 model.fit(X_train, y_train, sample_weight=np.linspace(1, recent_weight, len(X_train)))
Unutmayın: para birimleri dünyasında, dansta olduğu gibi, asıl önemli olan ritme uyum sağlayabilmektir. Bu ritim bazen en beklenmedik şekillerde değişse bile!
Anormallikleri avlama: Ekonomik verilerde bariz olmayan kalıplar nasıl bulunur?
Şimdi en ilginç kısımdan bahsedelim - verilerimizdeki gizli hazineleri bulma. Bu tıpkı bir dedektif olmak gibi, sadece elimizde kanıt yerine sayılar ve grafikler var.
Kodumuzda zaten oldukça fazla ekonomik gösterge kullanıyoruz. Peki ya aralarında bariz olmayan bazı bağlantılar varsa? Hadi onları bulmaya çalışalım!
Başlangıç olarak, farklı göstergeler arasındaki korelasyonlara bakabiliriz:
correlation_matrix = data[list(indicators.keys())].corr() print(correlation_matrix)
Ancak, bu sadece bir başlangıç. Gerçek sihir, doğrusal olmayan ilişkiler aramaya başladığımızda ortaya çıkar. Örneğin, GSYİH'daki bir değişikliğin döviz kurunu hemen etkilemediği, ancak birkaç aylık bir gecikmeyle etkilediği anlaşılabilir.
Veri hazırlama fonksiyonumuza bazı "kaydırılmış" ölçütler ekleyelim:
def prepare_data(symbol_data, economic_data): # ...... for indicator in indicators.keys(): if indicator in economic_data.columns: data[indicator] = economic_data[indicator] data[f"{indicator}_lag_3"] = economic_data[indicator].shift(3) data[f"{indicator}_lag_6"] = economic_data[indicator].shift(6) # ...
Artık modelimiz 3 ve 6 aylık gecikmelerle bağımlılıkları yakalayabilecektir.
Ancak en ilginç olan şey, tamamen bariz olmayan kalıpların araştırılmasıdır. Örneğin, EUR kurunun ABD'deki dondurma satışlarıyla garip bir şekilde ilişkili olduğu ortaya çıkabilir (bu bir şaka, ama siz fikri anladınız).
Bu tür amaçlar için, temel bileşen analizi (Principal Component Analysis, PCA) gibi özellik çıkarma yöntemleri kullanılabilir:
from sklearn.decomposition import PCA
def find_hidden_patterns(data):
pca = PCA(n_components=5)
pca_result = pca.fit_transform(data[list(indicators.keys())])
print("Explained variance ratio:", pca.explained_variance_ratio_)
return pca_result
pca_features = find_hidden_patterns(data)
data['hidden_pattern_1'] = pca_features[:, 0]
data['hidden_pattern_2'] = pca_features[:, 1]
Bu "gizli kalıplar" daha doğru tahminlerin anahtarı olabilir.
Mevsimselliği de unutmayın. Bazı para birimleri yılın zamanına bağlı olarak farklı davranabilir. Verilerinize ay ve haftanın günü bilgilerini ekleyin - ilginç bir şey bulabilirsiniz!
data['month'] = data.index.month data['day_of_week'] = data.index.dayofweek
Unutmayın, veri dünyasında keşif için her zaman yer vardır. Meraklı olun, denemeler yapın ve kim bilir, belki de alım-satım dünyasını değiştirecek o formasyonu bulacaksınız.
Sonuç: Algoritmik alım-satımda ekonomik tahminlerin potansiyeli
Basit bir fikirle başladık - ekonomik verilere dayanarak döviz kuru hareketlerini tahmin edebilir miyiz? Ne bulduk? Görünüşe göre bu fikrin bir haklılığı var. Ancak bu ilk bakışta göründüğü kadar basit değildir.
Kodumuz ekonomik verilerin analizini önemli ölçüde basitleştirmektedir. Dünyanın her yerinden bilgi toplamayı, bunları işlemeyi ve hatta bilgisayara tahminler yaptırmayı öğrendik. Ancak en gelişmiş makine öğrenimi modelinin bile sadece bir araç olduğunu unutmayın. Çok güçlü bir araç ama yine de bir araç.
CatBoostRegressor kütüphanesinin ekonomik göstergeler ve döviz kurları arasındaki karmaşık ilişkileri nasıl bulabildiğini gördük. Bu, insan yeteneklerinin ötesine geçmemizi ve verileri işlemek ve analiz etmek için harcanan zamanı önemli ölçüde azaltmamızı sağlar. Ancak böylesine harika bir araç bile geleceği %100 doğrulukla tahmin edemez.
Neden? Çünkü ekonomi birçok faktöre bağlı bir süreçtir. Bugün herkes petrol fiyatlarını izlerken, yarın beklenmedik bir olayla tüm dünya alt üst olabilir. Bu etkiden "sürpriz endeksi" hakkında konuşurken bahsetmiştik. İşte tam da bu yüzden bu kadar önemli.
MetaQuotes Ltd tarafından Rusçadan çevrilmiştir.
Orijinal makale: https://www.mql5.com/ru/articles/15998
Uyarı: Bu materyallerin tüm hakları MetaQuotes Ltd'ye aittir. Bu materyallerin tamamen veya kısmen kopyalanması veya yeniden yazdırılması yasaktır.
Bu makale sitenin bir kullanıcısı tarafından yazılmıştır ve kendi kişisel görüşlerini yansıtmaktadır. MetaQuotes Ltd, sunulan bilgilerin doğruluğundan veya açıklanan çözümlerin, stratejilerin veya tavsiyelerin kullanımından kaynaklanan herhangi bir sonuçtan sorumlu değildir.

- Ücretsiz alım-satım uygulamaları
- İşlem kopyalama için 8.000'den fazla sinyal
- Finansal piyasaları keşfetmek için ekonomik haberler
Web sitesi politikasını ve kullanım şartlarını kabul edersiniz
Buradan alın. Konuyla ilgili eski bir makale.
Şimdiye kadar, sinekten elde edebildiğim en fazla şey bugün için mevcut veriler((((
Anlamadığım şey, MQ'nun ne yaptığı?
Bu, yazarın yukarıdaki sinyali.
Bu sinyal tamamen Sber'de bir modeli test etmek için yapıldı. Ama hiç test etmedim, zaten para piyasası fonunda sadece para birimi. Temel olarak modellerim üzerinde kendim işlem yapmıyorum, iyileştirme ve geliştirme fikirlerinden uzaklaşamıyorum)))) İyileştirme konusunda sürekli yeni fikirler var) Ve borsada esas olarak hisselere yatırım yapıyorum, uzun vadede MOEX'te rez olmayan olarak ve Kazbirji endeks şirketlerinin KASE'sinde hisse satın alıyorum.
Şimdiye kadar sinekten elde edebildiğimiz en iyi şey(((( bugün için mevcut verilerdir.
Anladığım kadarıyla, izlemeye bağlı hesaplar hakkında veri topluyorlar? Her şey dürüst olsa bile, bu okyanusta bir damla.
Bence, spot olmasa da opsiyonlu vadeli işlemler olsa bile CFTC'den gelen veriler daha güvenilir. Çok uygun bir formda olmasa da 2005'ten beri orada bir geçmiş var, ancak muhtemelen Python için bazı API'ler var.
Tabii ki size kalmış, sadece fikrimi paylaşıyorum.
Bu sinyal tamamen Sber'de bir modeli test etmek için yapıldı. Ama hiç test etmedim, zaten para piyasası fonunda sadece para birimi. Temel olarak modellerim üzerinde kendim ticaret yapmıyorum, iyileştirme ve geliştirme fikirlerinden uzaklaşamıyorum)))) İyileştirme konusunda sürekli yeni fikirler var) Ve borsada ağırlıklı olarak hisse senetlerine yatırım yapıyorum, uzun vadede MOEX'te rez olmayan olarak ve Kazbirji endeks şirketlerinin KASE'sinde hisse satın alıyorum.
burada bir bilgi tutarsızlığı var, size yönelik bir iddia yok