
Técnicas do MQL5 Wizard que você deve conhecer (Parte 55): SAC com Prioritized Experience Replay
A crescente complexidade dos modelos de redes neurais é impulsionada pela nossa capacidade de processar grandes volumes de dados. O aprendizado de máquina tradicional enfrenta dificuldades de eficiência, enquanto redes neurais, exemplificadas por plataformas como DeepSeek, Grok e ChatGPT, oferecem soluções poderosas.
No entanto, treinar esses modelos apresenta desafios, especialmente com dados históricos limitados. O overfitting é uma grande preocupação, pois os modelos correm o risco de aprender ruído em vez de padrões significativos. O treinamento tradicional frequentemente prioriza a minimização das funções de perda, o que pode levar a uma generalização ruim.
O aprendizado por reforço (RL) aborda isso equilibrando exploração (testar alternativas) e exploração de conhecimento existente (otimizar pesos). Técnicas como Prioritized Experience Replay (PER) aumentam a eficiência do aprendizado, mitigando problemas de escassez de dados observados em áreas como trading, onde os pontos de dados econômicos mensais são limitados.
Considerações-chave em RL incluem projetar uma função de recompensa eficaz, selecionar o algoritmo correto e decidir entre métodos baseados em valor (por exemplo, Q-Learning, DQN) e métodos baseados em política (por exemplo, PPO, TRPO). Abordagens Actor-Critic (por exemplo, A3C, SAC) equilibram estabilidade e eficiência. Métodos on-policy (PPO, A3C) garantem aprendizado estável, enquanto métodos off-policy (DQN, SAC) maximizam a eficiência de dados.
A adaptabilidade do RL o torna uma adição valiosa aos pipelines de aprendizado de máquina, complementando abordagens tradicionais. Ao treinar modelos complexos com dados limitados, priorizar atualizações de peso em vez de apenas minimizar funções de perda promove melhor generalização e robustez.
Prioritized Experience Replay
Buffers de Prioritized Experience Replay (PER) e buffers de Replay típicos (para amostragem aleatória) são ambos utilizados em RL com algoritmos off-policy como DQN e SAC porque permitem armazenar e amostrar experiências passadas. O PER difere de um replay buffer típico na forma como experiências passadas são priorizadas e amostradas.
Com um replay buffer típico, as experiências são amostradas uniformemente e de forma aleatória, o que significa que qualquer experiência passada tem a mesma probabilidade de ser selecionada, independentemente de sua importância ou relevância para o processo de aprendizado. Com PER, as experiências passadas são amostradas com base em sua “prioridade”, propriedade frequentemente quantificada pela magnitude do erro de Diferença Temporal. Esse erro serve como um indicador do potencial de aprendizado. Cada experiência recebe um valor desse erro e experiências com valores altos são amostradas com maior frequência. Essa priorização pode ser implementada usando uma abordagem proporcional ou baseada em ranking.
Buffers de replay típicos também não introduzem nem utilizam qualquer viés. O PER introduz esse viés e isso pode distorcer injustamente o processo de aprendizado; por isso, para corrigir esse efeito, o PER utiliza pesos de importance sampling para ajustar o impacto de cada experiência amostrada. Buffers de replay típicos são, portanto, mais eficientes em termos de amostragem, pois realizam muito menos operações em segundo plano quando comparados ao PER. Por outro lado, o PER proporciona um aprendizado mais focado e construtivo, algo que buffers típicos não oferecem.
Consequentemente, implementar um PER é mais complexo do que um replay buffer típico; isso ocorre porque o PER requer uma classe adicional para manter a fila de prioridade frequentemente chamada de “sum-tree”. Essa estrutura de dados permite uma amostragem mais eficiente das experiências com base em sua prioridade. O PER tende a levar a convergência mais rápida e melhor desempenho, pois concentra o aprendizado nas experiências mais informativas ou desafiadoras para o agente.
