
Redes neurais de maneira fácil (Parte 81): Análise da dinâmica dos dados considerando o contexto (CCMR)

Introdução
Nesta série, exploramos vários métodos de análise do estado do ambiente e algoritmos para usar os dados obtidos. Usamos modelos convolucionais para identificar padrões consistentes em dados históricos de movimento de preço e modelos de atenção para buscar dependências entre estados locais específicos do ambiente. No entanto, sempre avaliamos os estados do ambiente como "fotografias" em momentos específicos, sem analisar a dinâmica dos indicadores do estado do ambiente. Assumimos que o modelo, ao analisar e comparar os estados do ambiente, notaria as mudanças chave, mas não representamos explicitamente essa dinâmica de maneira quantitativa.
No entanto, no campo da visão computacional, existe uma tarefa importante chamada de avaliação do fluxo óptico, que mostra informações sobre o movimento dos objetos na cena. E em relação a essa tarefa, foi proposto uma série de algoritmos interessantes, amplamente aplicados. Os resultados da avaliação do fluxo óptico são aplicados em várias áreas, como condução autônoma, rastreamento e observação de objetos.
A maioria das abordagens atuais usa redes neurais convolucionais, embora elas não disponham de contexto global. Isso dificulta a análise da oclusão de objetos ou de grandes deslocamentos. Uma abordagem alternativa consiste no uso de transformadores e métodos de atenção, que permitem ir além do campo de visão fixo das CNN clássicas.
Um método particularmente interessante neste contexto é o CCMR, apresentado no artigo "CCMR: High Resolution Optical Flow Estimation via Coarse-to-Fine Context-Guided Motion Reasoning". Esta forma de avaliar o fluxo óptico combina as vantagens dos métodos focados na agregação de movimento e em técnicas multiescala de alta resolução. Ela integra passo a passo ideias de agrupamento de movimento (baseadas no contexto) em um esquema que avalia a resolução grosseira e fina. Isso permite ter campos de fluxo detalhados que também oferecem alta precisão em áreas oclusas. Nesse contexto, é proposta uma estratégia de agrupamento de movimento em duas etapas: primeiro estimamos características contextuais de auto-atenção global, que usamos, então, para orientar características de movimento iterativamente em todas as escalas. Assim, o raciocínio sobre o movimento orientado por contexto baseado no XCiT assegura o processamento em todas as escalas grosseiras e finas. Experimentos realizados pelos autores do método mostram que a abordagem proposta tem um desempenho forte e destacam as vantagens de seus principais conceitos.
1. Algoritmo CCMR
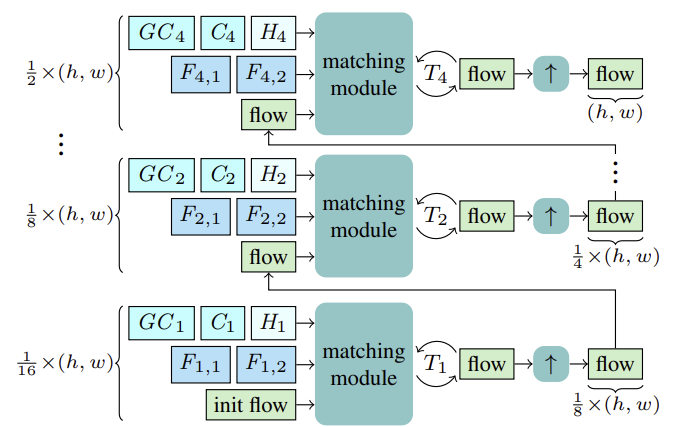
O método CCMR avalia o fluxo óptico utilizando atualizações recorrentes em escalas grosseiras e fina, com o uso de uma unidade recorrente fechada (GRU). Antes de iniciar a avaliação para cada escala S, estimamos as características de dois estados consecutivos Fs,1, Fs,2 para mapeamento. Além disso, calculamos as características contextuais Cs e, com base nelas, as características contextuais globais GCs, bem como o estado oculto inicial Hs para a escala atual do bloco recorrente a partir do estado de referência I1.
Começando pela escala mais grosseira 1/16, o fluxo é calculado com base nas características mencionadas F1,1, F1,2, C1, GC1, H1. Após T1 atualizações recorrentes, aumentamos a resolução do fluxo estimado usando um módulo comum de aumento 2x convexo, onde o fluxo inicializa o processo de mapeamento na próxima escala mais fina. Esse processo continua até calcularmos o fluxo na escala mais fina 1/2 e o aumentarmos de volta para a resolução original.
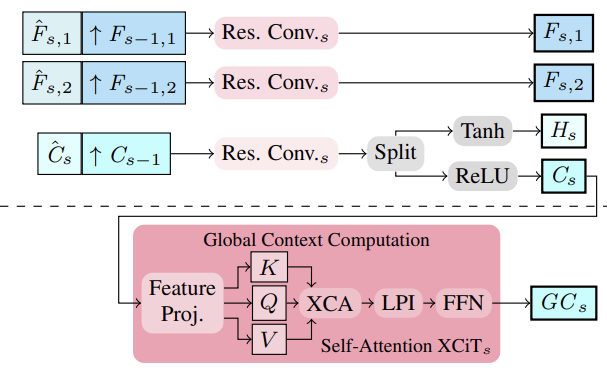
Os autores do método propuseram extrair características de imagem e contexto em múltiplas escalas utilizando um extrator de características. Para isso, calculam-se inicialmente as características intermediárias de cima para baixo, em seguida, para obter características multiescala mais estruturadas e refinadas Fs,1, Fs,2 e Cs, essas características são semanticamente aprimoradas pela combinação com características mais profundas da escala mais grosseira Fs−1,1, Fs−1,2 e Cs−1 para S ∈ {2, 3, 4}. Assim, consolidamos ao juntar características mais grosseiras ampliadas com características intermediárias mais finas e agregando-as.
As características contextuais multiescala Cs são a base para calcular as características contextuais globais. Aqui, o objetivo é obter características mais significativas que são então utilizadas para guiar o movimento. Para isso, é realizada a agregação de características contextuais Cs utilizando estatísticas de canais através de uma camada XCiT, que assegura complexidade linear em relação ao número de tokens. Essa escolha de arquitetura permite agregar contexto em todas as escalas, tanto grosseiras quanto finas, durante a avaliação. É importante notar que a abordagem CCMR proposta pelos autores ao usar o XCiT difere de sua abordagem original, onde a camada XCiT é aplicada a uma representação mais grosseira de suas entradas,realizada por meio de uma divisão explícita em patches, e depois aumentada novamente para a resolução original. No CCMR, por outro lado, a camada XCiT é aplicada diretamente às características em todas as escalas grosseiras e finas, utilizando conteúdo específico da escala. Para calcular o contexto global, primeiro é adicionada a codificação posicional às características contextuais Cs. Em seguida, é realizada a normalização da camada. Neste ponto, para aplicar a Autoatenção, todas as Query, Key e Value são calculadas a partir de Csp. Antes de aplicar a etapa de atenção de covariância-cruzada, os canais KCs, QCs, VCs são reformatados em h cabeças. Em seguida, a atenção de covariância-cruzada XCA(KCs, QCs, VCs) é calculada. Após isso, é aplicada uma camada de interação local de patches (LPI), e depois um bloco FFN.
Enquanto a atenção de covariância-cruzada assegura interações globais entre canais em cada cabeça, os módulos LPI e FFN garantem interações espaciais explícitas entre tokens localmente e a conexão entre todos os canais, respectivamente.
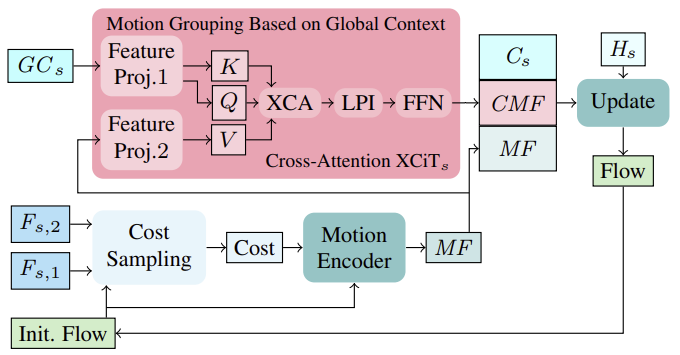
Primeiro, baseado no fluxo inicial na primeira iteração (ou no fluxo atualizado nas iterações seguintes), os custos de correspondência na vizinhança são calculados a partir das características da imagem (Fs,1, Fs,2). Os custos calculados, juntamente com a avaliação atual do fluxo, são então processados através de um codificador de movimento, que gera características de movimento que são eventualmente usadas no GRU para calcular a atualização do fluxo.
Ao calcular atualizações recorrentes do fluxo, incluir características de movimento globalmente agregadas com base nas características contextuais pode ajudar a resolver ambiguidades em áreas oclusas. Isso faz sentido, pois o movimento dos pixels oclusos de um objeto parcialmente não ocluso geralmente pode ser determinado pelo movimento de seus pixels não oclusos. Para agregar características de movimento em uma única escala, os autores do método adotam uma estratégia eficiente usando estatísticas globais dos canais, calculando o contexto global em todas as escalas, tanto grosseiras quanto finas. A agregação de movimento é realizada aplicando a camada de atenção cruzada XCiT às características contextuais globais GCs e características de movimento MF. Assim, Query e Key são calculados a partir das características contextuais globais GCs e Value das características de movimento diretamente em cada escala, sem divisão explícita em patches. Após aplicar XCA, LPI e FFN ao Query, Key e Value do contexto, as características de movimento orientadas por contexto (CMF), as características contextuais Cs e as características de movimento iniciais MF são combinadas e passadas através de um bloco recorrente para o cálculo iterativo da atualização do fluxo.
Observe que a aplicação de atenção cruzada por tokens para realizar a agregação de movimento em esquemas de ajuste grosseiro e fino não é viável em termos de uso de memória.
A visualização do método CCMR pelos autores é apresentada abaixo.
2. Implementação com MQL5
Após revisar os aspectos teóricos do método CCMR, passamos à parte prática do nosso artigo, na qual implementamos as abordagens propostas com MQL5. Como é evidente, a arquitetura proposta é bastante complexa e abrangente. Por isso, implementamos os algoritmos propostos dividindo-os em vários blocos.
2.1 Bloco convolucional com feedback
Primeiro, vamos analisar o bloco convolucional com feedback. Para sua implementação, criaremos a classe CResidualConv, que herdará a funcionalidade básica da classe de camada totalmente conectada CNeuronBaseOCL.
A estrutura da nova classe é apresentada abaixo. E, como pode-se notar, ela contém um conjunto familiar de métodos.
class CResidualConv : public CNeuronBaseOCL { protected: int iWindowOut; //--- CNeuronConvOCL cConvs[3]; CNeuronBatchNormOCL cNorm[3]; CNeuronBaseOCL cTemp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CResidualConv(void) {}; ~CResidualConv(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defResidualConv; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); virtual void TrainMode(bool flag); ///< Set Training Mode Flag };
Na funcionalidade da classe serão usados 3 blocos de camada convolucional e normalização em lotes. Todas as camadas internas são declaradas como estáticas, o que nos permite deixar o construtor e o destrutor da classe vazios.
A inicialização do objeto da classe é realizada no método Init. Nos parâmetros do método, passaremos as constantes que definem a arquitetura da classe.
bool CResidualConv::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_out * count, optimization_type, batch)) return false;
Dentro do método, usamos o método correspondente da classe pai para controlar os parâmetros recebidos e inicializar os objetos herdados.
Após a execução bem-sucedida do método da classe pai, inicializamos os objetos internos.
if(!cConvs[0].Init(0, 0, OpenCL, window, window, window_out, count, optimization, iBatch)) return false; if(!cNorm[0].Init(0, 1, OpenCL, window_out * count, iBatch, optimization)) return false; cNorm[0].SetActivationFunction(LReLU);
Para extrair características do estado analisado do ambiente, usaremos 2 blocos de camadas convolucionais sequenciais e normalização em lotes com a função LReLU para criar não linearidade entre eles.
if(!cConvs[1].Init(0, 2, OpenCL, window_out, window_out, window_out, count, optimization, iBatch)) return false; if(!cNorm[1].Init(0, 3, OpenCL, window_out * count, iBatch, optimization)) return false; cNorm[1].SetActivationFunction(None);
O terceiro bloco de camada convolucional e normalização em lotes (sem função de ativação) será usado para dimensionar os dados brutos ao tamanho dos resultados do nosso CResidualConv. Isso nos permitirá realizar o segundo fluxo de dados.
if(!cConvs[2].Init(0, 4, OpenCL, window, window, window_out, count, optimization, iBatch)) return false; if(!cNorm[2].Init(0, 5, OpenCL, window_out * count, iBatch, optimization)) return false; cNorm[2].SetActivationFunction(None);
A criação de 2 fluxos de dados paralelos nos obriga a transmitir o gradiente de erro em fluxos semelhantes de forma simultânea. Para a soma dos gradientes de erro, usaremos uma camada interna auxiliar.
if(!cTemp.Init(0, 6, OpenCL, window * count, optimization, batch)) return false;
Para evitar copiar dados repetidamente, substituiremos os buffers de dados.
cNorm[1].SetGradientIndex(getGradientIndex()); cNorm[2].SetGradientIndex(getGradientIndex()); SetActivationFunction(None); iWindowOut = (int)window_out; //--- return true; }
A funcionalidade de propagação para frente será implementada no método CResidualConv::feedForward. Nos parâmetros do método, receberemos um ponteiro para a camada neural anterior.
bool CResidualConv::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- if(!cConvs[0].FeedForward(NeuronOCL)) return false; if(!cNorm[0].FeedForward(GetPointer(cConvs[0]))) return false;
No corpo do método, não verificamos novamente o ponteiro recebido, pois essa verificação já é feita nos métodos correspondentes das camadas internas. Assim, vamos direto para a chamada dos métodos que propagam para frente nas camadas internas.
if(!cConvs[1].FeedForward(GetPointer(cNorm[0]))) return false; if(!cNorm[1].FeedForward(GetPointer(cConvs[1]))) return false;
Como já foi dito acima, os dados recebidos da camada neural anterior serão usados para a propagação para frente dos blocos 1 e 3.
if(!cConvs[2].FeedForward(NeuronOCL)) return false; if(!cNorm[2].FeedForward(GetPointer(cConvs[2]))) return false;
Os resultados serão somados e normalizados.
if(!SumAndNormilize(cNorm[1].getOutput(), cNorm[2].getOutput(), Output, iWindowOut, true)) return false; //--- return true; }
O processo reverso de distribuição do gradiente de erro é organizado no método CResidualConv::calcInputGradients. Seu algoritmo é bastante semelhante ao método de propagação para frente. Apenas chamamos os métodos homônimos das camadas internas, mas na ordem inversa.
bool CResidualConv::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!cNorm[2].calcInputGradients(GetPointer(cConvs[2]))) return false; if(!cConvs[2].calcInputGradients(GetPointer(cTemp))) return false; //--- if(!cNorm[1].calcInputGradients(GetPointer(cConvs[1]))) return false; if(!cConvs[1].calcInputGradients(GetPointer(cNorm[0]))) return false; if(!cNorm[0].calcInputGradients(prevLayer)) return false;
Aqui, vale destacar que substituímos os buffers de dados para eliminar a cópia inicial dos gradientes de erro nas camadas internas. E para a camada anterior, passamos a soma dos gradientes de erro de 2 fluxos de dados.
if(!SumAndNormilize(prevLayer.getGradient(), cTemp.getGradient(), prevLayer.getGradient(), iWindowOut, false)) return false; //--- return true; }
De maneira semelhante, preparamos o método que atualiza os parâmetros da classe CResidualConv::updateInputWeights; recomendo que você o estude por conta própria. O anexo contém o código completo da classe CResidualConv e todos os seus métodos, bem como o código completo de todos os programas utilizados na preparação deste artigo. E agora vejamos como construir o próximo bloco mediante o Codificador de características.
2.2 Codificador de características
O algoritmo do Codificador de características, proposto pelos autores do método CCMR, será implementado na classe CCCMREncoder, que também será herdada da classe base de camada neural totalmente conectada CNeuronBaseOCL.
class CCCMREncoder : public CNeuronBaseOCL { protected: CResidualConv cResidual[6]; CNeuronConvOCL cInput; CNeuronBatchNormOCL cNorm; CNeuronConvOCL cOutput; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CCCMREncoder(void) {}; ~CCCMREncoder(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defCCMREncoder; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); virtual void TrainMode(bool flag); ///< Set Training Mode Flag };
Neste classe, utilizaremos uma camada convolucional para projetar os dados brutos cInput, cujos resultados serão normalizados por uma camada de normalização em lotes cNorm, e uma camada convolucional para projetar os resultados do codificador cOutput. Graças ao uso dessas camadas de projeção, podemos ajustar a extração de características em múltiplas escalas, sem depender do tamanho dos dados brutos e da quantidade desejada de características.
A escalabilidade dos dados e a extração de características são realizadas em vários blocos convolucionais sequenciais com feedback, que agrupamos no array cResidual.
Como na classe anterior, todos os objetos internos da classe são declarados estáticos, permitindo que o construtor e o destrutor permaneçam vazios.
A inicialização dos objetos da classe é feita no método CCCMREncoder::Init, cujo algoritmo segue um esquema familiar. Os parâmetros do método recebem as constantes da arquitetura da classe.
bool CCCMREncoder::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_out * count, optimization_type, batch)) return false;
Dentro do método, inicialmente invocamos o método correspondente da classe pai para verificar os parâmetros recebidos e inicializar os objetos herdados. Controlamos o resultado da execução do método da classe pai com base no seu retorno lógico.
Depois, inicializamos o bloco de escalabilidade e normalização dos dados brutos, resultando na representação do estado do ambiente com 32 parâmetros.
if(!cInput.Init(0, 0, OpenCL, window, window, 32, count, optimization, iBatch)) return false; if(!cNorm.Init(0, 1, OpenCL, 32 * count, iBatch, optimization)) return false; cNorm.SetActivationFunction(LReLU);
Em seguida, criaremos uma cascata de escalabilidade de dados com quantidades de características {32, 64, 128}.
if(!cResidual[0].Init(0, 2, OpenCL, 32, 32, count, optimization, iBatch)) return false; if(!cResidual[1].Init(0, 3, OpenCL, 32, 32, count, optimization, iBatch)) return false;
if(!cResidual[2].Init(0, 4, OpenCL, 32, 64, count, optimization, iBatch)) return false; if(!cResidual[3].Init(0, 5, OpenCL, 64, 64, count, optimization, iBatch)) return false;
if(!cResidual[4].Init(0, 6, OpenCL, 64, 128, count, optimization, iBatch)) return false; if(!cResidual[5].Init(0, 7, OpenCL, 128, 128, count, optimization, iBatch)) return false;
Por fim, ajustamos a dimensionalidade dos dados ao tamanho definido pelo usuário.
if(!cOutput.Init(0, 8, OpenCL, 128, 128, window_out, count, optimization, iBatch)) return false;
Para evitar copiar excessivamente os resultados do bloco e os gradientes de erro, substituímos os buffers de dados.
if(Output != cOutput.getOutput()) { if(!!Output) delete Output; Output = cOutput.getOutput(); } //--- if(Gradient != cOutput.getGradient()) { if(!!Gradient) delete Gradient; Gradient = cOutput.getGradient(); } //--- return true; }
Controlamos a execução das operações em cada etapa e informamos o programa chamador sobre o resultado do método com um valor lógico.
O algoritmo de propagação para frente será implementado no método CCCMREncoder::feedForward. Nos parâmetros do método, recebemos um ponteiro para o objeto da camada anterior. Os métodos de propagação para frente dos objetos internos verificam se o ponteiro recebido é válido.
bool CCCMREncoder::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cInput.FeedForward(NeuronOCL)) return false; if(!cNorm.FeedForward(GetPointer(cInput))) return false;
Primeiro, escalamos e normalizamos os dados brutos. Em seguida, passamos os dados pela cascata de escalabilidade e extração de características.
Observe que o primeiro bloco convolucional com feedback recebe dados da camada de normalização em lotes, enquanto os blocos subsequentes recebem dados do bloco anterior do array. Isso nos permite iterar os blocos em um laço.
if(!cResidual[0].FeedForward(GetPointer(cNorm))) return false; for(int i = 1; i < 6; i++) if(!cResidual[i].FeedForward(GetPointer(cResidual[i - 1]))) return false;
O resultado das operações é escalado ao tamanho desejado.
if(!cOutput.FeedForward(GetPointer(cResidual[5]))) return false; //--- return true; }
A distribuição do gradiente de erro pelos objetos internos do codificador é feita na ordem inversa.
bool CCCMREncoder::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cInput.UpdateInputWeights(NeuronOCL)) return false; if(!cNorm.UpdateInputWeights(GetPointer(cInput))) return false; if(!cResidual[0].UpdateInputWeights(GetPointer(cNorm))) return false; for(int i = 1; i < 6; i++) if(!cResidual[i].UpdateInputWeights(GetPointer(cResidual[i - 1]))) return false; if(!cOutput.UpdateInputWeights(GetPointer(cResidual[5]))) return false; //--- return true; }
Neste artigo, não entraremos em detalhes sobre todos os métodos da classe, pois possuem uma estrutura modular similar de chamadas sequenciais dos métodos correspondentes dos objetos internos. Você poderá consultá-los facilmente no anexo, que contém o código completo de todos os programas utilizados na preparação deste artigo. Qualquer dúvida, estarei à disposição no fórum ou em mensagens privadas. A escolha do formato de contato fica a seu critério.
2.3 Agrupamento do contexto global com dinâmica
Para agrupar o contexto global considerando a dinâmica das mudanças nas características, os autores do método CCRM propuseram usar o bloco de atenção cruzada XCiT. Nele, as entidades Query e Key são formadas a partir das características do contexto global, enquanto Value — da dinâmica das características do ambiente em dois estados sucessivos. Esse uso do bloco difere um pouco do que discutimos anteriormente, e para implementar essa nova abordagem, precisamos fazer algumas melhorias.
Vamos criar uma nova classe CNeuronCrossXCiTOCL, que herdará grande parte da funcionalidade da implementação anterior do método XCiT.
class CNeuronCrossXCiTOCL : public CNeuronXCiTOCL { protected: CCollection cConcat; CCollection cValue; CCollection cV_Weights; CBufferFloat TempBuffer; uint iWindow2; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Motion); virtual bool Concat(CBufferFloat *input1, CBufferFloat *input2, CBufferFloat *output, int window1, int window2); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Motion); virtual bool DeConcat(CBufferFloat *input1, CBufferFloat *input2, CBufferFloat *output, int window1, int window2); public: CNeuronCrossXCiTOCL(void) {}; ~CNeuronCrossXCiTOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window1, uint window2, uint lpi_window, uint heads, uint units_count, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer, CNeuronBaseOCL *Motion); //--- virtual int Type(void) const { return defNeuronCrossXCiTOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); };
Note que nesta implementação, tentei ao máximo reutilizar a funcionalidade já criada. Na estrutura da classe, adicionamos três coleções de buffers de dados e um buffer auxiliar para armazenar dados intermediários.
Como antes, todos os objetos internos são declarados estáticos, permitindo que o construtor e o destrutor permaneçam vazios.
A inicialização de todos os objetos da classe é realizada no método CNeuronCrossXCiTOCL::Init.
bool CNeuronCrossXCiTOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window1, uint window2, uint lpi_window, uint heads, uint units_count, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronXCiTOCL::Init(numOutputs, myIndex, open_cl, window1, lpi_window, heads, units_count, layers, optimization_type, batch)) return false;
Nos parâmetros, o método recebe os principais parâmetros que definem a arquitetura da classe e seus objetos internos. No corpo do método, chamamos o método correspondente da classe pai, onde os parâmetros recebidos são verificados e todos os objetos herdados são inicializados.
Após a execução bem-sucedida do método da classe pai, definimos os parâmetros dos buffers para armazenar as entidades Value e seus gradientes de erro, além da matriz de pesos para gerar a referida entidade.
//--- Cross XCA iWindow2 = fmax(window2, 1); uint num = iWindowKey * iHeads * iUnits; //Size of V tensor uint v_weights = (iWindow2 + 1) * iWindowKey * iHeads; //Size of weights' matrix of V tensor
Em seguida, organizamos um laço para o número de camadas internas de atenção cruzada XCiT e, dentro do laço, criamos os buffers necessários. Primeiro, adicionamos o buffer para armazenar as entidades Value geradas e os gradientes de erro correspondentes.
for(uint i = 0; i < iLayers; i++) { CBufferFloat *temp = NULL; for(int d = 0; d < 2; d++) { //--- XCiT //--- Initilize V tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cValue.Add(temp)) return false;
Vale lembrar que na classe pai CNeuronXCiTOCL usamos um buffer concatenado para as entidades Query, Key e Value. Para podermos utilizar a funcionalidade herdada, concatenamos as referidas entidades de duas fontes em um único buffer da coleção cConcat.
//--- Initilize QKV tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(3 * num, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cConcat.Add(temp)) return false; }
O próximo passo é criar buffers para a matriz de pesos para gerar a entidade Value.
//--- XCiT //--- Initilize V weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(v_weights)) return false; float k = (float)(1 / sqrt(iWindow + 1)); for(uint w = 0; w < v_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!cV_Weights.Add(temp)) return false;
E buffers de momentos para otimizar a referida matriz de pesos.
for(int d = 0; d < (optimization == SGD ? 1 : 2); d++) { //--- XCiT temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(v_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cV_Weights.Add(temp)) return false; } }
Logo em seguida, inicializamos o buffer para armazenar dados intermediários.
TempBuffer.BufferInit(iWindow2 * iUnits, 0); if(!TempBuffer.BufferCreate(OpenCL)) return false; //--- return true; }
Durante todo esse processo, controlamos a execução das operações em cada etapa.
Transferimos a maior parte do método de propagação para frente, CNeuronCrossXCiTOCL::feedForward, da classe pai. No entanto, as características da atenção cruzada exigem que ele seja reimplementado. Em particular, para implementar a atenção cruzada, precisamos de dois conjuntos de dados brutos.
bool CNeuronCrossXCiTOCL::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Motion) { if(!NeuronOCL || !Motion) return false;
Dentro do método, verificamos se os ponteiros recebidos para os objetos de dados brutos são válidos e fazemos um laço para iterar pelas camadas internas.
for(uint i = 0; (i < iLayers && !IsStopped()); i++) { //--- Calculate Queries, Keys, Values CBufferFloat *inputs = (i == 0 ? NeuronOCL.getOutput() : FF_Tensors.At(4 * i - 2)); CBufferFloat *qkv = QKV_Tensors.At(i * 2); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), inputs, qkv, iWindow, 2 * iWindowKey * iHeads, None)) return false;
Dentro do laço, primeiro geramos as entidades Query e Key a partir dos dados da camada neural anterior. Assumimos que neste fluxo de informação obtemos o contexto global GCs.
Observe que utilizamos buffers das coleções herdadas QKV_Tensors e QKV_Weights, mas geramos apenas 2 entidades. A prova disso é a quantidade de filtros de convolução "2 * iWindowKey * iHeads".
De maneira semelhante, geramos a terceira entidade, Value, usando outros dados brutos.
CBufferFloat *v = cValue.At(i * 2); if(IsStopped() || !ConvolutionForward(cV_Weights.At(i * (optimization == SGD ? 2 : 3)), Motion, v, iWindow, iWindowKey * iHeads, None)) return false;
Como mencionado anteriormente, concatenamos todas as 3 entidades em um único tensor para possibilitar o uso da funcionalidade herdada.
if(IsStopped() || !Concat(qkv, v, cConcat.At(2 * i), 2 * iWindowKey * iHeads, iWindowKey * iHeads)) return false;
Em seguida, utilizamos a funcionalidade herdada, mas há um detalhe. Nesta implementação, o número de elementos na sequência em ambos os fluxos é idêntico. No nível superior, geramos ambos os fluxos a partir dos mesmos dados brutos. Com isso em mente, não verifiquei se as sequências eram iguais. Porém, para que a funcionalidade a seguir opere corretamente, essa correspondência é importante. Portanto, se você quiser usar esta classe separadamente, por favor, assegure-se de que as sequências tenham o mesmo comprimento.
Determinamos os resultados da atenção multi-cabeça.
//--- Score calculation CBufferFloat *temp = S_Tensors.At(i * 2); CBufferFloat *out = AO_Tensors.At(i * 2); if(IsStopped() || !XCiT(cConcat.At(2 * i), temp, out)) return false;
Somamos e normalizamos os fluxos de dados.
//--- Sum and normilize attention if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false;
Em seguida, há um bloco de interação local, seguido pela soma e normalização dos fluxos.
//--- LPI inputs = out; temp = cLPI.At(i * 6); if(IsStopped() || !ConvolutionForward(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7)), inputs, temp, iLPIWindow, iHeads, LReLU, iLPIStep)) return false; out = cLPI.At(i * 6 + 1); if(IsStopped() || !BatchNorm(temp, cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 1), out)) return false; temp = out; out = cLPI.At(i * 6 + 2); if(IsStopped() || !ConvolutionForward(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 2), temp, out, 2 * iHeads, 2, None, iHeads)) return false; //--- Sum and normilize attention if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false;
Bem como pelo bloco FeedForward.
//--- Feed Forward inputs = out; temp = FF_Tensors.At(i * 4); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 4 : 6)), inputs, temp, iWindow, 4 * iWindow, LReLU)) return false; out = FF_Tensors.At(i * 4 + 1); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 4 : 6) + 1), temp, out, 4 * iWindow, iWindow, activation)) return false; //--- Sum and normilize out if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false; } iBatchCount++; //--- return true; }
Após a iteração bem-sucedida de todas as camadas neurais internas, concluímos o método.
Observe que, neste método, para todas as camadas neurais internas, utilizamos um único buffer de dados brutos de dinâmica de características. Enquanto o contexto global é gradualmente alterado e transformado em um contexto global com dinâmica de características — Context-guided Motion Features (CMF).
Distribuímos o gradiente de erro pelos objetos internos de maneira semelhante, mas na ordem inversa. O algoritmo para isso é descrito no método CNeuronCrossXCiTOCL::calcInputGradients. Nos parâmetros, o método recebe ponteiros para 2 objetos de dados brutos com buffers dos gradientes de erro correspondentes que precisamos preencher.
bool CNeuronCrossXCiTOCL::calcInputGradients(CNeuronBaseOCL *prevLayer, CNeuronBaseOCL *Motion) { if(!prevLayer || !Motion) return false;
Dentro do método, primeiro verificamos se os ponteiros recebidos são válidos. Depois, criamos um laço para iterar pelas camadas internas na ordem inversa.
CBufferFloat *out_grad = Gradient; //--- for(int i = int(iLayers - 1); (i >= 0 && !IsStopped()); i--) { //--- Passing gradient through feed forward layers if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 4 : 6) + 1), out_grad, FF_Tensors.At(i * 4), FF_Tensors.At(i * 4 + 2), 4 * iWindow, iWindow, None)) return false; CBufferFloat *temp = cLPI.At(i * 6 + 5); if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 4 : 6)), FF_Tensors.At(i * 4 + 1), cLPI.At(i * 6 + 2), temp, iWindow, 4 * iWindow, LReLU)) return false;
Dentro do laço, a primeira coisa que fazemos é passar o gradiente de erro pelo bloco FeedForward.
Lembro que durante o processo de propagação para frente, somamos e normalizamos os dados brutos e a saída de cada bloco. Portanto, durante a propagação reversa, também precisamos propagar o gradiente de erro por ambos os fluxos de informação. Assim, após passar o gradiente de erro pelo bloco FeedForward, devemos somar os gradientes de erro dos dois fluxos.
//--- Sum gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false, 0, 0, 0, 1)) return false;
Da mesma forma, propagamos o gradiente de erro através do bloco de interação local e somamos os gradientes de erro dos dois fluxos de dados.
out_grad = temp; //--- Passing gradient through LPI if(IsStopped() || !ConvolutionInputGradients(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 2), temp, cLPI.At(i * 6 + 1), cLPI.At(i * 6 + 4), 2 * iHeads, 2, None, 0, iHeads)) return false; if(IsStopped() || !BatchNormInsideGradient(cLPI.At(i * 6), cLPI.At(i * 6 + 3), cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 1), cLPI.At(i * 6 + 1), cLPI.At(i * 6 + 4), LReLU)) return false; if(IsStopped() || !ConvolutionInputGradients(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7)), cLPI.At(i * 6 + 3), AO_Tensors.At(i * 2), AO_Tensors.At(i * 2 + 1), iLPIWindow, iHeads, None, 0, iLPIStep)) return false; temp = AO_Tensors.At(i * 2 + 1); //--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false, 0, 0, 0, 1)) return false;
O estágio final consiste na propagação do gradiente de erro através do bloco de atenção.
//--- Passing gradient to query, key and value if(IsStopped() || !XCiTInsideGradients(cConcat.At(i * 2), cConcat.At(i * 2 + 1), S_Tensors.At(i * 2), temp)) return false;
No entanto, aqui obtemos um buffer concatenado de gradientes de erro para 3 entidades: Query, Key e Value. Mas lembramos que as entidades foram geradas a partir de diferentes fontes de dados. Precisamos distribuir o gradiente de erro sobre elas. Primeiro, dividimos um buffer em dois.
if(IsStopped() || !DeConcat(QKV_Tensors.At(i * 2 + 1), cValue.At(i * 2 + 1), cConcat.At(i * 2 + 1), 2 * iWindowKey * iHeads, iWindowKey * iHeads)) return false;
Em seguida, chamamos os métodos de propagação de gradientes para os dados brutos correspondentes. Mas se para Query e Key podemos usar a funcionalidade herdada, com Value é um pouco mais complicado.
//--- CBufferFloat *inp = NULL; if(i == 0) { inp = prevLayer.getOutput(); temp = prevLayer.getGradient(); } else { temp = FF_Tensors.At(i * 4 - 1); inp = FF_Tensors.At(i * 4 - 3); } if(IsStopped() || !ConvolutionInputGradients(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), QKV_Tensors.At(i * 2 + 1), inp, temp, iWindow, 2 * iWindowKey * iHeads, None)) return false;
Na passagem para frente, destaquei que para todas as camadas usamos um buffer de dinâmica de características. Ao propagar o gradiente de erro para o buffer do objeto de dados brutos, ele simplesmente sobrescreverá e eliminará os dados previamente armazenados de outras camadas internas. Assim, durante a passagem para frente, escreveremos apenas na primeira iteração (última camada interna).
if(i > 0) out_grad = temp; if(i == iLayers - 1) { if(IsStopped() || !ConvolutionInputGradients(cV_Weights.At(i * (optimization == SGD ? 2 : 3)), cValue.At(i * 2 + 1), Motion.getOutput(), Motion.getGradient(), iWindow, iWindowKey * iHeads, None)) return false; }
Nos outros casos, usaremos um buffer auxiliar para armazenar dados temporários, somando os novos e os gradientes acumulados anteriormente.
else { if(IsStopped() || !ConvolutionInputGradients(cV_Weights.At(i * (optimization == SGD ? 2 : 3)), cValue.At(i * 2 + 1), Motion.getOutput(), GetPointer(TempBuffer), iWindow, iWindowKey * iHeads, None)) return false; if(IsStopped() || !SumAndNormilize(GetPointer(TempBuffer), Motion.getGradient(), Motion.getGradient(), iWindow2, false)) return false; }
Somamos os gradientes de erro pelos dois fluxos de dados e passamos para a próxima iteração do ciclo.
if(IsStopped() || !ConvolutionInputGradients(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), QKV_Tensors.At(i * 2 + 1), inp, temp, iWindow, 2 * iWindowKey * iHeads, None)) return false; //--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false, 0, 0, 0, 1)) return false; if(i > 0) out_grad = temp; } //--- return true; }
Após propagarmos com sucesso o gradiente de erro por todas as camadas internas, concluímos o método.
Para distribuir o gradiente de erro entre todos os objetos internos e dados brutos conforme sua influência no resultado final, ajustaremos os parâmetros do modelo para minimizar o erro. Este processo é realizado no método CNeuronCrossXCiTOCL::updateInputWeights. Da mesma forma que nos dois métodos discutidos anteriormente, vamos atualizar os parâmetros dos objetos internos durante o ciclo de iteração sequencial das camadas neurais internas.
bool CNeuronCrossXCiTOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Motion) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false; CBufferFloat *inputs = NeuronOCL.getOutput(); for(uint l = 0; l < iLayers; l++) { if(IsStopped() || !ConvolutuionUpdateWeights(QKV_Weights.At(l * (optimization == SGD ? 2 : 3)), QKV_Tensors.At(l * 2 + 1), inputs, (optimization == SGD ? QKV_Weights.At(l * 2 + 1) : QKV_Weights.At(l * 3 + 1)), (optimization == SGD ? NULL : QKV_Weights.At(l * 3 + 2)), iWindow, 2 * iWindowKey * iHeads)) return false; if(IsStopped() || !ConvolutuionUpdateWeights(cV_Weights.At(l * (optimization == SGD ? 2 : 3)), cValue.At(l * 2 + 1), inputs, (optimization == SGD ? cV_Weights.At(l * 2 + 1) : cV_Weights.At(l * 3 + 1)), (optimization == SGD ? NULL : cV_Weights.At(l * 3 + 2)), iWindow, iWindowKey * iHeads)) return false;
Primeiro, atualizamos os parâmetros de geração das entidades Query, Key e Value. Em seguida, vem o bloco de interação local LPI.
if(IsStopped() || !ConvolutuionUpdateWeights(cLPI_Weights.At(l * (optimization == SGD ? 5 : 7)), cLPI.At(l * 6 + 3), AO_Tensors.At(l * 2), (optimization == SGD ? cLPI_Weights.At(l * 5 + 3) : cLPI_Weights.At(l * 7 + 3)), (optimization == SGD ? NULL : cLPI_Weights.At(l * 7 + 5)), iLPIWindow, iHeads, iLPIStep)) return false; if(IsStopped() || !BatchNormUpdateWeights(cLPI_Weights.At(l * (optimization == SGD ? 5 : 7) + 1), cLPI.At(l * 6 + 4))) return false; if(IsStopped() || !ConvolutuionUpdateWeights(cLPI_Weights.At(l * (optimization == SGD ? 5 : 7) + 2), cLPI.At(l * 6 + 5), cLPI.At(l * 6 + 1), (optimization == SGD ? cLPI_Weights.At(l * 5 + 4) : cLPI_Weights.At(l * 7 + 4)), (optimization == SGD ? NULL : cLPI_Weights.At(l * 7 + 6)), 2 * iHeads, 2, iHeads)) return false;
E concluímos com o bloco FeedForward.
if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 4 : 6)), FF_Tensors.At(l * 4 + 2), cLPI.At(l * 6 + 2), (optimization == SGD ? FF_Weights.At(l * 4 + 2) : FF_Weights.At(l * 6 + 2)), (optimization == SGD ? NULL : FF_Weights.At(l * 6 + 4)), iWindow, 4 * iWindow)) return false; //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 4 : 6) + 1), FF_Tensors.At(l * 4 + 3), FF_Tensors.At(l * 4), (optimization == SGD ? FF_Weights.At(l * 4 + 3) : FF_Weights.At(l * 6 + 3)), (optimization == SGD ? NULL : FF_Weights.At(l * 6 + 5)), 4 * iWindow, iWindow)) return false; inputs = FF_Tensors.At(l * 4 + 1); } //--- return true; }
Com isso, concluímos a revisão dos métodos da classe CNeuronCrossXCiTOCL. Claro, no âmbito deste artigo não podemos nos deter detalhadamente em todos os métodos da classe. Mas você pode revisá-los por conta própria no anexo. Lá, você encontrará o código completo de todas as classes e seus métodos. Além de todos os programas utilizados na preparação deste artigo.
2.4 Implementação do algoritmo CCMR
Acima, realizamos um trabalho bastante extenso na criação de novas classes. Mas ainda assim, foi um trabalho preparatório. Agora vamos iniciar a implementação da nossa visão do algoritmo CCMR. Ressalto que esta é a nossa visão dos métodos propostos. E pode diferir da visão do autor. No entanto, tentamos incorporar os métodos propostos para resolver nossas tarefas.
Para implementar o método, criaremos a classe CNeuronCCMROCL, que herdará a funcionalidade básica da classe CNeuronBaseOCL. A estrutura da nova classe é apresentada abaixo.
class CNeuronCCMROCL : public CNeuronBaseOCL { protected: CCCMREncoder FeatureExtractor; CNeuronBaseOCL PrevFeatures; CNeuronBaseOCL Motion; CNeuronBaseOCL Temp; CCCMREncoder LocalContext; CNeuronXCiTOCL GlobalContext; CNeuronCrossXCiTOCL MotionContext; CNeuronLSTMOCL RecurentUnit; CNeuronConvOCL UpScale; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronCCMROCL(void) {}; ~CNeuronCCMROCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronCCMROCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual void SetOpenCL(COpenCLMy *obj); virtual void TrainMode(bool flag); ///< Set Training Mode Flag virtual bool Clear(void); };
Nela, encontramos um conjunto conhecido de métodos e uma série de objetos, a maioria dos quais já foi criada anteriormente. Criamos 2 instâncias da classe CCCMREncoder para extrair características do estado do ambiente e do contexto local (FeatureExtractor e LocalContext, respectivamente).
Utilizamos a instância do objeto CNeuronXCiTOCL para obter o contexto global (GlobalContext). E com o CNeuronCrossXCiTOCL ajustamos isso considerando a dinâmica das características até CMF (MotionContext).
Para implementar conexões recorrentes, usamos o bloco LSTM (CNeuronLSTMOCL RecurentUnit) em vez de GRU.
Vamos entender a função de todos os objetos internos durante a implementação dos métodos da classe.
Como antes, declaramos todos os objetos internos da classe como estáticos. Portanto, o construtor e o destrutor da classe permanecem "vazios".
A inicialização dos objetos internos da classe é realizada no método CNeuronCCMROCL::Init.
bool CNeuronCCMROCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_out * count, optimization_type, batch)) return false;
Nos parâmetros do método, recebemos as constantes-chave da arquitetura da classe. Dentro do método, chamamos imediatamente um método semelhante da classe pai para verificar os parâmetros recebidos e inicializar os objetos herdados.
Após a execução bem-sucedida do método da classe pai, passamos para a inicialização dos objetos internos. Primeiro, inicializamos o Codificador de características do estado atual do ambiente.
if(!FeatureExtractor.Init(0, 0, OpenCL, window, 16, count, optimization, iBatch)) return false;
Vale notar que para avaliar o fluxo, o método CCMR usa snapshots de 2 estados consecutivos do sistema. Abordamos essa questão de forma um pouco diferente. Em cada iteração da passagem para frente, geramos características de apenas um estado do ambiente. E salvamos isso em um buffer local chamado PrevFeatures. Usamos o valor desse buffer para avaliar o fluxo dinâmico na próxima passagem para frente. Inicializamos os objetos do buffer local do estado anterior e das alterações das características.
if(!PrevFeatures.Init(0, 1, OpenCL, 16 * count, optimization, iBatch)) return false; if(!Motion.Init(0, 2, OpenCL, 16 * count, optimization, iBatch)) return false;
Para evitar cópias desnecessárias de dados, substituímos os buffers.
if(Motion.getGradientIndex() != FeatureExtractor.getGradientIndex())
Motion.SetGradientIndex(FeatureExtractor.getGradientIndex());
Em seguida, com base no estado atual do ambiente, geramos características de contexto usando o Codificador LocalContext. Aqui, é importante notar que usamos um conjunto de dados em 2 fluxos de informação. Assim, obteremos o gradiente de erro de 2 fluxos. Para permitir a soma dos gradientes, criaremos um buffer de dados locais.
if(!Temp.Init(0, 3, OpenCL, window * count, optimization, iBatch)) return false; if(!LocalContext.Init(0, 4, OpenCL, window, 16, count, optimization, iBatch)) return false;
Os mecanismos de atenção nos permitirão agrupar contextos locais em um contexto global.
if(!GlobalContext.Init(0, 5, OpenCL, 16, 3, 4, count, 4, optimization, iBatch)) return false;
Que posteriormente ajustaremos com base na dinâmica do fluxo.
if(!MotionContext.Init(0, 6, OpenCL, 16, 16, 3, 4, count, 4, optimization, iBatch)) return false;
Finalmente, atualizamos o fluxo no bloco recorrente.
if(!RecurentUnit.Init(0, 7, OpenCL, 16 * count, optimization, iBatch) || !RecurentUnit.SetInputs(16 * count)) return false;
Para reduzir o volume do modelo, usamos objetos internos de estado bastante compactos. No entanto, o usuário pode precisar dos dados em outra dimensão. Para ajustar os resultados à dimensão necessária, utilizamos uma camada de escalonamento.
if(!UpScale.Init(0, 8, OpenCL, 16, 16, window_out, count, optimization, iBatch)) return false;
E para evitar copiar dados desnecessariamente, implementamos a troca dos buffers de dados.
if(UpScale.getGradientIndex() != getGradientIndex()) SetGradientIndex(UpScale.getGradientIndex()); if(UpScale.getOutputIndex() != getOutputIndex()) Output.BufferSet(UpScale.getOutputIndex()); //--- return true; }
O algoritmo de passagem para frente está implementado no método CNeuronCCMROCL::feedForward. No método de passagem para frente, os parâmetros incluem um ponteiro para o objeto da camada anterior, que contém os dados brutos.
bool CNeuronCCMROCL::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- Delta Features if(!SumAndNormilize(FeatureExtractor.getOutput(), FeatureExtractor.getOutput(), PrevFeatures.getOutput(), 1, false, 0, 0, 0, -0.5f)) return false;
No corpo do método, antes de qualquer operação, transferimos o conteúdo do buffer de resultados do Codificador de características do estado do ambiente para o buffer do estado anterior. É fácil deduzir que, antes do início das iterações, o buffer contém os resultados da passagem anterior.
Ao transferir os dados, observe que alteramos o sinal da característica para o oposto.
Após salvar os dados, realizamos a propagação para frente do Codificador do estado.
if(!FeatureExtractor.FeedForward(NeuronOCL)) return false;
Após a propagação bem-sucedida do FeatureExtractor, temos as características de 2 estados consecutivos e podemos determinar a variação. Para simplificar, apenas pegamos a diferença das características. Ao salvar o estado anterior, mudamos o sinal das características. E agora, para obter a diferença dos estados, podemos somar o conteúdo dos buffers.
if(!SumAndNormilize(FeatureExtractor.getOutput(), PrevFeatures.getOutput(), Motion.getOutput(), 1, false, 0, 0, 0, 1.0f)) return false;
O próximo passo é gerar as características do contexto local.
if(!LocalContext.FeedForward(NeuronOCL)) return false;
Extraímos o contexto global.
if(!GlobalContext.FeedForward(GetPointer(LocalContext))) return false;
E ajustamos com base na dinâmica das mudanças.
if(!MotionContext.FeedForward(GetPointer(GlobalContext), Motion.getOutput())) return false;
Em seguida, ajustamos o fluxo no bloco recorrente.
//--- Flow if(!RecurentUnit.FeedForward(GetPointer(MotionContext))) return false;
E escalamos os dados para o tamanho necessário.
if(!UpScale.FeedForward(GetPointer(RecurentUnit))) return false; //--- return true; }
Durante a implementação, não esquecemos de controlar o processo em cada etapa.
O algoritmo de propagação reversa é implementado no método CNeuronCCMROCL::calcInputGradients. Similar aos métodos correspondentes de outras classes, nos parâmetros do método recebemos um ponteiro para o objeto da camada anterior. No método, chamamos sequencialmente os métodos dos objetos internos, seguindo uma ordem inversa à da propagação.
bool CNeuronCCMROCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!UpScale.calcInputGradients(GetPointer(RecurentUnit))) return false;
Primeiro, passamos o gradiente do erro pela camada de escalonamento. E depois pelo bloco recorrente.
if(!RecurentUnit.calcInputGradients(GetPointer(MotionContext))) return false;
Em seguida, passamos o gradiente do erro sequencialmente por todas as etapas de transformação do contexto.
if(!MotionContext.calcInputGradients(GetPointer(GlobalContext), GetPointer(Motion))) return false; if(!GlobalContext.calcInputGradients(GetPointer(LocalContext))) return false; if(!LocalContext.calcInputGradients(GetPointer(Temp))) return false;
Devido à substituição dos buffers de dados, o gradiente do erro da dinâmica das características é transferido para o Codificador de características do estado. E propagamos o gradiente de erro através do Codificador até o buffer da camada anterior.
if(!FeatureExtractor.calcInputGradients(prevLayer)) return false;
E adicionamos o gradiente do erro do Codificador de contexto.
if(!SumAndNormilize(prevLayer.getGradient(), Temp.getGradient(), prevLayer.getGradient(), 1, false, 0, 0, 0, 1.0f)) return false; //--- return true; }
O método de atualização dos parâmetros do modelo não se destaca pela complexidade do algoritmo. Apenas atualizamos sequencialmente os parâmetros dos objetos internos.
bool CNeuronCCMROCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!FeatureExtractor.UpdateInputWeights(NeuronOCL)) return false; if(!LocalContext.UpdateInputWeights(NeuronOCL)) return false; if(!GlobalContext.UpdateInputWeights(GetPointer(LocalContext))) return false; if(!MotionContext.UpdateInputWeights(GetPointer(GlobalContext), Motion.getOutput())) return false; if(!RecurentUnit.UpdateInputWeights(GetPointer(MotionContext))) return false; if(!UpScale.UpdateInputWeights(GetPointer(RecurentUnit))) return false; //--- return true; }
É importante notar que esta classe contém um bloco recorrente e um buffer de salvamento do estado anterior. Por isso, precisamos redefinir o método de limpeza da parte recorrente CNeuronCCMROCL::Clear. Aqui chamamos o respectivo método do bloco recorrente e preenchemos com zeros o buffer de resultados do FeatureExtractor.
bool CNeuronCCMROCL::Clear(void) { if(!RecurentUnit.Clear()) return false; //--- CBufferFloat *temp = FeatureExtractor.getOutput(); temp.BufferInit(temp.Total(), 0); if(!temp.BufferWrite()) return false; //--- return true; }
Observe que zeramos o buffer de resultados do Codificador, e não o buffer do estado anterior. Lembre-se que, no início do método de propagação para frente, copiamos os dados do buffer de resultados do Codificador para o buffer do estado anterior.
Com isso, concluímos a análise dos principais métodos de implementação das abordagens CCMR. Realizamos um bom trabalho, e o artigo já está no limite de tamanho. Então, sugiro que você dê uma olhada nos métodos auxiliares no anexo para entender melhor o algoritmo. Lá você encontrará o código completo de todas as classes e seus métodos de implementação das abordagens CCMR. Além disso, no anexo você encontrará o código completo de todos os programas utilizados na preparação do artigo. Agora vamos analisar a arquitetura dos modelos treinados.
2.5. Arquitetura dos modelos
Ao descrever a arquitetura dos modelos, é importante mencionar que as abordagens CCMR afetaram apenas o Codificador do estado do ambiente.
A arquitetura dos modelos que vamos treinar é apresentada no método CreateDescriptions, em cujos parâmetros passaremos três arrays dinâmicos para registrar a arquitetura do Codificador, do Ator e do Crítico.
bool CreateDescriptions(CArrayObj *encoder, CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
No corpo do método, verificamos os ponteiros recebidos e, se necessário, criamos novas instâncias de arrays.
Alimentamos o Codificador com os dados não processados do estado atual do ambiente.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Os dados recebidos passam por um pré-processamento na camada de normalização em lote.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Em seguida, formamos uma pilha de embeddings dos estados.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize / 2; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.step = descr.window = prev_wout; prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Aos embeddings obtidos, adicionamos uma codificação posicional.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!encoder.Add(descr)) { delete descr; return false; }
E a arquitetura do Codificador é complementada pelo nosso novo bloco CNeuronCCMROCL, que é bastante complexo e requer processamento adicional.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCCMROCL; descr.count = prev_count; descr.window = prev_wout; descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
A arquitetura do Ator e do Crítico foi transferida sem alterações do artigo anterior. No link, você encontrará uma descrição detalhada da arquitetura dos modelos. Além disso, a arquitetura completa dos modelos está apresentada no anexo. Agora vamos para a etapa final, que é o teste do trabalho realizado.
3. Teste
Nas seções anteriores deste artigo, exploramos o método CCMR e implementamos as abordagens propostas nele usando MQL5. Agora é hora de verificar na prática os resultados do trabalho realizado. Como de costume, para treinar e testar os modelos, utilizamos dados históricos do instrumento EURUSD no timeframe H1. O treinamento dos modelos é realizado com dados dos primeiros 7 meses de 2023. O teste do modelo treinado é realizado no testador de estratégias MetaTrader 5 com dados históricos de agosto de 2023.
Neste artigo, utilizei um conjunto de dados de treinamento coletado anteriormente em trabalhos anteriores para treinar o modelo. Durante o treinamento, desenvolvi um modelo capaz de gerar lucro tanto no conjunto de dados de treinamento quanto no período de teste.
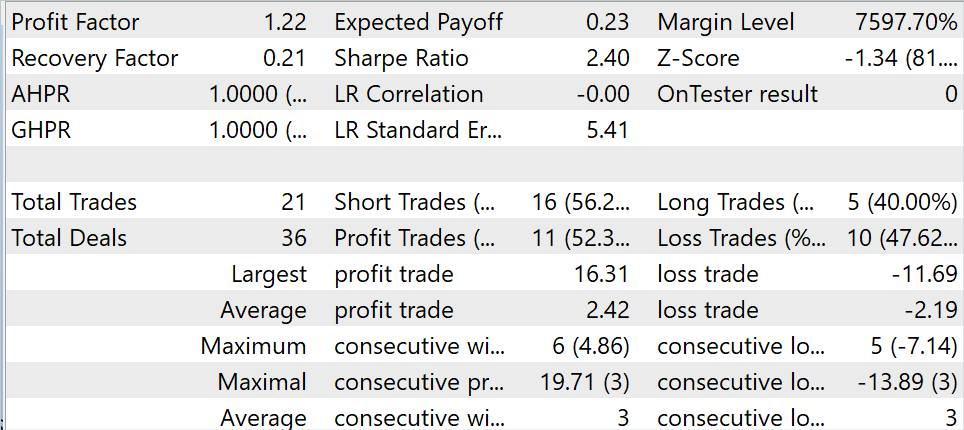
Durante o período de teste, o modelo realizou 21 negociações, 52,3% das quais foram fechadas com lucro. Tanto o lucro máximo quanto o lucro médio das negociações lucrativas superaram os correspondentes das negociações com perda. Isso permitiu obter um fator de lucro de 1,22.
Considerações finais
Neste artigo, exploramos um método de avaliação de fluxo óptico denominado CCMR, que combina as vantagens dos conceitos de agregação de movimento baseado em contexto e da abordagem multiescala de grosso para fino. Isso possibilita a obtenção de mapas de fluxo detalhados, com alta precisão mesmo em áreas com oclusões.
Os autores do método propuseram uma estratégia de agrupamento de movimento em duas etapas. Primeiro, calculam-se as características contextuais globais. Em seguida, essas características são empregadas para orientar iterativamente as características de movimento em todas as escalas. Isso possibilita o uso de algoritmos baseados em XCiT para processar todas as escalas de maneira detalhada, preservando o conteúdo específico de cada uma delas.
Na parte prática do artigo, implementamos as abordagens propostas usando MQL5. Treinamos e testamos o modelo com dados reais no testador de estratégias MetaTrader 5. Os resultados obtidos indicam a eficácia das abordagens propostas.
No entanto, é importante lembrar que todos os programas apresentados no artigo são apenas para fins informativos e destinam-se exclusivamente à demonstração das abordagens propostas.
Links
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | EA | EA de coleta de exemplos |
| 2 | ResearchRealORL.mq5 | EA | EA de coleta de exemplos pelo método Real-ORL |
| 3 | Study.mq5 | EA | EA de treinamento de Modelos |
| 4 | Test.mq5 | EA | EA para teste de modelo |
| 5 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 6 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de rede neural |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/14505
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso