
Redes neurais em trading: Abordagem sem máscara para previsão do movimento de preços

Introdução
Continuamos a explorar métodos de processamento de nuvens de pontos. No artigo anterior, apresentamos o método SPFormer. Seus autores desenvolveram um algoritmo complexo baseado na arquitetura Transformer. Várias camadas do decodificador Transformer utilizam um número fixo de consultas aos objetos, permitindo processar iterativamente as funções globais e gerar previsões diretas dos objetos. SPFormer não requer pós-processamento para remoção de duplicatas, pois, durante o treinamento, é utilizada uma correspondência bidirecional "um para um". Além disso, as máscaras dos objetos, definidas na última camada, são usadas para orientar a atenção cruzada.
No entanto, os autores do trabalho "Mask-Attention-Free Transformer for 3D Instance Segmentation" destacam que os métodos modernos baseados em Transformer sofrem com o problema da convergência lenta. Ao analisar o método base, eles identificaram que o problema pode ser causado pelo baixo nível das máscaras iniciais. Especificamente, as máscaras iniciais dos objetos são criadas mapeando a similaridade entre as consultas iniciais dos objetos e as funções de máscara ponto a ponto. Máscaras iniciais de baixa qualidade aumentam a complexidade do treinamento, retardando a convergência.
Dado o baixo nível de completude das máscaras iniciais, os autores do estudo propõem um novo algoritmo, Mask-Attention-Free Transformer (MAFT), no qual abandonam o design da máscara de atenção e, em vez disso, constroem uma tarefa auxiliar de regressão do centro para orientar a atenção cruzada. Para garantir a regressão do centro, uma série de construções foram desenvolvidas considerando as posições dos pontos. Primeiramente, os autores do método adicionam um conjunto de consultas posicionais treináveis, cada uma representando a posição da respectiva consulta de conteúdo. As posições das consultas são distribuídas densamente no espaço de interesse. Além disso, os autores do método introduzem uma restrição para que cada consulta considere apenas sua região local. Como resultado, as consultas podem capturar facilmente objetos na cena com maior grau de retenção, o que é crucial para reduzir a complexidade do treinamento e acelerar a convergência.
Além disso, os autores do MAFT propuseram uma codificação contextual de posição relativa para a atenção cruzada. Comparado à máscara de atenção utilizada em trabalhos anteriores, essa solução é mais flexível, pois os pesos da atenção são ajustados com base nas posições relativas, em vez de uma máscara rígida. As posições das consultas são atualizadas iterativamente para alcançar uma representação mais precisa.
Os resultados experimentais apresentados no artigo dos autores mostram que MAFT demonstra um desempenho superior em diversos conjuntos de dados.
1. Algoritmo MAFT
O algoritmo SPFormer é um pipeline totalmente end-to-end que permite que as consultas de objetos gerem previsões diretas das instâncias. Com o uso de decodificadores Transformer, um número fixo de consultas aos objetos agrega informações globais dos objetos na nuvem de pontos analisada. Além disso, SPFormer utiliza máscaras de objetos para orientar a atenção cruzada, garantindo que as consultas considerem apenas as características mascaradas. No entanto, nos estágios iniciais do treinamento, são utilizadas máscaras de baixa qualidade. Isso impede a obtenção de bons resultados nas camadas subsequentes, aumentando a complexidade do treinamento do modelo.
Por esse motivo, os autores do método MAFT introduzem uma tarefa auxiliar de regressão do centro para gerenciar a segmentação de instâncias. Primeiro, as posições globais 𝒫 são selecionadas a partir da nuvem de pontos original, e os recursos globais dos objetos ℱ são extraídos utilizando a espinha dorsal base. Esses recursos podem ser tanto voxels quanto Superpoints. Além das consultas de conteúdo 𝒬0c, os autores do MAFT introduzem um número fixo de consultas posicionais 𝒬0p, que representam os centros normalizados dos objetos. 𝒬0p é inicializado aleatoriamente, enquanto 𝒬0c começa com valores nulos. O objetivo principal é permitir que as consultas posicionais orientem as respectivas consultas contextuais na atenção cruzada e, em seguida, refinem iterativamente ambos os conjuntos de consultas para prever os centros dos objetos, suas classes e máscaras.
Para resolver de maneira eficiente o problema da regressão do centro dos objetos e aprimorar a geração das máscaras iniciais, os autores do MAFT propõem uma série de construções que levam em conta a posição dos pontos.
Diferentemente de trabalhos anteriores, um conjunto adicional de consultas posicionais 𝒬0p é introduzido. Como o intervalo das posições dos pontos varia significativamente entre diferentes cenas, as consultas posicionais iniciais são armazenadas em formato normalizado, como parâmetros treináveis, seguidos por uma função sigmoidal.
Vale destacar que as consultas iniciais de posição são distribuídas densamente por todo o espaço analisado. Além disso, cada consulta agrega objetos de sua região local. Essa escolha estrutural facilita a captura de objetos na cena com um alto grau de retenção por parte das consultas iniciais. Isso resolve o problema de baixa retenção causada pelas máscaras iniciais das instâncias e reduz a complexidade do treinamento das camadas subsequentes.
Além do codificação de posição absoluta, o MAFT aplica uma codificação contextual de posição relativa na atenção cruzada. Para isso, as posições relativas 𝐫 entre as consultas posicionais 𝒬tp e as posições globais 𝒫 são inicialmente calculadas e quantizadas em valores inteiros discretos 𝐫'. Em seguida, as posições relativas discretas são usadas como índices para buscar os valores correspondentes na tabela de codificação de posições.
Depois, a codificação de posição relativa 𝐟pos é multiplicada pela função Query 𝐟q ou Key das características 𝐟k na atenção cruzada. Em seguida, esse valor é adicionado aos pesos da atenção cruzada, seguido pela função SoftMax.
Vale destacar que a codificação posicional relativa proporciona maior flexibilidade e menor sensibilidade a erros em comparação com a atenção mascarada. Na prática, a codificação posicional relativa pode ser comparada a uma máscara suave, que permite ajustar dinamicamente os pesos da atenção, em vez de aplicar uma máscara rígida. Outra vantagem da codificação posicional relativa é sua capacidade de integrar informações semânticas e coletar seletivamente informações locais. Isso é alcançado através da interação entre as posições relativas e as características semânticas.
Como as consultas contextuais nas camadas do decodificador são atualizadas regularmente, não é ideal manter consultas posicionais estáticas ao longo de todo o processo de decodificação. Além disso, como as consultas posicionais iniciais são estáticas, é útil ajustá-las às características específicas da cena original nas camadas subsequentes. Para isso, os autores do método refinam iterativamente as consultas posicionais com base nas consultas de conteúdo. Em particular, eles utilizam uma MLP para prever o deslocamento do centro Δpt a partir da consulta de contexto atualizada 𝒬t+1c. O deslocamento resultante é então adicionado à consulta posicional anterior 𝒬tp..
A seguir, apresentamos a visualização do método MAFT.
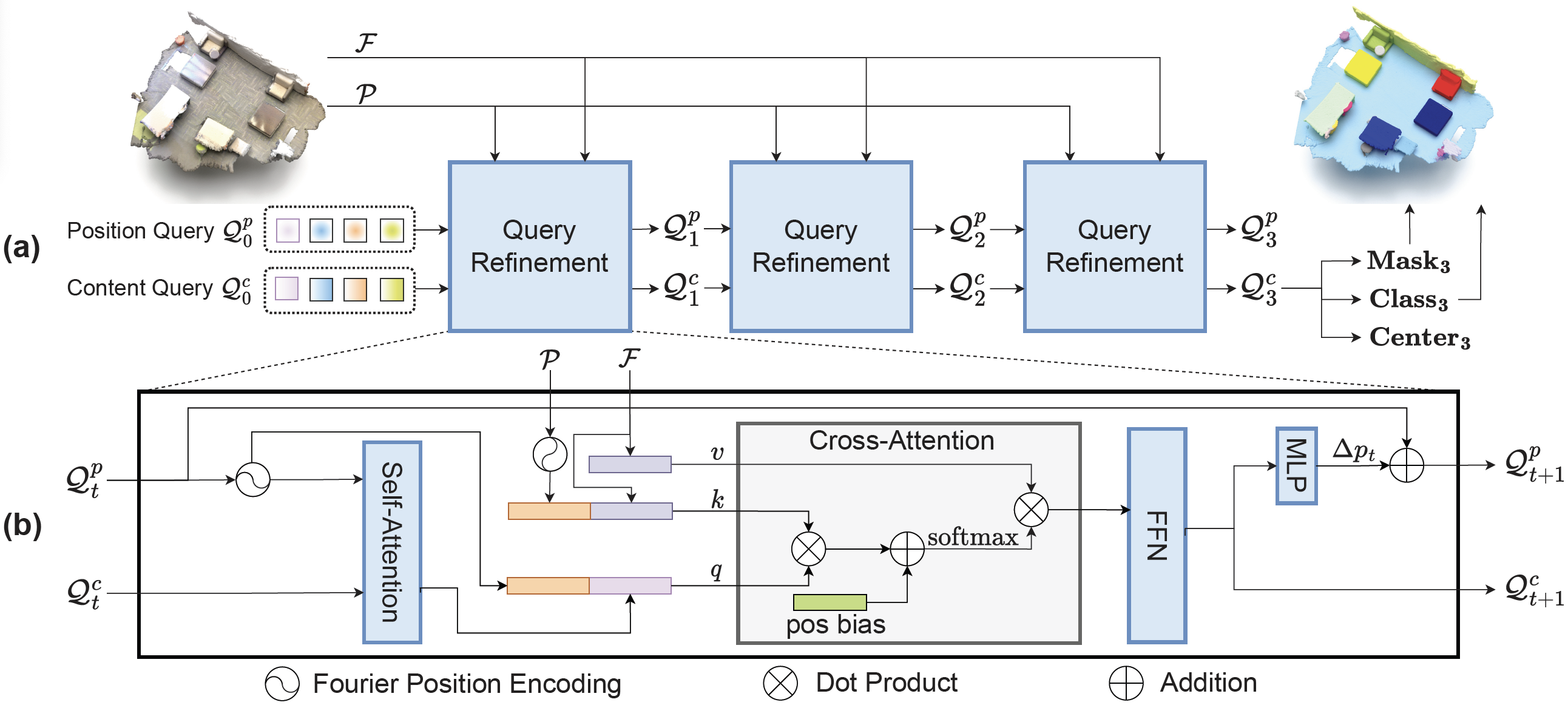
2. Implementação em MQL5
Após analisarmos os aspectos teóricos do método Mask-Attention-Free Transformer, passamos agora para a parte prática do artigo, onde implementamos nossa visão dos conceitos apresentados utilizando MQL5. Começaremos esse trabalho adicionando modificações ao programa OpenCL.
2.1 Expansão do programa OpenCL
Nosso primeiro passo será a construção do algoritmo de codificação posicional relativa. De um lado, o algoritmo é bastante simples. Precisamos apenas determinar a distância entre dois pontos. Além disso, os autores do método calculam a distância separadamente para cada coordenada. Por outro lado, os autores do MAFT realizam a quantização dos deslocamentos obtidos, que são então utilizados para buscar valores na tabela de parâmetros treináveis. Optamos por otimizar um pouco essa solução proposta. Nossa implementação baseia-se na suposição de que os pontos mais próximos da consulta analisada exercem a maior influência. Seguindo essa lógica, determinamos primeiro a distância S entre dois pontos em um espaço de N dimensões. Depois, calculamos o coeficiente de deslocamento posicional kpb pela seguinte fórmula:
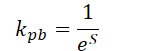
É evidente que a distância entre dois pontos nunca será inferior a 0. Quando os pontos coincidem, o coeficiente é igual a 1. À medida que a distância entre os pontos aumenta, o coeficiente de codificação posicional relativa tende a 0.
A implementação do algoritmo proposto é apresentada no kernel CalcPositionBias. Nos parâmetros do kernel, passamos ponteiros para três buffers globais de dados, dois dos quais contêm os dados de entrada. O terceiro buffer é destinado ao registro dos resultados. Aqui, também adicionamos a dimensionalidade do vetor de descrição de um único elemento.
É importante notar que, para calcular a distância entre dois vetores, é necessária a projeção deles em um mesmo subespaço. Isso implica que os vetores de descrição dos elementos em ambos os tensores de dados de entrada devem ter a mesma dimensionalidade.
__kernel void CalcPositionBias(__global const float *data1, __global const float *data2, __global float *result, const int dimension ) { const size_t idx1 = get_global_id(0); const size_t idx2 = get_global_id(1); const size_t total1 = get_global_size(0); const size_t total2 = get_global_size(1);
Planejamos executar o kernel em um espaço bidimensional de tarefas, onde cada dimensão corresponde ao número de elementos no respectivo tensor de dados de entrada. No corpo do kernel, identificamos imediatamente a thread atual em ambas as dimensões do espaço de tarefas.
No próximo passo, determinamos o deslocamento nos buffers de dados.
const int shift1 = idx1 * dimension; const int shift2 = idx2 * dimension; const int shift_out = idx1 * total2 + idx2;
Após a etapa preparatória, passamos para a execução direta dos cálculos. Primeiro, criamos um laço para calcular a distância entre os vetores analisados.
float res = 0; for(int i = 0; i < dimension; i++) res = pow(data1[shift1 + i] - data2[shift2 + i], 2.0f); res = sqrt(res);
Depois, calculamos o coeficiente de deslocamento relativo.
res = 1.0f / exp(res); if(isnan(res) || isinf(res)) res = 0; //--- result[shift_out] = res; }
O valor obtido é então gravado no respectivo elemento do buffer de resultados.
Observe que, entre os coeficientes obtidos, não há valores negativos. Isso significa que não estamos mascarando nenhum elemento na sequência de dados de entrada. Pelo contrário, a solução adotada enfatiza os elementos mais próximos.
Nesta etapa, calculamos os coeficientes de deslocamento posicional relativo. Agora, precisamos implementá-los em nosso mecanismo de atenção cruzada. Mas antes de prosseguirmos com essa implementação, gostaria de chamar sua atenção para um ponto específico. Observe a visualização do método MAFT apresentada anteriormente. Em particular, atente para o fluxo de informações na representação da cena. Aqui, destaca-se a abordagem dos autores do método quanto à codificação posicional da representação da cena. O ponto essencial é que a codificação posicional é aplicada apenas à entidade Key, enquanto Value permanece sem codificação posicional. Acredito que essa escolha foi intencional, permitindo o cálculo dos coeficientes de dependência considerando a codificação posicional, sem distorcer as características descritivas dos objetos da cena com essa mesma codificação. Isso implica que, para a geração das entidades Key e Value, será necessário utilizar diferentes fontes de dados. Em outras palavras, primeiro devemos gerar um tensor Value a partir da representação dos dados de entrada. Depois, adicionamos a codificação posicional aos dados de entrada. Somente então podemos gerar o tensor de entidades Key.
Por que escolhi discutir esse aspecto nesta fase do nosso trabalho? As reflexões apresentadas acima levam à necessidade de separar as entidades Key e Value em tensores distintos. Ao projetar um novo kernel para o algoritmo de atenção, podemos levar esse fator em consideração. Isso, por sua vez, nos permitirá eliminar a operação de concatenação de dois tensores, à qual recorríamos anteriormente.
Para implementar o algoritmo de atenção, criaremos o kernel MHPosBiasAttentionOut. Nos parâmetros do método, passamos uma lista abrangente de buffers globais de dados, cujos nomes já são familiares das implementações anteriores dos métodos de atenção. Aqui, também passamos um ponteiro para o buffer de índices do deslocamento posicional relativo pos_bias. Prevemos a operação do algoritmo clássico de atenção sem o uso dos coeficientes de deslocamento posicional. A ativação e desativação dessa funcionalidade são controladas pelo parâmetro use_pos_bias.
__kernel void MHPosBiasAttentionOut(__global const float *q, ///<[in] Matrix of Querys __global const float *k, ///<[in] Matrix of Keys __global const float *v, ///<[in] Matrix of Values __global float *score, ///<[out] Matrix of Scores __global const float *pos_bias, ///<[in] Position Bias __global float *out, ///<[out] Matrix of attention const int dimension, ///< Dimension of Key const int heads_kv, const int use_pos_bias ) { //--- const int q_id = get_global_id(0); const int k_id = get_global_id(1); const int h = get_global_id(2); const int qunits = get_global_size(0); const int kunits = get_global_size(1); const int heads = get_global_size(2);
Como antes, planejamos a execução desse kernel em um espaço tridimensional de tarefas. Os dois primeiros eixos representam a quantidade de elementos nas sequências analisadas, enquanto a terceira dimensão do espaço de tarefas indica o número de cabeças de atenção utilizadas. O algoritmo do kernel começa identificando a thread atual em todas as três dimensões do espaço de tarefas.
Em seguida, determinamos todas as constantes necessárias.
const int h_kv = h % heads_kv; const int shift_q = dimension * (q_id * heads + h); const int shift_kv = dimension * (heads_kv * k_id + h_kv); const int shift_s = kunits * (q_id * heads + h) + k_id; const int shift_pb = q_id * kunits + k_id; const uint ls = min((uint)get_local_size(1), (uint)LOCAL_ARRAY_SIZE); float koef = sqrt((float)dimension); if(koef < 1) koef = 1;
Criamos também um array de dados na memória local para a troca de informações entre as threads do grupo local.
__local float temp[LOCAL_ARRAY_SIZE];
Com isso, concluímos a fase preparatória e avançamos para os cálculos. O processo de cálculos é amplamente semelhante ao algoritmo clássico. Apenas adicionamos pontualmente os coeficientes de deslocamento posicional relativo, controlando sua utilização com base no valor do parâmetro use_pos_bias.
Primeiro, calculamos a soma exponencial dos coeficientes de atenção. Cada thread do grupo local calcula sua parte individualmente na primeira etapa e armazena o valor obtido no respectivo elemento do array de dados local.
//--- sum of exp uint count = 0; if(k_id < ls) { temp[k_id] = 0; do { if(q_id >= (count * ls + k_id)) if((count * ls) < (kunits - k_id)) { float sum = 0; int sh_k = dimension * heads_kv * count * ls; for(int d = 0; d < dimension; d++) sum = q[shift_q + d] * k[shift_kv + d + sh_k]; sum = exp(sum / koef); if(isnan(sum)) sum = 0; temp[k_id] = temp[k_id] + sum + (use_pos_bias > 0 ? pos_bias[shift_pb + count * ls] : 0); } count++; } while((count * ls + k_id) < kunits); } barrier(CLK_LOCAL_MEM_FENCE);
É importante notar que essa soma deve incluir também os coeficientes de deslocamento posicional relativo.
Depois, somamos os valores dos elementos do array local.
count = min(ls, (uint)kunits); //--- do { count = (count + 1) / 2; if(k_id < ls) temp[k_id] += (k_id < count && (k_id + count) < kunits ? temp[k_id + count] : 0); if(k_id + count < ls) temp[k_id + count] = 0; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
Após obter a soma total, determinamos e armazenamos os valores normalizados dos coeficientes de dependência, considerando os coeficientes de deslocamento posicional relativo.
//--- score float sum = temp[0]; float sc = 0; if(q_id >= (count * ls + k_id)) if(sum != 0) { for(int d = 0; d < dimension; d++) sc = q[shift_q + d] * k[shift_kv + d]; sc = (exp(sc / koef) + (use_pos_bias > 0 ? pos_bias[shift_pb] : 0)) / sum; if(isnan(sc)) sc = 0; } score[shift_s] = sc; barrier(CLK_LOCAL_MEM_FENCE);
Os coeficientes de atenção resultantes nos permitem calcular os valores finais da atenção multihead para cada elemento da sequência analisada.
//--- out for(int d = 0; d < dimension; d++) { uint count = 0; if(k_id < ls) do { if((count * ls) < (kunits - k_id)) { int sh_v = 2 * dimension * heads_kv * count * ls; float sum = v[shift_kv + d + sh_v] * (count == 0 ? sc : score[shift_s + count * ls]); if(isnan(sum)) sum = 0; temp[k_id] = (count > 0 ? temp[k_id] : 0) + sum; } count++; } while((count * ls + k_id) < kunits); barrier(CLK_LOCAL_MEM_FENCE); //--- count = min(ls, (uint)kunits); do { count = (count + 1) / 2; if(k_id < ls) temp[k_id] += (k_id < count && (k_id + count) < kunits ? temp[k_id + count] : 0); if(k_id + count < ls) temp[k_id + count] = 0; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1); //--- out[shift_q + d] = temp[0]; } }
Agora, precisamos implementar o algoritmo de propagação reversa do erro no kernel MHPosBiasAttentionInsideGradients. Aqui, vale lembrar que, ao distribuir o gradiente do erro em uma soma, normalmente repassamos o erro integralmente para ambos os termos. O uso de uma taxa de aprendizado significativamente inferior a 1 compensa amplamente a influência do duplo registro do erro. Outro ponto importante a destacar é que o cálculo dos coeficientes de deslocamento posicional relativo é baseado na localização real dos pontos no espaço. Esses são dados brutos e não dependem dos parâmetros do modelo. O próprio processo de cálculo não contém parâmetros treináveis. Portanto, repassar o gradiente do erro para o tensor de coeficientes de deslocamento posicional relativo não faz sentido. Por essa razão, eliminamos essa operação.
Dado o raciocínio apresentado acima, chegamos ao algoritmo clássico de distribuição do gradiente do erro através do bloco de atenção. No entanto, criamos um novo kernel, pois, conforme mencionado anteriormente, alocamos buffers de dados separados para as entidades Key e Value. Recomendo que você explore por conta própria o algoritmo do kernel de propagação reversa MHPosBiasAttentionInsideGradients, incluído como anexo. Com isso, concluímos o trabalho com o programa OpenCL.
2.2 Criação da classe MAFT
O próximo passo do nosso trabalho é a criação de um novo objeto, no qual implementamos nossa visão dos conceitos propostos pelos autores do método Mask-Attention-Free Transformer. Para isso, criamos a nova classe CNeuronMAFT.
Vale mencionar que os autores do MAFT construíram seu algoritmo com base no SPFormer, que analisamos anteriormente. Em nossa implementação, também utilizaremos elementos da classe CNeuronSPFormer. No entanto, a amplitude das modificações neutraliza as vantagens de herdar diretamente essa classe. Por essa razão, criamos nosso novo objeto como um descendente da classe base de camadas totalmente conectadas CNeuronBaseOCL. A estrutura da nova classe está apresentada a seguir.
class CNeuronMAFT : public CNeuronBaseOCL { protected: uint iWindow; uint iUnits; uint iHeads; uint iSPWindow; uint iSPUnits; uint iSPHeads; uint iWindowKey; uint iLayers; uint iLayersSP; //--- CLayer cSuperPoints; CLayer cQuery; CLayer cQPosition; CLayer cQKey; CLayer cQValue; CLayer cMHSelfAttentionOut; CLayer cSelfAttentionOut; CLayer cSPKey; CLayer cSPValue; CArrayInt cScores; CArrayInt cPositionBias; CLayer cMHCrossAttentionOut; CLayer cCrossAttentionOut; CLayer cResidual; CLayer cFeedForward; CBufferFloat cTempSP; CBufferFloat cTempQ; CBufferFloat cTempCrossK; CBufferFloat cTempCrossV; //--- virtual bool CreateBuffers(void); virtual bool CalcPositionBias(CBufferFloat *pos_q, CBufferFloat *pos_k, const int pos_bias, const int units, const int units_kv, const int dimension); virtual bool AttentionOut(CNeuronBaseOCL *q, CNeuronBaseOCL *k, CNeuronBaseOCL *v, const int scores, CNeuronBaseOCL *out, const int pos_bias, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension, const bool use_pos_bias); virtual bool AttentionInsideGradients(CNeuronBaseOCL *q, CNeuronBaseOCL *k, CNeuronBaseOCL *v, const int scores, CNeuronBaseOCL *out, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronMAFT(void) {}; ~CNeuronMAFT(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint window_sp, uint units_sp, uint heads_sp, uint layers, uint layers_to_sp, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronMAFT; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
Nela, encontramos um conjunto já familiar de métodos virtuais sobrescritos e um grande número de objetos internos. Parte desses objetos internos é semelhante aos que usamos anteriormente, mas há também novos elementos. Nos familiarizaremos com a funcionalidade de todos esses objetos internos ao longo da implementação dos métodos da classe CNeuronMAFT.
Assim como antes, todos os objetos internos foram declarados estaticamente, o que nos permite manter os construtores e destrutores da classe vazios. A inicialização de todos os objetos herdados e declarados ocorre no método de inicialização Init.
bool CNeuronMAFT::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint window_sp, uint units_sp, uint heads_sp, uint layers, uint layers_to_sp, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
Nos parâmetros desse método, recebemos as constantes principais que definem claramente a arquitetura do objeto criado. É fácil perceber que os parâmetros desse método foram completamente herdados do método homônimo da classe CNeuronSPFormer. Isso está alinhado com a abordagem baseada em herança que estabelecemos. No entanto, o algoritmo do método não passou por mudanças significativas.
No corpo do método, primeiro chamamos o método homônimo da classe pai, onde ocorre a verificação inicial dos parâmetros recebidos e a inicialização dos objetos herdados. Depois disso, armazenamos as constantes recebidas em variáveis internas da classe.
iWindow = window; iUnits = units_count; iHeads = heads; iSPUnits = units_sp; iSPWindow = window_sp; iSPHeads = heads_sp; iWindowKey = window_key; iLayers = MathMax(layers, 1); iLayersSP = MathMax(layers_to_sp, 1);
O próximo passo é a inicialização dos objetos responsáveis pela geração de consultas treináveis dos objetos e de sua codificação posicional. Os autores do MAFT propuseram inicializar as consultas com valores nulos. Seguiremos a mesma abordagem, zerando os parâmetros de geração de consultas.
CNeuronBaseOCL *base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(iWindow * iUnits, 0, OpenCL, 1, optimization, iBatch)) return false; CBufferFloat *buf = base.getOutput(); if(!buf || !buf.BufferInit(1, 1) || !buf.BufferWrite()) return false; buf = base.getWeights(); if(!buf || !buf.BufferInit(buf.Total(), 0) || !buf.BufferWrite()) return false; if(!cQuery.Add(base)) return false; base = new CNeuronBaseOCL(); if(!base || !base.Init(0, 1, OpenCL, iWindow * iUnits, optimization, iBatch)) return false; if(!cQuery.Add(base)) return false;
Neste ponto, também adicionamos a codificação posicional treinável, inicializada com valores aleatórios.
CNeuronLearnabledPE *pe = new CNeuronLearnabledPE(); if(!pe || !pe.Init(0, 2, OpenCL, base.Neurons(), optimization, iBatch)) return false; if(!cQuery.Add(pe)) return false;
Vale ressaltar que a codificação posicional percorre todo o algoritmo MAFT como um fluxo de informação separado. Portanto, alocamos objetos distintos para essa funcionalidade.
if(!base || !base.Init(0, 3, OpenCL, pe.Neurons(), optimization, iBatch)) return false; if(!base.SetOutput(pe.getOutput())) return false; if(!cQPosition.Add(base)) return false;
A próxima etapa é o pré-processamento dos dados. Aqui, adotamos a abordagem baseada em Superpoints, conforme apresentada no método SPFormer.
//--- Init SuperPoints int layer_id = 4; for(int r = 0; r < 4; r++) { if(iSPUnits % 2 == 0) { iSPUnits /= 2; CResidualConv *residual = new CResidualConv(); if(!residual) return false; if(!residual.Init(0, layer_id, OpenCL, 2 * iSPWindow, iSPWindow, iSPUnits, optimization, iBatch)) return false; if(!cSuperPoints.Add(residual)) return false; } else { iSPUnits--; CNeuronConvOCL *conv = new CNeuronConvOCL(); if(!conv.Init(0, layer_id, OpenCL, 2 * iSPWindow, iSPWindow, iSPWindow, iSPUnits, 1, optimization, iBatch)) return false; if(!cSuperPoints.Add(conv)) return false; } layer_id++; }
É importante notar que a implementação apresentada permite o uso de tensores de diferentes dimensões na atenção cruzada. No entanto, isso não é permitido no algoritmo dos coeficientes de deslocamento posicional relativo proposto. Por esse motivo, adicionamos uma camada de projeção dos superpontos no espaço das consultas treináveis.
CNeuronConvOCL *conv = new CNeuronConvOCL(); if(!conv.Init(0, layer_id, OpenCL, iSPWindow, iSPWindow, iWindow, iSPUnits, 1, optimization, iBatch)) return false; if(!cSuperPoints.Add(conv)) return false; layer_id++;
Além disso, incluímos uma camada de codificação posicional.
pe = new CNeuronLearnabledPE(); if(!pe || !pe.Init(0, layer_id, OpenCL, conv.Neurons(), optimization, iBatch)) return false; if(!cSuperPoints.Add(pe)) return false; layer_id++;
Vale mencionar que, neste ponto, nos desviamos um pouco do algoritmo proposto pelos autores do MAFT. Em seu trabalho, eles utilizaram a voxelização da nuvem de pontos com base nas coordenadas originais. Já nós optamos por um codificação posicional totalmente treinável, permitindo que o modelo aprenda as posições ideais para cada elemento da sequência de dados de entrada.
Após concluir o pré-processamento dos dados de entrada, criamos um laço para iterar pelos camadas internas do decodificador.
//--- Inside layers for(uint l = 0; l < iLayers; l++) { //--- Self-Attention //--- Query conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, layer_id, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; if(!cQuery.Add(conv)) return false; layer_id++;
Aqui, vale ressaltar que os autores do MAFT utilizam a configuração clássica: Self-Attention → Cross-Attention → Feed Forward. Enquanto isso, os autores do SPFormer inverteram a ordem de Self-Attention e Cross-Attention.
Primeiro, geramos as entidades Query. Em seguida, adicionamos as entidades Key e Value.
//--- Key conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, layer_id, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; if(!cQKey.Add(conv)) return false; layer_id++; //--- Value conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, layer_id, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; if(!cQValue.Add(conv)) return false; layer_id++;
Esperamos utilizar uma quantidade reduzida de consultas treináveis, portanto, não reduzimos o número de cabeças para Key-Value e geramos novas entidades em cada camada interna.
As entidades geradas são então passadas para o bloco de atenção multihead sem a utilização de coeficientes de deslocamento posicional.
//--- Multy-Heads Attention Out base = new CNeuronBaseOCL(); if(!base || !base.Init(0, layer_id, OpenCL, iWindowKey * iHeads * iUnits, optimization, iBatch)) return false; if(!cMHSelfAttentionOut.Add(base)) return false; layer_id++;
Adicionamos, em seguida, uma camada de escalonamento dos resultados da atenção multihead.
//--- Self-Attention Out conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, layer_id, OpenCL, iWindowKey * iHeads, iWindowKey * iHeads, iWindow, iUnits, 1, optimization, iBatch)) return false; if(!cSelfAttentionOut.Add(conv)) return false; layer_id++;
Ao final do bloco Self-Attention, seguindo o algoritmo do Transformer clássico, adicionamos uma camada de conexões residuais.
//--- Residual base = new CNeuronBaseOCL(); if(!base || !base.Init(0, layer_id, OpenCL, iWindow * iUnits, optimization, iBatch)) return false; if(!cResidual.Add(base)) return false; layer_id++;
Prosseguimos então para a configuração dos objetos do bloco de atenção cruzada. Começamos, como de costume, gerando o tensor da entidade Query.
//--- Cross-Attention //--- Query conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, layer_id, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; if(!cQuery.Add(conv)) return false; layer_id++;
Depois, adicionamos os tensores das entidades Key e Value. Desta vez, seguimos as configurações definidas pelo usuário para redução do número de cabeças de atenção e a alternância entre camadas.
if(l % iLayersSP == 0) { //--- Key conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, layer_id, OpenCL, iWindow, iWindow, iWindowKey * iSPHeads, iSPUnits, 1, optimization, iBatch)) return false; if(!cSPKey.Add(conv)) return false; layer_id++; //--- Value conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, layer_id, OpenCL, iWindow, iWindow, iWindowKey * iSPHeads, iSPUnits, 1, optimization, iBatch)) return false; if(!cSPValue.Add(conv)) return false; layer_id++; }
Adicionamos a camada de resultados da atenção multihead.
//--- Multy-Heads Attention Out base = new CNeuronBaseOCL(); if(!base || !base.Init(0, layer_id, OpenCL, iWindowKey * iHeads * iUnits, optimization, iBatch)) return false; if(!cMHCrossAttentionOut.Add(base)) return false; layer_id++;
Que, posteriormente, é escalonada e complementada com conexões residuais.
//--- Cross-Attention Out conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, layer_id, OpenCL, iWindowKey * iHeads, iWindowKey * iHeads, iWindow, iUnits, 1, optimization, iBatch)) return false; if(!cCrossAttentionOut.Add(conv)) return false; layer_id++; //--- Residual base = new CNeuronBaseOCL(); if(!base || !base.Init(0, layer_id, OpenCL, iWindow * iUnits, optimization, iBatch)) return false; if(!cResidual.Add(base)) return false; layer_id++;
O decodificador é finalizado com o bloco FeedForward, ao qual também adicionamos conexões residuais.
//--- Feed Forward conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, layer_id, OpenCL, iWindow, iWindow, 4 * iWindow, iUnits, 1, optimization, iBatch)) return false; conv.SetActivationFunction(LReLU); if(!cFeedForward.Add(conv)) return false; layer_id++; conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, layer_id, OpenCL, 4 * iWindow, 4 * iWindow, iWindow, iUnits, 1, optimization, iBatch)) return false; if(!cFeedForward.Add(conv)) return false; layer_id++; //--- Residual base = new CNeuronBaseOCL(); if(!base || !base.Init(0, layer_id, OpenCL, iWindow * iUnits, optimization, iBatch)) return false; if(!base.SetGradient(conv.getGradient())) return false; if(!cResidual.Add(base)) return false; layer_id++;
Resta agora adicionar a MLP para ajustar a codificação posicional das consultas treináveis.
//--- Delta position conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, layer_id, OpenCL, iWindow, iWindow, iWindow, iUnits, 1, optimization, iBatch)) return false; conv.SetActivationFunction(SIGMOID); if(!cQPosition.Add(conv)) return false; layer_id++; base = new CNeuronBaseOCL(); if(!base || !base.Init(0, layer_id, OpenCL, conv.Neurons(), optimization, iBatch)) return false; if(!base.SetGradient(conv.getGradient())) return false; if(!cQPosition.Add(base)) return false; layer_id++; }
Com isso, avançamos para a próxima iteração do laço, criando os objetos para uma nova camada interna do decodificador.
Após a inicialização bem-sucedida de todos os objetos internos do decodificador, realizamos a substituição dos ponteiros para os buffers de gradientes do erro e retornamos um valor lógico à função chamadora para indicar o sucesso das operações realizadas.
base = cResidual[iLayers * 3 - 1]; if(!SetGradient(base.getGradient())) return false; //--- SetOpenCL(OpenCL); //--- return true; }
Vale mencionar que a inicialização dos buffers auxiliares foi isolada em um método separado, CreateBuffers, cujo funcionamento recomendo que você explore por conta própria.
Lembro que o código completo desta classe e todos os seus métodos podem ser encontrados no anexo.
Agora, após a inicialização dos objetos internos, seguimos para a construção do algoritmo de propagação para frente no método feedForward. Nos parâmetros desse método, recebemos um ponteiro para o objeto de dados de entrada.
bool CNeuronMAFT::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- Superpoints CNeuronBaseOCL *superpoints = NeuronOCL; int total_sp = cSuperPoints.Total(); for(int i = 0; i < total_sp; i++) { if(!cSuperPoints[i] || !((CNeuronBaseOCL*)cSuperPoints[i]).FeedForward(superpoints)) return false; superpoints = cSuperPoints[i]; }
E utilizamos imediatamente o objeto obtido no processo de geração das características dos superpontos. Para isso, empregamos o modelo aninhado cSuperPoints.
Aqui, é importante lembrar que a última camada desse modelo é a camada de codificação posicional.
Prosseguimos gerando as consultas treináveis com codificação posicional.
//--- Query CNeuronBaseOCL *inputs = NULL; for(int i = 0; i < 2; i++) { inputs = cQuery[i + 1]; if(!inputs || !inputs.FeedForward(cQuery[i])) return false; }
Também criamos variáveis locais para armazenar temporariamente os ponteiros para os objetos.
CNeuronBaseOCL *query = NULL, *key = NULL, *value = NULL, *base = NULL;
Fazemos um laço para iterar sobre as camadas internas do decodificador.
//--- Inside layers for(uint l = 0; l < iLayers; l++) { //--- Self-Atention query = cQuery[l * 2 + 3]; if(!query || !query.FeedForward(inputs)) return false; key = cQKey[l]; if(!key || !key.FeedForward(inputs)) return false; value = cQValue[l]; if(!value || !value.FeedForward(inputs)) return false;
Inicialmente, configuramos o bloco Self-Attention, utilizando o conjunto de consultas treináveis com codificação posicional. Para isso, primeiro geramos as entidades necessárias e as enviamos ao bloco de atenção multihead.
if(!AttentionOut(query, key, value, cScores[l * 2], cMHSelfAttentionOut[l], -1, iUnits, iHeads, iUnits, iHeads, iWindowKey, false)) return false;
Em seguida, escalonamos os resultados obtidos e adicionamos conexões residuais.
base = cSelfAttentionOut[l]; if(!base || !base.FeedForward(cMHSelfAttentionOut[l])) return false; value = cResidual[l * 3]; if(!value || !SumAndNormilize(inputs.getOutput(), base.getOutput(), value.getOutput(), iWindow, true, 0, 0, 0, 1)) return false; inputs = value;
A codificação posicional é adicionada separadamente como um fluxo paralelo.
value = cQPosition[l * 2]; if(!value || !SumAndNormilize(inputs.getOutput(), value.getOutput(),inputs.getOutput(), iWindow, false, 0, 0, 0, 1)) return false;
Depois disso, seguimos para o bloco de atenção cruzada. Antes de prosseguir, determinamos os coeficientes de deslocamento posicional relativo.
//--- Calc Position bias if(!CalcPositionBias(value.getOutput(), ((CNeuronLearnabledPE*)superpoints).GetPE(), cPositionBias[l], iUnits, iSPUnits, iWindow)) return false;
Geramos a entidade Query a partir do tensor de consultas posicionais, considerando a codificação posicional.
//--- Cross-Attention query = cQuery[l * 2 + 4]; if(!query || !query.FeedForward(inputs)) return false;
A organização das entidades Key e Value exige atenção a alguns detalhes. Primeiro, a geração de novos tensores ocorre apenas quando necessário.
key = cSPKey[l / iLayersSP]; value = cSPValue[l / iLayersSP]; if(l % iLayersSP == 0) { if(!key || !key.FeedForward(superpoints)) return false; if(!value || !value.FeedForward(cSuperPoints[total_sp - 2])) return false; }
Segundo, a entidade Key é gerada a partir dos dados da última camada do cSuperPoints, que contém a codificação posicional. Já a entidade Value é gerada a partir da penúltima camada, onde não há codificação posicional.
As entidades geradas são então enviadas ao bloco de atenção multihead, considerando os coeficientes de deslocamento posicional relativo.
if(!AttentionOut(query, key, value, cScores[l * 2 + 1], cMHCrossAttentionOut[l], cPositionBias[l], iUnits, iHeads, iSPUnits, iSPHeads, iWindowKey, true)) return false;
Depois, os dados resultantes são escalonados e complementados com conexões residuais.
base = cCrossAttentionOut[l]; if(!base || !base.FeedForward(cMHCrossAttentionOut[l])) return false; value = cResidual[l * 3 + 1]; if(!value || !SumAndNormilize(inputs.getOutput(), base.getOutput(), value.getOutput(), iWindow, true, 0, 0, 0, 1)) return false; inputs = value;
O decodificador é finalizado passando os dados pelo bloco FeedForward, seguido por conexões residuais.
//--- Feed Forward base = cFeedForward[l * 2]; if(!base || !base.FeedForward(inputs)) return false; base = cFeedForward[l * 2 + 1]; if(!base || !base.FeedForward(cFeedForward[l * 2])) return false; value = cResidual[l * 3 + 2]; if(!value || !SumAndNormilize(inputs.getOutput(), base.getOutput(), value.getOutput(), iWindow, true, 0, 0, 0, 1)) return false; inputs = value;
Neste ponto, concluímos as operações de uma camada do decodificador, mas ainda precisamos corrigir os dados de codificação posicional das consultas treináveis. Com base nos dados obtidos, geramos um deslocamento posicional e o adicionamos aos valores existentes.
//--- Delta Query position base = cQPosition[l * 2 + 1]; if(!base || !base.FeedForward(inputs)) return false; value = cQPosition[(l + 1) * 2]; query = cQPosition[l * 2]; if(!value || !SumAndNormilize(query.getOutput(), base.getOutput(), value.getOutput(), iWindow, false, 0,0,0,0.5f)) return false; }
Agora, podemos avançar para a execução das operações da próxima camada interna do decodificador.
Após a execução bem-sucedida de todas as camadas internas do decodificador, obtemos como resultado consultas enriquecidas e suas posições ajustadas. Somamos os dois tensores resultantes e os enviamos para a cabeça de previsão.
value = cQPosition[iLayers * 2]; if(!value || !SumAndNormilize(inputs.getOutput(), value.getOutput(), Output, iWindow, true, 0, 0, 0, 1)) return false; //--- return true; }
O programa chamador recebe um valor lógico indicando o sucesso da execução das operações.
Com isso, finalizamos a construção do algoritmo de propagação para frente. Agora, seguimos com a implementação dos algoritmos de propagação reversa, realizados nos métodos calcInputGradients e updateInputWeights. O primeiro organiza o algoritmo de distribuição dos gradientes do erro para todos os objetos internos, conforme sua influência no resultado final. O segundo realiza a atualização dos parâmetros do modelo.
Como você sabe, a distribuição dos gradientes do erro ocorre seguindo o fluxo de informações do algoritmo de propagação para frente, mas no sentido inverso. Recomendo que você explore por conta própria a lógica desses métodos.
Lembro que o código completo desta classe e todos os seus métodos podem ser encontrados no anexo.
A arquitetura dos modelos treinados neste estudo, assim como todos os programas utilizados para seu treinamento e interação com o ambiente, foi completamente herdada de trabalhos anteriores. Na prática, na arquitetura do codificador do estado do ambiente, apenas alteramos o identificador de uma camada. Por isso, não entraremos em mais detalhes sobre essa parte. O código completo de todas as classes e programas utilizados na preparação deste artigo está disponível no anexo.
3. Teste
Neste artigo, exploramos o método MAFT e implementamos nossa visão dos conceitos propostos utilizando MQL5. Agora chegamos à etapa de avaliação do trabalho realizado. Precisamos treinar o modelo com a tecnologia MAFT utilizando dados históricos reais e testar a política treinada do Ator.
Para o treinamento do modelo, utilizamos dados históricos reais do ativo EURUSD ao longo de todo o ano de 2023 no timeframe H1. Todos os parâmetros dos indicadores analisados foram mantidos com seus valores padrão.
O algoritmo de treinamento das modelos foi reaproveitado de pesquisas anteriores, juntamente com os programas correspondentes para treinamento e testes.
O teste da política treinada do Ator foi realizado no testador de estratégias do MetaTrader 5 usando dados históricos de janeiro de 2024, mantendo todos os outros parâmetros inalterados. Os resultados do teste são apresentados abaixo.
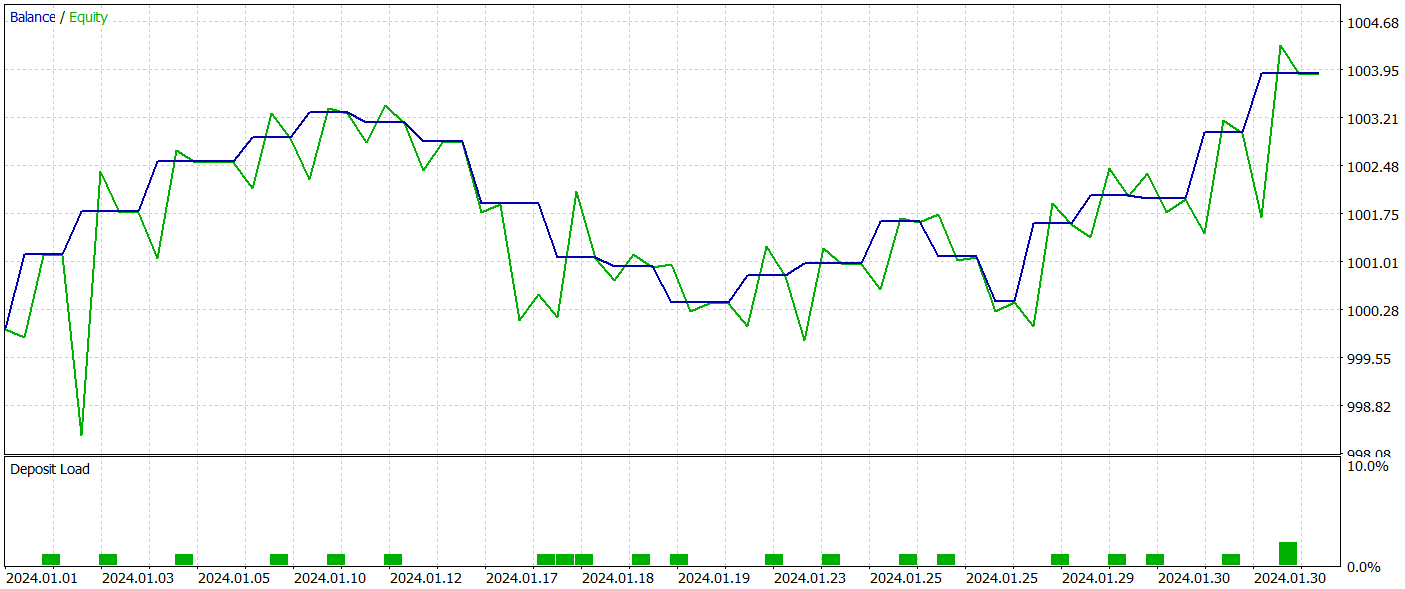
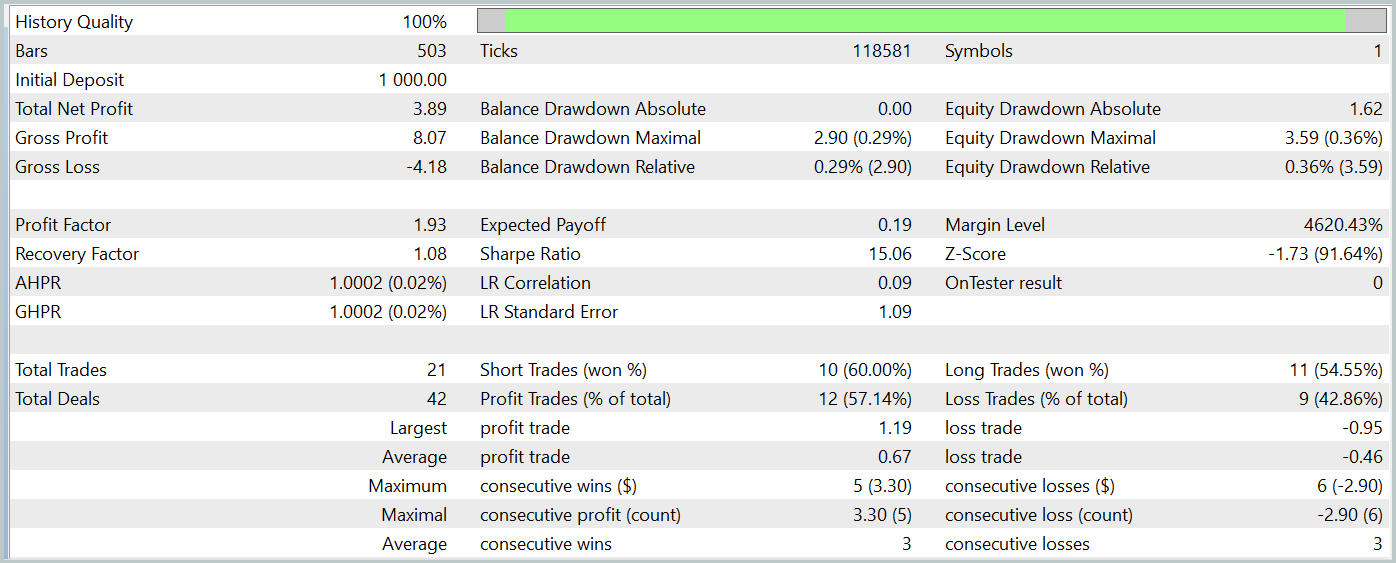
O gráfico de saldo do período de teste mostra uma tendência de crescimento, o que é, sem dúvida, um ponto positivo. No entanto, durante todo o período de teste, o modelo realizou apenas 21 operações, das quais 12 foram fechadas com lucro. Infelizmente, o baixo número de negociações realizadas não nos permite avaliar a eficácia do modelo em um intervalo de tempo mais longo.
Considerações finais
Neste artigo, analisamos o método Mask-Attention-Free Transformer (MAFT) e sua aplicação no trading algorítmico. Diferentemente dos Transformer clássicos, MAFT demonstra alta eficiência computacional, eliminando a necessidade de mascaramento de dados e acelerando o processamento de sequências.
Os resultados dos testes confirmaram que o MAFT pode melhorar a qualidade das previsões, além de reduzir o tempo de treinamento dos modelos.
Referências
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA para coleta de exemplos |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA para coleta de exemplos pelo método Real-ORL |
| 3 | Study.mq5 | Expert Advisor | EA para treinamento de Modelos |
| 4 | Test.mq5 | Expert Advisor | EA para teste do modelo |
| 5 | Trajectory.mqh | Biblioteca de classe | Estrutura para descrição do estado do sistema |
| 6 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de redes neurais |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca com código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/15973
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Olá, Dmitriy,
Parece que seus arquivos zip foram criados incorretamente. Eu esperava ver o código-fonte listado na sua caixa, mas é isso que o zip contém. Parece que cada diretório listado contém os arquivos que você usou em seus vários artigos. Você poderia fornecer uma descrição de cada um ou, melhor ainda, anexar o número do artigo a cada diretório, conforme apropriado.
Obrigado
CapeCoddah
Oi Dmitriy,
Parece que seus arquivos zip foram criados incorretamente. Eu esperava ver o código-fonte listado na sua caixa, mas é isso que o zip contém. Parece que cada diretório listado contém os arquivos que você usou em seus vários artigos. Você poderia fornecer uma descrição de cada um ou, melhor ainda, anexar o número do artigo a cada diretório, conforme apropriado.
Muito obrigado
CapeCoddah
Oi CapeCoddah,
O arquivo zip contém arquivos de todas as séries. O programa OpenCL foi salvo em "MQL5\Experts\NeuroNet_DNG\NeuroNet.cl". A biblioteca com todas as classes pode ser encontrada em "MQL5\Experts\NeuroNet_DNG\NeuroNet.mqh". E o modelo e os especialistas mencionados neste artigo estão localizados no diretório "MQL5\Experts\MAFT\"
Atenciosamente,
Dmitriy.
Oi CapeCoddah,
O arquivo zip contém arquivos de todas as séries. O programa OpenCL foi salvo em "MQL5\Experts\NeuroNet_DNG\NeuroNet.cl". A biblioteca com todas as classes pode ser encontrada em "MQL5\Experts\NeuroNet_DNG\NeuroNet.mqh". E o modelo e os especialistas mencionados neste artigo estão localizados no diretório "MQL5\Experts\MAFT\"
Atenciosamente,
Dmitriy.
Olá, Dmitriy,
Obrigado pela pronta resposta. Entendo o que você está dizendo, mas acho que você não me entendeu. Como faço para associar os nomes dos subdiretórios ao respectivo artigo, seja por nome ou por número de artigo, a partir do qual é possível pesquisar para encontrar o artigo.
Abraços
CapeCoddah
Oi Dmitriy,
Obrigado pela resposta rápida. Entendo o que você está dizendo, mas acho que você não me entendeu. Como faço para associar os nomes dos subdiretórios ao respectivo artigo, seja por nome ou por número de artigo, a partir do qual é possível pesquisar para encontrar o artigo.
Obrigado
CapeCoddah
Pelo nome da estrutura