Implementação no Modelo
Nossa classe PER, em Python, utiliza uma inicialização que valida os parâmetros do construtor, especificamente o parâmetro de modo. Posso estar enganado, mas acredito que isso não possa ser feito diretamente em C/MQL5 de forma nativa. Declaramos essa função init da seguinte forma:
def __init__(self, capacity, alpha=0.6, beta=0.4, beta_increment=0.001, mode='proportional'): self.capacity = capacity self.alpha = alpha self.beta = beta self.beta_increment = beta_increment self.mode = mode if mode == 'proportional': self.tree = SumTree(capacity) elif mode == 'rank': self.priorities = [] self.data = [] else: raise ValueError("Invalid mode. Choose 'proportional' or 'rank'.")
Com a classe declarada, uma das funções importantes que ela deve incluir é um método para adicionar experiências ao buffer. Implementamos isso da seguinte forma:
def add(self, error, sample): p = self._get_priority(error) if self.mode == 'proportional': self.tree.add(p, sample) elif self.mode == 'rank': heapq.heappush(self.priorities, -p) if len(self.data) < self.capacity: self.data.append(sample) else: heapq.heappop(self.priorities) heapq.heappush(self.data, sample)
Observe que nessa adição de experiências o modo de amostragem é fundamental, pois se estivermos selecionando experiências com base na proporção do erro, simplesmente as adicionamos à sum-tree; porém, se estivermos selecionando com base no ranking da magnitude do erro, utilizamos um módulo importado chamado heapq que é atualizado com essa amostra conforme indicado acima. A classe sum-tree, portanto, é utilizada na amostragem proporcional e não na amostragem por ranking. É assim que ela é implementada:
class SumTree: def __init__(self, capacity): self.capacity = capacity self.tree = np.zeros(2 * capacity - 1) self.data = np.zeros(capacity, dtype=object) self.write = 0 self.n_entries = 0 def _propagate(self, idx, change): parent = (idx - 1) // 2 self.tree[parent] += change if parent != 0: self._propagate(parent, change) def _retrieve(self, idx, s): left = 2 * idx + 1 right = left + 1 if left >= len(self.tree): return idx if s <= self.tree[left]: return self._retrieve(left, s) else: return self._retrieve(right, s - self.tree[left]) def total(self): return self.tree[0] def add(self, p, data): idx = self.write + self.capacity - 1 self.data[self.write] = data self.update(idx, p) self.write += 1 if self.write >= self.capacity: self.write = 0 if self.n_entries < self.capacity: self.n_entries += 1 def update(self, idx, p): change = p - self.tree[idx] self.tree[idx] = p self._propagate(idx, change) def get(self, s): idx = self._retrieve(0, s) data_idx = idx - self.capacity + 1 return (idx, self.tree[idx], self.data[data_idx])
Com essa classe chave definida, outro componente crucial é a função de amostragem em si, que faz parte da classe PER.
def sample(self, batch_size): batch = [] idxs = [] segment = self.tree.total() / batch_size if self.mode == 'proportional' else len(self.data) / batch_size priorities = [] self.beta = np.min([1., self.beta + self.beta_increment]) for i in range(batch_size): a = segment * i b = segment * (i + 1) if self.mode == 'proportional': s = random.uniform(a, b) (idx, p, data) = self.tree.get(s) priorities.append(p) batch.append(data) idxs.append(idx) elif self.mode == 'rank': idx = random.randint(0, len(self.data) - 1) priorities.append(-self.priorities[idx]) batch.append(self.data[idx]) idxs.append(idx) sampling_probabilities = np.array(priorities) / self.tree.total() if self.mode == 'proportional' else np.array(priorities) / sum(self.priorities) is_weights = np.power(len(self.data) * sampling_probabilities, -self.beta) is_weights /= is_weights.max() return batch, idxs, is_weights
Mais uma vez, o modo de amostragem — proporcional ou baseado em ranking — é uma consideração importante aqui. Essas duas abordagens atribuem prioridades a cada experiência considerando o erro TD, com uma diferença sutil. Magnitude do erro TD versus ranking do erro TD. O erro TD é essencialmente a diferença entre a saída de uma experiência e o valor real ou alvo. Ele nunca é usado diretamente em sua forma bruta para ponderar as experiências; em vez disso, é convertido em um valor de prioridade conforme mostrado nesta listagem:
def _get_priority(self, error): return (error + 1e-5) ** self.alpha
É esse valor de prioridade cuja magnitude (para amostragem proporcional) ou ranking (para amostragem por ranking) é utilizado na seleção das experiências para treinar o modelo. O PER foi introduzido por Shaul et al. em 2015. Experiências com maior prioridade são amostradas com mais frequência, melhorando a eficiência da amostragem e a velocidade de aprendizado no ambiente de RL. As prioridades são atualizadas após o aprendizado. Os pesos de importance sampling são utilizados para corrigir o viés introduzido pela amostragem não uniforme baseada em prioridade. Isso é indicado na função de amostragem da classe PER mostrada acima. Vamos explorar esses dois modos de amostragem.
Priorização Proporcional
Como mencionado anteriormente, as prioridades são diretamente proporcionais ao erro de Diferença Temporal (∣δ∣). A prioridade para uma experiência i seria calculada como:
pi=∣δi∣+ϵ
Onde ϵ, que é maior que zero, é uma pequena constante que garante que nenhuma experiência tenha prioridade zero. A probabilidade de amostragem para a experiência seria então:
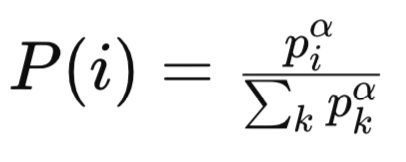
Onde:
-
pi é a prioridade da i-ésima experiência no replay buffer. A prioridade geralmente é baseada na magnitude do erro de diferença temporal (TD) para essa experiência. Experiências com erros TD maiores são consideradas mais importantes e recebem prioridades mais altas.
-
α é um hiperparâmetro que controla o grau de priorização. Quando (α = 0), todas as experiências são amostradas uniformemente (sem priorização). Quando (α = 1), a amostragem é totalmente baseada nas prioridades.
-
Sigma/soma de todas as k prioridades é o termo de normalização, que garante que as probabilidades somem 1. Ele soma as prioridades de todas as experiências no replay buffer elevadas à potência de (α).
-
P(i) é a probabilidade de amostrar a experiência (i). Ela é proporcional à prioridade da experiência (Piα), normalizada pela soma de todas as prioridades elevadas à potência (α).
Uma Sum Tree ou estrutura de dados similar pode então ser usada para amostrar eficientemente as experiências proporcionalmente a piα. A distribuição de amostragem com priorização proporcional é contínua e diretamente ligada à magnitude dos erros TD. Experiências com erros TD elevados tendem a ter prioridades significativamente maiores, resultando em uma distribuição de cauda pesada.
Isso pode levar algumas experiências a serem amostradas com muita frequência (uma preocupação especialmente se seus erros TD forem outliers) enquanto outras são raramente selecionadas por apresentarem erros pequenos. A sensibilidade a erros de treinamento pode variar entre tarefas ou fases de treinamento, mas existe vulnerabilidade da priorização proporcional a outliers nos erros TD, pois valores muito altos podem dominar a distribuição de amostragem.
Por exemplo, considere um cenário em que uma experiência apresenta uma diferença entre saída e alvo de 1000 enquanto as demais apresentam valor 1; claramente esse valor muito alto será amostrado com frequência desproporcional. Essa característica pode levar a overfitting em experiências ruidosas ou outliers, especialmente em ambientes de dados com alta variância em recompensas ou valores Q. Uma possível medida de mitigação seria aplicar clipping ou normalização do erro TD. Por exemplo:
pi=min(∣δi∣,δmax)+ϵ
Onde, essencialmente, a prioridade de uma experiência é definida como o mínimo entre seu próprio erro TD e o maior erro TD de todas as experiências dentro do segmento amostrado, somado a um pequeno valor não nulo epsilon. A complexidade operacional ao lidar com uma sum-tree é relativamente direta: calcular a prioridade de cada experiência ocorre em O(1) por experiência. A amostragem e atualização das prioridades ocorrem em O(log n) por operação, onde n é o tamanho do buffer. Sem overhead adicional de ordenação e ranking, isso torna o método computacionalmente eficiente para atualizações.
A Priorização Proporcional (PP) pode levar a treinamento instável em casos onde os erros TD variam significativamente entre fases de treinamento, pois a distribuição de amostragem muda rapidamente.unstable Ela também é sensível aos hiperparâmetros; portanto, os valores de alpha e epsilon devem ser escolhidos cuidadosamente para equilibrar exploração e exploração de conhecimento. A PP pode convergir mais rapidamente em tarefas com erros “bem comportados”, que refletem bem o valor de aprendizado, mas tende a ter dificuldades em ambientes ruidosos e não estacionários.
PP é adequada para tarefas em que os erros TD são bem comportados e indicam diretamente o potencial de aprendizado. É muito eficaz em ambientes com baixo ruído e valores Q estáveis onde erros TD são proporcionais à importância das experiências. Exemplos incluem jogos Atari com estruturas de recompensa estáveis e tarefas de controle contínuo com funções de valor suaves.
Os pesos de importance sampling em PP tendem a variar devido à distribuição de cauda pesada. Experiências com baixa prioridade possuem valores baixos de P(i) (probabilidade de amostragem da experiência i), o que leva a pesos wi elevados (pesos de ajuste destinados a corrigir viés). Essa configuração pode ter como consequência não intencional amplificar gradientes e desestabilizar o treinamento. Isso significa que o parâmetro beta também precisa ser ajustado cuidadosamente para equilibrar correção de viés e estabilidade.
Resumindo a PP: ela é adequada quando erros TD são bem comportados e correlacionam com valor de aprendizado; o ambiente de dados possui baixo ruído e valores Q estáveis; e eficiência computacional é crítica, ou seja, overhead de ordenação e ranking não é aceitável. O ajuste fino dos hiperparâmetros alpha, beta e epsilon pode ajudar a lidar com outliers e gerenciar instabilidade.
Priorização Baseada em Ranking
Neste modo, as prioridades são baseadas no índice de ranking do erro TD dentro de uma lista ordenada de erros TD. O ranking de uma experiência i é determinado ordenando todas as experiências pela magnitude do erro TD em ordem decrescente. Por que ordem decrescente? Porque intuitivamente essa lista reflete a importância das experiências. Quanto mais alto na lista, mais importante é a experiência. Além disso, do ponto de vista computacional, faz sentido que as experiências mais utilizadas estejam nos índices mais baixos dentro de um heap, pois o algoritmo não precisa percorrer toda a estrutura para acessar as experiências usadas com mais frequência no treinamento. A prioridade da experiência i geralmente é calculada como:
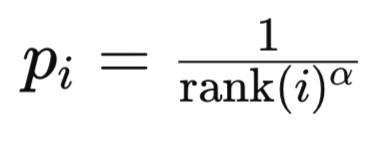
Onde:
- rank(i) é o ranking da i-ésima experiência.
- alpha é um hiperparâmetro que controla a força da priorização.
A probabilidade de amostragem da experiência utiliza uma fórmula semelhante à apresentada anteriormente na priorização proporcional.
Com Priorização Baseada em Ranking (RP), a distribuição de amostragem é discreta e baseada em rankings. Isso tende a torná-la menos sensível à escala absoluta dos erros TD. As experiências são escolhidas com base no ranking e não na magnitude do erro. Isso leva a uma distribuição de amostragem mais uniforme, já que a diferença de prioridade entre experiências é “padronizada” pela posição no ranking (por exemplo e. 1/1, ½, ⅓, etc..). Além disso, RP é menos propensa a overfitting a outliers, pois a maior prioridade atribuída a qualquer experiência é fixa em 1/1, independentemente da magnitude do erro TD. Essa robustez, porém, pode levar a subamostragem de experiências com erros TD muito altos se a função de prioridade baseada em ranking decair rapidamente demais.
No entanto, além do risco de subamostragem de experiências importantes, a principal desvantagem da RP é a complexidade computacional. Ordenar todo o buffer para determinar os rankings tem complexidade operacional de O(n log n) para um buffer de tamanho n. Na prática, essa ordenação pode ser evitada mantendo uma estrutura de dados ordenada (como uma árvore binária de busca ou um heap) para os erros TD, mas as atualizações ainda exigem O(log n) operações por experiência. A amostragem e atualização permanecem em O(log n), como ocorre na priorização proporcional. Assim, RP possui overhead computacional significativamente maior quando comparada à PP.
Durante o treinamento, RP tende a ser mais estável porque a distribuição de amostragem é menos sensível a mudanças na magnitude dos erros TD. Também tende a fornecer probabilidades de amostragem mais consistentes ao longo do tempo, pois os rankings são relativos e menos afetados por ruído e outliers. Pode convergir mais lentamente em tarefas onde erros TD absolutos são altamente informativos para o processo de treinamento, pois não prioriza agressivamente erros de grande magnitude. Também é um pouco mais fácil de ajustar (hiperparâmetros), pois a função de prioridade baseada em ranking é menos sensível à escala.
RP é adequada em ambientes de recompensa esparsa ou em tarefas com recompensas atrasadas ou alta variância de recompensas. É preferida quando estabilidade e amostragem equilibrada são críticas, mesmo que a convergência seja mais lenta.
Tanto PP quanto RP introduzem viés devido aos métodos de amostragem não uniformes e, como já mencionado e demonstrado no método de amostragem apresentado anteriormente, a fórmula básica para corrigir esse viés é:
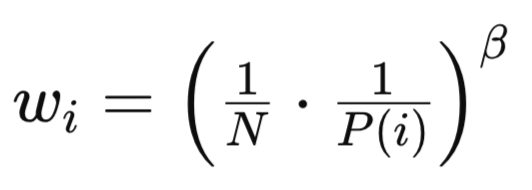
Onde:
- N é o número total de experiências no replay buffer.
- P(i) é a probabilidade de amostragem da i-ésima experiência.
- beta (β∈[0,1]) é um hiperparâmetro que controla a intensidade da correção de importance sampling.
Apesar de possuírem fórmulas semelhantes, os pesos wi em RP e PP diferem em aspectos importantes. Para RP, os pesos de importance sampling são mais uniformes, dado que a distribuição é menos distorcida. Essa menor variância nos valores de wi leva a um treinamento mais estável e a menor sensibilidade ao parâmetro beta. Além disso, a correção de viés é mais fácil de gerenciar, já que a distribuição baseada em ranking é inerentemente mais equilibrada.
Testando a Classe de Sinal
Se utilizarmos o código listado acima e modificarmos o código do modelo SAC do último artigo substituindo o replay buffer típico/simples por um PER, estaremos em posição de treinar o modelo e exportar uma rede com seus pesos como um arquivo ONNX. Abordamos como essa exportação pode ser gerenciada naquele último artigo, e existem notas de orientação aqui sobre como também exportar um modelo ONNX a partir do Python. Modelos ONNX são utilizados pelo MQL5 sendo incorporados como recursos no momento da compilação.
No lado do MQL5, na IDE, nossa classe de sinal personalizada — que estritamente falando não difere do que apresentamos no último artigo sobre SAC — deve ser montada pelo wizard do MQL5 e, para novos leitores, existem guias aqui e aqui sobre como fazer isso. Execuções de teste sem validação cruzada para USDJPY no timeframe diário para o ano de 2023 apresentam o seguinte relatório:


Seguindo em frente, no entanto, a validação cruzada com modelos em Python pode ser feita de forma muito eficiente, portanto talvez seja algo que eu comece a incorporar nesses artigos no futuro. Contudo, como sempre, desempenho passado não garante resultados futuros e o leitor é sempre convidado a realizar sua própria diligência adicional antes de escolher utilizar ou implementar qualquer um dos sistemas compartilhados aqui.
Conclusão
Revisitamos o caso do aprendizado por reforço reiterando que, no cenário atual de modelos complexos e dados históricos limitados para testes, é muito importante priorizar o processo de obtenção dos pesos adequados da rede em vez de simplesmente buscar valores baixos em funções de perda. O processo importa. E, com esse objetivo, destacamos um replay buffer alternativo para aprendizado por reforço, o Prioritized Experience Replay buffer, como um buffer que não apenas mantém experiências recentes disponíveis para amostragem durante o treinamento, mas também realiza amostragem desse buffer proporcionalmente à relevância ou ao quanto a rede pode aprender a partir da experiência amostrada.
| Arquivo | Descrição |
|---|---|
| wz_55.mq5 | Expert Advisor montado pelo wizard com cabeçalho mostrando os arquivos utilizados |
| SignlWZ_55.mqh | Arquivo de Classe de Sinal Personalizada |
| USDJPY.onnx | Arquivo de Rede ONNX |
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/17254
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso